
Этот пост — перевод оригинальной статьи Пейдж Нидринхауз, full-stack software engineer. Ее основная специальность — JavaScript, но Пейдж изучает и другие языки и фреймворки. А полученным опытом делится со своими читателями. К слову, статья будет интересна начинающим разработчикам.
Недавно я столкнулась с задачей, которая меня заинтересовала, — нужно было извлечь определенные данные из огромного объема неструктурированных файлов Федеральной избирательной комиссии США. Я не слишком много работала с raw-данными, поэтому решила принять вызов и взяться за эту задачу. В качестве инструмента для ее решения я выбрала Node.js.
Skillbox рекомендует: Онлайн-курс «Профессия Frontend-разработчик».
Напоминаем: для всех читателей «Хабра» — скидка 10 000 рублей при записи на любой курс Skillbox по промокоду «Хабр».
Задача была описана четырьмя пунктами:
- Программа должна просчитывать общее число строк в файле.
- Каждая восьмая колонка содержит имя человека. Нужно загрузить эти данные и создать массив со всеми содержащимися в файле именами. Необходимо отобразить 432-е и 43 243-е имя.
- Каждая пятая колонка содержит дату внесения пожертвований добровольцами. Посчитайте, сколько всего пожертвований вносится каждый месяц, и выведите общий результат.
- Каждая восьмая колонка содержит имя человека. Создайте массив, выбрав лишь имя, без фамилии. Узнайте, какое имя встречается чаще всего и сколько раз?
(Оригинальную задачу можно просмотреть вот по этой ссылке.)
Файл, с которым необходимо работать, — обычный .txt объемом 2,55 ГБ. Есть также папка, которая содержит части главного файла (на них можно отлаживать работу программы, не занимаясь анализом всего огромного массива).
Два возможных решения на Node.js
В принципе, работой с большими файлами специалиста по JavaScript не испугать. Кроме того, именно это является одной из основных функций Node.js. Есть несколько возможных решений для чтения из файлов и записи в них.
Привычное — fs.readFile(). Оно позволяет прочитать весь файл, занеся его в память, а затем использовать Node.
Альтернатива — fs.createReadStream(), функция, передающая данные подобно тому, как это организовано в других языках — например, в Python или Java.
Решение которое я выбрала
Поскольку мне нужно было просчитывать общее число строк и парсить данные для разбора имен и дат, я решила остановиться на втором варианте. Здесь я могла использовать функцию rl.on(‘line’,...) для получения необходимых данных из строк.
