Современные микроэлектронные технологии — как «Десять негритят». Стоимость разработки и оборудования так велика, что с каждым новым шагом вперёд кто-то отваливается. После новости об отказе GlobalFoundries от разработки 7 нм их осталось трое: TSMC, Intel и Samsung. А что такое, собственно “проектные нормы” и где там тот самый заветный размер 7 нм? И есть ли он там вообще?

Рисунок 1. Транзистор Fairchild FI-100, 1964 год.
Самые первые серийные МОП-транзисторы вышли на рынок в 1964 году и, как могут увидеть из рисунка искушенные читатели, они почти ничем не отличались от более-менее современных — кроме размера (посмотрите на проволоку для масштаба).
Зачем уменьшать размер транзисторов? Самый очевидный ответ на этот вопрос носит название закона Мура и гласит, что каждые два года количество транзисторов на кристалле должно увеличиваться вдвое, а значит линейные размеры транзисторов должны уменьшаться в корень из двух раз. «Должно» — согласно наблюдениям Гордона Мура (и некоторых других инженеров) в семидесятых. Из закона Мура следует много других факторов, составляющих дорожную карту микроэлектроники ITRS. Наиболее простая и грубая формулировка методов реализации закона Мура (также известная как закон миниатюризации Деннарда) — рост числа транзисторов на чипе не должен приводить к росту плотности потребляемой мощности, то есть с уменьшением размеров транзисторов должны пропорционально уменьшаться напряжение питания и рабочий ток.
Ток через МОП-транзистор пропорционален отношению его ширины к длине, а значит мы можем сохранять один и тот же ток, пропорционально уменьшая оба этих параметра. Более того, уменьшая размеры транзистора, мы уменьшаем еще и емкость затвора (пропорциональную произведению длины и ширины канала), делая схему еще быстрее. В общем, в цифровой схеме нет практически никаких причин делать транзисторы больше, чем минимально допустимый размер. Дальше начинаются нюансы насчет того, что в логике p-канальные транзисторы обычно несколько шире n-канальных, чтобы скомпенсировать разницу в подвижности носителей заряда, а в памяти наоборот, n-канальные транзисторы шире, чтобы память нормально записывалась через некомплементарный ключ, но это действительно нюансы, а глобально — чем меньше размеры транзистора — тем лучше для цифровых схем.
Именно поэтому длина канала всегда была самым маленьким размером в топологии микросхемы, и самым логичным обозначением проектных норм.
Здесь надо заметить, что вышеописанные рассуждения про размер не справедливы для аналоговых схем. Например, прямо сейчас на втором мониторе моего компьютера — согласованная пара транзисторов по 150 нм технологии, по 32 куска размером 8/1 мкм каждый. Так делается для того, чтобы обеспечить идентичность этих двух транзисторов, несмотря на технологический разброс параметров. Площадь при этом имеет второстепенное значение.
У технологов и топологов существует так называемая лямбда-система типовых размеров топологии. Она очень удобна для изучения проектирования (и была придумана в университете Беркли, если я не ошибаюсь) и переноса дизайнов с фабрики на фабрику. Фактически, это обобщение типичных размеров и технологических ограничений, но немного загрубленное, чтобы на любой фабрике точно получилось. На ее примере удобно посмотреть на типовые размеры элементов в микросхеме. Принципы в основе лямбда-системы очень просты:
Из третьего пункта следует, в частности, то, что лямбда в старых технологиях — половина проектной нормы (точнее, что длина канала транзистора и проектные нормы — две лямбды).

Рисунок 2. Пример топологии, выполненной по лямбда-системе.
Лямбда-система отлично работала на старых проектных нормах, позволяя удобно переносить производство с фабрики на фабрику, организовывать вторых поставщиков микросхем и делать много еще чего полезного. Но с ростом конкуренции и количества транзисторов на чипе фабрики стали стремиться сделать топологию немного компактнее, поэтому сейчас правила проектирования, соответствующие «чистой» лямбда-системе, уже не встретить, разве что в ситуациях, когда разработчики самостоятельно их загрубляют, имея в виду вероятность производства чипа на разных фабриках. Тем не менее, за долгие годы в отрасли сложилась прямая связь «проектные нормы = длина канала транзистора», которая успешно существовала до тех пор, пока размеры транзисторов не достигли десятков нанометров.
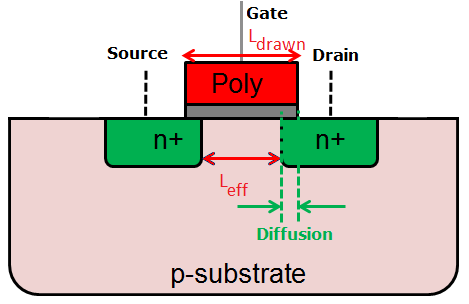
Рисунок 3. Схематичный разрез транзистора.
На этом рисунке приведен ОЧЕНЬ сильно упрощенный разрез обычного планарного (плоского) транзистора, демонстрирующий разницу между топологической длиной канала (Ldrawn) и эффективной длиной канала (Leff). Откуда берется разница?
Говоря о микроэлектронной технологии, почти всегда упоминают фотолитографию, но гораздо реже — другие, ничуть не менее важные технологические операции: травление, ионную имплантацию, диффузию и т.д. и т.п. Для нашего с вами разговора будет не лишним напоминание о том, как работают диффузия и ионная имплантация.
