На днях я наткнулся на одно любопытное видео:
Моей первой реакцией было Братан, хорош, давай, давай, вперёд! Контент в кайф, можно ещё? Вообще красавчик! Можно вот этого вот почаще? отрицание и усталость, потому что всё это я уже слышу с разной интенсивностью на протяжении лет пяти, в зависимости от текущих объектов хайпа. В этом посте я попытаюсь разобраться, что из сказанного в видео является правдой.
Утверждения:
Закон Мура больше не выполняется из-за фундаментальных физических ограничений ⇒ масштабирование нейросетевых моделей по вычислительному бюджету невозможно.
Нейросетевые модели внедряются слишком медленно.
Ответы нейросетевых моделей неконтролируемы и неинтерпретируемы.
Дальше обсудим каждое из них.
Сразу отмечу, что второй пункт очевидно абсурден по отношению ко всем нейросетям (распознавание лиц? машинный перевод? анализ медицинских изображений? шахматы? поисковики? контентные рекомендации и автоматическая модерация на том же YouTube?). Поэтому далее под «нейросетями» я буду подразумевать генеративные нейросети, типа GPT/SD. Из-за моей специализации это будут в основном языковые модели.
Выполняется ли закон Мура?
TL;DR: вероятно, закон Мура будет выполняться ещё минимум 5 лет.
Зако́н Му́ра (англ. Moore's law) — эмпирическое наблюдение, изначально сделанное Гордоном Муром, согласно которому (в современной формулировке) количество транзисторов, размещаемых на кристалле интегральной схемы, удваивается каждые 24 месяца.
Дисклеймер: я не эксперт в железе и уж тем более не физик. Я не знаю, что такое EUV, что означают магические цифры нанометров, и как производят процессоры. Да даже о том, что такое транзистор, знаю только понаслышке. Здесь отсылаю читателя к этим двум статьям: Moore's Law, AI, and the pace of progress и Predicting GPU performance.
Краткая выдержка:
Закон Мура выполняется для CPU до сих пор. Только количество транзисторов, размещаемых на кристалле интегральной схемы, удваивается каждые два с половиной года вместо двух лет. Для GPU он тоже выполняется, но не так идеально.
Из IRDS следует, что пределы классического транзисторного масштабирования в промышленных процессах будут достигнуты к 2028. Дальше есть обходные пути, типа упаковки транзисторов в несколько слоёв. Для GPU картина аналогичная, раньше 2030 стагнации ждать не стоит.
В случае GPU нас ещё интересует возможность соединять по сети несколько устройств. И там всё очень хорошо, скорость передачи данных растёт экспоненциально.
Что если закон Мура перестанет выполняться?
TL;DR: даже если мы упрёмся в стену физических ограничений для процессоров, всё ещё существует много способов развивать нейросети с использованием текущих вычислительных ресурсов.
Иначе говоря, что можно менять при фиксированном количестве вычислений? Сразу советую прочитать прекрасную статью про обучение BERT на одном GPU за один день, в ней применяются многие способы ускорения обучения из списка ниже.
Масштабирование по параметрами против масштабирования по данным для языковых моделей
GPT-3 обучалась по законам масштабирования, которые были описаны в статье OpenAI от 2020 года. Спустя 2 года, исследователи из DeepMind показали, что на самом деле законы масштабирования другие.
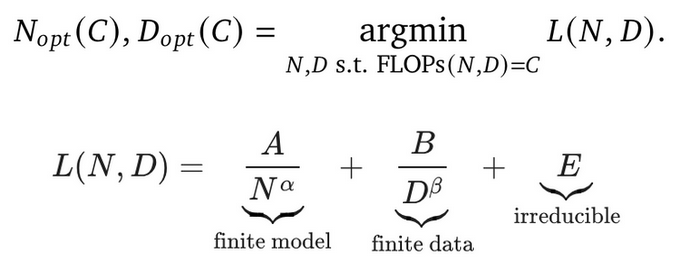
В основе обоих законов лежат четыре переменные:
N: количество параметров модели;
D: количество токенов в обучающей выборке;
C: количество вычислений в FLOPs, зависит от N и D;
L: финальное значение функции потерь, по сути качество модели.
