Введение
С распространением философии Agile российские IT-специалисты с каждым годом накапливают все больше экспертизы и компетенций в области настройки и управления продуктами для команд разработчиков, самым популярным из которых до сих пор остается Jira. Однако работа с самой «старшей», производительной и высокодоступной ее версией — Jira Data Center — все еще вызывает очень много вопросов. В этом посте я расскажу о некоторых принципах и механизмах работы Jira DataCenter, которые мы применяем на практике. Начну с рассказа о структуре кластера Jira.
Что такое Jira DataCenter?
Jira DataCenter – это, по сути, серверная версия, но с возможностью использовать общую базу данных и совместный индекс.
Важно понимать, что сама по себе Jira DataCenter, как продукт и как приложение – НЕ обеспечивает отказоустойчивость и балансировку нагрузки. За это отвечают модули и системы, к которым продукт Atlassian отношения не имеет.
Иными словами – Atlassian обеспечивают поддержку работы в кластере, но сама кластеризация реализуется внешними средствами, выбор которых довольно богат.
С подробным описанием продукта можно ознакомиться на сайте Atlassian.
Вариантов построения предлагается несколько:
1. На собственной инфраструктуре
2. В облаке Amazon (AWS)
3. В облаке MS (Azure)
В данной статье будет описываться решение для собственной инфраструктуры.
Какие проблемы решает Jira DataCenter?
Jira Data Center помогает достичь следующих целей:
- Реализация отказоустойчивости.
- Обеспечение стабильной работы под высокой нагрузкой. Под высокой нагрузкой подразумеваются large/enterprise scale инстансы, согласно Jira Sizing Guide.
- Обеспечение непрерывной работы при необходимости обслуживания. На этом пункте остановлюсь отдельно. Приложение довольно часто приходится обновлять и далеко не все компании имеют возможность сделать это быстро, и незаметно для пользователей. Эту проблему решает кластеризация и использование так называемой Zero Downtime схемы обновлений.
Указанные проблемы решаются благодаря кластеризации и масштабируемой архитектуре.
Из каких компонентов состоит Jira DataCenter?
Как видно на рисунке ниже, кластер Jira DataCenter представляет собой набор из нескольких выделенных машин
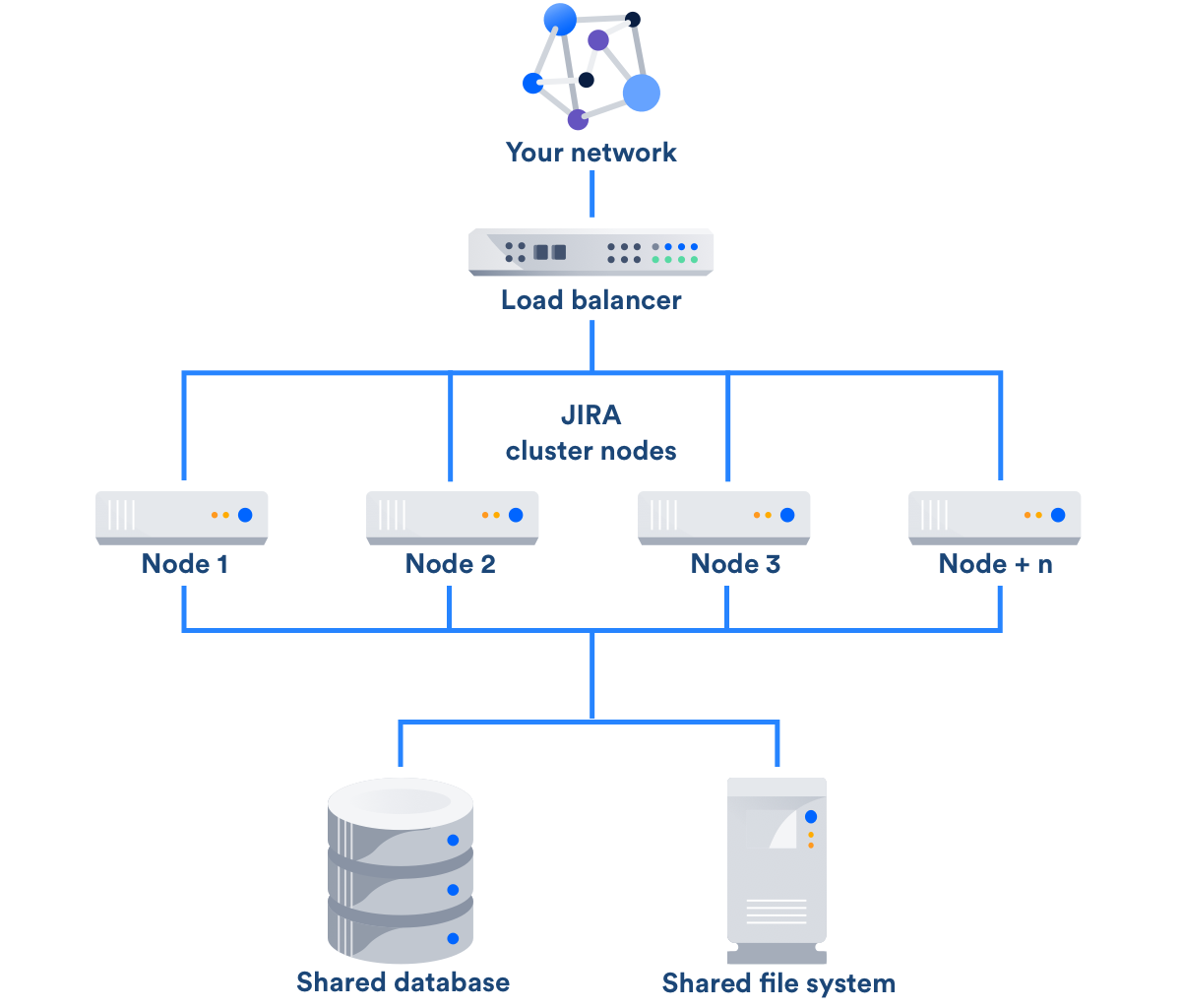
