Статья о том, как решали задачу оптимизации процесса удаления файлов из шардированной системы. Речь пойдет о проекте для совместного доступа и работы с файлами. Система была стартапом лет 8 назад, потом он успешно выстрелил и был несколько раз продан. В проекте 4 разработчика, которые с проектом с самого начала, что очень ценно. Документацию, традиционно, либо не успели написать, либо она не очень актуальна.
Зачем вам это читать и зачем я все это написала? Хочется рассказать о граблях, которые заботливо лежат внутри системы и бьют так, что звездочки сыпятся из глаз.
Хочу сказать большое спасибо Hanna_Hlushakova за совместную работу, доведение проекта до конца и помощь в подготовки статьи. В основном вы встретите описания проблемы и алгоритма ее решения, который мы использовали, никаких примеров кода, структур данных и других нужных вещей тут нет. Я не знаю поможет ли вам мой опыт избежать граблей у себя, но надеюсь что-то полезное вы извлечете. Возможно, данная статья будет абсолютно безвозвратной потерей драгоценного времени.

Проект входит в лидеры по квадрату Gartner, имеет клиентов-компании с численностью сотрудников более 300 тыс. человек в США и Европе, и несколько миллиардов файлов на обслуживании.
В проекте используются следующие технологии: Microsoft, серверы C# .net, БД MS SQL, 14 активных серверов + 14 в режиме зеркалирования данных.
Объем баз данных составляет до 4 Тб, постоянная нагрузка в бизнес часы — порядка 400 тыс. запросов в минуту.
В базе данных много бизнес логики:
450 таблиц
1000 хранимых процедур
80 000 строк SQL кода
Документацию традиционно либо не успели написать, либо она не актуальна.
Задача — переделать удаление файлов с хранилища, которые уже были удалены клиентами, и закончился период хранения удаленных файлов, на случай если их захотят восстановить. В текущей версии, по подсчетам самой компании, на серверах хранились файлы, которые были удалены 1 год назад, хотя по условиям бизнеса они должны были храниться только 1 месяц. Так как часть файлов хранится на S3, компания платила за лишние данные, а клиенты, которые использовали хранилище On-Premises недоумевали почему файлы занимают больше места, чем должны.
Базы данных шардированные по компании клиента.
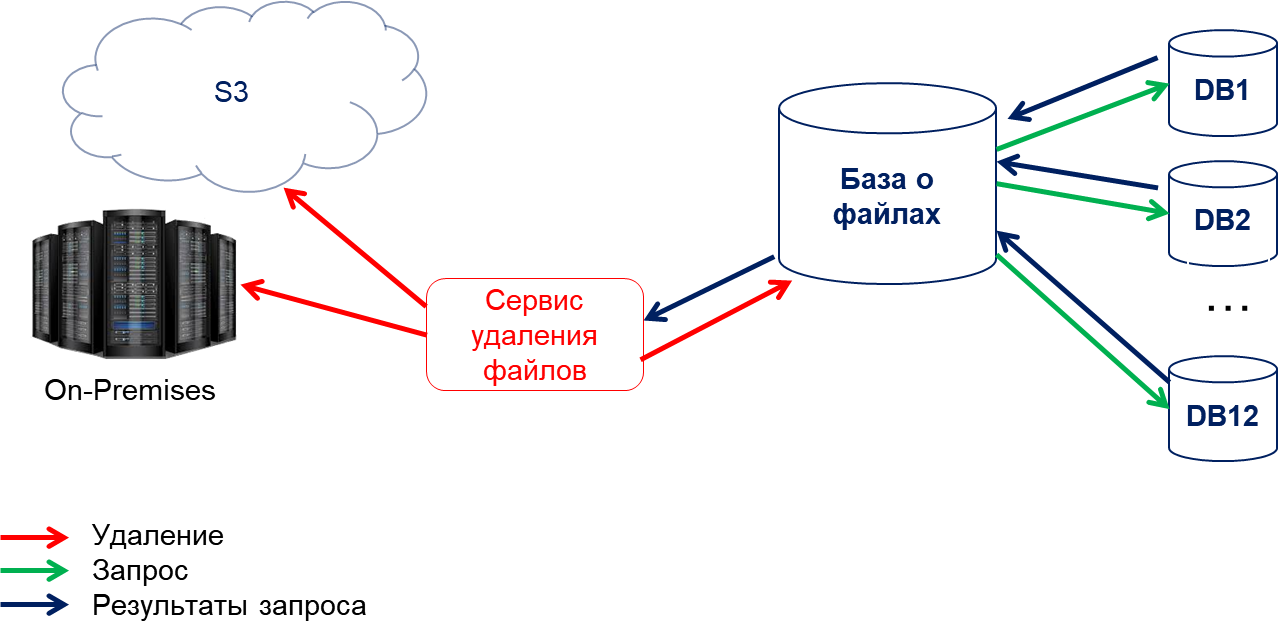
На глобальном сервере с информацией о всех файлах в системе формировались диапазоны по 15 тыс идентификаторов файлов.
Затем по расписанию запускался опрос серверов по диапазону идентификаторов файлов.
На каждый шард передавались границы диапазона.
