 Вот уже почти 20 лет компания Google обеспечивает работу невообразимо сложных и масштабных систем, которые чутко реагируют на запросы пользователей. Поисковик Google находит ответ на любые вопросы за доли секунды, карты Google с высочайшей точностью отражают земной ландшафт, а почта Google доступна в режиме 365/24/7 и, в сущности, стала первым общедоступным облачным хранилищем. Неужели эти системы безупречны? Нет, они тоже отказывают, ломаются и устаревают, как любая техника. Просто мы этого не замечаем. Все дело в том, что уже более десяти лет Google нарабатывает уникальную технологию Site Reliability Engineering, обеспечивающую бесперебойную работу и поступательное развитие софтверных систем любой сложности. Эта книга — кладезь опыта, накопленного компанией Google за долгие годы, коллективный труд многих выдающихся специалистов и незаменимый ресурс для любого инженера, желающего разрабатывать и поддерживать любые продукты максимально качественно и эффективно.
Вот уже почти 20 лет компания Google обеспечивает работу невообразимо сложных и масштабных систем, которые чутко реагируют на запросы пользователей. Поисковик Google находит ответ на любые вопросы за доли секунды, карты Google с высочайшей точностью отражают земной ландшафт, а почта Google доступна в режиме 365/24/7 и, в сущности, стала первым общедоступным облачным хранилищем. Неужели эти системы безупречны? Нет, они тоже отказывают, ломаются и устаревают, как любая техника. Просто мы этого не замечаем. Все дело в том, что уже более десяти лет Google нарабатывает уникальную технологию Site Reliability Engineering, обеспечивающую бесперебойную работу и поступательное развитие софтверных систем любой сложности. Эта книга — кладезь опыта, накопленного компанией Google за долгие годы, коллективный труд многих выдающихся специалистов и незаменимый ресурс для любого инженера, желающего разрабатывать и поддерживать любые продукты максимально качественно и эффективно.Среда промышленной эксплуатации Google с точки зрения SRE
Дата-центры (центры обработки данных) Google значительно отличаются от традиционных дата-центров и небольших серверных «ферм». Эти различия привносят как дополнительные проблемы, так и дополнительные возможности. В этой главе рассматриваются проблемы и возможности, характерные для дата-центров Google, и вводится терминология, которая будет использована на протяжении всей книги.
Оборудование
Большая часть вычислительных ресурсов Google располагается в спроектированных компанией дата-центрах, имеющих собственную систему энергоснабжения, систему охлаждения, внутреннюю сеть и вычислительное оборудование [Barroso et al., 2013]. В отличие от типичных дата-центров, предоставляемых провайдерами своим клиентам, все дата-центры Google оснащены одинаково1. Чтобы избежать путаницы между серверным оборудованием и серверным ПО, в этой книге мы используем следующую терминологию:
- машина (компьютер) — единица оборудования (или, возможно, виртуальная машина);
- сервер — единица программного обеспечения, которая реализует сервис.
На машинах может быть запущен любой сервер, поэтому мы не выделяем конкретные компьютеры для конкретных серверных программ. Например, у нас нет конкретной машины, на которой работает почтовый сервер. Вместо этого ресурсы распределяются нашей системой управления кластерами Borg.
Мы понимаем, что такое использование термина «сервер» нестандартно. Более привычно обозначать им сразу два понятия: программу, которая обслуживает сетевые соединения, и одновременно машину, на которой исполняются такие программы, но, когда мы говорим о вычислительных мощностях Google, разница между двумя этими понятиями существенна. Как только вы привыкнете к нашей трактовке слова «сервер», вам станет понятнее, почему важно использовать именно такую специализированную терминологию не только непосредственно в Google, но и на протяжении всей этой книги.
На рис. 2.1 продемонстрирована конфигурация дата-центра Google.
- Десятки машин размещаются на стойках.
- Стойки стоят рядами.
- Один или несколько рядов образуют кластер.
- Обычно в здании центра обработки данных (ЦОД), или дата-центра, размещается несколько кластеров.
- Несколько зданий дата-центров, которые располагаются близко друг к другу, составляют кампус.
