Когда, за бутылкой пива, я заводил разговор о нейронных сетях — люди обычно начинали боязливо на меня смотреть, грустнели, иногда у них начинал дёргаться глаз, а в крайних случаях они залезали под стол. Но, на самом деле, эти сети просты и интуитивны. Да-да, именно так! И, позвольте, я вам это докажу!
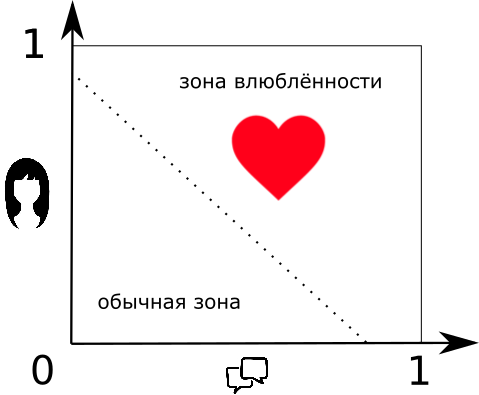
Допустим, я знаю о девушке две вещи — симпатична она мне или нет, а также, есть ли о чём мне с ней поговорить. Если есть, то будем считать это единицей, если нет, то — нулём. Аналогичный принцип возьмем и для внешности. Вопрос: “В какую девушку я влюблюсь и почему?”
Можно подумать просто и бескомпромиссно: “Если симпатична и есть о чём поговорить, то влюблюсь. Если ни то и ни другое, то — увольте.”
Но что если дама мне симпатична, но с ней не о чем разговаривать? Или наоборот?
Понятно, что для каждого из нас что-то одно будет важнее. Точнее, у каждого параметра есть его уровень важности, или вернее сказать — вес. Если помножить параметр на его вес, то получится соответственно “влияние внешности” и “влияние болтливости разговора”.
И вот теперь я с чистой совестью могу ответить на свой вопрос:
“Если влияние харизмы и влияние болтливости в сумме больше значения “влюбчивость” то влюблюсь…”
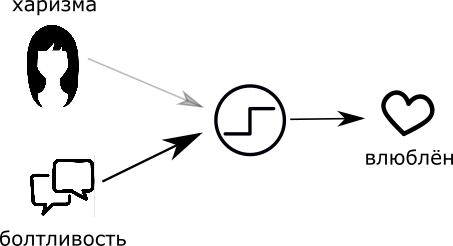
То есть, если я поставлю большой вес “болтологичности” дамы и маленький вес внешности, то в спорной ситуации я влюблюсь в особу, с которой приятно поболтать. И наоборот.
Собственно, это правило и есть нейрон.
Искусственный нейрон — это такая функция, которая преобразует несколько входных фактов в один выходной. Настройкой весов этих фактов, а также порога возбуждения — мы настраиваем адекватность нейрона. В принципе, для многих наука жизни заканчивается на этом уровне, но ведь эта история не про нас, верно?
Сделаем ещё несколько выводов:
- Если оба веса будут малыми, то мне будет сложно влюбиться в кого бы-то ни было.
- Если же оба веса будут чересчур большими, то я влюблюсь хоть в столб.
- Заставить меня влюбиться в столб можно также, понизив порог влюбчивости, но прошу — не делайте со мной этого! Лучше давайте пока забудем про него, ок?
Смешно, но параметр “влюбчивости” называется “порогом возбуждения”. Но, дабы эта статья не получила рейтинг “18+”, давайте договоримся говорить просто “порог”, ок?
Нейронная сеть
Не бывает однозначно симпатичных и однозначно общительных дам. Да и влюблённость влюблённости рознь, кто бы что ни говорил. Потому давайте вместо брутальных и бескомпромиссных “0” и “1”, будем использовать проценты. Тогда можно сказать — “я сильно влюблён (80%), или “эта дама не особо разговорчива (20%)”.
Наш примитивный “нейрон-максималист” из первой части уже нам не подходит. Ему на смену приходит “нейрон-мудрец”, результатом работы которого будет число от 0 до 1, в зависимости от входных данных.