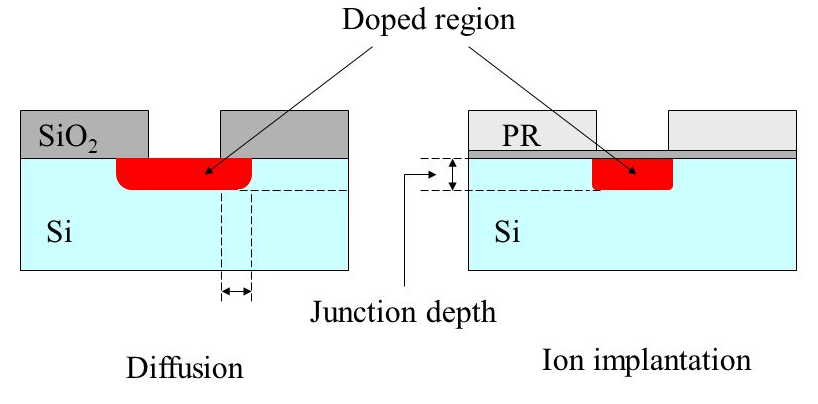
Рисунок 4. Сравнение диффузии и ионной имплантации.
С диффузией все просто. Вы берете кремниевую пластину, на которой заранее (с помощью фотолитографии) нанесен рисунок, закрывающий оксидом кремния те места, где примесь не нужна, и открывающий те, где она нужна. Дальше нужно поместить газообразную примесь в одну камеру с кристаллом и нагреть до температуры, при которой примесь начнет проникать в кремний. Регулируя температуру и длительность процесса, можно добиться требуемого количества и глубины примеси.
Очевидный минус диффузии — то, что примесь проникает в кремний во всех направлениях одинаково, что вниз, что вбок, таким образом сокращая эффективную длину канала. И мы говорим сейчас о сотнях нанометров! Пока проектные нормы измерялись в десятках микрон, все было нормально, но разумеется, такое положение дел не могло продолжаться долго, и на смену диффузии пришла ионная имплантация.
При ионной имплантации пучок ионов примеси разгоняется и направляется на пластину кремния. При этом все ионы движутся в одном направлении, что практически исключает их расползание в стороны. В теории, конечно же. На практике ионы все-таки немного расползаются в стороны, хоть и на гораздо меньшие расстояния, чем при диффузии.
Тем не менее, если мы возвратимся к рисунку транзистора, то увидим, что разница между топологической и эффективной длиной канала начинается именно из-за этого небольшого расползания. Ей, в принципе, можно было бы пренебречь, но она — не единственная причина различия. Есть еще короткоканальные эффекты. Их пять, и они разными способами изменяют параметры транзистора в случае, если длина канала приближается к различным физическим ограничениям. Описывать все их я не буду, остановлюсь на самом релевантном для нас — DIBL (Drain-Induced Barrier Lowering, индуцированное стоком снижение потенциального барьера).
Для того, чтобы попасть в сток, электрон (или дырка) должен преодолеть потенциальный барьер стокового pn-перехода. Напряжение на затворе уменьшает этот барьер, таким образом управляя током через транзистор, и мы хотим, чтобы напряжение на затворе было единственным управляющим напряжением. К сожалению, если канал транзистора слишком короткий, на поведение транзистора начинает влиять стоковый pn-переход, который во-первых, снижает поровогое напряжение (см. рисунок ниже), а во-вторых, на ток через транзистор начинает влиять напряжение не только на затворе, но и на стоке, потому что толщина стокового pn-перехода увеличивается пропорционально напряжению на стоке и соответственно укорачивает канал.

Рисунок 5. Эффект Drain-Induced Barrier Lowering (DIBL).
Источник — википедия.
Кроме того, уменьшение длины канала приводит к тому, что носители заряда начинают свободно попадать из истока в сток, минуя канал и формируя ток утечки (bad current на рисунке ниже), он же статическое энергопотребление, отсутствие которого было одной из важных причин раннего успеха КМОП-технологии, довольно тормозной по сравнению с биполярными конкурентами того времени. Фактически, каждый транзистор в современной технологии имеет стоящий параллельно ему резистор, номинал которого тем меньше, чем меньше длина канала.

Рисунок 6. Рост статического потребления из-за утечек в технологиях с коротким каналом.
Источник — Synopsys.

Рисунок 7. Доля статического энергопотребления микропроцессоров на разных проектных нормах.
Источник — B. Dieny et. al., «Spin-Transfer Effect and its Use in Spintronic Components», International Journal of Nanotechnology, 2010
Сейчас же, как вы можете видеть на рисунке выше, статическое потребление существенно превышает динамическое и является важным препятстствием для создания малопотребляющих микросхем, например, для носимой электроники и интернета вещей. Собственно, примерно в момент, когда это стало важной проблемой, и начался маркетинговый мухлеж с проектными нормами, потому что прогресс в литографии стал опережать прогресс в физике.
Для борьбы с нежелательными эффектами короткого канала на проектных нормах 800-32 нанометров было придумано очень много разных технологических решений, и я не буду описывать их все, иначе статья разрастется до совсем уж неприличных размеров, но с каждым новым шагом приходилось внедрять новые решения — дополнительные легирования областей, прилегающих к pn-переходам, легирования в глубине для предотвращения утечек, локальное превращение кремния в транзисторах в кремний-германий… Ни один шаг в уменьшении размеров транзисторов не дался просто так.