Node.js CreateReadStream() & ReadFile() Code
Ниже — код, который я написала при помощи Node.js и функции fs.createReadStream().
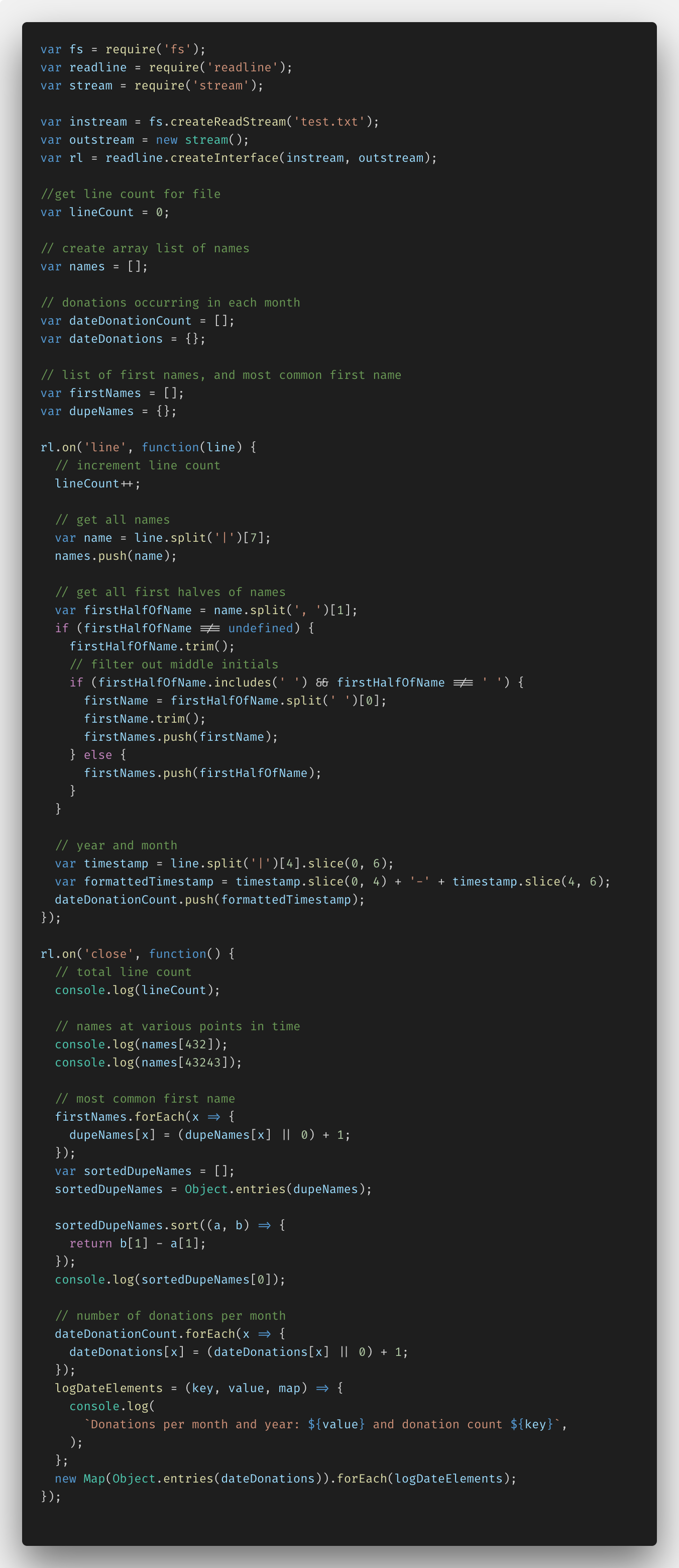
Изначально мне было нужно все настроить, понимая, что импорт данных требует таких функций Node.js, как fs (file system), readline и stream. Далее я смогла создать instream и outstream вместе с readLine.createInterface(). Полученный код дал возможность разбирать файл построчно, забирая необходимые данные.
Кроме того, я добавила несколько переменных и комментариев для работы с конкретными данными. Это lineCount, dupeNames и массивы names, donation и firstNames.
В функции rl.on('line',…) я смогла задать разбор файла построчно. Так, я ввела переменную lineCount для каждой строки. Я использовала метод JavaScript split () для парсинга имен, добавляя их в мой массив names. Далее я отделила лишь имена, без фамилий, одновременно выделяя исключения, вроде наличия двойных имен, инициалов в середине имени и т.п. Далее я отделила год и дату от колонки данных, преобразовав все это в формат YYYY-MM и добавив в массив dateDonationCount.
В функции rl.on('close',...) я выполнила все преобразования данных, добавленных в массивы, с внесением полученной информации в console.log.
lineCount и names необходимы для определения 432-го и 43 243-го имен, преобразований тут никаких не требуется. А вот выявление наиболее часто встречающегося в массиве имени и определение количества пожертвований — задачи более сложные.
Для того чтобы выявить самое частое имя, мне пришлось создать объект пар значений для каждого имени (ключа) и количества упоминаний Object.entries(). (значение), а затем преобразовать все это в массив массивов, используя функцию ES6. После этого задачи сортировки имен и выявления наиболее повторяющегося уже не представляли сложности.
С пожертвованиями я проделала примерно тот же фокус: создала объект пар значений и функцию logDateElements(), которая позволила мне, используя интерполяцию ES6, отобразить ключи и значения для каждого месяца. Затем я создала new Map(), преобразовав объект dateDonations в метамассив, и циклично обработала каждый массив при помощи logDateElements(). (Вышло не так и просто, как казалось в начале.)
Но это сработало, я смогла прочитать относительно небольшой файл объемом в 400 МБ, выделив нужную информацию.