Рисунок 1. Архитектура Jira Data Center
- Ноды приложений (Application nodes или cluster nodes). Они принимают и обрабатывают всю рабочую нагрузку и запросы. Роль нод выполняют обычные сервера, с идентичным содержимым и установленным приложением, а также подмонтированной общей файловой системой.
- Файловая система (Shared file system) со стандартными возможностями импорта/экспорта файлов, плагинами, кэшированием и так далее. Файловый сервер — тоже отдельный сервер, на котором создается общая папка или ресурс, который монтируется к нодам и используется для общих файлов.
- База данных (Shared database). Сервер баз данных также, в данном случае, является отдельным сервером и может быть построен на решениях MS SQL, PostgreSQL, MySQL, Oracle.
- Балансировщик нагрузки (Load balancer). Он распределяет запросы пользователей и доставляет их к нодам, а если одна из них выходит из строя, то балансировщик перенаправляет ее запросы к другим нодам практически моментально. Благодаря его работе выход одной ноды из строя пользователи даже не замечают. О работе балансировщика мы ниже поговорим отдельно.
Топология кластера Jira Data Center
Приведу основные принципы, по которым строится кластер в JDC:
- инстансы Jira используют общую базу данных;
- индекс Lucene реплицируется в реальном времени и сохраняется локально на каждый инстанс;
- вложения хранятся в общем хранилище;
- инстансы Jira следят за консистентностью кэшей;
- в любой момент могут быть одновременно активны несколько инстансов;
- доступны кластерные блокировки;
- балансировщик настраивается на перенаправление запросов только на активные ноды, при этом он не должен переадресовывать запросы на неактивные ноды, а также не может адресовать все сессии на одну ноду.
Все ноды делятся на активные и пассивные. Активные ноды отличаются тем, что они:
- Обрабатывают запросы
- Выполняют фоновые процессы и задачи
- На одной или нескольких из них могут быть настроены запланированные задачи
- Во все практических сценариях ситуация будет выглядеть как при использовании стандартного Jira Server. Соответственно, пассивные ноды не обрабатывают запросы и не выполняют задач, а служат для того, чтобы взять на себя кратковременную рабочую нагрузку (например, при старте системы, загрузке плагинов и/или индексировании).
