
Представьте, что вы можете подставлять данные в строки и при этом точно знать, что именно туда попадет, причем еще до того, как строка станет таковой. И чтобы все было под контролем: можно было замаскировать чувствительные данные в логах, безопасно собрать конфигурацию или защитить команду от инъекции на уровне структуры.
В Python 3.14 появился новый инструмент — t-строки (шаблонные строки). На первый взгляд они выглядят как еще одна вариация f-строк. Но на самом деле это принципиально другой механизм: строка больше не собирается автоматически, а передается разработчику в виде структуры, где отдельно хранится статический текст и отдельно — значения для интерполяции.
Меня зовут Алексей Макаров, я инженер по информационной безопасности в Лиге Цифровой Экономики. В этой статье разберемся, как работают t-строки в Python 3.14, чем они отличаются от привычных f-строк и в каких сценариях действительно помогают писать более безопасный код, а где использовать их не стоит.
Зачем вообще понадобились t-строки
В Python f-строки давно стали стандартом де-факто для форматирования строк. Они лаконичны, быстры и позволяют встраивать в строку практически любые выражения. Но именно эта простота и делает их потенциально опасными при работе с недоверенными данными.
Проблема в том, что интерполяция* в f-строках происходит немедленно и необратимо. В момент выполнения кода значения подставляются в строку напрямую, без возможности перехватить этот процесс или обработать данные до объединения в итоговый текст. В результате разработчик теряет контроль над тем, как именно пользовательский ввод оказывается внутри строки.
Скрытый текст
* В контексте программирования интерполяция строк — это механизм подстановки значений переменных или результатов выражений в текстовую строку. Например, в f"Hello, {name}" значение переменной name интерполируется в строку.
На практике это может приводить к целому набору типовых уязвимостей:
● SQL injection, когда пользовательский ввод напрямую встраивается в SQL-запрос;
● XSS, если данные без очистки попадают в HTML;
● OS command injection при формировании команд для оболочки;
● утечки чувствительных данных, например паролей, токенов или номеров карт в логах.
Формально для большинства этих проблем уже существуют стандартные решения: параметризованные SQL-запросы, автоматическое экранирование в шаблонизаторах, отказ от shell=True в subprocess. Однако эти механизмы работают только в своих конкретных контекстах и не всегда подходят для задач, где требуется гибко управлять подстановкой данных в строки.
Например:
● при логировании нужно маскировать отдельные поля, но не всю строку целиком;
● при генерации конфигурационных файлов важно заранее валидировать значения;
● при формировании команд оболочки корректно экранировать только пользовательский ввод, сохраняя структуру команды.
Попытки решать такие задачи через экранирование строки обычно оказываются недостаточными. Универсального экранирования не существует: правила безопасности зависят от контекста — SQL, HTML, shell, конфигурационный файл или лог. Когда строка уже собрана, определить этот контекст и безопасно обработать данные становится значительно сложнее.
Именно эту проблему и пытаются решить t-строки, появившиеся в Python 3.14. В отличие от f-строк, они не превращаются в готовый текст автоматически, а сохраняются как структура, в которой статические части строки и значения для интерполяции разделены. Это позволяет разработчику самостоятельно контролировать процесс сборки строки и применять нужную обработку к каждому вставляемому значению.
Теперь разберемся, как именно работают t-строки и в каких сценариях они действительно помогают писать более безопасный код.
Как мы форматировали строки в Python раньше (и где здесь подвох)
За все время существования Python разработчики использовали несколько способов форматирования строк. С точки зрения синтаксиса и удобства они сильно отличаются, но с точки зрения безопасности у них есть общее ограничение: значения подставляются в строку напрямую, без возможности вмешаться в процесс интерполяции.
Оператор %
Самый ранний способ форматирования строк в Python, унаследованный из языка C:
"Hello %s" % name "User %s has %d points" % (name, score)
Значения буквально копируются в строку без каких-либо проверок или валидации.
Плюсы:
● простота;
● совместимость со старым кодом.
