Развитие искусственного интеллекта, как и его восприятие человеком, прошло сложный путь и продолжается на наших глазах. ИИ давно вырос из коротких штанишек простого помощника человека и все активнее заявляет о своих правах. Стартующий в 2019 году технологический конкурс Up Great ставит перед собой долгосрочную амбициозную цель — создать универсальный ИИ, который будет обучаться вместе с людьми в ходе совместной деятельности. А это значит, что пришло время окончательно решить, кем является ИИ для человека и кем человек является для ИИ.
Шахматы
Одиннадцатое мая 1997 года. Нью-Йорк. Мир шахмат изменился навсегда. Машина победила человека. Стало понятно: игра уже не будет прежней — машина сильнее. Спустя годы Гарри Каспаров поедет по миру и в лекциях будет вспоминать о том, какими были шахматы и какими стали сегодня.
«Играя с машиной, ты словно играешь с пятиклассником — только в конце ты проигрываешь», — вспоминает он. Типичная игра компьютера отличается от человеческой: это прежде всего тактика и стратегия, основанная на последовательном получении маленького и едва заметного преимущества в каждом шаге. Горизонт планирования и расчета по дереву решений у человека и машины существенно отличается. Магнус Карлсен утверждает, что видит в среднем на 15, а иногда на 20 ходов вперед (не endspiel) — современные компьютеры могут обсчитать на порядок большее число шагов. Заметим, что для создания подобной системы необходимо иметь два ключевых элемента: функцию оценки доски и алгоритм обхода дерева возможных решений.
Первый модуль говорит нам, насколько хороша данная расстановка фигур для нас, а второй, модуль поиска, используя эту функцию, смотрит на возможные N шагов вперед и пытается найти наиболее выгодный шаг. Частой эвристикой и эффективным алгоритмом поиска является альфа-бета отсечение, а также стохастический метод Монте-Карло поиска по дереву. В чем соль? Мы играем в игру min-max: мы хотим сделать такой шаг, чтобы полученная доска была оптимальна для нас, а ответный шаг был минимален. Для этого мы просчитываем все возможные ответы оппонента, рассчитывая, как на них можно максимально эффективно ответить. Для этого нам нужно перейти на глубину n+1 и заново рассчитать min-max. Повторяя эту операцию N раз, мы можем узнать оптимальное для нас состояние доски через 2*N шагов (или N наших шагов).
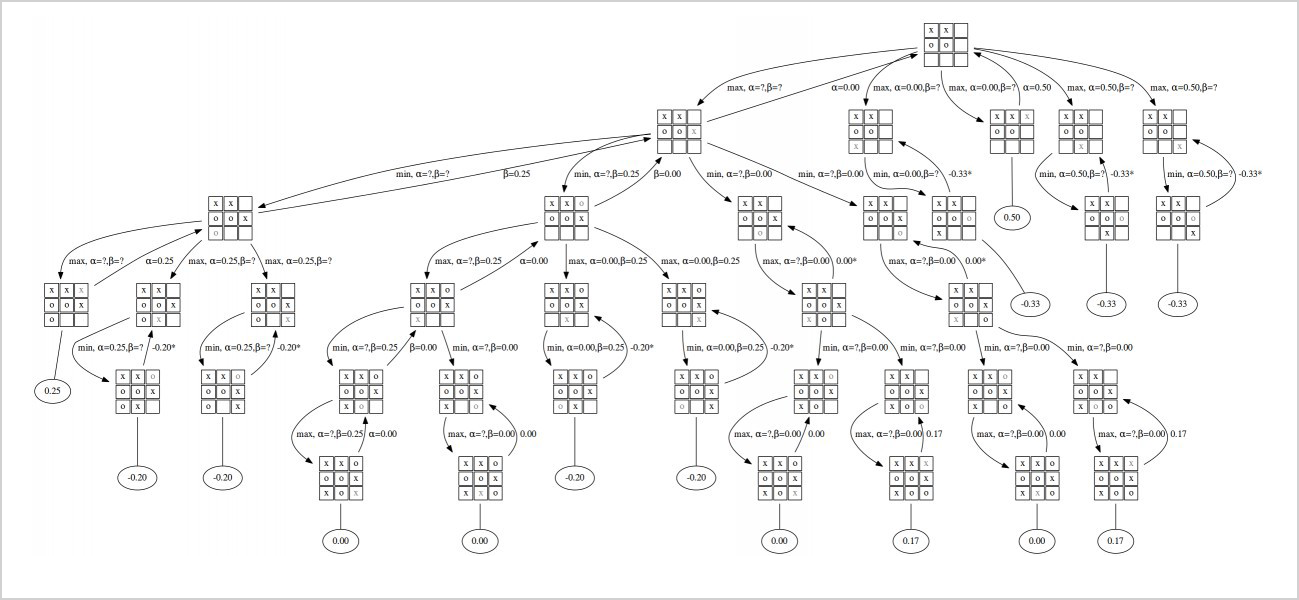

