
Хабр Курсы для всех
РЕКЛАМА
Практикум, Хекслет, SkyPro, авторские курсы — собрали всех и попросили скидки. Осталось выбрать!
Не знал про секунду координации, спасибо. Но тестовое смотреть не стал. Написали бы проверяющим, попросив развернутый ответ, добавив пару абзацев о вашем решении, раз вышло такое недопонимание.
Написал и даже позвонил. Просил соединить с тем, кто непосредственно проверял задание. Получил ответ «ни я , ни кто-то другой Вам ничего не обязаны объяснять.»
Попробую немного побыть адвокатом дьявола поскольку имею некий опыт этого дела "с другой стороны".
Так часто бывает что тестовые делают много людей. Потом HR берёт всё эту "пачку" с решениями и пихает тимлиду/сениору чтобы он разбирался. Тимлид просматривает всё это дело и сначала просто отсеивает всё что ему кажется в принципе "бесперспективным". Часто это подавляющее большинство примеров. Писать детальный ответ с разбором ошибок по каждому такому "бесперспективному" случаю у него нет ни желания, ни в общем-то и времени.
П.С. Далеко не все фирмы имеют такое количество кандидатов и могут себе такое позволить. Но и не так что это огромное исключение.
П.П.С. Писать кандидату в ответ «задание Вы выполнили действительно отвратительно, халтурно» и «ни я, ни кто-то другой Вам ничего не обязаны объяснять» это в любом случае хамство. И я лично не особо бы расстраивался если бы не попал работать в такую фирму.
П.П.П.С. Я лично тестовые не люблю и стараюсь их избегать. С обеих сторон. Особенно такие вот "домашки". Максимум тестовое на месте и в виде диалога с проверяющим.
Небольшое имхо
Если компания просит кандидата потратить свое время за бесплатно, то пусть постарается дать комментарий о проделанной работе. Баш на баш.
Миллион тестовых заданий от кандидатов и нет времени отвечать? - значит эффективность предварительных собеседований - нулевая. Работодатель жжет впустую время свое и время кандидатов.
У меня на конторе я даю тестовое если кандидат уже плавает, топовых людей мы берём сразу. А эти игры уде после собеседования для джунов и мидлов, это шанс проверить способен ли человек вообще код писать (вы не поверите, но многие этого не умеют в принципе).
Ну на вашем месте я бы радовался что не попал в этой компанию. Не думаю, что отношение к работникам там сильно лучше отношения к соискателями.
Ошибаются. Обязаны в течение 7 дней дать письменный ответ о причинах отказа, если вы об этом потребовали. Другой вопрос, точно ли вы хотите с такими людьми как-то дальше общаться? Может быть, и к лучшему, что вам отказали.
(Пояснения: https://rg.ru/2015/08/04/rabota.html)
"Неудовлетворительное выполнение тестового задания"
А такое понятие, как тестовое задание, есть в законодательстве РФ? Им действительно придется что-то выдумывать.
PS Автору, да и всем остальным, бы посоветовал выкладывать названия компаний, хотя бы, публикация персональных данных законом вроде как регулируются, но и это можно написать завуалированно. Ибо когда в стране нет института репутации от слова совсем, то и возникают такие чудаки, и им надо помочь сформировать "правильную" репутацию.
Похоже на анекдот про "неудачники нам не нужны"
Ну, начнём с того, что комментарии - кракозябрами...
Я не считаю себя специалистом, но лично меня пугает вложенность if'ов. Да и как-то не по ООПшному это все выглядит.
Спасибо за мнение. Обычно так и происходит при оптимизации на низком уровне: чем больше оптимизировано, тем более «не по ООПшному это все выглядит».
Помимо того чтобы множественные if в один if с and/or собирать
Частым вариантом решения слишком глубокой вложенности является Guard Clause
https://betterprogramming.pub/refactoring-guard-clauses-2ceeaa1a9da
На мой взгляд, самая большая проблема вашего кода, это то, что вы итерационно вычисляете возвращаемое значение, а его нужно конструировать. Ведь у вас есть абсолютно вся информация о возвращаемом значении, тем не менее, вы маленькими шагами подбираетесь к нему "сбоку".
Попробуйте сгенерить ответ только из миллисекунд, без итераций, получив его одним блоком кода, без циклов. Потом попробуйте добавить к ответу секунды и т. д., может быть, в финале получится сконструировать весь ответ целиком. Для проверки добавьте к задачке микросекунды - должен добавиться еще один блок кода, без еще одного вложенного if'а.
Доли секунды — это единственный компонент, который можно сразу вычислить. А дальше надо учитывать тонкости календаря, поэтому используются итерации. Ведь при любом изменении (даже на секунду) могут поменять все компоненты даты вплоть до года. Конечно, можно написать по-другому. Думаю дальше надо сравнивать уже готовые реализации.
internal readonly byte[] _seconds = new byte[60];
internal readonly byte[] _milliseconds = new byte[1000];
Мы имеем дело с объектом «расписание», которое задано понятной для человека строкой. Отсюда мы можем вполне уверенно сделать вывод, что в памяти не будет одновременно много тысяч расписаний. Память выделяется для традиционной техники оптимизации: заранее рассчитанных таблиц чтобы сэкономить на вычислениях позже. Выделение лишних 1300 байт на такой высокоуровневый объект, я считаю, это просто в пределах погрешности и ни на что не влияет. При дальнейшей оптимизации байты легко превратить в биты (там везде хранится 0 или 1) и уменьшить размер ещё в 8 раз.
Выделение лишних 1300 байт на такой высокоуровневый объект, я считаю, это просто в пределах погрешности и ни на что не влияет.В общем стоит пояснять такие моменты, т.к. непонятно почему кто-то выделил дополнительную память(либо для оптимизаций, либо по не знанию).У вас странный подход к оптимизации. С одной стороны пишите, что много расписаний не будет, и 1300 байт на один объект это не страшно и при этом в конструкторе же делаете свой "быстрый" велосипед даже для парсинга строки в число. Это вещи совершенно разного порядка. Если код используется так часто, что свой парсинг чисел вообще имеет смысл, то выделенние 1300 байт это точно не "в пределах погрешности".
В данном конкретном случае я бы предположил, что скорость работы конструктора вообще не важна и смысла отказываться от регулярных выражений небыло, а основное быстродействие требуется от NearestEvent и NearestPrevEvent.
в конструкторе же делаете свой "быстрый" велосипед даже для парсинга строки в число...
смысла отказываться от регулярных выражений небыло
Я, как на образец, всегда смотрю в исходный код самого .Net. Там регулярки используются только в очень высокоуровневом коде типа UI или СУБД. Примеры где парсинг делается также, как у меня (ищите в них '0' или * 10):
Кое где они напрямую пишут что хотели реализацию без регулярок.
Согласен в Вами. Народ, какие регэкспы, вы чо с ума посходили? Я думаю, что внутри DateTime.Parse даже Int32.Parse не используется. В данном случае я бы и String.IndexOf не стал применять.
Просто пробегаем по всей строке от начала до конца. Ну, пару раз пришлось бы заглянуть вперед. Это и есть нормальная стандартная практика парзинга чего-либо, особенно маленьких строк.
Можно, конечно, разбивать строку на токены, но в данном случае это овекил.
Ну да:
https://referencesource.microsoft.com/#mscorlib/system/globalization/datetimeparse.cs
(правда, это .Net Framework 4.8, но в .Net 5.0 ситуация аналогичная)
Всего 5000 строчек, и это не считая тестов. Если учесть, что в среднем разработчик пишет около 100 строк кода в день, то получается, что написание этого парсера требует 2 месяцев работы разработчика.
Хотите я вам парзинг того, что нужно в этой статье за час напишу? Только на Delphi (не люблю C#).
Не используя утилит из стандартной библиотеки языка вообще. И не создавая дополнительных объектов в куче (в отличие от регэксп и всяких там String.Split).
пишите
Чисто парзинг, без всего остального:
https://www.file.io/download/4hZfwBRjjCRn
150 строчек вместе с объявлением класса. Даже короче чем у автора статьи. А на C# еще короче получится.
type
TScheduleParser = class
private
function LookAheadOfList(C: PChar): Char;
procedure ParseList(var C: PChar);
procedure ParseListItem(var C: PChar);
procedure ParseNumber(var C: PChar; var N: Integer);
procedure Skip(var C: PChar); overload;
procedure Skip(var C: PChar; ARequired: Char); overload;
procedure SyntaxError;
public
procedure Parse(const S: string);
end;
function TScheduleParser.LookAheadOfList(C: PChar): Char;
begin
while C^ in ['*', ',', '-', '/', '0'..'9'] do
Inc(C^);
Result := C^;
end;
procedure TScheduleParser.Parse(const S: string);
var
c: PChar;
begin
if S = '' then
SyntaxError;
c := Pointer(S);
if LookAheadOfList(c) = '.' then // Date.
begin
ParseList(c);
Skip(c, '.');
ParseList(c);
Skip(c, '.');
ParseList(c);
Skip(c, ' ');
if LookAheadOfList(c) = ' ' then // Week day.
begin
ParseList(c);
Skip(c, ' ');
end;
end;
ParseList(c); // Time.
Skip(c, ':'); //
ParseList(c); //
Skip(c, ':'); //
ParseList(c); //
if c^ = '.' then // Milliseconds.
begin
Skip(c);
ParseList(c);
end;
Skip(c, #0); // Check the end of the string.
end;
procedure TScheduleParser.ParseNumber(var C: PChar; var N: Integer);
var
dgt: Boolean;
begin
dgt := False;
N := 0;
while C^ in ['0'..'9'] do
begin
N := N * 10 + Ord(C^) - Ord('0');
dgt := True;
Inc(C);
end;
if not dgt then
SyntaxError;
end;
procedure TScheduleParser.ParseList(var C: PChar);
begin
ParseListItem(C);
while C^ = ',' do
begin
Skip(C);
ParseListItem(C);
end;
end;
procedure TScheduleParser.ParseListItem(var C: PChar);
var
rng: Boolean;
dummy: Integer;
begin
if C^ = '*' then // Range.
begin
Skip(C);
rng := True;
end
else
begin
ParseNumber(c, dummy);
if C^ = '-' then // Range.
begin
Skip(C);
ParseNumber(c, dummy);
rng := True;
end
else
rng := False;
end;
if rng and (C^ = '/') then // Range step.
begin
Skip(C);
ParseNumber(C, dummy);
end;
end;
procedure TScheduleParser.Skip(var C: PChar; ARequired: Char);
begin
if C^ <> ARequired then
SyntaxError;
Inc(C);
end;
procedure TScheduleParser.Skip(var C: PChar);
begin
Inc(C);
end;
procedure TScheduleParser.SyntaxError;
begin
raise Exception.Create('Syntax error in schedule string');
end;
Теперь давайте представим, как бы это выглядело на String.Split() и Int.Parse(). Следите за руками:
1) Сплиттим по пробелу - получаем максимум три части.
2) Сплиттим дату по точке.
3) Сплиттим время по двоеточию.
4) Сплиттим секунды+миллисекунды по точке.
5) Получили восемь списков. Каждый из них сплиттим по запятой. Получаем диапазоны.
6) Диапазоны сплиттим по символу '/', а потом еще раз по символу '-'.
7) Ну и наконец используем Int.Parse для всех чисел.
А теперь возьмем, например, строку: "2021.07.07 06 12:01.01.333".
Давайте посчитаем для нее количество операций. Получится, если я не ошибаюсь, двадцать восемь сплиттов, которые создают шестьдесят два объекта (строки и массивы) в куче.
Это ли не шизофрения!
И я более чем уверен, что если вы все это напишете на C#, получится громоздкий и не читаемых код, по сравнению с моим, который к тому же еще и более гибкий (на случай изменения формата в будущем), не говоря уже про то, что несравнимо более производительный.
150 строчек вместе с объявлением класса. Даже короче чем у автора статьи.
шестьдесят два объекта (строки и массивы) в куче
ParseNumber(c, dummy);
if C^ = '*' then Skip(C);
Теперь давайте представим, как бы это выглядело на String.Split() и Int.Parse()
получится громоздкий и не читаемых код, по сравнению с моим
<?php
function parse(string $str)
{
$parts = explode(' ', $str);
$recordParts = [];
if (count($parts) === 1) { // hh:mm:ss
$timeParts = explode(':', $parts[0]);
$recordParts = array_merge(['*', '*', '*', '*'], $timeParts);
} else if (count($parts) === 2) { // yyyy.MM.dd hh:mm:ss
$dateParts = explode('.', $parts[0]);
$timeParts = explode(':', $parts[1]);
$recordParts = array_merge($dateParts, ['*'], $timeParts);
} elseif (count($parts) === 3) { // yyyy.MM.dd w hh:mm:ss
$dateParts = explode('.', $parts[0]);
$weekParts = [$parts[1]];
$timeParts = explode(':', $parts[2]);
$recordParts = array_merge($dateParts, $weekParts, $timeParts);
} else {
throw new Exception('Incorrect format');
}
$secondParts = explode('.', $recordParts[6]); // .fff
$recordParts[6] = $secondParts[0];
$recordParts[7] = $secondParts[1] ?? '*';
$resultParts = [];
foreach ($recordParts as $recordPart) {
$listElements = explode(',', $recordPart);
$resultPart = [];
foreach ($listElements as $listElement) {
$rangeElements = explode('/', $listElement);
$rangeElements[0] = explode('-', $rangeElements[0]);
$resultPart[] = $rangeElements;
}
$resultParts[] = $resultPart;
}
return $resultParts;
}
ini_set('xdebug.var_display_max_depth', 10);
var_export(parse('*/2.9.1-10/3 2,4 11:22:33.444-446'));
</php>
</spoiler>Ладно, ладно, количество строчек сравнивать некорректно. Ваш код еще посмотрю, хотя я PHP не знаю. Но, я же в целом отвечал тем, кто предлагает String.Split() использовать и регэкспы.
Вы не полностью проверяете синтаксис:
В начале Вы проверили, что частей должно быть от одной до трех. А дальше? Там еще много explode() и ни одной проверки к ним.
Вы не парзите числа. То есть, там, между разделителями, можно написать все что угодно.
Звездочку вместо числа тоже не проверяете. А между тем, звездочка сама по себе означает диапазон, и после нее второго числа через тире уже быть не может.
Может еще чего не заметил. Но, в том то и фишка - в методе на сплитах нужно задолбаться с проверками после каждого шага и нигде их не забыть. А у меня само собой все работает, ну почти :).
Вы не парзите числа.
Конечно, там же может быть звездочка, а не число.
в методе на сплитах нужно задолбаться с проверками после каждого шага и нигде их не забыть
Проверки там нужны ровно те же, что и в любом другом методе.
А дальше? Там еще много explode() и ни одной проверки к ним.
Потому что там нужны еще и другие проверки, которые при парсинге сделать нельзя, и они будут делаться потом — дни недели от 0 до 6, дни месяца не больше 32, и т.д. У вас их тоже нет. При том, что '' это одно из валидных значений, преобразовывать в int при парсинге, чтобы потом проверять только числа, нельзя. Либо надо передавать разрешенный для этой части диапазон и заменять '' на него. Я поэтому и написал, что код у вас неполный, а полный будет выглядеть по-другому.
При том, что '' это одно из валидных значенийИмелось в виду '*'.
Давайте так, у меня нет проверки диапазона допустимых значений просто потому, что это традиционно считается не частью синтаксиса, а частью семантики. Во всех остальных случаях мой код весь синтаксис проверяет, и если строка будет неправильной, он ругнется. Проверку допустимых значений могу добавить, если очень хочется.
Ваш же код не проверяет огромное количество случаев. Я уже привел примеры. Вот Вы пишете про то, что вместо числа может быть звездочка. Ну и что? Согласно Вашему коду там вообще все что угодно можно написать вместо числа, например буквы и ничего не случится.
Время можно написать, например так: 12:AB:CD:XY:SD и ошибки Ваш код не выдаст.
А можно написать диапазон вот так: *-10/3, что неправильно, т.к. после звездочки не может быть тире.
А можно даже так: 3-10/3/4/5/6/7 и Ваш код не ругнется.
Честно признаться, там и половины нет тех проверок, которые должны быть.
Согласно Вашему коду там вообще все что угодно можно написать вместо числа, например буквы и ничего не случится.
Я и говорю, семантика символов проверяется потом. У вас ее нет, поэтому и у меня нет. Сейчас там есть звездочка, потом вместо 32 решат сделать last или L. Сначала разбиваем на токены, потом конвертируем, если для токена это требуется.
Количество и последовательность частей в выражении формально это часть парсера, но можно проверить и вместе с семантикой. У меня нет проверок, у вас нет результата. Я в общем-то об этом и говорю, надо сравнивать рабочий код, а не отдельные части, которые кому-то кажутся достаточными для демонстрации.
Ну хорошо, пусть Ваш код делает то, что делает. Я бы ЭТО вообще никогда не назвал парзером, так как он тупо не проверят синтаксис.
У меня нет проверок, у вас нет результата
У Вас тоже нет результата. Т.к. то что ваш код формирует, это жесть, а не результат.
Есть. Этот результат можно использовать в дальнейшей программной обработке. Можно даже строковые ключи сделать для наглядности.
Я отвечал на ваше утверждение, что код будет громоздкий и нечитаемый. Это не так. Даже со всеми нужными проверками у меня получилось 60 строк кода.
Этот результат можно использовать в дальнейшей программной обработке
С таким подходом можно вообще входную строку вернуть как есть, ничего не делая, и заявить, что это результат и его можно дальше программно обрабатывать.
Можно даже строковые ключи сделать для наглядности.
Нельзя, так как вы даже не знаете из скольких частей у вас состоит дата, а также время.
Даже со всеми нужными проверками у меня получилось 60 строк кода.
Для начала покажите код "со всеми нужными проверками".
Пожалуйста. 62 строки, со вспомогательной функцией 69. Есть все проверки, которые есть у вас, возвращается готовое к использованию AST, также добавил строковые ключи и преобразование в int.
<?php
function parse(string $str)
{
$parts = explode(' ', $str);
ensureTrue(count($parts) >= 1 && count($parts) <= 3);
if (count($parts) === 1) { // hh:mm:ss
$dateParts = ['*', '*', '*'];
$weekParts = ['*'];
$timeParts = explode(':', $parts[0]);
} elseif (count($parts) === 2) { // yyyy.MM.dd hh:mm:ss
$dateParts = explode('.', $parts[0]);
$weekParts = ['week' => '*'];
$timeParts = explode(':', $parts[1]);
} elseif (count($parts) === 3) { // yyyy.MM.dd w hh:mm:ss
$dateParts = explode('.', $parts[0]);
$weekParts = [$parts[1]];
$timeParts = explode(':', $parts[2]);
}
ensureTrue(count($dateParts) === 3 && count($weekParts) === 1 && count($timeParts) === 3);
$secondParts = explode('.', $timeParts[2]); // .fff
ensureTrue(count($secondParts) === 1 || count($secondParts) === 2);
$timeParts[2] = $secondParts[0];
$timeParts[3] = $secondParts[1] ?? '*';
$keys = ['year', 'month', 'day', 'week', 'hour', 'minute', 'second', 'millisecond'];
$recordParts = array_combine($keys, array_merge($dateParts, $weekParts, $timeParts));
$resultParts = [];
foreach ($recordParts as $key => $recordPart) {
$listElements = explode(',', $recordPart);
$resultPart = [];
$value = ['start' => null, 'stop' => null, 'step' => null];
foreach ($listElements as $listElement) {
$valueElements = explode('/', $listElement);
ensureTrue(count($valueElements) === 1 || count($valueElements) === 2);
if (count($valueElements) === 2) {
ensureTrue(is_numeric($valueElements[1]));
$value['step'] = (int) $valueElements[1];
}
$value['start'] = $valueElements[0];
if ($value['start'] !== '*') {
$range = explode('-', $value['start']);
ensureTrue((count($range) === 1 || count($range) === 2) && is_numeric($range[0]));
$value['start'] = (int) $range[0];
if (count($range) === 2) {
ensureTrue(is_numeric($range[1]));
$value['stop'] = (int) $range[1];
}
}
$resultPart[] = $value;
}
$resultParts[$key] = $resultPart;
}
return $resultParts;
}
function ensureTrue(bool $condition)
{
if (!$condition) {
throw new Exception('Incorrect format');
}
}
echo json_encode(parse('*/2.9.1-10/3 2,4 11:22:33.444-446'), JSON_PRETTY_PRINT);Ну да. Похоже на дело. НО, лично для меня этот код запутанный и непонятный. Может потому, что все в одном большом методе. Еще есть дублирование кода, например:
$timeParts = explode(':', $parts[0]);
...
