Some time ago, in a discussion on one of SObjectizer's releases, we were asked: "Is it possible to make a DSL to describe a data-processing pipeline?" In other words, is it possible to write something like that:
A | B | C | D
and get a working pipeline where messages are going from A to B, and then to C, and then to D. With control that B receives exactly that type that A returns. And C receives exactly that type that B returns. And so on.
It was an interesting task with a surprisingly simple solution. For example, that's how the creation of a pipeline can look like:
auto pipeline = make_pipeline(env, stage(A) | stage(B) | stage(C) | stage(D));
Or, in a more complex case (that will be discussed below):
auto pipeline = make_pipeline( sobj.environment(), stage(validation) | stage(conversion) | broadcast( stage(archiving), stage(distribution), stage(range_checking) | stage(alarm_detector{}) | broadcast( stage(alarm_initiator), stage( []( const alarm_detected & v ) { alarm_distribution( cerr, v ); } ) ) ) );
In this article, we'll speak about the implementation of such pipeline DSL. We'll discuss mostly parts related to stage(), broadcast() and operator|() functions with several examples of usage of C++ templates. So I hope it will be interesting even for readers who don't know about SObjectizer (if you never heard of SObjectizer here is an overview of this tool).
A couple of words about the used demo
The example used in the article has been influenced by my old (and rather forgotten) experience in SCADA area.
The idea of the demo is the handling of data read from some sensor. The data is acquired from a sensor with some period, then that data has to be validated (incorrect data should be ignored) and converted into some actual values. For example, the raw data read from a sensor can be two 8-bit integer values and those values should be converted into one floating-point number.
Then the valid and converted values should be archived, distributed somewhere (on different nodes for visualization, for example), checked for "alarms" (if values are out of safe ranges then that should be specially handled). These operations are independent and can be performed in parallel.
Operations related to the detected alarm can be performed in parallel too: an "alarm" should be initiated (so the part of SCADA on the current node can react on it) and the information about the "alarm" should be distributed elsewhere (for example: stored to a historical database and/or visualized on SCADA operator's display).
This logic can be expressed in textual form that way:
optional(valid_raw_data) = validate(raw_data); if valid_raw_data is not empty then { converted_value = convert(valid_raw_data); do_async archive(converted_value); do_async distribute(converted_value); do_async { optional(suspicious_value) = check_range(converted_value); if suspicious_value is not empty then { optional(alarm) = detect_alarm(suspicious_value); if alarm is not empty then { do_async initiate_alarm(alarm); do_async distribute_alarm(alam); } } } }
Or, in graphical form:

It's a rather artificial example, but it has some interesting things I want to show. The first is the presence of parallel stages in a pipeline (operation broadcast() exists just because of that). The second is the presence of a state in some stages. For example, alarm_detector is stateful stage.
Pipeline capabilities
A pipeline is built from separate stages. Each stage is a function or a functor of the following format:
opt<Out> func(const In &);
or
void func(const In &);
Stages that return void can only be used as the last stage of a pipeline.
Stages are bound into a chain. Each next stage receives an object returned by the previous stage. If the previous stage returns empty opt<Out> value then the next stage is not called.
There is a special broadcast stage. It is constructed from several pipelines. A broadcast stage receives an object from the previous stage and broadcasts it to every subsidiary pipeline.
From the pipeline's point of view, broadcast stage looks like a function of the following format:
void func(const In &);
Because there is no return value from broadcast stage a broadcast stage can only be the last stage in a pipeline.
Why does the pipeline stage return an optional value?
It's because there is a need to drop some incoming values. For example, the validate stage returns nothing if a raw value is incorrect, and there is no sense to handle it.
Another example: the alarm_detector stage returns nothing if the current suspicious value doesn't produce a new alarm case.
