Классический вопрос, с которым разработчик приходит к своему DBA или владелец бизнеса — к консультанту по PostgreSQL, почти всегда звучит одинаково: «Почему запросы выполняются на базе так долго?»
Традиционный набор причин:
И если блокировки достаточно сложны в поимке и анализе, то для всего остального нам достаточно плана запроса, который можно получить с помощью оператора EXPLAIN (лучше, конечно, сразу EXPLAIN (ANALYZE, BUFFERS) ...) или модуля auto_explain.
Но, как сказано в той же документации,
Как обычно выглядит план запроса? Как-то вот так:
или вот так:
Но читать план текстом «с листа» — очень сложно и ненаглядно:
Когда мы попытались объяснить все это нескольким сотням наших разработчиков, то поняли, что со стороны это выглядит примерно вот так:

А, значит, нам нужен…
В нем мы постарались собрать все ключевые механики, которые помогают по плану и запросу понять, «кто виноват и что делать». Ну, и частью своего опыта поделиться с сообществом.
Встречайте и пользуйтесь — explain.tensor.ru
Легко ли понять план, когда он выглядит так?
Не очень.
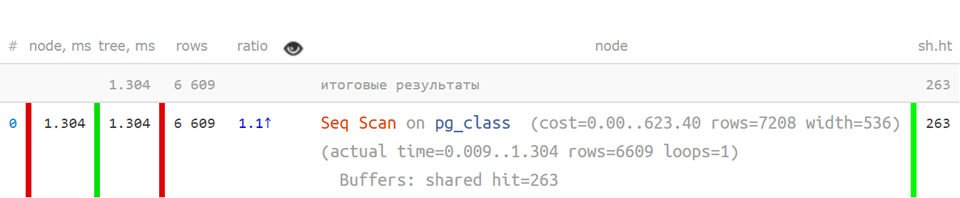
Но вот так, в сокращенном виде, когда ключевые показатели отделены — уже гораздо понятнее:
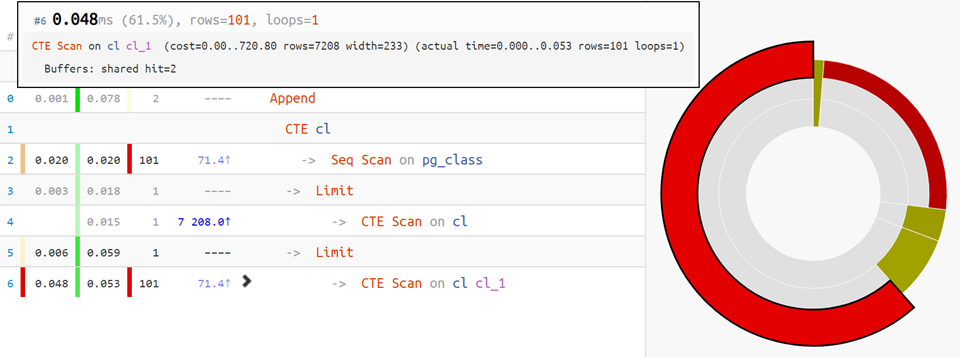
Но если план посложнее — на помощь придет piechart распределения времени по узлам:
Ну, а для самых сложных вариантов на помощь спешит диаграмма выполнения:
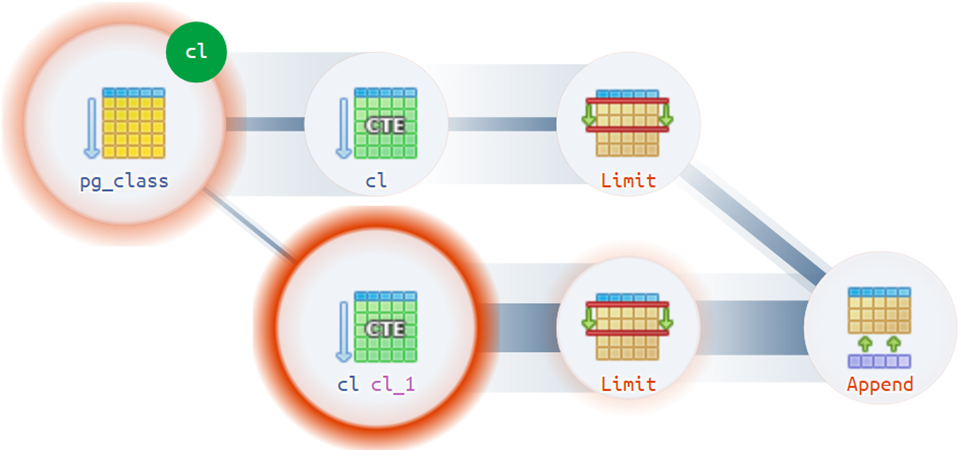
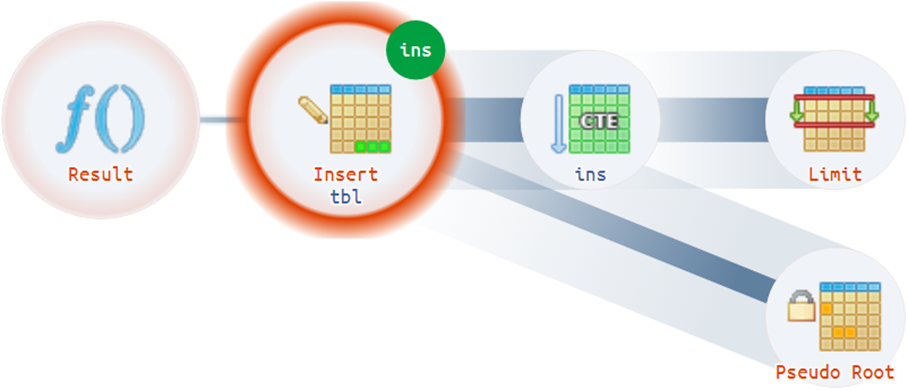
Например, бывают достаточно нетривиальные ситуации, когда план может иметь больше одного фактического корня:
Ну, а если вся структура плана и его больные места уже разложены и видны — почему бы не подсветить их разработчику, и не объяснить «русским языком»?