$timeParts = explode(':', $parts[1]);
...
$timeParts = explode(':', $parts[2]);А так, в целом на PHP получается короче, чем на Delphi, признаю.
Окей, вот решение на C# со сппитами: https://gist.github.com/vlova/27c1eecdc17c139e33db6e2d78dcea2d
В отличие от вашего решения — работает не вхолостую, а возвращает реальный результат. (Это, кстати, само по себе показатель, почему ваше решение никогда в продакшен не пойдет — потому что его никто не пишет)
В отличие от вашего решения — есть валидация ренджей. И т.д., и т.п.
Нечитабельно? Да вроде как читабельно и даже симпатично
Да, не такой гибкий. Однако и ваше решение при расширении формата рано или поздно упрется в необходимость быть переписанным, потому что нет токенизации
Да, создает объекты в куче. Вообще по барабану, у C# нормальный сборщик мусора, объекты попадут в Gen0 и соберутся даже раньше, чем метод закончит работу
Медленнее? Да наверняка. Но надо бенчить насколько это медленнее. И скорее всего это не критично, потому что этот метод не будет вызываться часто.
Возвращать результат нужно в каком-то определенном виде. Поскольку этот вид зависит от дальнейшего использования (от алгоритма поиска), а мы вроде как говорим про парзинг, я решил формирование результата опустить.
Валидацию ренджей легко добавить, это почти не увеличит размер кода. Хотя строчки я ну так, примерно, посчитал. Просто чтобы показать что такой низкоуровневый код не будет очень уж сильно больше. Т.е. не будет, например, 1000 строчек.
Что за "и т.д., и т.п." - мне непонятно. Код корректный.
Код действительно будет не очень большой, сравнимо по количеству строк — здесь довольно ясно.
Результат важен хотя-бы по той простой причине, что при его формировании вы начнете создавать объекты. Ваша риторика про шизофрению серьезно посыпется. Она и так сыпется, если догадаться, что можно написать собственный Split, который будет возвращать структуры (например, ReadOnlySpan), а не объекты. Просто решение со Split будет top-bottom, а ваше решение — bottom-top. (Хотя split действительно не так устойчив к изменению формата)
Особенность вашего кода — максимально полная императивность. С формированием результата это было бы забавно. Метод ParseListItem двигает нас по строке, и при этом возвращает данные. Это нарушает CQS и приводит к неустойчивому коду. А сейчас это не так заметно.
Результат возвращать важно, потому что половина говнокода — это формирование результата. Туда же отправляется валидация ренджей. Или, например, логика, что если миллисекунды не указаны, то надо заполнить массивом [0], а если годы не указаны, то надо массивом [2000-2100]
Я не очень понимаю, как вы узнаете, что код корректный. Ведь у вас не формируется результат, который можно проверить. Не самонадеянно ли?
Результат возвращать важно, потому что половина говнокода — это формирование результата.
Ну я упирал на токенизацию, потому что это один из способов повысить внятность кода. Да, вот сейчас @balabuev показал, что симпатично можно даже без токенизации.
Уговорили, вот вам код с минималистичным формированием результата. С проверкой диапазонов.
Раз уж вы про CQS упоминаете, то позволю себе просто возвращать диапазоны колбэком. Так как не парзера это дело, всякие битовые массивы для поиска заполнять.
type
TPart = (pYear, pMonth, pDay, pWeek, pHour, pMinute, pSecond,
pMillisec);
TAddItem = procedure(APart: TPart; AMin, AMax, AStep: Integer) of object;
TScheduleParser = class
private
FCurrent: PChar;
FResult: TAddItem;
function LookAheadOfList: Char;
procedure ParseList(APart: TPart);
procedure ParseListItem(APart: TPart);
procedure ParseNumber(var N: Integer);
procedure Skip; overload;
procedure Skip(ARequired: Char); overload;
procedure SyntaxError;
procedure AddItem(APart: TPart; AMin, AMax, AStep: Integer);
public
procedure Parse(const S: string; const AResult: TAddItem);
end;
procedure TScheduleParser.AddItem(APart: TPart; AMin, AMax, AStep: Integer);
type
TPartBounds = record
Min, Max, DefMax: Integer;
end;
const
PART_BOUNDS: array[TPart] of TPartBounds = (
(Min: 2000; Max: 2100; DefMax: 2100), // pYear
(Min: 1; Max: 12; DefMax: 12), // pMonth
(Min: 1; Max: 32; DefMax: 31), // pDay
(Min: 0; Max: 6; DefMax: 6), // pWeek
(Min: 0; Max: 23; DefMax: 23), // pHour
(Min: 0; Max: 59; DefMax: 59), // pMinute
(Min: 0; Max: 59; DefMax: 59), // pSecond
(Min: 0; Max: 999; DefMax: 999) // pMillisec
);
begin
if AMin = -1 then
begin
AMin := PART_BOUNDS[APart].Min; // '*'
AMax := PART_BOUNDS[APart].DefMax; //
end
else
begin
if AMin < PART_BOUNDS[APart].Min then
SyntaxError;
if AMax = -1 then
AMax := AMin
else if AMax > PART_BOUNDS[APart].Max then
SyntaxError;
end;
if AStep <= 0 then
SyntaxError;
if Assigned(FResult) then
FResult(APart, AMin, AMax, AStep);
end;
function TScheduleParser.LookAheadOfList: Char;
var
c: PChar;
begin
c := Self.FCurrent;
while c^ in ['*', ',', '-', '/', '0'..'9'] do
Inc(c);
Result := c^;
end;
procedure TScheduleParser.Parse(const S: string; const AResult: TAddItem);
begin
if S = '' then
SyntaxError;
FCurrent := Pointer(S);
FResult := AResult;
if LookAheadOfList = '.' then // Date.
begin
ParseList(pYear);
Skip('.');
ParseList(pMonth);
Skip('.');
ParseList(pDay);
Skip(' ');
if LookAheadOfList = ' ' then // Week day.
begin
ParseList(pWeek);
Skip(' ');
end;
end;
ParseList(pHour); // Time.
Skip(':'); //
ParseList(pMinute); //
Skip(':'); //
ParseList(pSecond); //
if FCurrent^ = '.' then // Milliseconds.
begin
Skip;
ParseList(pMillisec);
end;
Skip(#0); // Check the end of the string.
end;
procedure TScheduleParser.ParseNumber(var N: Integer);
var
dgt: Boolean;
begin
dgt := False;
N := 0;
while FCurrent^ in ['0'..'9'] do
begin
N := N * 10 + Ord(FCurrent^) - Ord('0');
dgt := True;
Skip;
end;
if not dgt then
SyntaxError;
end;
procedure TScheduleParser.ParseList(APart: TPart);
begin
ParseListItem(APart);
while FCurrent^ = ',' do
begin
Skip;
ParseListItem(APart);
end;
end;
procedure TScheduleParser.ParseListItem(APart: TPart);
var
rng: Boolean;
min, max, stp: Integer;
begin
min := -1; // Full range '*'
max := -1; //
stp := 1; //
if FCurrent^ = '*' then // Range.
begin
Skip;
rng := True;
end
else
begin
ParseNumber(min);
if FCurrent^ = '-' then // Range.
begin
Skip;
ParseNumber(max);
rng := True;
end
else
rng := False;
end;
if rng and (FCurrent^ = '/') then // Range step.
begin
Skip;
ParseNumber(stp);
end;
AddItem(APart, min, max, stp);
end;
procedure TScheduleParser.Skip(ARequired: Char);
begin
if FCurrent^ <> ARequired then
SyntaxError;
Inc(FCurrent);
end;
procedure TScheduleParser.Skip;
begin
Inc(FCurrent);
end;
procedure TScheduleParser.SyntaxError;
begin
raise Exception.Create('Syntax error in schedule string');
end;не сишник, да и вникать времени нет. Но, на первый взгляд, удивили ifы (как и предыдущего комментатора).
Почему бы не выложить решение на подраздел stackoverflow - codereview? Тот ресурс выглядит более подходящим, да и пользы больше будет.
Честно говоря, тестовое задание ни о чем. Видимо ищут джуна, чтобы валить на него косяки и пенать его без повода, вы не подошли, не расстраивайтесь.
В логику пока сильно не вникал.
Но вложенность 8-10 это реально печально, ни одного приватного метода. Ничего не разбито.
Возможно решение и оптимально по времени, но это не продакшен код. Такое подходит для решения олимпиадных задач, где код нужен что бы пройти тесты, но никак не для долгой жизни и поддержки на реальном проекте.
Спасибо за оценку. Я бы легко мог увеличить показатель удобства поддержки или, наоборот, улучшить оптимизацию по времени. Но в поставленной задаче не были указаны такие требования. Я нашёл некоторый компромисс с возможностью двигаться в любом направлении.
Мое мнение, что в большинстве случаев компании дают тестовые задания что бы оценить как кандидат пишет код и понимать чего от него ожидать. И тестовое задание надо делать так, как делал бы такую задачу на реальном проекте.
Читабельность и структурированность в таком случае не должны быть отдельным требованием.
Но Вам, в любом случае, плюс за то что не просто забили на это, а решили разобраться.
Для меня лично, главный показатель хорошего кода, этот как раз его поддерживаемость. Сейчас из-за кучи if, отсутсвия хоть какого-то разделения на методы очень трудно читать код. И я бы понял, если ваше задание даже не стали смотреть. Когда-то писал подобную штуку и даже спустя 10 лет могу хоть какт-то понять что там происходит.
Если вы всерьёз решили повыделываться, ведь DateTime и другие стандартные приёмы для слабоков :) , то стоило уж выделываться основательно и грамотно оформить код в методы, а не запихивать устрашающие многоэтажные if'ы в конструктор. А так вышло ни то ни сё - горе от ума.
У меня даже возникло ощущение, что вся эта история и ваше решение похожи на тонкий стёб: хотели супер-пупер оптимальное решение - получите! Только зацените, какой перед вами мастер психологической обфускации кода. Вы это хотели продемонстирировать? ;))
if (scheduleString == null), а еслиscheduleString == ""?
Согласен, "из коробки" же доступен более универсальный IsNullOrEmpty(String)
Мягко говоря, странное утверждение. Я знаю людей, которые любят писать что-то вроде IEnumerable<LayoutItem<Box>> вместо простого var, но у нас есть codereview, который такое не пропускает.
Довольно спорный момент. Неплохой компромисс, когда пишешь var там, где явно виден тип и пишешь тип, там, где он явно не виден, например, результат вызова функции
Вообще МС предлагает писать везде. Если в студии включить анализ кода, то она начнёт предлагать заменить явные типы на var
1) Используете var, когда тип очевиден или не важен
2) Указывайте явно, если неочевидно.
при этом там же по ссылке пример:
var currentPerformanceCounterCategory = new System.Diagnostics.
PerformanceCounterCategory();Ну и, как я сказал, диагностики студии предлагают менять на var почти везде. А если вспомнить, что придуман он был для Linq, где как раз точный тип неочевиден (просто не очень важен)....
при этом там же по ссылке пример:Так и что вас в нём смущает? Или вы хотите сказать, что тут не очевидно, что var — это
PerformanceCounterCategory?Ну и, как я сказал, диагностики студии предлагают менять на var почти везде.Видимо, у вас почти везде используются явные типы там, где они не нужны. Сути это не меняет совершенно.
А если вспомнить, что придуман он был для Linq, где как раз точный тип неочевиден (просто не очень важен)Я понимаю, что вы вообще не про Linq, а про анонимные типы, но вы постулируете просто городские легенды. var — это вещь в себе, он был придуман не «для Linq», который прекрасно живёт без него и не только для анонимных типов. Впредь прошу для утверждений вроде «придуман он был для Linq» приводить ссылки на документацию.
По поводу var - это зависит от принятого стандарта оформления кода в компании. В моей практике переменные объявляются именно через var и запись вида int number = 0 воспринимается как нечто чужеродное.
Вместо var рекомендуется сразу указывать тип, с которым будете работать, чтобы соблюдалась "строгая типизация", например int number = 0 вместо var number = 0
В C# var никак не влияет на то строгая у вас типизация или нет. Это просто "сахар" и для компилятора не играет никакой роли напишете вы "int number = 0" или "var number = 0".
Вложенность ifelse поражает. Но, допустим.
Я бы лично не допускал :) То есть для меня код ужасно нечитаемый и это огромный минус.
Вместо var рекомендуется сразу указывать тип, с которым будете работать, чтобы соблюдалась «строгая типизация», например int number = 0 вместо var number = 0C# — язык строгой типизации, и var — это просто alias явного типа. Там всё равно будет int. И нет, если тип очевиден, это просто лишние символы, так писать не рекомендуется.
бгг, интересно, как вы связали var со строгой типизацией?
особенно такие упоротые правила доставляют, когда работаешь с какими-то дженериками
MySuperPuperClass<GenericOne<GenericTwo>> variable = SomeMethod();
вместо
var variable = SomeMethod();
Лень было погружаться в код до полного понимания, но почему есть ощущение, что добрую логику парсинга можно было просто сделать регулярками.
Автор же пишет, что намерено отказался от регулярок в угоду оптимизациям.
Даже если запретить себе регулярки и не заморачиваться с грамматическим разбором, весь парсинг можно было сделать на обычных String.Split() вместо этой кучки низкоуровневых var {...}Position{N} = scheduleString.IndexOf (...), ибо формат элементарно разбивается на части по пробелам/точкам/двоеточиям/запятым
Можно было и String.Split(), но код бы не стал более читаемый. И я не согласен с тем, что код типа var позицияДвоеточия1 = scheduleString.IndexOf (':') является низкоуровневым и трудно читаемым. Дальше давайте сравнивать конкретный код, голословно мы не придём к истине.
String.IndexOf() низкоуровневый потому что вместо работы со строками вы переходите к работе с отдельными символами, их индексами.
Первым делом огромное спасибо за потраченное на реализацию время! К сожалению, у вас где то закралась ошибка, тесты не проходят. Например, если на входе строка где все звёздочки, то последние элементы в массивах years/days/months/... оказываются в ошибочном значении false.
Давайте сравним с моим вариантом. Все выводы, конечно же, представляют только моё личное мнение.
По объёму кода получилось у нас почти одинаково. Для сравнения я позволил себе привести форматирование вашего кода с своему стандарту (тело if всегда в фигурных скобках, каждая фигурная скобка в отдельной строке, после if или цикла - пустая строка) и убрал все комментарии. Ничья.
Ваш код более мелко нарезан на методы, соответственно методы более маленькие и более понятные. Тоже самое можно сделать и с моим кодом, от способа разбора строки это не зависит. Я посчитал, что формат строки не столь сложен чтобы выделять методы. Вам плюсик, а я учту на будущее.
Для парсинга чисел вы используете int.TryParse(str, out val), а это прямой призыв выстрелить себе в ногу. Посмотрите, например, какие неожиданные бывают результаты. Чтобы не получить проблем, надо указывать стиль или культуру. И при дальнейшем сопровождении кода могут снова забыть их указать. Вам минусик.
Использование string.Split() и int.TryParse() не характерно для системных библиотек. В исходном коде самого .Net их можно найти только в высокоуровневых подсистемах. В большинстве случаев сделано так, как у меня. Подробный список я привёл в другом моём комментарии.
Некоторые кусочки вашего кода также непонятны, как и мои. Например:
return (parts.Length == 4) ?
TryParseInterval (parts[3], 1000, out milliseconds) :
TryParseInterval ("0", 1000, out milliseconds);Поэтому не могу вам дать плюс за решение всех проблем понятности кода.
Итого, ваш код немного более понятен, чем мой. Но не принципиально. И есть свои недостатки.
К сожалению, у вас где то закралась ошибка, тесты не проходят. Например, если на входе строка где все звёздочки, то последние элементы в массивах years/days/months/… оказываются в ошибочном значении false.
Стопудово ошибки есть, я ведь накропал это за полчаса в LinqPad и моей целью была лишь демонстрация использования комбо Split/TryParse, а не создание 100% корректного кода покрытого всеми тестами. У вас тоже кстати не всё покрыто: попробуйте, например, отрицательные числа, нулевой шаг, шаг больше диапазона, диапазоны где левая граница больше правой. Я ваш код не запускал, только глазом лупил, но подозреваю, что отрицательный шаг он превратит в 0, после чего вероятен бесконечный цикл.
Я не вникал глубоко в логику вашего планировщика, и поэтому даже не уверен, что ваш подход с массивами вообще логически верный (или что я его правильно понял). Хотя и заданный вам формат расписания выглядит неполным — например, я не очень понимаю, как задать расписание вида "каждую 7-ю секунду"? *:*:*/7 тут не сработает, потому что это будет лишь "секунда, чей порядковый номер в минуте кратен 7", что совсем не одно и то же. Но вина того, кто придумывал синтаксис, не ваша.
Т.е. возможно, что если бы я решил плотно этим заняться, то я бы парсил это в другие структуры, вроде упорядоченного списка рекуррентных событий.
тело if всегда в фигурных скобках
Тоже имхо, но я считаю, что для guard clauses, где единственное и стандартное действие — немедленный выход или бросание исключения, это совершенно ненужное и даже вредное правило. Так же как и правило "после if — пустая строка" для нескольких последовательных guard clauses. Код без этой "воды" читается намного лучше, за счёт большей локальности, он не расползается на несколько экранов только потому что гуру стиля так сказали.
Посмотрите, например, какие неожиданные бывают результаты.
В принципе, могу согласиться. Однако, во-первых, см первый абзац. Во-вторых, в настоящее время int.TryParse("80", NumberStyles.Any, new CultureInfo("sv-SE"), out var i); не выдаёт у меня никаких проблем, похоже это был когда-то баг у Майкрософта, который пофиксили.
Использование string.Split() и int.TryParse() не характерно для системных библиотек.
Вас разве просили написать системную библиотеку?
Попытка оптимизации парсера в конструкторе через низкоуровневый доступ к символам была явно преждевременной. Задачей (как я её понимаю) была оптимальная итерация по событиям, и только. Ну просто из предметной логики видно, что расписания как правило создаются и намного реже (один раз на запуске программы, например), чем используются для поиска событий. Поэтому основное внимание должно быть на правильные структуры данных расписания, позволяющие итерироваться без огромных накладных расходов.
Некоторые кусочки вашего кода также непонятны, как и мои. Например:
Что там непонятного? Cтрока времени имеет формат "hh:mm:ss[.uuu]". Если разбить её по разделителям (':' и '.'), то будет либо 3 части (только часы, минуты и секунды), либо 4 части (+ миллисекунды). Если получили 4 части — парсим таблицу миллисекунд из этой 4й части; если нет — считаем, что в миллисекундах стоит дефолтное значение ("0") и парсим его (вызов с "0" всё равно нужен, чтобы создать таблицу миллисекунд, заполненную нулями).