Implementation details
Types and functions related to the application logic
Let's start from data types and functions related to the application logic. In the discussed example, the following data types are used for passing information from one stage to another:
// Raw data from a sensor. struct raw_measure { int m_meter_id; uint8_t m_high_bits; uint8_t m_low_bits; }; // Type of input for validation stage with raw data from a sensor. struct raw_value { raw_measure m_data; }; // Type of input for conversion stage with valid raw data from a sensor. struct valid_raw_value { raw_measure m_data; }; // Data from a sensor after conversion to Celsius degrees. struct calculated_measure { int m_meter_id; float m_measure; }; // The type for result of conversion stage with converted data from a sensor. struct sensor_value { calculated_measure m_data; }; // Type with value which could mean a dangerous level of temperature. struct suspicious_value { calculated_measure m_data; }; // Type with information about detected dangerous situation. struct alarm_detected { int m_meter_id; };
An instance of raw_value is going to the first stage of our pipeline. This raw_value contains information acquired from a sensor in the form of raw_measure object. Then raw_value is transformed to valid_raw_value. Then valid_raw_value transformed to sensor_value with an actual sensor's value in the form of calulated_measure. If an instance of sensor_value contains a suspicious value, then an instance of suspicious_value is produced. And that suspicious_value can be transformed into alarm_detected instance later.
Or, in the graphical form:

Now we can take a look at the implementation of our pipeline stages:
// // The first stage of a pipeline. Validation of raw data from a sensor. // // Returns valid_raw_value or nothing if value is invalid. // stage_result_t< valid_raw_value > validation( const raw_value & v ) { if( 0x7 >= v.m_data.m_high_bits ) return make_result< valid_raw_value >( v.m_data ); else return make_empty< valid_raw_value >(); } // // The second stage of a pipeline. Conversion from raw data to a value // in Celsius degrees. // stage_result_t< sensor_value > conversion( const valid_raw_value & v ) { return make_result< sensor_value >( calculated_measure{ v.m_data.m_meter_id, 0.5f * ((static_cast< uint16_t >( v.m_data.m_high_bits ) << 8) + v.m_data.m_low_bits) } ); } // // Simulation of the data archiving. // void archiving( const sensor_value & v ) { clog << "archiving (" << v.m_data.m_meter_id << "," << v.m_data.m_measure << ")" << endl; } // // Simulation of the data distribution. // void distribution( const sensor_value & v ) { clog << "distributing (" << v.m_data.m_meter_id << "," << v.m_data.m_measure << ")" << endl; } // // The first stage of a child pipeline at third level of the main pipeline. // // Checking for to high value of the temperature. // // Returns suspicious_value message or nothing. // stage_result_t< suspicious_value > range_checking( const sensor_value & v ) { if( v.m_data.m_measure >= 45.0f ) return make_result< suspicious_value >( v.m_data ); else return make_empty< suspicious_value >(); } // // The next stage of a child pipeline. // // Checks for two suspicious_value-es in 25ms time window. // class alarm_detector { using clock = chrono::steady_clock; public : stage_result_t< alarm_detected > operator()( const suspicious_value & v ) { if( m_previous ) if( *m_previous + chrono::milliseconds(25) > clock::now() ) { m_previous = nullopt; return make_result< alarm_detected >( v.m_data.m_meter_id ); } m_previous = clock::now(); return make_empty< alarm_detected >(); } private : optional< clock::time_point > m_previous; }; // // One of last stages of a child pipeline. // Imitates beginning of the alarm processing. // void alarm_initiator( const alarm_detected & v ) { clog << "=== alarm (" << v.m_meter_id << ") ===" << endl; } // // Another of last stages of a child pipeline. // Imitates distribution of the alarm. // void alarm_distribution( ostream & to, const alarm_detected & v ) { to << "alarm_distribution (" << v.m_meter_id << ")" << endl; }
Just skip stuff like stage_result_t, make_result and make_empty, we'll discuss it in the next section.
I hope that the code of those stages rather trivial. The only part that requires some additional explanation is the implementation of alarm_detector stage.
In that example, an alarm is initiated only if there are at least two suspicious_values in 25ms time window. So we have to remember the time of the previous suspicious_value instance at alarm_detector stage. That is because alarm_detector is implemented as a stateful functor with a function call operator.
