Всем привет! Слышали ли вы что-нибудь о феномене Баадера-Майнхофа? Это забавное когнитивное искажение, наблюдать которое, как оказалось, довольно интересно на собственном примере. В 2016 году на Хабре вышла обзорная статья про технологию Delphix. Как любая хорошая теория, которую ты потребляешь ежедневно тоннами, чтобы быть в курсе, ты начисто забываешь процентов 80, не применяя ее на практике. Так случилось и со мной – я довольно быстро забыл про тот пост и Delphix, пока где-то год назад по долгу службы не столкнулся с авторами продукта и с самим продуктом. Получив возможность изучить тему не в теории, а на практике, ЛАНИТ погрузился в данную технологию настолько глубоко, что в этой статье я бы хотел систематизировать полученные знания и проанализировать полученный опыт.
 Картинка любезно предоставлена поисковой выдачей Яндекса.
Картинка любезно предоставлена поисковой выдачей Яндекса.
Delphix – это ПО, работающее на виртуальной машине с ОС Solaris, к которой для полноценной работы нужно подключить СХД для хранения копий БД. Поставляется ПО в виде готового образа виртуальной машины (virtual appliance). Образ можно развернуть на VmWare, либо в облачной инфраструктуре AWS/Azure. Для тестов, в принципе, можно поднять и у себя локально на рабочей станции.
Если очень сильно обобщать и очень кратко излагать, Delphix виртуализирует данные и предоставляет готовые базы данных, с которыми можно работать. Он снимает копию с базы данных — источника (называется dSource) и складывает ее у себя в сторадже (локальный раздел ВМ, который подключен к внешней СХД). С помощью алгоритмов снижает объем этой копии до 60% (в зависимости от типов данных, само собой). Затем из этой же копии за несколько минут можно развертывать эту базу данных на других хостах. Такие БД называются Virtual Database – VDB. Файлы базы данных монтируются к целевым хостам по NFS, поэтому и не занимают на них место. Т. е., имея 1 dSource на 500 ГБ и 5 VDB, суммарное занимаемое место под это дело на СХД будет около 350 ГБ (или около того).
После того, как проходит шаг инициализации и начальной загрузки БД-источника в Delphix, движок Delphix поддерживает постоянную синхронизацию с этой БД на основе выбранной вами политики, например, синхронизация ежедневно или каждый час, или через некоторое время после транзакций.
Скорость создания первой копии БД напрямую зависит от пропускной способности сети между БД-источником и Delphix, так как бэкап передается по сети.
После привязки к БД-источнику Delphix поддерживает так называемый TimeFlow (машина времени) БД-источника – функциональность, похожую на управление версиями. Любую версию БД внутри этого временного интервала можно подключить к target-БД. Зачем? Например, для исследования инцидентов.
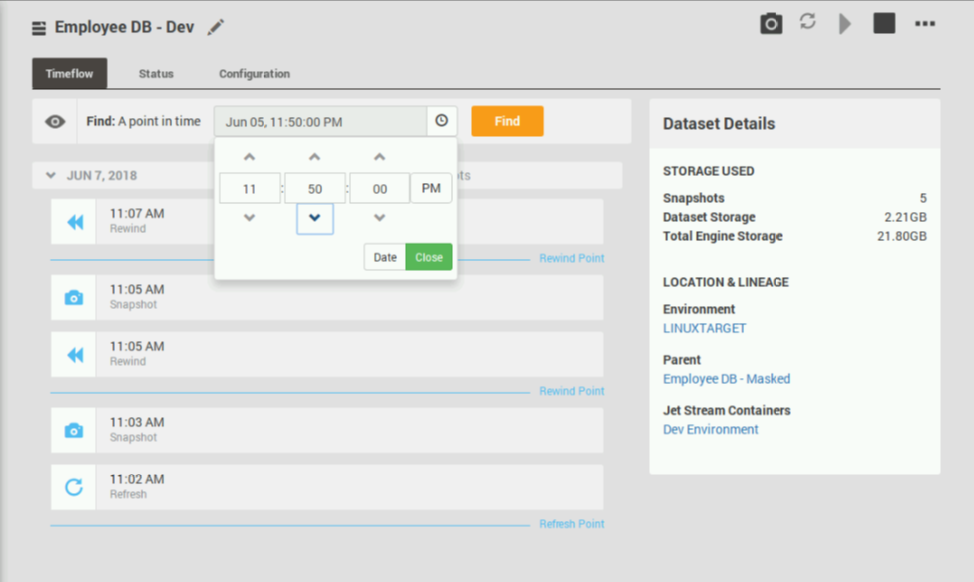 Рисунок 1: Возможность развернуть VDB на любой момент времени...
Рисунок 1: Возможность развернуть VDB на любой момент времени...
