 Все это плутни королевы Маб.
Все это плутни королевы Маб.Она в конюшнях гривы заплетает
И волосы сбивает колтуном…
Вильям Шекспир
Это был долгий релиз, но и сделано было немало. Появился session-manager, позволяющий откатывать ошибочно сделанные ходы. Кое где добавилось звуковое оформление. А ещё, я придумал прикольный способ, позволяющий затолкнуть несколько альтернативных вариантов начальной расстановки в одну игру. И самое главное — я наконец добрался до игр с неполной информацией.
Объясню, о чём идёт речь. В привычных нам настольных играх, таких как Шахматы или Шашки, игроки, в любой момент игры, обладают полной информацией о расположении фигур (своих и противника), правилах их перемещения, целях игры и т.п. Такие игры довольно хорошо изучены и относятся к категории "игр с полной информацией". Теперь, представьте себе, что часть этой информации может быть скрыта от игрока.

«Туман войны» — прекрасная иллюстрация темы. По правилам "Шахмат втёмную", игроки могут видеть не все фигуры противника, а только те, которые размещены на полях, до которых можно добраться одним ходом любой из своих фигур. Я внёс в это правило два дополнения:
- Разумеется, игрок всегда видит свои фигуры, но по тому как они отображаются — в нормальном виде или полупрозрачном, он может судить о том, видит ли их противник.
- Исключительно в декоративных целях, я разместил «облака» на тех областях, которые невидимы в настоящий момент.
Освоив общий принцип, я немного увлёкся и наделал огромное количество игр с «туманом войны». Помимо собственно Шахмат, у меня имеются «тёмные» варианты для Сянцы, Чанги, Шатранджа, Ситтуйина и многих других игр. Есть даже "Пушки втёмную"! Все эти игры объединяет одно:
Компьютер жульничает!
Я даже не пытался вносить изменения в алгоритмы работы ботов для этих игр, поскольку сделал ставку на то, что неравные условия хотя бы частично компенсируют крайне слабую их игру, по сравнению с человеком. Как я уже писал ранее, разработка качественного AI для настольных игр является очень непростой задачей. Разумеется, у правил есть исключения. Даже при очень слабой игре бота, человеку будет сложно играть в незнакомую игру, буквально напичканную ловушками. Что уж говорить о её «тёмном» варианте
Однако, в целом, это не очень правильный подход. Хочется видеть бота, умеющего обходиться ровно теми данными, которые имеются у его противника — человека. Почему это важно? Всё очень просто — по тому как играет бот, иногда бывает очень легко догадаться о том, имеет ли он доступ к скрытой информации (подглядывает) или нет. И разумеется, человеку гораздо интереснее играть с тем ботом, который не подглядывает (с другим человеком играть ещё интереснее, но это отдельная история).
И здесь стоит подобрать игру, немножко отличную от Шахмат (поскольку заниматься разработкой «честного» бота играющего в Шахматы «втёмную» я не готов). Таких игр довольно много и нельзя сказать, что они проще чем Шахматы или Шашки. Они просто другие и требуют индивидуального подхода.
Например
Есть одна детская игра, с разработкой бота для которой я пока не справился. Называется она «Джунгли» или Dou Shou Qi. Цель игры — проникновение на вражескую территорию. У каждого из игроков есть «логово» — центральное поле на первой линии. Если в логово войдёт любая из фигур противника — он победил (своими фигурами занимать логово нельзя).

Фигуры упорядочены по старшинству. Слон бьёт все фигуры, далее следуют: Лев, Тигр, Леопард, Собака, Волк, Кошка и Крыса. Крыса может бить только слона и другую крысу, кроме того, это единственная фигура, способная перемещаться в воде (в середине доски расположены два водоёма). Тигр и лев могут воду перепрыгивать, но только в том случае, если путь по воде не перекрывает крыса. За исключением прыжков, все фигуры движутся одинаково — на одно соседнее поле по вертикали или горизонтали. Логово окружено ловушками. Фигура в ловушке уязвима для любой фигуры противника.
Как можно видеть, правила довольно простые. Что мешает разработать бота для этой игры? Прежде всего — тихоходность фигур. При наличии угроз, я могу оценить выгоду разменов, но большую часть игры фигуры просто бегают друг за другом на довольно протяжённые расстояния. Я не могу позволить себе просмотр партии на большое число ходов вперёд (из за ограничений на продолжительность расчёта хода), в результате чего размены выпадают за «горизонт» просмотра и все ходы становятся для меня равноценными.
