
Привет! Меня зовут Денис Кирьянов, я работаю в Сбербанке и занимаюсь проблемами обработки естественного языка (NLP). Однажды нам понадобилось выбрать синтаксический парсер для работы с русским языком. Для этого мы углубились в дебри морфологии и токенизации, протестировали разные варианты и оценили их применение. Делимся опытом в этом посте.

Начнём с основ: как все работает? Мы берем текст, проводим токенизацию и получаем некоторый массив псевдослов-токенов. Этапы дальнейшего анализа укладываются в пирамиду:
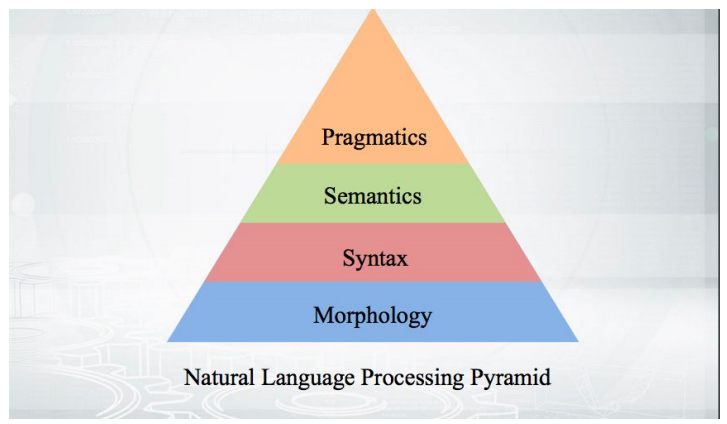
Начинается все с морфологии — с анализа формы слова и его грамматических категорий (род, падеж и т.п.). На морфологии базируется синтаксис — взаимоотношения за рамками одного слова, между словами. Синтаксические парсеры, о которых пойдет речь, анализируют текст и выдают структуру зависимостей слов друг от друга.
Есть два основных подхода к синтаксическому анализу, которые в лингвистической теории существуют примерно на равных.

В первой строке предложение разобрано в рамках грамматики зависимостей. Этому подходу учат в школе. Каждое слово в предложении как-то связ��но с другими. «Мыла» — сказуемое, от которого зависит подлежащее «мама» (здесь грамматика зависимостей расходится со школьной, где сказуемое зависит от подлежащего). У подлежащего есть зависимое определение «моя». У сказуемого есть зависимое прямое дополнение «раму». А у прямого дополнения «раму» — определение «грязную».
Во второй строке разбор идет в соответствии с грамматикой непосредственно составляющих.
Согласно ей, предложение делится на группы слов (phrases). Слова внутри одной группы связаны теснее. Слова «моя» и «мама» связаны более тесно, «раму» и «грязную» — тоже. И есть еще отдельное «мыла».
Второй подход для автоматического парсинга русского языка применим плохо, потому что в нем тесно связанные слова (члены одной группы) очень часто не стоят подряд. Нам пришлось бы объединять их странными скобками — через одно или два слова. Поэтому в автоматическом парсинге русского языка принято работать исходя из грамматики зависимостей. Это удобно еще и потому, что с таким «фреймворком» все знакомы по школе.
Набор зависимостей мы можем перевести в древовидную структуру. Вершина — слово «мыла», некоторые слова напрямую зависят от него, некоторые зависят от его зависимых. Вот определение дерева зависимостей из учебника Мартина и Журафского:
Dependency tree is a directed graph that satisfies the following constraints:
Есть верхнеуровневый узел — сказуемое. Из него можно дойти до любого слова. Каждое слово зависит от другого, но только от одного. Дерево зависимостей выглядит примерно так:
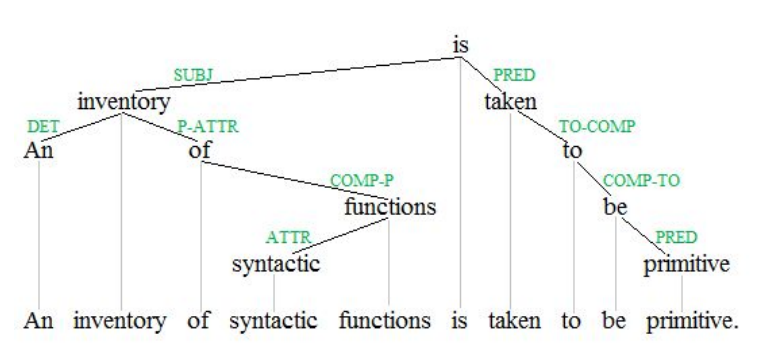
В этом дереве ребра подписаны некоторым особым типом синтаксического отношения. В грамматике зависимостей анализируют не только факт связи между словами, но и характер этой связи. Например, «is taken» — это почти одна глагольная форма, «inventory» — это подлежащее для «is taken». Соответственно, у нас от «is» есть ребро и в одну, и в другую сторону. Это не одинаковые связи, они носят разный характер, так что их надо различать.
Здесь и далее мы рассматриваем простые случаи, где члены предложения присутствуют, а не подразумеваются. Существуют структуры и отметки, позволяющие бороться с пропусками. В дереве появляется нечто, у чего нет поверхностного выражения — слова. Но это уже предмет другого исследования, а нам все-таки надо сосредоточиться на своем.
Чтобы облегчить себе выбор парсера, мы обратили свой взгляд на проект Universal Dependencies и недавно прошедшее в его рамках соревнование CoNLL Shared Task.
Universal Dependencies — это проект по унификации разметки синтаксических корпусов (трибанков) в рамках грамматики зависимостей. В русском языке количество типов синтаксических связей ограничено — подлежащее, сказуемое и т.д. В английском то же самое, но набор уже другой. Например, там появляется артикль, который тоже надо как-то маркиро��ать. Если бы мы хотели написать волшебный парсер, который мог бы обрабатывать все языки, то довольно быстро уперлись бы в проблемы сопоставления разных грамматик. Героическим создателям Universal Dependencies удалось договориться между собой и разметить все корпусы, которые имелись в их распоряжении, в едином формате. Не очень важно, как именно они договорились, главное, что на выходе мы получили некий единообразный формат представления всей этой истории — более 100 трибанков для 60 языков.
CoNLL Shared Task — это соревнование между разработчиками алгоритмов синтаксического парсинга, проводимое в рамках проекта Universal Dependencies. Организаторы берут некоторое количество трибанков и разбивают каждый из них на три части — обучающую, валидационную и тестовую. Первая часть предоставляется участникам соревнования, чтобы они обучили на ней свои модели. Вторая часть тоже используется участниками — чтобы после обучения оценить работу алгоритма. Обучение и оценку участники могут итеративно повторять. Потом они отдают свой лучший алгоритм организаторам, которые прогоняют его на тестовой части, закрытой для участников. Итоги работы моделей на тестовых частях трибанков — это и есть итоги соревнования.
У нас есть связи между словами и их типы. Мы можем оценивать, правильно ли нашли вершину слова — метрика UAS (Unlabeled attachment score). Или оценивать, правильно ли найдена как вершина, так и тип зависимости — метрика LAS (Labeled attachment score).

Казалось бы, здесь напрашивается оценка точности (accuracy) — считаем, сколько раз мы попали из общего количества случаев. Если у нас есть 5 слов и для 4 мы правильно определили вершину, то получаем 80%.
Но на самом деле оценить парсер в чистом виде проблематично. Разработчики, решающие задачи автоматического парсинга, часто берут на вход сырой текст, который в соответствии с пирамидой анализа проходит этапы токенизации и морфологического анализа. На качество работы парсера могут повлиять ошибки с этих более ранних этапов. В частности, это относится к процедуре токенизации — выделения слов. Если мы выделили неправильные слова-юниты, то уже не сможем корректно оценить синтаксические связи между ними — ведь в нашем исходном размеченном корпусе юниты были другие.
Поэтому формулой оценки в данном случае является ф-мера, где точность (precision) — доля точных попаданий относительно общего числа предсказаний, а полнота — доля точных попаданий относительно числа связей в размеченных данных.
Когда мы в дальнейшем будем приводить оценки, нужно помнить, что используемые метрики затрагивают не только синтаксис, но еще и качество разбиения на токены.
Для того, чтобы парсер смог синтаксически размечать предложения, которых он еще не видел, ему для обучения нужно скормить размеченный корпус. Для русского языка есть несколько таких корпусов:

Во втором столбце указано количество токенов — слов. Чем больше токенов, тем больше обучающий корпус и лучше итоговый алгоритм (если это хорошие данные). Очевидно, что все эксперименты проводятся на SynTagRus (разработка ИППИ РАН), в котором более миллиона токенов. На нем будут обучаться все алгоритмы, о которых пойдет речь дальше.