Минусы:
● легко ошибиться с количеством и порядком аргументов;
● плохая читаемость при большом числе подстановок;
● отсутствие контроля над типами и содержимым данных.
С точки зрения безопасности этот способ не дает никаких инструментов для анализа или обработки вставляемых значений.
Метод .format()
Более современный и читаемый механизм форматирования:
"Hello {}".format(name) "User {name}".format(name=name) "User {0} has {1} points".format(name, score)
Он поддерживает позиционные и именованные параметры и дает больше гибкости при форматировании.
Однако принцип работы остается тем же: интерполяция происходит сразу, и значения безусловно встраиваются в итоговую строку. Как и в случае с оператором %, перехватить или модифицировать подстановки до объединения строки невозможно.
f-строки
f-строки стали наиболее популярным способом форматирования благодаря лаконичному синтаксису и высокой производительности:
f"Hello {name}" f"User {name} has {score * 2} points"
Внутри f-строк можно выполнять выражения и вызывать функции, а сама интерполяция максимально оптимизирована на уровне компилятора.
Именно поэтому f-строки одновременно самые удобные и самые опасные. Интерполяция выполняется немедленно и необратимо, без какого-либо контроля над тем, какие значения и в каком виде попадают в строку. Разработчик получает уже готовый текст и больше не может отличить статическую часть строки от данных, пришедших извне.
При работе с недоверенными данными это становится критичным ограничением. Любая ошибка — и пользовательский ввод может оказаться внутри SQL-запроса, HTML-кода, команды оболочки или лога без необходимой обработки.
Так, все традиционные способы форматирования строк в Python объединяет одно фундаментальное свойство: строка формируется сразу, а безопасность полностью зависит от того, был ли заранее правильно обработан каждый вставляемый фрагмент. Именно отсутствие контроля над процессом интерполяции и стало причиной появления нового подхода — шаблонных строк в Python 3.14.
Что такое t-строки в Python 3.14
Исходя из официальной документации, шаблонные строки — это новый механизм для пользовательской обработки строк. Шаблонные строки используют знакомый синтаксис f-строк, но, в отличие от f-строк, возвращают объект, представляющий статическую и интерполированную части строки, до их объединения в одну строку.
Чтобы написать t-строку, нужно использовать префикс "t" вместо "f":
>>> variety = "Stilton" >>> template = t"Try some {variety} cheese!" >>> type(template) <class 'string.templatelib.Template'>
Шаблонные объекты предоставляют доступ к статическим и интерполированным частям строки до их объединения. Для доступа к частям интерполированной строки можно использовать функцию list:
>>> list(template) ['Try some ', Interpolation('Stilton', 'variety', None, ''), ' cheese!']
Написать код для обработки интерполированной строки легко. В качестве примера создадим функцию, которая отображает статические элементы в нижнем регистре, а интерполированные экземпляры — в верхнем:
from string.templatelib import Interpolation def lower_upper(ustring): parts = [] for part in ustring: if isinstance(part, Interpolation): parts.append(str(part.value).upper()) else: parts.append(part.lower()) return "".join(parts) name = "Lefen" template = t"Mister {name}" assert lower_upper(template) == "mister LEFEN"
Поскольку шаблонные строки различают статические строки от интерполированных во время выполнения, они могут быть полезны для очистки пользовательского ввода. Код обработки шаблона может обеспечивать большую гибкость, например, более сложная функция может принимать dict HTML-атрибуты непосредственно в шаблоне.
from string.templatelib import Interpolation def html(ustring): parts = [] for part in ustring: if type(part) == str: parts.append(part) elif isinstance(part, Interpolation): if type(part.value) == dict: for key, value in part.value.items(): parts.append(f"{key}='{value}' ") print("".join(parts)) return "".join(parts) attributes = {"src": "limburger.jpg", "alt": "lovely cheese"} template = t"<img {attributes}/>" assert html(template) == "<img src='limburger.jpg' alt='lovely cheese' />"
Код обработки ошибок не ограничивается возвратом результата только в виде строки. Более продвинутый вариант может возвращать пользовательский тип, предоставляющий структуру, подобную DOM.
