В статье мы расскажем о применении свёрточных нейронных сетей для решения практической бизнес-задачи восстановления реалограммы по фотографии полок с товарами. С помощью Tensorflow Object Detection API мы натренируем модель поиска/локализации. Улучшим качество поиска мелких товаров на фотографиях с большим разрешением с помощью плавающего окна и алгоритма подавления немаксимумов. На Keras реализуем классификатор товаров по брендам. Параллельно будем сравнивать подходы и результаты с решениями 4 летней давности. Все данные, использованные в статье, доступны для скачивания, а полностью рабочий код есть на GitHub и оформлен в виде tutorial.

Что такое планограмма? План-схема выкладки товара на конкретном торговом оборудовании магазина.
Что такое реалограмма? Схема выкладки товара на конкретном торговом оборудовании, существующая в магазине здесь и сейчас.
Планограмма — как надо, реалограмма — что имеем.

До сих пор во многих магазинах управление остатком товара на стойках, полках, прилавках, стеллажах является исключительно ручным трудом. Тысячи сотрудников проверяют наличие продуктов вручную, подсчитывают остаток, сверяют расположение с требованиями. Это дорого, а ошибки весьма вероятны. Неправильная выкладка или отсутствие товара приводит к снижению продаж.
Также многие производители заключают соглашения с розничными торговцами о выкладке их товаров. А поскольку производителей много, между ними начинается борьба за лучшее место на полке. Каждый хочет, чтобы его товар лежал в центре напротив глаз покупателя и занял как можно большую площадь. Возникает необходимость постоянного аудита.
Тысячи мерчандайзеров перемещаются от магазина к магазину, чтобы убедиться, что товар их компании есть на полке и представлен в соответствии с договором. Иногда они ленятся: гораздо приятнее составить отчёт, не выходя из дома, чем ехать в торговую точку. Появляется необходимость постоянного аудита аудиторов.
Естественно, задача автоматизации и упрощения этого процесса решается давно. Одной из самых сложных частей была обработка изображений: найти и распознать товары. И только сравнительно недавно эта задача упростилась настолько, что для частного случая в упрощённом виде её полное решение можно описать в одной статье. Это мы и сделаем.
Статья содержит минимум кода (только для случаев, когда код понятнее текста). Полное решение доступно в виде иллюстрированного tutorial'а в jupyter notebooks. Статья не содержит описания архитектур нейронных сетей, принципов работы нейронов, математических формул. В статье мы используем их как инженерный инструмент, не сильно вдаваясь в детали его устройства.
Как и для любого data driven подхода, для решений на основе нейронных сетей нужны данные. Собрать их можно и вручную: отснять несколько сотен прилавков и разметить с помощью, например, LabelImg. Можно заказать разметку, например, на Яндекс.Толоке.

Мы не можем раскрывать детали реального проекта, поэтому объясним технологию на открытых данных. Ходить по магазинам и делать фотографии было лень (да и нас бы там не поняли), а желание самостоятельно делать разметку найденных в интернете фотографий закончилось после сотого классифицированного объекта. К счастью, совершенно случайно наткнулись на архив Grocery Dataset.
В 2014 сотрудники Idea Teknoloji, Istanbul, Turkey выложили в свободный доступ 354 снимка из 40 магазинов, сделанных на 4 камеры. На каждой из этих фотографий они выделили прямоугольниками суммарно несколько тысяч объектов, часть из которых классифицировали в 10 категорий.
Это фотографии сигаретных пачек. Мы не пропагандируем и не рекламируем курение. Ничего более нейтрального просто не нашлось. Обещаем, что везде в статье, где это позволяет ситуация, будем использовать фотографии котиков.

Кроме размеченных фотографий прилавков, они написали статью Toward Retail Product Recognition on Grocery Shelves с решением задачи локализации и классификации. Это задало своего рода опорную отметку: наше решение с использованием новых подходов должно получиться проще и точнее, иначе это неинтересно. Их подход состоит из комбинации алгоритмов:

Недавно свёрточные нейронные сети (CNN) совершили революцию в области компьютерного зрения и совершенно изменили подход к решению такого рода задач. За последние несколько лет эти технологии стали доступными широкому кругу разработчиков, а такие высокоуровневые API как Keras значительно снизили порог вхождения. Сейчас практически любой разработчик уже через несколько дней знакомства может использовать всю мощь свёрточных нейронных сетей. Статья описывает использование этих технологий на примере, показывая, как целый каскад алгоритмов может быть с лёгкостью заменён всего лишь двумя нейронными сетями без потери точности.
Решать задачу будем по шагам:
Основные технологии, которые мы будем использовать: Tensorflow, Keras, Tensorflow Object Detection API, OpenCV. Несмотря на то, что и Windows и Mac OS походят для работы с Tensorflow, мы всё-таки рекомендуем использовать Ubuntu. Даже если вы никогда до этого не работали с этой операционной системой, её использование сохранит вам кучу времени. Установка Tensorflow для работы с GPU — тема, заслуживающая отдельной статьи. К счастью, такие статьи уже есть. Например, Installing TensorFlow on Ubuntu 16.04 with an Nvidia GPU. Некоторые инструкции из неё могут быть устаревшими.
Шаг 1. Подготовка данных (ссылка на github)
Этот шаг, как правило, занимает гораздо больше времени, чем само моделирование. К счастью, мы используем готовые данные, которые преобразуем в нужную для нас форму.
Скачать и распаковать можно так:
Получаем следующую структуру папок:

Будем использовать информацию из директорий ShelfImages и ProductImagesFromShelves.
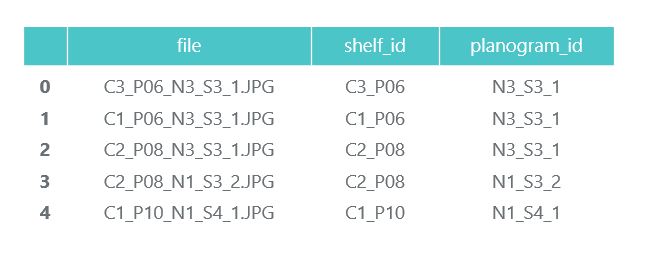
ShelfImages содержит снимки самих стеллажей. В названии закодирован идентификатор стеллажа с идентификатором снимка. Снимков одного стеллажа может быть несколько. Например, одна фотография целиком и 5 фотографий по частям с пересечениями.
Файл C1_P01_N1_S2_2.JPG (стеллаж C1_P01, снимок N1_S2_2):