Но, впрочем, я там действительно срезал угол (и оставил коммент о необходимости более строгого разбора), и из-за этого код пропускал некоторые невалидные форматы как валидные. Сейчас поменял код на более правильный. Заодно пофиксил проблему с неполным заполнением таблиц, избавился от null-таблиц, ещё больше упростил код конструктора и добавил валидаций.
Хотя и заданный вам формат расписания выглядит неполным — например, я не очень понимаю, как задать расписание вида "каждую 7-ю секунду"? ::*/7 тут не сработает, потому что это будет лишь "секунда, чей порядковый номер в минуте кратен 7", что совсем не одно и то же. Но вина того, кто придумывал синтаксис, не ваша.
Главное, на чём я решил сосредоточиться при выполнении задания — аккуратность обращения с календарём. ... . Поэтому сразу было решено отказаться от арифметических операций с временами и датами и использовать...
Вполне возможно, что ожидалось решение использующее unix-time, которое по коду вышло бы значительно проще, а для парсинга строки какой то аналог С-шного sscanf или регулярка.
К коду стоило приложить обоснование выбранных решений.
Могу ошибаться, но мне кажется, что будет гораздо проще, если вычислять с конца: сначала определить миллисекунду, затем секунду, минуту и т.д. На каждом шаге мы можем обновлять уже вычисленные значения в зависимости от ситуации. В этом случае циклы не должны появиться.
Немного посмотрел по этой теме, во что-то похожее: https://github.com/atifaziz/NCrontab/blob/9b68c8d1484ccd56a8f0bc1ce12e7270736f3493/NCrontab/CrontabSchedule.cs#L213
По поводу высказываемой выше идее про то что они захотели через тестовое задание сделать код для production - это совсем вряд ли. Хотя бы потому что для production в данном случае гораздо быстрее и проще использовать уже готовое решение.
В коде приведенного класса CrontabSchedule есть goto, первый раз такое вижу в прод коде. Говорят есть исключения когда его эффективнее применять. Есть какие-нибудь комментарии для данного конкретного случая?
хм, не вижу причин использовать goto в данном конкретном случае. Он избавляет ровно от одной вложенности do..while и не помогает читаемости от слова совсем.
Классическим примером оправданности goto считается выход из вложенного цикла.
Я ещё встречал использование goto default; внутри switch, в этом случае у goto не остается минусов (мы же четко понимаем, куда попадёт код), но кейс всё равно экзотический
Да вроде Дейкстра еще во времена динозавров доказал ненужность goto :) На мой взгляд, если в код удачно ложится goto, код лучше переписать.
Я так понимаю, что ассемблером вы никогда не пользовались?
Очень даже активно пользовался :) Писал ПО для микроконтроллеров семейств PIC и i51 на чистом ASM и на С c ассемблерными вставками.
Я понимаю, о чем вы, но - Дейкстра доказал (именно доказал, с точки зрения чистой математики), что goto не нужен.
именно доказал, с точки зрения чистой математики
А можно ссылку на это? самое релевантное, что я нашел, это его статья A Case against the GO TO Statement и это не математическое доказательство ненужности goto, а лишь использование математических аналогий для иллюстрации того как goto усложняет понимание потока исполнения программы. Но так можно договориться до того, что многопоточное программирование не нужно :). Впрочем все те же тезисы можно использовать, для рекомендации использование asyc в коде, вместо ада синхронизаций.
Насколько я понимаю, это не "A Case against the GO TO Statement", потому что "A Case..." - работа 1968 года, а полное доказательство того, что абсолютно любую программу можно написать, используя только ветвление, цикл и последовательное исполнение было сделано Дейкстрой в 70-х. Может быть, в книге Дейкстры "Структурное программирование" есть ссылка на более конкретный документ.
Каким образом можно сделать ветвление без goto?
заменить jmp на je, jz? Но это тот же самый goto. То есть на низком уровне это просто синтаксический сахар для улучшения читабельности программы человеком.
Опять же, доказательство, что "любую программу можно написать без goto" не является доказательство, что goto ненужен.
Я так могу сказать, что современная бытовая техника позволяет любые продукты перемолоть в миксере и съесть без жевания, но из этого разве правильно будет делать вывод, что на текущий момент зубы не нужны вообще?
Каким образом можно сделать ветвление без goto?
заменить jmp на je, jz? Но это тот же самый goto.
заменить jmp на je, jz? Но это тот же самый goto. То есть на низком уровне это просто синтаксический сахар для улучшения читабельности программы человеком.
Тут я с вами не согласен, goto и jmp соотносятся примерно никак.
jmp - благородная ассемблерная инструкция, ветвящая исполнение программы.
goto - костыль, позволяющий начинающему программисту внезапно телепортироваться в другое место кода.
Объединяет их только то, что goto после компиляции превращается в jmp, ну так и for, и if тоже превращаются в jmp.
Объединяет их только то, что goto после компиляции превращается в jmp, ну так и for, и if тоже превращаются в jmp.
я не вижу особой разницы между goto и jmp
Ибо просто jmp ничего не ветвит. Ветвят jz, jnz и др условные переходы. А jmp - как безусловный переход, является полным аналогом goto (точнее наоборот)
Опять же, goto был распространен в то время, когда бейсик работал не со скобками а с номерами строк (sinclair basic, бк 010-01) и был вполне себе благороден.
что значит не нужен? циклы, и брейки ни что иное, как синтаксический сахар над goto (jmp в ассемблере).
А так, да. приведённые мной примеры можно переписать, вынеся часть кода в функцию. Правда в некоторых случаях надо будет проследить, чтоб компилятор её заинлайнил
Брейки и циклы оперируют структурными единицами кода, что сводится навскидку к трём случаям: войти в подпрограмму (операторные скобки), пропустить подпрограмму, выйти из подпрограммы. Просто же Goto лоялен к провокациям вида «бросить всё на полпути и взяться за совсем другую работу не с начала». Нету привязки к границам структурных единиц кода.
Так-то и вызов метода будет для процессора чем-то вроде пуш-пуш-пуш-пуш-джа-а-амп! Но: это не тот уровень, на котором должна быть видна декомпозиция. Код, предназначенный для чтения машиной, а не человеком.
удалено.
Тестовое задание исполнило свою функцию идеально. Вы выяснили что не подходите друг другу. Оно же обоюдно работает. Тестовое задание не формальность вида да-нет. Это что-то вида похода в кафешку перед более тестными отношениями. Иногда можно выявить явные ошибки, а иногда нет. Тут и нравится - не нравится, или разные архитектурные подходы. Или управленческие подходы. Вы увидели как они ставят задачи и как реагируют на то, что получают не то, что они хотели бы. Возьми они вас по результатам этого тестового, все бы страдали, вы от них а они от вас. Процесс найма это процесс обоюдного принюхивания команды к человеку и человека к команде. Вы должны понимать что не только они вам отказали, но и вы выявили компанию которая вам не подходит. Стороны могут иметь разные ярлыки с точки зрения современных народных масс, как хорошие так и плохие, но вопрос не в том кто хороший а кто плохой а в совместимости, и тут тестовое показало что совместимости нет.
Верно подмечено. Но в моём случае наблюдается ассиметричность. Сравните мой ответ «Считаю своим долгом сообщить, что отказываюсь от рассмотрения вашей вакансии в .... Если интересна причина, то мне не нравится руководитель, который не может ничего объяснить, ограничиваясь словами типа "отвратительно". Извините за беспокойство.» с их ответом «задание Вы выполнили действительно отвратительно, халтурно», после чего они грубо отказались от дальнейших комментариев.
Сравнил. Вы разные. Вы не подошли друг к другу. Я не могу осуждать ни одну ни другую сторону. Они вам обещали разбор и вдумчивый фидбек? Нет. Грубо отказались? Да не очень, ну сказали что не будут давать обратную связь. Вы обиделись? Определённо да, но подумайте, на что вы обиделись, на то, что они не сделали чего-то, что вы считали, они должны сделать, а они, такие подлецы не сделали. Вы рано выяснили что не подходите друг другу, это прекрасно, а вы обижаетесь. Радоваться надо. И отдельно рекомендую шикарный видос от Академега про самодостаточность: https://www.youtube.com/watch?v=WwFgKxG9OOc
Мне кажется, им не понравилось решение с точки зрения вложенности if-ов.
Согласитесь, кто-то при взгляде может вспомнить пресловутые 3 if и сразы высказать "фе", не разбираясь.
Также, возможно, в алгоритмической части они хотели нечто более изощренное.
Aquahawk +1
[irony]Это всё из-за табов в начале строки. [/irony]
Судя по стилю ответа, вас проверял какой-то Очень Важный Прогер. Ему мог просто не понравиться стиль ваших комментариев, а про то, что это всё можно реализовать без регулярок, он вообще не подумал.
Вот и получилось, что у вас overenginering, а ему хотелось получить красиво выглядящий в IDE код и тонну комментариев, про объёму второе больше кода.
Попробуйте ради интереса написать им заново с другого аккаунта, решите задачу ещё раз ))
Не читал код, но вижу, что вложенность if большая, там порефакторить надо.
И комментарии на русском языке, в первый раз такое вижу
В дотнете есть функция Int32.Parse(string s), прекрасно парсит числа заместо возни с десятичным представлением в ParseNumber
Конечно, это первое, что пришло мне в голову. Но Int32.Parse() — довольно сложный метод, учитывающий особенности настройки локальной культуры. Я посчитал, что мой крохотный метод не сильно нагрузит смысл кода, но даст некоторую оптимизацию, которую так так хотел заказчик.
Вы этим добавили на свой счёт минус, показали себя как велосипедописателя, не ориентирующегося в стандартных фреймворках.
>учитывающий особенности настройки локальной культуры
Его можно попросить так не делать.
настройки локальной культуры
А как int зависит от культуры? Там ж цифры только, нет?
1.5 и 1,5
гоню, да. ну тогда десятичные разделители 1٫000, 1 000, 1,000, 1.000
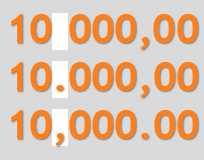
Это не int :)
Эти разделители, к слову, конфликтующие с синтаксисом в задании, еще одна причина не использовать Int32.Parse().
do{}while цикл, наверное, можно заменить поиском ненулевого значения в массиве:
var millisecond = t1.Millisecond;
do
{
if (_milliseconds[millisecond] > 0)
{
return new DateTime (t1.Year, t1.Month, t1.Day, t1.Hour, t1.Minute, t1.Second, millisecond);
}
millisecond--;
} while (millisecond >= 0);Если компания позволяет себе так высказываться, то я думаю что расстраиваться не стоит, а стоит найти другую с гетеросексуальными сотрудниками.
Геи != пидоры
Ну Вам наверно лучше знать. Я в этом не разбираюсь, а Вы судя по Вашему категорическому "!=" - да.
Первыми становятся осознанно и добровольно, а во вторые можно случайно попасть за один неудачный комментарий.
Цвет волос заложен в геноме. Для левшей нет однозначного мнения, насколько я вижу, но вроде тоже какой-то ген нашли.
А вот для ориентации ген сколько не искали, так и не нашли. Вряд ли можно утверждать, что это осознанный выбор, но и то, что это врождённое качество, тоже ещё надо доказать.
Все проще в большинстве люди бисексуальны.
Что показали все социальные опыты, в течении как минимум 200-х лет. :-)
Если предположить, что люди бисексуальны, то тогда ориентация действительно становится личным выбором. Но насколько я могу судить со своей колокольни - всё немного сложнее.
Физически телу пофиг с чем совершать фрикции, это хорошо видно на примере собак, которые пристают к ногам, мягким игрушкам.
Вот только человек несколько сложнее собак, и высшая нервная деятельность также влияет на влечение.
Хм... Хабр обучающий.. А я то грешным делом думал что разница только в количестве денег. Много денег - гей, мало - пид*р*с. Я же говорю что ничего не знаю о данных субкультурах. Раз Вы так много знаете, разрешите поинтересоваться к кому из них себя относите Вы?
Добавил голосование по общенародно выдвинутым версиям.
ХЗ как там что с ТЗ, просто общие замечания:
а) конструктор бросает исключения - зло
б) оптимизировать конструктор, который вызывается один раз - обычно глупость
в) вложенные if-ы любой SonarQube высветит как "вонь в коде", но иногда нужно, НО! здесь не тот случай - лучше писать как "guard clause" + break/continue (раз уж используете шаблон while(true))
г) 283 раза по два создания DateTime - странно выглядит (если не вникая в суть)
Формат очень похожий на crontab только для каких-то целей точность повышена до 1мс
А что-то типа set+ бинарный поиск в нем как в с++ никак было сделать? Ну скорость поиска (log n)^2 скорость добавления log n . Памяти требуется n*log n.(логарифмы все двоичные)
По поводу XML-комментариев к конструктору класса с параметром. Мне кажется, что не стоит размешать такой большой объем текста в элементе param. Многое можно было бы перенести в элемент remarks и разбить на параграфы:
/// <remarks>
/// <para>
/// …
/// </para>
/// <para>
/// …
/// </para>
/// </remarks>У вас два большущих метода, отличающихся только знаком:
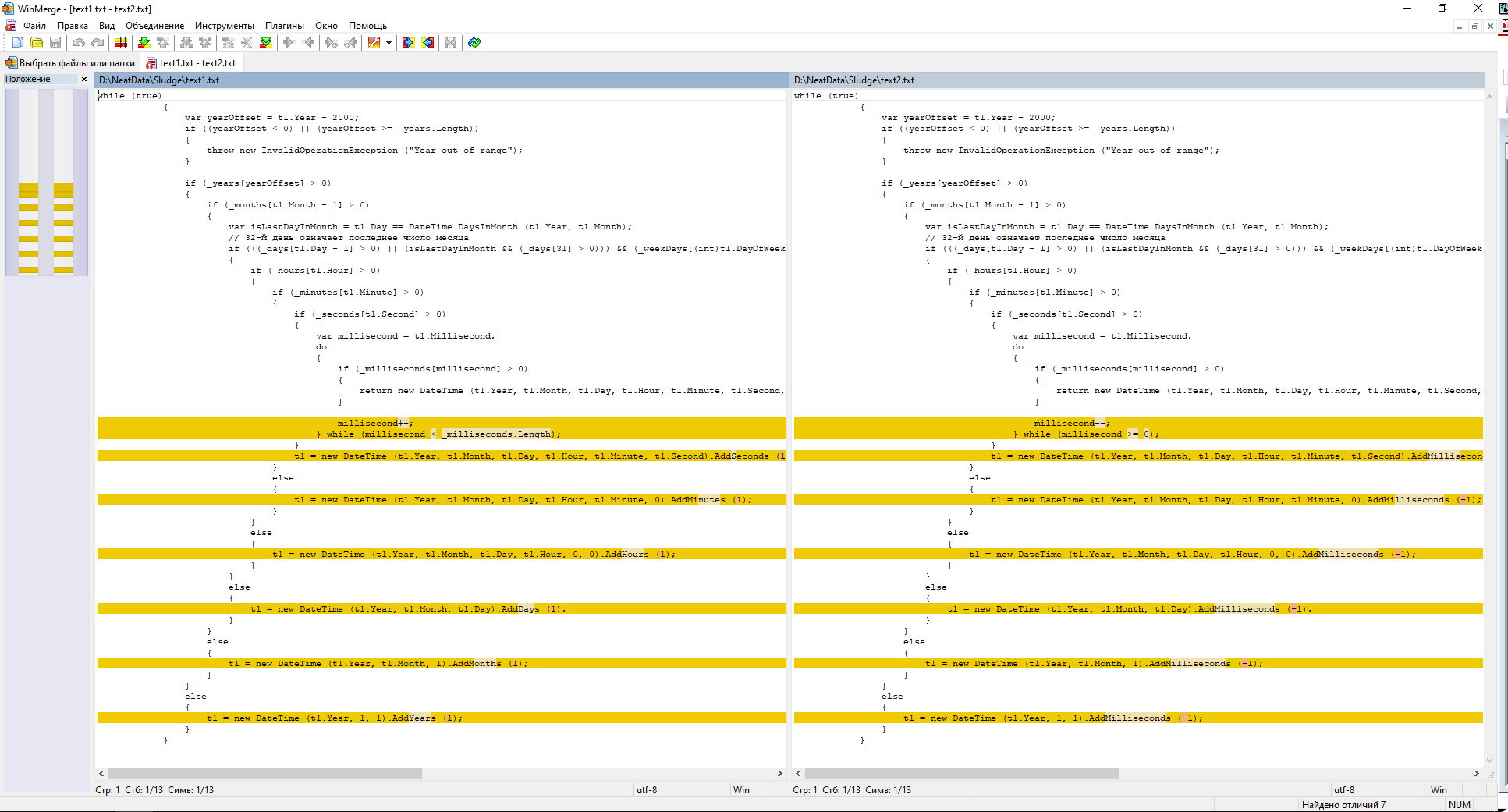
В общем-то, это сразу отказ на миддла как минимум, на джуна - 50/50, imho...
И, чтобы два раза не вставать, как говорится; вопрос к изначальной постановке задачи - не очень понимаю, зачем здесь конструктор, вижу место только для нескольких статических методов, которые принимают на вход время и строку расписания, отдавая время, удовлетворяющее условию. static не всегда хорошо, но вроде здесь вполне к месту, работаем прямо с чистыми функциями.
Ну не знаю. На мой взгляд скорее нужна причина и грамотная аргументация для того чтобы использовать static. То есть по умолчанию я бы его использовать точно не стал.
Например банально потому что он не совместим с интерфейсами. Что создаст определённый прoблемы с моками в юнит-тестах. Или с тем же dependency injection если вы им пользуетесь.
Кроме того в данном конкретном случае мы имеем конструктор "public Schedule(string scheduleString)". То есть у вас есть какое-то состояние и в теории могут понадобится несколько этих самых Schedule для разного контекста.
Да, вы подметили отличное направление для оптимизации исходного кода. Но я не думал, что это так важно. Буду совершенствоваться.
В чём конкретно вы видите проблему? В вещах вроде поиска эвента ближайщего к какой-то дате? Или в чём?
Промазал. Должен быть ответ к вот этому комментарию.
На мой взгляд огромная проблема в том что код плохо читаем. То есть задача в общем-то относительно тривиальная, но решена таким образом что мне понадобилось кучу времени чтобы понять что там происходит и зачем это всё вообще делается. Даже с учётом комментариев.
Плюс местами редундантный код. Плюс я бы сказал что вы слишком буквально восприняли момент с эффективностью и налицо явный overengineering. На мой взгляд "штатных" методов работы с датами в данном случае вполне бы хватило.
Всё как обычно) Современные так называемые программисты паталогически не могут не засрать всё кривым ооп там где оно нафиг не нужно. И естественно не могут вникнуть в аглоритмы календаря ибо это же надо разбираться а зачем? И естественно не могут всё что есть свалить в байты и инты и из стека вообще никогда не вылезать. И т.д. и т.п.
Про парсер строк можно вообще промолчать. Парсить строки не наплодив горы строк сверху похоже совсем никак. В общем ужас и кошмар. Собственно ничего нового я не увидел. Ко мне такие каждую неделю ходят и ничего не могут))
"Господа" кодеры [нет, не программисты], я вам следующее скажу. Мне не нужен код который придётся переписывать. Сделайте так, что бы этого не касаться, вообще никогда. Мне ваш ооп вхрен не упирался, тем более там где он вообще не нужен. Мне нужно единственное. Что бы оно максимально быстро работало, и разумеется корректно. Всё остальное мне вообще глубоко пофигу.