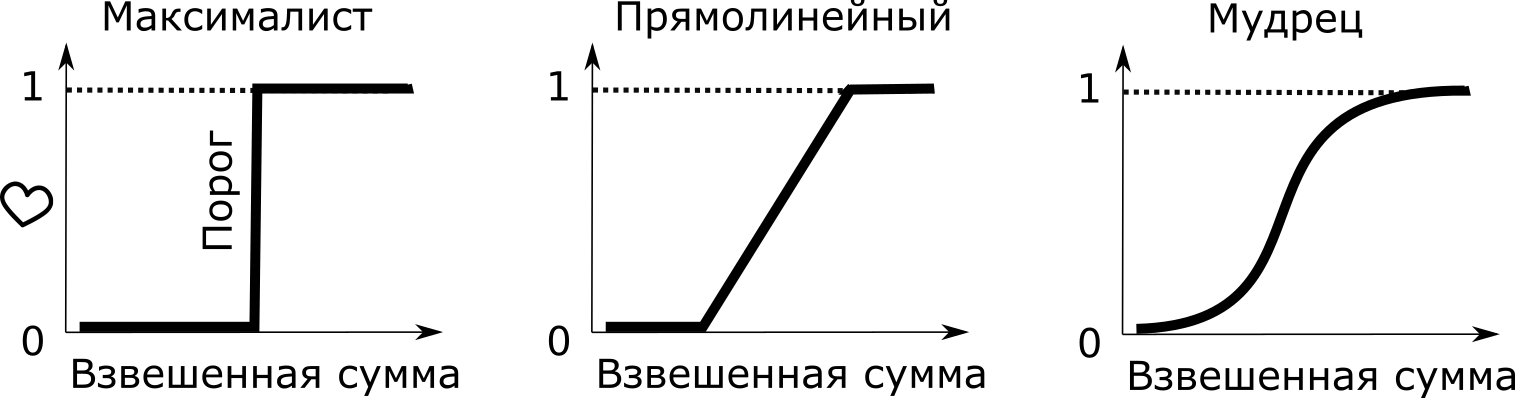
“Нейрон-мудрец” может нам сказать: “эта дама достаточно красива, но я не знаю о чём с ней говорить, поэтому я не очень-то ей и восхищён”
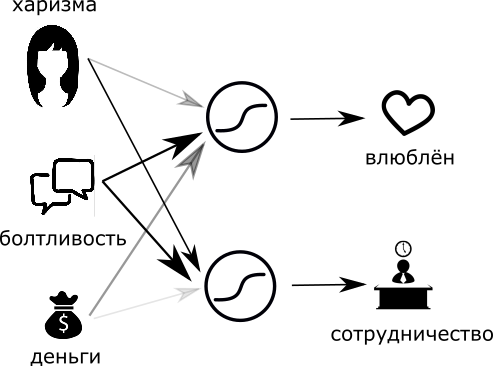
К слову говоря, входные факты нейрона называются синапсами, а выходное суждение — аксоном. Связи с положительным весом называются возбуждающими, а с отрицательным — тормозящими. Если же вес равен нулю, то считается, что связи нет (мёртвая связь).
Поехали дальше. Сделаем по этим двум фактам другую оценку: насколько хорошо с такой девушкой работать (сотрудничать)? Будем действовать абсолютно аналогичным образом — добавим мудрый нейрон и настроим веса комфортным для нас образом.
Но, судить девушку по двум характеристикам — это очень грубо. Давайте судить её по трём! Добавим ещё один факт – деньги. Который будет варьироваться от нуля (абсолютно бедная) до единицы (дочь Рокфеллера). Посмотрим, как с приходом денег изменятся наши суждения….
Для себя я решил, что, в плане очарования, деньги не очень важны, но шикарный вид всё же может на меня повлиять, потому вес денег я сделаю маленьким, но положительным.
В работе мне абсолютно всё равно, сколько денег у девушки, поэтому вес сделаю равным нулю.
Оценивать девушку только для работы и влюблённости — очень глупо. Давайте добавим, насколько с ней будет приятно путешествовать:
- Харизма в этой задаче нейтральна (нулевой или малый вес).
- Разговорчивость нам поможет (положительный вес).
- Когда в настоящих путешествиях заканчиваются деньги, начинается самый драйв, поэтому вес денег я сделаю слегка отрицательным.
Соединим все эти три схемы в одну и обнаружим, что мы перешли на более глубокий уровень суждений, а именно: от харизмы, денег и разговорчивости — к восхищению, сотрудничеству и комфортности совместного путешествия. И заметьте — это тоже сигналы от нуля до единицы. А значит, теперь я могу добавить финальный “нейрон-максималист”, и пускай он однозначно ответит на вопрос — “жениться или нет”?