Рисунок 8. Эффективная длина канала в технологиях 90 нм и 32 нм. Транзисторы сняты в одном и том же масштабе. Полукруги на рисунках — это форма дополнительного слабого подлегирования стоков (LDD, lightly doped drain), делаемого для уменьшения ширины pn-переходов.
Источник — Synopsys.
Типичные размеры металлизации и расстояния между элементами при переходе от 90 нм до примерно 28 нм уменьшались пропорционально уменьшению цифры проектных норм, то есть типовой размер следующего поколения составлял 0.7 от предыдущего (чтобы, согласно закону Мура, получить двукратное уменьшение площади). Одновременно с этим длина канала уменьшалась в лучшем случае как 0.9 от предыдущего поколения, а эффективная длина канала практически не менялась вовсе. Из рисунка выше хорошо видно, что линейные размеры транзисторов при переходе от 90 нм к 32 нм изменились вообще не в три раза, и все игры технологов были вокруг уменьшения перекрытий затвора и легированных областей, а также вокруг контроля за статическими утечками, который не позволяли делать канал короче.
В итоге стали понятны две вещи:
Закон Мура — это вообще противоречивая тема, потому что он является не законом природы, а эмпирическим наблюдением некоторых фактов из истории одной конкретной компании, экстраполированном на будущий прогресс всей отрасли. Собственно, популярность закона Мура неразрывно связана с маркетологами Intel, которые сделали его своим знаменем и, на самом деле, много лет толкали индустрию вперед, заставляя ее соответствовать закону Мура там, где, возможно, стоило бы немного подождать.
Какой выход нашли из ситуации маркетологи? Весьма изящный.
Длина канала транзистора — это хорошо, но как по ней оценить выигрыш площади, который дает переход на новые проектные нормы? Довольно давно в индустрии для этого использовалась площадь шеститранзисторной ячейки памяти — самого популярного строительного блока микропроцессоров. Именно из таких ячеек обычно состоит кэш-память и регистровый файл, которые могут занимать полкристалла, и именно поэтому схему и топологию шеститранзисторной ячейки всегда тщательно вылизывают до предела (часто — специальные люди, которые только этим и занимаются), так что это действительно хорошая мера плотности упаковки.
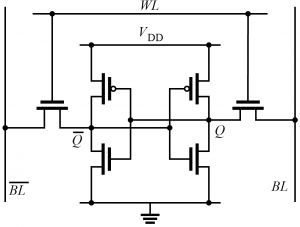
Рисунок 9. Схема шеститранзисторной ячейки статической памяти.

Рисунок 10. Разные варианты топологии шеститранзисторной ячейки статической памяти. Источник — G. Apostolidis et. al., «Design and Simulation of 6T SRAM Cell Architectures in 32nm Technology», Journal of Engineering Science and Technology Review, 2016
Так что довольно давно в описаниях технологий цифру проектных норм сопровождала вторая цифра — площадь ячейки памяти, которая, по идее, должна быть производной от длины канала. А дальше случилась интересная подмена понятий. В момент, когда прямое масштабирование перестало работать, и длина канала перестала уменьшаться каждые два года по закону Мура, маркетологи догадались, что можно не выводить площадь ячейки памяти из проектных норм, а выводить цифру проектных норм из площади ячейки памяти!
То есть натурально “раньше у нас была длина канала 65 нм и площадь ячейки памяти Х, а теперь длина канала 54 нм, но мы ужали металлизацию, и теперь площадь ячейки стала Х/5, что примерно соответствует переходу от 65 до 28 нм. Так давайте всем скажем, что у нас проектные нормы 28 нм, а про длину канала 54 нм никому говорить не будем?” Справедливости ради, “ужали металлизацию” — это тоже важное достижение, и какое-то время после начала проблем с миниатюризацией собственно транзисторов озвученным проектным нормам соответствовала минимальная ширина металлизации, размер контакта к транзистору или еще какая-нибудь цифра на топологии. Но дальше начались пляски с FinFET транзисторами, у которых ключевые размеры никак не связаны с разрешением литографии, скорости миниатюризации транзисторов и всего остального окончательно разошлись, и единственной нормальной цифрой осталась площадь ячейки памяти, на основе которой нам сейчас и сообщают про “10”, “7” и “5” нанометров.

Рисунок 11. Сравнение технологий 14 нм и 10 нм Intel.
Источник — Intel.
Вот отличный пример этого “нового скейлинга”. Нам показывают, как поменялись характерные размеры в ячейке памяти. Многие параметры, но о длине и ширине канала транзистора тут ни слова!
Как решали проблему невозможности уменьшения длины канала и контроля за утечками технологи?
Они нашли два пути. Первый — в лоб: если причина утечек — большая глубина имплантации, давайте ее уменьшим, желательно радикально. Технология «кремний на изоляторе» (КНИ) известна уже очень давно (и активно применялась все эти годы, например в 130-32 нм процессорах AMD, 90 нм процессоре приставки Sony Playstation 3, а также в радиочастотной, силовой или космической электронике), но с уменьшением проектных норм она получила второе дыхание.