По итогам соревнования прошлого года модели, которые обучались на одном и том же SynTagRus, достигли следующих показателей LAS:

Результаты парсеров для русского впечатляют — они лучше чем у парсеров для английского, французского и других более редких языков. Нам с вами очень повезло сразу по двум причинам. Во-первых, алгоритмы хорошо справляются с русским языком. Во-вторых, у нас есть SynTagRus — большой и размеченный корп��с.
Кстати, уже прошло соревнование 2018 года, но свое исследование мы проводили весной этого года, так что мы опираемся на итоги дорожки прошлого года. Забегая вперед, заметим, что новая версия UDPipe (Future) оказалась еще выше в этом году.
В список не вошел Syntaxnet — парсер Google. Что с ним не так? Ответ прост: Syntaxnet начинался лишь с этапа морфологического анализа. Он брал готовую идеальную токенизацию, а уже поверх строил обработку. Поэтому оценивать его наравне с остальными нечестно — остальные делали разбиение на токены своими алгоритмами, и это могло ухудшить результаты на последующем этапе синтаксиса. У Syntaxnet образца 2017 года результат лучше, чем у всего списка выше, но проводить сравнение напрямую нечестно.
В таблицу попали две версии UDPipe, на 12 и 15 места. Разработкой этого парсера занимаются те же люди, которые принимали активное участие в самом проекте Universal Dependencies.
Периодически появляются обновления UDPipe (несколько реже, кстати, обновляется и разметка корпусов). Так, уже после соревнования прошлого года UDPipe обновлялся (это были коммиты в еще не вышедшую версию 2.0; в дальнейшем для простоты мы будем грубо называть взятый нами коммит UDPipe 2.0, хотя строго говоря это не так); этих обновлений в таблице соревнования, разумеется, нет. Результат «нашего» коммита находится примерно в районе седьмого места.
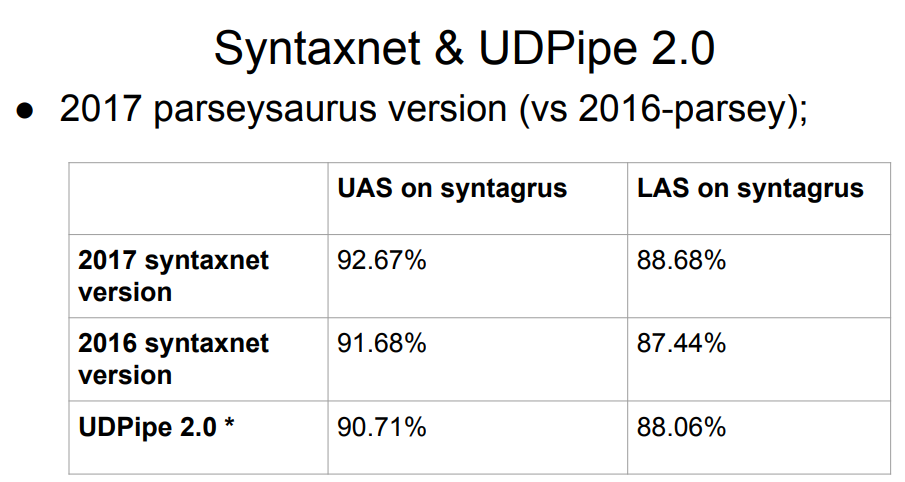
Итак, нам нужно выбрать парсер для русского языка. В качестве начальных данных у нас есть табличка выше с лидирующим Syntaxnet и с UDPipe 2.0 где-то на 7 месте.
Делаем просто: начинаем с парсера с самыми высокими показателями. Если с ним что-то не так, идем ниже. Что-то не так может быть по следующим критериям — может, они не идеальны, но нам подошли:
Все, что в чарте парсеров было выше UDPipe 2.0, нам не подошло. У нас проект на Python, а некоторые парсеры из списка написаны не на Python. Чтобы имплементировать их в питонский проект, пришлось бы применить те самые сверхусилия. В других случаях мы сталкивались с закрытым исходным кодом, академическими, индустриальными разработками — в общем, не докопаешься.
Звездный Syntaxnet заслуживает отдельного рассказа про качество работы. Здесь же он нас не устроил по скорости работы. Время его ответа на какие-то простые, распространенные в чатах фразы составляет от 100 миллисекунд. Если мы столько будем тратить на синтаксис, нам не хватит времени ни на что другое. В то же самое время UDPipe 2.0 делает разбор предложения за ~3ms. В итоге выбор пал на UDPipe 2.0.
UDPipe — пайплайн, который обучается токенизации, лемматизации, морфологическому тэггингу и парсингу, основанному на грамматике зависимостей. Мы можем обучить его всему этому или чему-то отдельно. Например, сделать с ним еще один морфологический анализатор для русского языка. Или обучить и использовать UDPipe в качестве токенизатора.
UDPipe 2.0 подробно задокументирован. Есть описание архитектуры, репозиторий с кодом обучения, мануал. Самое интересное — это готовые модели, в том числе и для русского языка. Качай и запускай. Также на этом ресурсе зарелизены подобранные для каждого языкового корпуса параметры обучения. Для каждой такой модели нужно порядка 60 параметров обучения, и с их помощью можно самостоятельно добиться таких же показат��лей качества, как в таблице. Они могут быть не оптимальны, но по крайней мере мы можем быть уверены, что пайплайн будет работать достаточно корректно. Кроме того, наличие такого референса позволяет нам спокойно поэкспериментировать с моделью самостоятельно.
Сначала текст разделяется на предложения, а предложения — на слова. UDPipe делает все это сразу с помощью совместного модуля — нейронной сети (однослойной двухсторонней GRU), которая для каждого символа предсказывает, последний ли он в предложении или в слове.
Затем начинает работу теггер — штука, которая предсказывает морфологические свойства токена: в каком падеже слово стоит, в каком числе. По последним четырем символам каждого слова теггер генерирует гипотезы относительно части речи и морфологических тегов этого слова, а затем при помощи перцептрона отбирает лучший вариант.
В UDPipe есть еще лемматизатор, который подбирает для слов начальную форму. Он обучается примерно по тому же принципу, по которому не-носитель языка мог бы попытаться определить лемму незнакомого ему слова. Отрезаем приставку и конец слова, добавляем какой-нибудь «ть», который присутствует в начальной форме глагола и т.п. Так генерируются кандидаты, из которых наилучшего выбирает перцептрон.
Схема морфологического тегирования (определение числа, падежа и всего остального) и предсказания лемм очень похожи. Их можно предсказывать вместе, но лучше раздельно — слишком уж богата морфология русского языка. Можно также подключить свой список лемм.
Перейдем к самому интересному — к парсеру. Есть несколько архитектур dependency-парсеров. UDPipe — это transition-based архитектура: она работает быстро, за линейное время проходя по всем токенам один раз.
Синтаксический парсинг в такой архитектуре начинается со стека (где в начале только root) и пустой конфигурации. Есть три дефолтных способа ее изменить:
Ниже приведен пример работы парсера (источник). У нас есть фраза «book me the morning flight», и мы восстанавливаем связи в ней:

Вот что получается в итоге:

У классических transition-based parser возможны три операции, перечисленные выше: стрелка в одну сторону, стрелка в другую сторону и шифт. Есть еще операция Swap, в базовых архитектурах transition-based парсеров она не используется, но в UDPipe включена. Swap возвращает второй элемент стека в буфер, чтобы взять потом из буфера следующий (в случае если они разнесены). Это помогает пропустить некоторое количество слов и восстановить правильную связь.
По ссылке есть хорошая статья человека, который придумал операцию swap. Выделим из нее один момент: несмотря на то, что мы не один раз проходим по исходному буферу токенов (т.е. наше время уже не линейное), эти операции можно оптимизировать так, чтобы вернуть время очень близко к линейному. То есть перед нами не просто осмысленная с точки зрения языка операция, но еще и инструмент, не сильно замедляющий работу парсера.
На примере выше мы показали операции, в результате которых мы получаем некоторую конфигурацию — буфер токенов и связи между ними. Мы отдаем эту конфигурацию на текущем шаге transition-based парсеру, и с помощью нее он должен предсказать конфигурацию на следующем шаге. Сопоставляя входящие вектора и конфигурации на каждом шаге, модель обучается.
Итак, мы отобрали парсер, который подходит под все наши критерии, и даже поняли, как он работает. Переходим к экспериментам.
Зададим небольшое предложение: «Переведи маме сто рублей». Результат заставляет схватиться за голову.