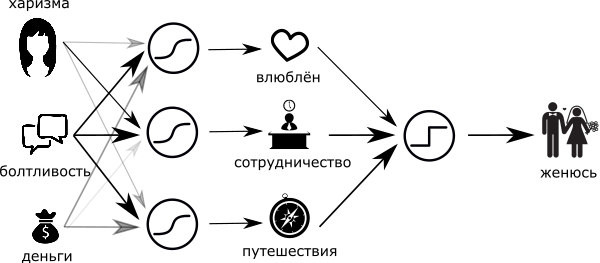
Ладно, конечно же, не всё так просто (в плане женщин). Привнесём немного драматизма и реальности в наш простой и радужный мир. Во-первых, сделаем нейрон "женюсь — не женюсь" — мудрым. Сомнения же присущи всем, так или иначе. И ещё — добавим нейрон "хочу от неё детей" и, чтобы совсем по правде, нейрон “держись от неё подальше".
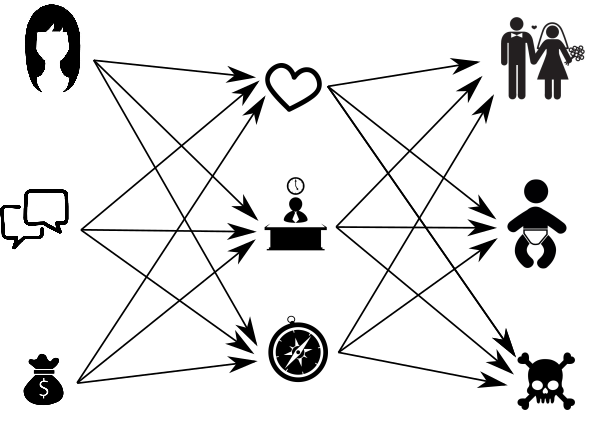
Я ничего не понимаю в женщинах, и поэтому моя примитивная сеть теперь выглядит как картинка в начале статьи.
Входные суждения называются “входной слой”, итоговые — “выходной слой”, а тот, что скрывается посередине, называется "скрытым". Скрытый слой — это мои суждения, полуфабрикаты, мысли, о которых никто не знает. Скрытых слоёв может быть несколько, а может быть и ни одного.
Долой максимализм.
Помните, я говорил об отрицательном влияние денег на моё желание путешествовать с человеком? Так вот — я слукавил. Для путешествий лучше всего подходит персона, у которой денег не мало, и не много. Мне так интереснее и не буду объяснять почему.
Но тут я сталкиваюсь с проблемой:
Если я ставлю вес денег отрицательным, то чем меньше денег — тем лучше для путешествий.
Если положительным, то чем богаче — тем лучше,
Если ноль — тогда деньги “побоку”.
Не получается мне вот так, одним весом, заставить нейрон распознать ситуацию “ни много -ни мало”!
Чтобы это обойти, я сделаю два нейрона — “денег много” и “денег мало”, и подам им на вход денежный поток от нашей дамы.
Теперь у меня есть два суждения: “много” и “мало”. Если оба вывода незначительны, то буквально получится “ни много — ни мало”. То есть, добавим на выход ещё один нейрон, с отрицательными весами:
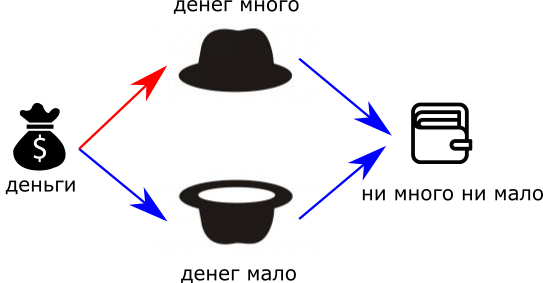
“Нимногонимало”. Красные стрелки — положительные связи, синие — отрицательные
Вообще, это значит, что нейроны подобны элементам конструктора. Подобно тому, как процессор делают из транзисторов, мы можем собрать из нейронов мозг. Например, суждение “Или богата, или умна” можно сделать так:
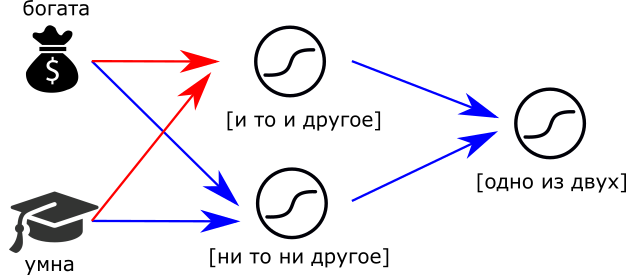
Или-или. Красные стрелки — положительные связи, синие – отрицательные
Или так:
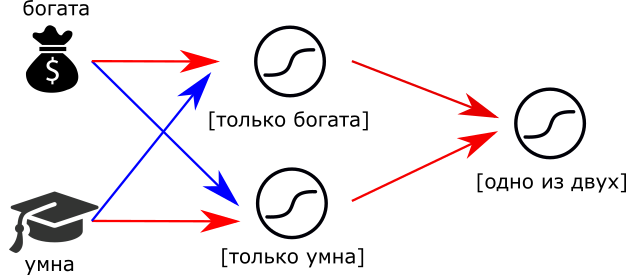
можно заменить “мудрые” нейроны на “максималистов” и тогда получим логический оператор XOR. Главное — не забыть настроить пороги возбуждения.