Evaluation function — как правило, набор экспертных эвристик, оценивающих качество доски для нашего игрока
Каспаров говорит, что сейчас все профессионалы тренируются с машинами: «Когда-то это было невозможно себе представить — правила игры поменялись». К сожалению, многие слепо следуют в тренировках советам машин. Как наставник Магнуса он отмечает, что прежде всего того отличает от других игроков в шахматы способность «прочувствовать» логику машины во время тренировки.
Когда-то мы учили машины «видеть» доску и «находить» лучший ответ на действия оппонента, а сейчас на основе этих алгоритмов, которые вдохновлялись видением и тактикой шахматистов и были основаны на человеческом опыте игры в шахматы, мы обучаем будущих и настоящих игроков в шахматы. Круг замкнулся?
На самом деле все куда интереснее, ведь связки «человек + машина», как правило, сильнее, чем человек или машина в отдельности. И здесь мы видим совершенно новое направление augmented intelligence. Подобные шахматы получили название advanced chess. Вышла невероятно интересная игра: взаимодействие машинной и человеческой логики.
Всегда ли машины работают на строгом расчете? Или у них есть «интуиция»?
αГо и триумф машинного обучения
Девятое марта 2016-го. Сеул. Практически никто из профессиональных игроков не верит, что легендарный Ли Седоль может проиграть машине в го — ведь это «священный Грааль» игр и самая сложная из настольных игр с открытой информацией.

На каждый шаг в шахматах есть 20 осмысленных переходов-ответов. В го их около 200. Это означает, что всего через несколько шагов число возможных комбинаций превышает число молекул в обозримой вселенной. Ниже приведен план «раскрытия» дерева возможных решений во времени (по шагам — слева направо).
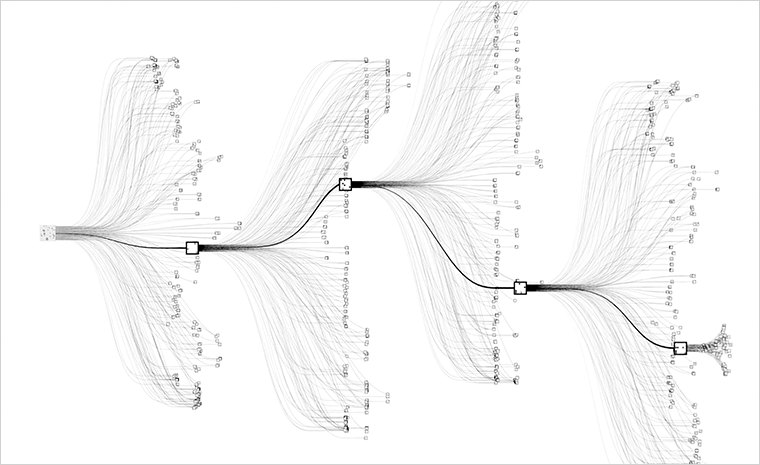
Общая стратегия, как мы видим на схеме ниже, похожа на алгоритм поиска.
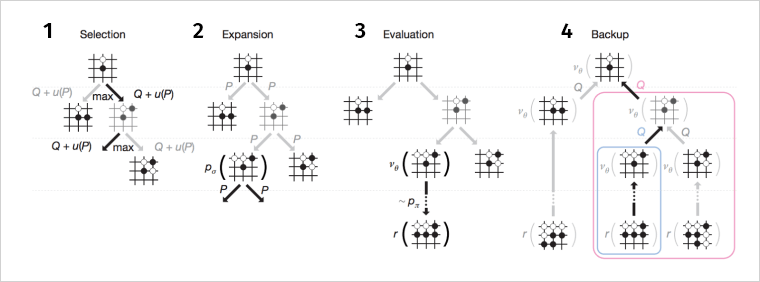
- Выбор (Selection). Симулирует обход дерева, выбирая дуги с максимальным весом Q (насколько хорош шаг).
- Раскрытие вершины (Expansion). Если вершина выбрана при обходе, она скармливается supervised learning (SL) policy network для получения априорных вероятностей возможных шагов.
- Оценка (Evaluation). Включается Reinforcement Learning стратегия, которая играет множество игр и оценивает, насколько текущая позиция хороша (условно, если белые выиграли у черных 8 из 10 раз начиная с данной расстановки, то вес позиции — 0,8).
- Backup. Приписываем вес всему дереву и продолжаем поиски.
Нейросети играют роль «интуиции» машины. Если в случае с шахматами в деле строгая логика, то здесь просчитать ходы невозможно.
В документальном фильме про AlphaGo мы видим, как система играет на 5-й линии. Шаг 37. Комментатор говорит, что это ошибка человека за столом. Приходит ответ системы: «Нет, это не ошибка». Корея замирает. Эксперты меняются в лице. Ли уходит покурить. Мир Го перевернулся навсегда.

