Ситуация, когда в IT-инфраструктуре работает множество монолитных систем сторонних вендоров, далеко не новая. И нередко при попытках подружить монолит с собственными решениями возникают проблемы. В посте рассказываем, как может помочь в решении этих проблем переход на микросервисы и как работать при этом с данными.
Внедрение в филиалах системы «Единого биллинга» и использование микросервисной архитектуры для создания внешней «обвязки» к биллингу ускорили вывод на рынок федеральных инициатив. Но из-за практически восьмикратного роста нагрузки возникли новые сложности. Когда каждая из подсистем обслуживает более 80 миллионов абонентов, это неизбежно. Технологическое окно для проведения работ сократилось до двух часов в сутки, к тому же появились интегрированные в биллинг продукты, требующие гарантированного доступа к базе данных: банковская карта, Мегафон ТВ и Real Time Campaining. Повышение нагрузки на СУБД давало деградацию производительности, и эту проблему пришлось оперативно решать.
Как пилили «монолит»?
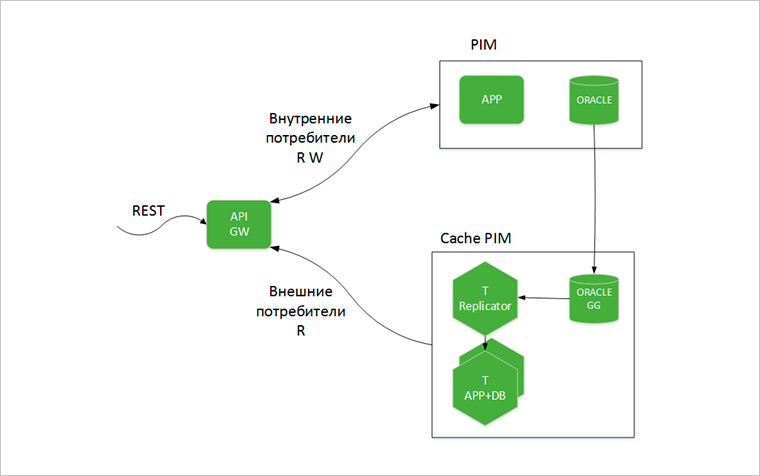
«Единый биллинг» МегаФона — построен по принципу распределенной архитектуры. Это система, которая имеет отдельные черты микросервисной архитектуры: полное покрытие API, доменное деление, свой бизнес-контекст и свои базы данных у каждой подсистемы. При этом в API невозможно изолировать слой работы с БД и, самое главное, в монолите нельзя заменить произвольную функцию (сервис) собственной. Вариант был только один: строить слой быстрых кэшей, поднимать туда данные из мастер-систем и переводить на эти кэши хотя бы нагрузку по чтению. Разработчик биллинга далеко не везде встраивает в свои продукты нужную функциональность, поэтому глубоко внедриться в монолит не получилось: собственное решение должно было встать как бы сбоку, не влияя на мастер-системы.
В качестве основного хранилища в биллинге используется Oracle, поэтому вполне логичным шагом стало получение данных из шины диспетчера сообщений при использовании в качестве асинхронной очереди RabbitMQ. Первый пилотный проект дал прекрасный результат (низкое влияние на мастер-систему и простоту реализации), но на втором история закончилась: не все события попадают в RMQ, и ждать нотификации приходится достаточно долго.
Это решение оказалось не универсальным, поэтому стоило попробовать получать данные из базы Oracle с использованием триггеров. Они, увы, потребовали внесения изменений в логику приложения, к тому же дали дополнительную точку отказа и сильно нагрузили мастер-систему.

Помимо испробованных, у Oracle остался только один не требующий лицензирования механизм репликации — CQN (Continuous Query Notification). Он не предполагает запуска дополнительных инстансов Oracle, довольно прост в использовании и позволяет получать все события из мастер-базы. С CQN возникла та же проблема, что и в предыдущем случае: выросла транзакционная нагрузка на мастер-базу из-за необходимости создавать таблицу с изменениями и чистить ее. Плюс под капотом там все-таки Oracle Advanced Queue, т.е. выросла нагрузка и на внутренние очереди Oracle.
С этим можно было бы жить, но на партиционированных таблицах механизм CQN некорректно работает, если вы одним коммитом закрываете более ста изменений. Все труды по репликации в этом случае пропадают, а транзакционная целостность сразу теряется.