Stages return SObjectizer's type instead of std::optional
I told earlier that stage could return optional value. But std::optional is not used in code, the different type stage_result_t can be seen in the implementation of stages.
It is because some of SObjectizer's specific plays its role here. The returned values will be distributed as messages between SObjectizer's agents (aka actors). Every message in SObjectizer is sent as a dynamically allocated object. So we have some kind of "optimization" here: instead of returning of std::optional and then allocating a new message object, we just allocate a message object and return a smart pointer to it.
In fact, stage_result_t is just a typedef for SObjectizer's shared_ptr analog:
template< typename M > using stage_result_t = message_holder_t< M >;
And make_result and make_empty are just helper functions for constructing stage_result_t with or without an actual value inside:
template< typename M, typename... Args > stage_result_t< M > make_result( Args &&... args ) { return stage_result_t< M >::make(forward< Args >(args)...); } template< typename M > stage_result_t< M > make_empty() { return stage_result_t< M >(); }
For simplicity it's safe to say the validation stage could be expressed that way:
std::shared_ptr< valid_raw_value > validation( const raw_value & v ) { if( 0x7 >= v.m_data.m_high_bits ) return std::make_shared< valid_raw_value >( v.m_data ); else return std::shared_ptr< valid_raw_value >{}; }
But, because of SObjectizer's specific, we can't use std::shared_ptr and have to deal with so_5::message_holder_t type. And we hide that specific behind stage_result_t, make_result and make_empty helpers.
stage_handler_t and stage_builder_t separation
An important point of the pipeline implementation is the separation of stage handler and stage builder concepts. This is done for simplicity. The presence of these concepts allowed me to have two steps in the pipeline definition.
At the first step, a user describes pipeline stages. As a result, I receive an instance of stage_t that holds all pipeline stages inside.
At the second step, a set of underlying SObjectizer's agents is created. Those agents receive messages with results of the previous stages and call actual stage handlers, then sends the results to the next stages.
But to create this set of agents every stage has to have a stage builder. Stage builder can be seen as a factory that creates an underlying SObjectizer's agent.
So we have the following relation: every pipeline stage produces two objects: stage handler that holds stage-related logic, and stage builder that creates an underlying SObjectizer's agent for calling stage handler at the appropriate time:

Stage handler is represented in the following way:
template< typename In, typename Out > class stage_handler_t { public : using traits = handler_traits_t< In, Out >; using func_type = function< typename traits::output(const typename traits::input &) >; stage_handler_t( func_type handler ) : m_handler( move(handler) ) {} template< typename Callable > stage_handler_t( Callable handler ) : m_handler( handler ) {} typename traits::output operator()( const typename traits::input & a ) const { return m_handler( a ); } private : func_type m_handler; };
Where handler_traits_t are defined the following way:
// // We have to deal with two types of stage handlers: // - intermediate handlers which will return some result (e.g. some new // message); // - terminal handlers which can return nothing (e.g. void instead of // stage_result_t<M>); // // This template with specialization defines `input` and `output` // aliases for both cases. // template< typename In, typename Out > struct handler_traits_t { using input = In; using output = stage_result_t< Out >; }; template< typename In > struct handler_traits_t< In, void > { using input = In; using output = void; };
Stage builder is represented by just std::function:
using stage_builder_t = function< mbox_t(coop_t &, mbox_t) >;
Helper types lambda_traits_t and callable_traits_t
Because stages can be represented by free functions or functors (like instances of alarm_detector class or anonymous compiler-generated classes representing lambdas), we need some helpers to detect types of stage's argument and return value. I used the following code for that purpose:
// // Helper type for `arg_type` and `result_type` alises definition. // template< typename R, typename A > struct callable_traits_typedefs_t { using arg_type = A; using result_type = R; }; // // Helper type for dealing with stateful objects with operator() // (they could be user-defined objects or generated by compiler // like lambdas). // template< typename T > struct lambda_traits_t; template< typename M, typename A, typename T > struct lambda_traits_t< stage_result_t< M >(T::*)(const A &) const > : public callable_traits_typedefs_t< M, A > {}; template< typename A, typename T > struct lambda_traits_t< void (T::*)(const A &) const > : public callable_traits_typedefs_t< void, A > {}; template< typename M, typename A, typename T > struct lambda_traits_t< stage_result_t< M >(T::*)(const A &) > : public callable_traits_typedefs_t< M, A > {}; template< typename A, typename T > struct lambda_traits_t< void (T::*)(const A &) > : public callable_traits_typedefs_t< void, A > {}; // // Main type for definition of `arg_type` and `result_type` aliases. // With specialization for various cases. // template< typename T > struct callable_traits_t : public lambda_traits_t< decltype(&T::operator()) > {}; template< typename M, typename A > struct callable_traits_t< stage_result_t< M >(*)(const A &) > : public callable_traits_typedefs_t< M, A > {}; template< typename A > struct callable_traits_t< void(*)(const A &) > : public callable_traits_typedefs_t< void, A > {};
I hope this code will be quite understandable for readers with good knowledge of C++. If not, feel free to ask me in the comments, I'll be glad to explain the logic behind lambda_traits_t and callable_traits_t in details.