Рисунок 12. Сравнение транзисторов, выполненных по обычной объемной и FDSOI (полностью обедненный КНИ) технологиях.
Источник — ST Microelectronics.
Как видите, идея более чем элегантная — под очень тонким активным слоем располагается оксид, убирающий вредный ток утечки на корню! Заодно, за счет уменьшения емкости pn-переходов (убрали четыре из пяти сторон куба стока) увеличивается быстродействие и еще уменьшается энергопотребление. Именно поэтому сейчас технологии FDSOI 28-22-20 нм активно рекламируются как платформы для микросхем интернета вещей — потребление действительно сокращается в разы, если не на порядок. И еще такой подход позволяет в перспективе поскейлить обычный плоский транзистор до уровня 14-16 нм, чего объемная технология уже не позволит.
Тем не менее, ниже 14 нм на FDSOI особенно не опуститься, да и другие проблемы у технологии тоже есть (например, страшная дороговизна подложек КНИ), в связи с чем индустрия пришла к другому решению — FinFET транзисторам. Идея FinFET транзистора тоже весьма элегантна. Мы хотим, чтобы бОльшая часть пространства между стоком и истоком управлялась затвором? Так давайте окружим это пространство затвором со всех сторон! Хорошо, не со всех, трех будет вполне достаточно.

Рисунок 13. Структура FinFET.
Источник — A. Tahrim et.al., «Design and Performance Analysis of 1-Bit FinFET Full Adder Cells for Subthreshold Region at 16 nm Process Technology», Journal of Nanomaterials, 2015

Рисунок 14. Сравнение энергопотребления разных вариантов сумматора, выполненных на планарных транзисторах и на FinFET.
Источник — A. Tahrim et.al., «Design and Performance Analysis of 1-Bit FinFET Full Adder Cells for Subthreshold Region at 16 nm Process Technology», Journal of Nanomaterials, 2015
В FinFET канал не плоский и находящийся прямо под поверхностью подложки, а образует вертикальный плавник (Fin — это и есть плавник), выступающий над поверхностью и с трех сторон окруженный затвором. Таким образом, все пространство между стоком и истоком контролируется затвором, и статические утечки очень сильно уменьшаются. Первыми FinFET серийно выпустили Intel на проектных нормах 22 нм, дальше подтянулись остальные топовые производители, включая такого апологета КНИ, как Global Foundries (бывшие AMD).
Вертикальность канала в FinFET, кроме всего прочего, позволяет экономить на площади ячейки, потому что FinFET c широким каналом довольно узкий в проекции, и это, в свою очередь, опять помогло маркетологам с их рассказами про площадь ячейки памяти и ее двухкратное уменьшение с каждым новым шагом «проектных норм», уже никак не привязанных к физическим размерам транзистора.

Рисунок 15. Топологии разных вариантов ячеек памяти (5T-9T) в технологии с FinFET. Источник — M. Ansari et. al., «A near-threshold 7T SRAM cell with high write and read margins and low write time for sub-20 nm FinFET technologies», the VLSI Journal on Integration, Volume 50, June 2015.
Вот примеры разных вариантов ячеек памяти в технологии с FinFET. Видите, как геометрическая ширина канала намного меньше длины? Также можно видеть, что, несмотря на все пертурбации, лямбда-система у топологов все еще в ходу для количественных оценок. А что с абсолютными цифрами?

Рисунок 16. Некоторые размеры транзисторов в 14-16 нм технологиях.
Источник — the ConFab 2016 conference proceedings.
Как видно из рисунка, топологическая длина канала в 16 нм FinFET технологиях все еще больше, чем 20-25 нм, о которых говорилось выше. И это логично, ведь физику не обманешь. Но из этого же рисунка можно сделать и другой, более интересный вывод: если присмотреться, то становится понятно, что минимальный имеющийся в транзисторах размер — это не длина канала, а ширина плавника. И тут нас ожидает забавное открытие: ширина плавника в техпроцессе Intel 14 nm составляет (барабанная дробь!) ВОСЕМЬ нанометров.
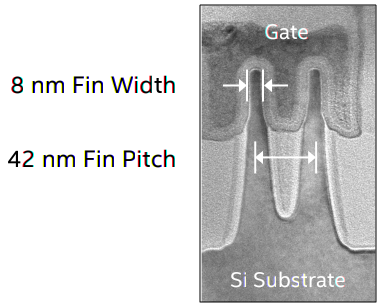
Рисунок 17. Размеры плавника в 14 нм техпроцессе Intel.
Источник — wikichip.org
Как видите, тут маркетологи, привязавшись к размерам ячейки памяти, обманули сами себя, и теперь вынуждены озвучивать цифру больше, чем могли бы. На самом деле, конечно, в условиях принципиального изменения структуры транзистора и ожидания пользователей услышать какую-то метрику, использование метрики, отражающей плотность упаковки, было, наверное, единственно верным решением, и маркетологи в конечном счете оказались правы, хоть это и приводит иногда к забавным ситуациям, когда одни и те же проектные нормы в разных компаниях называют по-разному. Например, читая новости о том, что TSMC уже запустила 7 нм, а Intel опять задерживает начало производства 10 нм, стоит помнить о том, что 7 нм TSMC и 10 нм Intel — это на самом деле одни и те же проектные нормы с точки зрения и плотности упаковки, и размеров отдельных транзисторов.