А сама форма эмпирического закон выглядит так:
Вот только для двух версий закона коэффициенты разные:
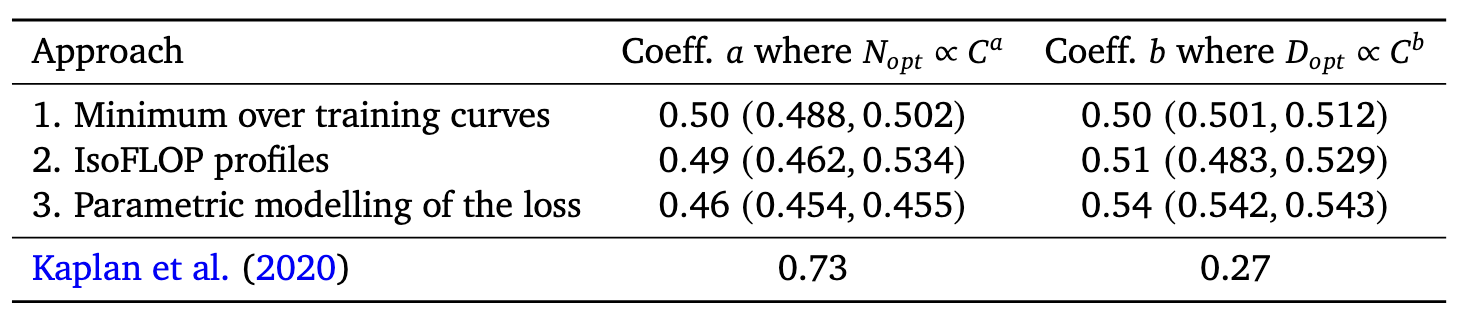
По старой версии выходило, что масштабирование по параметрам намного важнее масштабирования по данным. По новой версии коэффициенты одинаковы.

В качестве подтверждения нового закона DeepMind сделали Шиншиллу, модель в 2.5 раза меньшую, чем GPT-3, при этом не уступающую ей по метрикам. Позже аналогичную модель, LLaMA, сделали и в Meta.
Где просчитались OpenAI? На самом деле кроме 4 переменных, описанных выше, есть ещё куча других. Конкретно в этом случае дело, вероятно, было в шедулере. В кейсе OpenAI расписание изменения learning rate не масштабировалось с изменением числа шагов в обучении, что вообще-то не слишком типично.
Так вот вопрос: если OpenAI допустили ошибку, не найдётся ли другого скрытого параметра, изменение которого улучшит качество модели при тех же вычислениях?
Вот пара интересных постов на тему: chinchilla's wild implications и How should DeepMind's Chinchilla revise our AI forecasts?
FP32, FP16, BF16, TF32, int8 и другие способы представления чисел с плавающей точкой
IEEE 754 — широко используемый стандарт IEEE, описывающий формат представления чисел с плавающей точкой. Используется в программных и аппаратных реализациях арифметических действий.
FP32, также известный как float32 — формат представления чисел, использующий 32 бита. Заявляется, что он поддерживает диапазон примерно от 10^(–38) до 10^38. Можно ли вместить все числа из этого диапазона в 2^32 ячеек? По принципу Дирихле и здравому смыслу, нет.
FP32 этого и не делает, лишь малая часть чисел из указанного диапазона представимы в этом формате. Благодаря нескольким трюкам, этого достаточно для большинства применений, но явно не стоит использовать числа с плавающей точкой для финансовых операций.
.")
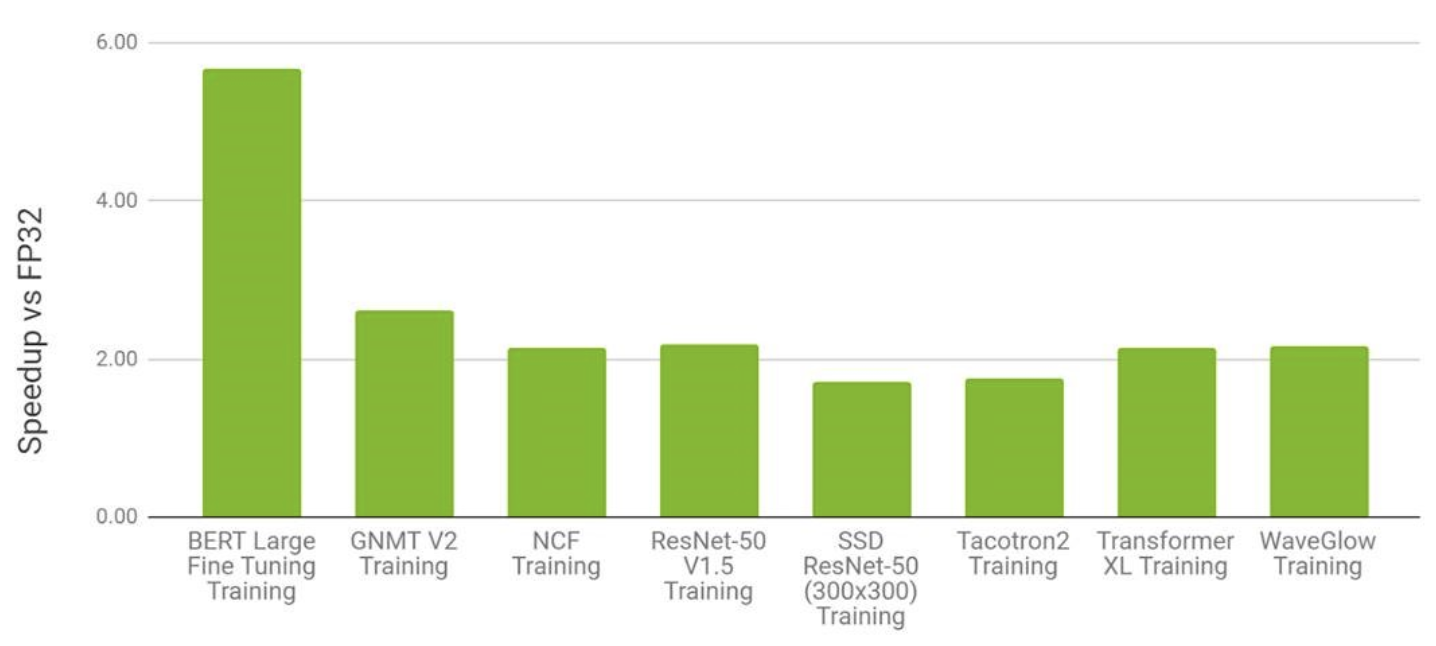
Основная идея остальных форматов — нам не нужно и 32 бита точности для успешной сходимости обучения. Чем меньше точность, тем быстрее умножение. А дальше в разных форматах мы можем по-разному уменьшать экспоненту и мантиссу, см. картинку ниже. Это влияет на диапазон представимых значений и плотность представимых чисел соответственно. Почти все современные GPU поддерживают FP16, а вот остальные форматы — как повезёт.

Финальное ускорение разное для разных моделей, но обычно минимум x1.5.
Более эффективный софт для обучения моделей