На рисунке ниже изображена работа кластера Jira
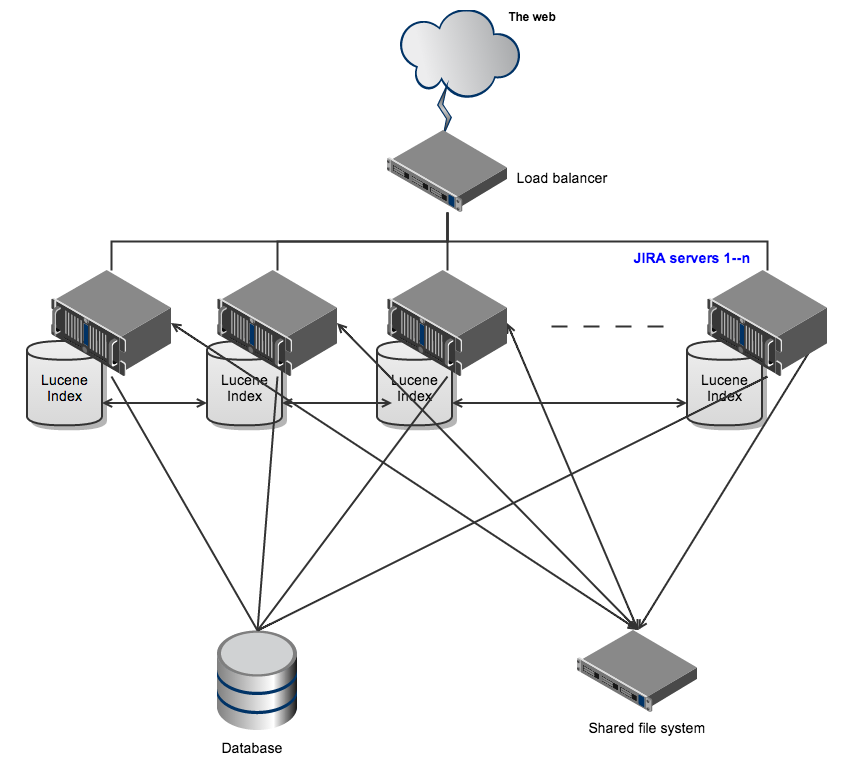
Рисунок 2. Упрощенная схема работы архитектуры
О балансировщиках нагрузки
Балансировщиком может выступать любой сервер с установленным обратным прокси или физическое устройство. Приведу наиболее известные примеры балансировщиков.
1. Аппаратные балансировщики:
• Cisco
• Juniper
• F5
2. Программные балансировщики:
• mod_proxy (Apache) — прокси-сервер для Apache HTTP Server, поддерживающий большинство популярных протоколов и несколько разных алгоритмов балансировки нагрузок.
• Varnish представляет собой обратный HTTP прокси-сервер и ускоритель, он предназначен для сайтов с большим трафиком. В отличие от других, он представляет собой только прокси-сервер и балансировки нагрузки HTTP-трафика. В частности Varnish используют Wikipedia, NY Times, The Guardian и многие другие крупные проекты.
• Nginx — веб-сервер номер №1 по популярности среди балансировщиков нагрузки и прокси-решений для сайтов с большим трафиком. Он активно развивается, производитель предлагает бесплатную и корпоративную версии. Используется на многих из самых посещаемых сайтов в мире, например, WordPress.com, Zynga, Airbnb, Hulu, MaxCDN.
• Nginx Plus — собственно, упомянутая выше платная корпоративная версия Nginx.
• HAProxy — свободный инструмент с открытым исходным кодом, который обеспечивает балансировку нагрузки и возможности прокси-сервера для протоколов TCP / HTTP. Он быстрый и потребляет немного системных ресурсов, совместим с Linux, Solaris, FreeBSD и Windows.
Хорошее сравнение прокси-серверов можно найти вот по этой ссылке.
«Прямые» и «обратные» прокси
Балансировщики нагрузки могут работать как прямые, а также и как обратные прокси. Разницу хорошо описал автор этого комментария на stackoverflow:
1. «Прямой прокси» (Forward proxy). Прокси-событие в этом случае заключается в том, что «прямой прокси» извлекает данные с другого веб-сайта от имени первоначального запрашивающего. В качестве примера я приведу список трех компьютеров, подключенных к Интернету.