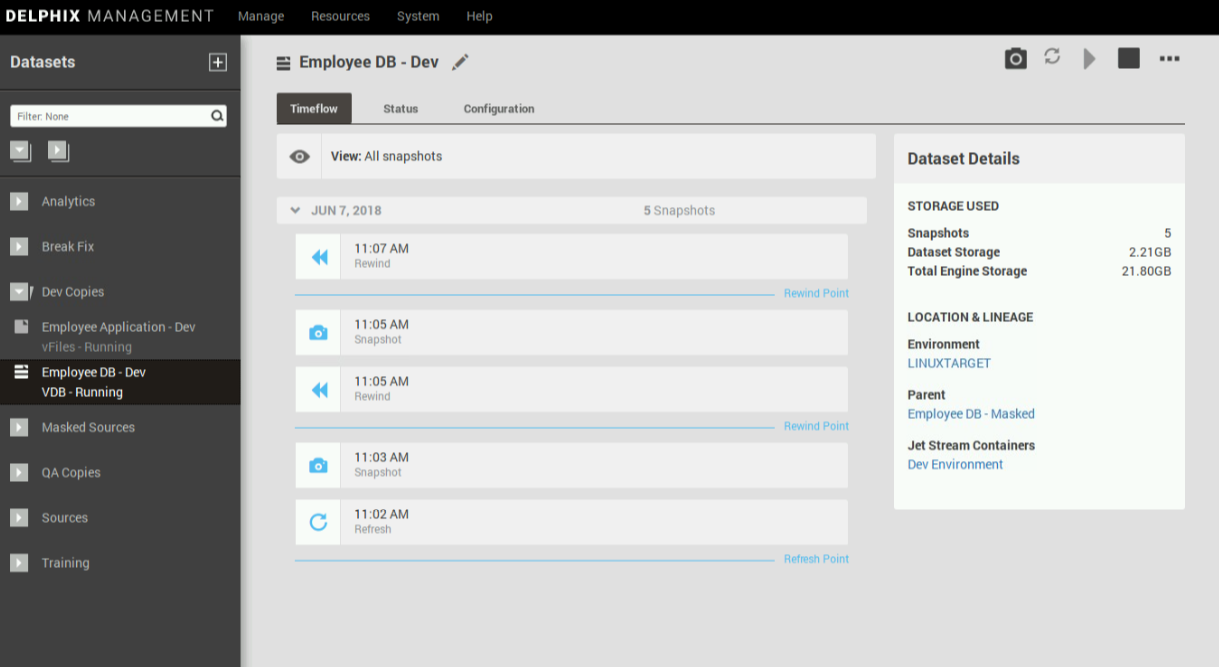 Рисунок 2:… либо на вручную созданный снапшот БД
Рисунок 2:… либо на вручную созданный снапшот БД
VDB находятся на общем сторадже, поэтому ни пользователям, ни админам не требуется дополнительных ресурсов СХД.
Можно быстро подключать любую версию этой VDB к целевой БД. VDB не зависят друг от друга и находятся в режиме Read-Write. Новые изменения, которые вносятся в VDB записываются в новые блоки на сторадже Delphix.
Можно создавать VDB на основе другой VDB и обновлять ее или откатывать по мере необходимости.
С такими VDB можно работать, “как с обычной БД”. Приложение ничего не заметит. Понятное дело, что бинарники СУБД уже должны быть установлены на этих серверах, так как клонируются только сами файлы БД.
Такие VDB используются в основном для функционального тестирования либо в качестве песочниц. Гонять нагрузку на VDB в большинстве случаев не стоит, так как из-за подключения БД по NFS интерпретировать результаты такого нагрузочного тестирования будет достаточно проблематично. Хотя если у вас БД в проме работает с СХД через NFS, тогда, наверное, можно.
Гарантированно можно рассчитывать на стабильную работу, если используется Oracle (в т.ч. с поддержкой multitenant и RAC), MS SQL, SAP ASE, IBM DB2, Oracle EBS, SAP HANA. Такие конфигурации поддерживаются вендором.
Помимо этого можно виртуализировать и обычные файлы (считай, любую БД, но с некоторыми ограничениями по функциональности). Например, в качестве proof-of-concept для внутренних тестов мы виртуализировали экземпляры PostgreSQL одного из наших проектов. Не скажу, что получилось на раз-два, но в итоге схема с PostgreSQL заработала, даже не смотря на то, что вендор в настоящее время официально PostgreSQL не поддерживает.
Само собой, что у СХД функционал снапшотов и thin-provision есть давно. Однако, если продуктивная БД и стенды находятся на СХД разных вендоров, то такое решение не подойдет. Да и не все СХД это умеют.
С помощью Delphix можно довольно успешно развертывать тестовые среды на технологически устаревших и отслуживших свой срок СХД, выведенных из промышленной эксплуатации. В итоге существенно снижаем стоимость хранения тестовых данных.
Также имеется возможность получить физическую копию базы данных из этого снапшота, например, для создания стендбая или для переноса БД на другую СХД.
Немаловажная составляющая – это self-service. С помощью GUI продукта Delphix JetStream даже неподготовленные разработчики/тестировщики самостоятельно могут откатывать/обновлять версии БД своих стендов, не дергать админов по несколько раз за неделю.
