
Архитектурная мина замедленного действия
В мире разработки программного обеспечения существует понятие, которое окружено множеством мифов, страхов и недопонимания.
Это технический долг.
Часто его воспринимают как нечто сугубо негативное, как признак некомпетентности команды или халатности архитектора. Однако, чем глубже ты погружаешься в тему и анализируешь практический опыт, то приходишь к выводу, что техдолг — это неизбежная часть жизненного цикла любого продукта. Не ошибка, а стратегические компромиссы.
В этом материале хочу поделиться своим видением подходов к работе с техдолгом: поразмышляю о природе техдолга, инструментах для работы с ним, стратегиях взаимодействия с бизнесом, чтобы показать, как тонкая грань между быстрым стартом и катастрофой может быть успешно пройдена.

Самая, на мой взгляд, лучшая метафора, поясняющая термин «техдолг» — это «архитектурная мина замедленного действия». В этом определении заложена вся суть проблемы. В начале проекта, когда горят сроки и нужно показать инвесторам работающий прототип, когда бизнес требует MVP «ещё вчера», команда сознательно идет на упрощения: «Ерунда, потом перепишем». В этот момент кажется, что мы контролируем ситуацию, но мина уже заложена и она тикает.
Главный вопрос, который должен задать себе любой руководитель проекта или архитектор, не «Как избежать техдолга?», а «Взорвётся ли он в тестовом контуре, где последствия минимальны, или прямо под продакшн-релизом, когда на кону репутация и деньги компании?».
На мой взгляд, игнорирование техдолга — одна из самых распространенных стратегических ошибок в IT-менеджменте. Многие проекты обладают техдолгом, это факт. Но часто он игнорируется до тех пор, пока его энтропия не становится блокером внедрения новой функциональности или причиной потери гибкости продукта.
Я считаю, что ключевая компетенция современного архитектора заключается не в создании идеальной системы с первого дня (что невозможно), а в умении вовремя распознать и структурировать техдолг, не дожидаясь критического состояния, и выстраивании архитектурной дисциплины, позволяющей им управлять.
Философия техдолга: компромисс, а не антипаттерн
Для начала необходимо четко определиться с терминами: что такое техдолг? В массовом сознании это синоним плохого кода. Но он имеет более глубокую суть.
Техдолг — это компромиссы. Иногда осознанные, иногда нет. На мой взгляд, в этом таится фундаментальное различие:
Если команда накопила долг осознанно, понимая риски и планируя их отработку, это управленческое решение.
Если же долг накопился из-за незнания, лени или отсутствия стандартов — это халатность.
Но в обоих случаях результат на выходе для системы похож: это гиря, которая тянет на дно.
Представим классическую ситуацию: вы запускаете новый сервис, бизнес требует функционал к завтрашнему дню. Вы делаете «быстрый фикс», чтобы успеть к демо, код работает, инвесторы довольны. Но через полгода этот фикс превращается в такой узел, который никто не хочет трогать. Принцип «работает — не трогай» становится главным правилом выживания команды. Вот это и есть техдолг в чистом виде.
Важно помнить и всегда подчеркивать в коммуникации с заказчиком: техдолг — это не антипаттерн.
Антипаттерн — это ошибочное решение, которое всегда ведет к проблемам, а техдолг — это компромисс ради скорости сейчас за счёт будущего.
Это фактически кредит, который мы берем у будущего себя. А как любой кредит он имеет процентную ставку, и чем дольше мы не возвращаем тело кредита (не рефакторим код), тем больше процентов (времени на поддержку и исправление багов) мы платим.
Я считаю, что принятие этой философии коренным образом меняет отношение команды к проблеме. Вместо самобичевания («мы написали плохой код») приходит понимание ответственности («мы взяли обязательство вернуть долг»). Это позволяет смотреть на вопрос не в плоскости эмоций, а в плоскости управления рисками.

Истоки проблемы: почему рождается техдолг?
Понимание причин возникновения техдолга критически важно для его предотвращения. Если мы лечим симптомы, не зная диагноза, болезнь вернется. Я вижу три ключевые причины, и считаю каждую из них заслуживающей отдельного глубокого анализа.
№1. Сжатые сроки и MVP
Первая и самая очевидная причина. Бизнес приходит и говорит: «Надо MVP за три месяца». И аналитики, и архитекторы — все понимают: идеальное решение за три месяца не построить. Мы понимаем, вы понимаете, все понимают. Значит, мы где-то упростим.
Однажды я участвовал в запуске пилота платформы дистанционного обучения. Задача стояла «Быстро», то есть без глубинной проработки нефункциональных требований (НФТ) и архитектуры. Выпускаем минимально жизнеспособный продукт в кратчайшие сроки, лишь бы показать инвесторам первые красивые цифры.
