В течение последних месяцев в нескольких проектах наш партнер использовал виртуальную машину для обработки и анализа данных (DSVM) на базе Ubuntu от Microsoft. Он решил попробовать ее в деле уже используя продукт Amazon. Рассмотрим все плюсы и минусы, а также сравним наш инструмент с похожими решениями. Присоединяйтесь!

Передаю слово автору.
Вначале мне не очень хотелось проверять ее в деле — у меня уже был настроенный экземпляр AMI для глубокого обучения в Amazon AWS. Я часто им пользуюсь, и он доступен всем читателям PyImageSearch для применения в собственных проектах.

Я не поклонник пользовательского интерфейса Amazon AWS, но за несколько лет к нему приспособился. Полагаю, в его неуклюжей сложности есть что-то знакомое. Однако мне попадались настолько хорошие отзывы о Ubuntu DSVM, что я все-таки решил ее опробовать. И она превзошла все мои ожидания. Более удобный интерфейс. Отличная производительность. Разумная цена.
…И кроме того, весь код из книги Deep Learning for Computer Vision with Python заработал на ней без единого изменения. Microsoft любезно разрешила мне опубликовать ряд гостевых статей в блоге компании о машинном обучении, в которых я оценил виртуальную машину и поделился впечатлениями от ее использования и тестирования:
Microsoft активно работает над тем, чтобы предлагаемая ими среда рассматривалась как приоритетная при выборе облачной платформы для глубокого обучения, машинного обучения, обработки и анализа данных. Качество их продукта DSVM служит наглядной иллюстрацией этого стремления.
В этой статье я хотел бы поделиться мыслями о DSVM, показать, как запустить первый экземпляр машины и начать выполнять на нем код для глубокого обучения. Если вас интересует виртуальная машина для глубокого обучения от Microsoft (и вы хотите понять, подходит ли она для решения ваших задач), эта статья для вас.
При первом знакомстве с виртуальной машиной Microsoft для глубокого обучения, обработки и анализа данных (DSVM) я взял все образцы кода из книги Deep Learning for Computer Vision with Python и запустил каждый из них в DSVM. Ручной запуск каждого образца и проверка результатов — монотонная работа, но она помогла изучить особенности DSVM и оценить ее по следующим параметрам:
Программный код, сопровождающий книгу Deep Learning for Computer Vision with Python, отлично подходит для такого рода испытаний.
Код из пакета Starter Bundle предназначен для первого знакомства с классификацией изображений, глубоким обучением и сверточными нейронными сетями (СНС). Если этот код будет без проблем выполнен в DSVM, значит, машину можно рекомендовать новичкам, которым нужна готовая среда для освоения глубокого обучения.
Учебные материалы и прилагаемый код из пакета Practitioner Bundle посвящены гораздо более продвинутым технологиям (переносу обучения, тонкой настройке генеративно-состязательных сетей и т. п.). Именно такие технологии применяют в своей повседневной работе практикующие специалисты и инженеры.
Если DSVM справится и с этими примерами, значит, ее можно рекомендовать практикующим специалистам в сфере глубокого обучения. И наконец, для работы кода из пакета ImageNet Bundle нужны производительные GPU (чем мощнее, тем лучше) и высокая пропускная способность операций ввода-вывода. В рамках этого пакета я показываю, как воспроизвести результаты из самых передовых публикаций (например, в ResNet, SqueezeNet и т. п.), полученные на огромных наборах графических данных (пример — набор ImageNet, состоящий из 1,2 млн изображений).
Если DSVM способна воспроизвести результаты из самых продвинутых статей, значит, ее можно рекомендовать исследователям. В первой половине статьи я представлю результаты каждого из описанных тестов и мои личные впечатления. Затем я покажу, как запустить в облаке Microsoft ваш первый экземпляр системы глубокого обучения и выполнить в DSVM первый фрагмент соответствующего кода.
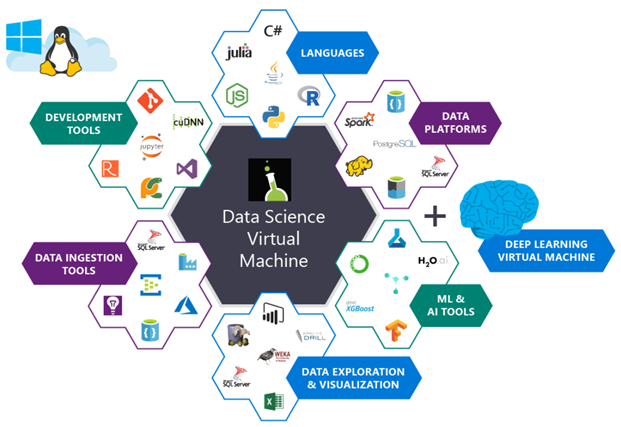
Рис. 1. На иллюстрации показаны пакеты, которые установлены на виртуальной машине Microsoft Azure для обработки и анализа данных. Они уже настроены и готовы к использованию
Виртуальная машина Microsoft для глубокого обучения работает в облаке Azure, которое также принадлежит корпорации. Технически на ней можно запустить как Windows, так и Linux, но для проектов глубокого обучения я бы рекомендовал использовать созданный компанией экземпляр Ubuntu DSVM (если только у вас нет причин использовать именно Windows).