Фигуры упорядочены по старшинству. Слон бьёт все фигуры, далее следуют: Лев, Тигр, Леопард, Собака, Волк, Кошка и Крыса. Крыса может бить только слона и другую крысу, кроме того, это единственная фигура, способная перемещаться в воде (в середине доски расположены два водоёма). Тигр и лев могут воду перепрыгивать, но только в том случае, если путь по воде не перекрывает крыса. За исключением прыжков, все фигуры движутся одинаково — на одно соседнее поле по вертикали или горизонтали. Логово окружено ловушками. Фигура в ловушке уязвима для любой фигуры противника.
Как можно видеть, правила довольно простые. Что мешает разработать бота для этой игры? Прежде всего — тихоходность фигур. При наличии угроз, я могу оценить выгоду разменов, но большую часть игры фигуры просто бегают друг за другом на довольно протяжённые расстояния. Я не могу позволить себе просмотр партии на большое число ходов вперёд (из за ограничений на продолжительность расчёта хода), в результате чего размены выпадают за «горизонт» просмотра и все ходы становятся для меня равноценными.
Для начала, я решил остановиться на BanQi — китайских «Слепых шахматах». Это весьма оригинальная игра со скрытой информацией, родственная «Джунглям». Для меня важно, что наработки, в связи с созданием бота для этой игры, могут быть использованы и в других играх, таких как Dou Shou Qi, Luzhan Qi, Stratego или даже (возможно) Tafl.
Расскажу о правилах. Игра протекает на половине доски для «Китайских шахмат» (Xiang Qi), при этом, оригинальная разметка доски не играет никакой роли. Фигуры размещаются внутри клеток (как в традиционных), а не на пересечениях линий (как в китайских шахматах). В начале игры, все фигуры тщательно перемешиваются и размещаются на доске лицевой стороной вниз (поскольку традиционные фигуры Сянцы представляют собой этакие бочонки, а их количество совпадает с количеством полей на половине доски, с этим не возникает трудностей).
Далее игроки чередуют свои ходы. Выполняя ход, игрок может перевернуть любую из закрытых фигур, либо переместить ранее открытую фигуру своего цвета. Цвета игроков определяются самым первым ходом. Если первой открыта чёрная фигура, открывший её игрок будет играть чёрными. Все фигуры в игре ходят одинаково (за исключением «Пушки» в тайваньском варианте, о которой я скажу позже) — на одну соседнюю клетку по вертикали или горизонтали. Возможность взятия определяется порядком старшинства фигур:
Генерал > Советник > Слон > Повозка > Конь > Пушка > Солдат
Старшие фигуры бьют младших или равных им, за одним исключением: солдат бьёт генерала (своего рода "Камень-Ножницы-Бумага"). Осталось сказать пару слов о тайваньском BanQi:
- В отличии от китайского варианта, в тайваньском BanQi генерал не может бить солдата.
- Пушка перемещается по правилам XiangQi, то есть на любое число полей по ортогонали тихим ходом (как колесница) или бьёт любую фигуру противника, с прыжком через «лафет», при выполнении атакующего хода.
Есть ещё гонконгский вариант, но он практически ничем не отличается от китайского, за исключением того, что изменён порядок старшинства фигур. Я решил сосредоточиться на тайваньском варианте правил, как на наиболее интересном, в тактическом плане.
На что стоит обратить внимание при разработке бота?
Во первых, игра выглядит очень простой, но таковой не является. Даже если не рассматривать нюансы, связанные с тайваньскими пушками, стоимость фигур контринтуитивна. Хотя «Советник» может побить меньшее количество фигур чем «Генерал», именно он является главным действующим лицом в игре. Во первых, советников у игрока два. Кроме того, каждого советника превосходит по силе всего один вражеский генерал, в то время как генерала могут атаковать целых пять солдат! По той же причине, стоимость солдата, в игре, выше стоимости генерала. В конце концов, он может побить самую сильную фигуру! Второе важное соображение подсказывает одна из «кентерберийских» головоломок Генри Дьюдени.
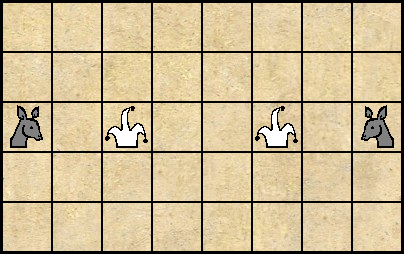
Это скорее задача-шутка, чем полноценная головоломка. Все фигуры могут ходить на одно соседнее поле по вертикали или горизонтали. Белые ходят первыми, при этом, и белые и чёрные всегда делают по два хода (разными фигурами)! В этих условиях, левый шут никогда не сможет поймать левого осла, а правый — правого (можете проверить это самостоятельно). Разумеется, правый шут может поймать левого осла без всякого труда. Всё дело в чётности!