MVP на деле оказался нежизнеспособным, потому что когда показали цифры и трафик попер, всё упало (страдает долговременная масштабируемость, лезут проблемы с производительностью и обработкой больших объемов транзакций).
На мой взгляд, это классическая ловушка стартапов и инновационных подразделений в крупных компаниях. Успех на ранней стадии («трафик попёр») становится наказанием за непроработанную архитектуру и желание «успеть все и сразу». Я считаю, что в таких ситуациях архитектор должен иметь полномочия сказать «Нет» или предложить альтернативу с чётко оговорёнными рисками. Молчаливое согласие на «убийственную» архитектуру ради демо — это профессиональное преступление.
№2. Отсутствие ресурсов
Вторая причина — классика жанра: нет бюджета, нет экспертизы, нет необходимого количества разработчиков. И вот архитектору говорят: «Спроектируй красиво, но чтобы это сделал один джун». Ну и всё, — теперь мы строим дом на фундаменте из фанеры.
Это ситуация, с которой сталкивался, пожалуй, каждый технический лидер: бизнес хочет Ferrari, но оплачивает только велосипед. Проблема усугубляется тем, что бизнес часто не понимает разницы в сложности реализации. Для них «кнопка — это кнопка».
Я убежден, что в таких условиях техдолг рождается автоматически. И когда приходят баги, техдолг уже аккуратно дышит нам в затылок. Управление этим видом долга требует честного разговора с заказчиком о том, что экономия на квалификации разработчиков сейчас обернется кратно большими затратами на поддержку позже. Это вопрос экономической целесообразности.
№3. Высокая неопределённость
Это частая история в финтехе: рынок меняется, бизнес ещё сам не понимает, какой именно продукт хочет и мы проектируем систему «заранее». Через полгода оказывается, что вектор сменился, а наша архитектура уже тянет нас назад.
И вот у нас классический коктейль: сроки поджимают, людей не хватает, требования меняются. В таких условиях техдолг — это плата за гибкость. Мы намеренно делаем систему менее оптимальной, но более изменяемой. Однако грань между гибкостью и хаосом очень тонка.
На мой взгляд, здесь помогает итеративный подход. Не нужно проектировать систему на пять лет вперед в условиях турбулентности. Нужно проектировать на один шаг вперед, оставляя точки расширения. Но даже это требует дисциплины, чтобы точки расширения не превратились в заброшенные двери, через которые в систему проникает хаос.
Архитектурные корни техдолга

Давайте разберём архитектурные корни техдолга. Откуда он появляется именно на уровне системных решений? Здесь я вижу три основных направления, которые часто становятся фатальными для проекта.
№1. Неправильная гранулярность сервисов
Когда слишком много маленьких сервисов, которые плодят интеграционную боль, либо это один огромный сервис, в котором уже не разобраться. И команда делится на два лагеря: одни говорят «раздробим», другие — «давайте склеим». Но плохо что так, что так.

Я считаю, что поиск правильной гранулярности — это искусство, а не наука. Нет универсальной формулы. Однако, явный признак проблемы это когда команда тратит больше времени на настройку взаимодействия между сервисами, чем на реализацию бизнес-логики. Это сигнал к консолидации. А вот когда изменение в одном модуле требует деплоя десяти других, это уже сигнал к разделению. Баланс здесь критически важен.
№2. «Божественный сервис»
Это когда всё и вся запихнули в один модуль. Получается такой «бог системы».
Сначала удобно — один сервис, одна база. Но через год это уже не супер-пупер сервис, а пещера, куда никто не хочет заходить, потому что страшно.
В моей практике я встречал такие системы неоднократно. Они работают годами, потому что «страшно трогать». Любое изменение в таком монолите напоминает саперную работу. Я убежден, что декомпозиция «божественного сервиса» должна быть приоритетом номер один, даже если бизнес не видит в этом прямой ценности. Потому что ценность здесь отрицательная: отсутствие этого долга предотвращает будущие убытки.
№3. Игнорирование нефункциональных требований
Все спешат пилить фичи: отчёты, кнопочки, API. А SLA, отказоустойчивость и безопасность «потом». А потом эти самые нефункциональные требования приходят к нам в виде инцидентов в проде. И выясняется, что у нас система держит нагрузку не 1000 rps, а 100.
Это, на мой взгляд, самая коварная форма техдолга. Если функциональный долг виден сразу, потому что фича не работает, то нефункциональный скрыт до момента пиковой нагрузки или атаки. Я считаю, что требования к производительности и безопасности должны быть зафиксированы наравне с бизнес-требованиями. Их нельзя откладывать в «долгий ящик», потому что цена исправления архитектуры под нагрузкой несоизмеримо выше.