Tensorflow выпустили в 2015, PyTorch в 2016. До них были и другие специализированные библиотеки, но за ними не стояли Google и Facebook. Вот неплохая статья про это. С тех пор библиотеки избавились от самых неприятных багов, но вряд ли в них больше нет места для оптимизаций. Про накладные расходы от использования PyTorch можно почитать здесь.
Вот-вот выйдет PyTorch 2.0, который уже можно потрогать. С ним мы возвращаемся к компиляции вычислительных графов, что даёт значимые приросты в скорости. Я трогал, оно действительно быстрее.

А ещё есть специализированный софт для обучения на нескольких GPU, которого до недавнего времени почти не было:
Новые подходы и архитектуры
Недавно произошёл большой переход от рекуррентных и свёрточных сетей к трансформерам, и я сильно сомневаюсь, что трансформеры — это конечная остановка.
Есть такой бенчмарк: LRA. Он проверяет, насколько хорошо модели обрабатывают длинные последовательности, не обязательно языковые. И там выигрывают два класса моделей: по-разному линеаризованные трансформеры, обрабатывающие последовательности за линейное время вместо квадратичного, и модели, основанные на пространствах состояний. Вот вторые для меня представляют особый интерес, и они вполне могут стать наследниками трансформеров.
Если коротко, то это такие штуки из теории управления, для которых наконец нашли применение в глубоком обучении. С точки зрения теории, я не имею ни малейшего понятия, как оно работает. Почитать можно в этих статьях: Why S4 is Good at Long Sequence: Remembering a Sequence with Online Function Approximation и The Annotated S4.
С точки зрения практики, это скорее рекуррентная сеть, матрицы переходов которой учатся как свёрточные сети. При этом оно в инференсе быстрее трансформеров, и лучше по качеству. Однако же это всё не имело смысла без наличия прямых экспериментов с машинным переводом или экспериментов по transfer learning’у. Но теперь и они есть!
Возвращаясь к оригинальному вопросу, ChatGPT сам по себе пример масштабирования не по вычислениям. Переход от GPT-3 к InstructGPT и ChatGPT потребовал дай бог 2% от вычислительных ресурсов от изначального обучения GPT-3. Чем качественнее данные, тем меньше их нужно для обучения.
Есть ли примеры внедрения генеративных нейросетей?
TL;DR: их много, но пока недостаточно из-за новизны технологии.
Тут всё одновременно очень просто и очень сложно. Просто — потому что в сфере развлечений генеративные сети уже осели очень прочно. Сложно — потому что вне сферы развлечений довольно мало успешных кейсов, в основном потому, что технологии очень новые. DALL-E вышла в январе 2021 года, её годный открытый аналог, Stable Diffusion, выпустили в августе 2022. ChatGPT вышла в ноябре 2022, а её открытого аналога до сих пор нет.