X = компьютер или компьютер «клиент» в Интернете
Y = веб-сайт прокси, proxy.example.org
Z = веб-сайт, который вы хотите посетить, www.example.net
Обычно можно подключиться непосредственно из X --> Z. Однако в некоторых сценариях лучше Y --> Z от имени X, которая цепью выглядит следующим образом: X --> Y --> Z.
2. «Обратный прокси» (Reverse proxy). Представим себе ту же ситуацию, только на сайте Y настроен обратный прокси. Обычно можно подключиться непосредственно из X --> Z. Однако в некоторых сценариях администратору Z лучше ограничивать или запрещать прямой доступ и заставлять посетителей сначала проходить через Y. Таким образом, как и раньше, мы получаем данные, получаемые Y --> Z от имени X, который следующим образом: X --> Y --> Z.
Этот случай отличается от «прямого прокси» тем, что пользователь X не знает, что он обращается к Z, потому что пользователь X видит, что он обменивается данными с Y. Сервер Z невидим для клиентов, и только внешний прокси-сервер Y виден внешне. Обратный прокси не требует конфигурации на стороне клиента. Клиент X считает, что он только взаимодействует с Y (X --> Y), но реальность такова, что Y перенаправляет всю связь (X --> Y --> Z снова).
Далее мы рассмотрим работу с программным балансировщиком.
Какой программный балансировщик выбрать?
По нашему опыту, оптимальным выбором среди программных балансировщиков является Nginx, потому что он поддерживает режим Sticky sessions, а также является одним из наиболее часто используемых веб-серверов, что подразумевает хорошее документирование и достаточную известность среди IT-специалистов.
Sticky session — метод балансировки нагрузки, при котором запросы клиента передаются на один и тот же сервер группы. В Nginx существует метод sticky, использующий cookie для балансировки, правда только в коммерческой версии. Но есть и бесплатный способ — использование внешних модулей.
Модуль создает cookie, и таким образом делает каждый браузер уникальным. Далее cookie используется для переадресации запросов на один и тот же сервер. При отсутствии cookie (например, при первом запросе) сервер выбирается случайным образом.
Подробнее о методе sticky можно прочитать по этой ссылке, а также вот в этом Хабрапосте.
А теперь, переходим к практической части…
Инструкция по созданию кластера Jira DataCenter
Для кластеризации можно использовать как имеющийся инстанс с установленной Jira, так и новый. В нашем примере будет описана установка новых инстансов, на разных ОС (чтобы продемонстрировать универсальность системы).
1. Начнем с сервера баз данных. Можно использовать как существующий, так и создать новый. Опять же, для иллюстрации, была выбрана ОС Windows Server 2016 + PostgreSQL 9.4. Устанавливаем ОС, ставим PG сервер, устанавливаем PG Admin, добавляем пользователя и базу.
2. Создаем первую ноду на ОС Ubuntu 16.04 LTS. Устанавливаем необходимые пакеты, обновления репозиториев.
3. Скачиваем и устанавливаем Jira DataCenter, запускаем, настраиваем базу (на всякий случай, у Atlassian имеется подробный гайд).
4. Выключаем Jira, выключаем ноду.
service jira stop
5. Для дальнейших манипуляций, лучше временно отключить автозапуск Jira:
update-rc.d -f jira remove
6. Клонируем выключенную ноду.
7. Запускаем первую ноду, выключаем Jira (по умолчанию Jira после установки прописывается в автозапуск).
8. Запускаем вторую ноду, выключаем Jira.
9. Создаем отдельный инстанс для балансировщика. Я выбрал Ubuntu 16.04, т.к. это довольно быстро, просто и не требует дополнительных затрат в виде лицензий.
10. Устанавливаем nginx (в примере использована версия 1.13.4).
11. Качаем и распаковываем nginx-sticky-module-ng:
git clone bitbucket.org/nginx-goodies/nginx-sticky-module-ng.git
12. Готовим nginx к перекомпиляции и добавлению модуля.