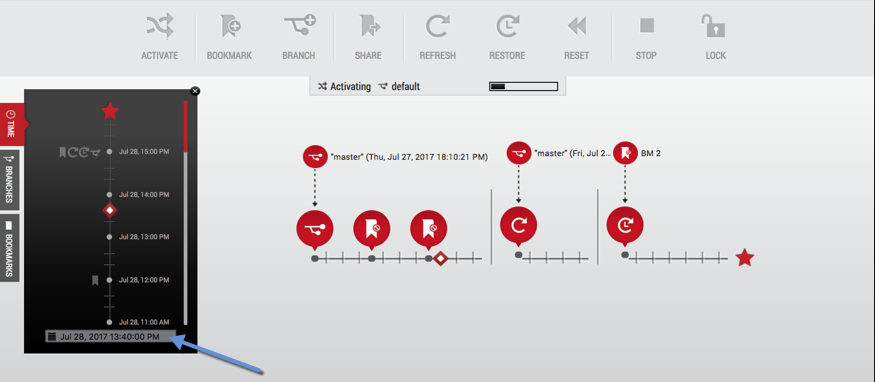 Рисунок 3. Использование JetStream на рисунке обозначено время жизни бранча главной версии VDB, создание снапшотов версии и пара откатов к этим снапшотам.
Рисунок 3. Использование JetStream на рисунке обозначено время жизни бранча главной версии VDB, создание снапшотов версии и пара откатов к этим снапшотам.
Delphix поддерживает постоянную синхронизацию VDB с продуктивной БД с помощью архивных/транзакционных лог-файлов. Для схожей реализации на основе СХД придется делать по… дцать снапшотов в день.
Да, умеет, но поддерживается в нем только СУБД Oracle. Поэтому для остальных СУБД его применять нельзя.
Сперва разберемся, кому и за счет чего Delphix может быть выгодным. Профит заключается в следующем:
Теперь кратко по каждому пункту.
Сокращение временных затрат на согласование под новые стенды. Да, в некоторых компаниях, с которыми мы работали, согласование развертывания нового стенда занимало две недели. А если необходимого количества ресурсов нет или организация попадается очень солидная и сильно бюрократизированная, то, скажем аккуратно, сроки называются “от месяца”.
Сокращение используемого места на СХД под тестовые стенды. По данным железячных вендоров, стоимость обслуживания 1 ТБ данных на СХД составляет от 800 евро в год. Цифры приблизительные, но порядок такой. При наличии продуктивной БД размером в 2 ТБ и 3 тестовых стендов с VDB — суммарный занимаемый делфиксом объем будет около 2 ТБ. Такие показатели достигаются за счет того, что для всех тестовых баз данных требуется только один общий сторадж, который, в общем случае, будет занимать не намного больше продуктивной БД. Конечно же, все зависит от количества изменений, которые вносятся на тестовые БД. Больше изменений – сильнее будет “разбухать” сторадж за счет хранения дельт. Чтобы это представить, можете представить схему со снимками виртуальных машин.
Суммарное количество возможных подключенных БД (включая БД – источник и тестовые БД) к одному экземпляру Delphix – около 300.
Сокращение времени на деплой базы на стенд. Вместо многочасовой рутинной операции по накатыванию бэкапа определенной версии на стенд требуется нажать 3 кнопки. Для тех, кто, привык работать в консоли или использовать мощный API, есть и CLI, и API соответственно.
Сокращение времени на обновлении БД на стендах. Движок Delphix поддерживает постоянную синхронизацию с БД-источником (с помощью архив-логов/транзакционных логов БД), и все изменения с этой БД можно распространять на подключенные VDB.
В файловой системе Delphix располагаются блоки данных (самый нижний уровень на картинке). Delphix создает индексы B-tree, которые указывают на эти блоки данных. Причем корневой блок индекса (самый верхний) является определяющим. Так выглядит состояние системы на момент времени t0.

Теперь представим, что пришли измененные блоки данных b’ и c’, и система перешла в состояние t1.
Delphix не перетирает старые блоки данных, а создает новые блоки рядом. Для того, чтобы обращаться к ним, создается новый корневой блок индекса, указывающий на новые блоки данных.

Благодаря индексам, система имеет две версии, с каждой из которых можно работать, подключившись к соответствующему корневому блоку индекса t0 или t1.
Например, при подключении к блоку индекса t1 система будет выглядеть так:

Когда Delphix снимает бэкап с БД-источника, то создает внутри себя такие индексы. Он автоматически применяет инкрементальные бэкапы к первоначальному, но не перетирает блоки, а записывает их рядом и создает новые корневые блоки индекса.
Поэтому всегда возможно получить снимок БД на определенный момент времени и развернуть из него VDB.
На ютубе есть видео, с объяснением Джонатана Льюиса (высококлассного специалиста по оптимизации / оптимизатору и вопросам производительности Oracle, автора хорошей книжки Cost-Based Oracle Fundamentals и еще множества полезных книг).