Пробегаем по всем файлам и собираем информацию в pandas data frame photos_df:
ProductImagesFromShelves содержит вырезанные фотографии товаров с полок в 11 поддиректориях: 0 — не классифицированные, 1 — Marlboro, 2 — Kent и т.д. Чтобы не рекламировать их, будем пользоваться только номерами категорий без указания названий. Файлы в названиях содержат информацию о стеллаже, положении и размеру пачки на нём.
Файл C1_P01_N1_S3_1.JPG_1276_1828_276_448.png из директории 1 (категория 1, стеллаж C1_P01, снимок N1_S3_1, координаты верхнего левого угла (1276, 1828), ширина 276, высота 448):

Нам не нужны сами фотографии отдельных пачек (будем вырезать их из снимков стеллажей), а информацию о их категории и положении собираем в pandas data frame products_df:
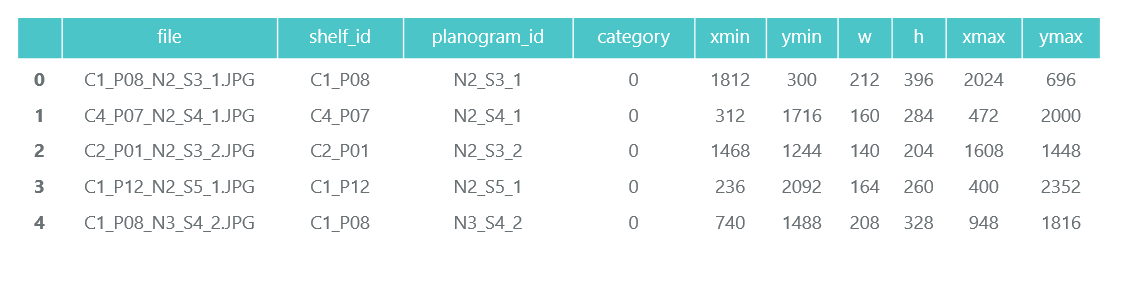
На этом же шаге мы разбиваем всю нашу информацию на два раздела: train для тренировки и validation для мониторинга тренировки. В реальных проектах так делать, конечно же, не стоит. А также не стоит доверять тем, кто так делает. Необходимо как минимум выделить ещё test для финальной проверки. Но даже при таком не очень честном подходе нам важно не сильно обмануть себя.
Как мы уже отметили, фотографий одного стеллажа может быть несколько. Соответственно, одна и та же пачка может попасть на несколько снимков. Поэтому советуем разбивать не по снимкам и уж тем более не по пачкам, а по стеллажам. Это нужно, чтобы не получилось так, что один и тот же объект, снятый с разных ракурсов, оказался и в train и в validation.
Делаем разбиение 70/30 (30% стеллажей идёт на валидацию, остальное на тренировку):
Убедимся, что при нашем разбиении имеется достаточно представителей каждого класса как для тренировки, так и для валидации:

Голубым цветом показано количество товаров категории для валидации, а оранжевым для тренировки. Не очень хорошо обстоят дела с категорией 3 для валидации, но её представителей в принципе мало.
На этапе подготовки данных важно не ошибиться, так как вся дальнейшая работа основывается на его результатах. Одну ошибку мы всё-таки допустили и провели много счастливых часов, пытаясь понять, почему качество моделей очень посредственное. Уже чувствовали себя проигравшими «олдскульным» технологиям, пока случайно не заметили, что часть исходных фотографий повёрнута на 90 градусов, а часть сделана вверх ногами.
При этом разметка сделана так, как будто фотографии ориентированы правильно. После быстрого исправления дело пошло гораздо веселее.
Сохраним наши данные в pkl-файлы для использования на следующих шагах. Итого, у нас есть:
Для проверки отобразим один стеллаж по нашим данным:

Шаг 2. Классификация по брендам (ссылка на github)
Классификация изображений является основной задачей в области компьютерного зрения. Проблема заключается в «семантическом разрыве»: фотография – это всего лишь большая матрица чисел [0, 255]. Например, 800x600x3 (3 канала RGB).

Почему эта задача является сложной:

Как мы уже говорили, авторы используемых нами данных выделили 10 брендов. Это крайне упрощённая задача, поскольку марок сигарет на стеллажах гораздо больше. Но всё, что не попало в эти 10 категорий, было отправлено в 0 — не классифицированное:
 "
"
Их статья предлагает такой алгоритм классификации с итоговой точностью 92%:

Что будем делать мы:
Звучит «объёмно», но мы всего лишь воспользовались примером Keras «Trains a ResNet on the CIFAR10 dataset» взяв из него функцию создания ResNet v1.
Для запуска процесса тренировки надо подготовить два массива: x – фотографии пачек с размерностью (количество_пачек, высота, ширина, 3) и y – их категории с размерностью (количество_пачек, 10). Массив y содержит так называемые 1-hot вектора. Если категория пачки для тренировки имеет номер 2 (от 0 до 9), то этому соответствует вектор [0, 0, 1, 0, 0, 0, 0, 0, 0, 0].
Важный вопрос, как быть с шириной и высотой, ведь все фотографии сделаны с разным разрешением с разного расстояния. Надо выбрать какой-нибудь фиксированный размер, к которому можно привести все наши снимки пачек. Этот фиксированный размер является мета-параметром, от которого зависит, как будет тренироваться и работать наша нейросеть.
С одной стороны, хочется сделать этот размер как можно больше, чтобы ни одна деталь снимка не осталась незамеченной. С другой стороны, при нашем скудном объёме данных для тренировки это может привести к быстрому переобучению: модель будет работать идеально на тренировочных данных, но плохо — на данных для валидации. Мы выбрали размер 120x80, возможно, на другом размере мы получили бы лучший результат. Функция масштабирования:
Отмасштабируем и отобразим одну пачку для проверки. Название марки человеком читается с трудом, посмотрим, как справится с задачей классификации нейронная сеть:

После подготовки по флагу, полученному на предыдущем шаге, разбиваем массивы x и y на x_train/x_validation и y_train/y_validation, получаем:
Данные подготовлены, функцию конструктор нейронной сети архитектуры ResNet v1 мы копируем из примера Keras:
Конструируем модель:
У нас довольно ограниченный набор данных. Поэтому для того, чтобы модель во время тренировки не видела одну и ту же фотографию каждую эпоху, используем аугментацию: случайным образом смещаем снимок и немного вращаем. Keras предоставляет для этого такой набор настроек:
Запускаем процесс тренировки.
После тренировки и оценки получаем точность в районе 92%. У вас может получиться другая точность: данных крайне мало, поэтому точность очень сильно зависит от удачности разбиения. На этом разбиении мы не получили точность значительно выше той, что была указана в статье, но мы практически ничего не сделали сами и написали мало кода. Более того, мы можем с лёгкостью добавить новую категорию, а точность должна (по идее) значительно вырасти, если мы подготовим больше данных.
Для интереса сравниваем confusion-матрицы:

Практически все категории наша нейронная сеть определяет лучше, кроме категорий 4 и 7. Также бывает полезно посмотреть на самых ярких представителей каждой ячейки confusion matrix:

Ещё можно понять, почему Parliament был принят за Camel, но вот почему Winston был принят за Lucky Strike – совершенно непонятно, у них же ничего общего. Это и есть основная проблема нейронных сетей – совершенная непрозрачность того, что там внутри происходит. Можно, конечно, визуализировать некоторые слои, но для нас эта визуализация выглядит так:

Очевидная возможность улучшить качество распознавания в наших условиях – добавлять больше фотографий.
Итак, классификатор готов. Переходим к детектору.
Шаг 3. Поиск товаров на фотографии (ссылка на github)
Следующие важные задачи в области компьютерного зрения: семантическая сегментация, локализация, поиск объектов и сегментация экземпляров.