У меня вопросов к "исполнителю" вообще нет. А вот к заданию есть) Какого хрена везде где только можно юзаются строки? Это бред собачий. Должны влетать инты и лонги и вылетать они же. Планировщик юзающий парсер дат... Мда... Это надо сильно упороться))))
Нужно понимать что дейт тайм внутри это просто количество миллисекунд. Оптимизация в виде отказа от регулярок это совсем не оптимизация. Тут важна не "скорость", а правильная с точки зрения хранения данных структура. Взяли-бы тот же SortedList.
У дейт тайма уже есть parse, если не подходит ни один из стандартных формат провайдеров (что врят-ли), то сделайте свой.
Такие ошибки это нормально для джуна. Главное чтобы в зоне видимости был сениор, который поправит.
«Тут важна не "скорость", а правильная с точки зрения хранения данных структура» — спорное утверждение. По-моему, заказчик как раз намекал на скорость. Думаю, стоило уточнить у заказчика. Но заказчик отказался предоставлять связь, на связи был только HR.
Стандартный парсер от DateTime (я его применяю в тестах) не подходит, потому что тут каждый компонент можно задавать в виде перечисления или диапазона.
Думаю, стоило уточнить у заказчика
Золотые слова (по личному опыту). Я лет пять назад понравился работодателю именно потому, что уточнял ТЗ и предлагал варианты в тестовом.
При отсутствии же возможности уточнить ТЗ я в пояснительной записке указал бы тезисно несколько вариантов решения и обосновал бы выбор. Если упирать на то, что решение обоснованно именно жёсткой оптимизацей (сам я в этом слаб, поэтому рассуждаю теоретически), вероятно, следовало бы сделать решение простое, но рабочее, и оптимизировать его под тестами (в т.ч. нагрузочными), чем показать его реальные преимущества в выбранных (и заявленных в ПЗ) объективно исчислимых показателях — либо отказаться от сложного решения потому, что простое решение достаточно эффективно. Без этого получается преждевременная оптимизация, из тех, что неизвестно, настолько ли лучше, насколько дороже.
Насчет обратной связи по тестовым это сейчас обычная практика, либо просто уйдут в тень либо скажут что нет неверно либо вот как вам, а сказать что именно неверно религия не позволит.
В вашем случае вангую, что слишком тяжело понимать и читать год, остальное вторично.
Имхо делать это красиво в стиле Cronos/NCrontab/CronEspresso много времени стоит, а больше 2 часов на тестовое тратить такое себе ...
Можно было приколоться и сказать что реализовать не могу так как класс не абстрактный)
Очень кстати обижаются, если видят что вы тестовые для других компаний выкладываете в общий доступ сделанные, считается плохим тоном и просят убрать некоторые компании.
Мне кажется у вас в функции NearestEvent ошибка или как минимум момент требующий внимания: вы итерируетесь в бесконечном цикле и изменяете дату. Функция завершается возвратом даты события или исключением по значению года, но если выбрана дата t1 такая что событий уже не будет до конца заданного временного промежутка у вас программа завершиться по исключению, хотя данные все корректны. Аналогично по функции NearestPrevEvent.
я решил сразу отметать плохо зарекомендовавшие себя в плане эффективности практики типа регулярных выраженийВот это интересно, но хочется хоть какого-то обоснования этому. В целом, задача — на регулярки; дальше вы пишите, что добавили в проект бенчмарки, но их в проекте нет. Забыли добавить?
Моё мнение. Регулярные выражения имеют только одно преимущество — компактный код. А в остальном:
Это другой язык, требующий особых знаний для понимания, не говоря уже про доработку.
Легко «выстрелить себе в пятку», получив разбор строки на многие секунды. Для эффективности, хотя бы сравнимой с простым разбором (как в моём проекте) требуется высокая квалификация по работе с регулярками.
Даже идеально подобранная регулярка будет медленнее простого последовательного разбора.
Это другой язык, требующий особых знаний для понимания, не говоря уже про доработку.Ну да, и вы, как программист, должны ими обладать. По-моему, это очевидно, но возможно вы собеседовались на джуна, конечно.
Легко «выстрелить себе в пятку», получив разбор строки на многие секунды.Для этого делают тестирование производительности. Для простых случаев вроде вашего такого не случится.
Для эффективности, хотя бы сравнимой с простым разбором (как в моём проекте) требуется высокая квалификация по работе с регулярками.Нет, у вас совершенно банальная задача для элементарных регулярок.
Даже идеально подобранная регулярка будет медленнее простого последовательного разбора.Есть пример, может быть? Голословно сложно что-либо обсуждать.
Немножко опоздал к банкету, конечно, но я знаю пример, как в коде одной Го-библиотеки использовалась регулярка для проверки вида "каждый символ в строке является одним из [одного и того же] множества". Строки короткие, но их потенциально много; в контексте этой библиотеки это очень "горячее" место. Я из любопытства поменял регулярку на простой посимвольный проход по строке с той же самой проверкой (а множество вроде как ещё и последовательное было с точки зрения ASCII, но тут не дам руку на отсечение), и это ускорило этот кусок кода в 10+ раз.
Бенчмарк в подпроекте TestApp.Benchmark (он единственный запускаемый). Конечно, там только заготовка, потому что запускать нужно используя параметры реальных условий эксплуатации. Я набросал только пример бенчмарка.
Выскожу своё виденье.
Вы не соблюли баланс. Вас очень сильно бросило в крайность. Крайность заключается в том, что в вашем коде демонстрируемы навыки программиста С# усугубили представление о вас, как о разработчике решений с использованием .NET.
Вас на работу нанимают в команду, где есть тим лидер и руководитель проекта, которые должны обосновать, почему продукт будет создан к определённому времени и почему он будет работать. Т.е. они занимаются риск менеджментом. В отношение вашего кода это будет технический риск менеджмент.
Для тех, кто вас нанимает, нужно видеть, что вы гарантируете им результат, т.е. будите предсказуемым. А это значит, что вы будете применять общеизвестные практики, которые проверены временем и самое главное, понятны техническим руководителям. Т.е. вы у них должны вызывать чувство спокойствия в будущем результате.
Задание, которое вам выдали, скорее, относиться к категории прикладного программирования. В прикладном программирование при разработке особенно сосредотачиваются на техническом риске – человеческий фактор. Т.е. делают всё, чтобы программист не внёс в код какую-нибудь отсебятину, которая имеется в общеизвестной реализации. Нет самопального кода – нет возможной ошибки программистом – нет риска «человеческий фактор». Я думаю, что большинство руководителей осознают это, как минимум, на интуитивном уровне.
И сразу к вашему комментарию
Конечно, это первое, что пришло мне в голову. Но Int32.Parse() — довольно сложный метод, учитывающий особенности настройки локальной культуры. Я посчитал, что мой крохотный метод не сильно нагрузит смысл кода, но даст некоторую оптимизацию, которую так так хотел заказчик.
Int32.Parse - общеизвестный, предсказуемый, отвечает ожиданиям. А применение вашей реализации требует серьёзных обоснований потому, что он идёт с риском "человеческого фактора". На многих проектах руководители предпочтут избавиться от такого программиста, который в тихоря будет вносить такой код потому, что весь код не проверишь и проще, если нет программиста - нет самопального кода - нет риска «человеческий фактор».
Я думаю, что от вас ожидался код, который можно проверить за пару минут, по диагонали (это тестовое задние). Проверяющий должен был выхватывать знакомые паттерны кода и сказать: «Ну, да. Будет работать.» А ваш из-за его специфичности, скорее всего, никто не смотрел (потому что никто за это не заплатит). А резюме было дано произвольное. Судя по содержанию из-за раздрожения.
Да и, ваш код ОЧЕНЬ КРУТОЙ. Но с точки зрения производственного процесса, он будет одни из тех факторов, который увеличит стоимость трансформации кода в последующей итерации продукта, в результате чего заказчик не выделит бюджет на дальнейшее развитие. И проект закроют.
Огромное спасибо за развёрнутый ответ. Про «отсебятину» совершенно согласен. Могу только добавить. Если требуется высокая степень оптимизации, то обычно в проекте уже есть свои «правильные» методы типа Int32.Parse (). И в реальном проекте я бы воспользовался ими.
Про «от вас ожидался код, который можно проверить за пару минут, по диагонали» добавлю, что заказчик давал срок — неделя и очень удивился когда я его сделал за день. Лично я считаю, что задание, которое надо делать неделю, не должно использоваться как тестовое. Поэтому специально ограничил время, учитывая что компонент небольшой.
Про «от вас ожидался код, который можно проверить за пару минут, по диагонали» добавлю, что заказчик давал срок — неделя и очень удивился когда я его сделал за день.
Так в этом и суть. Вы востребованный сотрудник на текущей работе, поэтому вас нагружают. Вы ответственный и увлечённый, поэтому работаете больше положенного времени. Плюс у вас всё в порядке в личной жизни, т.е. тратите время на семью, хобби и т.д.. Т.е. у хорошего человека жизнь занята и распланирована. А если он сразу делает задание, что это значит?
Если требуется высокая степень оптимизации, то обычно в проекте уже есть свои «правильные» методы типа Int32.Parse ().
Здесь ключевое слово "если" , т.е. какое-то додумывание. А ваша реализация задания должна вызывать доверие к вашему повелению на проекте.
И конечно вам должно повезти, чтоб вас правильно поняли.
Помню писал свою версию сравнения чисел double, основанную на целочисленном сравнении. Каково же было моё удивление, когда бенчмарк показал равные результаты, с незначительным опережением стандартного сравнения double. После этого я понял, что написать быстрее чем это реализовано в промышленной реализации крайне непросто. Вы повторяет как мантру слово "оптимизация" хотя в задании не было явного утверждения о оптимизации любой ценой и доведения её до максимально возможной. Вы же зациклились на этом предложении возведя его в обсолют, в основном правда из-за бестолковой формулировки самого задания. Отсюда имхо, все и пошло не поплану.
Задание то для работы расписания CRON в панелях управления сервером.
Видимо aPanel решили нанять кодера и все-таки напсиать нормальную работу крона, после того, как я им указал, что их "добавляльщик" крона не умеет никаких интервалов временных добавлять :) Либо кто-то пишет свою панель и хочет выйти на рынок.
CRON в котором реализованы ми-секунды, реально должен кушать мало памяти, ибо слишком быстро, если очередь будет периодически "флашиться" из памяти и перезагружаться.
// конструктор большой по объёму исходника, но выполняет лишь простейшие действия и не выделяет память
Разве она не выделяется здесь при вызове new Schedule()?
internal readonly byte[] _milliseconds = new byte[1000];Да, при вызове new() выделяется память для всех членов класса. Но, эта память выделяется ДО вызова конструктора, а собственно в конструкторе никаких new() нет и ничего не выделяется. Что и написано в комментарии внутри конструктора.
Нет, я имею в виду, что каждая конструкция new byte выделит отдельный участок памяти в куче, а указатели запишутся в поля класса, разве нет?
Вы всё говорите верно. Но изначальный ваш ответ намекал на то, что в моём комментарии в коде конструктора всё наврано. Но там написана истина.
Инициализация полей - это синтаксический сахар над присвоением этих значений в конструкторе. Убедитесь в этом сами, для C# кода:
class Test
{
private int[] test = new int[100];
public Test()
{
Console.WriteLine("Test create");
}
}Будет IL код:
.class private auto ansi beforefieldinit Test
extends [System.Private.CoreLib]System.Object
{
// Fields
.field private int32[] test
// Methods
.method public hidebysig specialname rtspecialname
instance void .ctor () cil managed
{
// Method begins at RVA 0x205d
// Code size 33 (0x21)
.maxstack 8
IL_0000: ldarg.0
IL_0001: ldc.i4.s 100
IL_0003: newarr [System.Private.CoreLib]System.Int32
IL_0008: stfld int32[] Test::test
IL_000d: ldarg.0
IL_000e: call instance void [System.Private.CoreLib]System.Object::.ctor()
IL_0013: nop
IL_0014: nop
IL_0015: ldstr "Test create"
IL_001a: call void [System.Console]System.Console::WriteLine(string)
IL_001f: nop
IL_0020: ret
} // end of method Test::.ctor
} // end of class TestКак видно из IL-кода, создание массива происходит именно в конструкторе.
Вы можете убедиться сами на https://sharplab.io
Но изначальный ваш ответ намекал на то, что в моём комментарии в коде конструктора всё наврано.
Мой ответ намекал на то, зачем вообще ставить целью сделать такой конструктор, если компилятор все равно добавит в начало конструктора то, чего мы хотели избежать.
Спасибо за мнение. Вы осуждаете читабельность и поддерживаемость кода. Но не забывайте, заказчик особо обратил внимание на эффективность по производительности и памяти. Пришлось идти на некоторый компромисс и кое где пожертвовать читабельностью. Я считаю, что читабельность пострадала не сильно. Но точно сказать это можно будет только при сравнении с другой реализацией.
Знаете, по моему опыту, чаще всего
просто достаточно использовать нужные структуры данных и избегать лишних созданий коллекций и ставить Capacity по возможности.
Спасибо за мнение. Вы осуждаете читабельность и поддерживаемость кода.
Но не забывайте, заказчик особо обратил внимание на эффективность по производительности и памяти.
Пришлось идти на некоторый компромисс и кое где пожертвовать читабельностью. Я считаю, что читабельность пострадала не сильно. Но точно сказать это можно будет только при сравнении с другой реализацией.
// Check condtion something ...
if(condition0)
{
return;
}
// Check condtion something ...
if(condition1)
{
return;
}
// Check condtion something ...
if(condition2)
{
return;
}Компромис - это про баланс, у вас же явный перекос в сторону производительности (большой вопрос кстати, так как бенчей нет) в ущерб читаемости. Что мешало развернуть if-hell в плоскую структуру c guard clause (о чем многие писали)? Что мешало нормально разнести эти портянки по отдельным методам (и заинлайнить, если прям очень хотелось сэкономить на вызовах)? Зачем вот это адище в конструкторе? Ну ладно, допустим экземпляры шедулера будут создаваться как из пулемёта и надо по максимуму ускорить конструирование, тогда почему мы видим в коде такое?
public Schedule () : this ("*.*.* * *:*:*.*") {}Опять таки, если экземпляры шедулера будут создаваться как из пулемёта, то где тут экономия памяти, если каждый экземпляр по умолчанию тащит больше килобайта массивов?
Производительность, ага. Вот тут докопаюсь с оглядкой на то, что вы постулировали её максимизацию.
Первый вызов `scheduleString.IndexOf ('.');` - вызывает `public int IndexOf(char value, int startIndex)`, который вызывает `public extern int IndexOf(char value, int startIndex, int count)`, два лишних вызова - не бьётся с экономией вызовов в портянках.
Дальше. `var spacePosition1 = scheduleString.IndexOf (' ');` сканируем строку с начала, хотя смещения вроде как уже есть.
Дальше. `if (partStr[idx] == '*')`, а как-же _placeholder? Ну это ладно, просто в глаза бросилось.
`if ((yearOffset < 0) || (yearOffset >= _years.Length))` - почему _years.Length ,а не константа? Вы заранее не знаете длину byte[101]? И это в цикле, который `макс. кол-во итераций: 283`?
Про 283 итерации. Тут вообще сложно что-либо сказать, поскольку код настолько запутан, что с ходу не понятно, гениальное ли это решение или треш, угар и содомия. Склоняюсь ко второму, поскольку найти ближайшую чиселку к переданной за 283 итерации с созданием нового DateTime на каждой? сириосли!?
Фух, ладно, хватит.
Я считаю, что проблема заключается в том, что на эту позицию вы overengineering, а возможно это касается даже всего проекта, раз они не смогли понять нюансов выполнения вашего задания
А кто сказал, что весь проект должен быть написан в таком стиле?
Да, проблема автора, что он взял тестовое задание, и ознакомившись с ним, не связался с заказчиком и не уточнил степень "оптимизации".
А так - в моей практике мы и для веб-приложения писали модуль для апача на ассемблере, для оптимизации, и он был совершенно нечитабелен, но решил проблему навсегда.
Выскажу свое мнение: не очень понравился код из-за "раздутости". То есть методы очень большие по объему кода. Это затрудняет чтение и, как следствие, понимание кода. Вам бы реорганизовать его. Перенести некоторую логику в подклассы, либо отдельные методы.
Вообще по опыту выполнения тестовых могу сказать, что в большинстве не нужно учитывать именно тонкости реализации. Нужно, чтобы +/- работало и все.
Теперь перейдем к ответу, который Вы получили «отвратительно, халтурно». Тут все куда интереснее. Даже если код оставляет желать лучшего, то можно выразится более обтекаемыми выражениями. Человек потратил время, к этому нужно отнестись с уважением. Если такое обращение допускается на начальном этапе отношений, то что будет дальше?! Радуйтесь, что не попали к этому работодателю.
while (true) выполняется 3777575 раз. Прибавим сюда ещё NearestPrevEvent, в котором цикл запускается 33973986 раз. Каждый раз создавая новый объект DateTime. Это грустно.Осталось уточнить, а сколько раз запускается собственно метод. Чтобы получить количество циклов на один вызов метода. А «создание DateTime» не является нагрузкой. Это просто 128-битное число. Никакие объекты при этом не создаются. Обычно это компилируется в регистры процессора без использования памяти вообще.
Осталось уточнить, а сколько раз запускается собственно метод. Чтобы получить количество циклов на один вызов метода.Ваш метод бенчмарка запускается, очевидно, один раз. В нём он запускает методы NextEvent и PrevEvent по 216963 раз.
А «создание DateTime» не является нагрузкой. Это просто 128-битное число.DateTime — это структура, и её создание через конструктор само по себе является нагрузкой в плане производительности, а число — это тоже объект. Про память же я ничего не писал. Да, это структура хранит одно число, хоть и 64-битное.
Например, конструктор `DateTime(long ticks)` вообще невесомый и ничем не отличается от просто присваивания одного лонга другому.Я всё-таки говорю про конкретную реализацию, там используются другие конструкторы. На один цикл создаётся и тут же выбрасывается сотни объектов DateTime. И мы говорим о перфоманс-ориентированном коде для собеседования.
public class MyTest
{
[Benchmark]
public void Long ()
{
new DateTime(637637692751830282);
}
[Benchmark]
public void Contructor()
{
new DateTime(2021, 08, 05, 10, 10, 10, 10);
}
}| Method | Mean | Error | StdDev || Long | 1.906 ns | 0.0140 ns | 0.0131 ns || Contructor | 11.807 ns | 0.2642 ns | 0.2472 ns |Ваш бенчмарк лишь показывает, что в сложном конструкторе приходится что-то вычислять. Также он показывает, что ~12 нс на вызов конструктора — это вообще ни о чём по сравнению с тем же выделением памяти при создании объекта.
Я не знаю, о каких «обёртках над long» вы вообще пишете.
О таких:
struct LongWrapper
{
public readonly long Value;
public static operator LongWrapper + (LongWrapper lhs, LongWrapper rhs);
...
}Метод бенчмарка должен имитировать какую то нагрузку, приближенную к реальной. И это явно не один вызов. В реальном приложении, учитывая указанное в задании "в расписании задано много значений. Например очень много значений с шагом в одну миллисекунду", будет очень много запусков метода в течении короткого промежутка времени. Что я и попытался хоть как то приблизительно имитировать в методе бенчмарка.
Все методы (в том числе и конструкторы) структур, в том числе DateTime, выполняются в разы быстрее, чем экземплярные методы ссылочных объектов. Плюс их создание не лезет в кучу, которая охраняется объектами синхронизации и постоянно блокируется сборщиком мусора. Подробности по разнице в производительности можно глянуть, например в статье What Is Faster In C#: A Struct Or A Class?