Список пакетов, предварительно установленных на DSVM, довольно обширен — полный перечень доступен здесь. Ниже я перечислил наиболее важные пакеты для решения задач глубокого обучения и компьютерного зрения (в частности, те из них, которые могут заинтересовать читателей PyImageSearch), чтобы вы представляли, насколько их много.
Создатели DSVM выпускают новые версии машины с самыми актуальными предустановленными и настроенными версиями пакетов каждые несколько месяцев. Это огромный труд, демонстрирующий как невероятные усилия команды DSVM в плане обеспечения стабильной работы экземпляра (устранение потенциальных конфликтов между пакетами DSVM должно быть непростой задачей, но при этом машина совершенно прозрачна для пользователя), так и стремление Microsoft выпускать продукт, взаимодействовать с которым было бы удобно и приятно пользователям.
Для запуска DSVM можно использовать как экземпляры, оснащенные только ЦП, так и экземпляры с GPU.
Большая часть описанных ниже экспериментов и тестов выполнялась на экземпляре Ubuntu GPU, который оснащен стандартным NVIDIA K80 GPU. Кроме того, Microsoft предоставила мне доступ к недавно выпущенному монстру NVIDIA V100, и несколько быстрых тестов я провел на нем (Результаты приводятся ниже). Для проведения всех экспериментов в рамках пакетов Starter Bundle и Practitioner Bundle я использовал Microsoft Jupyter Notebook. Процесс оказался невероятно простым.
Я скопировал и вставил URL-адрес сервера Jupyter Notebook в адресную строку браузера, запустил новый блокнот и уже через несколько минут выполнял фрагменты кода из книги.
Для экспериментов с ImageNet Bundle я использовал SSH, поскольку воспроизведение результатов из самых передовых публикаций требует потратить несколько дней на обучение. К тому же мне кажется, что это не лучший вариант использования блокнотов Jupyter.

Рис. 2. Обучение архитектуры LeNet на наборе данных MNIST. Эту комбинацию часто называют «Hello World глубокого обучения»
В рамках моей первой гостевой публикации в блоге Microsoft я обучил простую сверточную нейронную сеть (LeNet) на наборе рукописных цифр MNIST. Обучение LeNet на наборе MNIST, вероятнее всего, станет первым «реальным» экспериментом для новичка, осваивающего технологии глубокого обучения.
И модель, и набор данных организованы очень понятно. Для обучения можно использовать ЦП или GPU. Я взял образец кода из 14-й главы книги Deep Learning for Computer Vision with Python (пакет Starter Bundle) и запустил его в блокноте Jupyter Notebook (он доступен здесь) на Microsoft DSVM. Результаты показаны на рисунке 2 выше.
После 20 эпох обучения точность классификации составила 98%. Все остальные образцы кода из пакета Starter Bundle книги Deep Learning for Computer Vision with Python также отработали без проблем. Я был в восторге от возможности выполнять код в браузере с помощью Jupyter Notebook на Azure DSVM (без дополнительной настройки). Уверен, что новички в области глубокого обучения также по достоинству ее оценят.

Рис. 3. Предварительно настроенный экземпляр Microsoft Azure DSVM и код из книги Deep Learning for Computer Vision with Python позволили с легкостью занять вторую строчку в списке лидеров Kaggle по решению задачи «Dogs vs. Cats» (распознавание объекта на фотографии — кошка или собака)
Моя вторая статья в блоге Microsoft была рассчитана на практикующих специалистов. Для быстрого обучения высокоточной модели специалисты часто используют подход, который называется перенос обучения (точнее, его разновидность, извлечение признаков).
Чтобы показать, как DSVM способна помочь практикующим специалистам, которым нужно быстро обучить модель и оценить различные гиперпараметры, я сделал следующее:
Я поставил перед собой задачу — сделать все это меньше чем за 25 минут. Конечная модель смогла занять второе место, потребовав всего 22 минуты на вычисления (см. рисунок 3). Полное описание хода решения, блокнот Jupyter и код доступны в этой публикации.
Но можно ли решить эту задачу еще быстрее? После завершения эксперимента Kaggle «Dogs vs. Cats» на NVIDIA K80 представитель Microsoft разрешил мне воспользоваться только что выпущенными NVIDIA V100 GPU. Раньше я никогда не имел дела с NVIDIA V100, и мне было очень интересно, что из этого выйдет. Результаты оказались просто потрясающими.
На NVIDIA K80 весь процесс занял 22 минуты, а NVIDIA V100 справилась с задачей за 5 минут, то есть более чем в 4,4 раза быстрее. Уверен, что перенос рабочих решений с K80 на V100 позволит существенно улучшить результативность. Но здесь есть и другой фактор — финансовая целесообразность (он рассматривается ниже).

Рис. 4. Microsoft Azure DSVM с легкостью обучает SqueezeNet на наборе данных ImageNet
DSVM отлично подходит как для начинающих, так и для опытных специалистов в сфере глубокого обучения. Но что насчет исследователей, которые ведут работу на передовом рубеже отрасли? Поможет ли DSVM в решении их задач? Чтобы найти ответ на этот вопрос, я сделал следующее:
Я выбрал SqueezeNet по нескольким причинам:
Мое обучение SqueezeNet на NVIDIA K80 заняло 80 эпох. Для обучения сети использовался SGD с начальной скоростью обучения 1e-2 (в одной из публикаций Ландолы (landola) и соавторов есть замечание о том, что 4e-2 — слишком большой показатель для стабильного обучения). Скорость обучения уменьшалась на порядок на эпохах 50, 65 и 75 соответственно. Каждая эпоха заняла около 140 минут на K80, поэтому общее время обучения составило примерно неделю.