После этого я опробовала fs.createReadStream() — я реализовала задачу на fs.readFile(), для того чтобы увидеть разницу. Вот код:
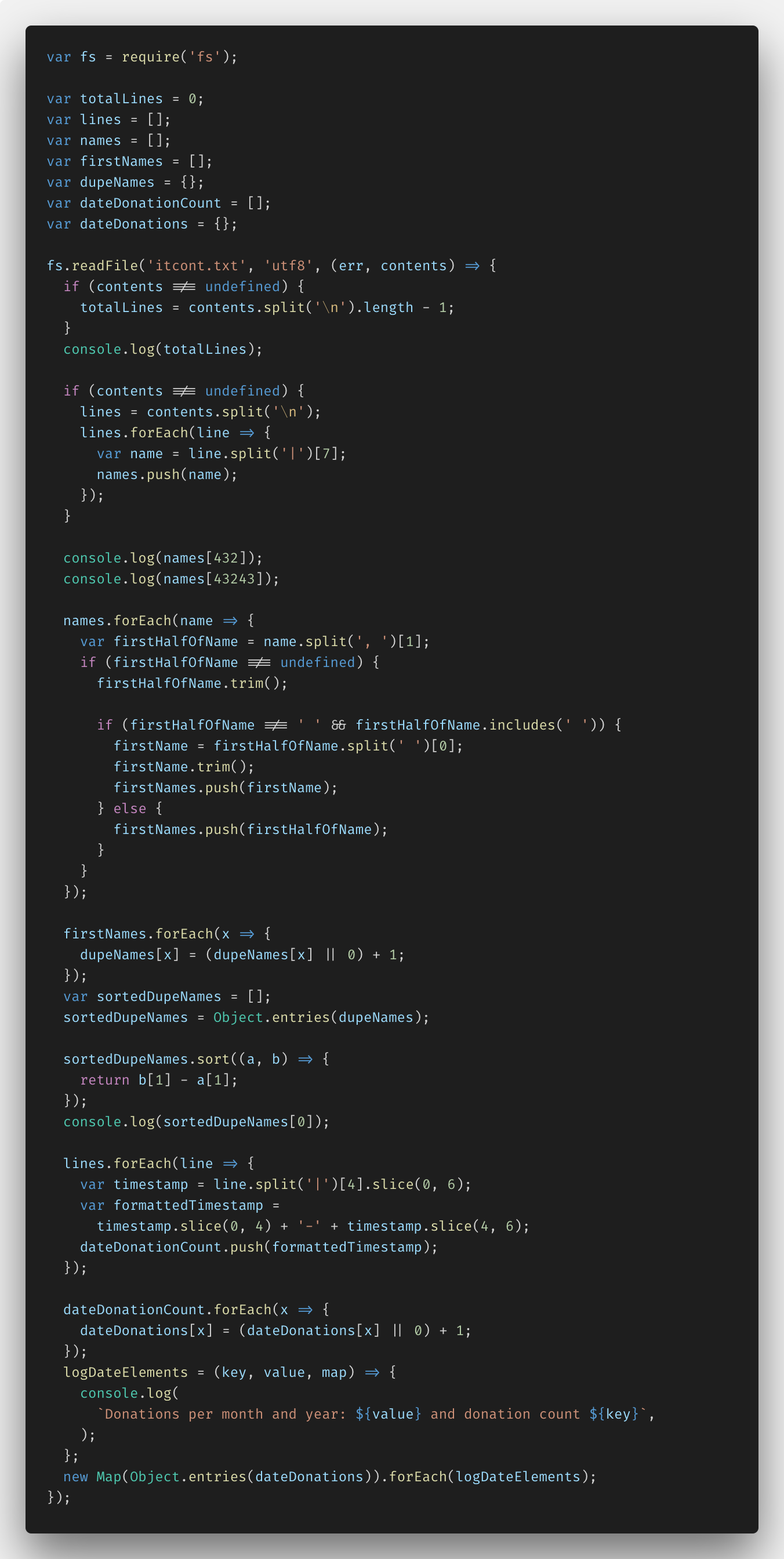
Все решение вы можете увидеть вот здесь.
Результаты работы с Node.js
Решение оказалось рабочим. Я добавила путь к файлу readFileStream.js и… наблюдала, как сервер Node упал с ошибкой JavaScript heap out of memory.

Оказалось, что, хотя все и работало, но это решение пыталось передавать все содержимое файла в память, что было невозможно с объемом в 2,55 ГБ. Node может одновременно работать с 1,5 ГБ в памяти, не больше.
Поэтому ни одно из моих решений не подошло. Понадобилось новое, которое смогло работать даже с такими объемными файлами.
Новое решение
Как оказалось, нужно было использовать популярный NPM-модуль EventStream.
Изучив документацию, я смогла понять, что нужно делать. Вот третий вариант кода программы.