С помощью шаблонных строк разработчики могут писать системы, которые очищают SQL команды прежде, чем отправлять их как запрос в БД, выполняют безопасные операции оболочки, улучшают ведение журнала, используют современные идеи в веб-разработке (HTML, CSS и т. д.).
Как использовать шаблонные строки в разработке кода
Так, новый строковый префикс t служит для определения шаблонных строковых литералов. Эти литералы преобразуются в новый тип Template, находящийся в модуле стандартной библиотеки string.templatelib.
Шаблонные строки имеют возможность вложения шаблонных строк в интерполяции, а также возможность использования всех доступных кавычек (', ", ''' и """). Как и другие строковые префиксы, t-префикс должен быть непосредственно перед кавычками. Префиксы поддерживаются как в нижнем регистре t"", так и в верхнем T"".
При создании t-строки образуется объект типа Template с атрибутами strings и interpolations. Атрибуты обеспечивают доступ к строковым частям и любым интерполированным строкам. Тип Interpolation остается неизменяемым. Его атрибуты не могут быть переназначены.
Атрибут value представляет собой преобразованный результат интерполяции:
name = "Alexey" template = t"Hello, {name}" template.interpolations[0].value
Атрибут expression содержит исходное имя литерала:
name = "Alexey" template = t"Hello, {name}" template.interpolations[0].expression
Превратим шаблон в обычную строку:
from string.templatelib import Interpolation def make_string(ustring): parts = [] # Список для будущего заполнения итоговой строки for item in ustring: if isinstance(item, str): parts.append(item) # Заносим в список строку else: parts.append(str(item.value)) # Заносим в список шаблонную строку return "".join(parts) first_name = "Alexey" last_name = "Makarov" ustring = t"Hello, {first_name} {last_name}!" print(make_string(ustring))
Используем структуру шаблона для логирования: извлечем не только значения, но и имена переменных.
from string.templatelib import Interpolation def make_string(ustring): parts = [] for item in ustring: if isinstance(item, str): parts.append(item) else: parts.append(str(item.value)) return "".join(parts) def log_template(ustring): values = { interp.expression: {interp.value: type(interp.value)} for interp in ustring.interpolations } message = make_string(ustring) return f"[LOG] {message} | data: {values}" data_test = [47, "12", True] for value_data_test in data_test: print(log_template(t"Result: {value_data_test}"))
Функция log_template формирует словарь из структуры шаблонной строки переменной ustring, затем сама переменная ustring обрабатывается функцией make_string и возвращает готовую строку в переменную message, после выводится на экран переменная ustring и ее структура.
Почему t-строки полезны для безопасной разработки
t-строки были созданы как механизм, который делегирует интерполяцию разработчику: вместо того чтобы сразу «склеить» строку, t-строка возвращает структуру, где статический текст и подстановки разделены. Это дает возможность обработать каждое значение до объединения — замаскировать, проверить, закодировать или отклонить.
Разберем три случая, где t-строки помогают писать более безопасный код.
Маскирование чувствительных данных в логах
Одна из типовых задач — не допускать попадания чувствительных данных в логи в открытом виде. С f-строками это сделать сложно, потому что интерполяция происходит сразу: как только строка сформирована, отличить «что было текстом» и «что было пользовательским значением» уже нельзя.
С t-строками можно обработать каждую интерполяцию отдельно — еще до сборки строки. В примере из фактуры маскирование реализовано функцией mask(), которая проходит по шаблону и меняет только те значения, которые распознает как номер карты и CVV.