stage(), broadcast() and operator|() functions
Now we can look inside the main pipeline-building functions. But before that, it's necessary to take a look at the definition of a template class stage_t:
template< typename In, typename Out > struct stage_t { stage_builder_t m_builder; };
It's a very simple struct that holds just stage_bulder_t instance. Template parameters are not used inside stage_t, so why they are present here?
They are necessary for compile-time checking of type compatibility between pipeline stages. We'll see that soon.
Let's look at the simplest pipeline-building function, the stage():
template< typename Callable, typename In = typename callable_traits_t< Callable >::arg_type, typename Out = typename callable_traits_t< Callable >::result_type > stage_t< In, Out > stage( Callable handler ) { stage_builder_t builder{ [h = std::move(handler)]( coop_t & coop, mbox_t next_stage) -> mbox_t { return coop.make_agent< a_stage_point_t<In, Out> >( std::move(h), std::move(next_stage) ) ->so_direct_mbox(); } }; return { std::move(builder) }; }
It receives an actual stage handler as a single parameter. It can be a pointer to a function or lambda-function or functor. The types of stage's input and output are deduced automatically because of "template magic" behind callable_traits_t template.
An instance of stage builder is created inside and that instance is returned in a new stage_t object as the result of stage() function. An actual stage handler is captured by stage builder lambda, it'll then be used for the construction of an underlying SObjectizer's agent (we'll speak about that in the next section).
The next function to review is operator|() that concatenates two stages together and return a new stage:
template< typename In, typename Out1, typename Out2 > stage_t< In, Out2 > operator|( stage_t< In, Out1 > && prev, stage_t< Out1, Out2 > && next ) { return { stage_builder_t{ [prev, next]( coop_t & coop, mbox_t next_stage ) -> mbox_t { auto m = next.m_builder( coop, std::move(next_stage) ); return prev.m_builder( coop, std::move(m) ); } } }; }
The simplest way to explain the logic of operator|() is to try to draw a picture. Let's assume we have the expression:
stage(A) | stage(B) | stage(C) | stage(B)
This expression will be transformed that way:

There we can also see how compile-time type-checking is working: the definition of operator|() requires that the output type of the first stage is the input of the second stage. If this is not the case the code won't be compiled.
And now we can take a look at the most complex pipeline-building function, the broadcast(). The function itself is rather simple:
template< typename In, typename Out, typename... Rest > stage_t< In, void > broadcast( stage_t< In, Out > && first, Rest &&... stages ) { stage_builder_t builder{ [broadcasts = collect_sink_builders( move(first), forward< Rest >(stages)...)] ( coop_t & coop, mbox_t ) -> mbox_t { vector< mbox_t > mboxes; mboxes.reserve( broadcasts.size() ); for( const auto & b : broadcasts ) mboxes.emplace_back( b( coop, mbox_t{} ) ); return broadcast_mbox_t::make( coop.environment(), std::move(mboxes) ); } }; return { std::move(builder) }; }
The main difference between an ordinary stage and broadcast-stage is that broadcast-stage has to hold a vector of subsidiary stage builders. So we have to create that vector and pass it into the main stage builder of broadcast-stage. Because of that, we can see a call to collect_sink_builders in a lambda's capture list inside broadcast() function:
stage_builder_t builder{ [broadcasts = collect_sink_builders( move(first), forward< Rest >(stages)...)]
