Всем привет! В этот раз я хочу написать о том, как мне удалось победить в соревновании Mini AI Cup 2. Как и в моей прошлой статье, деталей реализации практически не будет. В этот раз задача была менее объёмной, но всё же нюансов и мелочей, влияющих на поведение бота, было немало. В итоге даже после почти трёх недель активной работы над ботом всё ещё оставались идеи, как улучшать стратегию.
Под катом много гифок и трафика.
Стойкие разберутся, остальные убегут в ужасе (из комментариев ккраткой сжатой части).
Те, кому лень много читать, могут перейти к предпоследнему спойлеру статьи, чтобы просмотретькраткое сжатое описание алгоритма, а потом можно начать читать сначала.
Ссылка на исходники на гитхабе.
Как и в прошлый раз, у меня ушло достаточно много времени на обдумывание, с чего же начать. Выбор был в том числе между двумя языками: привычной мне Java и уже достаточно забытым со студенческих времён C++. Но поскольку с самого начала мне казалось, что основным препятствием для написания хорошего бота будет не столько скорость разработки, сколько производительность итогового решения, выбор всё же пал на С++.
После успешного опыта применения собственного визуализатора для отладки бота в предыдущих соревнованиях я не хотел обходиться без такового и на этот раз. Но тот визуализатор, который я написал для себя на Qt для CodeWars, не выглядел для меня идеальным решением, и я решил воспользоваться этим визуализатором. Он также был сделан под CodeWars, но не требовал серьёзной переработки для использования и в данном соревновании. В его пользу сыграла относительная простота в подключении и удобство вызова отрисовки в любом месте кода.
Как и раньше, я очень хотел дебаг любого тика в игре — наличие возможности запустить стратегию на произвольном моменте протестированной игры. Поскольку подключаемым визуализатором эта задача решаться не могла, то с помощью пары #ifdef (в которые я также оборачивал куски кода, ответственные за отрисовку) я добавил на каждый тик сохранение класса Context, в котором лежали все нужные значения переменных с предыдущего тика. По своей сути решение было похожим на то, что использовалось мной в Code Wizards, но на этот раз подход был сформирован не так стихийно. После симуляции всей игры запрашивался ввод номера игрового тика, который нужно запустить повторно. Из массива доставалась информация о состоянии переменных перед этим тиком, как и строка, полученная стратегией на входе, что позволяло проигрывать ходы моей стратегии в любом необходимом порядке.
В день открытия правил я не прошёл мимо и в первый же вечер посмотрел, что нас ждёт. Не погнушался повозмущаться json формату ввода (да, удобно, но некоторые участники начинают осваивать новые или давно забытые старые ЯП на таких соревнованиях, а стартовать с парсинга json не самое приятное), посмотрел на странную формулу движения и кое-как приступил к формированию каркаса будущей стратегии (для понимания статьи в дальнейшем полезно почитать правила). За 2 дня написал кучу классов вроде Ejection, Virus, Player и прочих, считывание json’a, подключения однофайловой библиотеки для логирования… И в вечер открытия нерейтинговой песочницы у меня уже была стратегия по силе и по принципу почти полностью повторяющая бейзлайн на C++, но значительно, значительно большая по размеру кода.
А дальше… Начал прикидывать варианты, как же её развивать. Мысли на тот момент:
Точно определился с одним: надо делать симуляцию мира. Ведь не могут приближённые вычисления “побить” холодный и точный расчёт? Такие соображения, конечно, побудили меня заглянуть в код, который должен был отвечать за симуляцию мира на сервере, ведь на этот раз его выложили в открытый доступ вместе с правилами. Ведь нет ничего лучше кода, который должен точно описывать правила мира?
Так я думал ровно до тех пор, пока не начал изучать код, который должен был тестировать наших ботов на сервере и локально. Изначально в плане понятности и корректности кода всё было не очень хорошо, и организаторы совместно с участниками начали активно его перерабатывать. За время бета-теста (захватив ещё пару дней после него) изменения игрового движка были весьма серьёзными, и многие не начинали участия до того момента, когда тестирующий движок не стабилизируется. Но в итоге дождались, на мой взгляд, неплохо работающего движка к очень подходящей под формат соревнований игре. Я также не начинал реализовывать сколь-либо серьёзных подходов до момента стабилизации работы локал раннера, и за первую неделю больше ничего толкового в моём боте, кроме прикрученного визуализатора, не делалось.
Накануне первых выходных вечером в телеграмме организаторами была создана отдельная группа, в которой предполагалось, что люди смогут помогать исправлять и улучшать локал раннер. Я также принял участие в работе над движком мира. После обсуждений в этом чате я в качестве пробы сделал 2 пулл реквеста в локал раннер: приводящий в соответствие с правилами формулы поедания (и небольшими правками по очерёдности съедения), и слияние нескольких частей в один агарик с сохранением инерции и центра масс). Затем я начал размышлять, как бы в этот код вставить вменяемую физику столкновений, потому что физика, присутствующая в игровом мире на тот момент, работала очень нелогично. Поскольку коллизии между двумя агариками в правилах не были описаны, я спросил у организаторов критерии, по которым моя реализация такой логики была бы приемлемой. Ответ был таков: агарики при столкновении должны быть “мягкими” (то есть могли немного заезжать друг на друга), при этом логику столкновения со стенами трогать не надо (т.е. стены должны просто останавливать агариков, но не отталкивать их). И следующим моим пулл реквестом была серьёзная переделка физики.
Отдельно хочется выделить ещё этот пулл реквест, который достаточно значительно сократил запутанный код с разбором состояний и большим количеством найденных (и потенциальных) багов во что-то куда более вразумительное.
После приведения кода локал раннера во вменяемый вид я постепенно начал переносить код симуляции мира из локал раннера в своего бота. В первую очередь это был, конечно же, код симуляции движения агариков, а заодно и код вычисления физики столкновений. Пару вечеров ушло на то, чтобы избавить переработанный код от багов переписывания (перенос логики проходил совсем не копированием кода) и примерные прикидки, насколько глубоко по ходам надо проводить вычисления.
Функция оценки на каждый тик на этот момент представляла собой +1 за съеденную мной еду и -1 за съеденную еду противником, а также чуть большие значения за съедение агариков друг друга. В константах за съедение других агариков изначально была разница между съедением мной соперника, соперником меня (и конечно же очень большой штраф за съедения соперником моего последнего агарика), а также двух разных соперников друг друга (через пару дней последний коэффициент стал равен 0). Кроме этого суммарный скор за все предыдущие тики симуляции каждый тик умножался на 1 + 1e-5, чтобы стимулировать моего бота выполнять более полезные действия хоть немного раньше, а в конце симуляции в качестве бонуса добавлялся скор за скорость движения в последний тик, также очень небольшой. Для симуляции движения агариков выбирались точки на крае карты с шагом 15 градусов от среднеарифметических координат всех моих агариков и выбиралась точка, при симуляции движения к которой функция оценки принимала наибольшее значение. И уже с такой вроде бы примитивной симуляцией и несложной оценкой на тот момент бот вполне себе уверенно закрепился в топ 10.
За вечер пятницы и субботу была добавлена симуляция слияния агариков, симуляция “подрыва” на вирусах, угадывание TTF соперника. TTF соперника был достаточно интересной вычисляемой величиной, и понять, в какой момент соперник сделал сплит или попал на вирус можно было только поймав момент неуправляемого полёта, который мог длиться от очень небольшого кол-ва тиков при большом viscosity и до полёта через всю карту. Поскольку столкновения агариков могли привести к небольшому превышению ими максимальной скорости, то для вычисления TTF соперника я сделал проверку, что его скорость два тика подряд действительно соответствует скорости, которую можно получить в свободном полёте два тика подряд (в свободном полёте агарики летели строго прямо и с замедлением каждый тик, строго равным viscosity). Это практически полностью исключало вероятность ложного срабатывания. Также в процессе тестирования этой логики заметил, что больший TTF всегда соответствует большему id агарика (в чём впоследствии убедился при переносе кода взрыва на вирусе и обработки сплита), чем тоже стоило воспользоваться.