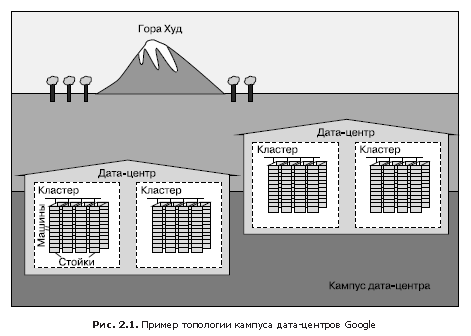
Внутри каждого дата-центра все машины должны иметь возможность эффективно общаться друг с другом, поэтому мы создали очень быстрый виртуальный коммутатор (switch) с десятками тысяч портов. Это удалось сделать, соединив сотни разработанных в Google коммутаторов в «фабрику» на основе топологии сети Клоза [Clos, 1953], названную Jupiter [Singh et al., 2015]. В своей максимальной конфигурации Jupiter поддерживает пропускную способность 1,3 Пб/с между серверами.
Дата-центры соединены друг с другом с помощью нашей глобальной магистральной сети B4 [Jain et al., 2013]. B4 имеет программно-конфигурируемую сетевую архитектуру и использует открытый коммуникационный протокол OpenFlow. B4 предоставляет широкую полосу пропускания ограниченному количеству систем и использует гибкое управление шириной канала для максимизации среднего ее значения [Kumar et al., 2015].
Системное ПО, которое «организует» оборудование
Программное обеспечение, которое обеспечивает управление и администрирование нашего оборудования, должно быть способно справляться с системами огромного масштаба. Сбои оборудования — это одна из основных проблем, решаемая с помощью ПО. Учитывая большое количество аппаратных компонентов в кластере, случаются они довольно часто. В каждом кластере за год обычно отказывают тысячи машин и выходят из строя тысячи жестких дисков. Если умножить это количество на число кластеров, функционирующих по всему миру, результат ошеломляет. Поэтому мы хотим изолировать пользователей от подобных проблем, и команды, занимающиеся нашими сервисами, также не хотят отвлекаться на аппаратные проблемы. В каждом кампусе дата-центров есть команды, отвечающие за поддержку оборудования и инфраструктуру дата-центра.
Управление машинами
Borg (рис. 2.2) — это распределенная система управления кластерами [Verma et al., 2015], похожая на Apache Mesos. Borg управляет заданиями на уровне кластеров.
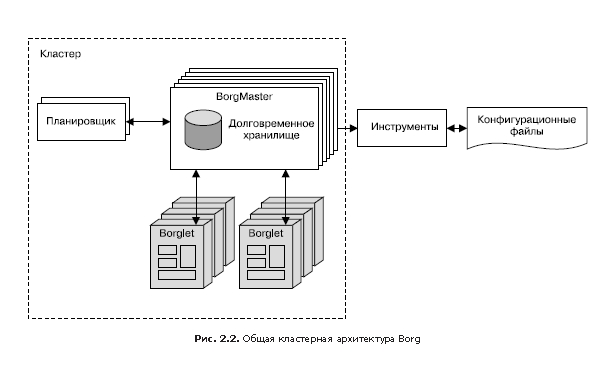
Поскольку задачи свободно распределяются между машинами, мы не можем использовать для обращения к ним IP-адреса и номера портов. Эта проблема решается дополнительным уровнем абстракции: при запуске задания Borg выделяет имя для задания и номер (индекс) для каждой его задачи с помощью сервиса именования Borg (Borg Naming Service, BNS). Вместо того чтобы использовать IP-адрес и номер порта, другие процессы связываются с задачами Borg по их BNS-имени, которое затем BNS преобразует в IP-адрес и номер порта. Например, путь BNS может быть строкой вроде /bns/<кластер>/<пользователь>/<имя_задания>/<номер_задачи>, которая затем транслируется (в сетях принято говорить «разрешается») в формат <IP-адрес>:<порт>.
Borg также отвечает за выделение ресурсов для заданий. Каждое задание должно указать, какие ресурсы требуются для его выполнения (например, три ядра процессора, 2 Гбайт оперативной памяти). Используя список требований всех заданий, Borg может оптимально распределять задания между машинами, учитывая также и соображения отказоустойчивости (например, Borg не будет запускать все задачи одного задания на одной и той же стойке, так как коммутатор данной стойки в случае сбоя окажется критической точкой для этого задания).