Эта задачка натолкнула меня на некоторые мысли. Во первых, задача бота, в таких играх как BanQi или DouShouQi — это, прежде всего, поиск кратчайшего пути. От каждой из активных фигур (своей или противника) необходимо построить цепочки ходов ко всем возможным целям (в том числе и к своим фигурам, для расчёта возможных разменов). После этого, цепочки необходимо оценить и здесь возможны следующие варианты.
Разумеется, всё не так просто. Как минимум, следует помнить о специфичном ходе пушек в тайваньском BanQi (Что касается «Джунглей», то там особых случаев ещё больше), но это то, с чего можно начать. Имея полный набор оцененных цепочек, можно оценивать ходы. Стоимость хода должна складываться из стоимостей цепочек (как бонусных так и штрафных), длину которых он уменьшает.
Это скорее задача-шутка, чем полноценная головоломка. Все фигуры могут ходить на одно соседнее поле по вертикали или горизонтали. Белые ходят первыми, при этом, и белые и чёрные всегда делают по два хода (разными фигурами)! В этих условиях, левый шут никогда не сможет поймать левого осла, а правый — правого (можете проверить это самостоятельно). Разумеется, правый шут может поймать левого осла без всякого труда. Всё дело в чётности!
Эта задачка натолкнула меня на некоторые мысли. Во первых, задача бота, в таких играх как BanQi или DouShouQi — это, прежде всего, поиск кратчайшего пути. От каждой из активных фигур (своей или противника) необходимо построить цепочки ходов ко всем возможным целям (в том числе и к своим фигурам, для расчёта возможных разменов). После этого, цепочки необходимо оценить и здесь возможны следующие варианты.
- Атакующая фигура бьёт атакуемую — выгодная (бонусная) цепочка оцениваемая стоимостью атакуемой фигуры (за вычетом стоимости атакующей, если последняя находится под защитой), с учётом длины цепочки.
- Атакующая фигура бьётся атакуемой — не выгодная (штрафная) цепочка, оцениваемая стоимостью атакующей фигуры.
- Фигуры бьют друг друга (например равны) — здесь всё зависит от чётности, выгодны нечётные цепочки, а чётные должны рассматриваться как штрафные (если бы других фигур на поле не было, чётность полностью определяла бы итог игры).
Разумеется, всё не так просто. Как минимум, следует помнить о специфичном ходе пушек в тайваньском BanQi (Что касается «Джунглей», то там особых случаев ещё больше), но это то, с чего можно начать. Имея полный набор оцененных цепочек, можно оценивать ходы. Стоимость хода должна складываться из стоимостей цепочек (как бонусных так и штрафных), длину которых он уменьшает.
Прежде всего, важно понимать, что эффективно использовать минимаксные алгоритмы здесь вряд ли удастся. Ходы, вскрывающие ранее скрытые фигуры, слишком радикально изменяют оценку позиции. Не имея информации о скрытых фигурах, практически невозможно просматривать позицию на много ходов вперёд. Но нет худа без добра, зато мы можем использовать гораздо более сложные (в вычислительном плане) эвристики для оценки самих ходов!
Бот, оценивающий ходы по их эвристике, у меня уже есть (понадобился для одной забавной игры). Это очень простой алгоритм. Все ходы отсортировываются по убыванию эвристики (ходы с отрицательным значением эвристики вообще отбрасываются), после чего просматриваются по порядку. Если очередной ход ведёт в позицию из которого нет ответа противника, ведущего к немедленной победе, бот считает его наилучшим. Используя этот алгоритм можно не заморачиваться оценкой позиции, но над эвристикой придётся попотеть.