Шаг 37 AlphaGo — игра на пятой линии
Это был всего лишь расчет, точный и кропотливый. Если Каспаров говорил, что машина — это школьник-пятиклассник, то в этот момент пятиклассником оказался сам мир.
В одной-единственной игре, возможно, последней, когда человек победил машину в Го, Ли Седоль делает свой 78-й ход. Машина говорит, что такой ход фактически невозможен — так никто никогда бы не пошел. Этот ход назовут «прикосновением Бога».

Шаг 78: Ли Седоль — «прикосновение бога»
Ход 37 был всего лишь расчетом, а ход 78 — откровением, актом человеческой интуиции, творчества и даже искусством, но без хода 37 не было бы и хода 78. Не делает ли это его чем-то большим, чем просто расчет? Не узнали ли мы о себе что-то, чего никогда не узнали бы без машин?
Может быть, это станет переходом из фазы «человек против машины» в фазу «человек и машина»?
Игры: что дальше?
Почему игры вызывают такой интерес? Сейчас понятно, что для того, чтобы решать реальные жизненные задачи, нужно абстрактное мышление и математика, что почти не требует общих знаний о физическом мире. Возможностей компьютеров пока (пусть и есть какие-то примеры) не хватает для моделирования всего мира. А игры — это интересная абстракция части существующего мира, и в них можно играть эффективно. Именно поэтому такая ситуация стала одним из бенчмарков развития искусственного интеллекта.
Сейчас мы видим, как DeepMind, OpenAi и многие другие покоряют новые горизонты.
На подходе системы, которые могут ориентироваться в пространстве и взаимодействовать с друг другом (например, Dota и StarCraft), используя совершенно разные стратегии, тактики и доступные ресурсы — безусловно, все это необходимо для применения подобных систем в реальной жизни.
Интересный инсайт: в такой игре, как StarCraft, обладая возможностью быстро и безошибочно контролировать и координировать действия, простые линейные юниты побеждают даже самые сложные комбинации созданий и существ. Это поможет упростить дизайн сложных инженерных систем, которые мы создаем сейчас.
Ну а DeepMind просто натренировал идеально скоординированную армию роботов-убийц — нет никаких поводов для волнений.
Реальная жизнь и взаимное обучение с ИИ: умные помощники
Стоит нам произнести: «Alexa Spotify Random Access Memories by Daft Punk», как заиграет хорошая музыка.
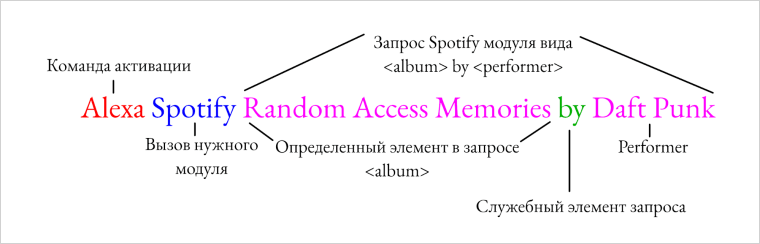
А тем временем сложилась целая цепочка решений, принятых несколькими разными системами искусственного интеллекта. Первый слой — голосовой модуль — преобразовал записанный звук в отдельные слова. Затем внутренняя система обнаружила команду активации.
Выделим ключевые аспекты процесса:
- Команда активации — Alexa;
- Команда выбора модуля — музыкальный модуль Spotify;
- Spotify query template matching <album> by <artist> — тут подсистема поняла, что у нас запрос вида <music> by <performer> и что в данной ситуации <music> является альбомом, а <performer> — группой.
И тут случается что-то невероятное. Сначала мы учим помощника понимать человеческую речь, общаясь с ним так, как с обычным человеком, но потом незаметно для себя мы переходим на искусственный язык запросов.
Кому-то пример с голосовым помощником может показаться надуманным (pun intended), ведь совсем не обязательно пользоваться системой в духе Алексы или Алисы. Но автоматические голосовые системы уже повсеместно внедряются для помощи человеку. Рассмотрим, например, голосовой помощник «Аэрофлота». Допустим, что нам нужно срочно вернуть билеты в связи с форс-мажорными обстоятельствами. Как только мы дозвонимся до диспетчерской, автомат попросит нас сообщить цель звонка — по сути, мы видим (концептуально) ту же систему, что и в случае с Алексой, только более специализированную. Мы произносим что-то похожее на «вернуть билеты срочно» и начинаем говорить с ботом, используя его же функциональные термины («категория» + «модификатор»), вставляя ключевые «поисковые» слова в простой язык запросов. И это, безусловно, эффективно, т. к. экономит время операторов первой линии, но возвращает нас к уже прозвучавшему ранее тезису: сначала мы обучаем машины, а потом сами машины учат нас, как с ними говорить. Главное здесь — помнить, что человек решает, что, как и зачем происходит.
В связи с этим появляются вопросы: не станет ли наш язык в результате интеграции с системами искусственного интеллекта более структурированным? Должны ли мы вообще говорить с ИИ так, как говорим с ним сейчас, или пусть боты подчиняются нашему интуитивному и эмоциональному языку, самостоятельно переводя его в логичную, графовую форму? И не это ли имел в виду Хомский в своей универсальной грамматике?
Умные помощники: граф знаний
Как именно Алекса поняла, что Random Access Memories — это альбом, а не песня? Как правило, подобные системы используют knowledge graphs — представление знаний в логической форме.