If we look into collect_sink_builder we'll see the following code:
// // Serie of helper functions for building description for // `broadcast` stage. // // Those functions are used for collecting // `builders` functions for every child pipeline. // // Please note that this functions checks that each child pipeline has the // same In type. // template< typename In, typename Out, typename... Rest > void move_sink_builder_to( vector< stage_builder_t > & receiver, stage_t< In, Out > && first, Rest &&... rest ) { receiver.emplace_back( move( first.m_builder ) ); if constexpr( 0u != sizeof...(rest) ) move_sink_builder_to<In>( receiver, forward< Rest >(rest)... ); } template< typename In, typename Out, typename... Rest > vector< stage_builder_t > collect_sink_builders( stage_t< In, Out > && first, Rest &&... stages ) { vector< stage_builder_t > receiver; receiver.reserve( 1 + sizeof...(stages) ); move_sink_builder_to<In>( receiver, move(first), std::forward<Rest>(stages)... ); return receiver; }
Compile-time type-checking works here too: it's because a call to move_sink_builder_to explicitly parameterized by type 'In'. It means that a call in the form collect_sink_builders(stage_t<In1, Out1>, stage_t<In2, Out2>, ...) will lead to compile error because compiler prohibits a call move_sink_builder_to<In1>(receiver, stage_t<In2, Out2>, ...).
I can also note that because the count of subsidiary pipelines for broadcast() is known at compile-time we can use std::array instead of std::vector and can avoid some memory allocations. But std::vector is used here just for simplicity.
Relation between stages and SObjectizer's agents/mboxes
The idea behind the implementation of the pipeline is the creation of a separate agent for every pipeline stage. An agent receives an incoming message, passes it to the corresponding stage handler, analyzes the result and, if the result is not empty, sends the result as an incoming message to the next stage. It can be illustrated by the following sequence diagram:

Some SObjectizer-related things have to be discussed, at least briefly. If you have no interest in such details you can skip the sections below and go to the conclusion directly.
Coop is a group of agents to work together
Agents are introduced into SObjectizer not individually but in groups named coops. A coop is a group of agents that should work together and there is no sense to continue the work if one of the agents of the group is missing.
So the introduction of agents to SObjectizer looks like the creation of coop instance, filling that instance with the appropriate agents and then registering the coop in SObjectizer.
Because of that the first argument for a stage builder is a reference to a new coop. This coop is created in make_pipeline() function (discussed below), then it's populated by stage builders and then registered (again in the make_pipeline() function).
Message boxes
SObjectizer implements several concurrency-related models. The Actor Model just one of them. Because of that, SObjectizer can differ significantly from other actor frameworks. One of the differences is the addressing scheme for messages.
Messages in SObjectizer is addressed not to actors, but message boxes (mboxes). Actors have to subscribe to messages from a mbox. If an actor subscribed to a particular message type from a mbox it would receive messages of that type:
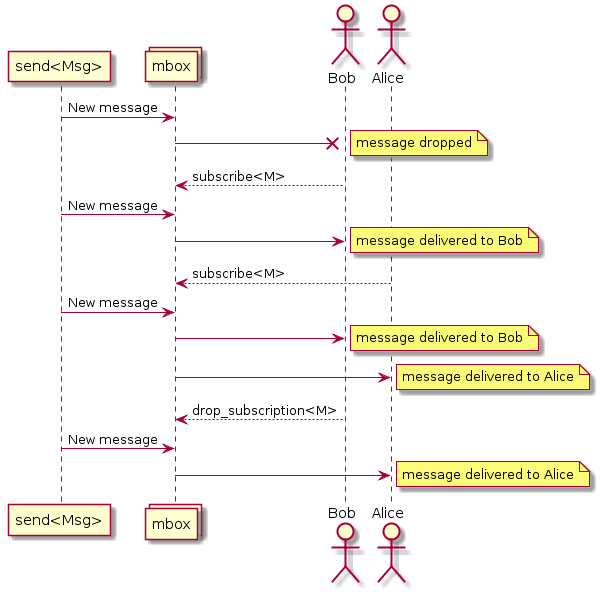
This fact is crucial because it's necessary to send messages from one stage to another. It means that every stage should have its mbox and that mbox should be known for the previous stage.