Шард в ответ присылал найденные файлы из диапазона.
Основной сервер добавлял отсутствующие файлы в таблицу-очередь на удаление в своей БД.
Затем из таблицы-очереди сервис физического удаления файлов с хранилища получал пачку идентификаторов на удалением, после чего посылал подтверждение, что собирается удалить файлы и запускалась проверка по всем шардам — не используются ли там эти файлы.
При увеличении количества файлов такой подход стал работать очень медленно, так как файлов стало несколько миллиардов, и количество диапазонов возросло в разы. Удаленных файлов по прежнему оставалось менее 5% по сравнению с общим количеством, соответственно очень неэффективно перебирать миллиарды файлов, чтобы найти несколько миллионов удаленных из них.
Для примера, обычно после удаления файла пользователем, он должен хранится 1 месяц, на тот случай, если его нужно будет восстановить. После этого периода, файл должен быть удален программой с хранилища. При текущем количестве файлов, количестве диапазонов и скорости обхода диапазонов, серверу, чтобы полностью обойти все диапазоны, потребовался бы 1 год.
Понятно, что место не освобождалось, и это вызывало недовольство пользователей, так как на их серверах хранилось в разы больше файлов, чем должно было быть по отчетности. За дополнительно место на S3 платила сама компания, предоставляющая сервис, что являлось для нее прямым убытком.
Только на S3 к моменту начала работ хранилось 2 Петабайта удаленных файлов, и это только на облаке. Кроме того были клиенты, у которых файлы хранились на своих выделенных серверах, у которых была такая же проблема: место на сервере занимали файлы, удаленные пользователями, но не удаленные с сервера.
Решили отслеживать события удаления:
При удалении файла с шардированной базы решили использовать оптимистичный подход и убрать одну из проверок на использование. Мы знали, что 99% файлов используются только в рамках одной шарды. Решили сразу добавлять файл в очередь на удаление, и не делать проверку по остальным шардам на использование этого файла, так как проверка будет сделана еще раз при подтверждении сервисом удаления с хранилища.
Кроме того оставили текущий JOB, который проверял удаленные файлы по диапазонам, чтобы добавлять файлы, которые были удалены до релиза новой версии.
Все, что было удалено на шарде, собирается в таблицу и затем передается на один сервер, с информацией о всех файлах.
На этом сервере отправляется в таблицу-очередь на удаление.
В таблице на удаление перед удалением проверяется, что файл не используется на всех шардах. Эта часть проверки была тут еще до изменения кода, и ее решили не трогать.
На каждой из шардов добавили таблицу, в которую нужно записывать идентификатор удаленного файла.
Нашли все процедуры удаления файлов из базы, их оказалось всего 2. После удаления файла пользователем, файл еще некоторое время лежит в базе.
В процедуры удаления файла из базы добавили запись в эту локальную таблицу с удаленными файлами.
На глобальном сервере с файлами сделали JOB, который выкачивает список файлов с шардированных баз. Просто вызов процедуры с шардированной базы, она внутри делает DELETE и в OUTPUT выводит список файлов. В MS SQL Server pull — вытягивание с удаленного сервера делается существенно быстрее, чем вставка на удаленный сервер. Все это делается блоками.
Затем эти файлы добавляются в таблицу-очередь на удаление на глобальном сервере.
В таблице-очереди добавили поле с идентификатором шарда, чтобы знать, откуда пришло событие на удаление.
Есть 3 среды:
Dev — среда разработки. Код берется из develop ветки гита. Есть возможность задеплоить разную версию кода на IIS и сделать несколько версий orchestration. Подключится к dev среде из клиента внутри vpn. До недавнего времени неудобство было только с базами, так как все изменения базы могут сломать работу других частей системы. Потом базы сделали локальные. На dev сервера с базами данных можно выливать уже работающий код, чтобы не рушить всем работу. На dev среде 3 шарда, вместо 12, которые есть на проде, но этого обычно хватает для тестирования взаимодействия.
Staging — среда одинаковая с продом по версии кода (почти одинаковая, так как редко, но бывают изменения прямо на проде администраторами). Копия кода из ветки master. В БД иногда вылавливали некоторые различия с кодом на проде, но в целом они идентичны. На Staging также 3 шарда как и на деве. На staging также нет нагрузки как и на devе. Здесь можно запустить интеграционные тесты уже вчистую, так как код совпадает с продом. Все тесты должны пройти, это обязательное условие перед выходом на деплой.
Perf lab, где делаются тесты под нагрузкой. Нагрузка создается с помощью jmeter, в 10 раз меньше, чем на проде, и есть только один шард, что иногда создает неудобства. Берутся данные с прода, затем анонимизируются и используется на perf lab. Все сервера той же конфигурации, что и на проде.
Нагрузка в 10 раз меньшая, потому что предполагается, что это примерная нагрузка, которая приходит на проде на 1 шард. Минус в том, что глобальная база при этом сильно недогружена, в отличие от прода. И, если в основном изменения касаются глобальной базы данных с файлами, то на результаты теста можно полагаться только примерно — на проде это может работать не так. Хотя perf lab не идеально совпадает по нагрузке с продом, наличие возможности протестировать под нагрузкой, уже помогает выловить много ошибок до деплоя на прод.
