GitHub использует MySQL в качестве основного хранилища данных для всего, что не связано с git, поэтому доступность MySQL имеет ключевое значение для нормальной работы GitHub. Сам сайт, интерфейс API на GitHub, система аутентификации и многие другие функции требуют доступа к базам данных. Мы используем несколько кластеров MySQL для обработки различных служб и задач. Они настроены по классической схеме с одним главным узлом, доступным для записи, и его репликами. Реплики (остальные узлы кластера) асинхронно воспроизводят изменения главного узла и обеспечивают доступ для чтения.
Доступность главных узлов критически важна. Без главного узла кластер не поддерживает запись, а это значит, что нельзя сохранить необходимые изменения. Фиксация транзакций, регистрация проблем, создание новых пользователей, репозиториев, обзоров и многое другое будет просто невозможно.
Для поддержки записи необходим соответствующий доступный узел – главный узел в кластере. Впрочем, не менее важна возможность определить или обнаружить такой узел.
В случае отказа текущего главного узла важно обеспечить оперативное появление нового сервера ему на замену, а также иметь возможность быстро оповестить об этом изменении все службы. Общее время простоя складывается из времени, уходящего на обнаружение сбоя, отработку отказа и оповещение о новом главном узле.

В этой публикации описано решение для обеспечения высокой доступности MySQL в GitHub и обнаружения главной службы, которое позволяет нам надежно выполнять операции с охватом нескольких центров обработки данных, поддерживать работоспособность при недоступности отдельных таких центров и гарантировать минимальное время простоя при сбое.
Цели обеспечения высокой доступности
Решение, описанное в статье, – это новая, улучшенная версия предыдущих решений для обеспечения высокой доступности (HA), реализованных в GitHub. По мере нашего роста нам необходимо адаптировать HA-стратегию MySQL к изменениям. Мы стремимся придерживаться аналогичных подходов для MySQL и других служб в GitHub.
Чтобы найти подходящее решение для обеспечения высокой доступности и обнаружения служб следует сначала ответить на несколько конкретных вопросов. Вот их примерный список:
- Какое максимальное время простоя для вас некритично?
- Насколько надежны средства обнаружения сбоев? Критичны ли для вас ложноположительные срабатывания (преждевременная отработка отказа)?
- Насколько надежна система отработки отказа? Где может возникнуть сбой?
- Насколько эффективно решение работает в условиях нескольких центров обработки данных? Насколько эффективно решение работает в сетях с низкой и высокой задержкой?
- Продолжит ли решение работать в случае полного отказа центра обработки данных (ЦОД) или в условиях сетевой изоляции?
- Какой механизм (при его наличии) предотвращает или смягчает последствия возникновения в кластере двух главных серверов, которые независимо друг от друга осуществляют запись?
- Критична ли для вас потеря данных? Если да, то в какой мере?
В целях демонстрации давайте сначала рассмотрим предыдущий вариант решения и обсудим, почему мы решили от него отказаться.
Отказ от использования VIP и DNS для обнаружения
В рамках предыдущего решения мы использовали:
- orchestrator для обнаружения и отработки отказа;
- VIP и DNS для обнаружения главного узла.
В том случае клиенты обнаруживали узел записи по его имени, например, mysql-writer-1.github.net. По имени определялся виртуальный IP-адрес (VIP) главного узла.
Таким образом, в обычной ситуации клиентам достаточно было просто разрешить имя и подключиться по полученному IP-адресу, где их уже ожидал главный узел.