Что дальше? На самом деле, никто не знает. Закон Мура исчерпал себя уже довольно давно, и если десять лет назад ответ на вопрос «что дальше?» можно было найти в отчетах исследовательских центров, то сейчас все чаще слышно о том, что от перспективных разработок приходится отказываться, так как они оказываются чрезмерно сложными во внедрении. Так уже произошло с пластинами диаметром 450 миллиметров, так частично происходит с EUV-литографией (с которой ученые носились лет двадцать), так, видимо, произойдет с транзисторами на графене и углеродных нанотрубках. Еще один технологический прорыв нужен, но пути к нему, как это ни прискорбно, пока не видно. Дошло до того, что новый директор TSMC Марк Лиу назвал наиболее перспективным направлением развития микроэлектронной технологии не уменьшение размеров транзисторов, а 3D-интеграцию. «Настоящая» 3D-интеграция, а не объединение нескольких чипов в одном корпусе действительно будет огромной вехой в развитии микроэлектроники, но вот закон Мура как закон уменьшения размеров транзисторов, кажется, умер окончательно.
Рисунок 1. Транзистор Fairchild FI-100, 1964 год.
Самые первые серийные МОП-транзисторы вышли на рынок в 1964 году и, как могут увидеть из рисунка искушенные читатели, они почти ничем не отличались от более-менее современных — кроме размера (посмотрите на проволоку для масштаба).
Зачем уменьшать размер транзисторов? Самый очевидный ответ на этот вопрос носит название закона Мура и гласит, что каждые два года количество транзисторов на кристалле должно увеличиваться вдвое, а значит линейные размеры транзисторов должны уменьшаться в корень из двух раз. «Должно» — согласно наблюдениям Гордона Мура (и некоторых других инженеров) в семидесятых. Из закона Мура следует много других факторов, составляющих дорожную карту микроэлектроники ITRS. Наиболее простая и грубая формулировка методов реализации закона Мура (также известная как закон миниатюризации Деннарда) — рост числа транзисторов на чипе не должен приводить к росту плотности потребляемой мощности, то есть с уменьшением размеров транзисторов должны пропорционально уменьшаться напряжение питания и рабочий ток.
Ток через МОП-транзистор пропорционален отношению его ширины к длине, а значит мы можем сохранять один и тот же ток, пропорционально уменьшая оба этих параметра. Более того, уменьшая размеры транзистора, мы уменьшаем еще и емкость затвора (пропорциональную произведению длины и ширины канала), делая схему еще быстрее. В общем, в цифровой схеме нет практически никаких причин делать транзисторы больше, чем минимально допустимый размер. Дальше начинаются нюансы насчет того, что в логике p-канальные транзисторы обычно несколько шире n-канальных, чтобы скомпенсировать разницу в подвижности носителей заряда, а в памяти наоборот, n-канальные транзисторы шире, чтобы память нормально записывалась через некомплементарный ключ, но это действительно нюансы, а глобально — чем меньше размеры транзистора — тем лучше для цифровых схем.
Именно поэтому длина канала всегда была самым маленьким размером в топологии микросхемы, и самым логичным обозначением проектных норм.
Здесь надо заметить, что вышеописанные рассуждения про размер не справедливы для аналоговых схем. Например, прямо сейчас на втором мониторе моего компьютера — согласованная пара транзисторов по 150 нм технологии, по 32 куска размером 8/1 мкм каждый. Так делается для того, чтобы обеспечить идентичность этих двух транзисторов, несмотря на технологический разброс параметров. Площадь при этом имеет второстепенное значение.
У технологов и топологов существует так называемая лямбда-система типовых размеров топологии. Она очень удобна для изучения проектирования (и была придумана в университете Беркли, если я не ошибаюсь) и переноса дизайнов с фабрики на фабрику. Фактически, это обобщение типичных размеров и технологических ограничений, но немного загрубленное, чтобы на любой фабрике точно получилось. На ее примере удобно посмотреть на типовые размеры элементов в микросхеме. Принципы в основе лямбда-системы очень просты:
- если сдвиг элементов на двух разных фотолитографических масках имеет катастрофические последствия (например, короткое замыкание), то запас размеров для предотвращения несостыковок должен быть не менее двух лямбд;
- если сдвиг элементов имеет нежелательные, но не катастрофические последствия, запас размеров должен быть не менее одной лямбды;
- минимально допустимый размер окон фотошаблона — две лямбды.
Из третьего пункта следует, в частности, то, что лямбда в старых технологиях — половина проектной нормы (точнее, что длина канала транзистора и проектные нормы — две лямбды).
Рисунок 2. Пример топологии, выполненной по лямбда-системе.
Лямбда-система отлично работала на старых проектных нормах, позволяя удобно переносить производство с фабрики на фабрику, организовывать вторых поставщиков микросхем и делать много еще чего полезного. Но с ростом конкуренции и количества транзисторов на чипе фабрики стали стремиться сделать топологию немного компактнее, поэтому сейчас правила проектирования, соответствующие «чистой» лямбда-системе, уже не встретить, разве что в ситуациях, когда разработчики самостоятельно их загрубляют, имея в виду вероятность производства чипа на разных фабриках. Тем не менее, за долгие годы в отрасли сложилась прямая связь «проектные нормы = длина канала транзистора», которая успешно существовала до тех пор, пока размеры транзисторов не достигли десятков нанометров.