Метод бенчмарка должен имитировать какую то нагрузку, приближенную к реальной.
Бенчмарк в первую очередь должен показывать наглядную разницу в производительности как минимум двух разных методов. Когда вы измеряете время работы одного своего метода, это не дает вам никакой дополнительной информации.
Это очевидно. Хотя, бывает, используют и на одном методе чтобы показать, как мало он выделяет объектов в куче или как быстро завершаются 100500 итераций. Поэтому я сделал не бенчмарк, а заготовку. Его надо дорабатывать по сценарию реального использования. А сценарий мне неизвестен.
Хотя, бывает, используют и на одном методе чтобы показать, как мало он выделяет объектов в куче или как быстро завершаются 100500 итераций.Профилировщик вышел из чата.
Поглядите, например, бенчмарки в статье An Introduction to System.Threading.Channels. Там много таких, из одного метода без сравнения.
Да вроде всё штатно, сначала автор меряет WriteThenRead vs ReadThenWrite, потом Channel_ReadThenWrite vs BufferBlock_ReadThenWrite. Просто WriteThenRead vs ReadThenWrite разнёс на две таблицы, потому что посерёдке исходный код.
Метод бенчмарка должен имитировать какую то нагрузку, приближенную к реальной.Нет, не должен. Вы не понимаете, что такое бенчмарк. А это даже не тест производительности.
Все методы (в том числе и конструкторы) структур, в том числе DateTime, выполняются в разы быстрее, чем экземплярные методы ссылочных объектов.Да причём тут экземпляры методов ссылочных объектов? Я вам говорю, что вы создаёте ненужные DateTime. Зачем вы мне рассказываете о том, что там быстрее, о куче, о сборщике мусора, синхронизации и прочем. Это же элементарная вещь. Простая, как дрын. Не нужно создавать лишнее.
Вы некорректно применяете глагол "создаёте". Создание DateTime - это просто привоение значения переменной, созданной ранее один раз в начале метода.
В случае структур конструктор не создаёт объект, а просто инициализирует поля.
Следующие примеры идентичны по логике, а варианты 2 и 3 — идентичны по MSIL (разница только в сигнатурах методов).
Вариант 1:
SomeStruct v
v.Field1 = ...;
v.Field2 = ...;Вариант 2:
SomeStruct v = new(...);
...
struct SomeStruct
{
public SomeType1 Field1;
public SomeType2 Field2;
public SomeStruct(...)
{
Field1 = ...;
Field2 = ...;
}
}Вариант 3:
SomeStruct v;
InitMethod(out v);
...
static void InitMethod(out SomeStruct v)
{
v.Field1 = ...;
v.Field2 = ...;
}В случае структур конструктор не создаёт объект, а просто инициализирует поля.Нет, создаёт. Собственно, если бы «просто инициализировались поля», вы бы не смогли передать объект структуры через ref. Ещё, можете попробовать сделать
v is objectСледующие примеры идентичны по логике, а варианты 2 и 3 — идентичны по MSIL (разница только в сигнатурах методов).Потому что значение по умолчанию для struct типов создаётся при помощи конструктора без параметров.
Собственно, если бы «просто инициализировались поля», вы бы не смогли передать объект структуры через ref.
А вы вообще, в курсе, что ref и out — это абсолютно одно и то же? Разница между ними заключается только в статическом контроле при компиляции программы.
Потому что значение по умолчанию для struct типов создаётся при помощи конструктора без параметров.
Нет. Конструктор без параметров вызывается, только если вы явно об этом попросите:
SomeType t = default;
SomeType t = new();
или как поле классаА вы вообще, в курсе, что ref и out — это абсолютно одно и то же?Вы пытаетесь «победить меня в споре», этот диалог мне не интересен.
Я просто не согласен с вашим утверждением:
и её создание через конструктор само по себе является нагрузкой в плане производительности
Потому что создание структуры само по себе нагрузкой не является. Существенной нагрузкой является логика в конструкторе. И ровным счётом ничего бы не поменялось, если бы вместо вызова конструктора был бы вызов функции с той же логикой.
Я просто не согласен с вашим утверждением:Именно поэтому вы решили узнать у меня, знаю ли я, чем отличаются ref и out? (вопрос риторический)
Потому что создание структуры само по себе нагрузкой не является. Существенной нагрузкой является логика в конструкторе.То есть, вы не согласны с моей фразой, что создание структуры через конструктор является нагрузкой… и тут же пишите, что «нагрузкой является логика в конструкторе». И я вам дополнительно указывал, что я говорю не просто про какой-нибудь конструктор, речь про конкретно используемые.
Комментариями выше вы явно дали понять, что речь идёт о самом факте создания объекта, а не о логике:
Я вам говорю, что вы создаёте ненужные DateTime. Не нужно создавать лишнее.
Возможно, я просто не очень понял, что вы хотели донести этим.
Верно только на половину.
Возьмем такой код:
using System; class A { static DateTime Do() { DateTime a; a = new DateTime(1); a = new DateTime(1).AddYears(1); return a; } }
Прогоним в IL через sharplab:
IL_0000: nop IL_0001: ldloca.s 0 IL_0003: ldc.i4.1 IL_0004: conv.i8 IL_0005: call instance void [System.Private.CoreLib]System.DateTime::.ctor(int64) IL_000a: ldc.i4.1 IL_000b: conv.i8 IL_000c: newobj instance void [System.Private.CoreLib]System.DateTime::.ctor(int64) IL_0011: stloc.1 IL_0012: ldloca.s 1 IL_0014: ldc.i4.1 IL_0015: call instance valuetype [System.Private.CoreLib]System.DateTime [System.Private.CoreLib]System.DateTime::AddYears(int32) IL_001a: stloc.0 IL_001b: ldloc.0 IL_001c: stloc.2 IL_001d: br.s IL_001f
Вуаля!
В первом случае у нас просто вызывается конструктор (call .DateTime::.ctor).
Во втором случае у нас происходит аллоцирование (newobj DateTime::.ctor).
Value types are not usually created using
newobj. They are usually allocated either as arguments or local variables, usingnewarr(for zero-based, one-dimensional arrays), or as fields of objects. Once allocated, they are initialized using Initobj. However, thenewobjinstruction can be used to create a new instance of a value type on the stack, that can then be passed as an argument, stored in a local, and so on.
И в коде у @novar как раз такой случай, потому что у него паттерн t1 = new DateTime().Add{Smth}(1)
Но все же аллоцирование структуры - все равно более дешевое удовольствие (по сравнению с объектом), потому что память выделяется на стеке.
В первом случае у нас просто вызывается конструктор (call .DateTime::.ctor).В обоих случаях происходит аллоцирование. В первом случае аллокация происходит для переменной (ldloca.s), и в уже аллоцированную память записываются значения. Разница в ключевых словах в том, что второй случай используется как параметр метода AddYears. Вот тут это всё хорошо описано Скитом.
Во втором случае у нас происходит аллоцирование (newobj DateTime::.ctor).
Маленькие уточнения:
ldloca.s не аллоцирует переменную, ldloca.s загружает адресс переменной в стек (см. https://docs.microsoft.com/en-us/dotnet/api/system.reflection.emit.opcodes.ldloca_s?view=net-5.0)
да, аллоцирование происходит в обоих случаях, но в первом случае оно происходит раз на жизнь метода (благодаря секции locals). Во втором случае оно происходит на каждой итерации while
Да, всё верно. Видимо, я перепутал с каким-то другим случаем (несколько месяцев назад как раз анализировал похожий код и получил одинаковый MSIL).
В вашем случае:
Память под локальную переменную выделяется на стеке при входе в функцию, поэтому в первом случае в конструкторе происходит инициализация этой переменной без аллокации.
Во втором случае значение переменной перезаписывается новым значением, и это новое значение сначала появляется на стеке, а затем копируется в переменную.
Но есть один нюанс: это стек виртуальной машины. Даже если бы вместо DateTime был бы простой тип, то новое значение, прежде чем записать его в переменную, все равно пришлось бы сначала положить в стек. А уж как это дело разрулит JIT-компилятор, лежит на его совести. Может, всё по регистрам рассуёт.
Я вам говорю, что вы создаёте ненужные DateTime.
Они создаются с вполне понятной целью: преобразовать (year, month, day, hour, minute, second) в ticks, прибавить к ticks некоторое значение, а затем сделать обратное преобразование в (year, month, day, hour, minute, second).
Первое делается в конструкторе, последнее — в свойствах DateTime. Ну а сам по себе DateTime — это структура, обёртка над long, и потому накладные расходы, связанные с использованием обёртки, ничтожно малы.
Они создаются с вполне понятной целью: преобразовать (year, month, day, hour, minute, second) в ticks, прибавить к ticks некоторое значение, а затем сделать обратное преобразование в (year, month, day, hour, minute, second).Хорошо, что вы всё поняли. Расскажите тогда, зачем 200 раз преобразовывать туда-сюда?
Ну а сам по себе DateTime — это структура, обёртка над long, и потому накладные расходы, связанные с использованием обёртки, ничтожно малы.Я последний раз напишу: сколько бы ничтожно малой операция не была, если она лишняя — её стоит удалить.
Весь дальнейший текст будет содержать очень много ругательств в сторону кода. И возможно, автора. Я не особо сдерживался. Если не готовы морально пострадать, то не открывайте спойлер.
Я бы на это решение тоже сказал, что кандидат не подходит явно. Код — говно и залупа.
Это однако, не отменяет того, что подобные формулировки (отвратительно, халтурно, отказ от дальнейших комментариев) являются неадекватными для хайринга. Но я очень понимаю и сочувствую.
Теперь о том, почему код — говно.
По коду явно видно, что автор не написал нормальное решение и оптимизировал его. По коду явно видно, что автор хуйнул микрооптимизации на старте.
Отказ от регулярок полностью необоснован и высосан из пальца.
Не нравится регулярка — у вас есть возможность заюзать чей-то чужой парсер (ANTLR, например), который произведет ясный код.
Не нравится чей-то чужой парсер — напишите свой, но нормально. Нормально — это несколькоуровневый парсер Token -> AST. У вас же получился scanerless parser, а это криповая поебень. Но даже scanerless parser может быть написан красивее.
Автор вообще вертел читабельность на хую. Принцип "все в функции должно работать на одном уровне абстракции" проигнорирован нахрен. Принцип "код должен быть понятным для других людей" проигнорирован нахрен.
Например, вы можете заместить, что паттерн типа var dotPosition2 = (dotPosition1 < 0) ? -1 : scheduleString.IndexOf ('.', dotPosition1 + 1) повторяется четыре раза, но не читабельноть этого дела не была оптимизирована
Вот читаю я строку internal readonly byte[] _years = new byte[101]; // год (2000-2100).
И каким хуем я должен понять, что эта поебень значит? Ну окей, я почитал остальной код и что-то понял — но это ж хуита. Судя по всему, мы в этом массиве храним признак, учавствует ли этот год в шедулинге.
Но почему же byte, а не boolean?
Почему это не сделать как отдельную явную структуру? Кроме того, в C# есть структуры для этого — BitArray, например. Но можно сделать свой IndexedBitArray. Так, чтобы он создавался через new IndexedBitArray(start: 2000, end: 2100). Т.е. чтобы была возможность указывать, откуда и до куда, раз уж вам не выгодно хранить range 0-2100.
Нейминг "_years", srsly? Это должно быть что-то типа "_scheduledYears" или типа того в такой реализации.
И таких строк много, и они связанны (years, months, days, etc). Почему бы не ввести новую структуру Schedule, в которую запихнуть все это говно?
У вас есть строка кода с 12-ю табами. Для C# норма 3-4. В сложных случаях 5-6 допустимо со скрипом и смазкой. А у вас 12 — это просто полный пиздец. Для сырого джуна еще допустимо. Но для позиции strong jun+ я не хочу никак взаимодействовать с таким программистомом и его кодом.
Вы также можете посмотреть на реализацию подобного метода у популярных ребят. Например, насколько я понимаю, Quartz.CronExpression.GetTimeAfter https://github.com/quartznet/quartznet/blob/f376d69537724d784d4aced87346dbfbfcd3e017/src/Quartz/CronExpression.cs#L1625https://github.com/quartznet/quartznet/blob/f376d69537724d784d4aced87346dbfbfcd3e017/src/Quartz/CronExpression.cs#L1625. Там правда, есть свои особенности. Код не очень, но уже ощутимо лучше по сравнению с вашим вариантом.
Вообще, когда вы пишите сложный нетривиальный алгоритм ориентированный на быстродействие — у вас никакими трюками не получится сделать его понятным, кроме как огромного количества комментариев. По-сути, вам нужно написать техдоку, что-то типа такого: https://www.wikiwand.com/en/Timsort.
Тест ScheduleTests.Construction — плох, поскольку лезет в internals и проверяет детали реализации. А еще и выглядит бредово
Benchmark ничего не сравнивает и написан просто шоб было.
И конечно, другие люди в комментариях уже тоже хорошо потыкали.
Дальше, хочу отдельно прокомментировать статью автора
Меня сразу насторожило неконкретное требование «класс должен быть эффективным и не использовать много памяти и ресурсов», ведь понятия «эффективно» и «много» каждый понимает по-своему
непонятно, поскольку неизвестны условия эксплуатации
Насторожило, непонятно, но вы не спросили. Это, кстати, очень интересная штука. Как с вами дальше работать, если вы не уточняете формулировку задания? Сразу нахуй.
отметать плохо зарекомендовавшие себя в плане эффективности практики типа регулярных выражений
Карго-культ. Регулярки неэффективны в ряде случаев, но не всегда.
и частого выделения объектов в «куче» (heap) чтобы не нагружать сборщик мусора
Хуита. В большинстве случаев вы не будете упираться в сборщик мусора. Особенно в C#.
Алсо, по объявленному опросу тоже интересно получается. Версии "я — хуевый программист" там нету. Как мне голосовать-то? Но это еще один микропоказатель, почему бы с вами не хотелось работать.
Так-то по делу, но на мате можно было бы и помикрооптимизировать, он тут лишний.
По коду явно видно, что автор *** микрооптимизации на старте.
И очень выборочно. Простые, понятные и напрашивающиеся забыл, а сложные, вырвиглазные и спорные рассыпал щедрою рукою
Спасибо за развернутый ответ. Мы не дети чтобы оскорбляться от грубых слов. Конкретно по делу:
"Отказ от регулярок полностью необоснован и высосан из пальца.". Я считаю, что неприменение регулярок внутри самого .Net - это уже достаточное обоснование. Посмотрите, например, разбор SMTP-ответа, там всё также как у меня в решении.
Во-первых, это не так
Найдите класс Regex. См. https://referencesource.microsoft.com/#System/regex/system/text/regularexpressions/Regex.cs,bbe3b2eb80ae5526
Кликните на его имя
Узрите 109 instantiations + 243 references
Во-вторых, это недостаточное обоснование.
Реальная причина, почему "не используются" регулярки — это потому что они подходят для малого количества задач.
В указанном вами примере (SMTP), применение регулярок не прокатит не потому что регулярки медленные, а потому что их нет поверх чего гонять — строк нету.
В рамках SMTP происходит вычитка стрима маленькими блоками. Грубо говоря, сначала приходят 10 байт (условное число), потом еще 10 байт, потом еще 10 байт.
Чтобы вкинуть регулярку ребятам понадобится на каждых 10 байтах делать следующее:
Превращать эти байты в строку и соединять с предыдущими строками
Запускать регулярку на детект данных
И проблема собственно в том, что для того, чтобы использовать регулярки придется N раз аллоцировать строку и N раз раннить регулярку.
Код внутри .NET должен быть определенно быстрее, чем код на самом .NET. Иначе получится очень странно.
В-третьих, разбор SMTP-ответа чище и понятнее, несмотря на интересные конструкции в виде goto.
Узрите 109 instantiations + 243 references". Там половина в UI-библиотеках, типа WinForms или в классах для подключения к СУБД, где никто ничего не оптимизирует. Плюс значительная часть в легаси библиотеке System.Web. Оставшиеся - это всякая экзотика типа служб компиляции исходного кода. Но я согласен, что утверждал слишком категорично. Это не отменяет факта, что их не используют где попало. Скорее их использование очень редкое.
"их нет поверх чего гонять — строк нету". SMTP это как раз только строки и больше ничего там нет.
"В рамках SMTP происходит вычитка стрима маленькими блоками". Не согласен. Согласно расширению SMTP под названием SMTP Service Extension for Command Pipelining, команды сыплются в обе стороны непрерывным потоком без ожидания ответа. И так работают все современные SMTP-сервера.
Я сначала кое-чего объясню.
--
Во-первых, SMTP хоть и про строки, но обратите внимание на декларацию метода:
int ProcessRead(byte[] buffer, int offset, int read, bool readLine)
Здесь что важно: buffer - byte[], не string. Т.е. строк таки нету.
Во-вторых, обратите внимание на вызов этого метода https://referencesource.microsoft.com/#System/net/System/Net/mail/SmtpReplyReaderFactory.cs,279
int read = bufferedStream.Read(buffer, offset, count); int actual = ProcessRead(buffer, offset, read, false);
Из стрима мы вычитываем count байтов. Не непрерывной поток байтов, а конечный поток байтов. Если быть точнее — 256 байтов. Даже если отправляющая сторона отправила все разом, то вычитка происходит все равно по 256 байтов.
В-третьих, то что ребята не ждут ответа - это замечательно. Но есть лаги на сетевом уровне, которые сделают невозможным неблокирующую вычитку всего за раз.
--
"их нет поверх чего гонять — строк нету". SMTP это как раз только строки и больше ничего там нет.
"В рамках SMTP происходит вычитка стрима маленькими блоками". Не согласен
Давайте вы сначала почитаете как работает код, а потом будет утверждать что-то.
"Но почему же byte, а не boolean?". Потому что надо экономить память (просьба заказчика), а boolean может занимать и 4 байта в зависимости от платформы. Всё таки разница 5000 байтов или 1300 - уже заметная.
"в C# есть структуры для этого — BitArray, например". Такие объёмы массивов как в моём решении (около 1300 байт), это как раз граничная область где переход на биты не даёт значительного уменьшения потребляемой памяти. Такая оптимизация планировалась как потенциальная, и именно поэтому так устроены массивы.
У BitArray 1 бит на 1 bool.
"Но почему же byte, а не boolean?". Потому что надо экономить память (просьба заказчика), а boolean может занимать и 4 байта в зависимости от платформы. Всё таки разница 5000 байтов или 1300 - уже заметная.
По вашей же ссылке первый ответ звучит так:
Firstly, this is only the size for interop. It doesn't represent the size in managed code of the array. That's 1 byte per
bool- at least on my machine. You can test it for yourself with this code:
Давайте я переведу на человеческий:
bool занимает 1 байт
но если вы укажете, что он должен занимать 4 байта, то он будет занимать 4 байта
"в C# есть структуры для этого — BitArray, например". Такие объёмы массивов как в моём решении (около 1300 байт), это как раз граничная область где переход на биты не даёт значительного уменьшения потребляемой памяти. Такая оптимизация планировалась как потенциальная, и именно поэтому так устроены массивы.
Я про BitArray написал не для оптимизации. Вообще по барабану как он там устроен, абы работал.
Я про BitArray написал, потому что этот тип имеет правильную семантику для задачи.
"Посмотреть на реализацию подобного метода у популярных ребят". Ребята из команды Quartz:
Не работают с долями секунд, а мне была поставлена задача сделать быстрое решение при планировании задач, отличающихся миллисекундами. Я считаю, что тяжёлые классы типа SortedSet - это перебор для таких вычислений.