Если задача пытается захватить больше ресурсов, чем было затребовано, Borg уничтожает ее и затем перезапускает (поскольку обычно предпочтительнее иметь задачу, которая иногда аварийно завершается и перезапускается, чем которая не перезапускается вовсе).
Хранилище
Для более быстрого доступа к данным задачи могут использовать локальный диск машин, но у нас есть несколько вариантов организации постоянного хранилища в кластере (и даже локально хранимые данные в итоге будут перемещаться в кластерное хранилище). Их можно сравнить с Lustre и Hadoop Distributed File System (HDFS) — кластерными файловыми системами, имеющими реализацию с открытым исходным кодом.
Хранилище обеспечивает пользователям возможность простого и надежного доступа к данным, доступным для кластера. Как показано на рис. 2.3, хранилище имеет несколько слоев.
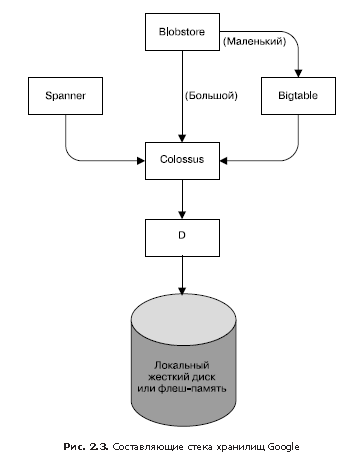
1. Самый нижний слой называется D (от disk, хотя уровень D использует как традиционные жесткие диски, так и накопители с флеш-памятью). D — это файловый сервер, работающий практически на всех машинах кластера. Однако пользователи, желающие получить доступ к своим данным, не хотели бы запоминать, на какой машине те хранятся, поэтому здесь подключается следующий слой.
2. Над слоем D располагается слой Colossus, который создает в кластере файловую систему, предлагающую обычную семантику файловой системы, а также репликацию и шифрование. Colossus является наследником GFS, Google File System (файловая система Google) [Ghemawat et al., 2003].
3. Далее, существует несколько похожих на базы данных сервисов, построенных над уровнем Colossus.
- Bigtable [Chang et al., 2006] — это нереляционная (NoSQL) система баз данных, способная работать с базами объемом в петабайты. Bigtable — это разреженная распределенная отказоустойчивая многомерная упорядоченная база данных, которая индексируется по ключам строк, столбцов и временным меткам; каждое значение базы данных — это произвольный неинтерпретированный массив байтов. Bigtable также поддерживает репл��кацию между дата-центрами.
- Spanner [Corbett et al., 2012] предлагает SQL-подобный интерфейс для пользователей, которым требуется целостность и согласованность данных при доступе из любой точки мира.
- Доступны и некоторые другие системы баз данных, например Blobstore. Все они имеют свои достоинства и недостатки (см. главу 26).
Сеть
Сетевое оборудование Google управляется несколькими способами. Как говорилось ранее, мы используем программно-конфигурируемую сеть, основанную на OpenFlow. Вместо «умных» маршрутизаторов мы используем не столь дорогие «глупые» коммутаторы в сочетании с центральным (продублированным) контроллером, который заранее вычисляет лучший маршрут в сети. Это и позволяет использовать более простое коммутирующее оборудование, освободив его от трудоемкого поиска маршрута.
Пропускная способность сети должна грамотно распределяться. Как Borg ограничивает вычислительные ресурсы, которые может использовать задача, так и Bandwidth Enforcer (BwE) управляет доступной полосой пропускания так, чтобы максимизировать среднюю пропускную способность. Оптимизация пропускной способности связана не только со стоимостью: централизованное управление трафиком позволяет решить ряд проблем, которые крайне плохо поддаются решению сочетанием распределенной маршрутизации и обычного управления трафиком (Kumar, 2015).