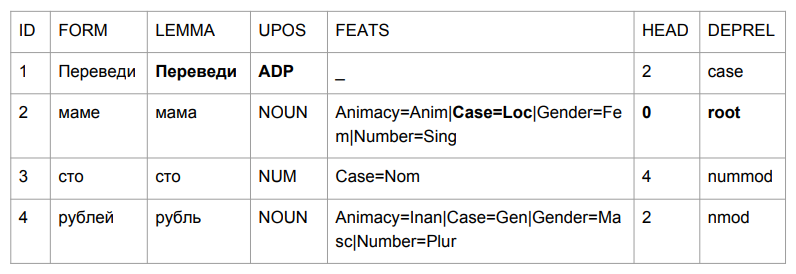
«Переведи» оказалось предлогом, но это вполне логично. Мы определяем грамматику словоформы по последним четырем символам. «Веди» — это что-то типа «посреди», так что выбор относительно логичен. С «мамой» поинтереснее: «мама» оказалась в предложном падеже и стала вершиной этого предложения.
Если пытаться интерпретировать все, исходя из результатов парсинга, то мы получили бы что-то типа «посреди мамы (мамы кого? чья это мама?) сотни рублей». Не совсем то, что было в начале. Нужно как-то с этим бороться. И мы придумали, как.
В пирамиде анализа синтаксис строится поверх морфологии, на основании морфологических тегов. Вот хрестоматийный пример лингвиста Л.В. Щербы на этот счет:
«Глокая куздра штеко будланула бокра и курдячит бокрёнка».
Анализ этого предложения не вызывает проблем. Почему? Потому что мы, как теггер UDPipe, смотрим на конец слова и понимаем, к какой оно относится части речи и какая это форма. История с «переведи» в качестве предлога совершенно противоречит нашей интуиции, но оказывается логична в тот момент, когда мы пытаемся проделать то же самое с незнакомыми словами. Человек мог бы подумать точно так же.
Оценим теггер UDPipe отдельно. Если он нас не устроит, возьмем другой теггер — чтобы потом построить синтаксический парсинг поверх другой морфологической разметки.
Tagging from plain text (CoNLL17 F1 score)
Качество морфологии UDPipe 2.0 неплохое. Но для русского языка достижимо лучше. Анализатор Mystem (разработка яндекса) в определении частей речи достигает лучших результатов, чем UDPipe. К тому же, остальные анализаторы сложнее имплементировать в python-проект, и они работают медленней при качестве, сопоставимом с Mystem. Кстати, сравнению морфологических анализаторов для русского языка посвящена пара интересных статей.
Можно попробовать использовать его выходную морфологическую разметку в качестве входа для синтакс��ческого парсера UDPipe. Но есть проблемы. Многие знают, что Mystem не полностью понимает морфологическую омонимию. Он знает, что в предложении «Мама мыла раму» слово «мыла» — от слова «мыть», а не от «мыло». Но нам этого мало. Еще нам нужно, чтобы в словах типа «директора», где лемма абсолютно очевидна (директор), мы понимали, какой это конкретно падеж. Это может быть:
В таких случаях Mystem честно отдает всю цепочку:
Но мы не можем подать UDPipe на вход всю цепочку, а должны указать какой-то лучший тег. Как его выбрать? Если ничего не трогать, хочется взять первый, авось сработает. Но теги отсортированы по алфавиту в соответствии с английскими названиями, поэтому наш выбор будет близок к случайному, а некоторые разборы практически лишаются шансов стать первыми.
Есть анализатор, который умеет отдавать лучший вариант, — Pymorphy2. Но с анализом морфологии у него хуже. К тому же, он отдает лучшее слово без учета контекста. Pymorphy2 выдаст только один разбор для «нет директора», «вижу директора» и «директора». Он будет не случайным, а действительно лучшим по вероятностям, которые в pymorphy2 считались на отдельном корпусе текстов. Но некоторый процент неверных разборов боевых текстов будет гарантирован, просто потому что в них вполне могут быть фразы с разными реальным формами: как «вижу директора», так и «директора пришли на встречу», и «нет директора». Бесконтекстная вероятность разбора нам не подходит.
Как получить контекстно лучший набор тегов? При помощи анализатора RNNMorph. Про него мало кто слышал, но в прошлом году он выиграл соревнование среди морфологических анализаторов, проводившееся в рамках конференции «Диалог».
У RNNMorph возникает своя проблема: у него нет токенизации. Если Mystem умеет токенизировать сырой текст, то RNNMorph требует на входе список токенов. Чтобы доехать до синтаксиса, придется сначала применить какой-то внешний токенизатор, потом отдать результат RNNMorph и только потом полученную морфологию скормить синтаксическому парсеру.
Вот какие варианты у нас есть. Не будем пока отказываться от бесконтекстного разбора в pymorphy2 поверх спорных случаев в Mystem — вдруг он от RNNMorph отстанет не сильно. Хотя если сравнивать их чисто на уровне качества морфологической разметки (данные с MorphoRuEval-2017), то проигрыш получается значительный — порядка 15%, если считать accuracy по словам.
Дальше нам нужно конвертировать выдачу Mystem в тот формат, который понимает UDPipe, — conllu. И это опять проблема, даже целых две. Чисто техническая — строки не совпадают. И концептуальная — не всегда до конца понятно, как их сопоставить. Сталкиваясь с двумя разными разметками языковых данных, вы почти наверняка упретесь в проблему соответствия тегов, см. примеры ниже. Ответы на вопрос «какой тег здесь правильный» могут быть разные, и, вероятно, правильный ответ зависит от задачи. Из-за такой непоследовательности сопоставление систем разметок — само по себе непростая задача.
Как конвертировать? Есть russian_tagsets_package — пакет для Python, который умеет конвертировать разные форматы. Там нет перевода из формата выдачи Mystem в Conllu, который принят в Universal Dependencies, но зато есть перевод в conllu, например, из формата разметки национального корпуса русского языка (и обратно). Автор пакета (кстати, он же автор pymorphy2) прямо в документации написал замечательную вещь: «Если вы можете не пользоваться этим пакетом, не пользуйтесь им». Он сделал это не потому, что криворукий программист (он превосходный программист!), а потому что если вам надо конвертировать одно в другое, то вы рискуете получить проблемы из-за лингвистического несоответствия конвенций разметок.
Вот пример. В школе учили «категории состояния» (холодно, нужно). Одни говорят — это наречие, другие — прилагательное. Вам нужно это конвертировать, и вы дописываете какие-то правила, но все равно не добиваетесь однозначного соответствия между одним форматом и другим.
Другой пример: залог (либо кто-то что-то делал, либо с кем-то что-то сделали). «Петя кого-то убил» или «Петя был убит». «Вася фотографирует» — «Вася фотографируется» (т.е. на самом деле «Васю фотографируют»). В SynTagRus есть еще медиальный залог — не будем даже углубляться в то, что это и почему. А в Mystem его нет. Если нужно как-то один формат привести к другому, это тупик.
Мы более-менее честно воспользовались советом автора пакета russian_tagsets — не использовали его разработку, потому что не нашли нужной пары в списке соответствий форматов. В итоге мы написали свой кастомный конвертер из Mystem в Conllu и поехали дальше.
После всех приключений мы взяли три алгоритма, про которые рассказывали выше:
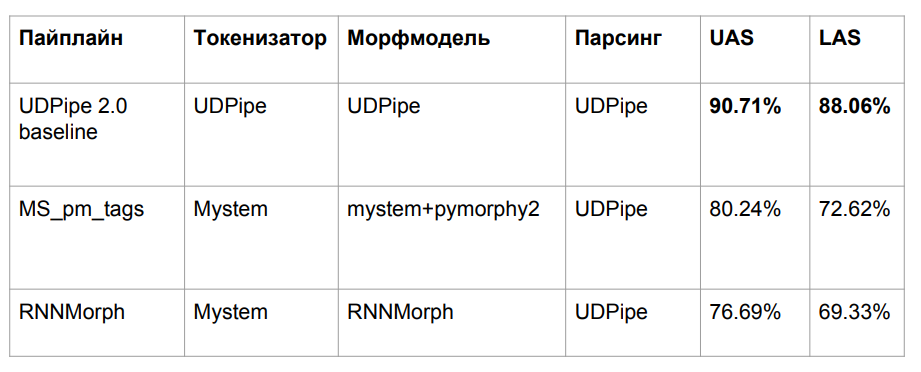
Мы потеряли в качестве по довольно понятной причине. Мы брали модель UDPipe, обученную на одной морфологии, но подсовывали на вход другую морфологию. Классическая проблема несоответствия данных трейна и теста — отсюда и падение качества.