При достаточном количестве людей, времени, денег и терпения можно что угодно написать скриптами. Однако от сложности такого решения прямо пропорционально будет зависеть стоимость его поддержки и множество других нюансов. Одна компания, с которой мы работаем и дружим, взвесила все за и против, оценила силы своего ИТ-департамента и приняла решение писать аналог Delphix самостоятельно на скриптах и ZFS. Вполне себе вариант, если у вам нужно специализированное решение под одну систему, вы уверены в своих силах. Да, что уж там, мы и сами любим писать скрипты…
К основной функциональности Delphix можно добавить дополнительный инструмент маскирования данных. Он позволит шифровать личные данные, например, номера кредиток, имена, фамилии и т.д. Очень востребованная функция у банков и тех, кто выполняет все требования по 149-ФЗ и 152-ФЗ.
Обычно разработчикам требуются данные из продуктивной БД, когда происходит:
Давать возможность подключения кому бы то ни было к промышленным БД напрямую не есть хорошо, но работу как-то работать надо и надо как-то обеспечить возможность работы всем, кому это необходимо с промышленной структурой данных и с промышленным объемом данных. Что еще более важно – с промышленным “профилем” данных. Учитывая, что продуктивные данные зачастую содержат конфиденциальную информацию, в том числе персональные данные, перелить их в тестовую зону или отдать разработчикам – задача обычно невозможная.
Об этом можно написать отдельную подробную статью, но если кратко, то опция маскирования данных скрывает или изменяет те данные, которые нельзя выносить за пределы контролируемой зоны промышленного контура и позволяет передать за “периметр” уже маскированные данные в среды разработки и тестирования.
Masking Engine (движок маскирования) удаляет или изменяет защищаемую информацию и оставляет аналог данных, тем самым, позволяя разработчикам и тестировщикам работать с аналогичными данными. Маскирование данных реализуется компонентом Delphix Masking Engine.
Безусловно, есть и другие решения, обладающие схожей функциональностью. Например, Oracle Masking, Informatica Masking и т.д. Плюс, как и в случае с самим Delphix, можно свои скрипты маскирования написать. Однако существенный общий недостаток – это необходимость покупки большого количества более дорогих лицензий/дополнительного ПО.
Чтобы не перегружать текст, более подробную иллюстрацию принципов работы функции маскирования оставим на отдельную статью.
Если вы можете привести примеры других, известных вам, инструментов маскирования, которыми вы пользовались на практике и которые решают задачу, было бы здорово увидеть пару слов от вас про них в комментариях.
Можно использовать и самописное, но при этом надо понимать, что с большой степенью вероятности прогон скриптов на тестовой БД в размере, допустим, 5 ТБ, займет очень много времени. А написание алгоритмов и самих скриптов может длиться еще дольше.
Когда надо быстро и гарантированно решить новую задачу и должно работать “как часы”, маскирования “из коробки” у Delphix будет работать. Скрипт, скорее всего, придется “допилить” под новую задачу (структуру данных, тип БД и т.д.).
Внедрение начинается с пилотного проекта. Сначала проводится интервью с заказчиком, и тут для полноценного взаимодействия нам понадобится всего один ответственный инженер (DBA или сисадмин). У нас есть специализированная анкета-опросник, которая помогает выяснить характеристики вычислительной среды заказчика.
Также нам обязательно потребуется информация о системах, которые могут быть кандидатами для виртуализации (либо отдельные БД, либо целые системы SAP / Dynamics). Совместными усилиями мы в режиме диалога определяем критерии тестирования, критерии успешности и сроки пилотного проекта. Далее, пока заказчик готовит инфраструктуру под пилот, мы получаем от вендора тестовую лицензию.
Наши инженеры приезжают на площадку заказчика, настраивают движок и подключают к нему БД-источник. В зависимости от внутренних правил заказчика в части ИБ, того, какой именно источник подключается и наличия своей технической команды, первичное развертывание и настройка может быть выполнена не нами, а собственными силами ИТ-команды заказчика, либо под нашим наблюдением, либо по инструкциям вендора с нашими консультациями.
Дальше, если у заказчика есть желание прокачать свою команду (а обычно такое желание есть), мы проводим обучение администраторов инфраструктуры и DBA. В целях обучения мы совместно с ними разворачиваем одну или несколько виртуальных БД и прогоняем все сценарии.
Обычно пилот длится от 2 до 4 недель, если внутренние процессы заказчика позволяют быстро подготовить нужную инфраструктуру. Как правило, за это время на реальных системах удается опробовать все функциональные возможности ПО и оценить масштабы получаемой выгоды.
По результатам тестирования составляется отчет, в котором анализируются все пилотные процессы, приводятся цифры «было-стало» и выдается заключение о целесообразности более долгосрочных отношений. В случае принятия руководством положительного решения процесс «перехода на промышленные рельсы» — дело нескольких часов, т.к. в процессе пилотирования основные трудности обычно преодолеваются, а «окупаемость», и «эффект от реализации проекта» начинаются буквально на следующий день.
Прямо скажем, продукт не дешевый. На торрентах скачать его не получится и, чтобы использовать решение, придется платить ежегодную плату вендору. Схема лицензирования – за объем виртуализированных данных.