Некоторые сервисы имеют задания, запущенные на нескольких кластерах, размещенных в разных точках мира. Для того чтобы снизить время задержки глобально распределенных систем, мы хотели бы направить пользователей в ближайший дата-центр, имеющий подходящие для этого мощности. Наш глобальный программный балансировщик нагрузки (Global Software Load Balancer, GSLB) выполняет балансировку нагрузки на трех уровнях:
- географическую балансировку нагрузки для DNS-запросов (например, к www.google.com), она описана в главе 19;
- балансировку нагрузки на уровне пользовательских сервисов (например, YouTube или Google Maps);
- балансировку нагрузки на уровне удаленных вызовов процедур (Remote Procedure Call, RPC), описанную в главе 20.
Владельцы сервисов задают для них символьные имена, список BNS-адресов серверов и производительность, доступную на каждой площадке (обычно она измеряется в запросах в секунду — queries per second, QPS). В дальнейшем GSLB направляет трафик по указанным BNS-адресам.
Другое системное ПО
В программном обеспечении дата-центров есть и другие важные компоненты.
Сервис блокировок
Сервис блокировок Chubby [Burrows, 2006] предоставляет API, схожий с файловой системой и предназначенный для обслуживания блокировок. Chubby обрабатывает блокировки всех дата-центров. Он использует протокол Paxos для асинхронного обращения к Consensus (см. главу 23).
Chubby также играет важную роль при выборе мастера. Если для какого-то сервиса с целью повышения надежности предусмотрено пять реплик задания, но в конкретный момент реальную работу выполняет только одна из них, то для выбора этой реплики используется Chubby.
Chubby отлично подходит для данных, которые требуют от хранилища надежности. По этой причине BNS использует Chubby для хранения соотношения BNS-путей и пар IP-адрес: порт.
Мониторинг и оповещение
Мы хотим быть уверены, что все сервисы работают как следует. Поэтому мы запускаем множество экземпляров программы мониторинга Borgmon (см. главу 10). Borgmon регулярно получает значения контрольных показателей от наблюдаемых сервисов. Эти данные могут быть использованы немедленно для оповещения или сохранены для последующей обработки и анализа, например для построения графиков. Такой мониторинг может применяться для таких целей, как:
- настройка оповещений о неотложных проблемах;
- сравнение поведения: ускорило ли обновление ПО работу сервера;
- оценка характера изменения потребления ресурсов со временем, что необходимо для планирования мощностей.
Наша инфраструктура ПО
Архитектура нашего ПО спроектирована так, чтобы можно было наиболее эффективно использовать аппаратные ресурсы системы. Весь наш код многопоточный, поэтому одна задача с легкостью может задействовать несколько ядер. В целях поддержки информационных панелей (dashboards), мониторинга и отладки каждый сервер включает в себя реализацию сервера HTTP в качестве интерфейса, через который предоставляется диагностическая информация и статистика по конкретной задаче.
Все сервисы Google «общаются» с помощью инфраструктуры удаленных вызовов процедур (RPC), которая называется Stubby. Существует ее версия с открытым исходным кодом, она называется gRPC (см. grpc.io). Зачастую вызов RPC выполняется даже для подпрограмм в локальной программе. Это позволяет переориентировать программу на вызовы другого сервера для достижения большей модульности или по мере разрастания исходного объема кода сервера. GSLB может выполнять балансировку нагрузки RPC точно так же, как и для внешних интерфейсов сервисов.
Сервер получает запросы RPC с фронтенда и отправляет RPC в бэкенд. Пользуясь традиционными терминами, фронтенд называется клиентом, а бэкенд — сервером.
Данные передаются в RPC и из них посредством протокола сериализации — так называемых протокольных буферов (protocol buffers), или, кратко, protobufs. Этот протокол похож на Thrift от Apache и имеет ряд преимуществ перед XML, когда речь идет о сериализации структурированных данных: он проще, от трех до десяти раз компактнее, от 20 до 100 раз быстрее и более однозначный.
Наша среда разработки
Скорость разработки продуктов очень важна для Google, поэтому мы создали специальную среду, максимально использующую возможности своей инфраструктуры [Morgenthaler et al., 2012].
За исключением нескольких групп, продукты которых имеют открытый код, и поэтому для них используются свои отдельные репозитории (например, Android и Chrome), инженеры-программисты Google работают в одном общем репозитории [Potvin, Levenberg, 2016]. Такой подход имеет несколько практических применений, важных для нашего производственного процесса.