Мы пытались наши автоматические инструменты морфологической разметки привести в соответствие с разметкой SynTagRus, который размечен вручную. У нас не получилось, поэтому в обучающем корпусе SynTagRus мы заменим всю ручную морфологическую разметку на полученную из Mystem и pymorphy2 в одном случае и из RNNMorph в другом. В размеченном руками валидированном корпусе мы вынуждены менять ручную разметку на автоматическую, потому что «в бою» мы никогда не получим ручную разметку.
В итоге мы обучили парсер UDPipe (только парсер) с такими же гиперпараметрами, как у baseline. То, что отвечало за синтаксис, — ID вершины, от кого зависит и тип связи — мы оставили, все остальное поменяли.
Дальше буду сравнивать нас с Syntaxnet и остальными алгоритмами. Организаторы CoNLL Shared Task зарелизили разбиение SynTagRus (train/dev/test 80/10/10). Мы изначально взяли другое (train/test 70/30), поэтому у нас не всегда совпадают данные, хотя они и получены на том же корпусе. Кроме того, мы взяли последний (по состоянию на февраль-март) релиз из репозитория SynTagRus — эта версия немного отличается от той, что была на соревновании. Данные для того, что у нас не взлетело, приводятся по статьям, где сплит был такой же, как на соревновании — такие алгоритмы помечены в таблице звездочкой.
Вот итоговые результаты:

RNNMorph действительно оказался лучше — не в абсолютном смысле, а в роли вспомогательного инструмента для получения общей метрики по итогам синтаксического анализа (по сравнению с Mystem + pymorphy2). То есть чем лучше морфология, тем лучше синтаксис, но при этом «синтаксический» отрыв значительно меньше морфологического. Заметим также, что мы не очень далеко уехали от baseline-модели, а значит, в морфологии на самом деле лежало не так много, как мы предполагали.
Интересно, много ли вообще лежит на морфологии? Можно ли добиться принципиального улучшения синтаксического парсера за счет идеальной морфологии? Чтобы ответить на этот вопрос, мы прогнали UDPipe 2.0 на идеально выверенной (на стандарте ручной разметки) токенизации и морфологии. Получился некоторый отрыв (см. в таблице строчку про Gold Morph; получается +1.54% от RNNMorph_reannotated_syntax) от того, что было у нас, в том числе, с точки зрения верного определения типа связи. Если кто-то когда-то напишет абсолютно идеальный морфологический анализатор русского языка, вероятно, результаты, которые мы получим, используя абстрактный синтаксический парсер, тоже вырастут. И мы примерно понимаем потолок (по крайней мере, потолок по той архитектуре и по тому сочетанию параметров, которое мы использовали для UDPipe, — он приведен в третьей строке таблицы выше).
Интересно, что мы почти дотянулись по метрике LAS до версии Syntaxnet. Понятно, что у нас немного разные данные, но в принципе все равно сопоставимо. У Syntaxnet токенизация «золотая», а у нас — от Mystem. Мы написали вышеупомянутую обертку к Mystem, но разбор все равно проходит автоматически; вероятно, Mystem тоже где-то ошибается. Из строчки таблицы «UDPipe 2.0 gold tok» видно, что если взять дефолтный UDPipe и золотую токенизацию, то он все равно немного проигрывает Syntaxnet-2017. Но зато работает намного быстрее.
До чего не дотянулся никто, так это до стенфордского парсера. Он устроен так же, как Syntaxnet, поэтому работает долго. В UDPipe мы идем просто по стеку. В архитектуре стенфордского парсера и Syntaxnet заложена другая концепия: сначала они генерируют полный ориентированный граф, и дальше работа алгоритма состоит в том, чтобы оставить тот скелет (минимальное остовное дерево), который будет наиболее вероятным. Для этого он перебирает комбинации, а этот перебор уже не линеен, потому что к одному слову вы будете обращаться не единожды. Несмотря на то, что это долго, с точки зрения чистой науки, по крайней мере для русского языка, — это более эффективная архитектура. Мы пытались поднять эту академическую разработку два дня — увы, не получилось. Но исходя из его архитектуры понятно, что работает он не быстро.
Что касается нашего подхода — хотя мы формально по метрикам почти не поднялись, зато у нас теперь с «мамой» все в порядке.
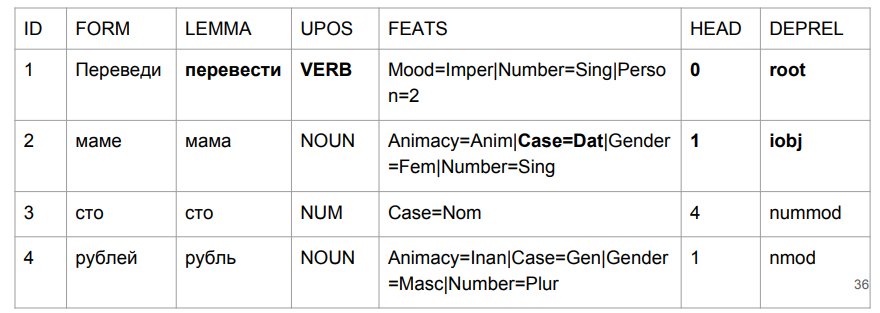
Во фразе «переведи маме сто рублей» у нас «переведи» — действительно глагол в повелительном наклонении. «Мама» получила свой дательный падеж. И самое главное для нас — наша метка (iobj) косвенный объект (адресат). Хотя прирост по цифрам незначительный, мы хорошо справились с той проблемой, с которой задача начиналась.
Если вернуться к реальным данным, то выясняется, что синтаксис зависит от пунктуации. Возьмем фразу «казнить нельзя помиловать». Что именно нельзя — «казнить» или «помиловать» — зависит от того, где стоит запятая. Даже если мы посадим лингвиста размечать данные, ему нужна будет пунктуация как некоторый вспомогательный инструмент. Без нее он не справится.
Возьмем фразы «Петя привет» и «Петя, привет» и посмотрим на их разбор baseline-UDPipe моделью. Оставим за скобками проблемы того, что, если верить этой модели, то:
1) «Петя» — это существительное женского рода;
2) «Петя» — это (судя по набору тегов) начальная форма, но при этом лемма у него якобы не «Петя».
Вот как меняется результат из-за запятой, с ее помощью мы получаем нечто похожее на правду.

Во втором случае «Петя» — это субъект, а «привет» — это глагол. Вернемся к предсказанию формы слова на основании последних четырех символов. В трактовке алгоритма это не «Петя привет», а «Петя привёт». Типа «Петя поет» или «Петя придет». Разбор довольно понятный: в русском языке запятой между подлежащим и сказуемым быть не может. Поэтому если запятая стоит, это слово «привет», а если запятой нет, это вполне может быть что-то вроде «Петя привёт».
Сталкиваться с этим на продакшене мы будем достаточно часто, потому что орфографию спеллчекеры исправят, а пунктуацию — нет. Что еще хуже, пользователь может неправильно ставить запятые, и наш алгоритм будет учитывать их в понимании естественного языка. Какие здесь есть возможные решения? Мы видим два варианта.
Первый вариант — сделать так, как иногда делают при переводе речи в текст. Изначально в таком тексте нет никакой пунктуации, поэтому она восстанавливается через модель. На выходе получается относительно грамотный с точки зрения правил русского языка материал, который помогает корректно работать синтаксическому парсеру.
Вторая идея несколько более смелая и противоречащая школьным урокам русского языка. Она предполагает работу без пунктуации: если вдруг входные данные будут с пунктуацией, мы ее оттуда уберем. Из обучающего корпуса тоже удалим абсолютно всю пунктуацию. Будем считать, что русский язык существует без пунктуации. Только точки для разделения на предложения.
Технически это довольно просто, потому что мы никак не меняем в синтаксическом дереве неконечные узлы. У нас не может быть такого, что знак пунктуации — это вершина. Это всегда некоторый конечный узел, кроме знака %, который почему-то в SynTagRus является вершиной для предшествующего числительного (50% в SynTagRus размечено как % — вершина, а 50 — зависимое).
Проведем тесты с использованием Mystem (+pymorphy 2) модели.

Нам критически важно не дать модели без пунктуации текст с пунктуацией. Но зато если мы всегда будем давать текст без пунктуации, то мы будем оказываться в рамках верхней строчки и получать как минимум приемлемые результаты. Если текст без пунктуации и модель будет работать непунктуационная, то относительно идеальной пунктуации и пунктуационной модели получится падение всего примерно в 3%.