Насмотревшись на постоянные сплиты в топ 3 (что позволяло им ощутимо быстрее собирать еду на карте), в качестве теста я добавил боту постоянную команду split, если в радиусе видимости не было противника, а утром воскресенья обнаружил своего бота на второй строчке рейтинга. Управление кучкой мелких агариков сильно поднимало в рейтинге, но и проиграть ими было куда как легче, если неудачно наткнуться на соперника. А так как страх быть съеденными мои агарики имели очень условный (штраф был только за съедение в симуляции, но не за приближение к сопернику, который мог съесть), то первым делом был добавлен штраф за пересечение с соперником, который мог съесть. И эта же оценка зеркально работала как бонус за преследование соперника. Проверив потребление CPU своей стратегией, я решил добавить ещё один круг симуляции, когда на первом тике делался split (эту логику, конечно же, также потребовалось переносить к себе в код из локал раннера), а затем симуляция проходила точно так же, как и ранее. Такой вариант логики не очень подходил для “стрельбы” в противника (хотя иногда случайно и делал сплит в очень подходящий момент), но очень неплохо подошёл для более быстрого собирания еды, чем и занимался на тот момент весь топ. Такие модификации позволили войти в следующую неделю на первой строчке рейтинга, хотя отрыв был несущественный.
На тот момент этого было вполне достаточно, “костяк” стратегии был выработан, стратегия выглядела достаточно примитивной и расширяемой. Но на что я действительно обратил внимание, так это на потребление CPU и общую стабильность кода. Поэтому в основном вечера следующей рабочей части недели были посвящены улучшение точности симуляций (в чём очень помогал визуализатор), стабилизация кода (valgrind) и некоторым оптимизациям скорости работы.
Следующая моя отправленная стратегия, которая показала ощутимо лучший результат и ушла в отрыв от соперников (на тот момент), содержала два существенных изменения: добавление потенциального поля для сбора еды и удвоение количества симуляций, если рядом есть противник с неизвестным TTF.
Потенциальное поле для сбора еды в первой версии было достаточно несложным и вся его суть сводилась к запоминанию еды, которая пропала из зоны видимости, уменьшение потенциала в тех местах, рядом с которыми находился бот противника и обнуление в зоне моей видимости (с последующим восстановлением каждые n тиков в соответствии с правилами). Это казалось полезным улучшением, однако на практике по моему субъективному мнению разница либо была небольшой, либо вовсе отсутствовала. Например на картах с большой инерцией и скоростью бот часто проскакивал мимо еды и затем пытался к ней вернуться, при этом сильно теряя в скорости. Однако если бы он решил сохранить скорость и просто проигнорировал пропущенную еду, то ел бы ощутимо больше.
Совсем другой по субъективной полезности оказалась двойная симуляция противника с различными TTF — минимально и максимально возможным (в случае, если я не знаю TTF для всех видимых агариков на карте). И если раньше мой бот думал, что вражеская кучка агариков на следующий тик станет единым целым и будет медленно передвигаться, то теперь он выбирал худший сценарий из двух и не рисковал находиться близко к противнику, про которого он знает меньше, чем хотел бы.
После получения существенного преимущества я попытался его увеличить, добавив определение точки, в которую соперник командует своим агарикам двигаться, и хотя такую точку получилось вычислять в большинстве случаев достаточно точно, само по себе это не принесло улучшения результатов бота. По моим наблюдениям становилось даже хуже варианта, когда агарики соперника просто двигались в том же направлении и с той же скоростью, как если бы соперник ничего не предпринимал, поэтому эти правки были сохранены в отдельной гит ветке до лучших времён.
Также были попытки перевести функцию оценки на оценку полученной массы, попытки изменить функцию оценки опасности соперника… Но опять же все такие изменения по ощущениям делали даже хуже. Единственное, что было сделано полезного с функцией оценки опасности от нахождения рядом с противником — очередные оптимизации производительности наряду с распространением этой оценки на куда больший радиус, нежели радиус пересечения с противником (по сути на всю карту, но с квадратичным убыванием, если чуть упрощённо — делая присутствие в пяти и более радиусах от соперника в районе 1/25 от максимальной опасности быть съеденным). Последнее изменение также незапланированно привело к тому, что мои агарики стали сильно бояться приближаться к ощутимо более крупному противнику, равно как и в случае своих сильно превосходящих размеров были более склонны подвинуться в сторону соперника. Таким образом, получилась удачная и не ресурсоёмкая замена запланированному на будущее коду, который должен был отвечать за боязнь атаки соперника через сплит (и небольшая помощь в такой атаке мне впоследствии).
После долгих и относительно бесплодных попыток что-то улучшить я ещё раз вернулся к предсказанию направления движения соперника. Решил попробовать раз уж не просто заменить dummy соперников, то поступить так, как я поступил с минимальным и максимальным вариантом TTF — просимулировать дважды и выбрать лучший из вариантов. Но для этого уже могло не хватить CPU, и во многих играх моего бота просто могли отключить от системы из-за неуёмного аппетита. Поэтому, прежде чем реализовать такой вариант, я добавил приблизительное определение потраченного времени и в случае превышения лимитов начинал уменьшать количество ходов симуляции. Добавив двойную симуляцию противника для случая, когда я знаю место, куда он направляется, я снова получил достаточно серьёзный прирост на большинстве настроек игр, кроме самых ресурсоёмких (с большой инерцией/малой скоростью/низким viscosity), на которых из-за сильного уменьшения глубины симуляции всё могло стать даже немного хуже.
Перед началом игр на 25к тиков были сделаны ещё две полезные доработки: штраф за окончание симуляции далеко от центра карты, а также запоминание предыдущей позиции соперника в случае его выхода из зоны видимости (а также симуляцию его движения в это время). Реализация штрафа за конечное положение бота в симуляции представляла из себя предподсчитаное статичное поле опасности с нулевой опасностью в радиусе, чуть большим половины длины игрового поля и постепенным увеличением её по мере удаления от игрового поля. Применение штрафа этого поля в конечных точках симуляции почти не требовало CPU и предотвращало лишние забегания в углы, иногда спасая от атак противника. А запоминание с последующей симуляцией соперников по большей части позволяло избежать двух иногда проявляющихся проблем. Первая проблема представлена на гифке ниже. Вторая проблема заключалась в том, что при потере из поля видимости более крупного врага (например, после слияния своих частей) можно было “удачно” сплитнуться в него, ещё дополнительно подкормив и без того опасного соперника.
Также к точкам на краю карты были добавлены дополнительные точки симуляции движения: к каждому агарику соперников и в радиусе от среднеарифметической координаты моих агариков каждые 45 градусов. Радиус был установлен в avgDistance от среднеарифметического координат моих агариков.
На момент открытия игр на 25к тиков и прохождения в финал у меня был солидный отрыв, но расслабляться я не планировал.
Вместе с новой длительностью игр по 25к пришли и новости: игры во время финала тоже будет длительностью в 25к, а ограничение времени работы стратегии на тик стало чуть больше. Оценив время, которое тратит моя стратегия на игру в новых условиях, я решил добавить ещё один вариант симуляции: делаем всё, как обычно, но во время симуляции на ходу n делаем сплит. Это в том числе потребовало на последующих ходах как базовый скор для всех симуляций применять симуляцию, найденную на предыдущем шаге, но со сдвигом на 1 ход (т.е. если мы нашли, что идеальным вариантом будет сплит на 7 тике от текущего, то на следующий ход повторяем то же самое, но сплит сделаем уже на 6 ходу). Это существенно добавило агрессивных атак на соперников, но съело ещё немного времени работы стратегии.
Все дальнейшие доработки были связаны исключительно с эффективностью работы симуляций в случае нехватки TL: оптимизация очерёдности отключения тех или иных частей логики в зависимости от потребляемого CPU. На большей части игр это не должно было изменить ничего, но придумать что-то более правильное тогда не вышло.
В целом старт этого соревнования получился достаточно смазанный, но за первые полторы недели не без помощи участников задача была приведена в достаточно играбельный вид. Изначально задача была очень вариативна, и выбрать правильный подход к её решению не показалось тривиальной задачей. Ещё более интересно было придумывать способы улучшить алгоритм, не вылетев за пределы потребления CPU. Организаторам большое спасибо за проведённое соревнование и за выкладку исходников мира в открытый доступ. Последнее, конечно, очень добавило им проблем на старте, но сильно облегчило (если не сказать, что сделало возможным в принципе) участникам понимание устройства симулятора мира. Отдельное большое спасибо за возможность выбора приза! Так приз вышел куда как более полезным :-)Зачем мне ещё один макбук?
Под катом много гифок и трафика.
Стойкие разберутся, остальные убегут в ужасе (из комментариев к
Те, кому лень много читать, могут перейти к предпоследнему спойлеру статьи, чтобы просмотреть
Ссылка на исходники на гитхабе.