from string.templatelib import Template, Interpolation card_number = "2200 2400 1500 9200" cvv = "412" date_expire_card = "11/30" MASK_CHAR = "*" def mask(ustring): parts = [] for item in ustring: if isinstance(item, str): parts.append(item) # Номер карты определяется по длине (19 символов с пробелами) elif len(item.value) == 19: masked_card_number = item.value[:5] for char in item.value[5:]: if char != " ": masked_card_number += "*" else: masked_card_number += " " parts.append(masked_card_number) # CVV определяется по длине (3 символа) elif len(item.value) == 3: masked_cvv = "".join([i.replace(i, "*") for i in item.value]) parts.append(masked_cvv) else: parts.append(item.value) return "".join(parts) masked_info = mask(t"User card: {card_number}, cvv: {cvv}, data expire: {date_expire_card}") print(masked_info)
Генерация безопасных конфигурационных файлов
Другой сценарий — сборка конфигурации, например .env, где значения должны соответствовать допустимому набору символов. В фактуре это решается через валидацию каждого интерполированного значения регулярным выражением.
import re from string.templatelib import Template def validate_env_value(item): if not re.match(r"^[a-zA-Z0-9_/.:-]*$", item.value): raise ValueError(f"Invalid .env value: ({item.expression}: {item.value})") return item.value def save_env(ustring): lines = [] for item in ustring: if isinstance(item, str): lines.append(item) else: lines.append(validate_env_value(item)) return "".join(lines) db_host = "db.host" port = "5432@" # символ @ не должен быть в этой переменной, будет ошибка config = t"DB_HOST={db_host}\nDB_PORT={port}" save_config = save_env(config)
Защита от command injection при subprocess(shell=True)
Использование subprocess(shell=True) потенциально уязвимо, потому что команда исполняется непосредственно в оболочке системы. В таком режиме строка команды становится критической точкой: если в нее попадет ввод пользователя, он может повлиять на исполняемую команду.
Пример из фактуры решает задачу через безопасное квотирование интерполированных значений с помощью shlex.quote():
import shlex import subprocess from string.templatelib import Template def safe_bash(ustring): parts = [] for item in ustring: if isinstance(item, str): parts.append(item) else: parts.append(shlex.quote(str(item.value))) return "".join(parts) filename = "hello.txt; del test/" cmd = t"type {filename}" safe_cmd = safe_bash(cmd) print(safe_cmd) subprocess.run(safe_cmd, shell=True)
Где t-строки использовать не стоит
t-строки дают разработчику контроль над интерполяцией, но это не означает, что их нужно использовать для решения всех задач, связанных с безопасностью. В ряде сценариев в Python уже существуют встроенные и проверенные механизмы защиты, и попытка заменить их t-строками будет избыточной или даже вводящей в заблуждение.
Защита от SQL injection при помощи параметризации
В библиотеках для работы с SQL, например sqlite3, есть встроенная защита от SQLi через метод параметризации запросов.
import sqlite3 conn = sqlite3.connect("shop.db") c = conn.cursor() c.execute("CREATE TABLE IF NOT EXISTS users \ (id INTEGER PRIMARY KEY, username TEXT, password TEXT)") c.execute("INSERT OR IGNORE INTO users VALUES \ (1, 'user', 'j12kxs0$zak!@-ov'), \ (999, 'admin', 'kjhcxkl2-02=f@')") conn.commit() conn.close() def get(query): with sqlite3.connect("shop.db") as conn: cursor = conn.cursor() data = cursor.execute("SELECT * FROM users WHERE id = ?", (query,)) print(data.fetchall()) get("1 UNION SELECT 999, username, password FROM users") get("1")
В этом примере параметризация реализуется через знак вопроса.
Вместо него подставляется значение из кортежа. Соответственно, по мере необходимости параметров может быть бесконечно много. За счет этой параметризации SQLi не сработает никогда. Использование t-строк в таком случае не целесообразно.
Совершенно не рекомендую использовать интерполяцию для защиты от SQL-инъекций. Единственное верное решение — это применять параметризированные запросы.
Защита от XSS через render_template
В Python есть встроенный модуль html, который занимается санитизацией пользовательских строк:
import html user_input="Hello, <script>print()</script>" safe_name = html.escape(user_input, quote=True)
В современных шаблонизаторах вроде Jinja2, Django Templates под капотом есть встроенные модули санитизации. Рассмотрим пример на модуле Flask.