Максимальная выгода от использования Delphix достигается тогда, когда вам нужно создавать большое количество копий больших объемов разных БД-источников (количество БД-источников >= 1), например, для создания кучи типовых стендов для аналитиков, службы тестирования, службы сопровождения для воспроизведения дефектов с продакшена и т.д., где нужны копии либо боевой базы с маскированными данными, либо копии очень большой тестовой базы, причем быстро и на относительно короткий период времени (создали клон, решили задачу, убили клон, сделали свежий и т.д.).
Если это ваш кейс, то считайте TCO (можем помочь сделать это правильно) и решайте, подходит он вам или нет. В остальном это действительно очень интересный коробочный (это важно!) инструмент, решающий вполне понятные с технической точки зрения задачи.
В качестве заключения мы бы хотели провести небольшой опрос, чтобы понять, насколько данный инструмент может быть полезен именно вам.
Что такое Delphix?
Delphix – это ПО, работающее на виртуальной машине с ОС Solaris, к которой для полноценной работы нужно подключить СХД для хранения копий БД. Поставляется ПО в виде готового образа виртуальной машины (virtual appliance). Образ можно развернуть на VmWare, либо в облачной инфраструктуре AWS/Azure. Для тестов, в принципе, можно поднять и у себя локально на рабочей станции.
Если очень сильно обобщать и очень кратко излагать, Delphix виртуализирует данные и предоставляет готовые базы данных, с которыми можно работать. Он снимает копию с базы данных — источника (называется dSource) и складывает ее у себя в сторадже (локальный раздел ВМ, который подключен к внешней СХД). С помощью алгоритмов снижает объем этой копии до 60% (в зависимости от типов данных, само собой). Затем из этой же копии за несколько минут можно развертывать эту базу данных на других хостах. Такие БД называются Virtual Database – VDB. Файлы базы данных монтируются к целевым хостам по NFS, поэтому и не занимают на них место. Т. е., имея 1 dSource на 500 ГБ и 5 VDB, суммарное занимаемое место под это дело на СХД будет около 350 ГБ (или около того).
Этот процесс создания копий однократный?
После того, как проходит шаг инициализации и начальной загрузки БД-источника в Delphix, движок Delphix поддерживает постоянную синхронизацию с этой БД на основе выбранной вами политики, например, синхронизация ежедневно или каждый час, или через некоторое время после транзакций.
Скорость создания первой копии БД напрямую зависит от пропускной способности сети между БД-источником и Delphix, так как бэкап передается по сети.
После привязки к БД-источнику Delphix поддерживает так называемый TimeFlow (машина времени) БД-источника – функциональность, похожую на управление версиями. Любую версию БД внутри этого временного интервала можно подключить к target-БД. Зачем? Например, для исследования инцидентов.
VDB находятся на общем сторадже, поэтому ни пользователям, ни админам не требуется дополнительных ресурсов СХД.
Можно быстро подключать любую версию этой VDB к целевой БД. VDB не зависят друг от друга и находятся в режиме Read-Write. Новые изменения, которые вносятся в VDB записываются в новые блоки на сторадже Delphix.
Можно создавать VDB на основе другой VDB и обновлять ее или откатывать по мере необходимости.
Как на это отреагирует приложение?
С такими VDB можно работать, “как с обычной БД”. Приложение ничего не заметит. Понятное дело, что бинарники СУБД уже должны быть установлены на этих серверах, так как клонируются только сами файлы БД.
Такие VDB используются в основном для функционального тестирования либо в качестве песочниц. Гонять нагрузку на VDB в большинстве случаев не стоит, так как из-за подключения БД по NFS интерпретировать результаты такого нагрузочного тестирования будет достаточно проблематично. Хотя если у вас БД в проме работает с СХД через NFS, тогда, наверное, можно.
Гарантированно можно рассчитывать на стабильную работу, если используется Oracle (в т.ч. с поддержкой multitenant и RAC), MS SQL, SAP ASE, IBM DB2, Oracle EBS, SAP HANA. Такие конфигурации поддерживаются вендором.
Помимо этого можно виртуализировать и обычные файлы (считай, любую БД, но с некоторыми ограничениями по функциональности). Например, в качестве proof-of-concept для внутренних тестов мы виртуализировали экземпляры PostgreSQL одного из наших проектов. Не скажу, что получилось на раз-два, но в итоге схема с PostgreSQL заработала, даже не смотря на то, что вендор в настоящее время официально PostgreSQL не поддерживает.
Зачем это нужно, если в СХД встроен схожий функционал?
Само собой, что у СХД функционал снапшотов и thin-provision есть давно. Однако, если продуктивная БД и стенды находятся на СХД разных вендоров, то такое решение не подойдет. Да и не все СХД это умеют.
С помощью Delphix можно довольно успешно развертывать тестовые среды на технологически устаревших и отслуживших свой срок СХД, выведенных из промышленной эксплуатации. В итоге существенно снижаем стоимость хранения тестовых данных.
Также имеется возможность получить физическую копию базы данных из этого снапшота, например, для создания стендбая или для переноса БД на другую СХД.
Немаловажная составляющая – это self-service. С помощью GUI продукта Delphix JetStream даже неподготовленные разработчики/тестировщики самостоятельно могут откатывать/обновлять версии БД своих стендов, не дергать админов по несколько раз за неделю.