Рассмотрим следующую топологию репликации, охватывающую три различных центра обработки данных:
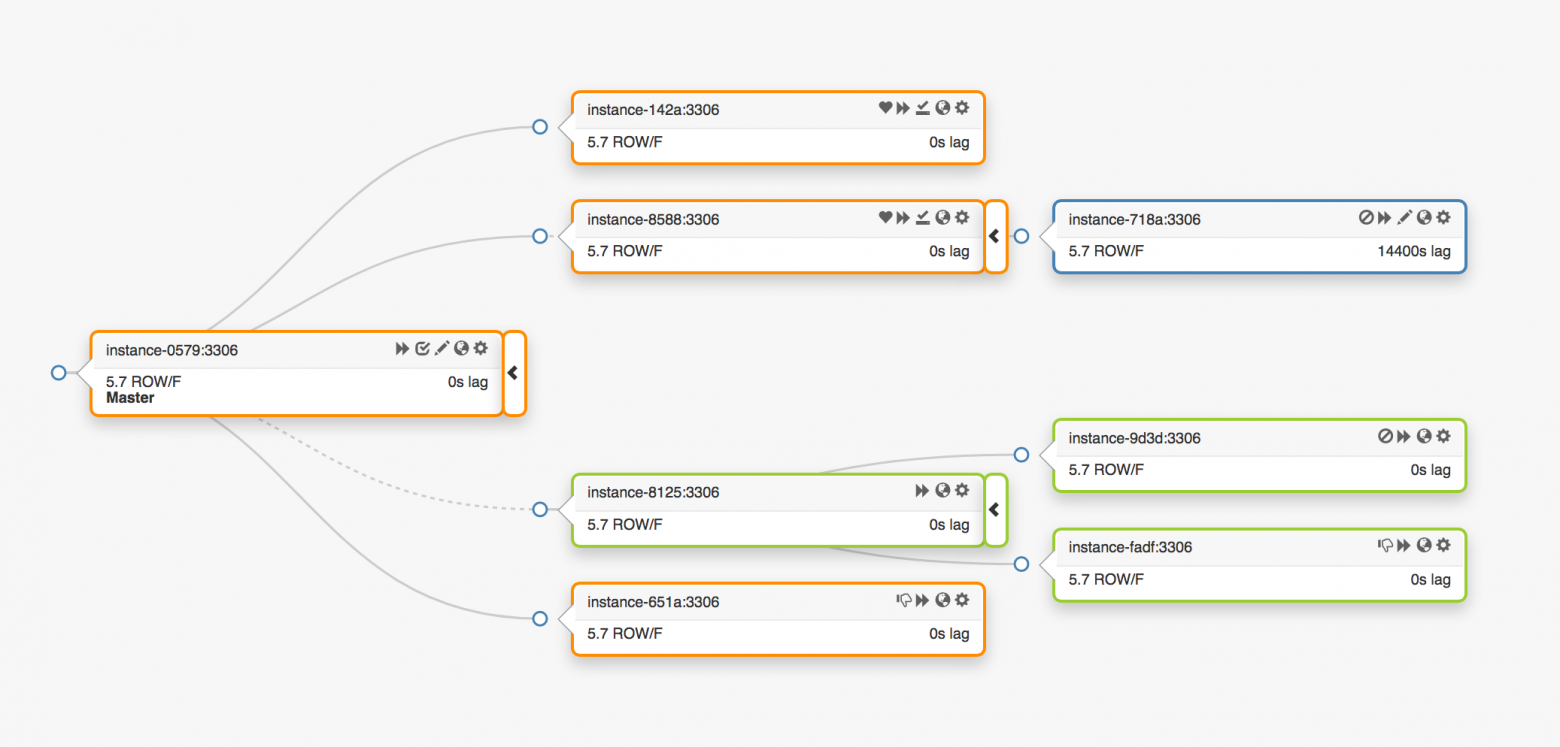
В случае сбоя главного узла на его место должен быть назначен новый сервер (одна из реплик).
orchestrator обнаруживает сбой, выбирает новый главный узел, а затем назначает имя/VIP. Клиентам на самом деле неизвестны идентификационные данные главного узла, они знают только имя, которое теперь должно указывать на новый узел. Однако обратите внимание вот на что.
VIP-адреса используются совместно, серверы баз данных сами запрашивают их и владеют ими. Чтобы получить или освободить VIP, сервер должен отправить ARP-запрос. Сервер, владеющий VIP, должен сначала освободить его, прежде чем новый главный узел получит доступ к этому адресу. Такой подход приводит к некоторым нежелательным последствиям:
- В штатном режиме система отработки отказа сначала свяжется с вышедшим из строя главным узлом и запросит его освободить VIP, а затем обратится к новому главному серверу с запросом на присвоение VIP. Но что делать, если первый главный узел недоступен или выдает отказ на запрос освободить VIP-адрес? Учитывая, что в данный момент сервер находится в состоянии отказа, маловероятно, что он сможет своевременно ответить на запрос или ответить на него вообще.
- В результате может возникнуть ситуация, когда два хоста заявляют свои права на один и тот же VIP. Разные клиенты могут подключаться к любому из этих серверов в зависимости от кратчайшего сетевого пути.