Использование нескольких GPU позволило бы с легкостью сократить время обучения до 1–3 дней, в зависимости от количества процессоров.
После того как обучение было завершено, я провел проверку на наборе из 50 000 изображений (они были взяты из учебного набора, поэтому мне не пришлось отправлять результаты на проверочный сервер ImageNet). Итоговые показатели точности: 58,86 % для ранга 1 и 79,38 % для ранга 5. Они соответствуют результатам, о которых сообщали Ландола и соавторы.
Полная статья о связке SqueezeNet + ImageNet доступна в блоге Microsoft.
После обучения SqueezeNet на ImageNet с использованием NVIDIA K80 я повторил эксперимент с одним GPU V100. Прирост скорости обучения оказался просто потрясающим. При использовании K80 одна эпоха занимала примерно 140 минут. Эпоха на V100 выполнялась за 28 минут, т. е. более чем в пять раз быстрее.
Мне удалось обучить SqueezeNet и воспроизвести результаты предыдущего эксперимента всего за 36 с небольшим часов. DSVM представляется весьма привлекательным инструментом для исследователей, особенно если вам не хочется приобретать и поддерживать аппаратные средства.

Рис. 5. Сравнение цен на вычислительную мощность GPU у различных поставщиков услуг глубокого обучения и ресурсов GPU
Экземпляр p2.xlarge в Amazon EC2 обойдется вам в 0,90 (1x K80), 7,20 (8x K80) или 14,40 (16x K80) долл. США/час. Таким образом, стоимость использования одного экземпляра K80 составляет 0,90 долл. США/час. В Microsoft Azure цены точно такие же: 0,90 (1x K80), 1,80 (2x K80) и 3,60 (4x K80) долл. США/час. Итоговая стоимость использования одного устройства K80 также составляет 0,90 долл. США/час.
Amazon предлагает готовые к использованию машины с V100. Их стоимость составляет 3,06 (1x V100), 12,24 (4x V100) и 24,48 (8x V100) долл. США/час. Таким образом, если вы хотите получить V100 в Amazon EC2, готовьтесь платить 3,06 долл. США/час.
Стоимость экземпляров с V100, которые недавно появились в Azure, вполне конкурентоспособна: 3,06 (1x V100), 6,12 (2x V100) и 12,24 (4x V100) долл. США/час.Итоговая стоимость одного V100 также составляет 3,06 долл. США/час.
Microsoft выпустила пакет Azure Batch AI, который напоминает спотовые инстансы Amazon и позволяет воспользоваться более выгодными ценами на экземпляры.
Для полного и справедливого сравнения цен необходимо также рассмотреть предложения Google, Paperspace и Floydhub.
Тарифы Google составляют 0,45 (1x K80), 0,90 (2x K80), 1,80 (4x K80) и 3,60 (8x K80) долл. США за час использования предлагаемых экземпляров. Это вдвое дешевле предложений K80 от MS/EC2 и определенно лучшая цена. У меня нет информации о предложениях машин с V100 от Google. Однако они реализуют собственную разработку, TPU, стоимость использования которой составляет 6,50 долл. США/час в расчете на один TPU.
Тариф Paperspace — 2,30 долл. США/час (1x V100). Стоит отметить, что они также предлагают конечные точки для API.
Тариф Floydhub — 4,20 долл. США/час (1x V100), но они предлагают отличные решения для совместной работы.
В плане надежности хорошо себя зарекомендовали предложения EC2 и Azure. А если учесть, насколько удобна работа в Azure по сравнению с EC2, то однозначно утверждать, что Amazon лучше подходит для долгосрочного использования, уже не получится.
Если вы хотите оценить возможности Azure в деле, Microsoft предлагает бесплатные ресурсы для пробного использования. Однако для запуска машин с GPU этот бонус использовать нельзя (к сожалению, экземпляры с GPU относятся к категории «премиум»).
Запустить экземпляр DSVM очень просто. В этом разделе я расскажу, как это сделать.
Если вам нужны расширенные настройки, обратитесь к документации — я в основном буду пользоваться параметрами по умолчанию. Чтобы бесплатно испытать возможности облака Azure, вы можете зарегистрировать бесплатную пробную учетную запись Microsoft Azure.
Примечание. В рамках пробной подписки Microsoft создавать экземпляры с GPU нельзя. К сожалению, экземпляры с GPU относятся к категории «премиум».
Шаг 1. Создайте учетную запись пользователя на странице portal.azure.com или войдите в систему.
Шаг 2. Нажмите кнопку «Создать ресурс» в левом верхнем углу.

Рис. 6. Экран создания ресурса в Microsoft Azure
Шаг 3. В поле поиска введите «Data Science Virtual Machine for Linux». В списке появится нужный вам вариант. Выберите первую строку со словом «Ubuntu».
Шаг 4. Настройте основные параметры. Укажите имя (без пробелов и спецсимволов). Выберите вариант HDD (не SSD). Вместо настройки файла ключей я ввел простой пароль, но здесь выбор за вами. Изучите раздел «Подписка»: возможно, у вас на счете есть бесплатно предоставленные средства. Также вам потребуется создать группу ресурсов. Я выбрал уже имеющуюся, rg1.