Delphix поддерживает постоянную синхронизацию VDB с продуктивной БД с помощью архивных/транзакционных лог-файлов. Для схожей реализации на основе СХД придется делать по… дцать снапшотов в день.
Вроде Oracle Enterprise Manager тоже умеет клонировать базы
Да, умеет, но поддерживается в нем только СУБД Oracle. Поэтому для остальных СУБД его применять нельзя.
Ключевой вопрос — почему он приносит профит?
Сперва разберемся, кому и за счет чего Delphix может быть выгодным. Профит заключается в следующем:
- сокращение временных затрат на согласование под новые стенды,
- сокращение используемого места на СХД под тестовые стенды,
- возможность использовать неспециализированные СХД от разных вендоров,
- сокращение времени на деплой базы на стенд,
- сокращение времени на обновлении БД на стендах.
Теперь кратко по каждому пункту.
Сокращение временных затрат на согласование под новые стенды. Да, в некоторых компаниях, с которыми мы работали, согласование развертывания нового стенда занимало две недели. А если необходимого количества ресурсов нет или организация попадается очень солидная и сильно бюрократизированная, то, скажем аккуратно, сроки называются “от месяца”.
Сокращение используемого места на СХД под тестовые стенды. По данным железячных вендоров, стоимость обслуживания 1 ТБ данных на СХД составляет от 800 евро в год. Цифры приблизительные, но порядок такой. При наличии продуктивной БД размером в 2 ТБ и 3 тестовых стендов с VDB — суммарный занимаемый делфиксом объем будет около 2 ТБ. Такие показатели достигаются за счет того, что для всех тестовых баз данных требуется только один общий сторадж, который, в общем случае, будет занимать не намного больше продуктивной БД. Конечно же, все зависит от количества изменений, которые вносятся на тестовые БД. Больше изменений – сильнее будет “разбухать” сторадж за счет хранения дельт. Чтобы это представить, можете представить схему со снимками виртуальных машин.
Суммарное количество возможных подключенных БД (включая БД – источник и тестовые БД) к одному экземпляру Delphix – около 300.
Сокращение времени на деплой базы на стенд. Вместо многочасовой рутинной операции по накатыванию бэкапа определенной версии на стенд требуется нажать 3 кнопки. Для тех, кто, привык работать в консоли или использовать мощный API, есть и CLI, и API соответственно.
Сокращение времени на обновлении БД на стендах. Движок Delphix поддерживает постоянную синхронизацию с БД-источником (с помощью архив-логов/транзакционных логов БД), и все изменения с этой БД можно распространять на подключенные VDB.
Как это технически реализовано?
В файловой системе Delphix располагаются блоки данных (самый нижний уровень на картинке). Delphix создает индексы B-tree, которые указывают на эти блоки данных. Причем корневой блок индекса (самый верхний) является определяющим. Так выглядит состояние системы на момент времени t0.
Теперь представим, что пришли измененные блоки данных b’ и c’, и система перешла в состояние t1.
Delphix не перетирает старые блоки данных, а создает новые блоки рядом. Для того, чтобы обращаться к ним, создается новый корневой блок индекса, указывающий на новые блоки данных.
Благодаря индексам, система имеет две версии, с каждой из которых можно работать, подключившись к соответствующему корневому блоку индекса t0 или t1.
Например, при подключении к блоку индекса t1 система будет выглядеть так:
Когда Delphix снимает бэкап с БД-источника, то создает внутри себя такие индексы. Он автоматически применяет инкрементальные бэкапы к первоначальному, но не перетирает блоки, а записывает их рядом и создает новые корневые блоки индекса.
Поэтому всегда возможно получить снимок БД на определенный момент времени и развернуть из него VDB.
На ютубе есть видео, с объяснением Джонатана Льюиса (высококлассного специалиста по оптимизации / оптимизатору и вопросам производительности Oracle, автора хорошей книжки Cost-Based Oracle Fundamentals и еще множества полезных книг).
Насколько он удобнее кастомного решения (скрипты, например)?
При достаточном количестве людей, времени, денег и терпения можно что угодно написать скриптами. Однако от сложности такого решения прямо пропорционально будет зависеть стоимость его поддержки и множество других нюансов. Одна компания, с которой мы работаем и дружим, взвесила все за и против, оценила силы своего ИТ-департамента и приняла решение писать аналог Delphix самостоятельно на скриптах и ZFS. Вполне себе вариант, если у вам нужно специализированное решение под одну систему, вы уверены в своих силах. Да, что уж там, мы и сами любим писать скрипты…
Где-то выше упоминалось про маскирование, что это?
К основной функциональности Delphix можно добавить дополнительный инструмент маскирования данных. Он позволит шифровать личные данные, например, номера кредиток, имена, фамилии и т.д. Очень востребованная функция у банков и тех, кто выполняет все требования по 149-ФЗ и 152-ФЗ.
Обычно разработчикам требуются данные из продуктивной БД, когда происходит:
- разработка нового приложения,
- поддержка или доработка приложения,
- тестирование функционала на тестовых стендах.