Что с этим делать? Мы можем остановиться на этих цифрах — полученных с помощью беспунктуационной модели и чистки пунктуации. Или придумать какой-то классификатор, чтобы восстанавливать пунктуацию. Идеальных цифр (тех, что с пунктуацией на пунктуационной модели) мы уже не добьемся, потому что алгоритм восстановления пунктуации работает с некоторой погрешностью, а «идеальные» цифры были рассчитаны на абсолютно чистом SynTagRus. Но если мы будем писать модель, восстанавливающую пунктуацию, окупит ли прогресс наши затраты? Ответ пока неочевиден.
Мы можем долго размышлять про архитектуру парсера, но должны помнить, что на самом деле пока нет большого синтаксически размеченного корпуса веб-текстов. Его существование помогло бы лучше решать реальные задачи. Пока что мы учимся на корпусах абсолютно грамотных, отредактированных текстов — и теряем в качестве, получая на бою пользовательские тексты, которые зачастую написаны неграмотно.
Мы рассмотрели использование различных алгоритмов синтаксического парсинга, основанного на грамматике зависимостей, применительно к русскому языку. Оказалось, что с точки зрения скорости, удобства и качества работы наилучшим инструментом оказался UDPipe. Его baseline-модель можно улучшить, если отдать этапы токенизации и морфологического анализа на откуп другим, сторонним, анализаторам: такой трюк даёт возможность исправлять некорректное поведение теггера и, как следствие, парсера в важных для анализа случаях.
Также мы проанализировали проблему взаимосвязи пунктуации и парсинга и пришли к выводу, что в нашем случае пунктуацию перед синтаксическим парсингом лучше удалять.
Надеемся, что прикладные моменты, разобранные в нашей статье, помогут использовать синтаксический парсинг для решения ваших задач максимально эффективно.
Автор благодарит за помощь в подготовке статьи Никиту Кузнецова и Наталью Филиппову; за помощь в исследовании — Антона Алексеева, Никиту Кузнецова, Андрея Кутузова, Бориса Орехова и Михаила Попова.
Подготовка к отбору
Начнём с основ: как все работает? Мы берем текст, проводим токенизацию и получаем некоторый массив псевдослов-токенов. Этапы дальнейшего анализа укладываются в пирамиду:
Начинается все с морфологии — с анализа формы слова и его грамматических категорий (род, падеж и т.п.). На морфологии базируется синтаксис — взаимоотношения за рамками одного слова, между словами. Синтаксические парсеры, о которых пойдет речь, анализируют текст и выдают структуру зависимостей слов друг от друга.
Грамматика зависимостей и грамматика непосредственных составляющих
Есть два основных подхода к синтаксическому анализу, которые в лингвистической теории существуют примерно на равных.
В первой строке предложение разобрано в рамках грамматики зависимостей. Этому подходу учат в школе. Каждое слово в предложении как-то связ��но с другими. «Мыла» — сказуемое, от которого зависит подлежащее «мама» (здесь грамматика зависимостей расходится со школьной, где сказуемое зависит от подлежащего). У подлежащего есть зависимое определение «моя». У сказуемого есть зависимое прямое дополнение «раму». А у прямого дополнения «раму» — определение «грязную».
Во второй строке разбор идет в соответствии с грамматикой непосредственно составляющих.
Согласно ей, предложение делится на группы слов (phrases). Слова внутри одной группы связаны теснее. Слова «моя» и «мама» связаны более тесно, «раму» и «грязную» — тоже. И есть еще отдельное «мыла».
Второй подход для автоматического парсинга русского языка применим плохо, потому что в нем тесно связанные слова (члены одной группы) очень часто не стоят подряд. Нам пришлось бы объединять их странными скобками — через одно или два слова. Поэтому в автоматическом парсинге русского языка принято работать исходя из грамматики зависимостей. Это удобно еще и потому, что с таким «фреймворком» все знакомы по школе.
Дерево зависимостей
Набор зависимостей мы можем перевести в древовидную структуру. Вершина — слово «мыла», некоторые слова напрямую зависят от него, некоторые зависят от его зависимых. Вот определение дерева зависимостей из учебника Мартина и Журафского:
Dependency tree is a directed graph that satisfies the following constraints:
- There is a single designated root node that has no incoming arcs.
- With the exception of the root node, each vertex has exactly one incoming arc.
- There is a unique path from the root node to each vertex in V.
Есть верхнеуровневый узел — сказуемое. Из него можно дойти до любого слова. Каждое слово зависит от другого, но только от одного. Дерево зависимостей выглядит примерно так:
В этом дереве ребра подписаны некоторым особым типом синтаксического отношения. В грамматике зависимостей анализируют не только факт связи между словами, но и характер этой связи. Например, «is taken» — это почти одна глагольная форма, «inventory» — это подлежащее для «is taken». Соответственно, у нас от «is» есть ребро и в одну, и в другую сторону. Это не одинаковые связи, они носят разный характер, так что их надо различать.
Здесь и далее мы рассматриваем простые случаи, где члены предложения присутствуют, а не подразумеваются. Существуют структуры и отметки, позволяющие бороться с пропусками. В дереве появляется нечто, у чего нет поверхностного выражения — слова. Но это уже предмет другого исследования, а нам все-таки надо сосредоточиться на своем.
Проект Universal Dependencies
Чтобы облегчить себе выбор парсера, мы обратили свой взгляд на проект Universal Dependencies и недавно прошедшее в его рамках соревнование CoNLL Shared Task.
Universal Dependencies — это проект по унификации разметки синтаксических корпусов (трибанков) в рамках грамматики зависимостей. В русском языке количество типов синтаксических связей ограничено — подлежащее, сказуемое и т.д. В английском то же самое, но набор уже другой. Например, там появляется артикль, который тоже надо как-то маркиро��ать. Если бы мы хотели написать волшебный парсер, который мог бы обрабатывать все языки, то довольно быстро уперлись бы в проблемы сопоставления разных грамматик. Героическим создателям Universal Dependencies удалось договориться между собой и разметить все корпусы, которые имелись в их распоряжении, в едином формате. Не очень важно, как именно они договорились, главное, что на выходе мы получили некий единообразный формат представления всей этой истории — более 100 трибанков для 60 языков.
CoNLL Shared Task — это соревнование между разработчиками алгоритмов синтаксического парсинга, проводимое в рамках проекта Universal Dependencies. Организаторы берут некоторое количество трибанков и разбивают каждый из них на три части — обучающую, валидационную и тестовую. Первая часть предоставляется участникам соревнования, чтобы они обучили на ней свои модели. Вторая часть тоже используется участниками — чтобы после обучения оценить работу алгоритма. Обучение и оценку участники могут итеративно повторять. Потом они отдают свой лучший алгоритм организаторам, которые прогоняют его на тестовой части, закрытой для участников. Итоги работы моделей на тестовых частях трибанков — это и есть итоги соревнования.
Метрики качества
У нас есть связи между словами и их типы. Мы можем оценивать, правильно ли нашли вершину слова — метрика UAS (Unlabeled attachment score). Или оценивать, правильно ли найдена как вершина, так и тип зависимости — метрика LAS (Labeled attachment score).
Казалось бы, здесь напрашивается оценка точности (accuracy) — считаем, сколько раз мы попали из общего количества случаев. Если у нас есть 5 слов и для 4 мы правильно определили вершину, то получаем 80%.
Но на самом деле оценить парсер в чистом виде проблематично. Разработчики, решающие задачи автоматического парсинга, часто берут на вход сырой текст, который в соответствии с пирамидой анализа проходит этапы токенизации и морфологического анализа. На качество работы парсера могут повлиять ошибки с этих более ранних этапов. В частности, это относится к процедуре токенизации — выделения слов. Если мы выделили неправильные слова-юниты, то уже не сможем корректно оценить синтаксические связи между ними — ведь в нашем исходном размеченном корпусе юниты были другие.
Поэтому формулой оценки в данном случае является ф-мера, где точность (precision) — доля точных попаданий относительно общего числа предсказаний, а полнота — доля точных попаданий относительно числа связей в размеченных данных.
Когда мы в дальнейшем будем приводить оценки, нужно помнить, что используемые метрики затрагивают не только синтаксис, но еще и качество разбиения на токены.
Русский язык в Universal Dependencies
Для того, чтобы парсер смог синтаксически размечать предложения, которых он еще не видел, ему для обучения нужно скормить размеченный корпус. Для русского языка есть несколько таких корпусов:
Во втором столбце указано количество токенов — слов. Чем больше токенов, тем больше обучающий корпус и лучше итоговый алгоритм (если это хорошие данные). Очевидно, что все эксперименты проводятся на SynTagRus (разработка ИППИ РАН), в котором более миллиона токенов. На нем будут обучаться все алгоритмы, о которых пойдет речь дальше.