Рис. 7. Основные параметры ресурса Microsoft Azure
Шаг 5. Выберите регион и виртуальную машину. Я выбрал доступный экземпляр с K80 (NC65_V3). Экземпляр с V100 находится ниже по списку (NC6S_V3). Должен отметить, что эта система именования мне непонятна. Это одно из негативных впечатлений от использования платформы. Я надеялся, что система именования здесь будет примерно такая же, как у спортивных автомобилей; в крайнем случае машину с двумя GPU K80 можно было назвать «K80-2». Но названия здесь определяются количеством виртуальных ЦП, тогда как нас интересуют GPU.

Рис. 8. Виртуальная машина Microsoft Azure DSVM будет работать на основе K80 GPU и V100 GPU
Шаг 6. Изучите страницу «Сводка» и подтвердите согласие с условиями договора.

Рис. 9. На странице «Сводка» можно ознакомиться с условиями договора и подтвердить свое согласие с ними
Шаг 7. Дождитесь завершения развертывания системы. Когда процесс закончится, вы получите уведомление.
Шаг 8. Выберите пункт «Все ресурсы». В этом списке перечислено все, за что вы платите.

Рис. 10. На странице «Все ресурсы» портала Azure отображается моя машина DSVM и связанные с ней службы
Если выбрать виртуальную машину, в окне появится информация о ней (откройте снимок экрана, приведенный ниже, в новой вкладке, чтобы изучить его в более высоком разрешении — там отображается IP-адрес и т. п.).

Рис. 11. На странице «Обзор ресурсов» можно просмотреть ваши экземпляры
Шаг 9. Подключитесь к машине посредством SSH и (или) Jupyter.
Если нажать кнопку «Подключиться», на экране появится информация для настройки SSH-соединения (с использованием файла ключей или пароля). К сожалению, удобной ссылки на Jupyter здесь нет. Чтобы подключиться к Jupyter, выполните следующие действия.
Теперь запустим пример с LeNet + MNIST, который рассматривается в моей первой публикации в блоге Microsoft, в среде Jupyter. Этот процесс состоит из двух шагов.
Шаг 1. Подключитесь к вашей машине посредством SSH (см. шаг 9 в предыдущем разделе).
Перейдите в каталог ~/notebooks.
Клонируйте репозиторий командой $ git clone github.com/jrosebr1/microsoft-dsvm.git
Шаг 2. Откройте страницу Jupyter в браузере (см. этап 9 в предыдущем разделе).
Щелкните каталог microsoft-dsvm.
Откройте нужный файл .ipynb (pyimagesearch-training-your-first-cnn.ipynb).
Пока не запускайте блокнот — вначале я расскажу вам об одном удобном приеме. Применять его не обязательно, но если вы будете работать в DSVM с несколькими блокнотами, он немного облегчит вам жизнь. Дело в том, что если вы запустите блокнот и оставите его в состоянии «выполня��тся», то ядро блокнота будет блокировать GPU. Если вы попробуете запустить другой блокнот, появятся ошибки, такие как «resource exhausted».
Чтобы избежать этого, добавьте в отдельную ячейку в самом конце блокнота следующие две строчки:
Теперь после того, как все ячейки будут обработаны, блокнот аккуратно отключит свое ядро, и вам не придется заботиться о его остановке вручную.
Теперь можно щелкнуть внутри первой ячейки и выбрать пункт меню «Cell > Run all». Так вы запустите выполнение всех ячеек блокнота и инициируете обучение LeNet на базе MNIST. Теперь вы можете следить за ходом выполнения в браузере и в итоге получить примерно такой результат, как у меня:
Рис. 12. Обучение LeNet на базе MNIST в виртуальной машине для обработки и анализа данных (DSVM) в облаке Microsoft Azure
Обычно я удаляю все содержимое вывода после завершения работы или перед тем, как заново запустить измененный блокнот. Чтобы сделать это, выберите пункт меню «Kernel > Restart & Clear Output».
В этой публикации я рассказал о личном опыте работы с виртуальной машиной Microsoft для глубокого обучения, обработки и анализа данных (DSVM). Также я показал, как запустить первый экземпляр DSVM и выполнить на нем первый образец кода для глубокого обучения. Изначально у меня были сомнения насчет DSVM, но я рад, что попробовал воспользоваться этой машиной.
DSVM с легкостью справилась со всеми испытаниями, от учебных задач для новичков до самых передовых экспериментов. После перехода от экземпляров с NVIDIA K80 на новые NVIDIA V100 GPU от Microsoft скорость выполнения экспериментов увеличилась в пять раз.
Если вы ищете облачный экземпляр с GPU для глубокого обучения, советую обратить внимание на DSVM от Microsoft — мои впечатления были самыми положительными, поддержка Microsoft работала прекрасно, а сама машина DSVM оказалась мощной и при этом удобной в использовании.
Передаю слово автору.
Вначале мне не очень хотелось проверять ее в деле — у меня уже был настроенный экземпляр AMI для глубокого обучения в Amazon AWS. Я часто им пользуюсь, и он доступен всем читателям PyImageSearch для применения в собственных проектах.
Я не поклонник пользовательского интерфейса Amazon AWS, но за несколько лет к нему приспособился. Полагаю, в его неуклюжей сложности есть что-то знакомое. Однако мне попадались настолько хорошие отзывы о Ubuntu DSVM, что я все-таки решил ее опробовать. И она превзошла все мои ожидания. Более удобный интерфейс. Отличная производительность. Разумная цена.