Выбор инструментов
Как и в прошлый раз, у меня ушло достаточно много времени на обдумывание, с чего же начать. Выбор был в том числе между двумя языками: привычной мне Java и уже достаточно забытым со студенческих времён C++. Но поскольку с самого начала мне казалось, что основным препятствием для написания хорошего бота будет не столько скорость разработки, сколько производительность итогового решения, выбор всё же пал на С++.
После успешного опыта применения собственного визуализатора для отладки бота в предыдущих соревнованиях я не хотел обходиться без такового и на этот раз. Но тот визуализатор, который я написал для себя на Qt для CodeWars, не выглядел для меня идеальным решением, и я решил воспользоваться этим визуализатором. Он также был сделан под CodeWars, но не требовал серьёзной переработки для использования и в данном соревновании. В его пользу сыграла относительная простота в подключении и удобство вызова отрисовки в любом месте кода.
Как и раньше, я очень хотел дебаг любого тика в игре — наличие возможности запустить стратегию на произвольном моменте протестированной игры. Поскольку подключаемым визуализатором эта задача решаться не могла, то с помощью пары #ifdef (в которые я также оборачивал куски кода, ответственные за отрисовку) я добавил на каждый тик сохранение класса Context, в котором лежали все нужные значения переменных с предыдущего тика. По своей сути решение было похожим на то, что использовалось мной в Code Wizards, но на этот раз подход был сформирован не так стихийно. После симуляции всей игры запрашивался ввод номера игрового тика, который нужно запустить повторно. Из массива доставалась информация о состоянии переменных перед этим тиком, как и строка, полученная стратегией на входе, что позволяло проигрывать ходы моей стратегии в любом необходимом порядке.
Начало
В день открытия правил я не прошёл мимо и в первый же вечер посмотрел, что нас ждёт. Не погнушался повозмущаться json формату ввода (да, удобно, но некоторые участники начинают осваивать новые или давно забытые старые ЯП на таких соревнованиях, а стартовать с парсинга json не самое приятное), посмотрел на странную формулу движения и кое-как приступил к формированию каркаса будущей стратегии (для понимания статьи в дальнейшем полезно почитать правила). За 2 дня написал кучу классов вроде Ejection, Virus, Player и прочих, считывание json’a, подключения однофайловой библиотеки для логирования… И в вечер открытия нерейтинговой песочницы у меня уже была стратегия по силе и по принципу почти полностью повторяющая бейзлайн на C++, но значительно, значительно большая по размеру кода.
А дальше… Начал прикидывать варианты, как же её развивать. Мысли на тот момент:
- Перебор по состояниям мира никак не сократить до тех величин, что может осилить минимакс и модификации;
- Потенциальные поля — это хорошо, но они плохо отвечают на вопрос, как мир будет меняться следующие n тиков;
- Генетика и подобные алгоритмы работать будут, но на ход дано всего 20 мсек, а глубину расчёта хочется, на первый взгляд, больше, чем по ощущениям можно обработать с помощью ГА. Да и играть с подбором параметров мутаций можно “долго и счастливо”.
Точно определился с одним: надо делать симуляцию мира. Ведь не могут приближённые вычисления “побить” холодный и точный расчёт? Такие соображения, конечно, побудили меня заглянуть в код, который должен был отвечать за симуляцию мира на сервере, ведь на этот раз его выложили в открытый доступ вместе с правилами. Ведь нет ничего лучше кода, который должен точно описывать правила мира?
Так я думал ровно до тех пор, пока не начал изучать код, который должен был тестировать наших ботов на сервере и локально. Изначально в плане понятности и корректности кода всё было не очень хорошо, и организаторы совместно с участниками начали активно его перерабатывать. За время бета-теста (захватив ещё пару дней после него) изменения игрового движка были весьма серьёзными, и многие не начинали участия до того момента, когда тестирующий движок не стабилизируется. Но в итоге дождались, на мой взгляд, неплохо работающего движка к очень подходящей под формат соревнований игре. Я также не начинал реализовывать сколь-либо серьёзных подходов до момента стабилизации работы локал раннера, и за первую неделю больше ничего толкового в моём боте, кроме прикрученного визуализатора, не делалось.
Накануне первых выходных вечером в телеграмме организаторами была создана отдельная группа, в которой предполагалось, что люди смогут помогать исправлять и улучшать локал раннер. Я также принял участие в работе над движком мира. После обсуждений в этом чате я в качестве пробы сделал 2 пулл реквеста в локал раннер: приводящий в соответствие с правилами формулы поедания (и небольшими правками по очерёдности съедения), и слияние нескольких частей в один агарик с сохранением инерции и центра масс). Затем я начал размышлять, как бы в этот код вставить вменяемую физику столкновений, потому что физика, присутствующая в игровом мире на тот момент, работала очень нелогично. Поскольку коллизии между двумя агариками в правилах не были описаны, я спросил у организаторов критерии, по которым моя реализация такой логики была бы приемлемой. Ответ был таков: агарики при столкновении должны быть “мягкими” (то есть могли немного заезжать друг на друга), при этом логику столкновения со стенами трогать не надо (т.е. стены должны просто останавливать агариков, но не отталкивать их). И следующим моим пулл реквестом была серьёзная переделка физики.
До и после переделки физики
Такая физика столкновений была:
И такой она стала после обновлений:
И такой она стала после обновлений:
Отдельно хочется выделить ещё этот пулл реквест, который достаточно значительно сократил запутанный код с разбором состояний и большим количеством найденных (и потенциальных) багов во что-то куда более вразумительное.
Пишем симуляцию
После приведения кода локал раннера во вменяемый вид я постепенно начал переносить код симуляции мира из локал раннера в своего бота. В первую очередь это был, конечно же, код симуляции движения агариков, а заодно и код вычисления физики столкновений. Пару вечеров ушло на то, чтобы избавить переработанный код от багов переписывания (перенос логики проходил совсем не копированием кода) и примерные прикидки, насколько глубоко по ходам надо проводить вычисления.
Функция оценки на каждый тик на этот момент представляла собой +1 за съеденную мной еду и -1 за съеденную еду противником, а также чуть большие значения за съедение агариков друг друга. В константах за съедение других агариков изначально была разница между съедением мной соперника, соперником меня (и конечно же очень большой штраф за съедения соперником моего последнего агарика), а также двух разных соперников друг друга (через пару дней последний коэффициент стал равен 0). Кроме этого суммарный скор за все предыдущие тики симуляции каждый тик умножался на 1 + 1e-5, чтобы стимулировать моего бота выполнять более полезные действия хоть немного раньше, а в конце симуляции в качестве бонуса добавлялся скор за скорость движения в последний тик, также очень небольшой. Для симуляции движения агариков выбирались точки на крае карты с шагом 15 градусов от среднеарифметических координат всех моих агариков и выбиралась точка, при симуляции движения к которой функция оценки принимала наибольшее значение. И уже с такой вроде бы примитивной симуляцией и несложной оценкой на тот момент бот вполне себе уверенно закрепился в топ 10.
Демонстрация точек, команду движения к которым симулировал алгоритм изначально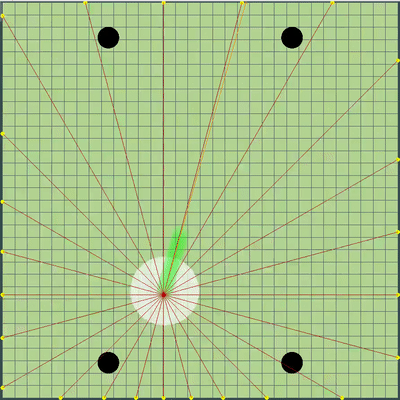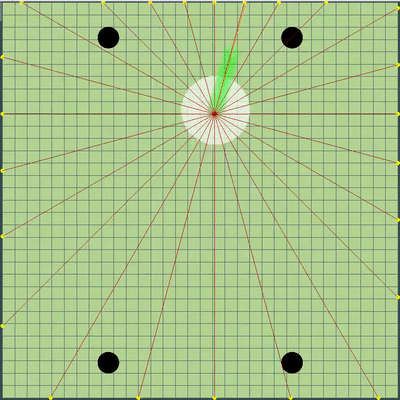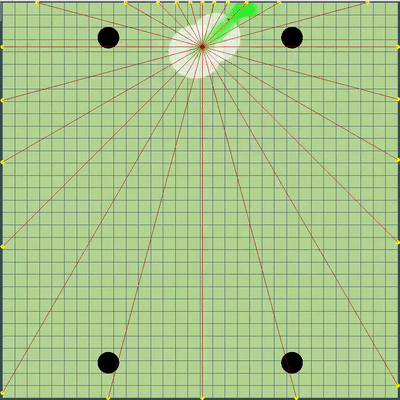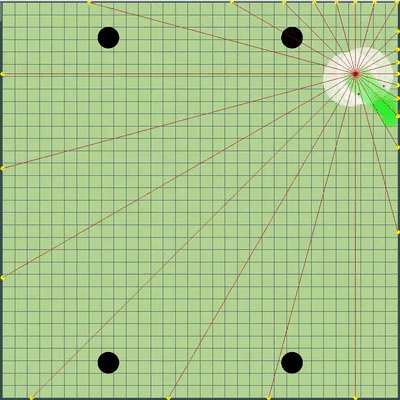
Точки, команда движения к которым отдавалась при разных симуляциях. Если очень присматриваться — итоговая отдаваемая команда иногда смещается относительно перебираемых точек, но это последствия будущих переделок.
