

Сегодня одним из главных препятствий на пути внедрения машинного обучения в бизнес является несовместимость метрик ML и показателей, которыми оперирует топ-менеджмент. Аналитик прогнозирует увеличение прибыли? Но ведь нужно понять, в каких случаях причиной увеличения станет именно машинное обучение, а в каких — прочие факторы. Увы, но довольно часто улучшение метрик ML не приводит к росту прибыли. К тому же иногда сложность данных такова, что даже опытные разработчики могут выбрать некорректные метрики, на которые нельзя ориентироваться.
Давайте рассмотрим, какие бывают метрики ML и когда их целесообразно использовать. Разберём типичные ошибки, а также расскажем о том, какие варианты постановки задачи могут подойти для машинного обучения и бизнеса.
ML-метрики: зачем их так много?
Метрики машинного обучения весьма специфичны и часто вводят в заблуждение, показывая
Какие задачи чаще всего решаются с помощью машинного обучения? В первую очередь это регрессия, классификация и кластеризация. Первые две — так называемое обучение с учителем: есть набор размеченных данных, на основе какого-то опыта нужно предсказать заданное значение. Регрессия — это предсказание какого-то значения: например, на какую сумму купит клиент, какова износостойкость материала, сколько километров проедет автомобиль до первой поломки.
Кластеризация — это определение структуры данных с помощью выделения кластеров (например, категорий клиентов), причём у нас нет предположений об этих кластерах. Этот тип задач мы рассматривать не будем.
Алгоритмы машинного обучения оптимизируют (вычисляя функцию потерь) математическую метрику — разность между предсказанием модели и истинным значением. Но если метрика представляет собой сумму отклонений, то при одинаковом количестве отклонений в обе стороны эта сумма будет равна нулю, и мы просто не узнаем о наличии ошибки. Поэтому обычно используют среднюю абсолютную (сумма абсолютных значений отклонений) или среднюю квадратичную ошибку (сумма квадратов отклонений от истинного значения). Иногда формулу усложняют: берут логарифм или извлекают квадратный корень из этих сумм. Благодаря этим метрикам можно оценить динамику качества вычислений модели, но для этого полученный результат нужно с чем-то сравнить.
C этим не возникнет сложностей, если уже есть построенная модель, с которой можно сравнить полученные результаты. А что если вы в первый раз создали модель? В этом случае часто используют коэффициент детерминации, или R2. Коэффициент детерминации выражается как:

Где:
R^2 — коэффициент детерминации,
et^2 — средняя квадратичная ошибка,
yt — верное значение,
yt с крышкой — среднее значение.
Единица минус отношение средней квадратичной ошибки модели к средней квадратичной ошибке среднего значения тестовой выборки.
То есть коэффициент детерминации позволяет оценить улучшение предсказания моделью.
Иногда бывает, что ошибка в одну сторону неравнозначна ошибке в другую. Например, если модель предсказывает заказ товара на склад магазина, то вполне можно ошибиться и заказать чуть больше, товар дождётся своего часа на складе. А если модель ошибётся в другую сторону и закажет меньше, то можно и потерять покупателей. В подобных случаях используют квантильную ошибку: положительные и отрицательные отклонения от истинного значения учитываются с разными весами.
В задаче классификации модель машинного обучения распределяет объекты по двум классам: уйдет пользователь с сайта или не уйдет, будет деталь бракованной или нет, и т.д. Точность предсказания часто оценивают как отношение количества верно определенных классов к общему количеству предсказаний. Однако эту характеристику редко можно считать адекватным параметром.