…И кроме того, весь код из книги Deep Learning for Computer Vision with Python заработал на ней без единого изменения. Microsoft любезно разрешила мне опубликовать ряд гостевых статей в блоге компании о машинном обучении, в которых я оценил виртуальную машину и поделился впечатлениями от ее использования и тестирования:
- Глубокое обучение и компьютерное зрение в облаке Microsoft Azure;
- Алгоритмы глубокого обучения и технологии Azure позволили занять второе место в одном из соревнований Kaggle всего за 22 минуты;
- Обучение продвинутых нейронных сетей в облаке Microsoft Azure.
Microsoft активно работает над тем, чтобы предлагаемая ими среда рассматривалась как приоритетная при выборе облачной платформы для глубокого обучения, машинного обучения, обработки и анализа данных. Качество их продукта DSVM служит наглядной иллюстрацией этого стремления.
В этой статье я хотел бы поделиться мыслями о DSVM, показать, как запустить первый экземпляр машины и начать выполнять на нем код для глубокого обучения. Если вас интересует виртуальная машина для глубокого обучения от Microsoft (и вы хотите понять, подходит ли она для решения ваших задач), эта статья для вас.
Виртуальная машина Microsoft для глубокого обучения: обзор
При первом знакомстве с виртуальной машиной Microsoft для глубокого обучения, обработки и анализа данных (DSVM) я взял все образцы кода из книги Deep Learning for Computer Vision with Python и запустил каждый из них в DSVM. Ручной запуск каждого образца и проверка результатов — монотонная работа, но она помогла изучить особенности DSVM и оценить ее по следующим параметрам:
- Возможность использования новичками (т. е. людьми, которые только начинают знакомство с глубоким обучением);
- Возможность решения практических задач, в рамках которых важно подготовить модель глубокого обучения и быстро оценить эффективность;
- Возможность решения исследовательских задач, т. е. обучения глубоких нейронных сетей на больших наборах графических данных.
Программный код, сопровождающий книгу Deep Learning for Computer Vision with Python, отлично подходит для такого рода испытаний.
Код из пакета Starter Bundle предназначен для первого знакомства с классификацией изображений, глубоким обучением и сверточными нейронными сетями (СНС). Если этот код будет без проблем выполнен в DSVM, значит, машину можно рекомендовать новичкам, которым нужна готовая среда для освоения глубокого обучения.
Учебные материалы и прилагаемый код из пакета Practitioner Bundle посвящены гораздо более продвинутым технологиям (переносу обучения, тонкой настройке генеративно-состязательных сетей и т. п.). Именно такие технологии применяют в своей повседневной работе практикующие специалисты и инженеры.
Если DSVM справится и с этими примерами, значит, ее можно рекомендовать практикующим специалистам в сфере глубокого обучения. И наконец, для работы кода из пакета ImageNet Bundle нужны производительные GPU (чем мощнее, тем лучше) и высокая пропускная способность операций ввода-вывода. В рамках этого пакета я показываю, как воспроизвести результаты из самых передовых публикаций (например, в ResNet, SqueezeNet и т. п.), полученные на огромных наборах графических данных (пример — набор ImageNet, состоящий из 1,2 млн изображений).
Если DSVM способна воспроизвести результаты из самых продвинутых статей, значит, ее можно рекомендовать исследователям. В первой половине статьи я представлю результаты каждого из описанных тестов и мои личные впечатления. Затем я покажу, как запустить в облаке Microsoft ваш первый экземпляр системы глубокого обучения и выполнить в DSVM первый фрагмент соответствующего кода.
Всеобъемлющий набор библиотек глубокого обучения
Рис. 1. На иллюстрации показаны пакеты, которые установлены на виртуальной машине Microsoft Azure для обработки и анализа данных. Они уже настроены и готовы к использованию
Виртуальная машина Microsoft для глубокого обучения работает в облаке Azure, которое также принадлежит корпорации. Технически на ней можно запустить как Windows, так и Linux, но для проектов глубокого обучения я бы рекомендовал использовать созданный компанией экземпляр Ubuntu DSVM (если только у вас нет причин использовать именно Windows).
Список пакетов, предварительно установленных на DSVM, довольно обширен — полный перечень доступен здесь. Ниже я перечислил наиболее важные пакеты для решения задач глубокого обучения и компьютерного зрения (в частности, те из них, которые могут заинтересовать читателей PyImageSearch), чтобы вы представляли, насколько их много.
- TensorFlow
- Keras
- mxnet
- Caffe/Caffe2
- Torch/PyTorch
- OpenCV
- Jupyter
- CUDA и cuDNN
- Python 3
Создатели DSVM выпускают новые версии машины с самыми актуальными предустановленными и настроенными версиями пакетов каждые несколько месяцев. Это огромный труд, демонстрирующий как невероятные усилия команды DSVM в плане обеспечения стабильной работы экземпляра (устранение потенциальных конфликтов между пакетами DSVM должно быть непростой задачей, но при этом машина совершенно прозрачна для пользователя), так и стремление Microsoft выпускать продукт, взаимодействовать с которым было бы удобно и приятно пользователям.
Что насчет GPU?
Для запуска DSVM можно использовать как экземпляры, оснащенные только ЦП, так и экземпляры с GPU.