Точки, команда движения к которым отдавалась при разных симуляциях. Если очень присматриваться — итоговая отдаваемая команда иногда смещается относительно перебираемых точек, но это последствия будущих переделок.
За вечер пятницы и субботу была добавлена симуляция слияния агариков, симуляция “подрыва” на вирусах, угадывание TTF соперника. TTF соперника был достаточно интересной вычисляемой величиной, и понять, в какой момент соперник сделал сплит или попал на вирус можно было только поймав момент неуправляемого полёта, который мог длиться от очень небольшого кол-ва тиков при большом viscosity и до полёта через всю карту. Поскольку столкновения агариков могли привести к небольшому превышению ими максимальной скорости, то для вычисления TTF соперника я сделал проверку, что его скорость два тика подряд действительно соответствует скорости, которую можно получить в свободном полёте два тика подряд (в свободном полёте агарики летели строго прямо и с замедлением каждый тик, строго равным viscosity). Это практически полностью исключало вероятность ложного срабатывания. Также в процессе тестирования этой логики заметил, что больший TTF всегда соответствует большему id агарика (в чём впоследствии убедился при переносе кода взрыва на вирусе и обработки сплита), чем тоже стоило воспользоваться.
Насмотревшись на постоянные сплиты в топ 3 (что позволяло им ощутимо быстрее собирать еду на карте), в качестве теста я добавил боту постоянную команду split, если в радиусе видимости не было противника, а утром воскресенья обнаружил своего бота на второй строчке рейтинга. Управление кучкой мелких агариков сильно поднимало в рейтинге, но и проиграть ими было куда как легче, если неудачно наткнуться на соперника. А так как страх быть съеденными мои агарики имели очень условный (штраф был только за съедение в симуляции, но не за приближение к сопернику, который мог съесть), то первым делом был добавлен штраф за пересечение с соперником, который мог съесть. И эта же оценка зеркально работала как бонус за преследование соперника. Проверив потребление CPU своей стратегией, я решил добавить ещё один круг симуляции, когда на первом тике делался split (эту логику, конечно же, также потребовалось переносить к себе в код из локал раннера), а затем симуляция проходила точно так же, как и ранее. Такой вариант логики не очень подходил для “стрельбы” в противника (хотя иногда случайно и делал сплит в очень подходящий момент), но очень неплохо подошёл для более быстрого собирания еды, чем и занимался на тот момент весь топ. Такие модификации позволили войти в следующую неделю на первой строчке рейтинга, хотя отрыв был несущественный.
На тот момент этого было вполне достаточно, “костяк” стратегии был выработан, стратегия выглядела достаточно примитивной и расширяемой. Но на что я действительно обратил внимание, так это на потребление CPU и общую стабильность кода. Поэтому в основном вечера следующей рабочей части недели были посвящены улучшение точности симуляций (в чём очень помогал визуализатор), стабилизация кода (valgrind) и некоторым оптимизациям скорости работы.
Идём в отрыв
Следующая моя отправленная стратегия, которая показала ощутимо лучший результат и ушла в отрыв от соперников (на тот момент), содержала два существенных изменения: добавление потенциального поля для сбора еды и удвоение количества симуляций, если рядом есть противник с неизвестным TTF.
Потенциальное поле для сбора еды в первой версии было достаточно несложным и вся его суть сводилась к запоминанию еды, которая пропала из зоны видимости, уменьшение потенциала в тех местах, рядом с которыми находился бот противника и обнуление в зоне моей видимости (с последующим восстановлением каждые n тиков в соответствии с правилами). Это казалось полезным улучшением, однако на практике по моему субъективному мнению разница либо была небольшой, либо вовсе отсутствовала. Например на картах с большой инерцией и скоростью бот часто проскакивал мимо еды и затем пытался к ней вернуться, при этом сильно теряя в скорости. Однако если бы он решил сохранить скорость и просто проигнорировал пропущенную еду, то ел бы ощутимо больше.
Потенциальное поле для сбора еды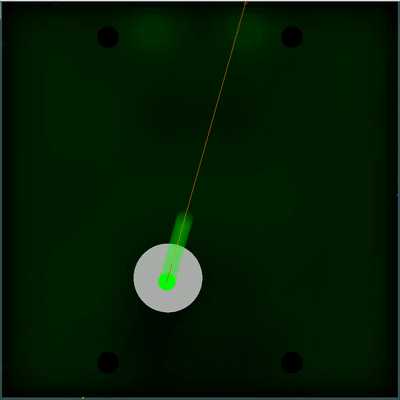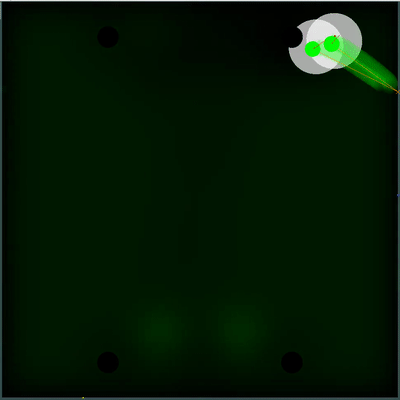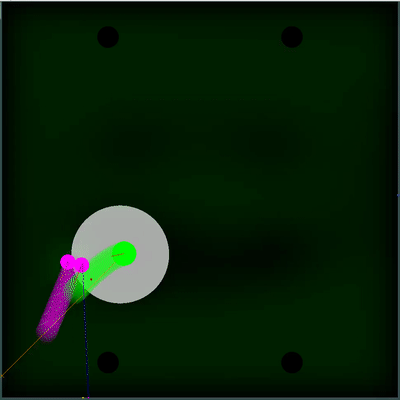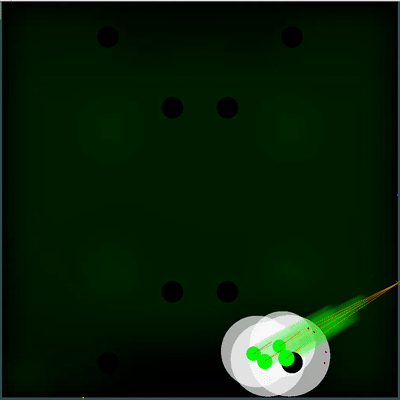
Можно обратить внимание, как каждые 40 тиков поле становится чуть ярче. Каждые 40 тиков поле обновляется в соответствии с тем, как добавляется еда по карте, и вероятность появление еды равномерно «размазывается» по полю. Если на этом тике мы видим, что появилась еда, которую мы видели бы на предыдущем тике — вероятность появление этой еды не «размазывается» вместе с остальными, а задаётся конкретными точками (еда появляется каждые 40 тиков строго симметрично).
Можно обратить внимание, как каждые 40 тиков поле становится чуть ярче. Каждые 40 тиков поле обновляется в соответствии с тем, как добавляется еда по карте, и вероятность появление еды равномерно «размазывается» по полю. Если на этом тике мы видим, что появилась еда, которую мы видели бы на предыдущем тике — вероятность появление этой еды не «размазывается» вместе с остальными, а задаётся конкретными точками (еда появляется каждые 40 тиков строго симметрично).
Совсем другой по субъективной полезности оказалась двойная симуляция противника с различными TTF — минимально и максимально возможным (в случае, если я не знаю TTF для всех видимых агариков на карте). И если раньше мой бот думал, что вражеская кучка агариков на следующий тик станет единым целым и будет медленно передвигаться, то теперь он выбирал худший сценарий из двух и не рисковал находиться близко к противнику, про которого он знает меньше, чем хотел бы.