Для нашей задачи нужен object detection. Статья 2014 года предлагает подход на основе метода Виолы-Джонса и HOG с визуальной точностью:

Благодаря использованию дополнительных статистических ограничений точность у них получается весьма хорошей:

Сейчас задача распознавания объектов успешно решается с помощью нейронных сетей. Мы воспользуемся системой Tensorflow Object Detection API и натренируем нейронную сеть с архитектурой SSD Mobilenet V1. Тренировка такой модели с нуля требует много данных и может занять дни, поэтому мы используем предтренированную на данных COCO модель по принципу transfer learning.
Ключевая концепция этого подхода такая. Почему ребёнку не надо показывать миллионы предметов, чтобы он научился находить и отличать шарик от кубика? Потому что у ребёнка есть 500 миллионов лет развития зрительной коры мозга. Эволюция сделала зрение крупнейшей сенсорной системой. Почти 50% (но это неточно) нейронов человеческого мозга отвечают за обработку изображений. Родителям остаётся только показать шарик и кубик, а затем несколько раз поправить ребёнка, чтобы он отлично находил и отличал одно от другого.
С философской точки зрения (с технической отличий больше, чем общего), transfer learning в нейронных сетях работает схожим образом. Свёрточные нейронные сети состоят из уровней, каждый из которых определяет всё более сложные формы: выделяет ключевые точки, объединяет их в линии, которые в свою очередь объединяет в фигуры. И только на последнем уровне из совокупности найденных признаков определяет объект.
У предметов реального мира очень много общего. При transfer learning мы используем уже натренированные уровни определения базовых признаков и обучаем лишь слои, ответственные за определение объектов. Для этого нам достаточно пары сотен фотографий и пары часов работы рядового GPU. Сеть изначально была тренирована на наборе данных COCO (Microsoft Common Objects in Context), а это 91 категория и 2 500 000 изображений! Много, хотя и не 500 миллионов лет эволюции.
Забегая немного вперёд, эта gif-анимация (немного медленная, не прокручивайте сразу) из tensorboard визуализирует процесс обучения. Как видим, вполне качественный результат модель начинает выдавать практически сразу, дальше идёт уже шлифовка:

«Тренер» системы Tensorflow Object Detection API самостоятельно умеет делать аугментацию, вырезать для тренировки случайные части изображений, подбирать «негативные» примеры (участки фотографии, не содержащие никаких объектов). По идее, никакая предобработка фотографий не нужна. Однако на домашнем компьютере с HDD и маленьким объёмом оперативной памяти работать с изображениями высокого разрешения он отказался: сначала долго висел, шуршал диском, потом вылетел.
В итоге, мы сжали фотографии до размера 1000x1000 пикселей с сохранением соотношения сторон. Но так как при сжатии большой фотографии теряется много признаков, сначала из каждой фотографии стеллажа вырезали несколько квадратов случайного размера и сжали их в 1000x1000. В результате в тренировочные данные попали и пачки в высоком разрешении (но мало), и в маленьком (но много). Повторимся: этот шаг вынужденный и, скорее всего, совершенно не нужный, а возможно, и вредный.
Подготовленные и сжатые фотографии сохраняем в отдельные директории (eval и train), а их описание (с содержащимися на них пачками) формируем в виде двух pandas data frame (train_df и eval_df):
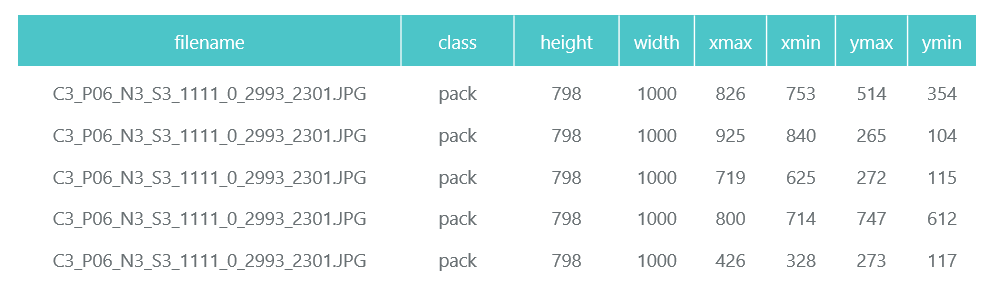
Система Tensorflow Object Detection API требует, чтобы входные данные были представлены в виде tfrecord-файлов. Сформировать их можно с помощью утилиты, но мы сделаем это кодом:
Нам остаётся подготовить специальную директорию и запустить процессы:

Структура может быть и другой, но мы находим её очень удобной.
Директория data cодержит сформированные нами файлы с tfrecords (train.record и eval.record), а также pack.pbtxt с типами объектов, на поиск которых мы будем тренировать нейронную сеть. У нас только один тип определяемых объектов, поэтому файл очень короткий:
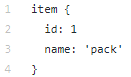
Директория models (моделей для решения одной задачи может быть много) в дочерней директории ssd_mobilenet_v1 содержит настройки для тренировки в .config файле, а также две пустые директории: train и eval. В train «тренер» будет сохранять контрольные точки модели, «оценщик» будет подхватывать их, запускать на данных для оценки и складывать в директорию eval. Tensorboard будет следить за этими двумя директориями и отображать информацию по процессу.
Детальное описание структуры конфигурационных файлов и т.д. можно найти здесь и здесь. Инструкции по установке Tensorflow Object Detection API можно найти здесь.
Заходим в директорию models/research/object_detection и выкачиваем предтренированную модель:
Копируем туда же подготовленную нами директорию pack_detector.
Сначала запускаем процесс тренировки:
Запускаем процесс оценки. У нас нет второй видеокарты, поэтому запускаем его на процессоре (с помощью инструкции CUDA_VISIBLE_DEVICES=""). Из-за этого он будет сильно запаздывать относительно процесса тренировки, но это не так страшно:
Запускаем процесс tensorboard:
После этого мы можем видеть красивые графики, а также реальную работу модели на оценочных данных (gif в начале):