- Если инженер сталкивается с проблемой в компоненте, за пределами своего проекта, он может исправить проблему, выслать предлагаемые изменения («список изменений» — changelist, CL) владельцу на рассмотрение и затем внедрить сделанные изменения в основную ветвь программы.
- Изменения исходного кода в собственном проекте инженера требуют рассмотрения — проведения ревизии (ревью). Весь софт перед принятием проходит этот этап.
Когда выполняется сборка ПО, запрос на сборку отправляется на специализированные серверы дата-центра. Даже сборка крупных проектов выполняется быстро, поскольку можно использовать несколько серверов для параллельной компиляции. Такая инфраструктура также применяется для непрерывного тестирования. Каждый раз, когда появляется новый список изменений (CL), выполняются тесты всего ПО, на которое могут повлиять эти изменения прямо или косвенно. Если фреймворк обнаруживает, что изменения нарушили работу других частей системы, он оповещает владельца этих изменений. Отдельные проекты используют систему push-on-green («отправка при успехе»), согласно которой новая версия автоматически отправляется в промышленную эксплуатацию после прохождения тестов.
Shakespeare: пример сервиса
Для того чтобы продемонстрировать, как в компании Google сервис разворачивается в среде промышленной эксплуатации, рассмотрим пример гипотетического сервиса, который взаимодействует с технологиями Google. Предположим, что мы хотим предложить сервис, который позволяет определить, в каких произведениях Шекспира встречается указанное вами слово.
Мы можем разделить систему на две части.
- Компонент пакетной обработки, который читает все тексты Шекспира, создает алфавитный указатель и записывает его в Bigtable. Эта задача (точнее, задание) выполняется однократно или, возможно, изредка (ведь может обнаружиться какой-нибудь новый текст Шекспира!).
- Приложение-фронтенд, обрабатывающее запросы конечных пользователей. Это задание всегда запущено, поскольку в любой момент времени пользователь из любого часового пояса может захотеть выполнить поиск по книгам Шекспира.
Компонентом пакетной обработки будет сервис MapReduce, чья работа делится на три фазы.
1. В фазе Mapping тексты Шекспира считываются и разбиваются на отдельные слова. Эта часть работы будет выполнена быстрее, если запустить параллельно несколько рабочих процессов (задач).
2. В фазе Shuffle записи сортируются по словам.
3. В фазе Reduce создаются кортежи вида (слово, список_произведений).
Каждый кортеж записывается в виде строки в Bigtable, ключом выступает слово.
Жизненный цикл запроса
На рис. 2.4 показано, как обслуживается запрос пользователя. Сначала пользователь переходит в браузере по ссылке shakespeare.google.com. Для получения соответствующего IP-адреса устройство пользователя транслирует («разрешает») адрес с помощью DNS-сервера (1). DNS-запрос в итоге оказывается на DNS-сервере Google, который взаимодействует с GSLB. Отслеживая загруженность трафиком всех фронтенд-серверов по регионам, GSLB выбирает, IP-адрес какого из серверов нужно возвратить пользователю.
Браузер соединяется с HTTP-сервером по указанному адресу. Этот сервер (он называется Google Frontend или GFE) представляет собой «обратный» прокси-сервер (reverse proxy), находящийся на другом конце TCP-соединения клиента (2). GFE выполняет поиск требуемого сервиса (например, это может быть поисковый сервис, карты или — в нашем случае — сервис Shakespeare). Повторно обращаясь к GSLB, сервер находит доступный фронтенд-сервер Shakespeare и обращается к нему посредством удаленного вызова процедуры (RPC), передавая полученный от пользователя HTTP-запрос (3).
Сервер Shakespeare анализирует HTTP-запрос и создает «протокольный буфер» (protobuf), содержащий слова, которые требуется найти. Теперь фронтенд-сервер Shakespeare должен связаться с бэкенд-сервером Shakespeare: первый связывается с GSLB, чтобы получить BNS-адрес подходящего и незагруженного экземпляра второго (4). Далее бэкенд-сервер Shakespeare связывается с сервером Bigtable для получения запрашиваемых данных (5).