Давать возможность подключения кому бы то ни было к промышленным БД напрямую не есть хорошо, но работу как-то работать надо и надо как-то обеспечить возможность работы всем, кому это необходимо с промышленной структурой данных и с промышленным объемом данных. Что еще более важно – с промышленным “профилем” данных. Учитывая, что продуктивные данные зачастую содержат конфиденциальную информацию, в том числе персональные данные, перелить их в тестовую зону или отдать разработчикам – задача обычно невозможная.
Об этом можно написать отдельную подробную статью, но если кратко, то опция маскирования данных скрывает или изменяет те данные, которые нельзя выносить за пределы контролируемой зоны промышленного контура и позволяет передать за “периметр” уже маскированные данные в среды разработки и тестирования.
Masking Engine (движок маскирования) удаляет или изменяет защищаемую информацию и оставляет аналог данных, тем самым, позволяя разработчикам и тестировщикам работать с аналогичными данными. Маскирование данных реализуется компонентом Delphix Masking Engine.
Почему бы не использовать в качестве маскирования IBM Optim/Oracle Masking/аналоги?
Безусловно, есть и другие решения, обладающие схожей функциональностью. Например, Oracle Masking, Informatica Masking и т.д. Плюс, как и в случае с самим Delphix, можно свои скрипты маскирования написать. Однако существенный общий недостаток – это необходимость покупки большого количества более дорогих лицензий/дополнительного ПО.
- У Oracle — это лицензирование каждого сервера с маскингом (это лицензия самого Masking и Database Gateway для non-Oracle БД).
- У Informatica — это PowerCenter ETL, Designer и Lifecycle Management. А если захотите прикрутить ее к SAP, то за это придется еще заплатить.
- Скрипты – со скриптами все зависит от вашей веры в себя и доверия к вам вашего руководства.
Чтобы не перегружать текст, более подробную иллюстрацию принципов работы функции маскирования оставим на отдельную статью.
Если вы можете привести примеры других, известных вам, инструментов маскирования, которыми вы пользовались на практике и которые решают задачу, было бы здорово увидеть пару слов от вас про них в комментариях.
Я хочу все-таки написать свой скрипт маскирования...
Можно использовать и самописное, но при этом надо понимать, что с большой степенью вероятности прогон скриптов на тестовой БД в размере, допустим, 5 ТБ, займет очень много времени. А написание алгоритмов и самих скриптов может длиться еще дольше.
Когда надо быстро и гарантированно решить новую задачу и должно работать “как часы”, маскирования “из коробки” у Delphix будет работать. Скрипт, скорее всего, придется “допилить” под новую задачу (структуру данных, тип БД и т.д.).
Что умеет Delphix Masking Engine “из коробки”
- Secure Lookup – замещает исходные данные, например, “Вася” -> “Петя”. В этом алгоритме возможно появление коллизий, когда замещенные данные получатся одинаковыми.
- Segmented mapping – делит значение на несколько сегментов и замещает эти сегменты по отдельности. Например, номер NM831026-04 можно разделить на три части, из которых буквы NM — не маскировать, значение после трансформации — NM390572-50. Это актуально для маскирования значений колонок, используемых в качестве первичного ключа или для уникальных колонок.
- Mapping Algorithm – для его работы необходимо указать точное соответствие оригинальных и заменяемых значений. В этом случае коллизий не будет, т.к. оригинальное значение напрямую заменяется определенным. В качестве примера, имя “Алексей” всегда будет заменяться на “Никита”.
- Binary Lookup algorithm – заменяет clob/blob значение в колонках и т.д. Delphix не умеет сам заменять значение в картинках/текстах, но вместо этого можно выбрать замещающую картинку или текст.
- Tokenization Algorithm – это вид шифрования данных, при котором входные данные преобразуются в токены, имеющие похожие атрибуты (длина строки, цифровое или текстовое значение), однако они не несут в себе никакого смыслового значения. С помощью алгоритмов можно зашифровать/расшифровать эти данные. Например, можно замаскировать данные и направить вендору продукта. Он их проанализирует и пометит те данные, которые неправильные (например, неверное заполнение), а затем отправит назад.
- Min Max Algorithm – алгоритм, который усредняет все значения в колонке, чтобы скрыть максимальные и минимальные значения (допустим, зарплаты).
- Data Cleansing Algorithm – не маскирует, а стандартизирует данные. Например, можно задать правила, по которым значения Ru, Rus, R преобразуются к единому формату RU.
ОК. Я уже понял, что нам нужен Delphix. Долго внедрять? Как выглядит процесс?
Внедрение начинается с пилотного проекта. Сначала проводится интервью с заказчиком, и тут для полноценного взаимодействия нам понадобится всего один ответственный инженер (DBA или сисадмин). У нас есть специализированная анкета-опросник, которая помогает выяснить характеристики вычислительной среды заказчика.
Также нам обязательно потребуется информация о системах, которые могут быть кандидатами для виртуализации (либо отдельные БД, либо целые системы SAP / Dynamics). Совместными усилиями мы в режиме диалога определяем критерии тестирования, критерии успешности и сроки пилотного проекта. Далее, пока заказчик готовит инфраструктуру под пилот, мы получаем от вендора тестовую лицензию.