Большая часть описанных ниже экспериментов и тестов выполнялась на экземпляре Ubuntu GPU, который оснащен стандартным NVIDIA K80 GPU. Кроме того, Microsoft предоставила мне доступ к недавно выпущенному монстру NVIDIA V100, и несколько быстрых тестов я провел на нем (Результаты приводятся ниже). Для проведения всех экспериментов в рамках пакетов Starter Bundle и Practitioner Bundle я использовал Microsoft Jupyter Notebook. Процесс оказался невероятно простым.
Я скопировал и вставил URL-адрес сервера Jupyter Notebook в адресную строку браузера, запустил новый блокнот и уже через несколько минут выполнял фрагменты кода из книги.
Для экспериментов с ImageNet Bundle я использовал SSH, поскольку воспроизведение результатов из самых передовых публикаций требует потратить несколько дней на обучение. К тому же мне кажется, что это не лучший вариант использования блокнотов Jupyter.
Удобство для новичков в области глубокого обучения
Рис. 2. Обучение архитектуры LeNet на наборе данных MNIST. Эту комбинацию часто называют «Hello World глубокого обучения»
В рамках моей первой гостевой публикации в блоге Microsoft я обучил простую сверточную нейронную сеть (LeNet) на наборе рукописных цифр MNIST. Обучение LeNet на наборе MNIST, вероятнее всего, станет первым «реальным» экспериментом для новичка, осваивающего технологии глубокого обучения.
И модель, и набор данных организованы очень понятно. Для обучения можно использовать ЦП или GPU. Я взял образец кода из 14-й главы книги Deep Learning for Computer Vision with Python (пакет Starter Bundle) и запустил его в блокноте Jupyter Notebook (он доступен здесь) на Microsoft DSVM. Результаты показаны на рисунке 2 выше.
После 20 эпох обучения точность классификации составила 98%. Все остальные образцы кода из пакета Starter Bundle книги Deep Learning for Computer Vision with Python также отработали без проблем. Я был в восторге от возможности выполнять код в браузере с помощью Jupyter Notebook на Azure DSVM (без дополнительной настройки). Уверен, что новички в области глубокого обучения также по достоинству ее оценят.
Удобство для практикующих специалистов в области глубокого обучения
Рис. 3. Предварительно настроенный экземпляр Microsoft Azure DSVM и код из книги Deep Learning for Computer Vision with Python позволили с легкостью занять вторую строчку в списке лидеров Kaggle по решению задачи «Dogs vs. Cats» (распознавание объекта на фотографии — кошка или собака)
Моя вторая статья в блоге Microsoft была рассчитана на практикующих специалистов. Для быстрого обучения высокоточной модели специалисты часто используют подход, который называется перенос обучения (точнее, его разновидность, извлечение признаков).
Чтобы показать, как DSVM способна помочь практикующим специалистам, которым нужно быстро обучить модель и оценить различные гиперпараметры, я сделал следующее:
- Применил извлечение признаков с использованием модели ResNet, предварительно обученной на наборе данных из задания Kaggle «Dogs vs. Cats».
; - Применил классификатор на основе логистической регрессии с поиском гиперпараметров для извлеченных признаков по сетке;
- Получил модель, которая смогла занять второе место в соревновании.
Я поставил перед собой задачу — сделать все это меньше чем за 25 минут. Конечная модель смогла занять второе место, потребовав всего 22 минуты на вычисления (см. рисунок 3). Полное описание хода решения, блокнот Jupyter и код доступны в этой публикации.
Но можно ли решить эту задачу еще быстрее? После завершения эксперимента Kaggle «Dogs vs. Cats» на NVIDIA K80 представитель Microsoft разрешил мне воспользоваться только что выпущенными NVIDIA V100 GPU. Раньше я никогда не имел дела с NVIDIA V100, и мне было очень интересно, что из этого выйдет. Результаты оказались просто потрясающими.
На NVIDIA K80 весь процесс занял 22 минуты, а NVIDIA V100 справилась с задачей за 5 минут, то есть более чем в 4,4 раза быстрее. Уверен, что перенос рабочих решений с K80 на V100 позволит существенно улучшить результативность. Но здесь есть и другой фактор — финансовая целесообразность (он рассматривается ниже).
Достаточная мощность для передовых разработок в сфере глубокого обучения
Рис. 4. Microsoft Azure DSVM с легкостью обучает SqueezeNet на наборе данных ImageNet
DSVM отлично подходит как для начинающих, так и для опытных специалистов в сфере глубокого обучения. Но что насчет исследователей, которые ведут работу на передовом рубеже отрасли? Поможет ли DSVM в решении их задач? Чтобы найти ответ на этот вопрос, я сделал следующее:
- Скачал весь набор данных ImageNet на виртуальную машину;
- Взял код из 9-й главы книги Deep Learning for Computer Vision with Python (пакет ImageNet Bundle), в которой показываю, как обучить SqueezeNet на основе ImageNet.
Я выбрал SqueezeNet по нескольким причинам:
- На моем локальном компьютере уже выполнялось обучение SqueezeNet на базе ImageNet для отдельного проекта, поэтому я мог с легкостью сравнить результаты;
- SqueezeNet — одна из моих любимых архитектур;
- Благодаря малому размеру (менее 5 МБ без квантования) конечная модель хорошо подходит для использования в рабочих средах, где для развертывания часто используются сети или устройства с ограниченными возможностями.
