
Попытки научить различные системы видеть и понимать мир так же, как это делает человек, начались несколько десятилетий назад, но уже сейчас эти технологии стали настолько совершенны, что активно используются во многих сферах нашей жизни. На Хабре уже есть подробные статьи о машинном зрении, нейросетях и алгоритмах распознавания, поэтому мы не будем углубляться и вновь описывать эти сложные технологии, мы расскажем о практическом использовании этих систем в реальном мире.
Как это работает? Кратко
То, что для нас является фотографией, для системы распознавания образов — лишь набор пикселей с разными параметрами цвета. Чтобы научить систему распознавать на изображении отдельные объекты, необходимо предоставить ей датасет — набор из тысяч изображений, в которых указано, где именно находится нужный объект. Например, если мы хотим, чтобы система научилась распознавать на снимках людей, нужно показать ей множество фотографий людей разного возраста, в разных позах и одежде, в разных условиях. После подобной тренировки система сможет безошибочно распознать человека на фотографиях. Однако напрашивается другой вопрос: если для системы фотография — это просто совокупность пикселей, то как же нейросеть понимает, что именно изображено на фото?
Для распознавания объектов на изображении используются различные методы, но одним из самых перспективных признан метод гистограмм ориентированных градиентов (HOG). Изображение обесцвечивается, а затем в блоках 16х16 пикселей система находит направление смены цвета (вектор градиента), строит по всему изображению карту этих векторов, и тем самым «снимок» признаков объекта, которые не меняются в зависимости от позы/положения и освещения. Усовершенствованная версия алгоритма называется CoHOG — в ней учитываются границы объектов, то есть производится распознавание формы, а не только векторов градиентов.
Toshiba усовершенствовала метод CoHOG, значительно улучшив распознавание при плохом освещении — традиционный CoHOG, к примеру, плохо справляется с быстрым распознаванием в темноте, когда пешеходов практически не видно в свете фар. Метод ECoHOG (технология гистограмм совместного присутствия ориентированных градиентов) определяет человека за счёт дополнительного анализа направлений и размеров его очертаний, находя голову, ноги, руки, плечи. Если CoHOG просто вычленяет на изображении антропометрические очертания (анализ «граница объекта — векторы границ»), то для ECoHOG важны размерности границ объекта относительно друг друга.
Пять ключевых сфер применения
Маркетинг
Распознавание образов — перспективное направление в рекламе и маркетинге. Нейросети позволяются за считанные часы узнать вещи, для поиска которых в других случаях нужна большая команда профессионалов и недели, а то и месяцы исследований. Например, российский сервис YouScan, система мониторинга социальных медиа, отслеживает упоминание брендов в соцсетях. Причём делает это не только в тексте постов, но и на фотографиях, а также помогает сделать определённые выводы о продукте. С помощью распознавания образов на фото нашли интересную закономерность, поиск которой никому бы и не пришел в голову: среди животных коты чаще встречаются с техникой Apple, а собаки — с брендом Adidas. Эта необычная информация может пригодиться для таргетирования рекламы.
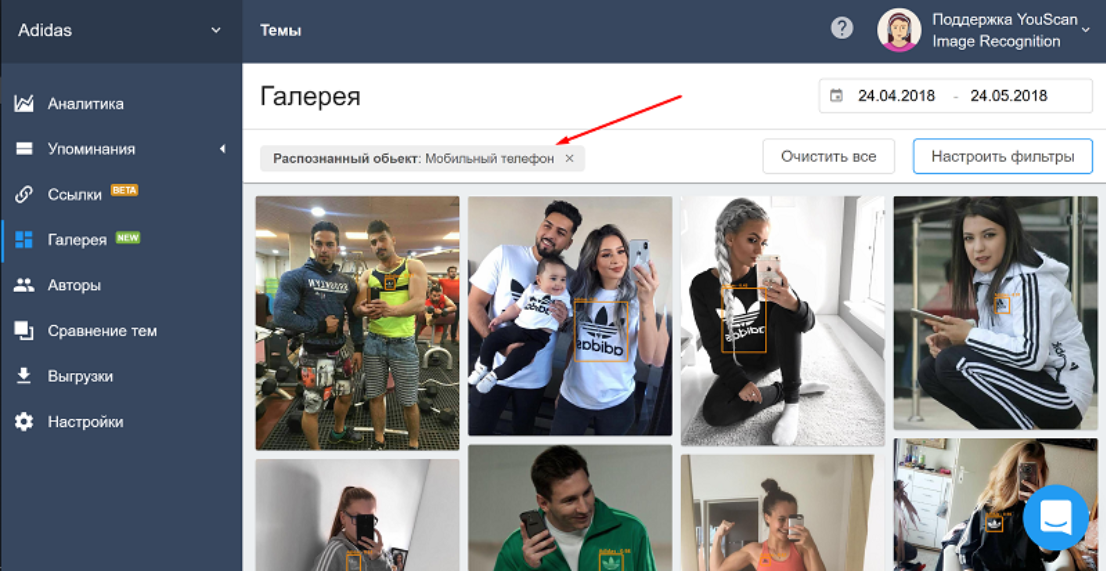
При поиске по логотипу Adidas сервис YouScan отфильтровал фотографии со смартфонами в руках владельцев. Копирайт: YouScan
Видеонаблюдение
Распознавание образов на камерах городского видеонаблюдения — это, пожалуй, самая неотвратимая перспектива использования машинного зрения. С 2017 года в Москве тестируется система умного видеонаблюдения с целью идентификации преступников в местах массового скопления людей. К городской сети камер подключена технология от российской компании NTechLab, которая уже помогла задержать несколько десятков правонарушителей. В Китае подобная система видеонаблюдения способна распознавать не только лица, но и марки автомобилей и одежды на людях, что может быть впоследствии использовано маркетологами для своих исследований.