- Правильность работы в такой ситуации зависит от взаимодействия двух независимых серверов, а такая конфигурация ненадежна.
- Даже если первый главный узел отвечает на запросы, мы впустую тратим драгоценное время: переключение на новый главный сервер не происходит, пока мы связываемся со старым.
- При этом даже в случае переназначения VIP нет гарантии, что существующие клиентские соединения на старом сервере будут разорваны. Мы опять рискуем оказаться в ситуации с двумя независимыми главными узлами.
Кое-где в рамках нашей среды VIP-адреса связаны с физическим местоположением. Они назначены коммутатору или маршрутизатору. Поэтому мы можем переназначить VIP-адрес только серверу, расположенному в том же окружении, что и первоначальный главный узел. В частности, в некоторых случаях мы не сможем назначить VIP серверу в другом центре обработки данных и должны будем внести изменения в DNS.
- Для распространения изменений в DNS требуется больше времени. Клиенты хранят DNS-имена в течение заранее настроенного периода времени. Отработка отказа с участием нескольких ЦОД влечет за собой более длительные простои, поскольку уходит больше времени на предоставление всем клиентам сведений о новом главном узле.
Этих ограничений было достаточно, чтобы вынудить нас начать поиск нового решения, но учесть нужно было и следующее:
- Главные узлы самостоятельно передавали пакеты пульса через службу
pt-heartbeatдля измерения величины запаздывания и регулировки нагрузки. Службу необходимо было переносить на вновь назначенный главный узел. При возможности, на старом сервере ее нужно было отключить. - Аналогичным образом, главные узлы самостоятельно управляли работой с Pseudo-GTID. Нужно было запустить этот процесс на новом главном узле и желательно остановить на старом.
- Новый главный узел становился доступным для записи. Старый узел (если возможно) должен был получить метку
read_only(только для чтения).
Эти дополнительные шаги приводили к увеличению общего времени простоя и добавляли собственные точки отказа и возникновения проблем.
Решение работало, и GitHub успешно отрабатывал отказы MySQL в фоновом режиме, но мы хотели улучшить свой подход к HA следующим образом:
- обеспечить независимость от конкретных ЦОД;
- гарантировать работоспособность в случае сбоев ЦОД;
- отказаться от ненадежных совместных рабочих процессов;
- сократить общее время простоя;
- выполнять, насколько это возможно, отработку отказов без потерь.