Пришлось даже открыть на эту тему кейс в Oracle, но поддержка разработчика СУБД не смогла решить проблему, и от технологии отказались в пользу Golden Gate в режиме down stream integration mode. С его помощью изменения в базе Oracle можно выгружать в потоковом режиме при практически нулевой дополнительной загрузке мастера. Из минусов последнего решения стоит упомянуть необходимость дополнительных инстансов и необходимость лицензирования, но это единственный вариант, который гарантирует транзакционную целостность (связка SCN+XID контролирует, в какой точке репликации мы находимся в текущем моменте) и низкую дополнительную нагрузку на основные БД.
Наверное, при желании можно найти и другие пути, но Golden Gate оказался универсальным решением для биллинга МегаФона.
Почему Tarantool?

В качестве быстрого кэша рассматривались разные нереляционные СУБД, но лучшее соотношение цены и качества дал Tarantool: у коллег из Mail.ru по нему наработана мощная экспертиза, есть большое комьюнити и поддержка в режиме 24×7.
Tarantool хорошо показал себя при нагрузочном тестировании, а кроме того, в нем есть свой сервер приложений, позволяющий реализовать логику любой сложности (не только для репликации, но и для будущих микросервисов).
Чтобы написать совместно с коллегами из Mail.ru на Lua парсер trail-файлов Golden Gate, не потребовалось никаких дополнительных инструментов. Вначале были попытки сделать репликацию в Tarantool непосредственно из Oracle (благо, коннектор есть), но из-за дополнительной нагрузки на мастер-систему от этого варианта также отказались.
Продуктовая витрина
После внедрения «Единого биллинга» в департаменте Бизнес-систем была создана структура R&D, в задачи которой входит разработка микросервисов. Необходимость перехода на микросервисную архитектуру для ускорения вывода продуктов на рынок была очевидной, так что это стало логичным шагом.

У нас было 2 kubernetes кластера, 75 нод, 5 мастеров, полпетабайта стораджа и куча микросервисов на го, пхп, питоне, руби, джаве, эрланге и всем таком разной степени упоротости. Не то, чтобы это все было нужно для проекта, но раз начал строить микросервисную архитектуру, то иди в своем увлечении devops-ом до конца. Единственное, что меня беспокоило, — это docker образы с systemd. В мире нет никого более беспомощного, безответственного и безнравственного, чем человек, запускающий systemd в docker-е. И я знал, что довольно скоро мы в это окунемся.
Одним из первых проектов R&D стала продуктовая витрина абонента. Этот «небольшой» микросервис имеет всего два метода, но работает с огромным количеством записей в кэше. Он реализует новую модель, когда все подключенные у абонента тарифы и услуги называются продуктами.
Для создания витрины было решено построить быстрый кэш на Tarantool, но возникла проблема с холодным прогревом: в хранилище требовалось загрузить 2,5 ТБ сырых данных из Oracle, или порядка 10 миллиардов записей. При этом в кэш загружаются только горячие (актуальные) данные, т. е. требовалось отсечь всю историю (неактуальные статусы). В Oracle пришлось сделать некий SELECT с определенными условиями (применить WHERE).
Оказалось, что в этом случае на таблицах с миллиардами записей чтение по локально-партиционированным индексам обрушилось в пользу обычного use hash по партициям: время холодного прогрева кэша измерялось неделями при практически стопроцентной загрузке процессоров серверов.
Попытки оптимизировать запросы ничего не дали, на больших объемах сработал только один вариант — пришлось убрать WHERE, и Oracle полетел.
Решение оказалось простым: нужно было взять Golang Oracle Driver, поставить Prefetch = 1000 и Tread = 10, а каждый тред натравить на отдельную sub-партицию. Главное здесь — никаких WHERE. В каждом SELECT выбираются только нужные поля, таким образом часть метаданных можно отфильтровать уже на этом этапе, но основная логика фильтрации уходит на приложение-репликатор (спасибо, что в Tarantool есть Lua).
Нагрузка на CPU сразу упала. Понятно, что в таком варианте утилизируется сеть и ввод-вывод, но это неизбежное зло — нужно иметь некоторый запас. Из Oracle удалось выжать от 600 000 до 1 000 000 записей в секунду, а время холодного прогрева кэша сократилось до 19 часов: выгрузка в CSV занимала 5 часов, загрузка в Tarantool — 8 часов, проигрывание накопившихся логов Redo — 6 часов. Вставка в Tarantool (это кластер) с фильтрацией данных на лету шла со скоростью 200 000 записей в секунду, и объем отфильтрованных данных, которые загружались в кэш, составлял 1,1 ТБ.
Как работает кэш?