Every actor (aka agent) in SObjectizer has the direct mbox. This mbox is associated only with the owner agent and can't be used by any other agents. The direct mboxes of agents created for stages will be used for stages interaction.
This SObjectizer's specific feature dictates some pipeline-implementation details.
The first is the fact that stage builder has the following prototype:
mbox_t builder(coop_t &, mbox_t);
It means that stage builder receives a mbox of the next stage and should create a new agent that will send the stage's results to that mbox. A mbox of the new agent should be returned by stage builder. That mbox will be used for the creation of an agent for the previous stage.
The second is the fact that agents for stages are created in reserve order. It means that if we have a pipeline:
stage(A) | stage(B) | stage(C)
An agent for stage C will be created first, then its mbox will be used for the creation of an agent for stage B, and then mbox of B-stage agent will be used for the creation of an agent for stage A.
It also worth to note that operator|() doesn't create agents:
stage_builder_t{ [prev, next]( coop_t & coop, mbox_t next_stage ) -> mbox_t { auto m = next.m_builder( coop, std::move(next_stage) ); return prev.m_builder( coop, std::move(m) ); } }
The operator|() creates a builder that only calls other builders but doesn't introduce additional agents. So for the case:
stage(A) | stage(B)
only two agents will be created (for A-stage and B-stage) and then they will be linked together in the stage builder created by operator|().
There is no agent for broadcast() implementation
An obvious way to implement a broadcasting stage is to create a special agent that will receive an incoming message and then resend that message to a list of destination mboxes. That way was used in the first implementation of the described pipeline DSL.
But our companion project, so5extra, now has a special variant of mbox: broadcasting one. That mbox does exactly what is required here: it takes a new message and delivers it to a set of destination mboxes.
Because of that there is no need to create a separate broadcasting agent, we can just use broadcasting mbox from so5extra:
// // A special mbox for broadcasting of a message to a set of destination // mboxes. // using broadcast_mbox_t = so_5::extra::mboxes::broadcast::fixed_mbox_template_t<>; ... // // Inside the broadcast() function: // stage_builder_t builder{ [broadcasts = collect_sink_builders( move(first), forward< Rest >(stages)...)] ( coop_t & coop, mbox_t ) -> mbox_t { vector< mbox_t > mboxes; mboxes.reserve( broadcasts.size() ); for( const auto & b : broadcasts ) mboxes.emplace_back( b( coop, mbox_t{} ) ); // That is the creation of broadcasting mbox instance. return broadcast_mbox_t::make( coop.environment(), std::move(mboxes) ); } };
Implementation of stage-agent
Now we can take a look at the implementation of stage agent:
// // An agent which will be used as intermediate or terminal pipeline stage. // It will receive input message, call the stage handler and pass // handler result to the next stage (if any). // template< typename In, typename Out > class a_stage_point_t final : public agent_t { public : a_stage_point_t( context_t ctx, stage_handler_t< In, Out > handler, mbox_t next_stage ) : agent_t{ ctx } , m_handler{ move( handler ) } , m_next{ move(next_stage) } {} void so_define_agent() override { if( m_next ) // Because there is the next stage the appropriate // message handler will be used. so_subscribe_self().event( [=]( const In & evt ) { auto r = m_handler( evt ); if( r ) so_5::send( m_next, r ); } ); else // There is no next stage. A very simple message handler // will be used for that case. so_subscribe_self().event( [=]( const In & evt ) { m_handler( evt ); } ); } private : const stage_handler_t< In, Out > m_handler; const mbox_t m_next; }; // // A specialization of a_stage_point_t for the case of terminal stage of // a pipeline. This type will be used for stage handlers with void // return type. // template< typename In > class a_stage_point_t< In, void > final : public agent_t { public : a_stage_point_t( context_t ctx, stage_handler_t< In, void > handler, mbox_t next_stage ) : agent_t{ ctx } , m_handler{ move( handler ) } { if( next_stage ) throw std::runtime_error( "sink point cannot have next stage" ); } void so_define_agent() override { so_subscribe_self().event( [=]( const In & evt ) { m_handler( evt ); } ); } private : const stage_handler_t< In, void > m_handler; };
It's rather trivial if you understand the SObjectizer's basics. If not it will be quite hard to explain in a few words (so feel free to ask questions in the comments).