Рисунок 3. Схематичный разрез транзистора.
На этом рисунке приведен ОЧЕНЬ сильно упрощенный разрез обычного планарного (плоского) транзистора, демонстрирующий разницу между топологической длиной канала (Ldrawn) и эффективной длиной канала (Leff). Откуда берется разница?
Говоря о микроэлектронной технологии, почти всегда упоминают фотолитографию, но гораздо реже — другие, ничуть не менее важные технологические операции: травление, ионную имплантацию, диффузию и т.д. и т.п. Для нашего с вами разговора будет не лишним напоминание о том, как работают диффузия и ионная имплантация.
Рисунок 4. Сравнение диффузии и ионной имплантации.
С диффузией все просто. Вы берете кремниевую пластину, на которой заранее (с помощью фотолитографии) нанесен рисунок, закрывающий оксидом кремния те места, где примесь не нужна, и открывающий те, где она нужна. Дальше нужно поместить газообразную примесь в одну камеру с кристаллом и нагреть до температуры, при которой примесь начнет проникать в кремний. Регулируя температуру и длительность процесса, можно добиться требуемого количества и глубины примеси.
Очевидный минус диффузии — то, что примесь проникает в кремний во всех направлениях одинаково, что вниз, что вбок, таким образом сокращая эффективную длину канала. И мы говорим сейчас о сотнях нанометров! Пока проектные нормы измерялись в десятках микрон, все было нормально, но разумеется, такое положение дел не могло продолжаться долго, и на смену диффузии пришла ионная имплантация.
При ионной имплантации пучок ионов примеси разгоняется и направляется на пластину кремния. При этом все ионы движутся в одном направлении, что практически исключает их расползание в стороны. В теории, конечно же. На практике ионы все-таки немного расползаются в стороны, хоть и на гораздо меньшие расстояния, чем при диффузии.
Тем не менее, если мы возвратимся к рисунку транзистора, то увидим, что разница между топологической и эффективной длиной канала начинается именно из-за этого небольшого расползания. Ей, в принципе, можно было бы пренебречь, но она — не единственная причина различия. Есть еще короткоканальные эффекты. Их пять, и они разными способами изменяют параметры транзистора в случае, если длина канала приближается к различным физическим ограничениям. Описывать все их я не буду, остановлюсь на самом релевантном для нас — DIBL (Drain-Induced Barrier Lowering, индуцированное стоком снижение потенциального барьера).
Для того, чтобы попасть в сток, электрон (или дырка) должен преодолеть потенциальный барьер стокового pn-перехода. Напряжение на затворе уменьшает этот барьер, таким образом управляя током через транзистор, и мы хотим, чтобы напряжение на затворе было единственным управляющим напряжением. К сожалению, если канал транзистора слишком короткий, на поведение транзистора начинает влиять стоковый pn-переход, который во-первых, снижает поровогое напряжение (см. рисунок ниже), а во-вторых, на ток через транзистор начинает влиять напряжение не только на затворе, но и на стоке, потому что толщина стокового pn-перехода увеличивается пропорционально напряжению на стоке и соответственно укорачивает канал.
Рисунок 5. Эффект Drain-Induced Barrier Lowering (DIBL).
Источник — википедия.
Кроме того, уменьшение длины канала приводит к тому, что носители заряда начинают свободно попадать из истока в сток, минуя канал и формируя ток утечки (bad current на рисунке ниже), он же статическое энергопотребление, отсутствие которого было одной из важных причин раннего успеха КМОП-технологии, довольно тормозной по сравнению с биполярными конкурентами того времени. Фактически, каждый транзистор в современной технологии имеет стоящий параллельно ему резистор, номинал которого тем меньше, чем меньше длина канала.
Рисунок 6. Рост статического потребления из-за утечек в технологиях с коротким каналом.
Источник — Synopsys.
Рисунок 7. Доля статического энергопотребления микропроцессоров на разных проектных нормах.
Источник — B. Dieny et. al., «Spin-Transfer Effect and its Use in Spintronic Components», International Journal of Nanotechnology, 2010
Сейчас же, как вы можете видеть на рисунке выше, статическое потребление существенно превышает динамическое и является важным препятстствием для создания малопотребляющих микросхем, например, для носимой электроники и интернета вещей. Собственно, примерно в момент, когда это стало важной проблемой, и начался маркетинговый мухлеж с проектными нормами, потому что прогресс в литографии стал опережать прогресс в физике.
Для борьбы с нежелательными эффектами короткого канала на проектных нормах 800-32 нанометров было придумано очень много разных технологических решений, и я не буду описывать их все, иначе статья разрастется до совсем уж неприличных размеров, но с каждым новым шагом приходилось внедрять новые решения — дополнительные легирования областей, прилегающих к pn-переходам, легирования в глубине для предотвращения утечек, локальное превращение кремния в транзисторах в кремний-германий… Ни один шаг в уменьшении размеров транзисторов не дался просто так.
Рисунок 8. Эффективная длина канала в технологиях 90 нм и 32 нм. Транзисторы сняты в одном и том же масштабе. Полукруги на рисунках — это форма дополнительного слабого подлегирования стоков (LDD, lightly doped drain), делаемого для уменьшения ширины pn-переходов.
Источник — Synopsys.