Файл example_sec_xss.py:
from flask import Flask, render_template, request app = Flask(__name__) @app.route("/hello") def hello(): username = request.args.get("username") return render_template("hello.html", username=username) if __name__ == "__main__": app.run()
Файл template/hello.html:
<!DOCTYPE html> <html> <head><title>Профиль</title></head> <body> <h1>Привет, {{ username }}!</h1> </body> </html>
Так выглядит страница после рендеринга запроса:
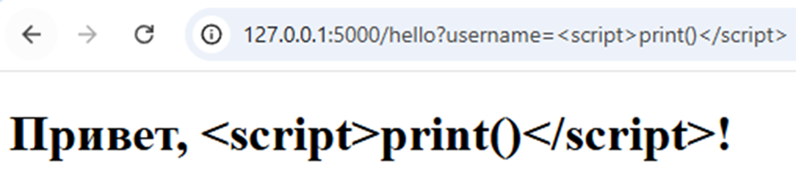
А вот так — код после попытки инъекции:
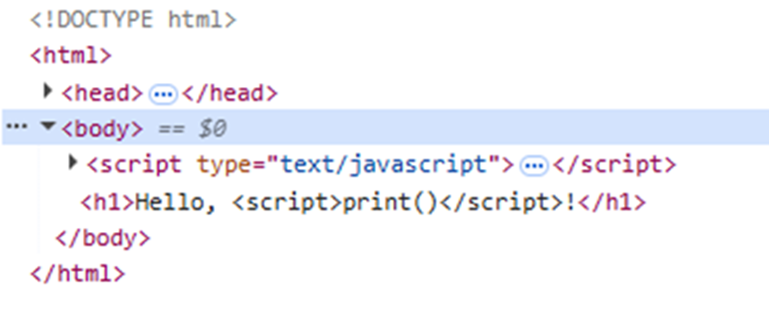
Защита от SSTI через render_template
Продолжу предыдущий пример. render_template защищает также и от SSTI.
Файл example_sec_ssti.py
from flask import Flask, render_template, request app = Flask(__name__) @app.route("/profile") def profile(): user_input = request.args.get("username", "") return render_template("profile.html", username=user_input) if __name__ == "__main__": app.run()
Файл template/profile.html:
<!DOCTYPE html> <html> <head><title>Профиль</title></head> <body> <h1>Привет, {{ username }}!</h1> </body> </html>
Выглядит так:
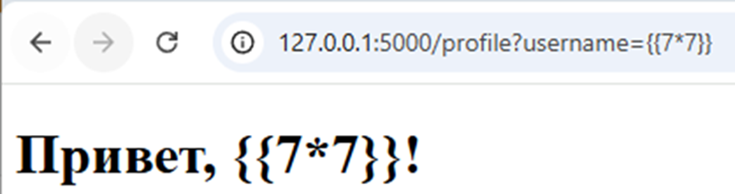
Защита от XXE при помощи встроенной санитизации
Если говорить о модуле xml.etree.ElementTree, то в нем также имеется встроенная защита от инъекций. Рассмотрим пример:
import xml.etree.ElementTree as ET xml_data = """<?xml version="1.0"?> <root> <name>John</name> </root>""" root = ET.fromstring(xml_data) # функция санитайзер print(root.find("name").text)
На скриншоте — пример нереализованной инъекции:
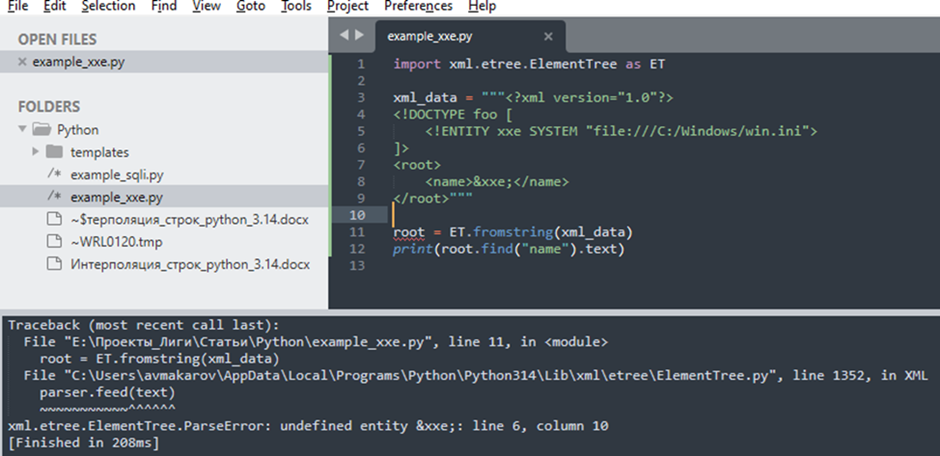
Парсер xml.etree.ElementTree не поддерживает обработку DTD и пользовательских сущностей. Поэтому любая ссылка на нестандартную сущность (например, &xxe;), даже если она объявлена в DOCTYPE, считается неопределенной и вызывает ошибку разбора. Поэтому эксплуатация XXE-уязвимостей с использованием этого парсера невозможна.