Мое обучение SqueezeNet на NVIDIA K80 заняло 80 эпох. Для обучения сети использовался SGD с начальной скоростью обучения 1e-2 (в одной из публикаций Ландолы (landola) и соавторов есть замечание о том, что 4e-2 — слишком большой показатель для стабильного обучения). Скорость обучения уменьшалась на порядок на эпохах 50, 65 и 75 соответственно. Каждая эпоха заняла около 140 минут на K80, поэтому общее время обучения составило примерно неделю.
Использование нескольких GPU позволило бы с легкостью сократить время обучения до 1–3 дней, в зависимости от количества процессоров.
После того как обучение было завершено, я провел проверку на наборе из 50 000 изображений (они были взяты из учебного набора, поэтому мне не пришлось отправлять результаты на проверочный сервер ImageNet). Итоговые показатели точности: 58,86 % для ранга 1 и 79,38 % для ранга 5. Они соответствуют результатам, о которых сообщали Ландола и соавторы.
Полная статья о связке SqueezeNet + ImageNet доступна в блоге Microsoft.
Высочайшая скорость обучения при использовании NVIDIA V100
После обучения SqueezeNet на ImageNet с использованием NVIDIA K80 я повторил эксперимент с одним GPU V100. Прирост скорости обучения оказался просто потрясающим. При использовании K80 одна эпоха занимала примерно 140 минут. Эпоха на V100 выполнялась за 28 минут, т. е. более чем в пять раз быстрее.
Мне удалось обучить SqueezeNet и воспроизвести результаты предыдущего эксперимента всего за 36 с небольшим часов. DSVM представляется весьма привлекательным инструментом для исследователей, особенно если вам не хочется приобретать и поддерживать аппаратные средства.
Но что насчет цены?
Рис. 5. Сравнение цен на вычислительную мощность GPU у различных поставщиков услуг глубокого обучения и ресурсов GPU
Экземпляр p2.xlarge в Amazon EC2 обойдется вам в 0,90 (1x K80), 7,20 (8x K80) или 14,40 (16x K80) долл. США/час. Таким образом, стоимость использования одного экземпляра K80 составляет 0,90 долл. США/час. В Microsoft Azure цены точно такие же: 0,90 (1x K80), 1,80 (2x K80) и 3,60 (4x K80) долл. США/час. Итоговая стоимость использования одного устройства K80 также составляет 0,90 долл. США/час.
Amazon предлагает готовые к использованию машины с V100. Их стоимость составляет 3,06 (1x V100), 12,24 (4x V100) и 24,48 (8x V100) долл. США/час. Таким образом, если вы хотите получить V100 в Amazon EC2, готовьтесь платить 3,06 долл. США/час.
Стоимость экземпляров с V100, которые недавно появились в Azure, вполне конкурентоспособна: 3,06 (1x V100), 6,12 (2x V100) и 12,24 (4x V100) долл. США/час.Итоговая стоимость одного V100 также составляет 3,06 долл. США/час.
Microsoft выпустила пакет Azure Batch AI, который напоминает спотовые инстансы Amazon и позволяет воспользоваться более выгодными ценами на экземпляры.
Для полного и справедливого сравнения цен необходимо также рассмотреть предложения Google, Paperspace и Floydhub.
Тарифы Google составляют 0,45 (1x K80), 0,90 (2x K80), 1,80 (4x K80) и 3,60 (8x K80) долл. США за час использования предлагаемых экземпляров. Это вдвое дешевле предложений K80 от MS/EC2 и определенно лучшая цена. У меня нет информации о предложениях машин с V100 от Google. Однако они реализуют собственную разработку, TPU, стоимость использования которой составляет 6,50 долл. США/час в расчете на один TPU.
Тариф Paperspace — 2,30 долл. США/час (1x V100). Стоит отметить, что они также предлагают конечные точки для API.
Тариф Floydhub — 4,20 долл. США/час (1x V100), но они предлагают отличные решения для совместной работы.
В плане надежности хорошо себя зарекомендовали предложения EC2 и Azure. А если учесть, насколько удобна работа в Azure по сравнению с EC2, то однозначно утверждать, что Amazon лучше подходит для долгосрочного использования, уже не получится.
Если вы хотите оценить возможности Azure в деле, Microsoft предлагает бесплатные ресурсы для пробного использования. Однако для запуска машин с GPU этот бонус использовать нельзя (к сожалению, экземпляры с GPU относятся к категории «премиум»).
Запуск первого экземпляра для глубокого обучения в облаке Microsoft
Запустить экземпляр DSVM очень просто. В этом разделе я расскажу, как это сделать.
Если вам нужны расширенные настройки, обратитесь к документации — я в основном буду пользоваться параметрами по умолчанию. Чтобы бесплатно испытать возможности облака Azure, вы можете зарегистрировать бесплатную пробную учетную запись Microsoft Azure.
Примечание. В рамках пробной подписки Microsoft создавать экземпляры с GPU нельзя. К сожалению, экземпляры с GPU относятся к категории «премиум».
Шаг 1. Создайте учетную запись пользователя на странице portal.azure.com или войдите в систему.
Шаг 2. Нажмите кнопку «Создать ресурс» в левом верхнем углу.
Рис. 6. Экран создания ресурса в Microsoft Azure
Шаг 3. В поле поиска введите «Data Science Virtual Machine for Linux». В списке появится нужный вам вариант. Выберите первую строку со словом «Ubuntu».
Шаг 4. Настройте основные параметры. Укажите имя (без пробелов и спецсимволов). Выберите вариант HDD (не SSD). Вместо настройки файла ключей я ввел простой пароль, но здесь выбор за вами. Изучите раздел «Подписка»: возможно, у вас на счете есть бесплатно предоставленные средства. Также вам потребуется создать группу ресурсов. Я выбрал уже имеющуюся, rg1.