Прежде всего, строим цепочки
var getChains = function(design, board) { var player = board.getValue(board.player); if (player === null) return []; if (_.isUndefined(board.chains)) { board.chains = []; var pieces = getGoals(design, board); var targets = getTargets(design, board, pieces); _.each(pieces.positions, function(pos) { var goals = pieces; var f = true; var piece = board.getPiece(pos); if (piece === null) return; if (!chinese && (piece.type == 12)) { goals = targets; f = false; } var group = [ pos ]; var level = []; level[pos] = 0; for (var i = 0; i < group.length; i++) { if (_.indexOf(goals.positions, group[i]) >= 0) { // Строим цепочку... } if ((i > 0) && (board.getPiece(group[i]) !== null)) continue; _.each(design.allDirections(), function(dir) { p = design.navigate(board.player, group[i], dir); while (p !== null) { if (_.indexOf(group, p) >= 0) break; group.push(p); level[p] = level[ group[i] ] + 1; if (f || (board.getPiece(p) !== null)) break; p = design.navigate(board.player, p, dir); } }); } }); } return board.chains; }
Разумеется, я кэширую все промежуточные данные в игровом состоянии, чтобы не считать их по нескольку раз. Кроме того, здесь используется один трюк, весьма полезный при расчёте связных областей. Я выполняю итерации по массиву group, подкладывая в него дополнительные элементы внутри цикла, по мере необходимости. Все сложности связаны с пушками. Для них целями цепочек считаются не сами фигуры, а поля, с которых последние могут быть атакованы.
Оцениваются цепочки ровно так, как я и говорил
var getChainPrice = function(design, board, attacker, attacking, len) { var player = board.getValue(board.player); if ((player === null) || (attacker == null) || (attacking === null)) return 0; if (attacker.player == attacking.player) return 0; var isAttacking = isAttacker(design, attacker.type, attacking.type); var isAttacked = isAttacker(design, attacking.type, attacker.type); if (!chinese && (attacker.type == 12)) { isAttacking = true; isAttacked = (attacking.type == attacker.type) && (len == 1); } var price = 0; var f = (len % 2 == 0); if (attacker.player != player) f = !f; if (isAttacking) { if (isAttacked) { price = f ? (len - design.price[attacker.type]) : (design.price[attacking.type] - len); } else { price = design.price[attacking.type] - len; if (f) price = (price / 2) | 0; } } else { if (isAttacked) { price = len - design.price[attacker.type]; } } return price; }
… в зависимости от длины и чётности цепочки, а также с учётом стоимостей атакующей и атакуемой фигур. Но это только половина дела! необходимо оценить каждый из возможных ходов, используя построенные цепочки. Я ввожу ещё одну промежуточную структуру — пожелания, чтобы агрегировать имеющиеся данные. Оценка хода складывается из оценок пожеланий, которым он удовлетворяет:
Как-то вот так
var addWish = function(board, comment, price, src, dst) { if (_.isUndefined(board.wish[src])) { board.wish[src] = []; } if (_.isUndefined(dst)) dst = src; if (_.isUndefined(board.wish[src][dst])) { board.wish[src][dst] = price; } else { board.wish[src][dst] += price; } } var getWish = function(design, board) { if (_.isUndefined(board.wish)) { ... } return board.wish; } Dagaz.AI.heuristic = function(ai, design, board, move) { var wish = getWish(design, board); if (move.isSimpleMove() && !_.isUndefined(wish[ move.actions[0][0][0] ]) && !_.isUndefined(wish[ move.actions[0][0][0] ][ move.actions[0][1][0] ])) { return wish[ move.actions[0][0][0] ][ move.actions[0][1][0] ]; } return 0; }
Что касается самой функции getWish, то здесь начинается магия (и это то место, где я скорее всего напахал и не один раз). Прежде всего, я разделяю оценку ходов на основе открытой информации и ввод в игру новых фигур. Это не совсем правильно, но пока я просто не знаю как согласовать столь разнородные оценки. Если на основе открытой информации никаких пожеланий сформировано не было, бот пытается открывать новые фигуры (здесь тоже есть некоторые трюки).
- Если открыта вражеская пушка, окружённая закрытыми фигурами, имеет смысл открыть одну из фигур рядом с ней, поскольку велика вероятность, что она сможет атаковать пушку, а пушка побить её, в любом случае, не сможет.
- Если открыта фигура отличная от пушки, можно попробовать вскрыть фигуру, расположенную через «лафет» от неё, поскольку есть вероятность, что это окажется пушка.
- При наличии атакующей цепочки со стороны противника, можно вскрыть одну из фигур, по соседству с цепочкой, чтобы перехватить атаку.
- Если защитить фигуру не получается, можно открыть фигуру рядом с ней, попытавшись свести ситуацию к размену.