Таким образом, мы зафиксировали, как должны быть представлены знания, чтобы система могла их извлечь. Вернемся к основному тезису: сначала человек научил систему, как представлять знания, а потом стал следовать машинному представлению, чтобы получить эти данные из системы.
Умные помощники: Natural Language Processing

Картинка из OpenAI: better language models
Но как система идет от набора звуков к буквам и смыслам, которые за ним стоят? Идеи в основе таких систем, как Word2Vec, BERT (RoBERTa, etc), восходят своими корнями еще к Людвигу Витгенштайну: «Значение слова — это его употребление в контексте» (Die Bedeutung eines Wortes ist sein Gebrauch in der Sprache).
Система изучает контексты и может оперировать с ними, как с алгебраическими величинами:

Особенность BERT в том, что эта технология умеет учитывать так называемые правые и левые контексты — например, для слова bank ниже:

Таким образом, каждое слово представляется в виде совокупности контекстов, в которых оно может использоваться. В частности, в машинном представлении контекст — это N-мерный вектор, а значит, слово может быть представлено в виде радиус-вектора в N-мерном пространстве, например:

Подобным представлением и пользуются многие NLP-системы для поиска и анализа большинства запросов, а также ответов на вопросы. Например, если задать Алексе вопрос: «Who was the president before Obama?», она сможет распознать контекст выборов в США даже без упоминания страны, а также понять, что нам необходим человек, бывший президентом до личности, упомянутой в запросе, и корректно ответить: «Barack Obama was preceded as the president United States by the George W. Bush».
Продолжать тему можно бесконечно, но, наверное, актуальный путь ее развития — это движение в сторону плотного взаимодействия человека и ИИ. Еще одним шагом на пути прогресса в этой отрасли станет технологический конкурс Up Great. Похоже, вопрос о роли ИИ в жизни человека постепенно находит свое окончательное решение.