После получения существенного преимущества я попытался его увеличить, добавив определение точки, в которую соперник командует своим агарикам двигаться, и хотя такую точку получилось вычислять в большинстве случаев достаточно точно, само по себе это не принесло улучшения результатов бота. По моим наблюдениям становилось даже хуже варианта, когда агарики соперника просто двигались в том же направлении и с той же скоростью, как если бы соперник ничего не предпринимал, поэтому эти правки были сохранены в отдельной гит ветке до лучших времён.
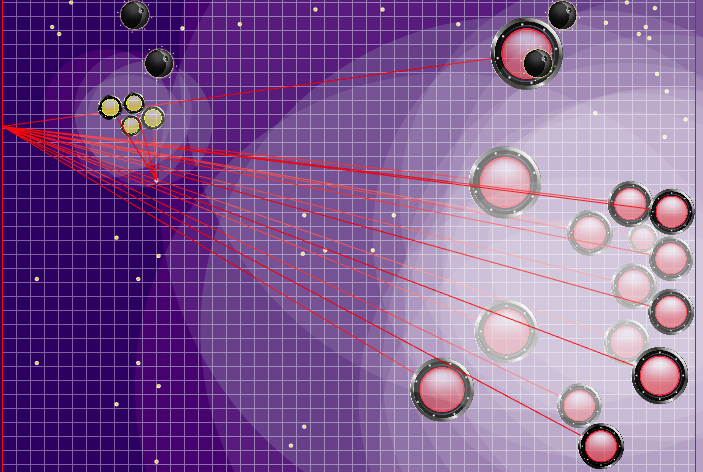
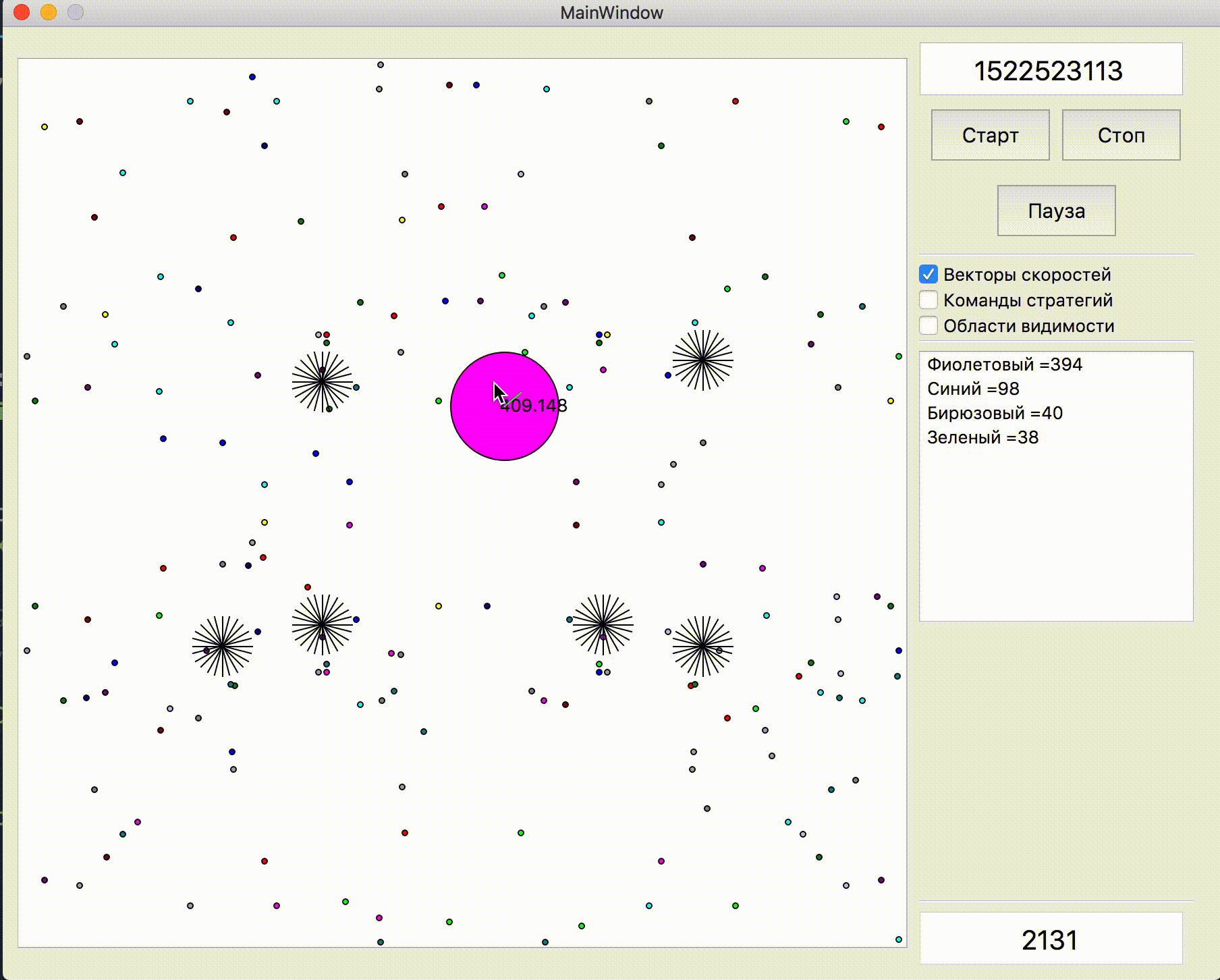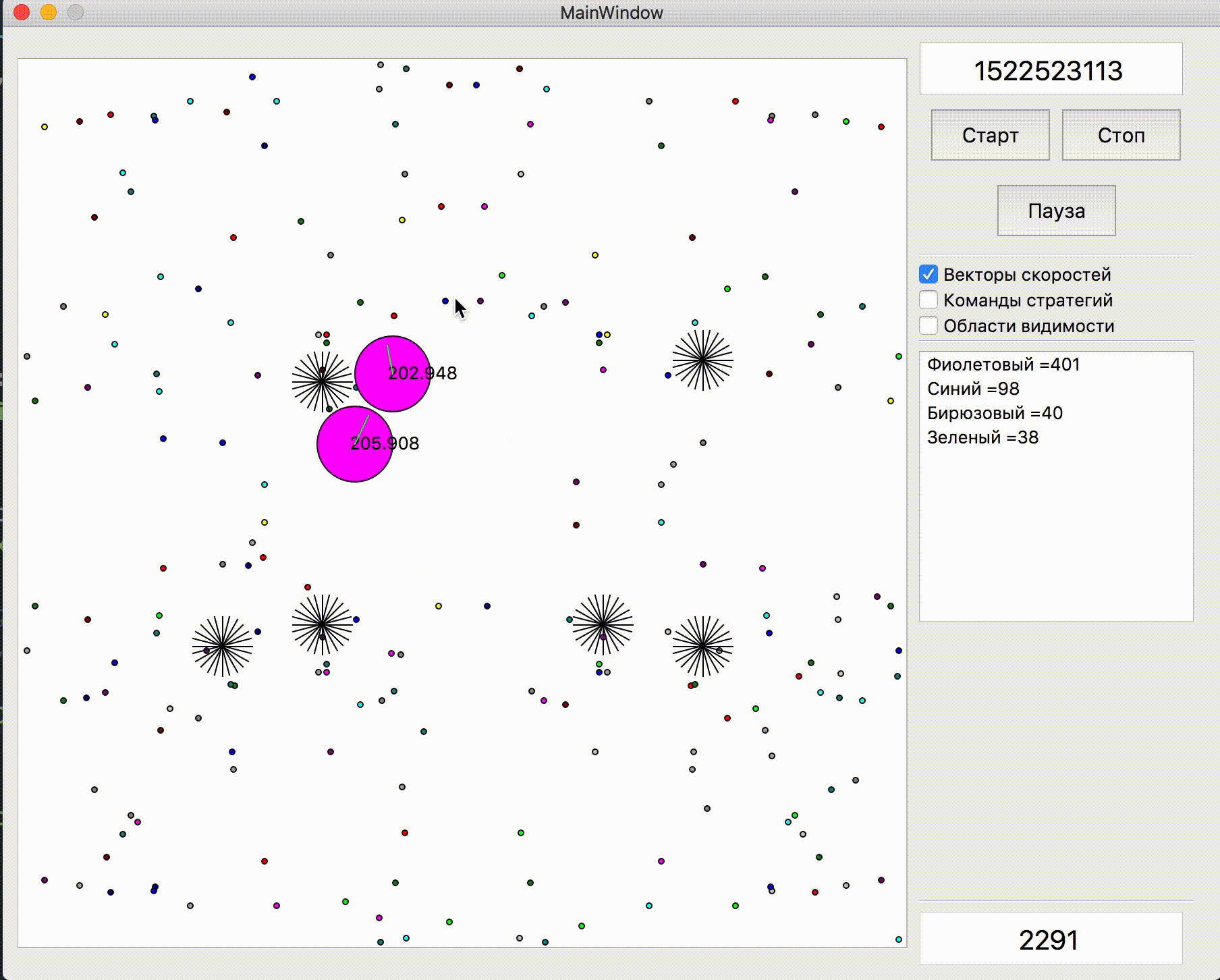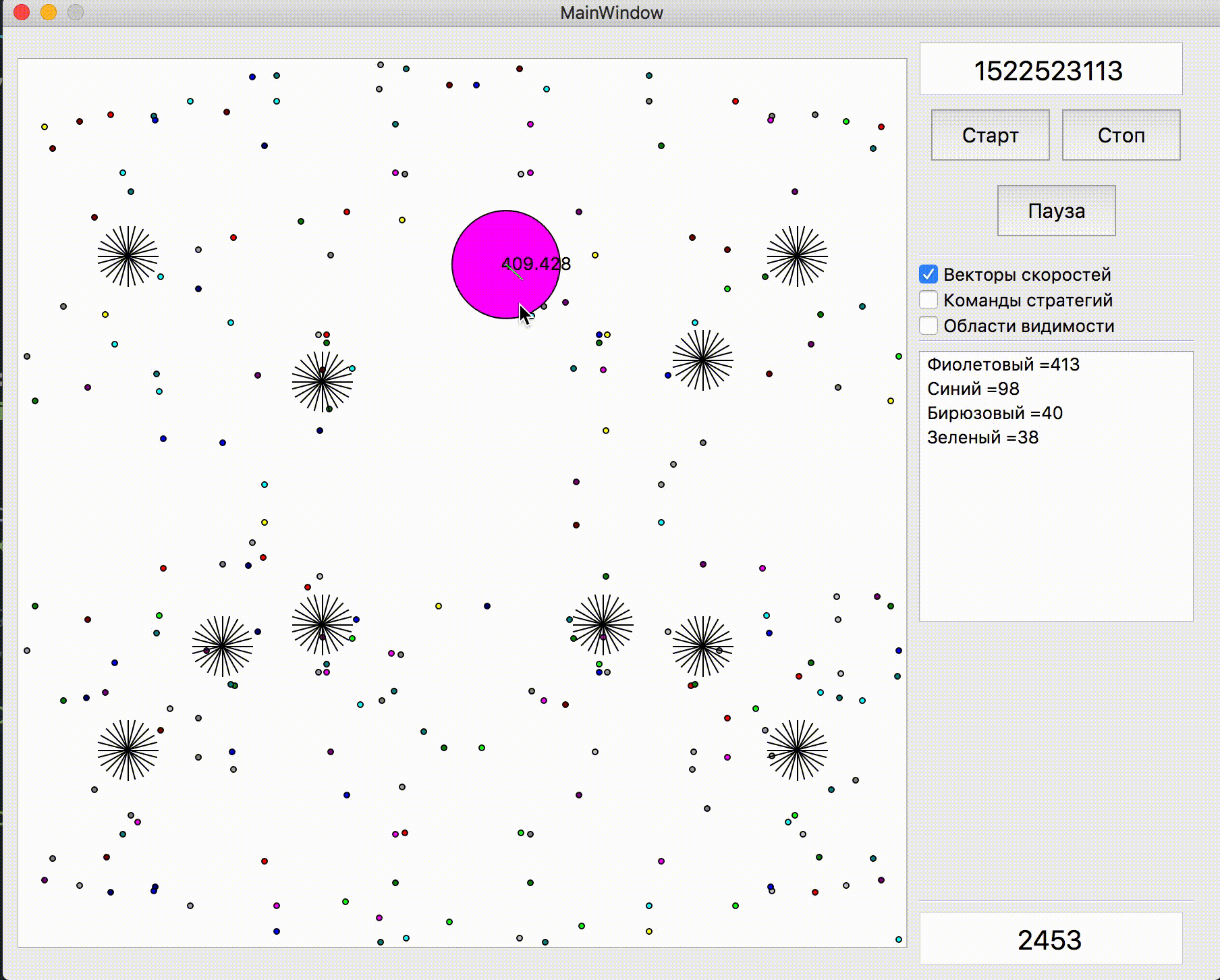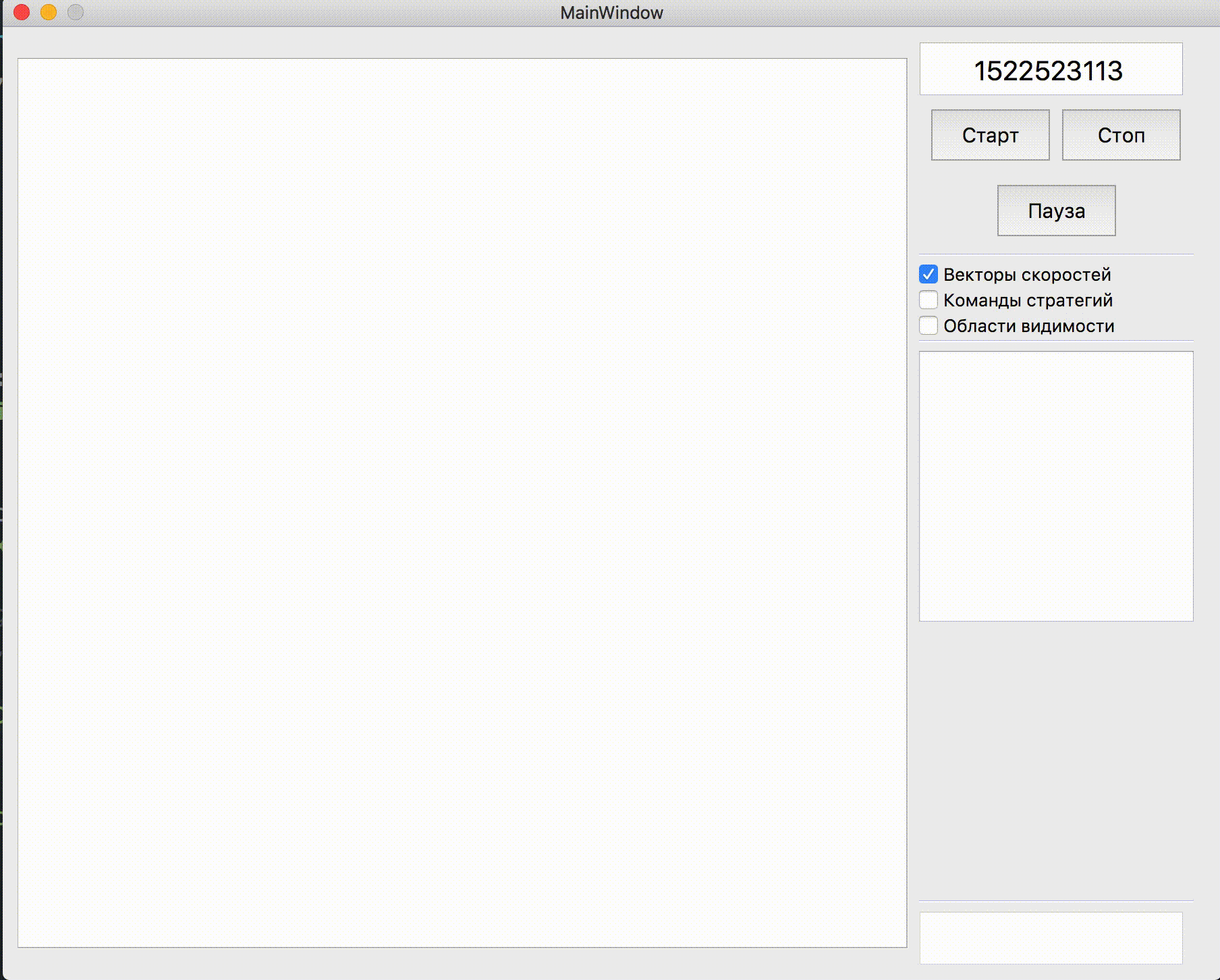
Определение команды противника, которое было использовано позднее
Лучами из агариков соперника показана предполагаемая команда, которую соперник отдавал своим агарикам на предыдущем тике. Синие лучи — точное направление, в котором агарик менял направление на прошлом тике. Чёрные — предполагаемое. Более точно определить направление команды можно было только в случае, если агарик полностью в зоне нашей видимости (можно было просчитать влияние коллизий на изменение его скорости). Место пересечения лучей и есть предполагаемая команда соперника. Гифка сделана на базе игры aicups.ru/session/200710, около 3000 тика.