Парсеры для русского языка в CoNLL Shared Task
По итогам соревнования прошлого года модели, которые обучались на одном и том же SynTagRus, достигли следующих показателей LAS:
Результаты парсеров для русского впечатляют — они лучше чем у парсеров для английского, французского и других более редких языков. Нам с вами очень повезло сразу по двум причинам. Во-первых, алгоритмы хорошо справляются с русским языком. Во-вторых, у нас есть SynTagRus — большой и размеченный корп��с.
Кстати, уже прошло соревнование 2018 года, но свое исследование мы проводили весной этого года, так что мы опираемся на итоги дорожки прошлого года. Забегая вперед, заметим, что новая версия UDPipe (Future) оказалась еще выше в этом году.
В список не вошел Syntaxnet — парсер Google. Что с ним не так? Ответ прост: Syntaxnet начинался лишь с этапа морфологического анализа. Он брал готовую идеальную токенизацию, а уже поверх строил обработку. Поэтому оценивать его наравне с остальными нечестно — остальные делали разбиение на токены своими алгоритмами, и это могло ухудшить результаты на последующем этапе синтаксиса. У Syntaxnet образца 2017 года результат лучше, чем у всего списка выше, но проводить сравнение напрямую нечестно.
В таблицу попали две версии UDPipe, на 12 и 15 места. Разработкой этого парсера занимаются те же люди, которые принимали активное участие в самом проекте Universal Dependencies.
Периодически появляются обновления UDPipe (несколько реже, кстати, обновляется и разметка корпусов). Так, уже после соревнования прошлого года UDPipe обновлялся (это были коммиты в еще не вышедшую версию 2.0; в дальнейшем для простоты мы будем грубо называть взятый нами коммит UDPipe 2.0, хотя строго говоря это не так); этих обновлений в таблице соревнования, разумеется, нет. Результат «нашего» коммита находится примерно в районе седьмого места.
Итак, нам нужно выбрать парсер для русского языка. В качестве начальных данных у нас есть табличка выше с лидирующим Syntaxnet и с UDPipe 2.0 где-то на 7 месте.
Выбираем модель
Делаем просто: начинаем с парсера с самыми высокими показателями. Если с ним что-то не так, идем ниже. Что-то не так может быть по следующим критериям — может, они не идеальны, но нам подошли:
- Скорость работы. Наш парсер должен работать достаточно быстро. Синтаксис, разумеется, далеко не единственный модуль «под капотом» real-time системы, поэтому тратить на него больше десятка миллисекунд не стоит.
- Качество работы. Как минимум, самого парсера именно на данных русского языка. Требование очевидное. Для русского языка у нас есть достаточно хорошие морфологические анализаторы, которые могут встроиться в нашу пирамиду. Если мы сможем убедиться, что сам парсер без морфологии круто работает, то это нас устроит — морфологию подсунем потом.
- Наличие кода обучения и желательно модели в открытом доступе. При наличии кода обучения мы будем способны повторить результаты автора модели. Для этого они должны быть открыты. И, кроме того, нужно внимательно следить за условиями распространения корпусов и модели — придется ли нам, если мы будем их использовать в рамках своих алгоритмов, покупать лицензию на их использование?
- Запуск без сверхусилий. Этот пункт очень субъективный, но важный. Что это значит? Это значит, что если мы три дня сидим и что-то запускаем, а оно не запускается, то выбрать этот парсер мы не сможем, даже если там будет идеальное качество.
Все, что в чарте парсеров было выше UDPipe 2.0, нам не подошло. У нас проект на Python, а некоторые парсеры из списка написаны не на Python. Чтобы имплементировать их в питонский проект, пришлось бы применить те самые сверхусилия. В других случаях мы сталкивались с закрытым исходным кодом, академическими, индустриальными разработками — в общем, не докопаешься.
Звездный Syntaxnet заслуживает отдельного рассказа про качество работы. Здесь же он нас не устроил по скорости работы. Время его ответа на какие-то простые, распространенные в чатах фразы составляет от 100 миллисекунд. Если мы столько будем тратить на синтаксис, нам не хватит времени ни на что другое. В то же самое время UDPipe 2.0 делает разбор предложения за ~3ms. В итоге выбор пал на UDPipe 2.0.
UDPipe 2.0
UDPipe — пайплайн, который обучается токенизации, лемматизации, морфологическому тэггингу и парсингу, основанному на грамматике зависимостей. Мы можем обучить его всему этому или чему-то отдельно. Например, сделать с ним еще один морфологический анализатор для русского языка. Или обучить и использовать UDPipe в качестве токенизатора.
UDPipe 2.0 подробно задокументирован. Есть описание архитектуры, репозиторий с кодом обучения, мануал. Самое интересное — это готовые модели, в том числе и для русского языка. Качай и запускай. Также на этом ресурсе зарелизены подобранные для каждого языкового корпуса параметры обучения. Для каждой такой модели нужно порядка 60 параметров обучения, и с их помощью можно самостоятельно добиться таких же показат��лей качества, как в таблице. Они могут быть не оптимальны, но по крайней мере мы можем быть уверены, что пайплайн будет работать достаточно корректно. Кроме того, наличие такого референса позволяет нам спокойно поэкспериментировать с моделью самостоятельно.
Как работает UDPipe 2.0
Сначала текст разделяется на предложения, а предложения — на слова. UDPipe делает все это сразу с помощью совместного модуля — нейронной сети (однослойной двухсторонней GRU), которая для каждого символа предсказывает, последний ли он в предложении или в слове.
Затем начинает работу теггер — штука, которая предсказывает морфологические свойства токена: в каком падеже слово стоит, в каком числе. По последним четырем символам каждого слова теггер генерирует гипотезы относительно части речи и морфологических тегов этого слова, а затем при помощи перцептрона отбирает лучший вариант.
В UDPipe есть еще лемматизатор, который подбирает для слов начальную форму. Он обучается примерно по тому же принципу, по которому не-носитель языка мог бы попытаться определить лемму незнакомого ему слова. Отрезаем приставку и конец слова, добавляем какой-нибудь «ть», который присутствует в начальной форме глагола и т.п. Так генерируются кандидаты, из которых наилучшего выбирает перцептрон.
Схема морфологического тегирования (определение числа, падежа и всего остального) и предсказания лемм очень похожи. Их можно предсказывать вместе, но лучше раздельно — слишком уж богата морфология русского языка. Можно также подключить свой список лемм.
Перейдем к самому интересному — к парсеру. Есть несколько архитектур dependency-парсеров. UDPipe — это transition-based архитектура: она работает быстро, за линейное время проходя по всем токенам один раз.
Синтаксический парсинг в такой архитектуре начинается со стека (где в начале только root) и пустой конфигурации. Есть три дефолтных способа ее изменить:
- LeftArc — применим, если второй элемент стека не root. Сохраняет зависимость между токеном на верхушке стека и вторым токеном, а также выкидывает второй из стека.
- RightArc — то же самое, но зависимость строится в другую сторону, и отбрасывается верхушка.
- Shift — переносит очередное слово из буфера в стек.
Ниже приведен пример работы парсера (источник). У нас есть фраза «book me the morning flight», и мы восстанавливаем связи в ней:
Вот что получается в итоге:
У классических transition-based parser возможны три операции, перечисленные выше: стрелка в одну сторону, стрелка в другую сторону и шифт. Есть еще операция Swap, в базовых архитектурах transition-based парсеров она не используется, но в UDPipe включена. Swap возвращает второй элемент стека в буфер, чтобы взять потом из буфера следующий (в случае если они разнесены). Это помогает пропустить некоторое количество слов и восстановить правильную связь.
По ссылке есть хорошая статья человека, который придумал операцию swap. Выделим из нее один момент: несмотря на то, что мы не один раз проходим по исходному буферу токенов (т.е. наше время уже не линейное), эти операции можно оптимизировать так, чтобы вернуть время очень близко к линейному. То есть перед нами не просто осмысленная с точки зрения языка операция, но еще и инструмент, не сильно замедляющий работу парсера.
На примере выше мы показали операции, в результате которых мы получаем некоторую конфигурацию — буфер токенов и связи между ними. Мы отдаем эту конфигурацию на текущем шаге transition-based парсеру, и с помощью нее он должен предсказать конфигурацию на следующем шаге. Сопоставляя входящие вектора и конфигурации на каждом шаге, модель обучается.
Итак, мы отобрали парсер, который подходит под все наши критерии, и даже поняли, как он работает. Переходим к экспериментам.
Проблемы UDPipe
Зададим небольшое предложение: «Переведи маме сто рублей». Результат заставляет схватиться за голову.