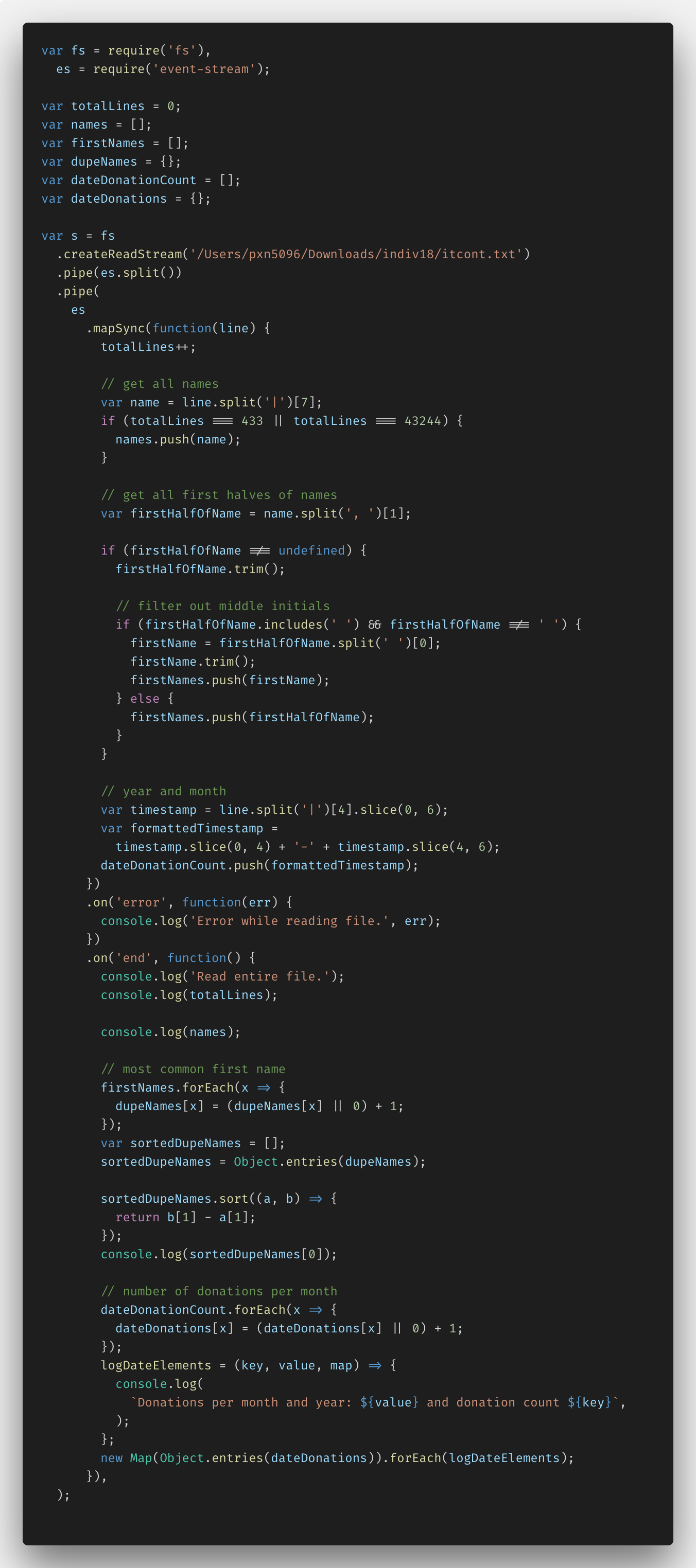
В документации к модулю было указано, что поток данных стоит разбить на отдельные элементы при помощи символа \n в конце каждой строки txt-файла.
В принципе, единственное, что мне пришлось изменить, — это ответ names. У меня не получилось поместить 130 млн имен в массив — снова проявилась ошибка нехватки памяти. Я решила проблему, просчитав 432-е и 43 243-е имя и внеся их в собственный массив. Немного не то, о чем просили в условиях, но кто сказал, что нельзя быть креативным?
Раунд 2. Пробуем программу в работе
Да, все тот же файл объемом в 2,55 ГБ, скрещиваем пальцы и следим за результатом.

Успех!
Как оказалось, просто Node.js для решения подобных задач не подходит, его возможности несколько ограничены. А вот расширив их при помощи модулей, можно работать и с такими крупными файлами.
Skillbox рекомендует:
- Практический курс «Профессия веб-разработчик».
- Практический курс «Мобильный разработчик PRO».
- Практический годовой курс «PHP-разработчик с нуля до PRO».