Лучами из агариков соперника показана предполагаемая команда, которую соперник отдавал своим агарикам на предыдущем тике. Синие лучи — точное направление, в котором агарик менял направление на прошлом тике. Чёрные — предполагаемое. Более точно определить направление команды можно было только в случае, если агарик полностью в зоне нашей видимости (можно было просчитать влияние коллизий на изменение его скорости). Место пересечения лучей и есть предполагаемая команда соперника. Гифка сделана на базе игры aicups.ru/session/200710, около 3000 тика.
Также были попытки перевести функцию оценки на оценку полученной массы, попытки изменить функцию оценки опасности соперника… Но опять же все такие изменения по ощущениям делали даже хуже. Единственное, что было сделано полезного с функцией оценки опасности от нахождения рядом с противником — очередные оптимизации производительности наряду с распространением этой оценки на куда больший радиус, нежели радиус пересечения с противником (по сути на всю карту, но с квадратичным убыванием, если чуть упрощённо — делая присутствие в пяти и более радиусах от соперника в районе 1/25 от максимальной опасности быть съеденным). Последнее изменение также незапланированно привело к тому, что мои агарики стали сильно бояться приближаться к ощутимо более крупному противнику, равно как и в случае своих сильно превосходящих размеров были более склонны подвинуться в сторону соперника. Таким образом, получилась удачная и не ресурсоёмкая замена запланированному на будущее коду, который должен был отвечать за боязнь атаки соперника через сплит (и небольшая помощь в такой атаке мне впоследствии).
После долгих и относительно бесплодных попыток что-то улучшить я ещё раз вернулся к предсказанию направления движения соперника. Решил попробовать раз уж не просто заменить dummy соперников, то поступить так, как я поступил с минимальным и максимальным вариантом TTF — просимулировать дважды и выбрать лучший из вариантов. Но для этого уже могло не хватить CPU, и во многих играх моего бота просто могли отключить от системы из-за неуёмного аппетита. Поэтому, прежде чем реализовать такой вариант, я добавил приблизительное определение потраченного времени и в случае превышения лимитов начинал уменьшать количество ходов симуляции. Добавив двойную симуляцию противника для случая, когда я знаю место, куда он направляется, я снова получил достаточно серьёзный прирост на большинстве настроек игр, кроме самых ресурсоёмких (с большой инерцией/малой скоростью/низким viscosity), на которых из-за сильного уменьшения глубины симуляции всё могло стать даже немного хуже.
Перед началом игр на 25к тиков были сделаны ещё две полезные доработки: штраф за окончание симуляции далеко от центра карты, а также запоминание предыдущей позиции соперника в случае его выхода из зоны видимости (а также симуляцию его движения в это время). Реализация штрафа за конечное положение бота в симуляции представляла из себя предподсчитаное статичное поле опасности с нулевой опасностью в радиусе, чуть большим половины длины игрового поля и постепенным увеличением её по мере удаления от игрового поля. Применение штрафа этого поля в конечных точках симуляции почти не требовало CPU и предотвращало лишние забегания в углы, иногда спасая от атак противника. А запоминание с последующей симуляцией соперников по большей части позволяло избежать двух иногда проявляющихся проблем. Первая проблема представлена на гифке ниже. Вторая проблема заключалась в том, что при потере из поля видимости более крупного врага (например, после слияния своих частей) можно было “удачно” сплитнуться в него, ещё дополнительно подкормив и без того опасного соперника.
Пример поля опасности за окончание хода в углу и зря потраченные тики
Изначально планировались штрафы и рядом со стенами, но в итоге они были добавлены только в углах
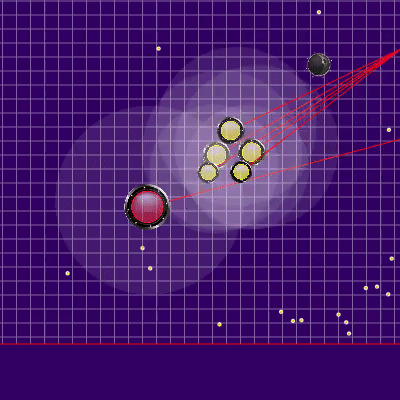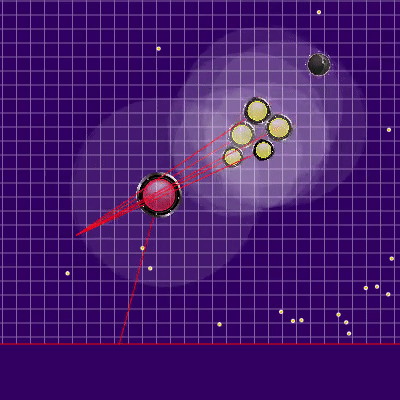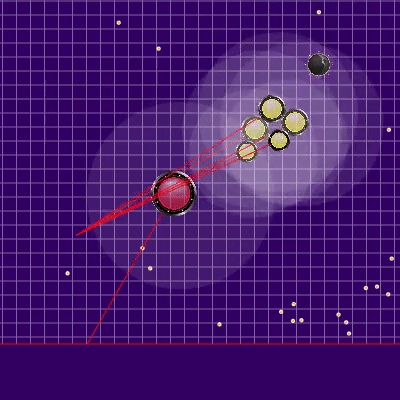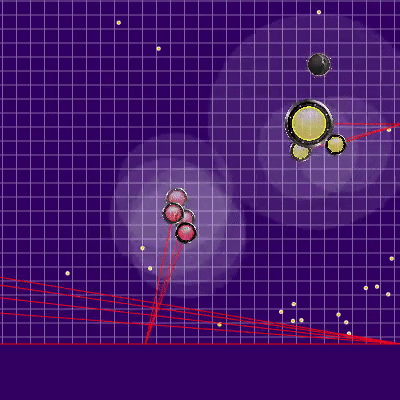
Что может происходить, если совсем не помнить предыдущего расположения противника. В данном случае застревание было недолгим, но встречались и куда более серьёзные.
Изначально планировались штрафы и рядом со стенами, но в итоге они были добавлены только в углах
Что может происходить, если совсем не помнить предыдущего расположения противника. В данном случае застревание было недолгим, но встречались и куда более серьёзные.
Также к точкам на краю карты были добавлены дополнительные точки симуляции движения: к каждому агарику соперников и в радиусе от среднеарифметической координаты моих агариков каждые 45 градусов. Радиус был установлен в avgDistance от среднеарифметического координат моих агариков.
Новые точки симуляции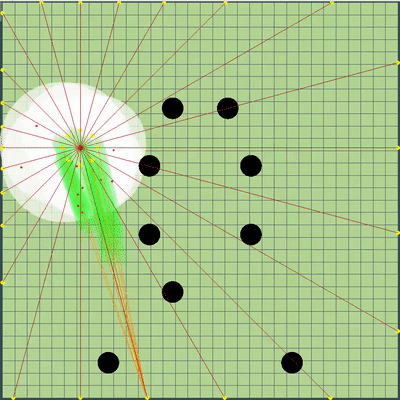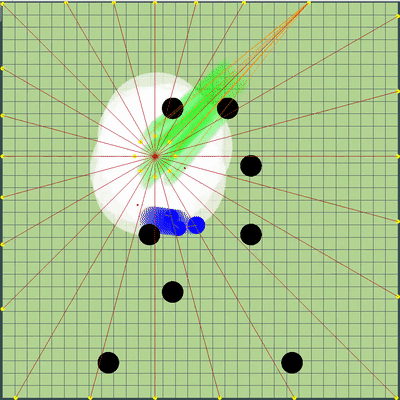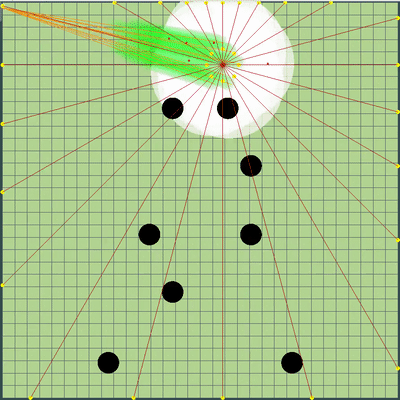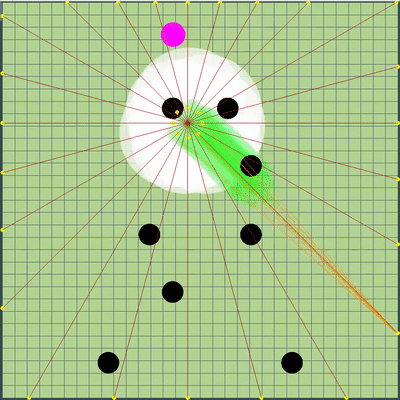
Вокруг центральной точки моих агариков добавились дополнительные точки симуляции. Они только иногда помогали агарикам скорее «собраться» в правильном месте, чтобы съесть соперников. В остальное же время были практически бесполезны.