HA-решение GitHub: orchestrator, Consul, GLB
Наша новая стратегия, наряду с сопутствующими улучшениями, устраняет большую часть проблем, упомянутых выше, или смягчает их последствия. Наша текущая HA-система состоит из следующих элементов:
- orchestrator для обнаружения и отработки отказов. Мы используем схему orchestrator/raft с несколькими ЦОД, как изображено на рисунке ниже;
- Consul от Hashicorp для обнаружения служб;
- GLB/HAProxy как прокси-слой между клиентами и узлами записи. Исходный код инструмента GLB Director открыт;
- технология
anycastдля сетевой маршрутизации.
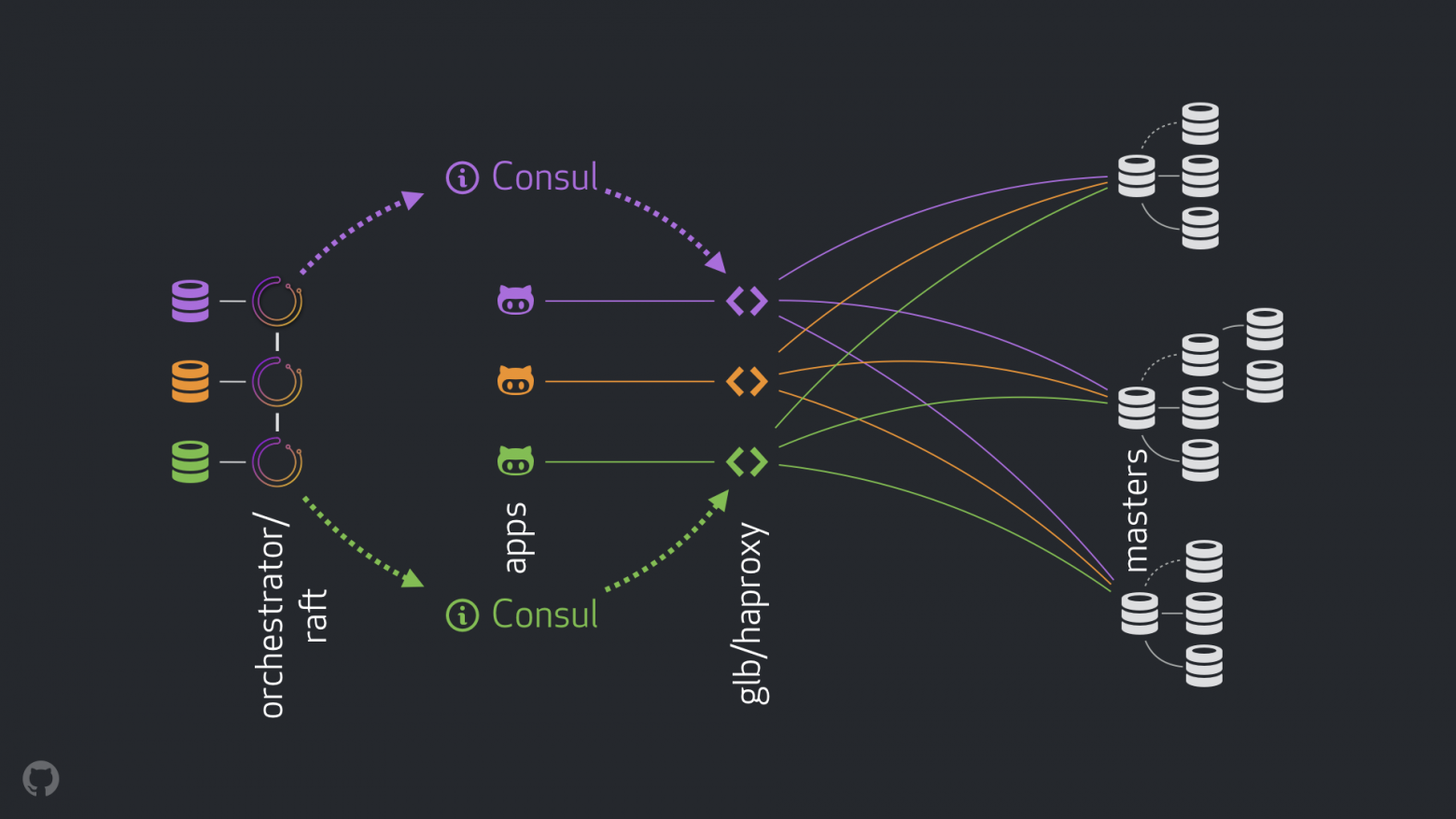
Новая схема позволила полностью отказаться от внесения изменений в VIP и DNS. Теперь при вводе новых компонентов мы можем отделить их и упростить задачу. Кроме того, мы получили возможность использовать надежные и стабильные решения. Подробный разбор нового решения приведен далее.
Нормальный поток
В обычной ситуации приложения подключаются к узлам записи через GLB/HAProxy.
Приложения не получают идентификационной информации главного сервера. Как и раньше, они используют только имя. Например, главным узлом для cluster1 будет mysql-writer-1.github.net. Однако в нашей текущей конфигурации это имя разрешается в IP-адрес anycast.
Благодаря технологии anycast имя разрешается в один тот же IP-адрес в любом месте, но трафик направляется по-разному, учитывая местоположение клиента. В частности, в каждом из наших ЦОД развернуто несколько экземпляров GLB, нашего высокодоступного балансировщика нагрузки. Трафик на mysql-writer-1.github.net всегда направляется к кластеру GLB локального ЦОД. За счет этого все клиенты обслуживаются локальными прокси.
Мы запускаем GLB поверх HAProxy. Наш сервер HAProxy предоставляет пулы записи: по одному на каждый кластер MySQL. При этом у каждого пула лишь один сервер (главный узел кластера). Все экземпляры GLB/HAProxy во всех ЦОД имеют одинаковые пулы, и все они указывают на одни и те же серверы в этих пулах. Таким образом, если приложение хочет записать данные в базу на mysql-writer-1.github.net, то не имеет значения, к какому серверу GLB оно подключается. В любом случае будет выполнено перенаправление на фактический главный узел кластера cluster1.
Для приложений обнаружение заканчивается на GLB, а необходимость в повторном обнаружении отсутствует. Именно GLB перенаправляет трафик в нужное место.
Откуда в GLB поступает информация о том, какие серверы включать в список? Как мы вносим изменения в GLB?