13. Компилируем nginx с модулем nginx-sticky-module-ng. В моем случае строка компиляции получилась такой:
./configure --prefix=/etc/nginx --sbin-path=/usr/sbin/nginx --modules-path=/usr/lib/nginx/modules --conf-path=/etc/nginx/nginx.conf --error-log-path=/var/log/nginx/error.log --http-log-path=/var/log/nginx/access.log --pid-path=/var/run/nginx.pid --lock-path=/var/run/nginx.lock --http-client-body-temp-path=/var/cache/nginx/client_temp --http-proxy-temp-path=/var/cache/nginx/proxy_temp --http-fastcgi-temp-path=/var/cache/nginx/fastcgi_temp --http-uwsgi-temp-path=/var/cache/nginx/uwsgi_temp --http-scgi-temp-path=/var/cache/nginx/scgi_temp --user=nginx --group=nginx --with-compat --with-file-aio --with-threads --with-http_addition_module --with-http_auth_request_module --with-http_dav_module --with-http_flv_module --with-http_gunzip_module --with-http_gzip_static_module --with-http_mp4_module --with-http_random_index_module --with-http_realip_module --with-http_secure_link_module --with-http_slice_module --with-http_ssl_module --with-http_stub_status_module --with-http_sub_module --with-http_v2_module --with-mail --with-mail_ssl_module --with-stream --with-stream_realip_module --with-stream_ssl_module --with-stream_ssl_preread_module --with-cc-opt='-g -O2 -fstack-protector --param=ssp-buffer-size=4 -Wformat -Werror=format-security -Wp,-D_FORTIFY_SOURCE=2 -fPIC' --with-ld-opt='-Wl,-Bsymbolic-functions -Wl,-z,relro -Wl,-z,now -Wl,--as-needed -pie' --add-module=/usr/local/src/nginx-sticky-module-ng
14. Находим файл /etc/nginx/nginx.conf, копируем его в .bak, настраиваем nginx на режим обратного прокси.
15. Далее, нам потребуется файловый сервер (желательно тоже отказоустойчивый). Для примера я выбрал Windows-сервер, где создал NFS-шару.
16. На каждой ноде устанавливаем пакеты для поддержки NFS:
apt-get install nfs-common
17. Создаем папку /media/jira и выполняем:
chmod -R 0777 /media/Jira
18. Монтируем NFS шару как общую (обязательно монтировать не в root-папку, а, например, в /media/jira ) — НА КАЖДОЙ НОДЕ
19.1. Далее, можно осуществить либо ручное монтирование (однократное):
sudo mount -t nfs -O uid=1000,iocharset=utf-8 xx.xx.xx.xx:/jira /media/jira
где xx.xx.xx.xx – ip адрес сервера с NFS шарой
19.2. Либо сразу автоматическое монтирование (при запуске ОС):
mcedit /etc/fstab
В конце необходимо добавить строчку:
192.168.7.239:/jira /media/jira nfs user,rw 0 0
Затем сохранить и выйти.
20. Присваиваем ID: первой ноде node1, на второй ноде node2, и так далее.
#This ID must be unique across the cluster
jira.node.id = node1
#The location of the shared home directory for all Jira nodes
jira.shared.home = /media/jira
21. Запускаем джиру на первой ноде
service jira start
проверяем:
заходим в system -> system info -> ищем cluster ON и номер ноды.
22. Настраиваем балансировку nginx
23. Т.к. ранее мы отключили автозапуск Jira на нодах, то включить его можно командой:
update-rc.d -f jira enable
24. Проверяем работу кластера и по необходимости добавляем ноды.
Порядок запуска кластера
1. Включить Shared file system сервер
2. Включить Load balancer
3. Включить node1
4. Включить node2
5. …
Порядок остановки кластера
1. Остановить Jira на обеих нодах командой service Jira stop
2. Выключить ноду 2
3. Выключить ноду 1
4. Выключить балансировщик нагрузки
5. Выключить сервер файловой системы
На этом все…
Разумеется, описанный метод не является единственно верным. Это всего лишь один из путей реализации.
Выражаю благодарность коллегам за помощь в подготовке материала.
Комментируйте, задавайте вопросы и благодарю за внимание.