Вокруг центральной точки моих агариков добавились дополнительные точки симуляции. Они только иногда помогали агарикам скорее «собраться» в правильном месте, чтобы съесть соперников. В остальное же время были практически бесполезны.
Подготовка к финалу
На момент открытия игр на 25к тиков и прохождения в финал у меня был солидный отрыв, но расслабляться я не планировал.
Вместе с новой длительностью игр по 25к пришли и новости: игры во время финала тоже будет длительностью в 25к, а ограничение времени работы стратегии на тик стало чуть больше. Оценив время, которое тратит моя стратегия на игру в новых условиях, я решил добавить ещё один вариант симуляции: делаем всё, как обычно, но во время симуляции на ходу n делаем сплит. Это в том числе потребовало на последующих ходах как базовый скор для всех симуляций применять симуляцию, найденную на предыдущем шаге, но со сдвигом на 1 ход (т.е. если мы нашли, что идеальным вариантом будет сплит на 7 тике от текущего, то на следующий ход повторяем то же самое, но сплит сделаем уже на 6 ходу). Это существенно добавило агрессивных атак на соперников, но съело ещё немного времени работы стратегии.
Тут должно было быть сжатое описание алгоритма
А получилось вот так
Оценка симуляции:
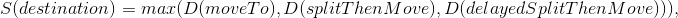
За базовый набор команд брался выбранный на предыдущем тике со сдвигом на 1 тик. Т.е. вызов splitThenMove превращался в вызов moveTo, delayedSplitThenMove менял задержку на сплит с 7 до 6 тиков, а на следующий ход с 6 до 5 и т.д. Дополнительно оценивались два набора команд, сделанных на основе базового — если мы добавим команду сплит на следующем тике и если мы добавим сплит на 7 тике. Выбрав лучшую оценку для трёх наборов команд начинали работать над поиском новых направлений с большей оценкой.
В destination подставлялась:
Каждый следующий оцененный destination сравнивался с текущим набором команд, который набрал максимальную оценку и в случае нахождения новой лучшей оценки заменял предыдущую найденную.
Оценка симуляции:
- f — функция, которая оценивает промежуточные и конечное состояние мира при симуляции с заданными параметрами;
- sim — заранее заданный набор команд и параметры симуляции (моё направление движения, направления соперников, TTF соперников, на каком тике делаем сплит);
- finalPositionFoodPotentialField — очки конкретного агарика, полученный из ПП, отвечающего за близость еды;
- finalPositionCornerDanger — мера опасности нахождения данного агарика в конкретной точке. ПП рассчитано на основе расстояния от цента карты, опасность отлична от нуля только ближе к краям карты;
- n — величина, рассчитываемая исходя из потреблённого стратегией времени и конфигурации мира. Ограничена 10 снизу и 50 сверху;
- ateFood — очки за съеденную моими агариками еду на тике i;
- virusBurst — очки за взрыв одного из моих агариков на вирусе на тике i;
- opponentAteFood — очки за съеденную соперником еду на тике i;
- meAteOpponent — очки за съедение моими агариками соперников;
- opponentAteMe — очки за съедение соперниками моих агариков;
- mine/opponents — оставшиеся в конце симуляции агарики. Т.е. если агарик был съеден или слился во время симуляции — в данной оценке он не участвует;
- danger — оценка риска, которому подвергался агарик, находясь рядом большим агариком соперника.
- moveType — заранее заданный набор команд, куда двигаться и на каком тике делать сплит;
- max/min TTF — симулируем противника считая, что у его агариков минимальный и максимальный TTF из возможных (основано на алгоритме определения TTF соперника);
- dummy/aim — симулируем всех агариков противника как Dummy или на основании определённой с предыдущего тика команды (основано на алгоритме определения точки, команда движения к которой была отдана соперником на предыдущем шаге).
- destination — точка, движение к которой мы хотим симулировать с разными параметрами;
- moveTo — набор команд, где все n тиков отдаётся команда “движемся в заданную точку” без дополнительных параметров;
- splitThenMove — дополнительно к простому движению добавляем команду split на первом тике;
- delayedSplitThenMove — аналогично предыдущему, но split добавляется на седьмом тике.
За базовый набор команд брался выбранный на предыдущем тике со сдвигом на 1 тик. Т.е. вызов splitThenMove превращался в вызов moveTo, delayedSplitThenMove менял задержку на сплит с 7 до 6 тиков, а на следующий ход с 6 до 5 и т.д. Дополнительно оценивались два набора команд, сделанных на основе базового — если мы добавим команду сплит на следующем тике и если мы добавим сплит на 7 тике. Выбрав лучшую оценку для трёх наборов команд начинали работать над поиском новых направлений с большей оценкой.
В destination подставлялась:
- Все направления с шагом в 15 градусов от среднеарифметического координат моих агариков (далее — центральная точка). По 24 направлениям брались точки на краю карты;
- Центральная точка, совпадающая со среднеарифметическим координат моих агариков (даже если агарик был один);
- Если мы не приближались к таймлимитам в текущей игре:
- “преследующее” один из вражеских агариков направление, которое во время симуляции соперника также менялось;
- дополнительные 8 точек вокруг центральной. Расстояние от центральной точки до целевых зависело от удалённости моих агариков от центра.
Каждый следующий оцененный destination сравнивался с текущим набором команд, который набрал максимальную оценку и в случае нахождения новой лучшей оценки заменял предыдущую найденную.
Все дальнейшие доработки были связаны исключительно с эффективностью работы симуляций в случае нехватки TL: оптимизация очерёдности отключения тех или иных частей логики в зависимости от потребляемого CPU. На большей части игр это не должно было изменить ничего, но придумать что-то более правильное тогда не вышло.
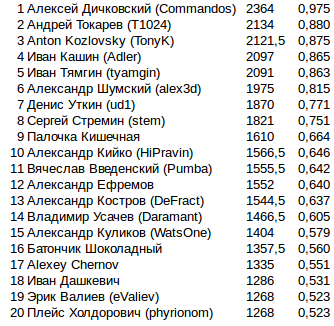
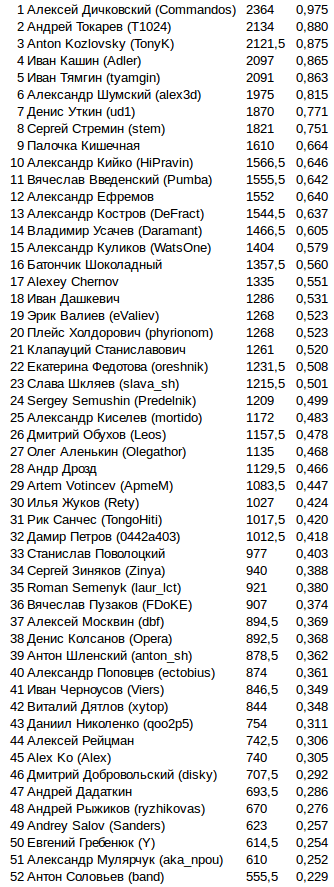
Итоговое количество очков в финале
Последней колонкой добавил какую долю из максимально возможных очков набрал бот. За 808 проведенных игр можно было максимум набрать 2424 очка, если победить во всех играх. Так просто красивее смотрится.
Вместо заключения
В целом старт этого соревнования получился достаточно смазанный, но за первые полторы недели не без помощи участников задача была приведена в достаточно играбельный вид. Изначально задача была очень вариативна, и выбрать правильный подход к её решению не показалось тривиальной задачей. Ещё более интересно было придумывать способы улучшить алгоритм, не вылетев за пределы потребления CPU. Организаторам большое спасибо за проведённое соревнование и за выкладку исходников мира в открытый доступ. Последнее, конечно, очень добавило им проблем на старте, но сильно облегчило (если не сказать, что сделало возможным в принципе) участникам понимание устройства симулятора мира. Отдельное большое спасибо за возможность выбора приза! Так приз вышел куда как более полезным :-)