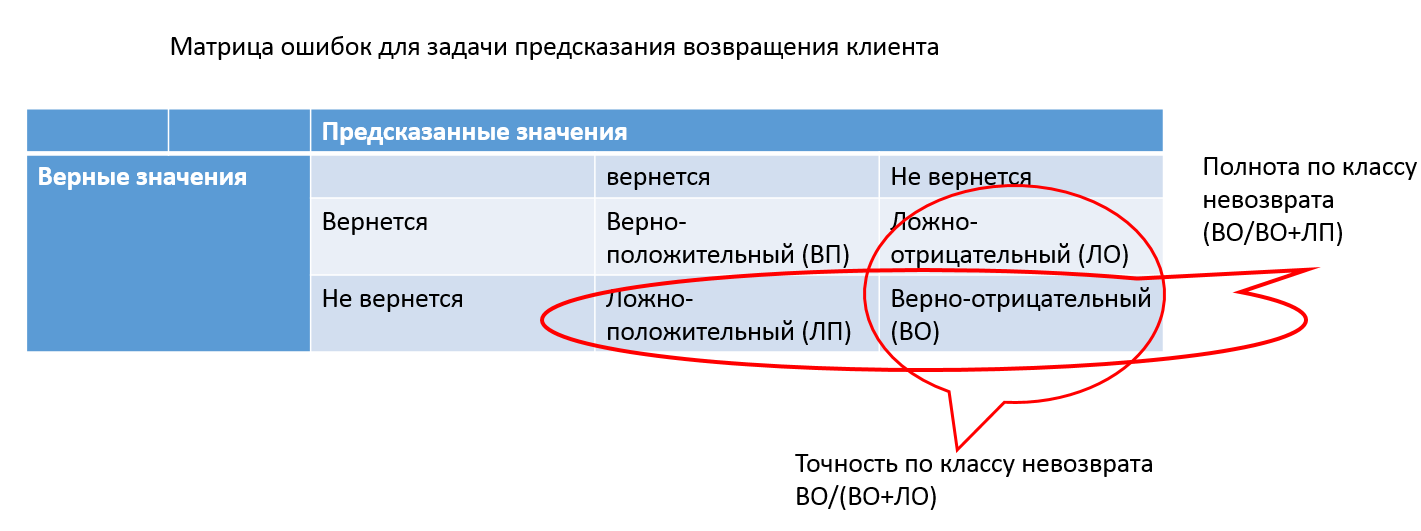
Рис. 1. Матрица ошибок для задачи предсказания возвращения клиента
Пример: если из 100 застрахованных за возмещением обращаются 7 человек, то модель, предсказывающая отсутствие страхового случая, будет иметь точность 93%, не имея никакой предсказательной силы.

Рис. 2. Пример зависимости фактической прибыли компании от точности модели в случае разбалансированных классов
Для каких-то задач можно применить метрики полноты (количество правильно определенных объектов класса среди всех объектов этого класса) и точности (количество правильных определенных объектов класса среди всех объектов, которые модель отнесла к этому классу). Если необходимо учитывать одновременно полноту и точность, то применяют среднее гармоническо�� между этими величинами (F1-мера).
С помощью этих метрик можно оценить выполненное разбиение по классам. При этом многие модели предсказывают вероятность отношения модели к определенному классу. С этой точки зрения можно изменять порог вероятности, относительно которого элементы будут присваиваться к одному или другому классу (например, если клиент уйдёт с вероятностью 60 %, то его можно считать остающимися). Если конкретный порог не задан, то для оценки эффективности модели можно построить график зависимости метрик от разных пороговых значений (ROC-кривая или PR-кривая), взяв в качестве метрики площадь под выбранной кривой.

Рис. 3. PR-кривая
Бизнес-метрики
Выражаясь аллегорически, бизнес-метрики — это слоны: их невозможно не заметить, и в одном таком «слоне» может уместиться большое количество «попугаев» машинного обучения. Ответ на вопрос, какие метрики ML позволят увеличить прибыль, зависит от улучшения. По сути, бизнес-метрики так или иначе привязаны к увеличению прибыли, однако нам почти никогда не удаётся напрямую связать с ними прибыль. Обычно применяются промежуточные метрики, например:
- длительность нахождения товара на складе и количество запросов товара, когда его нет в наличии;
- количество денег у клиентов, которые собираются уйти;
- количество материала, которое экономится в процессе производства.
Когда речь идёт об оптимизации бизнеса с помощью машинного обучения, всегда подразумевается создание двух моделей: предсказательной и оптимизационной.
Первая сложнее, её результаты использует вторая. Ошибки в модели предсказания вынуждают закладывать больший запас в модели оптимизации, поэтому оптимизируемая сумма уменьшается.
Пример: чем ниже точность предсказания поведения клиентов или вероятности промышленного брака, тем меньше клиентов удаётся удержать и тем меньше объём сэкономленных материалов.
Общепринятые метрики успешности бизнеса (EBITDA и др.) редко получается использовать при постановках задач ML. Обычно приходится глубоко изучать специфику и применять метрики, принятые в той сфере, в который мы внедряем машинное обучение (средний чек, посещаемость и т.д.).
Трудности перевода
По иронии судьбы удобнее всего оптимизировать модели с помощью метрик, которые трудно понять представителям бизнеса. Как площадь под ROC-кривой в модели определения тональности комментария соотносится с конкретным размером выручки? С этой точки зрения перед бизнесом встают две задачи: как измерить и как максимизировать эффект от внедрения машинного обучения?