Наши инженеры приезжают на площадку заказчика, настраивают движок и подключают к нему БД-источник. В зависимости от внутренних правил заказчика в части ИБ, того, какой именно источник подключается и наличия своей технической команды, первичное развертывание и настройка может быть выполнена не нами, а собственными силами ИТ-команды заказчика, либо под нашим наблюдением, либо по инструкциям вендора с нашими консультациями.
Дальше, если у заказчика есть желание прокачать свою команду (а обычно такое желание есть), мы проводим обучение администраторов инфраструктуры и DBA. В целях обучения мы совместно с ними разворачиваем одну или несколько виртуальных БД и прогоняем все сценарии.
Обычно пилот длится от 2 до 4 недель, если внутренние процессы заказчика позволяют быстро подготовить нужную инфраструктуру. Как правило, за это время на реальных системах удается опробовать все функциональные возможности ПО и оценить масштабы получаемой выгоды.
По результатам тестирования составляется отчет, в котором анализируются все пилотные процессы, приводятся цифры «было-стало» и выдается заключение о целесообразности более долгосрочных отношений. В случае принятия руководством положительного решения процесс «перехода на промышленные рельсы» — дело нескольких часов, т.к. в процессе пилотирования основные трудности обычно преодолеваются, а «окупаемость», и «эффект от реализации проекта» начинаются буквально на следующий день.
Есть ли отрицательные моменты? Что не нравится?
Прямо скажем, продукт не дешевый. На торрентах скачать его не получится и, чтобы использовать решение, придется платить ежегодную плату вендору. Схема лицензирования – за объем виртуализированных данных.
Максимальная выгода от использования Delphix достигается тогда, когда вам нужно создавать большое количество копий больших объемов разных БД-источников (количество БД-источников >= 1), например, для создания кучи типовых стендов для аналитиков, службы тестирования, службы сопровождения для воспроизведения дефектов с продакшена и т.д., где нужны копии либо боевой базы с маскированными данными, либо копии очень большой тестовой базы, причем быстро и на относительно короткий период времени (создали клон, решили задачу, убили клон, сделали свежий и т.д.).
Если это ваш кейс, то считайте TCO (можем помочь сделать это правильно) и решайте, подходит он вам или нет. В остальном это действительно очень интересный коробочный (это важно!) инструмент, решающий вполне понятные с технической точки зрения задачи.
А ещё у нас есть вакансии.
В качестве заключения мы бы хотели провести небольшой опрос, чтобы понять, насколько данный инструмент может быть полезен именно вам.
Только зарегистрированные пользователи могут участвовать в опросе. Войдите, пожалуйста.
1) Сколько времени в вашей компании обычно занимает процесс создания тестовых БД (Возникновение потребности -> согласование -> подготовка ресурсов -> установка ПО и патчей -> БД доступна)?
52.94%Своя инфраструктура, успеваем в течение дня.9
11.76%Своя инфраструктура, бывает, ждем целую неделю.2
17.65%Своя инфраструктура, меньше недели ни разу не было, обычно дольше.3
5.88%Своей инфраструктуры нет, мы в облаке (AWS и т.п.), а там все делается в два клика.1
11.76%У нас нет тестовых сред, мы сразу в продакшн.2
Проголосовали 17 пользователей. Воздержались 10 пользователей.
Только зарегистрированные пользователи могут участвовать в опросе. Войдите, пожалуйста.
2) Сколько полных копий промышленных БД в ваших тестовых средах?
35.29%1-3 (большие, но по пять ©)6
29.41%4-9 (средние)5
11.76%10 и более (маленькие, но по три ©)2
23.53%Сложно посчитать то, чего нет.4
Проголосовали 17 пользователей. Воздержались 10 пользователей.
Только зарегистрированные пользователи могут участвовать в опросе. Войдите, пожалуйста.
3) Как часто вы обновляете свои тестовые среды (копии тестовых сред)?
33.33%Каждый день (несколько раз в день)6
5.56%Каждые 1-2 недели1
22.22%Каждые 3-4 недели4
22.22%Реже 1 раза в месяц4
16.67%Чтобы обновить что-нибудь ненужное, нужно сначала сделать что-нибудь ненужное, а у нас времени нет…3
Проголосовали 18 пользователей. Воздержались 7 пользователей.
Только зарегистрированные пользователи могут участвовать в опросе. Войдите, пожалуйста.
4) Если вышеописанные процессы в вашей компании “завтра” получится ускорить в несколько раз:
68.75%С точки зрения бизнеса ничего не изменится11
18.75%Бизнес начнет экономить денежные и человеческие ресурсы3
6.25%Перед нами стояли описанные задачи, но мы уже ускорились (у нас уже есть Delphix или аналоги, включая свои скрипты)1
6.25%Не верится, что это можно так ускорить, т.к. иначе бы ��се уже давно у себя все ускорили.1
Проголосовали 16 пользователей. Воздержались 9 пользователей.