Типичные размеры металлизации и расстояния между элементами при переходе от 90 нм до примерно 28 нм уменьшались пропорционально уменьшению цифры проектных норм, то есть типовой размер следующего поколения составлял 0.7 от предыдущего (чтобы, согласно закону Мура, получить двукратное уменьшение площади). Одновременно с этим длина канала уменьшалась в лучшем случае как 0.9 от предыдущего поколения, а эффективная длина канала практически не менялась вовсе. Из рисунка выше хорошо видно, что линейные размеры транзисторов при переходе от 90 нм к 32 нм изменились вообще не в три раза, и все игры технологов были вокруг уменьшения перекрытий затвора и легированных областей, а также вокруг контроля за статическими утечками, который не позволяли делать канал короче.
В итоге стали понятны две вещи:
- спуститься ниже 25-20 нм без технологического прорыва не получится;
- маркетологам стало все сложнее рисовать картину соответствия прогресса технологии закону Мура.
Закон Мура — это вообще противоречивая тема, потому что он является не законом природы, а эмпирическим наблюдением некоторых фактов из истории одной конкретной компании, экстраполированном на будущий прогресс всей отрасли. Собственно, популярность закона Мура неразрывно связана с маркетологами Intel, которые сделали его своим знаменем и, на самом деле, много лет толкали индустрию вперед, заставляя ее соответствовать закону Мура там, где, возможно, стоило бы немного подождать.
Какой выход нашли из ситуации маркетологи? Весьма изящный.
Длина канала транзистора — это хорошо, но как по ней оценить выигрыш площади, который дает переход на новые проектные нормы? Довольно давно в индустрии для этого использовалась площадь шеститранзисторной ячейки памяти — самого популярного строительного блока микропроцессоров. Именно из таких ячеек обычно состоит кэш-память и регистровый файл, которые могут занимать полкристалла, и именно поэтому схему и топологию шеститранзисторной ячейки всегда тщательно вылизывают до предела (часто — специальные люди, которые только этим и занимаются), так что это действительно хорошая мера плотности упаковки.
Рисунок 9. Схема шеститранзисторной ячейки статической памяти.
Рисунок 10. Разные варианты топологии шеститранзисторной ячейки статической памяти. Источник — G. Apostolidis et. al., «Design and Simulation of 6T SRAM Cell Architectures in 32nm Technology», Journal of Engineering Science and Technology Review, 2016
Так что довольно давно в описаниях технологий цифру проектных норм сопровождала вторая цифра — площадь ячейки памяти, которая, по идее, должна быть производной от длины канала. А дальше случилась интересная подмена понятий. В момент, когда прямое масштабирование перестало работать, и длина канала перестала уменьшаться каждые два года по закону Мура, маркетологи догадались, что можно не выводить площадь ячейки памяти из проектных норм, а выводить цифру проектных норм из площади ячейки памяти!
То есть натурально “раньше у нас была длина канала 65 нм и площадь ячейки памяти Х, а теперь длина канала 54 нм, но мы ужали металлизацию, и теперь площадь ячейки стала Х/5, что примерно соответствует переходу от 65 до 28 нм. Так давайте всем скажем, что у нас проектные нормы 28 нм, а про длину канала 54 нм никому говорить не будем?” Справедливости ради, “ужали металлизацию” — это тоже важное достижение, и какое-то время после начала проблем с миниатюризацией собственно транзисторов озвученным проектным нормам соответствовала минимальная ширина металлизации, размер контакта к транзистору или еще какая-нибудь цифра на топологии. Но дальше начались пляски с FinFET транзисторами, у которых ключевые размеры никак не связаны с разрешением литографии, скорости миниатюризации транзисторов и всего остального окончательно разошлись, и единственной нормальной цифрой осталась площадь ячейки памяти, на основе которой нам сейчас и сообщают про “10”, “7” и “5” нанометров.
Рисунок 11. Сравнение технологий 14 нм и 10 нм Intel.
Источник — Intel.
Вот отличный пример этого “нового скейлинга”. Нам показывают, как поменялись характерные размеры в ячейке памяти. Многие параметры, но о длине и ширине канала транзистора тут ни слова!
Как решали проблему невозможности уменьшения длины канала и контроля за утечками технологи?
Они нашли два пути. Первый — в лоб: если причина утечек — большая глубина имплантации, давайте ее уменьшим, желательно радикально. Технология «кремний на изоляторе» (КНИ) известна уже очень давно (и активно применялась все эти годы, например в 130-32 нм процессорах AMD, 90 нм процессоре приставки Sony Playstation 3, а также в радиочастотной, силовой или космической электронике), но с уменьшением проектных норм она получила второе дыхание.
Рисунок 12. Сравнение транзисторов, выполненных по обычной объемной и FDSOI (полностью обедненный КНИ) технологиях.
Источник — ST Microelectronics.
Как видите, идея более чем элегантная — под очень тонким активным слоем располагается оксид, убирающий вредный ток утечки на корню! Заодно, за счет уменьшения емкости pn-переходов (убрали четыре из пяти сторон куба стока) увеличивается быстродействие и еще уменьшается энергопотребление. Именно поэтому сейчас технологии FDSOI 28-22-20 нм активно рекламируются как платформы для микросхем интернета вещей — потребление действительно сокращается в разы, если не на порядок. И еще такой подход позволяет в перспективе поскейлить обычный плоский транзистор до уровня 14-16 нм, чего объемная технология уже не позволит.