Рис. 7. Основные параметры ресурса Microsoft Azure
Шаг 5. Выберите регион и виртуальную машину. Я выбрал доступный экземпляр с K80 (NC65_V3). Экземпляр с V100 находится ниже по списку (NC6S_V3). Должен отметить, что эта система именования мне непонятна. Это одно из негативных впечатлений от использования платформы. Я надеялся, что система именования здесь будет примерно такая же, как у спортивных автомобилей; в крайнем случае машину с двумя GPU K80 можно было назвать «K80-2». Но названия здесь определяются количеством виртуальных ЦП, тогда как нас интересуют GPU.
Рис. 8. Виртуальная машина Microsoft Azure DSVM будет работать на основе K80 GPU и V100 GPU
Шаг 6. Изучите страницу «Сводка» и подтвердите согласие с условиями договора.
Рис. 9. На странице «Сводка» можно ознакомиться с условиями договора и подтвердить свое согласие с ними
Шаг 7. Дождитесь завершения развертывания системы. Когда процесс закончится, вы получите уведомление.
Шаг 8. Выберите пункт «Все ресурсы». В этом списке перечислено все, за что вы платите.
Рис. 10. На странице «Все ресурсы» портала Azure отображается моя машина DSVM и связанные с ней службы
Если выбрать виртуальную машину, в окне появится информация о ней (откройте снимок экрана, приведенный ниже, в новой вкладке, чтобы изучить его в более высоком разрешении — там отображается IP-адрес и т. п.).
Рис. 11. На странице «Обзор ресурсов» можно просмотреть ваши экземпляры
Шаг 9. Подключитесь к машине посредством SSH и (или) Jupyter.
Если нажать кнопку «Подключиться», на экране появится информация для настройки SSH-соединения (с использованием файла ключей или пароля). К сожалению, удобной ссылки на Jupyter здесь нет. Чтобы подключиться к Jupyter, выполните следующие действия.
- Откройте в браузере новую вкладку;
- Перейдите по адресу «https ://общедоступный_IP_вашего_экземпляра_Azure_Dsvm:8000» (именно https, не http). Замените соответствующую часть URL-адреса на общедоступный IP вашего экземпляра.
Выполнение кода на виртуальной машине для глубокого обучения
Теперь запустим пример с LeNet + MNIST, который рассматривается в моей первой публикации в блоге Microsoft, в среде Jupyter. Этот процесс состоит из двух шагов.
Шаг 1. Подключитесь к вашей машине посредством SSH (см. шаг 9 в предыдущем разделе).
Перейдите в каталог ~/notebooks.
Клонируйте репозиторий командой $ git clone github.com/jrosebr1/microsoft-dsvm.git
Шаг 2. Откройте страницу Jupyter в браузере (см. этап 9 в предыдущем разделе).
Щелкните каталог microsoft-dsvm.
Откройте нужный файл .ipynb (pyimagesearch-training-your-first-cnn.ipynb).
Пока не запускайте блокнот — вначале я расскажу вам об одном удобном приеме. Применять его не обязательно, но если вы будете работать в DSVM с несколькими блокнотами, он немного облегчит вам жизнь. Дело в том, что если вы запустите блокнот и оставите его в состоянии «выполня��тся», то ядро блокнота будет блокировать GPU. Если вы попробуете запустить другой блокнот, появятся ошибки, такие как «resource exhausted».
Чтобы избежать этого, добавьте в отдельную ячейку в самом конце блокнота следующие две строчки:
%%javascript Jupyter.notebook.session.delete();
Теперь после того, как все ячейки будут обработаны, блокнот аккуратно отключит свое ядро, и вам не придется заботиться о его остановке вручную.
Теперь можно щелкнуть внутри первой ячейки и выбрать пункт меню «Cell > Run all». Так вы запустите выполнение всех ячеек блокнота и инициируете обучение LeNet на базе MNIST. Теперь вы можете следить за ходом выполнения в браузере и в итоге получить примерно такой результат, как у меня:
Рис. 12. Обучение LeNet на базе MNIST в виртуальной машине для обработки и анализа данных (DSVM) в облаке Microsoft Azure
Обычно я удаляю все содержимое вывода после завершения работы или перед тем, как заново запустить измененный блокнот. Чтобы сделать это, выберите пункт меню «Kernel > Restart & Clear Output».
Заключение
В этой публикации я рассказал о личном опыте работы с виртуальной машиной Microsoft для глубокого обучения, обработки и анализа данных (DSVM). Также я показал, как запустить первый экземпляр DSVM и выполнить на нем первый образец кода для глубокого обучения. Изначально у меня были сомнения насчет DSVM, но я рад, что попробовал воспользоваться этой машиной.
DSVM с легкостью справилась со всеми испытаниями, от учебных задач для новичков до самых передовых экспериментов. После перехода от экземпляров с NVIDIA K80 на новые NVIDIA V100 GPU от Microsoft скорость выполнения экспериментов увеличилась в пять раз.
Если вы ищете облачный экземпляр с GPU для глубокого обучения, советую обратить внимание на DSVM от Microsoft — мои впечатления были самыми положительными, поддержка Microsoft работала прекрасно, а сама машина DSVM оказалась мощной и при этом удобной в использовании.