Результат записывается в ответный protobuf и возвращается на бэкенд-сервер Shakespeare. Бэкенд передает protobuf с результатом работы сервиса фронтенд-серверу Shakespeare, который создает HTML-документ и возвращает его в качестве ответа пользователю.
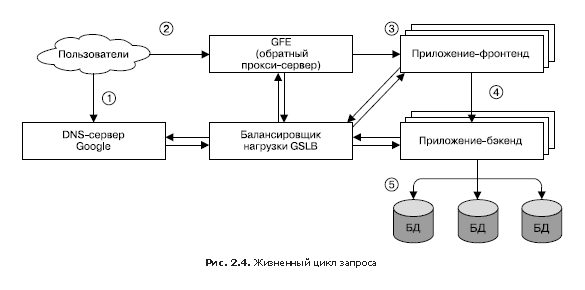
Вся эта цепочка событий выполняется в мгновение ока — всего за несколько сотен миллисекунд! Поскольку задействовано множество компонентов, существует множество мест, где потенциально может возникнуть ошибка; в частности, сбой в GSLB может дезорганизовать всю работу и привести к коллапсу. Однако политика Google, предусматривающая строгий контроль, всеобъемлющее тестирование и безопасное развертывание новых программ в дополнение к нашим упреждающим методам восстановления при ошибках (вроде постепенного отключения функций), позволяет нам создавать надежные сервисы, отвечающие ожиданиям наших пользователей. В конце концов, люди регулярно обращаются к сайту www.google.com чтобы проверить, есть ли подключение к Интернету.
Организация задач и данных
Тестирование нагрузки показало, что наш бэкенд-сервер может обработать около 100 запросов в секунду (QPS). Опытная эксплуатация с ограниченным количеством пользователей показала, что пиковая нагрузка может достигать примерно 3470 QPS, поэтому нам нужно создавать как минимум 35 задач. Однако следующие соображения говорят, что нам понадобится как минимум 37 задач, или N + 2.
- Во время обновления одна задача будет временно недоступна, поэтому активными будут оставаться 36 задач.
- Во время обновления может произойти сбой в аппаратной части, из-за чего останется всего 35 задач — ровно столько, сколько нужно для обслуживания пиковой нагрузки.
Более подробное исследование пользовательс��ого трафика обнаруживает географическое распределение пиковой нагрузки: 1430 QPS генерируются из Северной Америки, 290 — из Южной Америки, 1400 — из Европы и 350 — из Азии и Австралии. Вместо того чтобы размещать все бэкенд-серверы в одном месте, мы распределяем их по регионам: в США, Южной Америке, Европе и Азии. Учитывая принцип N + 2 в каждом регионе, получаем 17 задач в США, 16 — в Европе и шесть — в Азии. В Южной Америке, однако, мы решаем использовать четыре задачи (вместо пяти), чтобы снизить затраты — с N + 2 до N + 1. В этом случае мы готовы взять на себя небольшой риск появления большего времени задержки и снизить стоимость оборудования: разрешив GSLB при перегрузке южноамериканского дата-центра перенаправлять трафик с одного континента на другой, мы можем сэкономить 20 % ресурсов, которые были бы потрачены на оборудование. В более крупных регионах для дополнительной устойчивости мы распределяем задачи между 2–3 кластерами.
Поскольку бэкенд-сервера должны связываться с хранилищем данных Bigtable, нам также нужно стратегически продумать это хранилище. Если бэкенд-сервер Азии будет связываться с Bigtable, расположенным в США, это приведет к значительному увеличению задержек, поэтому мы дублируем Bigtable в каждом регионе. Это дает нам дополнительную устойчивость на тот случай, если сервер Bigtable даст сбой, а также снижает время задержки доступа к данным. И хотя Bigtable не обеспечивает строгое соответствие данных между экземплярами в любой момент времени, дублирование не становится серьезной проблемой, ведь нам не требуется слишком часто обновлять содержимое хранилища.
Итак, в этой главе вы познакомились с множеством понятий и терминов. Хотя вам не нужно запоминать их все, они могут оказаться полезными при изучении многих других систем, которые мы рассмотрим далее.
» Более подробно с книгой можно ознакомиться на сайте издательства
» Оглавление
» Отрывок
Для Хаброжителей скидка 20% по купону — Site Reliability Engineering