Также есть backup сервер, где можно посмотреть данные с прода, чтобы отловить некоторые кейсы. Вообще компания работает под лицензией, которая запрещает разработчикам давать доступ к прод данным, а команде администрирования и поддержки (Operations) доступ к разработке, поэтому нужно просить помочь администраторов БД. Данные с прода очень облегчают тестирование, потому что некоторые кейсы возникают только на прод данных и очень полезно изучать данные в реальной системе, чтобы понять, как работает система у пользователя.
При тестах на perf lab выяснилось, что нагрузка по удалению файлов с хранилища не реализована от слова совсем. При реализации нагрузочного тестирования выбрали более популярные запросы от клиентского ПО, часть на очистку хранилища не вошла. Так как это база, то получилось провести упрощенное тестирование на все измененные объекты с вызовом измененных процедур на разных данных вручную. (на тех вариантах, о которых я знала).
Кроме того, и в интеграционных и в перф тестах основной упор делался на самый популярный вид хранения файла.
Дополнительная особенность перф лабы, которая выяснилась не сразу, — это несоответствие количества данных в некоторых таблицах на проде и перфе. В том смысле, что на перфе работают все JOBы с прода, которые формируют данные, но не всегда есть то, что обрабатывает сформированные в таблицу данные. И, например, упомянутая выше таблица-очередь на удаление на перфе сильно больше, чем на проде — 20 млн записей на перфе и 200 тыс на проде.
Процесс деплоя довольно стандартный. Изменений в коде приложения для этой задачи не было, все изменения только в базе данных. На базу изменения всегда накатывают DBA, этот процесс не автоматизирован. Подготавливаются 2 версии скриптов — для применения изменений и для отката изменений, и пишется инструкция для DBA. 2 версии скриптов делаются всегда, и они обязательно тестируются на накат и откат изменений. И эти же скрипты используются для применения изменений на staging и perf lab перед запуском интеграционного и нагрузочного тестирования.
За первые 5 часов после деплоя пришел 1 млн событий, о том, что клиентское ПО получило ошибку, при попытке загрузить файл. Событие “file corrupted”. Оно означает, что файл пытается скачать клиент, но файл не найден на хранилище. Обычно этих событий либо нет совсем, либо они измеряются 1 — 2 тысячами в день.
Сразу скажу, что поиск причины фейла у команды из 3х и иногда 5 человек (включая меня) занял не менее 1 недели.
Собрали весь список файлов, по которым пришло событие “File Corrupted”.
Несмотря на то, что событий было более 1 миллиона и они все были от разных пользователей, разных компаний, уникальных файлов в этом списке оказалось только 250.
DBA на backup сервере подняли для расследования бэкапы баз на момент, когда пришли события. В базах проекта есть довольно много таблиц со всякого рода логами, которые помогли в анализе. Даже при удалении информации из БД обязательно добавляется лог, что было удалено и каким событием. На проде такие записи хранятся 1 неделю, затем сливаются на архивный сервер.
И так таблицы с логами, которые очень помогли в анализе того, что произошло:
Полный лог с событиями у клиента, ведется на каждой шарде
На глобальном сервере:
Кроме того в распоряжении был ELK с логами приложения.
Ошибку удалось повторить на dev среде, что подтвердило правильность предположения. Сначала эту гипотезу никто не воспринимал всерьез, так как было очень сложно поверить, что столько факторов совпало одновременно и столько пользователей пришло именно в этот момент времени.
Оказалось, в системе было порядка 250 (для сравнения в системе миллиарды файлов) супер пупер мега популярных файлов. 250, да!
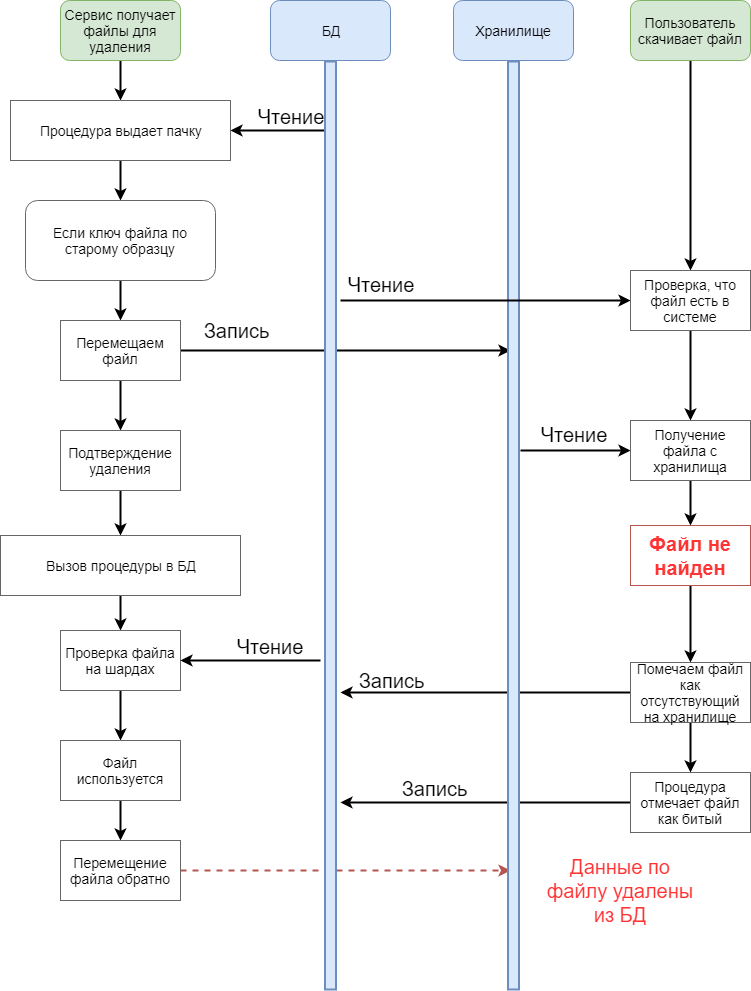
Эти файлы еще были очень старыми. В то время, когда эти файлы загружались в систему, использовалась другая система генерации ключа файла на хранилище.