Защита от OS command injection через Subprocess(cmd, shell=False)
При написании кода с модулем subprocess, если есть возможность, лучше не использовать параметр shell=True. Это позволит модулю обрабатывать пользовательский ввод отдельно, превратив его в строку, и он не будет выполнен как команда.
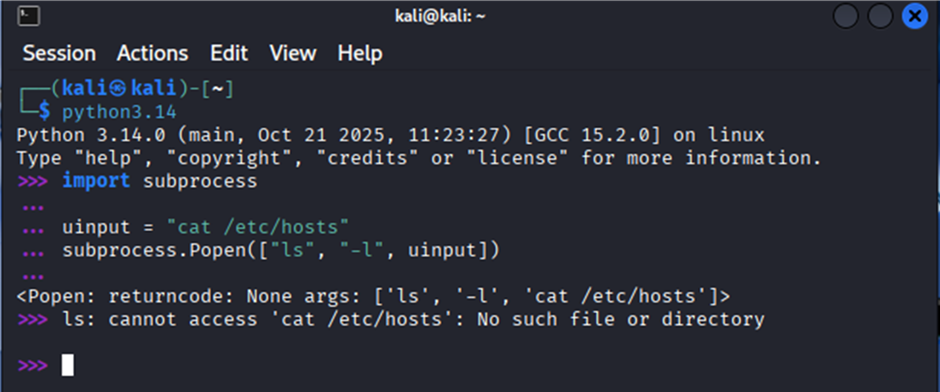
import subprocess uinput = "cat /etc/hosts" # пользовательский ввод subprocess.Popen(["ls", "-l", uinput])
При написании кода с модулем subprocess, если есть возможность, лучше не использовать параметр shell=True. Это позволит модулю обрабатывать пользовательский ввод отдельно, превратив его в строку, и он не будет выполнен как команда.
В примере выше команда будет приведена в следующий вид:
ls –l "cat /etc/hosts"
Так, команда ls будет буквально искать файл "cat /etc/hosts":
Выводы
Шаблонные строки в Python 3.14 — это не замена f-строкам, а новый инструмент для ситуаций, где важен контроль над подстановкой данных. Вместо того чтобы сразу превращаться в строку, t-строка сохраняется как структура: отдельно текст, отдельно значения для вставки. Это позволяет безопасно обрабатывать недоверенные данные: маскировать пароли в логах, экранировать HTML, квотировать аргументы командной строки и т. д.
Однако важно, что t-строки не делают код безопасным автоматически. Безопасность зависит от того, как вы обрабатываете вставляемые значения. А в задачах, где уже есть проверенные средства защиты (параметризованные SQL-запросы, автоматическое экранирование в Jinja2, вызов subprocess без shell=True), использовать t-строки не нужно — это избыточно и может ввести в заблуждение.
Подытожу главное:
Используйте f-строки, когда вам просто нужна строка.
Используйте t-строки, когда вы строите систему, где важно, как и в каком виде данные попадают в строку.
Всегда отдавайте приоритет специализированным защитным механизмам, а не пытайтесь решать все через форматирование строк.