Первая задача проще в решении, если у вас есть ретроспективные данные и при этом остальные факторы можно нивелировать или измерить. Тогда ничто не мешает сравнить полученные значения с аналогичными ретроспективными данными. Но есть одна сложность: выборка должна быть репрезентативна и при этом максимально похожа на ту, с помощью которой мы апробируем модель.
Пример: нужно найти самых похожих клиентов, чтобы выяснить, увеличился ли у них средний чек. Но при этом выборка клиентов должна быть достаточно большой, чтобы избежать всплесков из-за нестандартного поведения. Эту задачу можно решить с помощью предварительного создания достаточно большой выборки похожих клиентов и на ней проверять результат своих усилий.
Однако вы спросите: как перевести выбранную метрику в функцию потерь (минимизацией которой и занимается модель) для машинного обучения. С наскока эту задачу не решить: разработчикам модели придётся глубоко вникнуть в бизнес-процессы. Но если при обучении модели использовать метрику, которая зависит от бизнеса, качество моделей сразу вырастает. Скажем, если модель предсказывает, какие клиенты уйдут, то в роли бизнес-метрики можно использовать график, где по одной оси отложено количество уходящих, по мнению модели, клиентов, а по другой оси — общий объём средств у этих клиентов. С помощью такого графика бизнес-заказчик может выбрать удобную для себя точку и работать с ней. Если с помощью линейных преобразований свести график к PR-кривой (по одной оси точность, по второй полнота), то можно оптимизировать площадь под этой кривой одновременно с бизнес-метрикой.
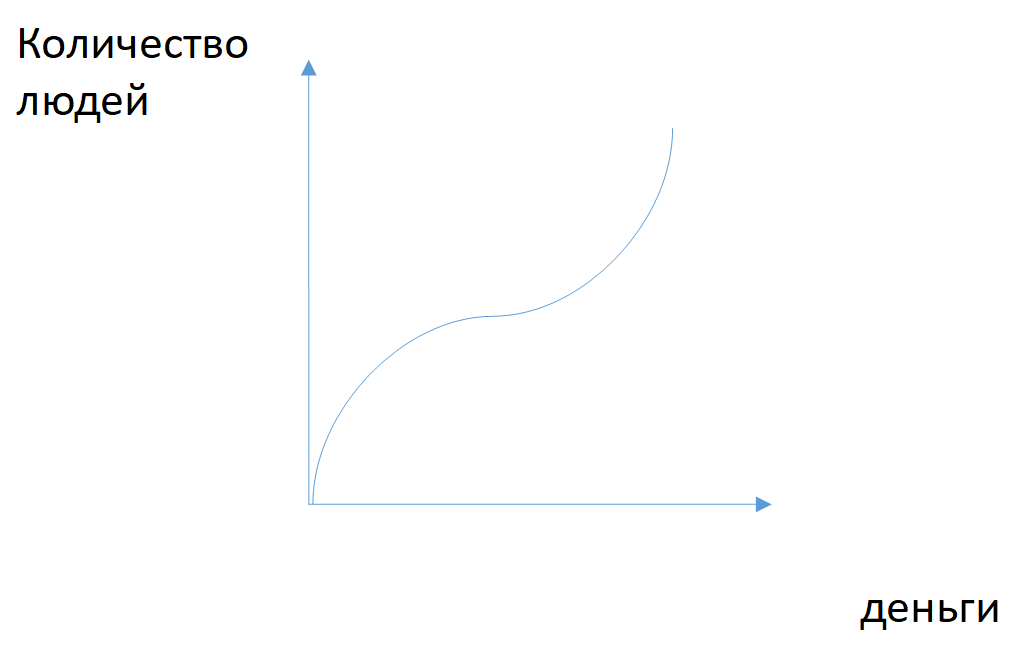
Рис. 4. Кривая денежного эффекта
Заключение
Прежде чем ставить задачу для машинного обучения и создавать модель, нужно выбрать разумную метрику. Если вы собираетесь оптимизировать модель, то в качестве функции ошибок можно использовать одну из стандартных метрик. Обязательно согласуйте с заказчиком выбранную метрику, её веса и прочие параметры, преобразовав бизнес-метрики в модели ML. По длительности это может быть сравнимо с разработкой самой модели, но без этого не имеет смысла приступать к работе. Если привлечь математиков к изучению бизнес-процессов, то можно сильно уменьшить вероятность ошибок в метриках. Эффективная оптимизация модели невозможна без понимания предметной области и совместной постановки задачи на уровне бизнеса и статистики. И уже после проведения всех расчётов вы сможете оценить полученную прибыль (или экономию) в зависимости от каждого улучшения модели.
Николай Князев (iRumata), руководитель группы машинного обучения «Инфосистемы Джет»