Оказалось, что для такого типа ключа, метод физического удаления с физического хранилища ведет себя не так как с другими файлами.
В классе с удалением есть блок кода с условием специально для файлов со старым ключом. Система, на время удаления, до того как проверяется, что файл отсутствует на шардах, перемещает данный старый файл в другое место. Ну чтобы чего не вышло.
И, оказалось, что в момент, когда файл перемещен (а он напомню очень популярный), если кто-то из пользователей пытается дать на него права новому пользователю, клиентское ПО идет на хранилище за этим файлом, а файла в нужном месте нет. Так как он перемещен, чтобы чего не вышло. И клиентское ПО посылает сообщение, что файл битый. В БД он отмечается как битый. И вся информация удаляется из базы (ну почти вся).
А тем временем наша процедура проверки по шардам выясняет, что файл используется. И отправляет ответ, что нужно его вернуть. Но вся инфа уже удалилась из базы, и вернуть его не получается.
Забавно, да?
То есть при удалении файла пользователь попал именно в тот промежуток времени, когда файл был перемещен, шла проверка по шардам, и именно в этот момент времени пользователь послал запрос на загрузку.
Вот он — highload в действии, когда самые невероятные совпадения у вас совпадают.
Оправившись от удивления и откатив все назад, мы убедились, что файлы у пользователей живы, так как были восстановлены с дисков других клиентов.
Естественно, на тестах все было хорошо, потому что при тесте удалялись более новые файлы с новым типом ключа, который использовался последние лет 5. Такие файлы не переносятся в другое место хранения на время удаления.
У нас оптимизма поубавилось, и мы решили не идти самым оптимистичным путем.
Решили, что нужно добавить тесты на разные виды хранилищ
Добавить нагрузку на perf lab, которая использует вызовы при удалении с хранилища
Закрыть известные race conditions
Добавить мониторинг (хотя он и бы в планах, но не влез в изначальный scope)
Мониторинг сразу решили делать, но потом что-то он отошел на второй план, так как надо было быстрее деплоить.
Для мониторинга в проекте использовался Zabbix, ELK, Grafana, NewRelic, SQL Sentry и тестовая версия AppDynamics.
Из этого на pef lab был NewRelic и SQL Sentry.
Все системные метрики мы уже мерили и так, хотелось мерить бизнес метрики. У меня был опыт организации такого мониторинга через Zabbix — решили делать так же.
Схема очень простая в БД сделать таблицу, в которую по JOBу собирать нужные метрики и процедуру, которая будет выгружать собранные метрики в Zabbix.
Метрики:
Мониторинг реализовали и задеплоили на прод отдельно, до того как стали деплоить новую реализацию удаления.
В общем, мы решили, что лучше переесть, чем недоспать, и сделали новый план.
Пункт 6 при деплое включал в себя удаление проверки в несколько этапов. Сначала проверку оставили, затем через неделю отключили проверку по файлам сотрудников компании, через 2 недели — отключили проверку совсем.
Опять же все изменения касаются только базы данных.
Масштаб изменений был самым большим на глобальном сервере:
Добавить промежуточную таблицу, в которую складывать все файлы скачанные с шардов.
Сделать JOB, который бы по промежуточной таблице проверял по файлам, что они не используются на шардах.
В таблицу очередь удаленных файлов добавить поле с датой последнего обращения к файлу и добавить индекс.
Найти все процедуры с доступом к файлу — оказалось 5 процедур. Добавить в них блок изменение даты последнего использования в таблице очереди. Дата менялась каждый раз, в независимости от того была она заполнена или нет.
В процедуры выдачи файлов программе удаления добавить, чтобы она выдавала только файлы с пустой датой использования.
Добавить JOB, который собирает все файлы с датой использования и проверяет (с задержкой 10 минут, которая нужна, чтобы клиентское ПО успело добавить файл на шарду, вообще это до 2 минут, но решили перестраховаться) использование файла на всех шардах. После завершения проверки дата использования обнуляется, если файл не найден, в противном случае файл удаляется из очереди. Если дата использования изменилась в процессе проверки, данные не изменяются так как предполагается, что пока шла проверка файл мог быть загружен на шард, на которой уже отработала проверка и требуется новый цикл проверки для файла.