Разумеется, вероятность открытия той или иной фигуры полезно оценивать
var getShadow = function(design, board) { var player = board.getValue(board.player); if (player === null) return []; if (_.isUndefined(board.shadow)) { board.shadow = []; _.each(design.allPositions(), function(pos) { var piece = board.getPiece(pos); if ((piece !== null) && (piece.type < 7)) { var value = piece.type + 7; if (piece.player != player) { value = -value; } board.shadow.push(value); } }); } return board.shadow; } var isFriend = function(design, x) { return x > 0; } var isPiece = function(design, x, y) { return x == y; } var isAttacker = function(design, x, enemy) { if (x < 0) return false; if ((x == 13) && (enemy == 7)) return true; if (!chinese && (x == 7) && (enemy == 13)) return false; if (!chinese && (x == 12)) return false; return x <= enemy; } var isDefender = function(design, x, enemy, friend) { if (!isAttacker(design, x, enemy)) return false; return design.price[friend] <= design.price[enemy]; } var estimate = function(design, board, p, y, z) { var shadow = getShadow(design, board); if (shadow.length == 0) return 0; var r = 0; _.each(shadow, function(x) { if (p(design, x, y, z)) r++; }); return (100 * r) / shadow.length; }
Игрок может оценивать вероятности, ведя учёт фигур, выбывших из игры. В принципе, то же самое может делать и бот, но есть более простой способ — просмотреть все ещё не открытые фигуры скопом и на основе собранной информации оценивать вероятность открытия желаемой. При этом, не гарантируется успешность выбранного хода, но если вероятность благоприятного исхода низка, ход не будет выбираться вообще.
В принципе, подход себя оправдал, но ещё есть над чем поработать
Пока не очень хорошо получаются защитные ходы. Некоторые фигуры отважно идут навстречу более сильному врагу, вместо того чтобы от него убегать (хотя убегать в их случае, как правило, уже бесполезно). Также, есть сложности с координацией действий различных фигур (это может быть полезно, для того чтобы «загнать» остатки фигур противника). Сам подход выглядит очень перспективным, но над эвристиками ещё предстоит подумать.
Эвристики на основе «цепочек» ходов могут быть полезны не только в BanQi, но и во многих других играх, с преобладанием «тихоходных» фигур (если и не в качестве определяющего критерия, то для предварительной оценки качества ходов в более сложных алгоритмах, по крайней мере). Особенно востребован этот подход в тех играх, для которых применение минимаксных алгоритмов затруднено или вообще невозможно (таких как Yonin Shogi, например).
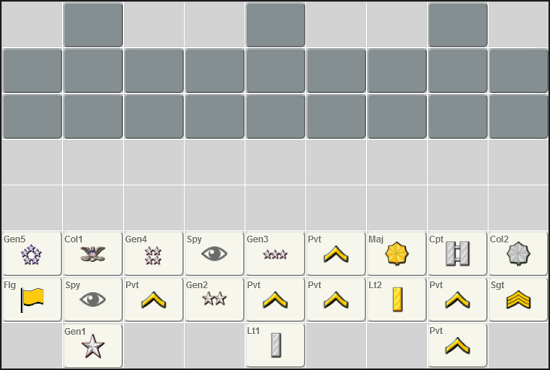
Разумеется, я собираюсь продолжить работу над играми с неполной информацией. На рисунке изображена филиппинская "Игра генералов", пока ещё не готовая. Это самая простая игра из большого семейства, включающего в себя такие игры как LuzhanQi и Stratego. И конечно, я всё ещё рассчитываю сделать работающего бота для "Джунглей"!
Эвристики на основе «цепочек» ходов могут быть полезны не только в BanQi, но и во многих других играх, с преобладанием «тихоходных» фигур (если и не в качестве определяющего критерия, то для предварительной оценки качества ходов в более сложных алгоритмах, по крайней мере). Особенно востребован этот подход в тех играх, для которых применение минимаксных алгоритмов затруднено или вообще невозможно (таких как Yonin Shogi, например).
Разумеется, я собираюсь продолжить работу над играми с неполной информацией. На рисунке изображена филиппинская "Игра генералов", пока ещё не готовая. Это самая простая игра из большого семейства, включающего в себя такие игры как LuzhanQi и Stratego. И конечно, я всё ещё рассчитываю сделать работающего бота для "Джунглей"!
А для тех, кто меня всё ещё читает, могу предложить ещё одну забавную игру-головоломку со скрытой информацией:

Я играл в неё в детстве, на программируемом калькуляторе, называется «Охота на лис». На поле случайным образом спрятаны 8 лис, которых надо найти «методом тыка». При выборе пустой области, отображается суммарное количество лис по всем восьми направлениям. Проиграть невозможно, но можно посоревноваться на минимальное количество кликов. И если будете играть в наушниках, убавьте звук. Возможно, я перестарался со звуковыми эффектами.