В отличие от транзисторов и бескомпромиссной логики типичного программиста “если — то”, нейронная сеть умеет принимать взвешенные решения. Их результаты будут плавно меняться, при плавном изменение входных параметров. Вот она мудрость!
Обращу ваше внимание, что добавление слоя из двух нейронов, позволило нейрону “ни много — ни мало” делать более сложное и взвешенное суждение, перейти на новый уровень логики. От “много” или “мало” — к компромиссному решению, к более глубокому, с философской точки зрения, суждению. А что если добавить скрытых слоёв ещё? Мы способны охватить разумом ту простую сеть, но как насчёт сети, у которой есть 7 слоёв? Способны ли мы осознать глубину её суждений? А если в каждом из них, включая входной, около тысячи нейронов? Как вы думаете, на что она способна?
Представьте, что я и дальше усложнял свой пример с женитьбой и влюблённостью, и пришёл к такой сети. Где-то там в ней скрыты все наши девять нейрончиков, и это уже больше похоже на правду. При всём желании, понять все зависимости и глубину суждений такой сети — попросту невозможно. Для меня переход от сети 3х3 к 7х1000 — сравним с осознанием масштабов, если не вселенной, то галактики — относительно моего роста. Попросту говоря, у меня это не получится. Решение такой сети, загоревшийся выход одного из её нейронов — будет необъясним логикой. Это то, что в быту мы можем назвать “интуицией” (по крайней мере – “одно из..”). Непонятное желание системы или её подсказка.
Но, в отличие от нашего синтетического примера 3х3, где каждый нейрон скрытого слоя достаточно чётко формализован, в настоящей сети это не обязательно так. В хорошо настроенной сети, чей размер не избыточен для решения поставленной задачи — каждый нейрон будет детектировать какой-то признак, но это абсолютно не значит, что в нашем языке найдётся слово или предложение, которое сможет его описать. Если проецировать на человека, то это — какая-то его характеристика, которую ты чувствуешь, но словами объяснить не можешь.
Обучение.
Несколькими строчками ранее я обмолвился о хорошо настроенной сети, чем вероятно спровоцировал немой вопрос: “А как мы можем настроить сеть, состоящую из нескольких тысяч нейронов? Сколько “человеколет” и погубленных жизней нужно на это?.. Боюсь предположить ответ на последний вопрос. Куда лучше автоматизировать такой процесс настройки — заставить сеть саму настраивать себя. Такой процесс автоматизации называется обучением. И чтобы дать поверхностное о нём представление, я вернусь к изначальной метафоре об “очень важном вопросе”:
Мы появляемся в этом мире с чистым, невинным мозгом и нейронной сетью, абсолютно не настроенной относительно дам. Её необходимо как-то грамотно настроить, дабы счастье и радость пришли в наш дом. Для этого нам нужен некоторый опыт, и тут есть несколько путей по его добыче:
1) Обучение с учителем (для романтиков). Насмотреться на голливудские мелодрамы и начитаться слезливых романов. Или же насмотреться на своих родителей и/или друзей. После этого, в зависимости от выборки, отправиться проверять полученные знания. После неудачной попытки — повторить всё заново, начиная с романов.
2) Обучение без учителя (для отчаянных экспериментаторов). Попробовать методом “тыка” жениться на десятке-другом женщин. После каждой женитьбы, в недоумение чесать репу. Повторять, пока не поймёшь, что надоело, и ты “уже знаешь, как это бывает”.
3) Обучение без учителя, вариант 2 (путь отчаянных оптимистов). Забить на всё, что-то делать по жизни, и однажды обнаружить себя женатым. После этого, перенастроить свою сеть в соответствие с текущей реальностью, дабы всё устраивало.
Далее, по логике я должен расписать всё это подробно, но без математики это будет слишком философично. Потому считаю, что мне стоит на этом остановиться. Быть может в другой раз?
Всё вышесказанное справедливо для искусственной нейронной сети типа “персептрон”. Остальные сети похожи на нее по основным принципам, но имеют свою нюансы.
Хороших вам весов и отличных обучающих выборок! Ну а если это уже и не нужно, то расскажите об этом кому-нибудь ещё.