На шардах:
В процедуру, которая удаляет файлы из таблицы с удаленными файлами нужно было добавить проверку на то, что файл не использовался. Процедура потеряла свою простоту и прекрасность не сильно — в DELETE с output просто добавили NOT EXISTS.
Добавили JOB, который в фоне грохал из таблицы используемые на сервере файлы.
В интеграционные тесты добавили сценарии на использования всех вариантов хранилища.
Также написали новые кейсы, чтобы протестировать новую функциональность по удалению файлов.
На Perf Lab добавили нагрузку на глобальный сервер. Кроме того добавили нагрузку соответствующую удалению файлов с хранилища.
Были подготовлены скрипты на применение и откат изменений для базы. DBA накатили скрипты и выяснилось, что при нагрузочном тестировании не обратили внимание на блокировки на таблицы-очереди на удаление файлов. В результате не исправили индекс, который был не самый оптимальный.
Из-за этого понадобилось отключить JOB проверки по диапазонам и проанализировать и добавить идентификаторы удаленных файлов вручную, по файлам, которые были удалены в системе до деплоя нового кода.
В итоге в результате деплоя новые удаленные файлы удаляются с хранилища в течение суток.
Файлы, удаленные до запуска новой системы, были сформированы на бэкапе и добавлены в очередь на прод.
В результате лишние данные на S3 в размере 2 петабайт были удалены. Тоже самое произошло с файлами на выделенных серверах клиентов, и теперь у них место, занимаемое на сервере совпадает с местом отображаемом в их клиентах.
Кривой индекс на таблице-очереди пока так и живет на проде, задача по изменению индекса в бэклоге, но немного отодвинута из-за более приоритетных задач.
Зачем вам это читать и зачем я все это написала? Хочется рассказать о граблях, которые заботливо лежат внутри системы и бьют так, что звездочки сыпятся из глаз.
Хочу сказать большое спасибо Hanna_Hlushakova за совместную работу, доведение проекта до конца и помощь в подготовки статьи. В основном вы встретите описания проблемы и алгоритма ее решения, который мы использовали, никаких примеров кода, структур данных и других нужных вещей тут нет. Я не знаю поможет ли вам мой опыт избежать граблей у себя, но надеюсь что-то полезное вы извлечете. Возможно, данная статья будет абсолютно безвозвратной потерей драгоценного времени.
О проекте
Проект входит в лидеры по квадрату Gartner, имеет клиентов-компании с численностью сотрудников более 300 тыс. человек в США и Европе, и несколько миллиардов файлов на обслуживании.
В проекте используются следующие технологии: Microsoft, серверы C# .net, БД MS SQL, 14 активных серверов + 14 в режиме зеркалирования данных.
Объем баз данных составляет до 4 Тб, постоянная нагрузка в бизнес часы — порядка 400 тыс. запросов в минуту.
В базе данных много бизнес логики:
450 таблиц
1000 хранимых процедур
80 000 строк SQL кода
Документацию традиционно либо не успели написать, либо она не актуальна.
О задаче
Задача — переделать удаление файлов с хранилища, которые уже были удалены клиентами, и закончился период хранения удаленных файлов, на случай если их захотят восстановить. В текущей версии, по подсчетам самой компании, на серверах хранились файлы, которые были удалены 1 год назад, хотя по условиям бизнеса они должны были храниться только 1 месяц. Так как часть файлов хранится на S3, компания платила за лишние данные, а клиенты, которые использовали хранилище On-Premises недоумевали почему файлы занимают больше места, чем должны.
Базы данных шардированные по компании клиента.
Как работало удаление ранее?
На глобальном сервере с информацией о всех файлах в системе формировались диапазоны по 15 тыс идентификаторов файлов.
Затем по расписанию запускался опрос серверов по диапазону идентификаторов файлов.
На каждый шард передавались границы диапазона.
Шард в ответ присылал найденные файлы из диапазона.
Основной сервер добавлял отсутствующие файлы в таблицу-очередь на удаление в своей БД.
Затем из таблицы-очереди сервис физического удаления файлов с хранилища получал пачку идентификаторов на удалением, после чего посылал подтверждение, что собирается удалить файлы и запускалась проверка по всем шардам — не используются ли там эти файлы.
При увеличении количества файлов такой подход стал работать очень медленно, так как файлов стало несколько миллиардов, и количество диапазонов возросло в разы. Удаленных файлов по прежнему оставалось менее 5% по сравнению с общим количеством, соответственно очень неэффективно перебирать миллиарды файлов, чтобы найти несколько миллионов удаленных из них.
Для примера, обычно после удаления файла пользователем, он должен хранится 1 месяц, на тот случай, если его нужно будет восстановить. После этого периода, файл должен быть удален программой с хранилища. При текущем количестве файлов, количестве диапазонов и скорости обхода диапазонов, серверу, чтобы полностью обойти все диапазоны, потребовался бы 1 год.