The main implementation of a_stage_point_t agent creates a subscription to a message of type In. When a message of this type arrives the stage handler is called. If the stage handler returns an actual result the result is sent to the next stage (if that stage exists).
There is also a version of a_stage_point_t for the case when the corresponding stage is the terminal stage and there can't be the next stage.
The implementation of a_stage_point_t can look a bit complicated but believe me, it's one of the simplest agents I've written.
make_pipeline() function
It's time to discuss the last pipeline-building function, the make_pipeline():
template< typename In, typename Out, typename... Args > mbox_t make_pipeline( // SObjectizer Environment to work in. so_5::environment_t & env, // Definition of a pipeline. stage_t< In, Out > && sink, // Optional args to be passed to make_coop() function. Args &&... args ) { auto coop = env.make_coop( forward< Args >(args)... ); auto mbox = sink.m_builder( *coop, mbox_t{} ); env.register_coop( move(coop) ); return mbox; }
There is no magic nor surprises here. We just need to create a new coop for underlying agents of the pipeline, fill that coop with agents by calling a top-level stage builder, and then register that coop into SObjectizer. That all.
The result of make_pipeline() is the mbox of the left-most (the first) stage of the pipeline. That mbox should be used for sending messages to the pipeline.
The simulation and experiments with it
So now we have data types and functions for our application logic and the tools for chaining those functions into a data-processing pipeline. Let's do it and see a result:
int main() { // Launch SObjectizer in a separate thread. wrapped_env_t sobj; // Make a pipeline. auto pipeline = make_pipeline( sobj.environment(), stage(validation) | stage(conversion) | broadcast( stage(archiving), stage(distribution), stage(range_checking) | stage(alarm_detector{}) | broadcast( stage(alarm_initiator), stage( []( const alarm_detected & v ) { alarm_distribution( cerr, v ); } ) ) ) ); // Send messages to a pipeline in a loop with 10ms delays. for( uint8_t i = 0; i < static_cast< uint8_t >(250); i += 10 ) { send< raw_value >( pipeline, raw_measure{ 0, 0, i } ); std::this_thread::sleep_for( chrono::milliseconds{10} ); } }
If we run that example we'll see the following output:
archiving (0,0) distributing (0,0) archiving (0,5) distributing (0,5) archiving (0,10) distributing (0,10) archiving (0,15) distributing (0,15) archiving (0,20) distributing (0,20) archiving (0,25) distributing (0,25) archiving (0,30) distributing (0,30) ... archiving (0,105) distributing (0,105) archiving (0,110) distributing (0,110) === alarm (0) === alarm_distribution (0) archiving (0,115) distributing (0,115) archiving (0,120) distributing (0,120) === alarm (0) === alarm_distribution (0)
It works.
But it seems that stages of our pipeline work sequentially, one after another, isn't it?
Yes, it is. This is because all pipeline agents are bound to the default SObjectizer's dispatcher. And that dispatcher uses just one worker thread for serving message processing of all agents.