Используют методы в десять экранов. Не факт что это лучше, чем отступы в 10 табов.
Их код оптимизировался годами. От решения тестовой задачи требуется такое же качество? При том что я не знаком с реальными условиями эксплуатации кода.
Не работают с долями секунд, а мне была поставлена задача сделать быстрое решение при планировании задач, отличающихся миллисекундами. Я считаю, что тяжёлые классы типа SortedSet - это перебор для таких вычислений
Да, я писал, что у них своя специфика.
Да, sortedset может быть действительно тяжелее. Вам никто не мешает использовать BitArray или если его недостаточно — написать BitSet поверх BitArray.
Что быстрее, что тяжелее, что дороже — это надо бенчать.
Впрочем, конкретно здесь неважно, если у вас перфоманс просядет из-за SortedSet. Условие "Обращаю Ваше внимание, что класс должен быть эффективным и не использовать много памяти и ресурсов даже тогда, когда в расписании задано много значений. Например очень много значений с шагом в одну миллисекунду" — это условие о асимптотическом анализе (O(1) лучше O(N), O(logN) лучше O(N^2) и т.д.), а не о константом ускорении (1 байт лучше 10 байтов).
Используют методы в десять экранов. Не факт что это лучше, чем отступы в 10 табов
Зуб даю — лучше. Конечно, еще бы лучше, если бы методы были покороче, но щито поделать.
Кстати, в комментариях к этой статье я видел ссылку https://github.com/atifaziz/NCrontab/blob/9b68c8d1484ccd56a8f0bc1ce12e7270736f3493/NCrontab/CrontabSchedule.cs#L213 - это еще красивее.
Их код оптимизировался годами. От решения тестовой задачи требуется такое же качество?
По читабельности требуется качество даже лучше. По работоспособности, скорости, эффективности — не обязательно.
У них SortedSet потому что у них происходит мерж кучи расписаний насколько я понимаю. Т.е. из расписаний "каждый четверг" и "каждый день в 12:00" нужно найти правильно ближайшую точку во времени. У автора такой проблемы нет, у него всего один предсказуемый паттерн.
Нет, cron expression из quartz не поддерживают такого "или". Только "и". Например, "каждый четверг в 12:00".
"Или" там поддерживается только на уровне одной штуки. Например, "каждый четверг или среду". Или сложнее: "12:00 каждого четверга/среды".
В целом за исключением мелких деталей задача решается та же самая.
Но если задача та же самая то мне трудно понять почему там код такой, с запашком. Там конечно нет 5 вложенных ифов, но все равно логики на километр.
Я пока только планирую попробовать сегодня-завтра поковырять задачу, но со стороны выглядит странно.
У NCrontab все же посимпатичнее выглядит, чем у Quartz
У Quartz код сильно зашкварился из-за того, что они поддерживают day of week (mon, tue, wed). Там примерно ¼-⅓ кода чисто из-за этого написана. А вот автору day of week не надо
Мне все же не нравится даже решение NCrontab, но полагаю, что это самое лучшее, что можно сделать, если не морочиться, но при этом добиваться эффективности.
Автору как раз надо day of week, вы же видели формат:
/// Формат строки:
/// yyyy.MM.dd w HH:mm:ss.fff
/// yyyy.MM.dd HH:mm:ss.fff
/// HH:mm:ss.fff
/// yyyy.MM.dd w HH:mm:ss
/// yyyy.MM.dd HH:mm:ss
/// HH:mm:ss
/// Где yyyy - год (2000-2100)
/// MM - месяц (1-12)
/// dd - число месяца (1-31 или 32). 32 означает последнее число месяца
/// w - день недели (0-6). 0 - воскресенье, 6 - суббота
/// HH - часы (0-23)
/// mm - минуты (0-59)
/// ss - секунды (0-59)
/// fff - миллисекунды (0-999). Если не указаны, то 0Задача по сути сводится к тому, чтобы закодировать инкремент числа, если мы будем рассматривать каждый компонент даты-времени как цифру.
С осложнениями:
У каждой "цифры" разный набор доступных значений. Причем в случае цифры "день" - оно еще зависит и от месяца/года
Особые проблемы несет то, что все эти компоненты "именованные". Из-за этого красивый код написать трудно.
Число 32 как последний день месяца
Есть day of week, который определяется из year/month/day. Но можно просто последовательно инкрементить дату, пока не найдём подходящую под day of week. Хотя авторы quartz предпочли более оптимизированное решение
Да, я про это как раз думал. В итоге решил, что "правильное" решение просто не влезает во временные рамки тестового. Это можно сделать, за пару деньков-неделю. Но не за 4-8 часов, сколько обычно отводится на тестовое.
Ну, я сейчас ставлю на часов 10-16. Это действительно очень много. Это как раз почему я считаю дающих тестовые задания - нехорошими
Хотя есть еще костыльный вариант. Перебрать компонент время втупую внутри заданного дня. Если никакое время не подходит, то засетить его в минимальное и перебрать компонент даты. Жутко неэффективно, но для заданных ограничений покатит и будет шустро
Ну, как именно это должно писаться на работе в код-ревью — это вопрос интересный.
Лично для себя я считаю, что если вы работаете в коллективе, то полезно исходить из следующих убеждений:
это работа в долгосрок, поэтому гораздо лучше и проще потратить ресурсы на дообучение человека, причем так, чтобы в коллективе сохранилась нормальная обстановка
если коллеги уж чересчур бесят, то надо или заменять коллег одного за одним, или менять работу
Но меня тоже забавляет, что "не думать о качестве кода" — это норм, а "не думать о вежливости" — это не норм.
Я, кстати, думаю, что автор не получил фидбек как раз потому что детальный фидбек без мата было дать очень трудно.
"Тест ScheduleTests.Construction — плох, поскольку лезет в internals". Ну они для того и сделаны internal чтобы тест до них достал. Конечно, по уму надо было отдельную структуру расписания, где из методов был бы только парсер. Тесты этой структуры были бы красивыми. И отдельный класс с методами поиска ближайших событий. Но заказчик задал конкретную архитектуру, где это в едином классе. И без этого залезания в internals не получится протестировать парсинг.
Прошу прощения за плохие формулировки. Под internals я подразумевал не "поля помеченные internal", а "кровь, кишки и внутренние органы класса". Тестировать такие вещи противопоказано, потому что при изменении реализации (без изменения внешнего API) ваш тест станет очень мешать. Скорее всего при переработке этот тест придется удалить. И те кейсы, которые проверялись чисто за счет этого теста — они проверены не будут.
Даже если вы настаиваете на том, что это нужно тестировать, то вы действительно можете сделать отдельную структуру. Если вам кажется, что это не так, то вероятно вы не понимаете сути тестовых заданий. На них ожидается production-like-код, а не подвыподверты.
"Непонятно, но вы не спросили". Я спросил. HR отказался меня соединять с тех.специалистом и сказал что то типа "вам выдали задание, делайте что можете".
Значит я зря по этому поводу вас оговорил. Простите.
Такое тоже бывает. В таких случаях полезно писать "Я исходил из X,Y, Z, если вместо Z будет F то тогда бы сделал не так а вот так". В целом, тоже может быть одной из гранью проверки заданием.
Вообще, сопроводительное письмо к коду — это очень важная вещь.
Но еще более важно это становится, когда делаются зарисовки кода и трансфер кода к незнакомым лицам. Как минимум нужно high-level обзор писать.
Вообще, сопроводительная документация к коду — это очень важная вещь в рабочих условиях.
Но еще более важно это становится, когда делаются зарисовки кода и трансфер кода к незнакомым лицам. Потому что не телепаты и нет возможности прояснить лично. Как минимум нужно high-level обзор писать.
"В большинстве случаев вы не будете упираться в сборщик мусора". Согласен на 100% и именно поэтому навсегда перебрался в платформы с автоматической сборкой мусора. Но. Заказчик пишет "в расписании задано много значений. Например очень много значений с шагом в одну миллисекунду.". Это уже серьёзное масштабирование и, как мне кажется, уже явный повод снижать нагрузку на GC.
Если вас волнует GC именно из-за количества миллисекунд, то непонятно причем тут парсинг строки.
Я практически уверен, что ребята имели в виду алгоритмическую сложность, а не общую скорость работы. Типа кейс "раз в 1мс" должен работать не сильно медленнее кейса "раз в 1 год". Потому что есть разные вариации решения этой задачи.
Подозреваю следующее. Вы думаете, что раз нужно расписание "раз в 1мс", то это значит, что ваш код должен отрабатывать <1ms, чтобы успевать переходить от одного момента расписания к другому и выполнять задачу возложенную на этот момент. Если я прав, то вы наверняка напрасно тревожитесь.
"по объявленному опросу тоже интересно получается. Версии "я — хуевый программист" там нету". Это вариант подразумевается по ответу заказчика. Если вы не голосовали, то очевидно выбрали этот вариант. Загвоздка в том, что есть множество людей, с которыми я работаю (и начальники, и подчинённые, и параллельные из других организаций), которые так не считают. Вот и хотелось прояснить. Спасибо за ваше мнение.
Согласен. Отвечать таким образом, как представитель компании рекруту - нельзя. Но по сути правда.
Код весь выполнен в угоду микрооптимизациям. Такое оправдано в нескольких случаях: у вас стомиллионов RPS на функцию и она плохо масштабируется горизонтально или же вы программируете микроконтроллеры и у вас 20кб памяти (условно).
Более того, если у вас такой кейс скорее всего у вас инструментом будет не c#. А в прикладных задачах в миллионы раз ценней читаемость и структурность кода (т.е. экономия времени разработчиков), чем микро- и не очень оптимизации. Этот код может быть короче минимум в три раза с явно выделенным семантическими блоками, без повторения и адского ветвления.
Я думаю это просто разница ожиданий. Автор задания плюхнул про оптимизацию имея в виду "юзай стрингбилдер и не делай 20 классов". А кандидат услышал "выжми из этого кода всё, что можно". Бывает.
Но это не повод отвечать по-хамски и игнорить. Так что считаю автору повезло тоже, вполне возможно избежал говноконторы.
Так далеко не факт, что код автора оптимизирован же. Оптимизированный код не обязательно лапшекод с гоуту ведь. Например, вполне вероятно что парсинг int.Parse быстрее чем авторский. У него минус что он только для строки работает, да, но это просто пример.
Другой вопрос применимости оптимизаций. 99% что требуется оптимизировать функции "получить следующее/предыдущее", а конструктор вызывается ну хорошо если раз в секунду (и его производительность вообще за рамками). Т.е. как раз оптимизировать парсинг смысла большого не было — вся суть была в оптимизации задачи поиска следующего/предыдущего. Я, конечно, прямого подтверждения этого в статье не вижу, но я бы крайне удивился если бы это было не так. Учитывая, как задание составлено, его делали вполне грамотные чуваки.
По-хамски игнорить, правда, тоже не стоит. Но тут уже мы правды не узнаем, как оно было на самом деле.
Вообще, я иногда задумываюсь, не является ли наличие тестового задания — признаком говноконторы.
Я давал тестовое задание для джунов, когда искал нам джунов\l3 чуваков. Ориентировочное время работы для джуна там была пара часов, для грамотного чела — на полчаса. Контора была нормальной.
Сениоров так я собесить бы не стал, а джунов — почему бы и нет.
Ну, джуны никому не нужны, поэтому их можно мучать как угодно - да.
Но для синьоров тестовые задания тоже часто бывают.
Ну я сторонник гипотезы что все могут делать что угодно, вопрос только к каким последствиям это ведет)
Если люди мучают тестовыми и у них в итоге 1.5 разраба доедает шиш без соли и заменить их не на кого — то возможно это не лучшая стратегия. А если это гугл который может изгаляться как угодно, ведь поток кандидатов все равно на порядок больше свободных мест — то чо бы нет называется.
Я бы использовал схему (совокупность точек, пробелов, двоеточий) для определения формата строки:
private static readonly IReadOnlyDictionary<string, IParser> SchemaToParser = new Dictionary<string, IParser>
{
{".. ::.", null}, // yyyy.MM.dd w HH:mm:ss.fff
{".. ::.", null}, // yyyy.MM.dd HH:mm:ss.fff
{"::.", null}, // HH:mm:ss.fff
{".. ::", null}, // yyyy.MM.dd w HH:mm:ss
{".. ::", null}, //yyyy.MM.dd HH:mm:ss
{"::", null} //HH:mm:ss
};
private static string GetSchema(string scheduleString)
{
var separators = scheduleString.Aggregate(new List<char>(), (list, c) =>
{
if (c == '.' || c == ' ' || c == ':')
list.Add(c);
return list;
});
return new string(separators.ToArray());
}
public void Schedule(string scheduleString)
{
var schema = GetSchema(scheduleString);
if (!SchemaToParser.TryGetValue(schema, out var parser))
throw new ArgumentException(nameof(scheduleString));
//...
}
А дальше написал бы парсер под каждый конкретный случай.
«yy.MM.dd HH:mm:ss» то же самое, что и «yyyy.MM.dd HH:mm:ss» (который уже есть), просто в парсере надо будет учесть, что год может состоять и из 2 символов. По поводу "чем вас не устраивает" не совсем понял... указанного вами формата нет в задании.
Форматы, да, могут дополняться, но мы ведь говорим про конкретное задание с определенными входными данными. Указано, что "Каждую часть даты/времени можно задавать в виде списков и диапазонов", т.е. "*.9.*/2 1-5 10:00:00.000" этим «yyyy.MM.dd HH:mm:ss» не распарсить.
Как вы писали ранее "И рано или поздно у вашего варианта начнутся проблемы из-за коллизий" - у моего варианта есть запас по добавлению новых форматов. А попытка предугадать большое количество вариантов развития - это перепроектирование, которое в большинстве случаев выливается в пустую трату времени сейчас и ненужный код в будущем. Плюс вы так и не предложили работающий вариант.
Плюс вы так и не предложили работающий вариант.
Что-то вас из крайности в крайность кидает: то
Но на мой взгляд как раз таки часть теста это посмотреть предусмотрите ли вы возможность добавления новых форматов или нет
- попытка продумать все до мелочей, то
Ну если вот «на коленке»
К тому же в задании указано, что класс должен быть эффективным и это явно не про регекс. А вот за это:
При этом регексы и форматы для штатных парсеров для среднего программиста будут понятнее чем ваш проприетарный формат.
- спасибо, насмешили. Куда уж моему варианту до чего-то такого по понятности:
@"^(?("")(""[^""]+?""@)|((0-9a-z*)(?<=[0-9a-z])@))"ИМХО регексп понятнее. Я сразу вижу что это регексп, а значит тут идет работа со строкой, вычленение из нее данных, мне не надо продираться сквозь килобайты кода пытаясь понять а что там вообще происходит.
К тому же в задании указано, что класс должен быть эффективным и это явно не про регекс
Такие заявления стоти подкреплять хотя бы бенчмарками. То есть регекс может быть сам по себе не суперэффективный, но при этом он вполне может оказатся эффективнее вашего решения.
спасибо, насмешили. Куда уж моему варианту до чего-то такого по понятности
Регекс это грубо говоря стандарт. Его используют куча людей, про него написано куча туториалов и если что всегда можно спросить кого-то кто разбирается.
Ваш вариант это вещь в себе. Спросить если что можно только у вас. Если вы уволились, то вообще спросить некого. И даже если вы ещё на месте, то не факт что вы через 5-10 лет вспомните что вы там в своё время напридумывали и как оно точно должно работать.
«Регекс это грубо говоря стандарт. Его используют куча людей...Ваш вариант это вещь в себе. Спросить если что можно только у вас» — тут вы передёргиваете (так говорят когда тайно меняют карту в карточной игре). Мой вариант — это C#, который гораздо легче понять, отладить и подработать. Справится даже не профильный специалист, а например джававед. А Regex — сложная штука, в которой трудно разбираться и даже опытные легко могут сделать плохой Regex.
--- добавлено ---
«Ваш вариант» сказали не мне. Что не отменяет моих выводов про Regex!
То есть регекс может быть сам по себе не суперэффективный, но при этом он вполне может оказатся эффективнее вашего решения.
Тот же вопрос по бенчмаркам к вам.
Ваш вариант это вещь в себе. Спросить если что можно только у вас. Если вы уволились, то вообще спросить некого.
К такие вещам я всегда добавляю модульные тесты и по ним можно четко разобраться, что делает класс.
{".. ::.", null}, // yyyy.MM.dd w HH:mm:ss.fffМне как-то сложно поверить, что нужно быть Шерлоком Холмсом, чтобы сопоставить ключ с комментарием.
Тот же вопрос по бенчмаркам к вам.
Производительность регексов секретом не является :)
К такие вещам я всегда добавляю модульные тесты и по ним можно четко разобраться, что делает класс.
Разработчик, который будет использовать у себя ваш код или библиотеку, совсем не обязательно будет что-то про них знать.
Мне как-то сложно поверить, что нужно быть Шерлоком Холмсом, чтобы сопоставить ключ с комментарием.
А потом например где-то будет человек, который должен это использовать. И у него почему-то что-то не работает. И как он должен понять это он что-то в формате входных данных напутал или это у вас в логике где-то баг?
А потом например где-то будет человек, который должен это использовать. И у него почему-то что-то не работает. И как он должен понять это он что-то в формате входных данных напутал или это у вас в логике где-то баг?
- фраза применимая к абсолютно любому коду.
Ладно, это уже какой-то непонятный разговор про несуществующие бенчмарки и кто-где будет библиотеки использовать. Я предложил вариант и придерживаюсь его.
- фраза применимая к абсолютно любому коду.
В случае с регексом можно с очень большой вероятносью исходить из того что багов нет. По крайней мере если вы используете системную библиотеку. Кроме того есть вагон и маленькая тележка возможнстей проверить насколько правильно вы написали конкретное правило.
спасибо, насмешили. Куда уж моему варианту до чего-то такого по понятности
Спасибо за предоставленную ужасную регулярку. Специально для вас я решил показать, как выглядит нормальное использование регулярок. См. полноценное решение парсинга здесь: https://gist.github.com/vlova/544d693cc4083caafa477383b2e1c216
См. ParseSchedule.pattern и ParseCronSubRange.cronPartPattern.
Вы если свою идею развернете в полноценное решение — получите хуже, чем у меня с регулярками.
Кстати, @novar, сейчас вы можете сравнить предложенное мною решение (только по парсингу пока, увы) со своим. Что по читабельности, что по производительности.
Согласен с комментарием выше. Ваш конструктор просто жесть, на 3 км (как и все важные методы), каша из валидации и инициализации. Если вы говорите про читаемость кода, тогда пишите методы которые по длине не превышают трети вашего экрана. Вложенность условий просто выносит мозг. Если вы говорите про читаемость кода, тогда откажитесь от вложенных условных блоков и от веток `else`, от слова совсем. Я в целом согласен с работодателем, неуд.
Вот что я думаю по поводу всех этих тестовых заданий - Если видно что человек знает язык уверенно пишет код, пусть как то и не так, то подкорректировать дело нескольких дней, а в данном случае полагаю ещё меньше, но нет мы будем месяцами искать принца который пишет как мы хотим. Задание некорректное.
Впрочем, против live-coding во время интервью наоборот совершенно ничего не имею и мне это даже весьма нравится - по-моему довольно увлекательно писать код попутно его с кем-то обсуждая.
Завидую людям, которым это нравится. Я уже много лет работаю, с кодингом никаких проблем не имею (по крайней мере таких, которые не позволяют успешно работать на разных проектах), но вот от этого лайфкодинга вечно ловлю ступор и отупление, не пишется мне под присмотром хоть тресни.