Понятно, что место не освобождалось, и это вызывало недовольство пользователей, так как на их серверах хранилось в разы больше файлов, чем должно было быть по отчетности. За дополнительно место на S3 платила сама компания, предоставляющая сервис, что являлось для нее прямым убытком.
Только на S3 к моменту начала работ хранилось 2 Петабайта удаленных файлов, и это только на облаке. Кроме того были клиенты, у которых файлы хранились на своих выделенных серверах, у которых была такая же проблема: место на сервере занимали файлы, удаленные пользователями, но не удаленные с сервера.
Что решили сделать?
Решили отслеживать события удаления:
- клиент удалил файл, и затем истек срок его хранения.
- пользователь удалил файл сразу без возможности восстановления.
При удалении файла с шардированной базы решили использовать оптимистичный подход и убрать одну из проверок на использование. Мы знали, что 99% файлов используются только в рамках одной шарды. Решили сразу добавлять файл в очередь на удаление, и не делать проверку по остальным шардам на использование этого файла, так как проверка будет сделана еще раз при подтверждении сервисом удаления с хранилища.
Кроме того оставили текущий JOB, который проверял удаленные файлы по диапазонам, чтобы добавлять файлы, которые были удалены до релиза новой версии.
Все, что было удалено на шарде, собирается в таблицу и затем передается на один сервер, с информацией о всех файлах.
На этом сервере отправляется в таблицу-очередь на удаление.
В таблице на удаление перед удалением проверяется, что файл не используется на всех шардах. Эта часть проверки была тут еще до изменения кода, и ее решили не трогать.
Что надо было изменить в коде?
На каждой из шардов добавили таблицу, в которую нужно записывать идентификатор удаленного файла.
Нашли все процедуры удаления файлов из базы, их оказалось всего 2. После удаления файла пользователем, файл еще некоторое время лежит в базе.
В процедуры удаления файла из базы добавили запись в эту локальную таблицу с удаленными файлами.
На глобальном сервере с файлами сделали JOB, который выкачивает список файлов с шардированных баз. Просто вызов процедуры с шардированной базы, она внутри делает DELETE и в OUTPUT выводит список файлов. В MS SQL Server pull — вытягивание с удаленного сервера делается существенно быстрее, чем вставка на удаленный сервер. Все это делается блоками.
Затем эти файлы добавляются в таблицу-очередь на удаление на глобальном сервере.
В таблице-очереди добавили поле с идентификатором шарда, чтобы знать, откуда пришло событие на удаление.
Как это все тестировали?
Есть 3 среды:
Dev — среда разработки. Код берется из develop ветки гита. Есть возможность задеплоить разную версию кода на IIS и сделать несколько версий orchestration. Подключится к dev среде из клиента внутри vpn. До недавнего времени неудобство было только с базами, так как все изменения базы могут сломать работу других частей системы. Потом базы сделали локальные. На dev сервера с базами данных можно выливать уже работающий код, чтобы не рушить всем работу. На dev среде 3 шарда, вместо 12, которые есть на проде, но этого обычно хватает для тестирования взаимодействия.
Staging — среда одинаковая с продом по версии кода (почти одинаковая, так как редко, но бывают изменения прямо на проде администраторами). Копия кода из ветки master. В БД иногда вылавливали некоторые различия с кодом на проде, но в целом они идентичны. На Staging также 3 шарда как и на деве. На staging также нет нагрузки как и на devе. Здесь можно запустить интеграционные тесты уже вчистую, так как код совпадает с продом. Все тесты должны пройти, это обязательное условие перед выходом на деплой.
Perf lab, где делаются тесты под нагрузкой. Нагрузка создается с помощью jmeter, в 10 раз меньше, чем на проде, и есть только один шард, что иногда создает неудобства. Берутся данные с прода, затем анонимизируются и используется на perf lab. Все сервера той же конфигурации, что и на проде.
Нагрузка в 10 раз меньшая, потому что предполагается, что это примерная нагрузка, которая приходит на проде на 1 шард. Минус в том, что глобальная база при этом сильно недогружена, в отличие от прода. И, если в основном изменения касаются глобальной базы данных с файлами, то на результаты теста можно полагаться только примерно — на проде это может работать не так. Хотя perf lab не идеально совпадает по нагрузке с продом, наличие возможности протестировать под нагрузкой, уже помогает выловить много ошибок до деплоя на прод.
Также есть backup сервер, где можно посмотреть данные с прода, чтобы отловить некоторые кейсы. Вообще компания работает под лицензией, которая запрещает разработчикам давать доступ к прод данным, а команде администрирования и поддержки (Operations) доступ к разработке, поэтому нужно просить помочь администраторов БД. Данные с прода очень облегчают тестирование, потому что некоторые кейсы возникают только на прод данных и очень полезно изучать данные в реальной системе, чтобы понять, как работает система у пользователя.
При тестах на perf lab выяснилось, что нагрузка по удалению файлов с хранилища не реализована от слова совсем. При реализации нагрузочного тестирования выбрали более популярные запросы от клиентского ПО, часть на очистку хранилища не вошла. Так как это база, то получилось провести упрощенное тестирование на все измененные объекты с вызовом измененных процедур на разных данных вручную. (на тех вариантах, о которых я знала).