Спустя полгода с выпуска SD, она везде. Я лично знаю людей в компаниях, разрабатывающих игры, которые используют Midjourney для создания эскизов для художников. Появляется всё больше клипов, которые используют MJ/DALL-E/SD. С каких пор полгода — это «медленное внедрение»?
Примеры клипов
Инфраструктура вокруг SD просто божественна, что значительно упрощает работу людям без опыта в машинном обучении:
Self-hosted веб-интерфейс для SD: https://github.com/AUTOMATIC1111/stable-diffusion-webui
Библиотека тюнов SD: https://civitai.com/
Поиск по картинкам, которые сгенерировала SD: https://lexica.art/
Один из многих генераторов затравок: https://promptomania.com/prompt-builder/
Что касается текстов, на основе API GPT-3 работают сотни стартапов, но это довольно далеко от того, что бы я мог назвать реальным внедрением. По сути единственные, кто сейчас на полную катушку извлекает пользу от генеративных трансформеров — это поисковики. И я сейчас не про чат-бот в Bing’е, а скорее про вопросно-ответные сниппеты, карточки с информацией, тексты рекламных объявлений и вот это всё. Если бы не ChatGPT, корпорации так бы и продолжили молча использовать генеративные сети для агрегации и красивого представления контента.
Инфраструктура тоже постепенно появляется:
Открытый проект по воспроизведению ChatGPT (как SD был для DALL-E): https://open-assistant.io/
Библиотека для цепных вызовов языковых моделей и внешних API: https://github.com/hwchase17/langchain
Self-hosted веб-интерфейс для языковых моделей: https://github.com/KoboldAI/KoboldAI-Client
Сервис для создания чат-ботов, имитирующих разных персонажей: https://beta.character.ai/
А ещё не стоит забывать про автодополнение для программистов! Copilot — вполне успешный продукт, которым пользуются сотни тысяч людей. Я бы тоже пользовался, но мне пока лень настраивать плагин для vim’а, да ещё и деньги платить.
Кто виноват и что делать?
TL;DR: проблема есть, проблему решаем.
Как на самом деле звучат вопросы: когда ChatGPT скажет N-слово или склонит кого-то к <ркн>, кто будет виноват? Можно ли такое предугадать? Можно ли сделать так, чтобы после инцидента она больше никогда так не делала? Нужно ли для этого переучивать нейросеть?
На большинство вопросов сейчас нет хороших ответов, но мне всё это видится скорее техническими трудностями, а не какими-то фундаментальными ограничениями. Во-первых, все вопросы выше касаются real-time ответов. Если говорить о не real-time задачах, то можно прикручивать какую угодно модерацию, хоть автоматическую, хоть ручную. Оценивать тексты вручную всё равно дешевле, чем вручную их писать, поэтому в этом будет смысл.
Во-вторых, над этим работают. Здесь я остановлюсь на трёх вещах:
RLHF, reinforcement learning from human feedback — метод обучения, который позволяет тюнить языковую модель на отранжированном людьми списке возможных продолжений диалога. Ключ в том, что модель учат тому, что генерировать НЕ надо, в отличие от классического языкового моделирования, в котором модели учатся только на положительных примерах. Именно благодаря ему ChatGPT так хороша и может переобучаться хоть каждый день.
CoT, chain of thought — метод формирования затравок для языковых моделей, когда кроме собственно примеров выполнения задачи используются ещё и пошаговые объяснения решений. С такими затравками модель не только тоже пишет объяснения, но ещё и повышается качество финальных ответов.
Цепные вызовы, chaining — способ интегрировать несколько вызовов разных языковых моделей или внешних API. Например, известно, что языковые модели общего назначения плохо складывают большие числа. Так давайте вместо сложения научим их вызывать для этого калькулятор или интерпретатор Python.
А ещё есть вторая категория вопросов: являются ли картинки от SD и тексты от ChatGPT плагиатом? Насколько легально их использовать? Кто владеет авторскими правами на сгенерированное изображение или текст? На эти вопросы нам, как человечеству, ещё предстоит ответить.
Финал

На заре GPT-1 я тоже был крайне скептично настроен ко всей этой движухе вокруг zero-shot/few-shot инференса, способностей языковых моделей и их масштабируемости. Мне всегда больше нравились encoder-only и encoder-decoder модели. Генерация картинок по тексту тогда тоже не впечатляла. Но год за годом, раз за разом оказывалось, что всё это просто работает. А когда что-то просто работает, это тяжело игнорировать. Можно долго рассуждать какие нейросети тупиковые, как увеличение количества параметров не приближает нас к сильному ИИ, но цифры бенчмарков говорят сами за себя. Пойду поработаю, пока в этом есть смысл.
Писал Илья Гусев, специально для @betterdatacommunity.