«Переведи» оказалось предлогом, но это вполне логично. Мы определяем грамматику словоформы по последним четырем символам. «Веди» — это что-то типа «посреди», так что выбор относительно логичен. С «мамой» поинтереснее: «мама» оказалась в предложном падеже и стала вершиной этого предложения.
Если пытаться интерпретировать все, исходя из результатов парсинга, то мы получили бы что-то типа «посреди мамы (мамы кого? чья это мама?) сотни рублей». Не совсем то, что было в начале. Нужно как-то с этим бороться. И мы придумали, как.
В пирамиде анализа синтаксис строится поверх морфологии, на основании морфологических тегов. Вот хрестоматийный пример лингвиста Л.В. Щербы на этот счет:
«Глокая куздра штеко будланула бокра и курдячит бокрёнка».
Анализ этого предложения не вызывает проблем. Почему? Потому что мы, как теггер UDPipe, смотрим на конец слова и понимаем, к какой оно относится части речи и какая это форма. История с «переведи» в качестве предлога совершенно противоречит нашей интуиции, но оказывается логична в тот момент, когда мы пытаемся проделать то же самое с незнакомыми словами. Человек мог бы подумать точно так же.
Оценим теггер UDPipe отдельно. Если он нас не устроит, возьмем другой теггер — чтобы потом построить синтаксический парсинг поверх другой морфологической разметки.
Tagging from plain text (CoNLL17 F1 score)
- gold forms: 301639,
- upostag: 98.15%,
- xpostag: 99.89%,
- feats: 93.97%,
- alltags: 93.44%,
- lemmas: 96.68%
Качество морфологии UDPipe 2.0 неплохое. Но для русского языка достижимо лучше. Анализатор Mystem (разработка яндекса) в определении частей речи достигает лучших результатов, чем UDPipe. К тому же, остальные анализаторы сложнее имплементировать в python-проект, и они работают медленней при качестве, сопоставимом с Mystem. Кстати, сравнению морфологических анализаторов для русского языка посвящена пара интересных статей.
Можно попробовать использовать его выходную морфологическую разметку в качестве входа для синтакс��ческого парсера UDPipe. Но есть проблемы. Многие знают, что Mystem не полностью понимает морфологическую омонимию. Он знает, что в предложении «Мама мыла раму» слово «мыла» — от слова «мыть», а не от «мыло». Но нам этого мало. Еще нам нужно, чтобы в словах типа «директора», где лемма абсолютно очевидна (директор), мы понимали, какой это конкретно падеж. Это может быть:
- «нет директора» — родительный падеж единственного числа
- «я вижу директора» — т.е. винительный падеж единственного числа
- «это какие-то директора» — именительный падеж множественного числа (ударения-то у нас на письме нет)
В таких случаях Mystem честно отдает всю цепочку:
m.analyze("нет директора")
[{'analysis': [{'lex': 'нет', 'gr': 'PART='}], 'text': 'нет'},
{'text': ' '},
{'analysis': [{'lex': 'директор', 'gr': 'S,муж,од=(вин,ед|род,ед|им,мн)'}],
'text': 'директора'},
{'text': '\n'}]
Но мы не можем подать UDPipe на вход всю цепочку, а должны указать какой-то лучший тег. Как его выбрать? Если ничего не трогать, хочется взять первый, авось сработает. Но теги отсортированы по алфавиту в соответствии с английскими названиями, поэтому наш выбор будет близок к случайному, а некоторые разборы практически лишаются шансов стать первыми.
Есть анализатор, который умеет отдавать лучший вариант, — Pymorphy2. Но с анализом морфологии у него хуже. К тому же, он отдает лучшее слово без учета контекста. Pymorphy2 выдаст только один разбор для «нет директора», «вижу директора» и «директора». Он будет не случайным, а действительно лучшим по вероятностям, которые в pymorphy2 считались на отдельном корпусе текстов. Но некоторый процент неверных разборов боевых текстов будет гарантирован, просто потому что в них вполне могут быть фразы с разными реальным формами: как «вижу директора», так и «директора пришли на встречу», и «нет директора». Бесконтекстная вероятность разбора нам не подходит.
Как получить контекстно лучший набор тегов? При помощи анализатора RNNMorph. Про него мало кто слышал, но в прошлом году он выиграл соревнование среди морфологических анализаторов, проводившееся в рамках конференции «Диалог».
У RNNMorph возникает своя проблема: у него нет токенизации. Если Mystem умеет токенизировать сырой текст, то RNNMorph требует на входе список токенов. Чтобы доехать до синтаксиса, придется сначала применить какой-то внешний токенизатор, потом отдать результат RNNMorph и только потом полученную морфологию скормить синтаксическому парсеру.
Вот какие варианты у нас есть. Не будем пока отказываться от бесконтекстного разбора в pymorphy2 поверх спорных случаев в Mystem — вдруг он от RNNMorph отстанет не сильно. Хотя если сравнивать их чисто на уровне качества морфологической разметки (данные с MorphoRuEval-2017), то проигрыш получается значительный — порядка 15%, если считать accuracy по словам.
Дальше нам нужно конвертировать выдачу Mystem в тот формат, который понимает UDPipe, — conllu. И это опять проблема, даже целых две. Чисто техническая — строки не совпадают. И концептуальная — не всегда до конца понятно, как их сопоставить. Сталкиваясь с двумя разными разметками языковых данных, вы почти наверняка упретесь в проблему соответствия тегов, см. примеры ниже. Ответы на вопрос «какой тег здесь правильный» могут быть разные, и, вероятно, правильный ответ зависит от задачи. Из-за такой непоследовательности сопоставление систем разметок — само по себе непростая задача.
Как конвертировать? Есть russian_tagsets_package — пакет для Python, который умеет конвертировать разные форматы. Там нет перевода из формата выдачи Mystem в Conllu, который принят в Universal Dependencies, но зато есть перевод в conllu, например, из формата разметки национального корпуса русского языка (и обратно). Автор пакета (кстати, он же автор pymorphy2) прямо в документации написал замечательную вещь: «Если вы можете не пользоваться этим пакетом, не пользуйтесь им». Он сделал это не потому, что криворукий программист (он превосходный программист!), а потому что если вам надо конвертировать одно в другое, то вы рискуете получить проблемы из-за лингвистического несоответствия конвенций разметок.
Вот пример. В школе учили «категории состояния» (холодно, нужно). Одни говорят — это наречие, другие — прилагательное. Вам нужно это конвертировать, и вы дописываете какие-то правила, но все равно не добиваетесь однозначного соответствия между одним форматом и другим.
Другой пример: залог (либо кто-то что-то делал, либо с кем-то что-то сделали). «Петя кого-то убил» или «Петя был убит». «Вася фотографирует» — «Вася фотографируется» (т.е. на самом деле «Васю фотографируют»). В SynTagRus есть еще медиальный залог — не будем даже углубляться в то, что это и почему. А в Mystem его нет. Если нужно как-то один формат привести к другому, это тупик.
Мы более-менее честно воспользовались советом автора пакета russian_tagsets — не использовали его разработку, потому что не нашли нужной пары в списке соответствий форматов. В итоге мы написали свой кастомный конвертер из Mystem в Conllu и поехали дальше.
Соединяем сторонний теггер и парсер UDPipe
После всех приключений мы взяли три алгоритма, про которые рассказывали выше:
- baseline UDPipe
- Mystem с дизамбигуацией тегов от pymorphy2
- RNNMorph
Мы потеряли в качестве по довольно понятной причине. Мы брали модель UDPipe, обученную на одной морфологии, но подсовывали на вход другую морфологию. Классическая проблема несоответствия данных трейна и теста — отсюда и падение качества.
Мы пытались наши автоматические инструменты морфологической разметки привести в соответствие с разметкой SynTagRus, который размечен вручную. У нас не получилось, поэтому в обучающем корпусе SynTagRus мы заменим всю ручную морфологическую разметку на полученную из Mystem и pymorphy2 в одном случае и из RNNMorph в другом. В размеченном руками валидированном корпусе мы вынуждены менять ручную разметку на автоматическую, потому что «в бою» мы никогда не получим ручную разметку.
В итоге мы обучили парсер UDPipe (только парсер) с такими же гиперпараметрами, как у baseline. То, что отвечало за синтаксис, — ID вершины, от кого зависит и тип связи — мы оставили, все остальное поменяли.