Кроме того, и в интеграционных и в перф тестах основной упор делался на самый популярный вид хранения файла.
Дополнительная особенность перф лабы, которая выяснилась не сразу, — это несоответствие количества данных в некоторых таблицах на проде и перфе. В том смысле, что на перфе работают все JOBы с прода, которые формируют данные, но не всегда есть то, что обрабатывает сформированные в таблицу данные. И, например, упомянутая выше таблица-очередь на удаление на перфе сильно больше, чем на проде — 20 млн записей на перфе и 200 тыс на проде.
Процесс деплоя
Процесс деплоя довольно стандартный. Изменений в коде приложения для этой задачи не было, все изменения только в базе данных. На базу изменения всегда накатывают DBA, этот процесс не автоматизирован. Подготавливаются 2 версии скриптов — для применения изменений и для отката изменений, и пишется инструкция для DBA. 2 версии скриптов делаются всегда, и они обязательно тестируются на накат и откат изменений. И эти же скрипты используются для применения изменений на staging и perf lab перед запуском интеграционного и нагрузочного тестирования.
Что произошло после деплоя?
За первые 5 часов после деплоя пришел 1 млн событий, о том, что клиентское ПО получило ошибку, при попытке загрузить файл. Событие “file corrupted”. Оно означает, что файл пытается скачать клиент, но файл не найден на хранилище. Обычно этих событий либо нет совсем, либо они измеряются 1 — 2 тысячами в день.
Сразу скажу, что поиск причины фейла у команды из 3х и иногда 5 человек (включая меня) занял не менее 1 недели.
Собрали весь список файлов, по которым пришло событие “File Corrupted”.
Несмотря на то, что событий было более 1 миллиона и они все были от разных пользователей, разных компаний, уникальных файлов в этом списке оказалось только 250.
DBA на backup сервере подняли для расследования бэкапы баз на момент, когда пришли события. В базах проекта есть довольно много таблиц со всякого рода логами, которые помогли в анализе. Даже при удалении информации из БД обязательно добавляется лог, что было удалено и каким событием. На проде такие записи хранятся 1 неделю, затем сливаются на архивный сервер.
И так таблицы с логами, которые очень помогли в анализе того, что произошло:
Полный лог с событиями у клиента, ведется на каждой шарде
На глобальном сервере:
- Лог запросов на скачивания всех файлов пользователями
- Лог загрузки в систему файлов от пользователей
- Лог файлов с событием FileCorrupt
- Лог файлов для отмены удаления с хранилища
- Лог удаленных файлов из базы
Кроме того в распоряжении был ELK с логами приложения.
Ошибку удалось повторить на dev среде, что подтвердило правильность предположения. Сначала эту гипотезу никто не воспринимал всерьез, так как было очень сложно поверить, что столько факторов совпало одновременно и столько пользователей пришло именно в этот момент времени.
Что же пошло не так?
Оказалось, в системе было порядка 250 (для сравнения в системе миллиарды файлов) супер пупер мега популярных файлов. 250, да!
Эти файлы еще были очень старыми. В то время, когда эти файлы загружались в систему, использовалась другая система генерации ключа файла на хранилище.
Оказалось, что для такого типа ключа, метод физического удаления с физического хранилища ведет себя не так как с другими файлами.
В классе с удалением есть блок кода с условием специально для файлов со старым ключом. Система, на время удаления, до того как проверяется, что файл отсутствует на шардах, перемещает данный старый файл в другое место. Ну чтобы чего не вышло.
И, оказалось, что в момент, когда файл перемещен (а он напомню очень популярный), если кто-то из пользователей пытается дать на него права новому пользователю, клиентское ПО идет на хранилище за этим файлом, а файла в нужном месте нет. Так как он перемещен, чтобы чего не вышло. И клиентское ПО посылает сообщение, что файл битый. В БД он отмечается как битый. И вся информация удаляется из базы (ну почти вся).
А тем временем наша процедура проверки по шардам выясняет, что файл используется. И отправляет ответ, что нужно его вернуть. Но вся инфа уже удалилась из базы, и вернуть его не получается.
Забавно, да?
То есть при удалении файла пользователь попал именно в тот промежуток времени, когда файл был перемещен, шла проверка по шардам, и именно в этот момент времени пользователь послал запрос на загрузку.
Вот он — highload в действии, когда самые невероятные совпадения у вас совпадают.
Оправившись от удивления и откатив все назад, мы убедились, что файлы у пользователей живы, так как были восстановлены с дисков других клиентов.
Естественно, на тестах все было хорошо, потому что при тесте удалялись более новые файлы с новым типом ключа, который использовался последние лет 5. Такие файлы не переносятся в другое место хранения на время удаления.
У нас оптимизма поубавилось, и мы решили не идти самым оптимистичным путем.
Ретроспектива
Решили, что нужно добавить тесты на разные виды хранилищ
Добавить нагрузку на perf lab, которая использует вызовы при удалении с хранилища
Закрыть известные race conditions
Добавить мониторинг (хотя он и бы в планах, но не влез в изначальный scope)
Про мониторинг
Мониторинг сразу решили делать, но потом что-то он отошел на второй план, так как надо было быстрее деплоить.