Процесс тренировки можно в любой момент остановить и возобновить. Когда считаем, что модель достаточно хороша, сохраняем чекпоинт в виде inference graph:
Итак, на этом шаге мы получили inference graph, который можем использовать для поиска объектов пачек. Переходим к его использованию.
Шаг 4. Реализация поиска (ссылка на github)
Код загрузки inference graph и инициализации есть по ссылке выше. Ключевые функции поиска:
Функция находит ограничивающие прямоугольники (bounded boxes) для пачек не на всей фотографии, а на её части. Также функция отфильтровывает найденные прямоугольники с низким показателем обнаружения (detection score), указанным в параметре cutoff.
Получается дилемма. С одной стороны, при высоком cutoff мы теряем много объектов, с другой — при низком cutoff начинаем находить много объектов, которые не являются пачками. При этом находим всё равно не всё и не идеально:

Однако заметим, что если мы запустим функцию для небольшого куска фотографии, то распознавание получается практически идеальным при cutoff = 0.9:

Это происходит из-за того, что модель SSD MobileNet V1 принимает на вход фотографии 300x300. Естественно, при таком сжатии теряется очень много признаков.
Но эти признаки сохраняются, если мы вырезаем небольшой квадрат, содержащий несколько пачек. Это наталкивает на идею применения плавающего окна: небольшим прямоугольником пробегаем по фотографии и запоминаем всё найденное.

Возникает проблема: мы находим по несколько раз одни и те же пачки, иногда в очень урезанном варианте. Эту проблему можно решить с помощью алгоритма подавления немаксимумов. Идея крайне простая: за один шаг находим прямоугольник с максимальным показателем распознавания (detection score), запоминаем его, удаляем все остальные прямоугольники, которые имеют площадь пересечения с ним больше overlapTresh (реализация найдена на просторах интернета с небольшими изменениями):
Результат получается визуально почти идеальным:

Результат работы на фотографии плохого качества с большим количеством пачек:

Как мы видим, количество объектов и качество фотографий не помешало распознать все упаковки правильно, чего мы и добивались.
Этот пример в нашей статье довольно «игрушечный»: авторы данных уже собирали их в расчёте на то, что им придётся использовать их для распознавания. Соответственно, выбрали только хорошие снимки, сделанные при нормальном освещении не под углом и т.д. Реальная жизнь намного богаче.
Мы не можем раскрывать детали реального проекта, но вот ряд сложностей, которые нам пришлось преодолевать:
Всё это кардинально меняет и усложняет процесс подготовки данных, тренировки и архитектуру применяемых нейронных сетей, но нас не остановит.
Введение
Что такое планограмма? План-схема выкладки товара на конкретном торговом оборудовании магазина.
Что такое реалограмма? Схема выкладки товара на конкретном торговом оборудовании, существующая в магазине здесь и сейчас.
Планограмма — как надо, реалограмма — что имеем.
До сих пор во многих магазинах управление остатком товара на стойках, полках, прилавках, стеллажах является исключительно ручным трудом. Тысячи сотрудников проверяют наличие продуктов вручную, подсчитывают остаток, сверяют расположение с требованиями. Это дорого, а ошибки весьма вероятны. Неправильная выкладка или отсутствие товара приводит к снижению продаж.
Также многие производители заключают соглашения с розничными торговцами о выкладке их товаров. А поскольку производителей много, между ними начинается борьба за лучшее место на полке. Каждый хочет, чтобы его товар лежал в центре напротив глаз покупателя и занял как можно большую площадь. Возникает необходимость постоянного аудита.
Тысячи мерчандайзеров перемещаются от магазина к магазину, чтобы убедиться, что товар их компании есть на полке и представлен в соответствии с договором. Иногда они ленятся: гораздо приятнее составить отчёт, не выходя из дома, чем ехать в торговую точку. Появляется необходимость постоянного аудита аудиторов.
Естественно, задача автоматизации и упрощения этого процесса решается давно. Одной из самых сложных частей была обработка изображений: найти и распознать товары. И только сравнительно недавно эта задача упростилась настолько, что для частного случая в упрощённом виде её полное решение можно описать в одной статье. Это мы и сделаем.
Статья содержит минимум кода (только для случаев, когда код понятнее текста). Полное решение доступно в виде иллюстрированного tutorial'а в jupyter notebooks. Статья не содержит описания архитектур нейронных сетей, принципов работы нейронов, математических формул. В статье мы используем их как инженерный инструмент, не сильно вдаваясь в детали его устройства.
Данные и подход
Как и для любого data driven подхода, для решений на основе нейронных сетей нужны данные. Собрать их можно и вручную: отснять несколько сотен прилавков и разметить с помощью, например, LabelImg. Можно заказать разметку, например, на Яндекс.Толоке.
Мы не можем раскрывать детали реального проекта, поэтому объясним технологию на открытых данных. Ходить по магазинам и делать фотографии было лень (да и нас бы там не поняли), а желание самостоятельно делать разметку найденных в интернете фотографий закончилось после сотого классифицированного объекта. К счастью, совершенно случайно наткнулись на архив Grocery Dataset.
В 2014 сотрудники Idea Teknoloji, Istanbul, Turkey выложили в свободный доступ 354 снимка из 40 магазинов, сделанных на 4 камеры. На каждой из этих фотографий они выделили прямоугольниками суммарно несколько тысяч объектов, часть из которых классифицировали в 10 категорий.
Это фотографии сигаретных пачек. Мы не пропагандируем и не рекламируем курение. Ничего более нейтрального просто не нашлось. Обещаем, что везде в статье, где это позволяет ситуация, будем использовать фотографии котиков.
Кроме размеченных фотографий прилавков, они написали статью Toward Retail Product Recognition on Grocery Shelves с решением задачи локализации и классификации. Это задало своего рода опорную отметку: наше решение с использованием новых подходов должно получиться проще и точнее, иначе это неинтересно. Их подход состоит из комбинации алгоритмов:
Недавно свёрточные нейронные сети (CNN) совершили революцию в области компьютерного зрения и совершенно изменили подход к решению такого рода задач. За последние несколько лет эти технологии стали доступными широкому кругу разработчиков, а такие высокоуровневые API как Keras значительно снизили порог вхождения. Сейчас практически любой разработчик уже через несколько дней знакомства может использовать всю мощь свёрточных нейронных сетей. Статья описывает использование этих технологий на примере, показывая, как целый каскад алгоритмов может быть с лёгкостью заменён всего лишь двумя нейронными сетями без потери точности.
Решать задачу будем по шагам:
- Подготовка данных. Выкачаем архивы и преобразуем в удобный для работы вид.
- Классификация по брендам. Решим задачу классификации с помощью нейронной сети.
- Поиск товаров на фотографии. Натренируем нейронную сеть на поиск товаров.
- Реализация поиска. Улучшим качество детектирования с использованием плавающего окна и алгоритма подавления немаксимумов.
- Заключение. Кратко расскажем, почему реальная жизнь намного сложнее этого примера.
Технологии
Основные технологии, которые мы будем использовать: Tensorflow, Keras, Tensorflow Object Detection API, OpenCV. Несмотря на то, что и Windows и Mac OS походят для работы с Tensorflow, мы всё-таки рекомендуем использовать Ubuntu. Даже если вы никогда до этого не работали с этой операционной системой, её использование сохранит вам кучу времени. Установка Tensorflow для работы с GPU — тема, заслуживающая отдельной статьи. К счастью, такие статьи уже есть. Например, Installing TensorFlow on Ubuntu 16.04 with an Nvidia GPU. Некоторые инструкции из неё могут быть устаревшими.
Шаг 1. Подготовка данных (ссылка на github)
Этот шаг, как правило, занимает гораздо больше времени, чем само моделирование. К счастью, мы используем готовые данные, которые преобразуем в нужную для нас форму.
Скачать и распаковать можно так:
wget https://github.com/gulvarol/grocerydataset/releases/download/1.0/GroceryDataset_part1.tar.gz wget https://github.com/gulvarol/grocerydataset/releases/download/1.0/GroceryDataset_part2.tar.gz tar -xvzf GroceryDataset_part1.tar.gz tar -xvzf GroceryDataset_part2.tar.gz
Получаем следующую структуру папок:
Будем использовать информацию из директорий ShelfImages и ProductImagesFromShelves.
ShelfImages содержит снимки самих стеллажей. В названии закодирован идентификатор стеллажа с идентификатором снимка. Снимков одного стеллажа может быть несколько. Например, одна фотография целиком и 5 фотографий по частям с пересечениями.
Файл C1_P01_N1_S2_2.JPG (стеллаж C1_P01, снимок N1_S2_2):
Пробегаем по всем файлам и собираем информацию в pandas data frame photos_df:
ProductImagesFromShelves содержит вырезанные фотографии товаров с полок в 11 поддиректориях: 0 — не классифицированные, 1 — Marlboro, 2 — Kent и т.д. Чтобы не рекламировать их, будем пользоваться только номерами категорий без указания названий. Файлы в названиях содержат информацию о стеллаже, положении и размеру пачки на нём.
Файл C1_P01_N1_S3_1.JPG_1276_1828_276_448.png из директории 1 (категория 1, стеллаж C1_P01, снимок N1_S3_1, координаты верхнего левого угла (1276, 1828), ширина 276, высота 448):
Нам не нужны сами фотографии отдельных пачек (будем вырезать их из снимков стеллажей), а информацию о их категории и положении собираем в pandas data frame products_df:
На этом же шаге мы разбиваем всю нашу информацию на два раздела: train для тренировки и validation для мониторинга тренировки. В реальных проектах так делать, конечно же, не стоит. А также не стоит доверять тем, кто так делает. Необходимо как минимум выделить ещё test для финальной проверки. Но даже при таком не очень честном подходе нам важно не сильно обмануть себя.
Как мы уже отметили, фотографий одного стеллажа может быть несколько. Соответственно, одна и та же пачка может попасть на несколько снимков. Поэтому советуем разбивать не по снимкам и уж тем более не по пачкам, а по стеллажам. Это нужно, чтобы не получилось так, что один и тот же объект, снятый с разных ракурсов, оказался и в train и в validation.
Делаем разбиение 70/30 (30% стеллажей идёт на валидацию, остальное на тренировку):
# get distinct shelves shelves = list(set(photos_df['shelf_id'].values)) # use train_test_split from sklearn shelves_train, shelves_validation, _, _ = train_test_split( shelves, shelves, test_size=0.3, random_state=6) # mark all records in data frames with is_train flag def is_train(shelf_id): return shelf_id in shelves_train photos_df['is_train'] = photos_df.shelf_id.apply(is_train) products_df['is_train'] = products_df.shelf_id.apply(is_train)
Убедимся, что при нашем разбиении имеется достаточно представителей каждого класса как для тренировки, так и для валидации:
Голубым цветом показано количество товаров категории для валидации, а оранжевым для тренировки. Не очень хорошо обстоят дела с категорией 3 для валидации, но её представителей в принципе мало.
На этапе подготовки данных важно не ошибиться, так как вся дальнейшая работа основывается на его результатах. Одну ошибку мы всё-таки допустили и провели много счастливых часов, пытаясь понять, почему качество моделей очень посредственное. Уже чувствовали себя проигравшими «олдскульным» технологиям, пока случайно не заметили, что часть исходных фотографий повёрнута на 90 градусов, а часть сделана вверх ногами.
При этом разметка сделана так, как будто фотографии ориентированы правильно. После быстрого исправления дело пошло гораздо веселее.
Сохраним наши данные в pkl-файлы для использования на следующих шагах. Итого, у нас есть:
- Директория фотографий стеллажей и их частей с пачками,
- Дата-фрейм с описанием каждого стеллажа с пометкой, предназначен ли он для тренировки,
- Дата-фрейм с информацией по всем товарам на стеллажах, с указанием их положения, размера, категории и пометкой, предназначены ли они для тренировки.
Для проверки отобразим один стеллаж по нашим данным:
# function to display shelf photo with rectangled products def draw_shelf_photo(file): file_products_df = products_df[products_df.file == file] coordinates = file_products_df[['xmin', 'ymin', 'xmax', 'ymax']].values im = cv2.imread(f'{shelf_images}{file}') im = cv2.cvtColor(im, cv2.COLOR_BGR2RGB) for xmin, ymin, xmax, ymax in coordinates: cv2.rectangle(im, (xmin, ymin), (xmax, ymax), (0, 255, 0), 5) plt.imshow(im) # draw one photo to check our data fig = plt.gcf() fig.set_size_inches(18.5, 10.5) draw_shelf_photo('C3_P07_N1_S6_1.JPG')
Шаг 2. Классификация по брендам (ссылка на github)
Классификация изображений является основной задачей в области компьютерного зрения. Проблема заключается в «семантическом разрыве»: фотография – это всего лишь большая матрица чисел [0, 255]. Например, 800x600x3 (3 канала RGB).
Почему эта задача является сложной:
Как мы уже говорили, авторы используемых нами данных выделили 10 брендов. Это крайне упрощённая задача, поскольку марок сигарет на стеллажах гораздо больше. Но всё, что не попало в эти 10 категорий, было отправлено в 0 — не классифицированное:
" Их статья предлагает такой алгоритм классификации с итоговой точностью 92%:
Что будем делать мы:
- Подготовим данные для обучения,
- Натренируем свёрточную нейронную сеть с архитектурой ResNet v1,
- Проверим на фотографиях для валидации.
Звучит «объёмно», но мы всего лишь воспользовались примером Keras «Trains a ResNet on the CIFAR10 dataset» взяв из него функцию создания ResNet v1.
Для запуска процесса тренировки надо подготовить два массива: x – фотографии пачек с размерностью (количество_пачек, высота, ширина, 3) и y – их категории с размерностью (количество_пачек, 10). Массив y содержит так называемые 1-hot вектора. Если категория пачки для тренировки имеет номер 2 (от 0 до 9), то этому соответствует вектор [0, 0, 1, 0, 0, 0, 0, 0, 0, 0].
Важный вопрос, как быть с шириной и высотой, ведь все фотографии сделаны с разным разрешением с разного расстояния. Надо выбрать какой-нибудь фиксированный размер, к которому можно привести все наши снимки пачек. Этот фиксированный размер является мета-параметром, от которого зависит, как будет тренироваться и работать наша нейросеть.
С одной стороны, хочется сделать этот размер как можно больше, чтобы ни одна деталь снимка не осталась незамеченной. С другой стороны, при нашем скудном объёме данных для тренировки это может привести к быстрому переобучению: модель будет работать идеально на тренировочных данных, но плохо — на данных для валидации. Мы выбрали размер 120x80, возможно, на другом размере мы получили бы лучший результат. Функция масштабирования:
# resize pack to fixed size SHAPE_WIDTH x SHAPE_HEIGHT def resize_pack(pack): fx_ratio = SHAPE_WIDTH / pack.shape[1] fy_ratio = SHAPE_HEIGHT / pack.shape[0] pack = cv2.resize(pack, (0, 0), fx=fx_ratio, fy=fy_ratio) return pack[0:SHAPE_HEIGHT, 0:SHAPE_WIDTH]
Отмасштабируем и отобразим одну пачку для проверки. Название марки человеком читается с трудом, посмотрим, как справится с задачей классификации нейронная сеть:
После подготовки по флагу, полученному на предыдущем шаге, разбиваем массивы x и y на x_train/x_validation и y_train/y_validation, получаем:
x_train shape: (1969, 120, 80, 3) y_train shape: (1969, 10) 1969 train samples 775 validation samples
Данные подготовлены, функцию конструктор нейронной сети архитектуры ResNet v1 мы копируем из примера Keras:
def resnet_v1(input_shape, depth, num_classes=10): …
Конструируем модель:
model = resnet_v1(input_shape=x_train.shape[1:], depth=depth, num_classes=num_classes) model.compile(loss='categorical_crossentropy', optimizer=Adam(lr=lr_schedule(0)), metrics=['accuracy'])
У нас довольно ограниченный набор данных. Поэтому для того, чтобы модель во время тренировки не видела одну и ту же фотографию каждую эпоху, используем аугментацию: случайным образом смещаем снимок и немного вращаем. Keras предоставляет для этого такой набор настроек:
# This will do preprocessing and realtime data augmentation: datagen = ImageDataGenerator( featurewise_center=False, # set input mean to 0 over the dataset samplewise_center=False, # set each sample mean to 0 featurewise_std_normalization=False, # divide inputs by std of the dataset samplewise_std_normalization=False, # divide each input by its std zca_whitening=False, # apply ZCA whitening rotation_range=5, # randomly rotate images in the range (degrees, 0 to 180) width_shift_range=0.1, # randomly shift images horizontally (fraction of total width) height_shift_range=0.1, # randomly shift images vertically (fraction of total height) horizontal_flip=False, # randomly flip images vertical_flip=False) # randomly flip images datagen.fit(x_train)
Запускаем процесс тренировки.
# let's run training process, 20 epochs is enough batch_size = 50 epochs = 15 model.fit_generator(datagen.flow(x_train, y_train, batch_size=batch_size), validation_data=(x_validation, y_validation), epochs=epochs, verbose=1, workers=4, callbacks=[LearningRateScheduler(lr_schedule)])
После тренировки и оценки получаем точность в районе 92%. У вас может получиться другая точность: данных крайне мало, поэтому точность очень сильно зависит от удачности разбиения. На этом разбиении мы не получили точность значительно выше той, что была указана в статье, но мы практически ничего не сделали сами и написали мало кода. Более того, мы можем с лёгкостью добавить новую категорию, а точность должна (по идее) значительно вырасти, если мы подготовим больше данных.