Обнаружение через Consul
Служба Consul широко известна как решение для обнаружения служб, кроме того, она также берет на себя функции DNS. Впрочем, в нашем случае мы используем ее как высокодоступное хранилище значений ключей (KV).
В хранилище KV в Consul мы записываем идентификационные данные главных узлов кластера. Для каждого кластера существует набор записей KV, указывающих на данные соответствующего главного узла: его fqdn, порт, адреса ipv4 и ipv6.
Каждый узел GLB/HAProxy запускает consul-template, службу, которая отслеживает изменения в данных Consul (в нашем случае это изменения в данных главных узлов). Служба consul-template создает файл конфигурации и может перезагрузить HAProxy при изменении настроек.
Благодаря этому информация об изменении идентификационных данных главного узла в Consul доступна каждому экземпляру GLB/HAProxy. На основе этой информации выполняется настройка экземпляров, новые главные узлы указываются в качестве единственной сущности в пуле серверов кластера. После этого экземпляры перезагружаются, чтобы изменения вступили в силу.
Мы развернули экземпляры Consul в каждом ЦОД, и каждый экземпляр обеспечивает высокую доступность. Тем не менее, эти экземпляры независимы друг от друга. Они не выполняют репликацию и не обмениваются какими-либо данными.
Откуда Consul получает информацию об изменениях и как она распространяется между ЦОД?
orchestrator/raft
Мы используем схему orchestrator/raft: узлы orchestrator взаимодействуют друг с другом посредством консенсуса raft. В каждом ЦОД у нас один или два узла orchestrator.
orchestrator отвечает за обнаружение сбоев, отработку отказов MySQL и передачу измененных данных о главном узле в Consul. Отработка отказа управляется одним ведущим узлом orchestrator/raft, но изменения, новости о том, что в кластере теперь новый главный узел, распространяются на все узлы orchestrator с помощью механизма raft.
Когда узлы orchestrator получают новости об изменении данных главного узла, каждый из них связывается со своим локальным экземпляром Consul и инициирует запись KV. ЦОД с несколькими экземплярами orchestrator получат несколько (идентичных) записей в Consul.
Обобщенное представление всего потока
При сбое главного узла:
- узлы
orchestratorобнаруживают сбои; - ведущий узел
orchestrator/raftинициирует восстановление. Назначается новый главный узел; - схема
orchestrator/raftпередает данные об изменении главного узла всем узлам кластераraft; - каждый экземпляр
orchestrator/raftполучает уведомление об изменении узла и записывает в локальное хранилище KV в Consul идентификационные данные нового главного узла; - на каждом экземпляре GLB/HAProxy запущена служба
consul-template, которая отслеживает изменения в хранилище KV в Consul, перенастраивает и перезагружает HAProxy; - клиентский трафик перенаправляется к новому главному узлу.
Для каждого компонента обязанности четко распределены, и вся структура диверсифицирована и упрощена. orchestrator не взаимодействует с балансировщиками нагрузки. Службе Consul не требуются данные о происхождении информации. Прокси-серверы работают только с Consul. Клиенты работают только с прокси-серверами.
Более того:
- нет необходимости вносить изменения в DNS и распространять информацию о них;
- TTL не используется;
- поток не ждет ответов от главного узла в состоянии ошибки. В целом он игнорируется.
Дополнительная информация
Для стабилизации потока мы также применяем следующие методы:
- Для параметра HAProxy
hard-stop-afterнастроено очень малое значение. Когда HAProxy перезагружается с новым сервером в пуле записи, сервер автоматически завершает все существующие подключения к старому главному узлу.
- Настройка параметра
hard-stop-afterпозволяет не ждать каких-либо действий от клиентов, кроме того, минимизируются негативные последствия возможного возникновения в кластере двух главных узлов. Важно понимать, что здесь нет никакой магии, и в любом случае проходит некоторое время, прежде чем старые связи будут разорваны. Но есть момент времени, после которого мы можем перестать ждать неприятных сюрпризов.
- Настройка параметра
- Мы не требуем постоянной доступности службы Consul. Фактически нам нужно, чтобы она была доступна только при отработке отказа. Если служба Consul не отвечает, то GLB продолжает работать с последними известными значениями и не принимает радикальных мер.