Результаты
Дальше буду сравнивать нас с Syntaxnet и остальными алгоритмами. Организаторы CoNLL Shared Task зарелизили разбиение SynTagRus (train/dev/test 80/10/10). Мы изначально взяли другое (train/test 70/30), поэтому у нас не всегда совпадают данные, хотя они и получены на том же корпусе. Кроме того, мы взяли последний (по состоянию на февраль-март) релиз из репозитория SynTagRus — эта версия немного отличается от той, что была на соревновании. Данные для того, что у нас не взлетело, приводятся по статьям, где сплит был такой же, как на соревновании — такие алгоритмы помечены в таблице звездочкой.
Вот итоговые результаты:
RNNMorph действительно оказался лучше — не в абсолютном смысле, а в роли вспомогательного инструмента для получения общей метрики по итогам синтаксического анализа (по сравнению с Mystem + pymorphy2). То есть чем лучше морфология, тем лучше синтаксис, но при этом «синтаксический» отрыв значительно меньше морфологического. Заметим также, что мы не очень далеко уехали от baseline-модели, а значит, в морфологии на самом деле лежало не так много, как мы предполагали.
Интересно, много ли вообще лежит на морфологии? Можно ли добиться принципиального улучшения синтаксического парсера за счет идеальной морфологии? Чтобы ответить на этот вопрос, мы прогнали UDPipe 2.0 на идеально выверенной (на стандарте ручной разметки) токенизации и морфологии. Получился некоторый отрыв (см. в таблице строчку про Gold Morph; получается +1.54% от RNNMorph_reannotated_syntax) от того, что было у нас, в том числе, с точки зрения верного определения типа связи. Если кто-то когда-то напишет абсолютно идеальный морфологический анализатор русского языка, вероятно, результаты, которые мы получим, используя абстрактный синтаксический парсер, тоже вырастут. И мы примерно понимаем потолок (по крайней мере, потолок по той архитектуре и по тому сочетанию параметров, которое мы использовали для UDPipe, — он приведен в третьей строке таблицы выше).
Интересно, что мы почти дотянулись по метрике LAS до версии Syntaxnet. Понятно, что у нас немного разные данные, но в принципе все равно сопоставимо. У Syntaxnet токенизация «золотая», а у нас — от Mystem. Мы написали вышеупомянутую обертку к Mystem, но разбор все равно проходит автоматически; вероятно, Mystem тоже где-то ошибается. Из строчки таблицы «UDPipe 2.0 gold tok» видно, что если взять дефолтный UDPipe и золотую токенизацию, то он все равно немного проигрывает Syntaxnet-2017. Но зато работает намного быстрее.
До чего не дотянулся никто, так это до стенфордского парсера. Он устроен так же, как Syntaxnet, поэтому работает долго. В UDPipe мы идем просто по стеку. В архитектуре стенфордского парсера и Syntaxnet заложена другая концепия: сначала они генерируют полный ориентированный граф, и дальше работа алгоритма состоит в том, чтобы оставить тот скелет (минимальное остовное дерево), который будет наиболее вероятным. Для этого он перебирает комбинации, а этот перебор уже не линеен, потому что к одному слову вы будете обращаться не единожды. Несмотря на то, что это долго, с точки зрения чистой науки, по крайней мере для русского языка, — это более эффективная архитектура. Мы пытались поднять эту академическую разработку два дня — увы, не получилось. Но исходя из его архитектуры понятно, что работает он не быстро.
Что касается нашего подхода — хотя мы формально по метрикам почти не поднялись, зато у нас теперь с «мамой» все в порядке.
Во фразе «переведи маме сто рублей» у нас «переведи» — действительно глагол в повелительном наклонении. «Мама» получила свой дательный падеж. И самое главное для нас — наша метка (iobj) косвенный объект (адресат). Хотя прирост по цифрам незначительный, мы хорошо справились с той проблемой, с которой задача начиналась.
Bonus track: пунктуация
Если вернуться к реальным данным, то выясняется, что синтаксис зависит от пунктуации. Возьмем фразу «казнить нельзя помиловать». Что именно нельзя — «казнить» или «помиловать» — зависит от того, где стоит запятая. Даже если мы посадим лингвиста размечать данные, ему нужна будет пунктуация как некоторый вспомогательный инструмент. Без нее он не справится.
Возьмем фразы «Петя привет» и «Петя, привет» и посмотрим на их разбор baseline-UDPipe моделью. Оставим за скобками проблемы того, что, если верить этой модели, то:
1) «Петя» — это существительное женского рода;
2) «Петя» — это (судя по набору тегов) начальная форма, но при этом лемма у него якобы не «Петя».
Вот как меняется результат из-за запятой, с ее помощью мы получаем нечто похожее на правду.
Во втором случае «Петя» — это субъект, а «привет» — это глагол. Вернемся к предсказанию формы слова на основании последних четырех символов. В трактовке алгоритма это не «Петя привет», а «Петя привёт». Типа «Петя поет» или «Петя придет». Разбор довольно понятный: в русском языке запятой между подлежащим и сказуемым быть не может. Поэтому если запятая стоит, это слово «привет», а если запятой нет, это вполне может быть что-то вроде «Петя привёт».
Сталкиваться с этим на продакшене мы будем достаточно часто, потому что орфографию спеллчекеры исправят, а пунктуацию — нет. Что еще хуже, пользователь может неправильно ставить запятые, и наш алгоритм будет учитывать их в понимании естественного языка. Какие здесь есть возможные решения? Мы видим два варианта.
Первый вариант — сделать так, как иногда делают при переводе речи в текст. Изначально в таком тексте нет никакой пунктуации, поэтому она восстанавливается через модель. На выходе получается относительно грамотный с точки зрения правил русского языка материал, который помогает корректно работать синтаксическому парсеру.
Вторая идея несколько более смелая и противоречащая школьным урокам русского языка. Она предполагает работу без пунктуации: если вдруг входные данные будут с пунктуацией, мы ее оттуда уберем. Из обучающего корпуса тоже удалим абсолютно всю пунктуацию. Будем считать, что русский язык существует без пунктуации. Только точки для разделения на предложения.
Технически это довольно просто, потому что мы никак не меняем в синтаксическом дереве неконечные узлы. У нас не может быть такого, что знак пунктуации — это вершина. Это всегда некоторый конечный узел, кроме знака %, который почему-то в SynTagRus является вершиной для предшествующего числительного (50% в SynTagRus размечено как % — вершина, а 50 — зависимое).
Проведем тесты с использованием Mystem (+pymorphy 2) модели.
Нам критически важно не дать модели без пунктуации текст с пунктуацией. Но зато если мы всегда будем давать текст без пунктуации, то мы будем оказываться в рамках верхней строчки и получать как минимум приемлемые результаты. Если текст без пунктуации и модель будет работать непунктуационная, то относительно идеальной пунктуации и пунктуационной модели получится падение всего примерно в 3%.
Что с этим делать? Мы можем остановиться на этих цифрах — полученных с помощью беспунктуационной модели и чистки пунктуации. Или придумать какой-то классификатор, чтобы восстанавливать пунктуацию. Идеальных цифр (тех, что с пунктуацией на пунктуационной модели) мы уже не добьемся, потому что алгоритм восстановления пунктуации работает с некоторой погрешностью, а «идеальные» цифры были рассчитаны на абсолютно чистом SynTagRus. Но если мы будем писать модель, восстанавливающую пунктуацию, окупит ли прогресс наши затраты? Ответ пока неочевиден.
Мы можем долго размышлять про архитектуру парсера, но должны помнить, что на самом деле пока нет большого синтаксически размеченного корпуса веб-текстов. Его существование помогло бы лучше решать реальные задачи. Пока что мы учимся на корпусах абсолютно грамотных, отредактированных текстов — и теряем в качестве, получая на бою пользовательские тексты, которые зачастую написаны неграмотно.
Заключение
Мы рассмотрели использование различных алгоритмов синтаксического парсинга, основанного на грамматике зависимостей, применительно к русскому языку. Оказалось, что с точки зрения скорости, удобства и качества работы наилучшим инструментом оказался UDPipe. Его baseline-модель можно улучшить, если отдать этапы токенизации и морфологического анализа на откуп другим, сторонним, анализаторам: такой трюк даёт возможность исправлять некорректное поведение теггера и, как следствие, парсера в важных для анализа случаях.
Также мы проанализировали проблему взаимосвязи пунктуации и парсинга и пришли к выводу, что в нашем случае пунктуацию перед синтаксическим парсингом лучше удалять.
Надеемся, что прикладные моменты, разобранные в нашей статье, помогут использовать синтаксический парсинг для решения ваших задач максимально эффективно.
Автор благодарит за помощь в подготовке статьи Никиту Кузнецова и Наталью Филиппову; за помощь в исследовании — Антона Алексеева, Никиту Кузнецова, Андрея Кутузова, Бориса Орехова и Михаила Попова.