But this can be easily changed. Just pass an additional argument to make_pipeline() call:
// Make a pipeline. auto pipeline = make_pipeline( sobj.environment(), stage(validation) | stage(conversion) | broadcast( stage(archiving), stage(distribution), stage(range_checking) | stage(alarm_detector{}) | broadcast( stage(alarm_initiator), stage( []( const alarm_detected & v ) { alarm_distribution( cerr, v ); } ) ) ), disp::thread_pool::make_dispatcher( sobj.environment() ).binder( disp::thread_pool::bind_params_t{}.fifo( disp::thread_pool::fifo_t::individual ) ) );
This creates a new thread pool and binds all pipeline agents to that pool. Each agent will be served by the pool independently from other agents.
If we run the modified example we can see something like that:
archiving (0,0) distributing (0,0) distributing (0,5) archiving (0,5) archiving (0,10) distributing (0,10) distributing (archiving (0,15) 0,15) archiving (0,20) distributing (0,20) archiving (0,25) distributing (0,25) archiving (0,distributing (030) ,30) ... archiving (0,distributing (0,105) 105) archiving (0,alarm_distribution (0) distributing (0,=== alarm (0) === 110) 110) archiving (distributing (0,0,115) 115) archiving (distributing (=== alarm (0) === 0alarm_distribution (0) 0,120) ,120)
So we can see that different stages of the pipeline work in parallel.
But is it possible to go further and to have an ability to bind stages to different dispatchers?
Yes, it is possible, but we have to implement another overload for stage() function:
template< typename Callable, typename In = typename callable_traits_t< Callable >::arg_type, typename Out = typename callable_traits_t< Callable >::result_type > stage_t< In, Out > stage( disp_binder_shptr_t disp_binder, Callable handler ) { stage_builder_t builder{ [binder = std::move(disp_binder), h = std::move(handler)]( coop_t & coop, mbox_t next_stage) -> mbox_t { return coop.make_agent_with_binder< a_stage_point_t<In, Out> >( std::move(binder), std::move(h), std::move(next_stage) ) ->so_direct_mbox(); } }; return { std::move(builder) }; }
This version of stage() accepts not only a stage handler but also a dispatcher binder. Dispatcher binder is a way to bind an agent to the particular dispatcher. So to assign a stage to a specific working context we can create an appropriate dispatcher and then pass the binder to that dispatcher to stage() function. Let's do that:
// An active_obj dispatcher to be used for some stages. auto ao_disp = disp::active_obj::make_dispatcher( sobj.environment() ); // Make a pipeline. auto pipeline = make_pipeline( sobj.environment(), stage(validation) | stage(conversion) | broadcast( stage(ao_disp.binder(), archiving), stage(ao_disp.binder(), distribution), stage(range_checking) | stage(alarm_detector{}) | broadcast( stage(ao_disp.binder(), alarm_initiator), stage(ao_disp.binder(), []( const alarm_detected & v ) { alarm_distribution( cerr, v ); } ) ) ), disp::one_thread::make_dispatcher( sobj.environment() ).binder() );
In that case stages archiving, distribution, alarm_initiator and alarm_distribution will work on own worker threads. All other stages will work on the same single worker thread.
The conclusion
This was an interesting experiment and I was surprised how easy SObjectizer could be used in something like reactive programming or data-flow programming.
However, I don't think that pipeline DSL can be practically meaningful. It's too simple and, maybe not flexible enough. But, I hope, it can be a base for more interesting experiments for those why need to deal with different workflows and data-processing pipelines. At least as a base for some ideas in that area. C++ language a rather good here and some (not so complicated) template magic can help to catch various errors at compile-time.
In conclusion, I want to say that we see SObjectizer not as a specialized tool for solving a particular problem, but as a basic set of tools to be used in solutions for different problems. And, more importantly, that basic set can be extended for your needs. Just take a look at SObjectizer, try it, and share your feedback. Maybe you missed something in SObjectizer? Perhaps you don't like something? Tell us, and we can try to help you.
If you want to help further development of SObjectizer, please share a reference to it or to this article somewhere you want (Reddit, HackerNews, LinkedIn, Facebook, Twitter, ...). The more attention and the more feedback, the more new features will be incorporated into SObjectizer.
And many thanks for reading this ;)
PS. The source code for that example can be found in that repository.