Вот мне тоже не писалось когда-то. Ровно до тех пор, пока мы с @0xFFFFFFне попробовали кодить "на пáру" один из её пет-проджектов. То ли по две пинты тёмного сделали своё, не менее тёмное, дело. То ли хорошая обратная связь. Но мне резко стало пофиг, когда заглядывают в код из-за плеча. Разве что, немного некомфортно когда долго молчат при этом.
У меня проблема именно когда заглядывают. Показывать код на ревью, или даже вовсе сырой, не готовый к МР, это без проблем, тут никаких комплексов нет, а вот когда кто-то за спиной стоит и смотрит что пишу, тут совсем никак не пишется, постоянно сбиваюсь, туплю, забываю даже синтаксис иногда, мучительно пытаюсь вспомнить какую-либо ерунду типа где надо размещать угловые скобки в дженериках, при том что когда один пишу, делаю все это не задумываясь автоматически.
Мда. Количество if конечно поражает. )))
А если вам задание сразу было не понятно до конца, почему вы не уточнили у заказчика детали?
Во первых, я пытался уточнить, но мне сказали что ничего уточнять не будут, типа должно быть и так понятно. Во-вторых, те детали, которые непонятны, я посчитал не такими уж важными для тестового задания. Я, по наивности (это было моё первое тестовое задание), предполагал что то типа как сказали выше "Если видно что человек знает язык уверенно пишет код, пусть как то и не так, то подкорректировать дело нескольких дней".
Не соглашусь с мнением, что код совсем уж плохой, хотя технических замечаний разной степени валидности тут в комментариях хватает. Плохое тут скорее изначальное задание.
Можно долго рассуждать о том хорошо ли использовать регулярные выражения или плохо, стоит ли пытаться танцевать вокруг сборщика мусора или нет, и вообще нужно ли сразу писать код с микрооптимизациями или лучше сначала сделать просто и потом это оптимизировать, но в конечном итоге на эти вопросы нет однозначных ответов. Проекты разные, требования разные. Где-то нужен энтерпрайз головного мозга с абстрактными фабриками, которые строят фабрики для фабрик. Где-то нужна производительность. Где-то нужна экономия памяти, даже ценой производительности. Причины и требования всегда разные.
В условиях плохого описания задачи и невозможности уточнить требования (что вообще нонсенс в нормальной ситуации), любое решение можно назвать плохим. Просто потому, что на выходе легко может оказаться, что описал задание один человек, а проверял его — другой. Один хотел как раз лютый стрёмный код ради оптимизаций, а другой — рафинированный энтерпрайз ООП. Удачи угодить второму, когда исходишь из требований первого. Такого бардака на самом деле хватает много где, но в найме особенно.
Чего уж говорить про вопрос времени: задача на которую есть X времени будет обычно выполнена не так, как задача, на которую есть 5X или 10X времени. Опять же, ситуации когда оценивает человек, который тупо не в курсе, что решение было сделано в сверхкороткий срок (когда, уж простите, не до фэншуя в коде) и оценивает его так словно на него было потрачены несколько месяцев, это тоже к сожалению "норма".
А так да, я тоже бы воспринял это неполное описание как желание увидеть код с оптимизациями вместо типичного подхода. Не хотите оптимизаций — нечего поднимать тему производительности вообще.
В условиях плохого описания задачи и невозможности уточнить требования
А откуда такая информация? Я всегда когда мне давали тестовые мог отписаться обратно за комментариями и в течение пары часов-максимум суток получал ответ назад. То что автор этой возможностью не воспользовался - просто минус к нему как к разработчику.
По коду уже проехались все кому не лень, поэтому комментировать не буду.
Из вашего голосования самый близкий вариант ответа 1, но я бы его прокомментировал: тут не нужна тонна комментариев и объяснениями что до как. Требовалось написать эффективное продакшн решение, т.е. оно должно быть эффективным, но при этом уровня "берем в прод". Закрывая глаза на перформанс (возможно, это эффективное решение, хотя опяь же судя по комментариям выше - не очень), это не является продакшн решением, соответственно с какой скоростью оно работает и не важно.
Если в задании чего-то непонятно - нужно спрашивать. Я как-то 3 дня переписывался уточнениями по задаче, прежде чем приступил. И потом ещё сделал сносок где какие трейдофы у меня есть, при каких условиях я решил делать так, а не иначе, и как бы я сделал по-другому. Более того, работодатель может специально опустить какие-то моменты, чтобы проверить - спросит ли его об этом исполнитель или начнет играть в вангу.
Согласен с комментаторами выше что задание не выполнено. Был в той же ситуации, мне как-то дали тестовое задание, которое я не смог сделать за 2 дня (при том, что отводилось на него 1 день). Ну и фиг с ним, просто не стал туда подаваться - видимо, им нужен был кто-то более скилловый.
Вам стоит поработать с навыками написания поддерживаемого кода. Возможно, стоит устроиться в какую-нибудь галеру типа епама, со стандартизованным кодстайлом, налаженным процессом ревью/грейдов/..., чтобы они помогли.
Лично я бы с таким кодом работать не смог даже близко. Даже если он работает. Если бы пришла доработка на него - с высокой вероятностью я бы просто переписал. Не потому, что я злой любитель выкидывать чужой код, а потому что я просто НЕ ПОНИМАЮ как его можно доработать. Физически. Как говорили классики, не надо писать самый умный код который можешь: ведь чтобы прочитать код, нужно быть вдвое умнее чем чтобы его написать.
Я думаю были кандидаты, у которых код был лучше поэтому вам и отказали. Когда есть несколько вариантов решения легче выбрать.
Вообще задание достаточно сложное, что сделать его прямо хорошо не затратив на это слишко много времени. Я бы первым делом погуглил как работают с "cron expression" библиотеки типа Quartz.
По коду:
если говорить про эффективность я бы его заточил на определенный сценарий, например "может быть долгое создание, но быстрый расчет даты"
очень сложный для понимания код, возможно стоило логику парсинга выделить в отдельный класс? с регулярными выражениями возможно этот код был бы проще для понимания
размер объекта сложно назвать оптимальным
алгоритм и структура данных не тривиальна, поэтому должна быть хорошо описана в комментарии к коду
методы расчета дат очень большие и сложные
в эксепшенах никакой информации о контексте ошибки, просто "Invalid character." не очень поможет пользователю понять что же не так
если корректировка времени сильно усложняет код (тем более вас не просили), то я бы не реализовывал это в рамках тестового задания, но написал бы список что можно еще улучшить
простите, но "schedule.cs", когда внутри Schedule, говорит о некоторой небрежности, так же как у другие мелкие недочеты как названия проекта...
юнит тесты которые проверяют внутреннее состояние? ну такое... может это индикатор того, что парсинг хорошо бы положить в отдельный файл?
бенчмарки я бы сделал отдельно на создание, отдельно на методы, ваш бенчмарк если честно не понятно чего намерит
"первым делом погуглил как работают с cron expression библиотеки типа Quartz". Она работает примерно по такому же алгоритму, только вместо массивов фиксированного размера использует SortedSet. Код у них очень большой, понять его лично мне гораздо тяжелее чем мой простой цикл на одном экране. Посмотрите их метод GetTimeAfter(), после чего, я думаю, пересмотрите своё мнение что мои "методы расчета дат очень большие и сложные".
Вдогонку обратил внимание на комментарий:
// цикл проверки каждый раз после корректировки времени, макс. кол-во итераций: 100 + 11 + 31 + 23 + 59 + 59 = 283
Вы же понимаете что
а) вы забыли тут про миллисекунды
б) вложенные циклы уможаются, а не складываются. То что циклы у вас неявные (вы при изменении счетчика минут сбрасываете счетчик секунд) ничего не меняет. Так что у вас тут количество итераций куда больше.
Я не забыл про миллисекунды. Цикл на них вложенный (очень простой, без вызовов методов DateTime) и не приводит к итерациями основного цикла.
Вложенные циклы именно что складываются. Лично мне алгоритм ясен. Именно для ясности алгоритма весь цикл помещается на одном экране.
Ну и количество итераций проверено практически. 283 - это абсолютный максимум для случая, когда в расписании задан максимальный год, а проверяется минимальный (или наоборот).
Вложенные циклы именно что складываются. Лично мне алгоритм ясен. Именно для ясности алгоритма весь цикл помещается на одном экране.
К сожалению, как раз с ясностью алгоритма проблемы.
Во-вторых не очень понятно что за "тут считаем, тут не считаем". Все итерации надо считать, то что цикл маленький" не дает ему права бегать сколько угодно.
Я вижу там 5 челвоек уже форкнуло вашу репу, надо сделать так же и предложить конкретные улучшения.
Устал листать комменты, чтобы написать свой отзыв)
Мой опыт на шарпах 10+ лет, я думаю hr смягчили ответ тимлида который проводил ревью кода)) там наверное были маты через слово. Код и правда непонятно что решает.
Вероятнее всего ожидалось что-то типа IMyList<DateTime> scheduler...
Заполнение его событиями и организация поиска в этом календаре. Видимо хотели увидеть как умеете пользоваться базовыми методами класса object, как умеете организовать оптимальный поиск по дате в каком нибудь дереве и + куда-то все засунуть и работать с нужным диапазоном дат.
Такое решение я бы тоже отклонил. Надеюсь на понимание.
я правильно понял, что вы предлагаете создать календарь с потенциально 365 ⋅ 24 ⋅ 3600 ⋅ 1000 = 31536000000 элементами на каждый год?
не могли бы вы пояснить?
Ок, не заметил что Markdown "скушал" скобки и их содержание. Я имел ввиду вместо
IMyList<DateTime>взять
IMyList<TimeSpan>И тогда количество элементов у вас заметно сократится. То есть если совсем упростить, то условное "**.08.2021" вместо тридцати одного DateTime будет иметь один TimeSpan.
я не знаю сишарпа, но вроде бы понял, что вы хотите хранить интервалы.
но что делать с /2 в микросекундах?
Такое естественно создаст "лишние" записи. Вопрос в том проблема это или нет. И если нам нужен полноценный аналог Quartz.NET, то это естественно проблема.
Но Quartz.NET писался не за пару часов одним человеком. То есть если тестовая домашка имеет такие требования, то с моей точки зрения просто в топку такие тестовые и фирмы их предлагающие. Особенно если нельзя уточнять требования к заданию.
идея, реализованная автором статьи, не выглядит чересчур сложной и при этом она решает проблему потребления памяти в граничных случаях.
вот реализация… вложенные if'ы не ужас-ужас-ужас, конечно, но некрасивы.
конструктор не рассматривал так как не пишу на шарпе (и, соответственно не знаю, как писать правильно), но критика выглядит разумной, оптимизация тут ни к чему на мой взгляд.
Я думаю, что требовалось.
Действительно, полноценное решение такого тестового задания до уровня "шобнестыдно" - это один-два рабочих дня.
Это весьма ужасно и компания сильно много хочет от кандидата.
Прочитал 99 % комментариев , тут прям своя Санта-Барбара, и защитника автора, и противники автора, и люди которые матом покрывали показывая код команды (который разрабатывается год) *типо вот так должно было выглядить твое тестовое задание*.
Вчерашний накал эмоций еще был усилен тем, что сначала отписались в основном поддерживающие автора, потом началась осторожная критика, а еще позже появился @nsinreal, пронесший под полой спойлером шестиствольный высокоточный экстрементомёт, заряженный в целом справедливой критикой, и всё закру...
Хотелось бы поблагодарить @novar за то, что выложил тестовое задание и своё решение в открытый доступ и спровоцировал мощную дискуссию; благодаря этому наш завтрашний код имеет возможность стать чуть лучше, чем вчерашний.
Строгог говоря любой код имеет право на жизнь.
Для тестовых заданий как правило ждут использования базовых объектов и их расширений. В данном случае ожидалось DateTime.Parse по всей видимости, ключевая заковырка по всей видимости по мнению заказчика это определение следующий даты согласно расписанию, на этом и следовало сделать акцент.
Вообще код плохо читаемый из за множества вложенных If, я такое тоже не люблю и на проектах стараюсь избегать если можно без них.
Что касается парсинга и оптимизации, его можно сделать в один проход одним циклом без поиска точек и кучи вложенностей, но это для любителей своих велосипедов))))
Добавил в статью суммарную информацию по всем комментариям.
по второму пункту: ИМХО вас явно попросили оптимизировать расход памяти и поиск (который потенциально может выполняться часто), а вы зачем-то начали оптимизировать парсинг строки и прочее, что выполняется редко.
по четвёртому: мне сходу показалось, что можно обойтись последовательными условиями:
Парсинг строки оптимизирован на случай если его переносить прямо внутрь методов поиска, а в конструкторе только запоминать переданную строку. Мне показалось, что такая архитектура тоже достойна рассмотрения, всё таки парсинг для конструктора — это многовато работы.
если его переносить внутрь, то там совсем всё переделывать ИМХО, так что это будет совсем другая реализация.
Лично у меня, после прочтения задания сложилось ощущение того что в нем требуется оптимизация поиска следующей/предыдущей задачи из списка (по скорости и по объему памяти), а не парсинга строки расписания. Я не пишу на шарпе, но все-же, вот так бегло пробежавшись по коду скажу что выглядит он ужасно, это нечитабельно, такой код в проде на проекте с которым я работаю, я бы видеть не хотел.
Даже если все-таки писать вот так, ради ускорения парсинга (не знаю насколько это работает быстрее регулярок), то стоило бы сопроводить код подробными комментариями по структурам используемых данных, и с обоснованием того, почему был использован именно такой подход. Заставлять ревьювера разгадывать ребусы и пытаться угадать причины того почему написан такой неудобоваримый код - это не правильно, в первую очередь для вас-же, ведь ваша задача продемонстрировать свои умения писать код пригодный для проекта, а не просто выдать как-то там работающее и компилируемое решение.
Далее - бенчмарк. Замер скорости одного единственного решения - это вообще ни о чем, раз уж вы заморочились скоростью парсинга, то стоило тогда уж написать минимум две реализации и замерами показать преимущества своей. Иначе совсем не очевидно что вся вот эта трудночитаемая реализация лучше банального (и легко читаемого) парсинга регулярками.
Хотя, повторюсь, лично у меня сложилось ощущение что речь там в первую очередь шла об эффективном поиске заданий в расписании, а не о парсинге. Быстрый и потребляющий разумное количество памяти поиск задания не такое уж простое дело, учитывая использование периодов, которые могут сгенерировать огромное количество заданий.
Вашему же неудавшемуся работодателю - жирный минус за отсутствие обратной связи при постановке задачи (не уточнили требования по запросу) и за хамство при оценке тестового задания. Независимо от того насколько оно хорошо (или не хорошо) было сделано - так отвечать нельзя ни в коем случае. Автор на его решение потратил массу времени, элементарная профессиональная вежливость требует того что-бы при ответе потратить хотя-бы пол часа на описание того что в решении не понравилось. Если нет желания тратить время на ревью и обратную связь - тогда наверное не стоит и рассылать тестовые задания. Тут надо или делать хорошо, или не делать вовсе.
Спасибо за конструктивный отклик. Хотелось бы заметить, что «нечитабельный» всё таки понятие относительное. Сложный алгорим реализовать хорошо читабельно невозможно. Надо для начала понимать сам алгоритм. В качестве ориентира, посмотрите как сделаны разбор строки расписания в методе StoreExpressionVals() и поиск времени в методе GetTimeAfter() известной библиотеки Quartz. Эти методы делают по сути тоже самое, что и мои.
Я не против "нечитабельного" кода в принципе. Хотя и считаю что его количество надо уменьшать любыми способами, но, согласен - иногда красотой кода стоит пожертвовать в пользу скорости или другой оптимизации. Я писал о том, что ваша главная ошибка в том, что вы никак не обосновали его использование, в виде комментариев в коде, и не доказали его большую эффективность в сравнении с "красивым" кодом. Без всего этого ваша реализация выглядит как просто код неопытного программиста, который научился на лабах парсить строки, но не особо научился еще правильно оформлять код.
ЗЫ разумеется, это моя субъективная точка зрения, и никоим образом не хочу вас как-то задеть.
Не беспокойтесь про «задеть». Хотелось бы больше конкретики, что именно делает мой код выглядящим как «код неопытного программиста». Вот давайте, например, сравним с системным кодом Guid.TryParseGuid() где тоже идёт разбор строки.
Даже не знаю, что еще могу добавить к написанному, вроде достаточно подробно и понятно написал. Если вы пишете код в таком стиле, там где явно ожидалось что-то более читабельное, то это стоит обосновывать в виде подробных комментариев к коду.
Как по мне так код по ссылке выглядит сильно лучше вашего, он лучше декомпозирован, там есть достаточно короткие методы, которые проще понять, не видно всех этих корявых многоуровневых if-else.. Это если не погружаться в задачу более глубоко, на это, скажу честно, сейчас нет особого желания.
Думаю если отвлечься от кода, и посмотреть на ситуации более отстраненно - основная ошибка тут, вы увлеклись самой задачей, и забыли о том что главная цель тестового задания, для соискателя, состоит не в том, что-бы добиться максимальной производительности или минимального потребления памяти. Главная задача в том что-бы продемонстрировать свои знания и умения, и тут нужно ориентироваться больше на навыки, нужные в командной работе, важнее выдавать код, в котором даже джун сможет разобраться без больших затруднений, и код, который в дальнейшем легко будет развивать и поддерживать. Грубо говоря, открывая модуль, человек не должен испытывать WTF эффекта, если код сам по своей природе такой эффект может вызвать (запутанный алгоритм, лютая оптимизация, и т.п.), то стоит сопроводить его подробными комментариями почему он такой получился, и что там собственно происходит, хотя-бы основные идеи оптимизации)
\+ Кстати хочу добавить - очень нравится ваше желание разобраться в своих ошибках, и то что часть их вы признаете. Это достойно уважения.
Я что-то не понял. Разве в задании нужно быть создать массивы хз сколько байт и распихать в них флаги? И это все ради того, чтобы NearestEvent() и другие методы перебирали микросекунды???
Не вижу перебора годов, месяцев и следующих. Или я не так понял решение?
И я может слаб в C#, но мне показалось, что для выхода из цикла while(true) нужны breakи.
Я не в том положении, чтобы оценивать ваш навык в C#, но похоже вы слабоваты. Предлагайте альтернативу. Вот серьёзная команда авторов библиотеки Quartz сделала примерно также как у меня, но у них вместо массивов идут SortedSet.
Аа, мне потребовалось время, чтобы понять, что выходом из цикла while(true) является return. Вы серьезно????????? В каких случаях применяется while(true) знаете? Это не ваш случай.
Перепишите код кратко. Я смотрю, что после всех подсказок каша в вашей голове не разваривается. Я чувствую, что вы никогда не писали и не видели краткий и понятный код. Из вложенности миллисекунд в секунды, секунд в минуты и так далее (я прочитал ваш один коммент в ветке ниже) абсолютно не следует, что ifы должны быть вложены. Ifы могут быть последовательными (зависит от конкретики, а не по аналогии). У вас работает интуиционисткая логика, которая не позволяет писать правильно и с доказательным подходом. Вы увидели какие-то аналогии, что-то почувствовали и давай парить код! Это неправильно.
Еще раз прочитайте задание: вас просили создать класс, который выполняет некоторые функции. Никто не просил создавать массивы с флагами. Вы могли создать простую структуру в несколько байт и функции Nearest() бы работали просто и без циклов с milliseconds++. Понимаете? Вы как-то неправильно втюхали про класс-календарь, усложнили без необходимости, наваяли спагетти-код... Можете обосновать, что я не прав?
Я бы не сказал, что работа халтурная, просто логика страдает.