Тем не менее, ниже 14 нм на FDSOI особенно не опуститься, да и другие проблемы у технологии тоже есть (например, страшная дороговизна подложек КНИ), в связи с чем индустрия пришла к другому решению — FinFET транзисторам. Идея FinFET транзистора тоже весьма элегантна. Мы хотим, чтобы бОльшая часть пространства между стоком и истоком управлялась затвором? Так давайте окружим это пространство затвором со всех сторон! Хорошо, не со всех, трех будет вполне достаточно.
Рисунок 13. Структура FinFET.
Источник — A. Tahrim et.al., «Design and Performance Analysis of 1-Bit FinFET Full Adder Cells for Subthreshold Region at 16 nm Process Technology», Journal of Nanomaterials, 2015
Рисунок 14. Сравнение энергопотребления разных вариантов сумматора, выполненных на планарных транзисторах и на FinFET.
Источник — A. Tahrim et.al., «Design and Performance Analysis of 1-Bit FinFET Full Adder Cells for Subthreshold Region at 16 nm Process Technology», Journal of Nanomaterials, 2015
В FinFET канал не плоский и находящийся прямо под поверхностью подложки, а образует вертикальный плавник (Fin — это и есть плавник), выступающий над поверхностью и с трех сторон окруженный затвором. Таким образом, все пространство между стоком и истоком контролируется затвором, и статические утечки очень сильно уменьшаются. Первыми FinFET серийно выпустили Intel на проектных нормах 22 нм, дальше подтянулись остальные топовые производители, включая такого апологета КНИ, как Global Foundries (бывшие AMD).
Вертикальность канала в FinFET, кроме всего прочего, позволяет экономить на площади ячейки, потому что FinFET c широким каналом довольно узкий в проекции, и это, в свою очередь, опять помогло маркетологам с их рассказами про площадь ячейки памяти и ее двухкратное уменьшение с каждым новым шагом «проектных норм», уже никак не привязанных к физическим размерам транзистора.
Рисунок 15. Топологии разных вариантов ячеек памяти (5T-9T) в технологии с FinFET. Источник — M. Ansari et. al., «A near-threshold 7T SRAM cell with high write and read margins and low write time for sub-20 nm FinFET technologies», the VLSI Journal on Integration, Volume 50, June 2015.
Вот примеры разных вариантов ячеек памяти в технологии с FinFET. Видите, как геометрическая ширина канала намного меньше длины? Также можно видеть, что, несмотря на все пертурбации, лямбда-система у топологов все еще в ходу для количественных оценок. А что с абсолютными цифрами?
Рисунок 16. Некоторые размеры транзисторов в 14-16 нм технологиях.
Источник — the ConFab 2016 conference proceedings.
Как видно из рисунка, топологическая длина канала в 16 нм FinFET технологиях все еще больше, чем 20-25 нм, о которых говорилось выше. И это логично, ведь физику не обманешь. Но из этого же рисунка можно сделать и другой, более интересный вывод: если присмотреться, то становится понятно, что минимальный имеющийся в транзисторах размер — это не длина канала, а ширина плавника. И тут нас ожидает забавное открытие: ширина плавника в техпроцессе Intel 14 nm составляет (барабанная дробь!) ВОСЕМЬ нанометров.
Рисунок 17. Размеры плавника в 14 нм техпроцессе Intel.
Источник — wikichip.org
Как видите, тут маркетологи, привязавшись к размерам ячейки памяти, обманули сами себя, и теперь вынуждены озвучивать цифру больше, чем могли бы. На самом деле, конечно, в условиях принципиального изменения структуры транзистора и ожидания пользователей услышать какую-то метрику, использование метрики, отражающей плотность упаковки, было, наверное, единственно верным решением, и маркетологи в конечном счете оказались правы, хоть это и приводит иногда к забавным ситуациям, когда одни и те же проектные нормы в разных компаниях называют по-разному. Например, читая новости о том, что TSMC уже запустила 7 нм, а Intel опять задерживает начало производства 10 нм, стоит помнить о том, что 7 нм TSMC и 10 нм Intel — это на самом деле одни и те же проектные нормы с точки зрения и плотности упаковки, и размеров отдельных транзисторов.
Что дальше? На самом деле, никто не знает. Закон Мура исчерпал себя уже довольно давно, и если десять лет назад ответ на вопрос «что дальше?» можно было найти в отчетах исследовательских центров, то сейчас все чаще слышно о том, что от перспективных разработок приходится отказываться, так как они оказываются чрезмерно сложными во внедрении. Так уже произошло с пластинами диаметром 450 миллиметров, так частично происходит с EUV-литографией (с которой ученые носились лет двадцать), так, видимо, произойдет с транзисторами на графене и углеродных нанотрубках. Еще один технологический прорыв нужен, но пути к нему, как это ни прискорбно, пока не видно. Дошло до того, что новый директор TSMC Марк Лиу назвал наиболее перспективным направлением развития микроэлектронной технологии не уменьшение размеров транзисторов, а 3D-интеграцию. «Настоящая» 3D-интеграция, а не объединение нескольких чипов в одном корпусе действительно будет огромной вехой в развитии микроэлектроники, но вот закон Мура как закон уменьшения размеров транзисторов, кажется, умер окончательно.