Для мониторинга в проекте использовался Zabbix, ELK, Grafana, NewRelic, SQL Sentry и тестовая версия AppDynamics.
Из этого на pef lab был NewRelic и SQL Sentry.
Все системные метрики мы уже мерили и так, хотелось мерить бизнес метрики. У меня был опыт организации такого мониторинга через Zabbix — решили делать так же.
Схема очень простая в БД сделать таблицу, в которую по JOBу собирать нужные метрики и процедуру, которая будет выгружать собранные метрики в Zabbix.
Метрики:
- Количество файлов в очереди на удаление на глобальной базе
- Количество файлов в очереди по серверу
- Количество файлов отправленных в программу удаления с хранилища
- Количество удаленных файлов
- Количество событий FileCorrupt
- Количество файлов на удаление на каждой шарде
Мониторинг реализовали и задеплоили на прод отдельно, до того как стали деплоить новую реализацию удаления.
Новое решение
В общем, мы решили, что лучше переесть, чем недоспать, и сделали новый план.
- проверять на той же шарде, что файл точно больше никто не использует, и передавать на сервер только не используемые файлы;
- при переносе на сервер собирать все файлы в таблицу и проверять, что файлы не используются на шардах до помещения в таблицу-очередь на удаление;
- при использовании файла и поиска его в системе, отмечать в таблице очереди на удаление как файл, требующий проверки;
- выдавать на удаление только файлы, по которым не было поисков;
- файлы, по которым были поиски, повторно проверять на наличие на шардах;
- вообще убрать проверку в процедуре, которая удаляет файл, так как она должна отрабатывать быстро — и используемый файл до нее в принципе не должен дойти;
- учитывать в процедуре, которая все удаляет по битому файлу, что он находится в процессе удаления, и не удалять информацию по нему.
Пункт 6 при деплое включал в себя удаление проверки в несколько этапов. Сначала проверку оставили, затем через неделю отключили проверку по файлам сотрудников компании, через 2 недели — отключили проверку совсем.
Что нужно было поменять в коде?
Опять же все изменения касаются только базы данных.
Масштаб изменений был самым большим на глобальном сервере:
Добавить промежуточную таблицу, в которую складывать все файлы скачанные с шардов.
Сделать JOB, который бы по промежуточной таблице проверял по файлам, что они не используются на шардах.
В таблицу очередь удаленных файлов добавить поле с датой последнего обращения к файлу и добавить индекс.
Найти все процедуры с доступом к файлу — оказалось 5 процедур. Добавить в них блок изменение даты последнего использования в таблице очереди. Дата менялась каждый раз, в независимости от того была она заполнена или нет.
В процедуры выдачи файлов программе удаления добавить, чтобы она выдавала только файлы с пустой датой использования.
Добавить JOB, который собирает все файлы с датой использования и проверяет (с задержкой 10 минут, которая нужна, чтобы клиентское ПО успело добавить файл на шарду, вообще это до 2 минут, но решили перестраховаться) использование файла на всех шардах. После завершения проверки дата использования обнуляется, если файл не найден, в противном случае файл удаляется из очереди. Если дата использования изменилась в процессе проверки, данные не изменяются так как предполагается, что пока шла проверка файл мог быть загружен на шард, на которой уже отработала проверка и требуется новый цикл проверки для файла.
На шардах:
В процедуру, которая удаляет файлы из таблицы с удаленными файлами нужно было добавить проверку на то, что файл не использовался. Процедура потеряла свою простоту и прекрасность не сильно — в DELETE с output просто добавили NOT EXISTS.
Добавили JOB, который в фоне грохал из таблицы используемые на сервере файлы.
Тесты
В интеграционные тесты добавили сценарии на использования всех вариантов хранилища.
Также написали новые кейсы, чтобы протестировать новую функциональность по удалению файлов.
На Perf Lab добавили нагрузку на глобальный сервер. Кроме того добавили нагрузку соответствующую удалению файлов с хранилища.
Деплой
Были подготовлены скрипты на применение и откат изменений для базы. DBA накатили скрипты и выяснилось, что при нагрузочном тестировании не обратили внимание на блокировки на таблицы-очереди на удаление файлов. В результате не исправили индекс, который был не самый оптимальный.
Из-за этого понадобилось отключить JOB проверки по диапазонам и проанализировать и добавить идентификаторы удаленных файлов вручную, по файлам, которые были удалены в системе до деплоя нового кода.
Результаты
В итоге в результате деплоя новые удаленные файлы удаляются с хранилища в течение суток.
Файлы, удаленные до запуска новой системы, были сформированы на бэкапе и добавлены в очередь на прод.
В результате лишние данные на S3 в размере 2 петабайт были удалены. Тоже самое произошло с файлами на выделенных серверах клиентов, и теперь у них место, занимаемое на сервере совпадает с местом отображаемом в их клиентах.
Кривой индекс на таблице-очереди пока так и живет на проде, задача по изменению индекса в бэклоге, но немного отодвинута из-за более приоритетных задач.