 Таких шаблонов рекомендаций мы собрали уже пару десятков.
Таких шаблонов рекомендаций мы собрали уже пару десятков.
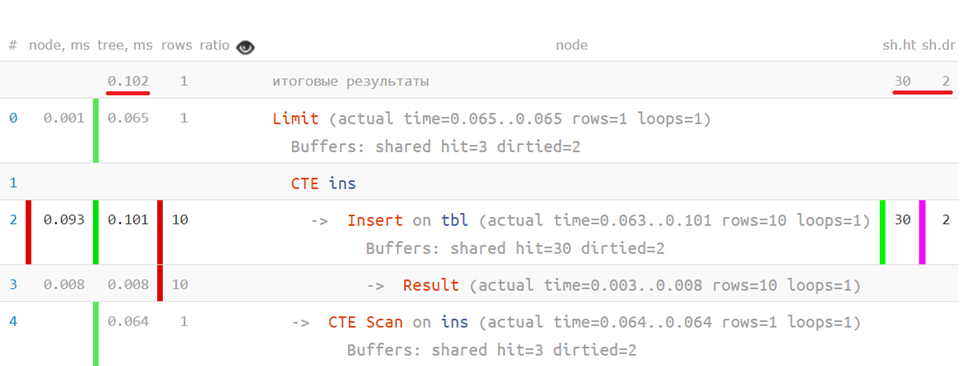
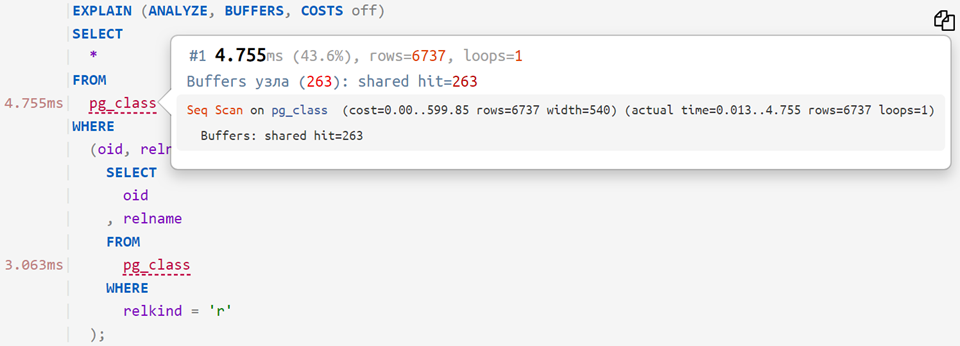
Теперь, если на анализируемый план наложить исходный запрос, то можно увидеть, сколько времени ушло на каждый отдельный оператор — примерно вот так:
… или даже так:

Если вы «прицепили» к плану не только запрос, но и его параметры из DETAIL-строки лога, то сможете скопировать его дополнительно в одном из вариантов:
Вставляйте, анализируйте, делитесь с коллегами! Планы останутся в архиве, и вы сможете вернуться к ним позднее: explain.tensor.ru/archive
Но если не хотите, чтобы ваш план увидели другие, не забудьте поставить галочку «не публиковать в архиве».
В следующих статьях я расскажу о тех сложностях и решениях, которые возникают при анализе плана.
Традиционный набор причин:
- неэффективный алгоритм
когда вы решили сделать JOIN нескольких CTE по паре десятков тысяч записей - неактуальная статистика
если фактическое распределение данных в таблице уже сильно отличается от собранной ANALYZE'ом в последний раз - «затык» по ресурсам
и уже не хватает выделенных вычислительных мощностей CPU, постоянно прокачиваются гигабайты памяти или диск не успевает за всеми «хотелками» БД - блокировки от конкурирующих процессов
И если блокировки достаточно сложны в поимке и анализе, то для всего остального нам достаточно плана запроса, который можно получить с помощью оператора EXPLAIN (лучше, конечно, сразу EXPLAIN (ANALYZE, BUFFERS) ...) или модуля auto_explain.