- GLB настроен для проверки идентификационных данных недавно назначенного главного узла. Как и в случае с нашими контекстно-зависимыми пулами MySQL, выполняется проверка, чтобы подтвердить, что сервер действительно доступен для записи. Если мы случайно удалим идентификационные данные главного узла в Consul, то никаких проблем не возникнет, пустая запись будет проигнорирована. Если мы по ошибке запишем в Consul имя другого сервера (не главного), то и в этом случае ничего страшного: GLB не будет обновлять его и продолжит работать с последним допустимым состоянием.
В следующих разделах мы рассматриваем проблемы и разбираем цели обеспечения высокой доступности.
Обнаружение сбоев с помощью orchestrator/raft
orchestrator использует комплексный подход к обнаружению сбоев, что обеспечивает высокую надежность инструмента. Мы не сталкиваемся с ложноположительными результатами, преждевременная отработка отказов не выполняется, а значит, исключаются необязательные простои.
Схема orchestrator/raft также справляется с ситуациями полной сетевой изоляции ЦОД («ограждение» ЦОД). Сетевая изоляция ЦОД может вызвать путаницу: серверы внутри ЦОД могут взаимодействовать друг с другом. Как понять, кто на самом деле изолирован – серверы внутри данного ЦОД или все остальные ЦОД?
В схеме orchestrator/raft ведущий узел raft выполняет отработку отказов. Ведущим становится узел, который получает поддержку большинства в группе (кворум). Мы развернули узел orchestrator таким образом, что ни один отдельный ЦОД не может обеспечить большинство, в то время как его обеспечивают любые n-1 ЦОД.
В случае полной сетевой изоляции ЦОД узлы orchestrator в этом центре отключаются от аналогичных узлов в других ЦОД. В результате узлы orchestrator в изолированном ЦОД не могут стать ведущими в кластере raft. Если такой узел был ведущим, то он теряет этот статус. Новым ведущим будет назначен один из узлов других ЦОД. Этот ведущий будет иметь поддержку всех других ЦОД, способных взаимодействовать между собой.
Таким образом, ведущий узел orchestrator всегда будет находиться за пределами изолированного от сети центра обработки данных. Если в изолированном ЦОД находился главный узел, orchestrator инициирует отработку отказа, чтобы заменить его сервером одного из доступных ЦОД. Мы смягчаем последствия изоляции ЦОД, делегируя принятие решений кворуму доступных ЦОД.
Ускоренное оповещение
Общее время простоя может быть дополнительно сокращено, если ускорить оповещение о смене главного узла. Как этого достичь?
Когда orchestrator начинает отработку отказа, он рассматривает группу серверов, один из которых можно назначить главным. Учитывая правила репликации, рекомендации и ограничения, он способен принять обоснованное решение о наилучшем варианте действий.
По следующим признакам он также может понять, что доступный сервер является идеальным кандидатом для назначения главным:
- ничто не препятствует повышению статуса сервера (и, возможно, пользователь рекомендует этот сервер);
- ожидается, что сервер сможет использовать все другие серверы в качестве реплик.
В этом случае orchestrator сначала настраивает сервер как доступный для записи и немедленно объявляет о повышении его статуса (в нашем случае вносит запись в хранилище KV в Consul). При этом orchestrator асинхронно начинает исправлять дерево репликации, что обычно занимает несколько секунд.
Вполне вероятно, что к тому времени, когда наши серверы GLB будут полностью перезагружены, дерево репликации также будет готово, хотя это и не обязательно. Вот и все: сервер готов к записи!
Полусинхронная репликация
В процессе полусинхронной репликации MySQL главный узел не подтверждает фиксацию транзакции до тех пор, пока изменения точно не будут переданы в одну или несколько реплик. Это позволяет обеспечить отработку отказов без потерь: любые изменения, примененные к главному узлу, либо уже применены, либо ожидают применения к одной из его реплик.
Такая согласованность имеет свою цену, поскольку может привести к снижению доступности. Если ни одна реплика не подтвердит получение изменений, главный узел будет заблокирован, а запись остановится. К счастью, можно настроить время ожидания, по истечении которого главный узел сможет вернуться в режим асинхронной репликации, и запись будет возобновлена.
Мы выбрали достаточно низкое значение времени ожидания: 500 мс. Этого более чем достаточно для отправки изменений с главного узла в реплики в локальном ЦОД и даже в удаленные ЦОД. С таким временем ожидания мы получили идеальный полусинхронный режим (без отката к асинхронной репликации), а также очень короткий период блокировки в случае отсутствия подтверждения.