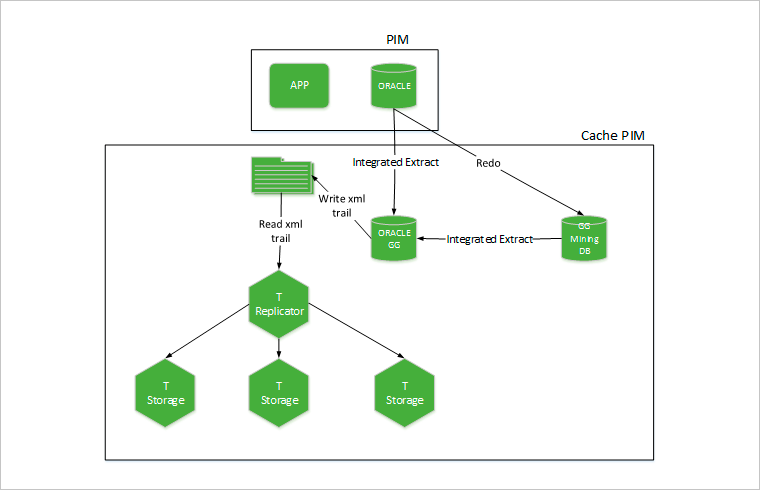
Вначале запускается инкрементальная репликация: физически интегрированный экстракт GoldenGate, который практически в режиме реального времени принимает изменения из майнинговой базы и складывает данные в виде trail-файлов формата xml для дальнейшего парсинга репликатором — инстансом Tarantool с определенной ролью. На этом этапе данные не загружаются в продуктовый кластер. Потом запускается процесс импорта из Oracle в CSV и данные загружаются в Tarantool с ролью импорта, попутно проходя фильтрацию.
Когда импорт закончен, начинается процесс загрузки данных в рабочий кластер на Tarantool. Чтобы не нагружать роутер кластера, вычисление нужного шарда переносится в приложение-импортер. После завершения загрузки запускается репликатор и начинается проигрывание накопившихся xml-файлов из Golden Gate с изменениями (проигрывание Redo). Физически это код на языке Lua? в основу которого положен паттерн Pipes and Filters.
Принцип его работы с данными — загрузка информации из trail-файлов, подготовка, трансформация, нормализация, роутинг и применение транзакции на шарде. Когда достигается отставание кэша от мастер-системы в 1–2 минуты, API Gateway переключает нагрузку на чтение для внешних потребителей на кэш.
Поскольку кэш получился объемным, приходится держать кластер на Tarantool в двух дата-центрах для геораспределенного резерва — в сумме там работает 27 шардов и 6 роутеров. Для оптимизации данные по одному абоненту собираются на одном шарде, тем самым удается избежать Map Reduce — обход всего кластера для выполнения запроса уже не нужен.
Это несколько усложняет запись, но дает прекрасную производительность на чтение и позволяет делать быстрые кэши для монолитных систем сторонних разработчиков, которые для заказчика являются черным ящиком.
Что дальше?
Первый проект с продуктовой витриной показал успешность подхода, но в «МегаФоне» решили не останавливаться на достигнутом. Вполне логичным развитием стали попытки напрямую загружать поток данных в Tarantool, минуя CSV — альфа-версия решения реализована с помощью механизма userexits из GoldenGate и проходит тестирование. Разумеется, Tarantool не заменяет Oracle, а дополняет его. Количество запросов к основной базе данных продолжает расти, поэтому задача снижения нагрузки на мастер-систему в обозримом будущем останется актуальной.
Кроме того, необходимо разработать механизм контроля консистентности данных в основной базе и в кэше на Tarantool. В Oracle для этих целей используется специальный продукт Veridata, но со сторонними СУБД он не работает. Также будут созданы тесты для отслеживания изменений структуры таблиц мастер-базы и автоматической корректировки на стороне Tarantool.
Постоянно увеличивается и количество микросервисов. Пилот с R&D оказался успешным, и теперь в Нижнем Новгороде появилась настоящая Фабрика микросервисов, где уже работает свыше 50 сотрудников. Сейчас там строится новый офис и идет массовый набор специалистов.
Фабрика работает по гибким методологиям Agile, по принципу кросс-функциональных DevSecOps команд, используя передовые инструменты разработки и CI/CD, но это уже совсем другая история, которую мы расскажем в следующих статьях.
P.S: Если тебя манят интересные задачи, современный технологический стек, культура стартапа и остальные приятности, то фабрика микросервисов ждет тебя.