Но, как сказано в той же документации,
«Понимание плана — это искусство, и чтобы овладеть им, нужен определённый опыт, …»Но можно обойтись и без него, если воспользоваться подходящим инструментом!
Как обычно выглядит план запроса? Как-то вот так:
Index Scan using pg_class_relname_nsp_index on pg_class (actual time=0.049..0.050 rows=1 loops=1) Index Cond: (relname = $1) Filter: (oid = $0) Buffers: shared hit=4 InitPlan 1 (returns $0,$1) -> Limit (actual time=0.019..0.020 rows=1 loops=1) Buffers: shared hit=1 -> Seq Scan on pg_class pg_class_1 (actual time=0.015..0.015 rows=1 loops=1) Filter: (relkind = 'r'::"char") Rows Removed by Filter: 5 Buffers: shared hit=1
или вот так:
"Append (cost=868.60..878.95 rows=2 width=233) (actual time=0.024..0.144 rows=2 loops=1)" " Buffers: shared hit=3" " CTE cl" " -> Seq Scan on pg_class (cost=0.00..868.60 rows=9972 width=537) (actual time=0.016..0.042 rows=101 loops=1)" " Buffers: shared hit=3" " -> Limit (cost=0.00..0.10 rows=1 width=233) (actual time=0.023..0.024 rows=1 loops=1)" " Buffers: shared hit=1" " -> CTE Scan on cl (cost=0.00..997.20 rows=9972 width=233) (actual time=0.021..0.021 rows=1 loops=1)" " Buffers: shared hit=1" " -> Limit (cost=10.00..10.10 rows=1 width=233) (actual time=0.117..0.118 rows=1 loops=1)" " Buffers: shared hit=2" " -> CTE Scan on cl cl_1 (cost=0.00..997.20 rows=9972 width=233) (actual time=0.001..0.104 rows=101 loops=1)" " Buffers: shared hit=2" "Planning Time: 0.634 ms" "Execution Time: 0.248 ms"
Но читать план текстом «с листа» — очень сложно и ненаглядно:
- в узле выводится сумма по ресурсам поддерева
то есть чтобы понять, сколько ушло времени на выполнение конкретного узла, или сколько именно вот это чтение из таблицы подняло данных с диска — нужно как-то вычитать одно из другого - время узла необходимо умножать на loops
да, вычитание еще не самая сложная операция, которую надо делать «в уме» — ведь время выполнения указывается усредненное для одного выполнения узла, а их могут быть сотни - ну, и все это вместе мешает ответить на главный вопрос — так кто же «самое слабое звено»?
Когда мы попытались объяснить все это нескольким сотням наших разработчиков, то поняли, что со стороны это выглядит примерно вот так:
А, значит, нам нужен…
Инструмент
В нем мы постарались собрать все ключевые механики, которые помогают по плану и запросу понять, «кто виноват и что делать». Ну, и частью своего опыта поделиться с сообществом.
Встречайте и пользуйтесь — explain.tensor.ru
Наглядность планов
Легко ли понять план, когда он выглядит так?
Seq Scan on pg_class (actual time=0.009..1.304 rows=6609 loops=1) Buffers: shared hit=263 Planning Time: 0.108 ms Execution Time: 1.800 ms
Не очень.
Но вот так, в сокращенном виде, когда ключевые показатели отделены — уже гораздо понятнее:
Но если план посложнее — на помощь придет piechart распределения времени по узлам:
Ну, а для самых сложных вариантов на помощь спешит диаграмма выполнения:
Например, бывают достаточно нетривиальные ситуации, когда план может иметь больше одного фактического корня:
Структурные подсказки
Ну, а если вся структура плана и его больные места уже разложены и видны — почему бы не подсветить их разработчику, и не объяснить «русским языком»?
Таких шаблонов рекомендаций мы собрали уже пару десятков.Построчный профайлер запроса
Теперь, если на анализируемый план наложить исходный запрос, то можно увидеть, сколько времени ушло на каждый отдельный оператор — примерно вот так:
… или даже так:
Подстановка параметров в запрос
Если вы «прицепили» к плану не только запрос, но и его параметры из DETAIL-строки лога, то сможете скопировать его дополнительно в одном из вариантов:
- с подстановкой значений в запрос
для непосредственного выполнения на своей базе и дальнейшей профилировки
SELECT 'const', 'param'::text; - с подстановкой значений через PREPARE/EXECUTE
для эмуляции работы планировщика, когда параметрическая часть может быть проигнорирована — например, при работе на секционированных таблицах
DEALLOCATE ALL; PREPARE q(text) AS SELECT 'const', $1::text; EXECUTE q('param'::text);
Архив планов
Вставляйте, анализируйте, делитесь с коллегами! Планы останутся в архиве, и вы сможете вернуться к ним позднее: explain.tensor.ru/archive
Но если не хотите, чтобы ваш план увидели другие, не забудьте поставить галочку «не публиковать в архиве».
В следующих статьях я расскажу о тех сложностях и решениях, которые возникают при анализе плана.