Спасибо за мнение. Вот я в поисках "краткого и понятного" кода гляжу метод GetTimeAfter() в библиотеке Quartz, который делает то же самое что у меня. Делал уже несколько подходов, но полностью логику пока не понял. Зато не много вложенных if и выход из цикла показан в последней его строке (которая примерно на 10 экранов отстоит от начала цикла). Мой цикл виден на одном экране, а вложенность if отражает натуральную вложенность компонентов даты (месяцы вложены в года, дни вложены в месяцы и т.д.) Я посчитал такой вариант вполне пригодным для понимания. Но я, конечно, могу понять что в чьих то правилах может существовать жёсткий запрет на вложенные if.
Никто не просил создавать массивы с флагами. Вы могли создать простую структуру в несколько байт и функции Nearest() бы работали просто и без циклов с milliseconds++. Понимаете? Вы как-то неправильно втюхали про класс-календарь, усложнили без необходимости
В одной строке расписания заданы списки, диапазоны и периоды. Тут простой структурой не обойдёшься. Если я не прав, покажите подробнее, про что вы говорите.
Проблема ифов в том, что вам нужно держать слишком много в голове. Советую взять язык типа солидити и попробовать на нем пописать код — у него вообще 16 переменных максимум, и если их превзойти то будет "stack too deep" и код не скомпилируется) Очень помогает понять, где навернули глубины.
Каждый иф создает контекст. Контексты это сложно (магическое число 7+-2). Особенно если каждый контекст раздваивается на if/else, это экспоненциальнйы рост сложности за каждую строчку. Ну и fail fast, это правильный подход.
В одной строке расписания заданы списки, диапазоны и периоды. Тут простой структурой не обойдёшься.
Списки, диапазоны и периоды как структуры гораздо проще, чем конструкция с флагами. ;-)
ну напишите иллюстрацю
Можно самим подумать и догадаться, как оптимальным образом хранить в памяти списки и диапазоны. Это будет структура массивов структур.
Псевдокод:
struct Timerange{
int start
int finish
int step
}
struct Event{
Array[0,y] of Timerange Year
Array[0,m] of Timerange Month
Array[0,d] of Timerange Days
....
}По сравнению с этим вариантом массивы флагов: 1. Занимают много памяти, 2. Долго строятся, 3. Долго обрабатываются. Одни минусы, плюсов нет.
Вы могли создать простую структуру в несколько байт и функции Nearest() бы работали просто и без циклов с milliseconds++. Понимаете?
можете пояснить примером что вы имеете в виду?
Мне лично кажется, что тут вообще имелось ввиду другое.
Расписание - это набор событий
Спарсить строку - преобразовать текст в набор событий
Найти событие к заданному интервалу - поиск в списке (дереве что там уже придумано)
Другое дело, что это все не совсем ясно из постановки задания
По примерам вида "10-20/3" напрашивается класс SchedulePart со свойствами start, stop, step.
public DateTime NearestEvent(DateTime t1)
{
// цикл проверки каждый раз после корректировки времени, макс. кол-во итераций: 100 + 11 + 31 + 23 + 59 + 59 = 283
while (true)
{
var yearOffset = t1.Year - 2000;
if ((yearOffset < 0) || (yearOffset >= _years.Length))
{
throw new InvalidOperationException("Year out of range");
}
if (_years[yearOffset] <= 0)
{
t1 = new DateTime(t1.Year, 1, 1).AddYears(1);
continue;
}
if (_months[t1.Month - 1] <= 0)
{
t1 = new DateTime(t1.Year, t1.Month, 1).AddMonths(1);
continue;
}
var isLastDayInMonth = t1.Day == DateTime.DaysInMonth(t1.Year, t1.Month);
// 32-й день означает последнее число месяца
if (!(((_days[t1.Day - 1] > 0) || (isLastDayInMonth && (_days[31] > 0))) && (_weekDays[(int)t1.DayOfWeek] > 0)))
{
t1 = new DateTime(t1.Year, t1.Month, t1.Day).AddDays(1);
continue;
}
if (_hours[t1.Hour] <= 0)
{
t1 = new DateTime(t1.Year, t1.Month, t1.Day, t1.Hour, 0, 0).AddHours(1);
continue;
}
if (_minutes[t1.Minute] <= 0)
{
t1 = new DateTime(t1.Year, t1.Month, t1.Day, t1.Hour, t1.Minute, 0).AddMinutes(1);
continue;
}
if (_seconds[t1.Second] <= 0)
{
t1 = new DateTime(t1.Year, t1.Month, t1.Day, t1.Hour, t1.Minute, t1.Second).AddSeconds(1);
continue;
}
var millisecond = t1.Millisecond;
do
{
if (_milliseconds[millisecond] > 0)
{
return new DateTime(t1.Year, t1.Month, t1.Day, t1.Hour, t1.Minute, t1.Second, millisecond);
}
millisecond++;
} while (millisecond < _milliseconds.Length);
}
}
Спасибо за конкретику. Моя ошибка в том, что мне алгоритм был виден яснее именно в виде вложенных if на одном экране. Я не знал, что количество вложений if считается страшным злом даже если строки короткие и понятные.
Но вы где то ошиблись (видимо по мелочи). Алгоритм нарушен, тесты зависают.
Истекло время редактирования комментария, продолжу. У меня в цикле вложены элементы даты (строка год, строка месяц, строка день, строка час и т.д.) и вся вложенность выглядит как естественная иерархия элементов даты (ведь месяц вложен в год, а не идёт последовательно за ним). Лично для меня это повышало понятность алгоритма. Вы вот не разбирались в смысле кода, а зря. Я бы не согласился, что после правок стало принципиально читабельнее.
решение с вложенными if'ами плохо тем, что нарушена локальность, действие (добавление года, месяца,…) отделено от условия.
как раз последовательные условия очень логичны:
Я не знал, что количество вложений if считается страшным злом даже если строки короткие
гхм, у вас строки не короткие хотя бы из-за отступов.
Я не знал, что количество вложений if считается страшным злом
Термин Cyclomatic complexity появился аж в 76-м году прошлого века, а в знаменитом труде Фаулера идёт под грифом "фу-фу-фу"
if (!(((_days[t1.Day - 1] > 0) || (isLastDayInMonth && (_days[31] > 0))) && (_weekDays[(int)t1.DayOfWeek] > 0)))ИМХО это не менее ужасно, чем вложенные if'ы )))
Вы про то, что надо было просто разбить на строки так:
if ((
(_days[t1.Day - 1] > 0) ||
(isLastDayInMonth && (_days[31] > 0))
) && (_weekDays[(int)t1.DayOfWeek] > 0))или что то другое?
Конечно, нет. Каждое из этих условий нужно завернуть в функцию.
Будет что-то вроде:
if (!DayScheduled(t1.Day, isLastDayInMonth) && WeekDayScheduled(t1.DayOfWeek))P.S. Вы, кстати, неправильно переписали условие, забыв про отрицание первого условия, что говорит о плохой читаемости кода.
В некоторых рекомендациях просят не вызвать функции/методы внутри if-выражения. Вот например статья C# Coding Standards, раздел 4.3 Flow Control пункт 33. Avoid invoking methods within a conditional expression.
P.S.: я переписывал мой исходный вариант, а не предложенный неработающий с инвертированием
Это значит, что некоторые рекомендации крайне плохи.
Но если вам хочется им следовать, то можно просто вынести хотя-бы в переменные.
А ещё он говорит что нужно использовать extract function до тех пор пока это возможно: https://youtu.be/7EmboKQH8lM?t=3350
К чему это приводит можно посмотреть в его книжке Clean Code, где разумная функция на 20 строк разбита на нонсенс из 10 функций по 1-3 строки каждая.
В нормальных рекомендациях не просто постулируются какие-то утверждения, а ещё и даётся обоснование для них.
Моё обоснование рекомендации
33. Avoid invoking methods within a conditional expression.:
Если метод имеет побочное действие, то могут быть проблемы. Если побочных действий нет, то всё ок.
Например:
if (dict.TryGetValue(key, out var item)) ...Очень удобно писать так. По-вашему, нельзя вызывать этот метод внутри условия? Надо пихать результат в отдельную переменную?
А ещё там дальше идёт:
35. Avoid using foreach to iterate over immutable value-type collections. E.g. String arrays.
И что, вместо foreach надо использовать цикл? Это ж полнейший бред. Может, в 2007 году, когда писались эти гайды, это имело значение (например, из-за создания объекта-итератора), но сейчас — уже нет.
ваш вариант ещё был более-менее читаемым, но добавление дополнительного инвертирования условия убило его напрочь, без IDE считать число скобок нет никакого желания.
Скажу как человек, побывавший много раз с обеих сторон процесса найма.
Как потенциальный кандидат, я бы отказался от выполнения такого задания. Во-первых, оно сложное для тестового задания, которое вообще-то должно читаться по диагонали за несколько минут (больше у технического интервьюера обычно нет, у него свой бэклог и дедлайны и без вас) и улетать в корзину, в лучшем случае быть началом дискуссии на самом интервью. Сложное оно причем не с алгоритмической точки зрения, а просто из-за множества однотипных кейсов типа */4, 32 число месяца и тп, которые отнимут много времени, но не дадут дополнительного value ни для кандидата, ни для проверяющего.
Как проверяющий ваш код я бы сказал, что это сразу "нет", и я очень хорошо понимаю ответ компании. Ваш код плохой для любого уровня разработчика, особенно для тестового задания на интервью, и вот почему.
.NET это все-таки про ООП, вы написали обычную простыню процедурного кода, хорошо хоть оператора goto избежали. Вы не показали ни знания, ни опыта с наследованием, полиморфизмом и инкапсуляцией.
Подобное задание предполагает использование паттернов проектирования. Вы не применили ни одного. Могли бы прикрутить какой-нибудь Builder, Strategy, Singleton, Factory method, хоть что-то, что показало бы ваш опыт работы с паттернами.
Код абсолютно неприменим в Enterprise решении: он нечитаем, неподдерживаемый и нетестируемый, в нем магические числа, у него запредельная цикломатическая сложность (собственно поэтому и нетестируемый).
Требования "не использовать много ресурсов" скорее всего это обычное требование здравого смысла, вы как минимум должны представлять временную и цикломатическую сложность вашего кода и не писать "индусский" код с циклами по одной миллисекунде. В идеале я представляею некий builder, который парсит и возвращает массив из N следующих элементов после указанного DateTime. Time complexity должно быть O(1).
Могли бы показать знание регулярных выражений, это идеальный кейс для них. Дополнительно могли бы показать, что знаете как сделать их быстрее с использованием синглтона и опции Compiled, например.
Если коротко, это код, который неприемлем в проектах enterprise уровня. И вообще он неприемлем в проектах никакого уровня, кроме очень редких кейсов погони за экономией наносекунд, типа торговых роботов, где ради лишней наносекунды можно и пренебречь красотой кода. Очевидно, что календарь это не тот случай.
Спасибо за оценку. Главное в том, что я не верно оценил сопроводительную фразу заказчика «Обращаю Ваше внимание, что класс должен быть эффективным и не использовать много памяти и ресурсов». Остальное — последствия. И последствий стало много ввиду сложности задания. Я всё написал в стиле исходников самого .Net. (не применял регулярки, string.Split() и int.Parse()). Если бы заказчик хотя бы намекнул, что требуется показать «опыт с наследованием, полиморфизмом и инкапсуляцией» и «опыт работы с паттернами», то я бы делал задание совсем по другому.
Не соглашусь про «календарь это не тот случай». Тут заказчик как раз чётко сказал «очень много значений с шагом в одну миллисекунду» и это дополнительно увело меня в сторону оптимизации памяти и ресурсов.
Мне бы помогла обратная связь с заказчиком, но в ней было отказано.
Я всё написал в стиле исходников самого .Net.
Это вы себе льстите, уж поверьте.
Если бы заказчик хотя бы намекнул ...
В том то и дело, все это имело место, что бы проверить как вы пишите код в повседневной среде. Лично мне было бы стыдно показывать такой код, как у вас, кому-либо.
Мне бы помогла обратная связь с заказчиком, но в ней было отказано.
Мне кажется обратной связи не было потому что заказчик и вы живете в совершенно разных измерениях, но заказчик это понял сразу, а вы наверное нет.
Так давайте разоблачим само-лесть! Давайте конкретно сравним. Вот метод из исходников .Net: RegexParser.ScanReplacement(), который используется для парсинга регулярок. По смысловой нагрузке он примерно сравним с моим парсингом строки расписания.
А без конкретики, ваши слова выглядят как снобизм.
Давайте конкретно сравним.
Давайте. Начнем с длинны методов, ` ScanReplacement` или `AddConcatenate` выходят под 30-40 строчек, что неплохо. Читаемость нормальная, есть избыточность, но это скорее всего из-за того что коду лет так 20. Облагораживанию подлежит. Код процедуральный, а значит, с душком, не идеален. Но все же в разы лучше вашего творчества.
А вот методы парсинга у них так себе конечно, например `ScanRegex`, с другой стороны такие вещи, не обязательно, должны писаться руками, а могут быть сгенерированы из грамматики(см Ragel State Machine Compiler). Хотя в целом код оптимален, для парсинга регулярок потянет.
К сожалению, оценка «в разы лучше вашего творчества» осталась нераскрытой. Тут ведь тоже не наблюдается наследование, полиморфизм, инкапсуляция и работа с паттернами. И тоже код не идеален и подлежит облагораживанию. Почему же «вы живете в совершенно разных измерениях»?
Тут ведь тоже не наблюдается наследование, полиморфизм, инкапсуляция и работа с паттернами.
У меня такое впечатление, что вы не готовы конструктивно воспринимать критику в адрес вашего подхода к решению поставленной задачи. Ваш опрос в конце статьи не конструктивен и ориентирован в вашу пользу.
Что касается сравнения вашего решения и классов платформы, то я считаю его не уместным. Именно по этому полагаю что мы продолжаем общение, пребывая в разных измерениях.
Взгляните на определение самого класса и на его методы:
```
internal sealed class RegexParser {
internal static RegexTree Parse(String re, RegexOptions op) {}
//....
}
```
Класс является сугубо внутренним и объявлен как статический. Он намертво интегрирован в более глобальный модуль для работы с регулярными выражениями. Если мне не изменяет память, то вас не просили написать подобный модуль для интеграции в какую либо системную утилиту. Вас попросили запилить простенький парсер а-ля CRON-таб выражений.
Работодатель ждал от вас что-то вроде(в гораздо более простом исполнении):
- https://github.com/atifaziz/NCrontab/blob/master/NCrontab/CrontabSchedule.cs
- https://github.com/HangfireIO/Cronos/blob/master/src/Cronos/CronExpression.cs
Оба представленных класса не являются эталоном оформления кода или дизайна решений, но дают богатую пищу для размышлений как следует оформлять и тестировать(!) простенькие, самописные парсеры.
Мои 5 копеек как человек более 20лет собеседовавший кучу народа и как кандидат сейчас проходящий собеседования :)
Со стороны работадателя:
1. Слова про эффективность и не использовать много памяти - просто вода
2. Задание честно говоря сделано не очень. Т.е. не сильно думали, для меня это большой минус у кандидата
3. Мы всегда даем фидбек по заданию, если есть доп вопросы стараемся ответить, но в споры никогда не влезаем, это просто правила хорошего тона, и возможно нам этот человек подойдет в будущем, и нам не надо чтобы человек был обижен.
4. Никогда не давать тестовое задание из продакшена, это плохой тон
Со стороны кандидата:
1. Явно произошло недопонимание друг-друга, это и плохо - провал на собеседовании, и хорошо - вам в эту компанию не надо. У меня на 20 собеседований было одно такое.
2. К сожалению я сам уже столкнулся, что попросили сделать тестовое задание из продакшена, я его сделал просто потому что было интересно, но это минус для комнпании.
Как специалист по парсерам поясню что вы сделали не так.
1. Вы написали парсер самостоятельно вместо того чтобы взять библиотеку наподобие ANTLR или https://github.com/sprache/sprache/
2. Если вы хотите написать парсер самостоятельно то это делается иначе. В целом парсинг в самом простом варианте выглядит так :
1. Запись языка который будете парсить в форме Бэкуса — Наура.
2. Разбивание текста на токены (с помощью регулярок как правило)
3. Рекурсивный спуск по правилам языка из шага 1.
Спасибо за рекомендации. Я глядел, как на образец, как сделан парсинг в исходниках .Net (подробно в моём комментариии выше). Почти везде там парсинг свой (без регулярок и даже без int.Parse). Разбиение на токены применяется только в сложных комплексных форматах.
Знаком с темой, но не считаю себя в ней крутым специалистом. В целом поддерживаю ваши мысли. В данном конкретном случае, в связи с простотой синтаксиса, BNF можно представлять в уме, а шаг 2 (т.е. разбиение на токены) - пропустить и работать прямо с символами.
Ну, давайте прикинем BNF:
<ScheduleString> ::= [<Date> ' '] <Time>
<Date> ::= <Range> '.' <Range> '.' <Range> [' ' <Range>]
<Time> ::= <Range> ':' <Range> ':' <Range> ['.' <Range>]
<Range> ::= <Item> {',' <Item>}
<Item> ::= <Number> | (((<Number> '-' <Number>) | '*') ['/' <Number>])
<Number> ::= <Digit> {<Digit>}
<Digit> ::= {'0' | '1' | '2' | '3' | '4' | '5' | '6' | '7' | '8' | '9'}
Понаписали 100500 комментариев про оптимизацию разбора строки расписания, а я вот вообще не пойму — зачем это оптимизировать
разве? ИМХО как раз про парсинг больше писали про то, как красивее его сделать.
В целом очень подробно все расписано вот в этом комментарии https://habr.com/ru/post/571342/comments/#comment_23339830
Но я добавлю кое что от себя. Немного с другой стороны.
Представьте, что вы хотите объяснить собеседнику как работает ваш код. На словах. Понятным языком. Вот так и пишите изначально. Только в виде функций на английском языке. Ну, разве что, чуть более завуалированно, чем "а здесь я делаю вот это". Тогда верхнеуровнево можно будет посмотреть, что из себя представляет алгоритм. Его даже документировать не придется, он сам себя будет документировать. Далее уже реализовывайте каждую функцию. Здесь уже будет низкоуровневый код (количество уровней может быть и больше, тут тоже главное не перестараться). Однако, то что вы хотите сделать в этой функции, все еще должно быть понятным. Самый низкий уровень уже будет включать в себя все эти ваши парсинги строк (а может вы таки решите использовать вместо этого регулярки) и другие штуки. Это будут, скорее всего, неоднократно используемые функции.
По поводу вложенных if и "хочу, чтобы все было на одном экране". Ну тут тоже можно последовать тому же совету. Вам не обязательно видеть одновременно и смысл и детали реализации.
По поводу оптимизации. Ну тут важно, чтобы алгоритм, который может иметь сложность O(n) не стал вдруг O(n2). Ну и как заметили ранее, стоит избегать повторного пробега по коллекции, когда этого можно избежать. Однако, в некоторых случаях для читаемости я бы этим пренебрег.
Представьте, что вы хотите объяснить собеседнику как работает ваш код. На словах. Понятным языком. Вот так и пишите изначально. Только в виде функций на английском языке. Ну, разве что, чуть более завуалированно, чем "а здесь я делаю вот это". Тогда верхнеуровнево можно будет посмотреть, что из себя представляет алгоритм. Его даже документировать не придется, он сам себя будет документировать.
Как говорил мой коллега: "любая более-менее сложная логика мгновенно перестаёт быть самодокументированной, как только оказывается, что это не ты её написал".
История одного фееричного провала тестового задания на C#