Мы включаем полусинхронную репликацию на локальных репликах в ЦОД и в случае выхода из строя главного узла ожидаем (хотя и не требуем) отработку отказа без потерь. Отработка отказа без потерь при полном отказе ЦОД обходится слишком дорого, поэтому мы этого и не ждем.
Экспериментируя со временем ожидания для полусинхронной репликации, мы также обнаружили возможность повлиять на выбор идеального кандидата в случае сбоя главного узла. Активировав полусинхронный режим на нужных серверах и пометив их в качестве кандидатов, мы можем уменьшить общее время простоя, поскольку влияем на результат отработки отказа. Наши эксперименты показывают, что в большинстве случаев мы получаем идеальных кандидатов и, следовательно, быстрее распространяем информацию о смене главного узла.
Передача пакетов пульса
Вместо того, чтобы управлять запуском/остановкой службы pt-heartbeat на назначаемых/отключаемых главных узлах, мы решили запускать ее везде и всегда. Это потребовало определенной доработки, чтобы служба pt-heartbeat могла спокойно работать с серверами, которые либо часто изменяют значение параметра read_only, либо становятся полностью недоступны.
В нашей текущей конфигурации службы pt-heartbeat работают как на главных узлах, так и на их репликах. На главных узлах они генерируют события пульса. На репликах они определяют доступность серверов только для чтения и регулярно проверяют их текущее состояние. Как только сервер становится главным, служба pt-heartbeat на этом сервере определяет его как доступный для записи и начинает генерировать события пульса.
Делегирование задач orchestrator
Мы также делегировали orchestrator следующие задачи:
- генерация Pseudo-GTID;
- идентификация нового мастера как доступного для записи, очистка его состояния репликации;
- идентификация старого мастера как доступного только для чтения (
read_only), если это возможно.
Это упрощает выполнение задач, связанных с новым главным узлом. Узел, который только что был назначен главным, явно должен быть работоспособным и доступным, иначе мы бы его не назначили. Поэтому имеет смысл предоставить orchestrator возможность применять изменения непосредственно на вновь назначенном главном узле.
Ограничения и недостатки
Использование прокси-слоя приводит к тому, что приложения не получают идентификационных данных главного узла, однако и сам этот узел не может идентифицировать приложения. Главному узлу доступны только соединения, поступающие из прокси-слоя, и мы теряем информацию о реальном источнике этих соединений.
В плане развития распределенных систем, у нас все еще есть необработанные сценарии.
Отметим, что при изоляции центра обработки данных, в котором находится главный узел, приложения в этом ЦОД по-прежнему могут осуществлять запись на такой узел. Это может привести к несогласованности состояний после восстановления сети. Мы стараемся смягчить последствия возникновения двух главных узлов в такой ситуации путем реализации метода STONITH изнутри самого изолированного ЦОД. Как уже говорилось ранее, пройдет некоторое время, прежде чем старый главный узел будет отключен, поэтому короткого периода «двоевластия» все-таки избежать не удастся. Эксплуатационные издержки, направленные на полное предотвращение возникновения таких ситуаций, очень высоки.
Существуют и другие сценарии: отключение Consul во время отработки отказа, частичная изоляция ЦОД и т. д. Мы понимаем, что, работая с распределенными системами такого рода, невозможно закрыть все дыры, поэтому мы концентрируемся на самых важных.
Результаты
Наша система orchestrator/GLB/Consul обеспечила следующие преимущества:
- надежное обнаружение отказов;
- отработка отказов независимо от конкретных ЦОД;
- отработка отказов без потерь в большинстве случаев;
- поддержка сетевой изоляции ЦОД;
- смягчение последствий, когда возникают два главных узла (работа в этом направлении продолжается);
- отсутствие зависимости от взаимодействий;
- общее время простоя
10-13 секундв большинстве случаев.
- В редких ситуациях общее время простоя достигает
20 секунд, а в самых крайних случаях —25 секунд.
- В редких ситуациях общее время простоя достигает
Заключение
Схема «оркестровка/прокси/обнаружение служб» использует хорошо известные и надежные компоненты в несвязанной архитектуре, что упрощает развертывание, эксплуатацию и мониторинг. При этом каждый компонент можно отдельно масштабировать. Мы продолжаем искать способы улучшения, постоянно тестируя нашу систему.