Для интереса сравниваем confusion-матрицы:
Практически все категории наша нейронная сеть определяет лучше, кроме категорий 4 и 7. Также бывает полезно посмотреть на самых ярких представителей каждой ячейки confusion matrix:
Ещё можно понять, почему Parliament был принят за Camel, но вот почему Winston был принят за Lucky Strike – совершенно непонятно, у них же ничего общего. Это и есть основная проблема нейронных сетей – совершенная непрозрачность того, что там внутри происходит. Можно, конечно, визуализировать некоторые слои, но для нас эта визуализация выглядит так:
Очевидная возможность улучшить качество распознавания в наших условиях – добавлять больше фотографий.
Итак, классификатор готов. Переходим к детектору.
Шаг 3. Поиск товаров на фотографии (ссылка на github)
Следующие важные задачи в области компьютерного зрения: семантическая сегментация, локализация, поиск объектов и сегментация экземпляров.
Для нашей задачи нужен object detection. Статья 2014 года предлагает подход на основе метода Виолы-Джонса и HOG с визуальной точностью:
Благодаря использованию дополнительных статистических ограничений точность у них получается весьма хорошей:
Сейчас задача распознавания объектов успешно решается с помощью нейронных сетей. Мы воспользуемся системой Tensorflow Object Detection API и натренируем нейронную сеть с архитектурой SSD Mobilenet V1. Тренировка такой модели с нуля требует много данных и может занять дни, поэтому мы используем предтренированную на данных COCO модель по принципу transfer learning.
Ключевая концепция этого подхода такая. Почему ребёнку не надо показывать миллионы предметов, чтобы он научился находить и отличать шарик от кубика? Потому что у ребёнка есть 500 миллионов лет развития зрительной коры мозга. Эволюция сделала зрение крупнейшей сенсорной системой. Почти 50% (но это неточно) нейронов человеческого мозга отвечают за обработку изображений. Родителям остаётся только показать шарик и кубик, а затем несколько раз поправить ребёнка, чтобы он отлично находил и отличал одно от другого.
С философской точки зрения (с технической отличий больше, чем общего), transfer learning в нейронных сетях работает схожим образом. Свёрточные нейронные сети состоят из уровней, каждый из которых определяет всё более сложные формы: выделяет ключевые точки, объединяет их в линии, которые в свою очередь объединяет в фигуры. И только на последнем уровне из совокупности найденных признаков определяет объект.
У предметов реального мира очень много общего. При transfer learning мы используем уже натренированные уровни определения базовых признаков и обучаем лишь слои, ответственные за определение объектов. Для этого нам достаточно пары сотен фотографий и пары часов работы рядового GPU. Сеть изначально была тренирована на наборе данных COCO (Microsoft Common Objects in Context), а это 91 категория и 2 500 000 изображений! Много, хотя и не 500 миллионов лет эволюции.
Забегая немного вперёд, эта gif-анимация (немного медленная, не прокручивайте сразу) из tensorboard визуализирует процесс обучения. Как видим, вполне качественный результат модель начинает выдавать практически сразу, дальше идёт уже шлифовка:
«Тренер» системы Tensorflow Object Detection API самостоятельно умеет делать аугментацию, вырезать для тренировки случайные части изображений, подбирать «негативные» примеры (участки фотографии, не содержащие никаких объектов). По идее, никакая предобработка фотографий не нужна. Однако на домашнем компьютере с HDD и маленьким объёмом оперативной памяти работать с изображениями высокого разрешения он отказался: сначала долго висел, шуршал диском, потом вылетел.
В итоге, мы сжали фотографии до размера 1000x1000 пикселей с сохранением соотношения сторон. Но так как при сжатии большой фотографии теряется много признаков, сначала из каждой фотографии стеллажа вырезали несколько квадратов случайного размера и сжали их в 1000x1000. В результате в тренировочные данные попали и пачки в высоком разрешении (но мало), и в маленьком (но много). Повторимся: этот шаг вынужденный и, скорее всего, совершенно не нужный, а возможно, и вредный.
Подготовленные и сжатые фотографии сохраняем в отдельные директории (eval и train), а их описание (с содержащимися на них пачками) формируем в виде двух pandas data frame (train_df и eval_df):
Система Tensorflow Object Detection API требует, чтобы входные данные были представлены в виде tfrecord-файлов. Сформировать их можно с помощью утилиты, но мы сделаем это кодом:
def class_text_to_int(row_label): if row_label == 'pack': return 1 else: None def split(df, group): data = namedtuple('data', ['filename', 'object']) gb = df.groupby(group) return [data(filename, gb.get_group(x)) for filename, x in zip(gb.groups.keys(), gb.groups)] def create_tf_example(group, path): with tf.gfile.GFile(os.path.join(path, '{}'.format(group.filename)), 'rb') as fid: encoded_jpg = fid.read() encoded_jpg_io = io.BytesIO(encoded_jpg) image = Image.open(encoded_jpg_io) width, height = image.size filename = group.filename.encode('utf8') image_format = b'jpg' xmins = [] xmaxs = [] ymins = [] ymaxs = [] classes_text = [] classes = [] for index, row in group.object.iterrows(): xmins.append(row['xmin'] / width) xmaxs.append(row['xmax'] / width) ymins.append(row['ymin'] / height) ymaxs.append(row['ymax'] / height) classes_text.append(row['class'].encode('utf8')) classes.append(class_text_to_int(row['class'])) tf_example = tf.train.Example(features=tf.train.Features(feature={ 'image/height': dataset_util.int64_feature(height), 'image/width': dataset_util.int64_feature(width), 'image/filename': dataset_util.bytes_feature(filename), 'image/source_id': dataset_util.bytes_feature(filename), 'image/encoded': dataset_util.bytes_feature(encoded_jpg), 'image/format': dataset_util.bytes_feature(image_format), 'image/object/bbox/xmin': dataset_util.float_list_feature(xmins), 'image/object/bbox/xmax': dataset_util.float_list_feature(xmaxs), 'image/object/bbox/ymin': dataset_util.float_list_feature(ymins), 'image/object/bbox/ymax': dataset_util.float_list_feature(ymaxs), 'image/object/class/text': dataset_util.bytes_list_feature(classes_text), 'image/object/class/label': dataset_util.int64_list_feature(classes), })) return tf_example def convert_to_tf_records(images_path, examples, dst_file): writer = tf.python_io.TFRecordWriter(dst_file) grouped = split(examples, 'filename') for group in grouped: tf_example = create_tf_example(group, images_path) writer.write(tf_example.SerializeToString()) writer.close() convert_to_tf_records(f'{cropped_path}train/', train_df, f'{detector_data_path}train.record') convert_to_tf_records(f'{cropped_path}eval/', eval_df, f'{detector_data_path}eval.record')
Нам остаётся подготовить специальную директорию и запустить процессы:
Структура может быть и другой, но мы находим её очень удобной.
Директория data cодержит сформированные нами файлы с tfrecords (train.record и eval.record), а также pack.pbtxt с типами объектов, на поиск которых мы будем тренировать нейронную сеть. У нас только один тип определяемых объектов, поэтому файл очень короткий:
Директория models (моделей для решения одной задачи может быть много) в дочерней директории ssd_mobilenet_v1 содержит настройки для тренировки в .config файле, а также две пустые директории: train и eval. В train «тренер» будет сохранять контрольные точки модели, «оценщик» будет подхватывать их, запускать на данных для оценки и складывать в директорию eval. Tensorboard будет следить за этими двумя директориями и отображать информацию по процессу.
Детальное описание структуры конфигурационных файлов и т.д. можно найти здесь и здесь. Инструкции по установке Tensorflow Object Detection API можно найти здесь.
Заходим в директорию models/research/object_detection и выкачиваем предтренированную модель:
wget http://download.tensorflow.org/models/object_detection/ssd_mobilenet_v1_coco_2017_11_17.tar.gz tar -xvzf ssd_mobilenet_v1_coco_2017_11_17.tar.gz
Копируем туда же подготовленную нами директорию pack_detector.
Сначала запускаем процесс тренировки:
python3 train.py --logtostderr \ --train_dir=pack_detector/models/ssd_mobilenet_v1/train/ \ --pipeline_config_path=pack_detector/models/ssd_mobilenet_v1/ssd_mobilenet_v1_pack.config
Запускаем процесс оценки. У нас нет второй видеокарты, поэтому запускаем его на процессоре (с помощью инструкции CUDA_VISIBLE_DEVICES=""). Из-за этого он будет сильно запаздывать относительно процесса тренировки, но это не так страшно:
CUDA_VISIBLE_DEVICES="" python3 eval.py \ --logtostderr \ --checkpoint_dir=pack_detector/models/ssd_mobilenet_v1/train \ --pipeline_config_path=pack_detector/models/ssd_mobilenet_v1/ssd_mobilenet_v1_pack.config \ --eval_dir=pack_detector/models/ssd_mobilenet_v1/eval
Запускаем процесс tensorboard:
tensorboard --logdir=pack_detector/models/ssd_mobilenet_v1
После этого мы можем видеть красивые графики, а также реальную работу модели на оценочных данных (gif в начале):
Процесс тренировки можно в любой момент остановить и возобновить. Когда считаем, что модель достаточно хороша, сохраняем чекпоинт в виде inference graph:
python3 export_inference_graph.py \ --input_type image_tensor \ --pipeline_config_path pack_detector/models/ssd_mobilenet_v1/ssd_mobilenet_v1_pack.config \ --trained_checkpoint_prefix pack_detector/models/ssd_mobilenet_v1/train/model.ckpt-13756 \ --output_directory pack_detector/models/ssd_mobilenet_v1/pack_detector_2018_06_03
Итак, на этом шаге мы получили inference graph, который можем использовать для поиска объектов пачек. Переходим к его использованию.
Шаг 4. Реализация поиска (ссылка на github)
Код загрузки inference graph и инициализации есть по ссылке выше. Ключевые функции поиска:
# let's write function that executes detection def run_inference_for_single_image(image, image_tensor, sess, tensor_dict): # Run inference expanded_dims = np.expand_dims(image, 0) output_dict = sess.run(tensor_dict, feed_dict={image_tensor: expanded_dims}) # all outputs are float32 numpy arrays, so convert types as appropriate output_dict['num_detections'] = int(output_dict['num_detections'][0]) output_dict['detection_classes'] = output_dict['detection_classes'][0].astype(np.uint8) output_dict['detection_boxes'] = output_dict['detection_boxes'][0] output_dict['detection_scores'] = output_dict['detection_scores'][0] return output_dict # it is useful to be able to run inference not only on the whole image, # but also on its parts # cutoff - minimum detection score needed to take box def run_inference_for_image_part(image_tensor, sess, tensor_dict, image, cutoff, ax0, ay0, ax1, ay1): boxes = [] im = image[ay0:ay1, ax0:ax1] h, w, c = im.shape output_dict = run_inference_for_single_image(im, image_tensor, sess, tensor_dict) for i in range(100): if output_dict['detection_scores'][i] < cutoff: break y0, x0, y1, x1, score = *output_dict['detection_boxes'][i], \ output_dict['detection_scores'][i] x0, y0, x1, y1, score = int(x0*w), int(y0*h), \ int(x1*w), int(y1*h), \ int(score * 100) boxes.append((x0+ax0, y0+ay0, x1+ax0, y1+ay0, score)) return boxes
Функция находит ограничивающие прямоугольники (bounded boxes) для пачек не на всей фотографии, а на её части. Также функция отфильтровывает найденные прямоугольники с низким показателем обнаружения (detection score), указанным в параметре cutoff.
Получается дилемма. С одной стороны, при высоком cutoff мы теряем много объектов, с другой — при низком cutoff начинаем находить много объектов, которые не являются пачками. При этом находим всё равно не всё и не идеально:
Однако заметим, что если мы запустим функцию для небольшого куска фотографии, то распознавание получается практически идеальным при cutoff = 0.9:
Это происходит из-за того, что модель SSD MobileNet V1 принимает на вход фотографии 300x300. Естественно, при таком сжатии теряется очень много признаков.
Но эти признаки сохраняются, если мы вырезаем небольшой квадрат, содержащий несколько пачек. Это наталкивает на идею применения плавающего окна: небольшим прямоугольником пробегаем по фотографии и запоминаем всё найденное.
Возникает проблема: мы находим по несколько раз одни и те же пачки, иногда в очень урезанном варианте. Эту проблему можно решить с помощью алгоритма подавления немаксимумов. Идея крайне простая: за один шаг находим прямоугольник с максимальным показателем распознавания (detection score), запоминаем его, удаляем все остальные прямоугольники, которые имеют площадь пересечения с ним больше overlapTresh (реализация найдена на просторах интернета с небольшими изменениями):
# function for non-maximum suppression def non_max_suppression(boxes, overlapThresh): if len(boxes) == 0: return np.array([]).astype("int") if boxes.dtype.kind == "i": boxes = boxes.astype("float") pick = [] x1 = boxes[:,0] y1 = boxes[:,1] x2 = boxes[:,2] y2 = boxes[:,3] sc = boxes[:,4] area = (x2 - x1 + 1) * (y2 - y1 + 1) idxs = np.argsort(sc) while len(idxs) > 0: last = len(idxs) - 1 i = idxs[last] pick.append(i) xx1 = np.maximum(x1[i], x1[idxs[:last]]) yy1 = np.maximum(y1[i], y1[idxs[:last]]) xx2 = np.minimum(x2[i], x2[idxs[:last]]) yy2 = np.minimum(y2[i], y2[idxs[:last]]) w = np.maximum(0, xx2 - xx1 + 1) h = np.maximum(0, yy2 - yy1 + 1) #todo fix overlap-contains... overlap = (w * h) / area[idxs[:last]] idxs = np.delete(idxs, np.concatenate(([last], np.where(overlap > overlapThresh)[0]))) return boxes[pick].astype("int")
Результат получается визуально почти идеальным:
Результат работы на фотографии плохого качества с большим количеством пачек:
Как мы видим, количество объектов и качество фотографий не помешало распознать все упаковки правильно, чего мы и добивались.
Заключение
Этот пример в нашей статье довольно «игрушечный»: авторы данных уже собирали их в расчёте на то, что им придётся использовать их для распознавания. Соответственно, выбрали только хорошие снимки, сделанные при нормальном освещении не под углом и т.д. Реальная жизнь намного богаче.
Мы не можем раскрывать детали реального проекта, но вот ряд сложностей, которые нам пришлось преодолевать:
- Примерно 150 категорий товаров, которые надо находить и классифицировать, а также размечать,
- Практически каждая из этих категорий имеет по 3-7 стилей оформления,
- Зачастую более 100 товаров на одном снимке,
- Иногда невозможно сделать фотографию стеллажа в одну фотографию,
- Плохое освещение и игра продавцов с подсветкой (неон),
- Товар за стеклом (блики, отражение фотографа),
- Фотографии под большим углом, когда фотографу не хватает места сделать фотографию «анфас»,
- Наложение товаров, а также ситуации, когда товар стоит впритык (SSD не справляется),
- Товары на нижних полках сильно искажены, плохо подсвечены,
- Нестандартные стеллажи.
Всё это кардинально меняет и усложняет процесс подготовки данных, тренировки и архитектуру применяемых нейронных сетей, но нас не остановит.