На видео показана реальная работа распознавания образов и лиц SenseTime
Медицина
Распознавание образов уже стало настоящим прорывом в медицине — во многих случаях компьютеры замечают вещи, которые пропускают даже самые опытные врачи. Они выступают своеобразными помощниками, чье «техническое» мнение подтверждает гипотезу врача или дает повод для более глубоких исследований.
В России ведутся разработки программных комплексов для диагностики раковых образований на снимках КТ, МРТ и ПЭТ. Для этого через нейросеть прогоняют тысячи размеченных снимков, после чего точность распознавания новых снимков возрастает до 95-97%. Среди прочих разработкой такой платформы занимается Департамент информационных технологий Москвы, используя открытую библиотеку Google TensorFlow.
Созданная Google нейросеть Inception анализирует микроскопическое исследование биопсии лимфатических узлов в поиске раковых клеток в молочных железах. Для человека это очень долгий и трудоемкий процесс, в ходе которого легко ошибиться или пропустить что-то важное, так как в некоторых случаях размер изображения составляет 100 000 х 100 000 пикселей. Нейросеть Inception обеспечивает чувствительность около 92% против 72% у врача. Нейросеть не упустит из виду все подозрительные участки снимков, хотя и допускаются ложные срабатывания, которые позже отфильтрует врач.
Автомобили
Распознавание объектов в автомобилях — это необходимая часть систем безопасности ADAS (Advanced driver-assistance systems). ADAS могут быть реализованы как сложными средствами, вроде радара и инфракрасных датчиков, так и при помощи монокулярной камеры. В прошлой статье мы уже рассказывали, что одной видеокамеры вполне достаточно для того, чтобы автомобиль в реальном времени смог распознать пешеходов, знаки и светофоры. Однако такое распознавание «на лету» — очень ресурсоемкая задача, для выполнения которой нужен специализированный процессор. Toshiba уже в течение нескольких лет развивает серию таких процессоров. Они строят трехмерную модель на основе движущегося изображения с одной камеры, и тем самым замечают неизвестные препятствия на дороге. Ведь если нейросеть обучена распознавать только людей, разметку и знаки, то лежащая на асфальте покрышка или кусок ограждения не будут распознаны и расценены, как опасность.

Процессоры Visconti выделяют на изображении зоны, классифицируют их и помогают автопилоту или ADAS принять решение. Источник: Toshiba
Дроны
В дронах распознавание объектов используется как в развлекательных, так и в научных целях. В 2015 году немало шума наделал коптер Lily с автоматическим включением двигателей при подбрасывании и функцией слежения за владельцем. Lily направлял объектив на хозяина, независимо от траектории и скорости его передвижения. Правда, к распознаванию образов эта функция Lily не имела никакого отношения, так как дрон следил не столько за образом человека, сколько за пультом управления, который был надет на руку владельца.
Дроны с распознаванием изображений используются и для более серьезных вещей. Например, норвежская компания eSmart Systems разработала интеллектуальные решения для энергосетей. В рамках одного из их проектов — Connected Drone — дроны используются для поиска неисправностей на линиях электропередач. Обученные распознаванию элементов энергосетей, они проверяют целостность проводов, изоляторов и других частей ЛЭП. Это особенно важно для быстрой локализации неисправности, когда от линии зависит электроснабжение города или предприятия. Учитывая, что часто ЛЭП построены в труднодоступных местах, послать бригаду дронов на поиск неисправности где-нибудь в тайге или в горах гораздо эффективней, чем послать бригаду людей.

Дроны eSmart находят элементы энергетической инфраструктуры и в случае обнаружения повреждений помечают объект, оставляя предупреждение для оператора. Источник: eSmart Systems