Техдолг как блокер развития бизнеса
К чему всё это приводит? Часто бизнес воспринимает работу с техдолгом как «игру в технологии», которая не приносит денег. Это фундаментальное заблуждение. Техдолг напрямую влияет на bottom line компании.
№1. Невозможность роста из-за риска отказа системы.
Если архитектура не масштабируется, бизнес не может захватывать новые рынки. Мы становимся заложниками собственной инфраструктуры.
№2. Рост затрат.
Инфраструктура пухнет, разработка дорожает, саппорт задыхается. Это как старый автомобиль: сначала вы экономите, что не меняете его. А потом каждая поездка в сервис стоит дороже, чем платеж по кредиту на новую машину. Но машина у вас старая.
Я считаю эту метафору одной из самых удачных — она понятна любому. Поддержание легаси часто обходится дороже, чем разработка нового решения с нуля, если учитывать совокупную стоимость владения (TCO).
№3. Снижение производительности.
И речь не столько про системы, сколько про команды. Когда разработчик тратит недели на то, чтобы понять, как работает старый модуль, у него опускаются руки. Он работает медленнее, и компания в итоге теряет не только деньги, но и людей.
Выгорание сотрудников из-за работы с некачественным кодом — это неявный убыток. Потеря ключевого разработчика из-за того, что ему надоело копаться в «гоу-кхакхакха-нокоде», может стоить компании миллионов на поиск и адаптацию замены.
№4. Графики и цифры.
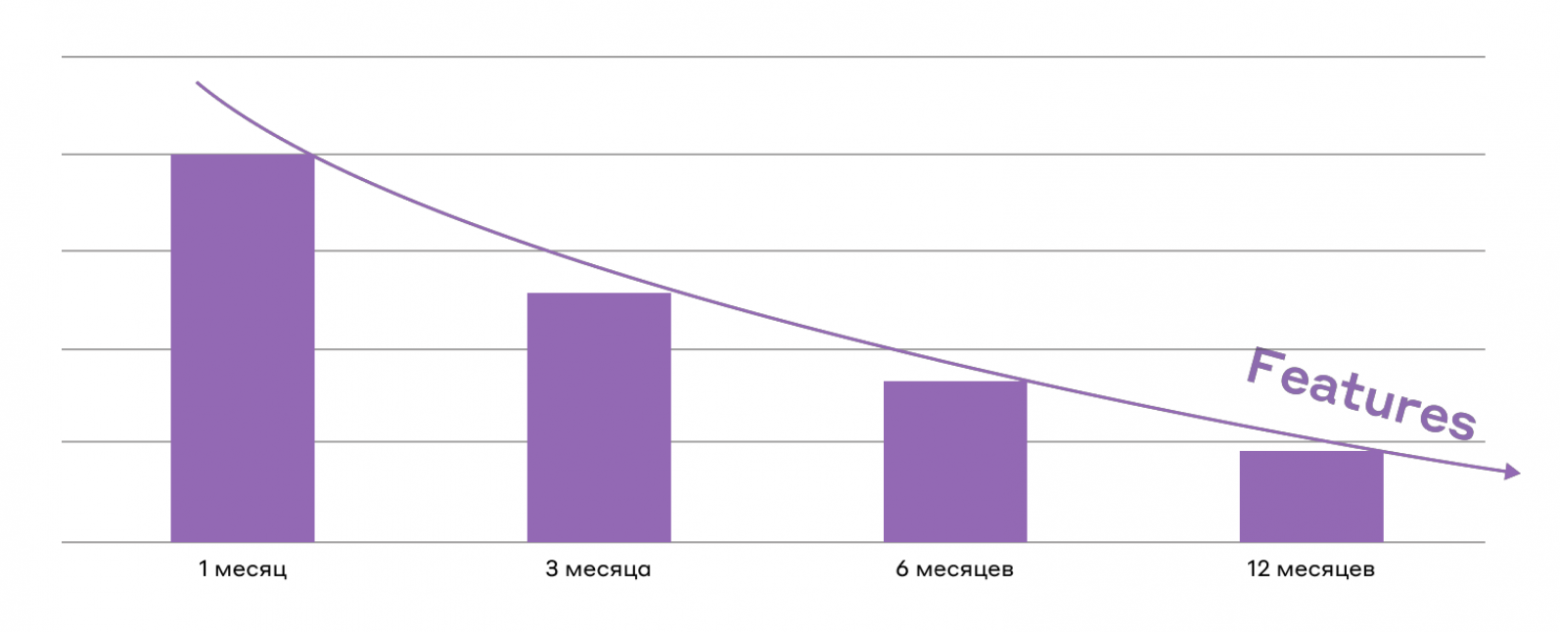
Давайте посмотрим на два графика:
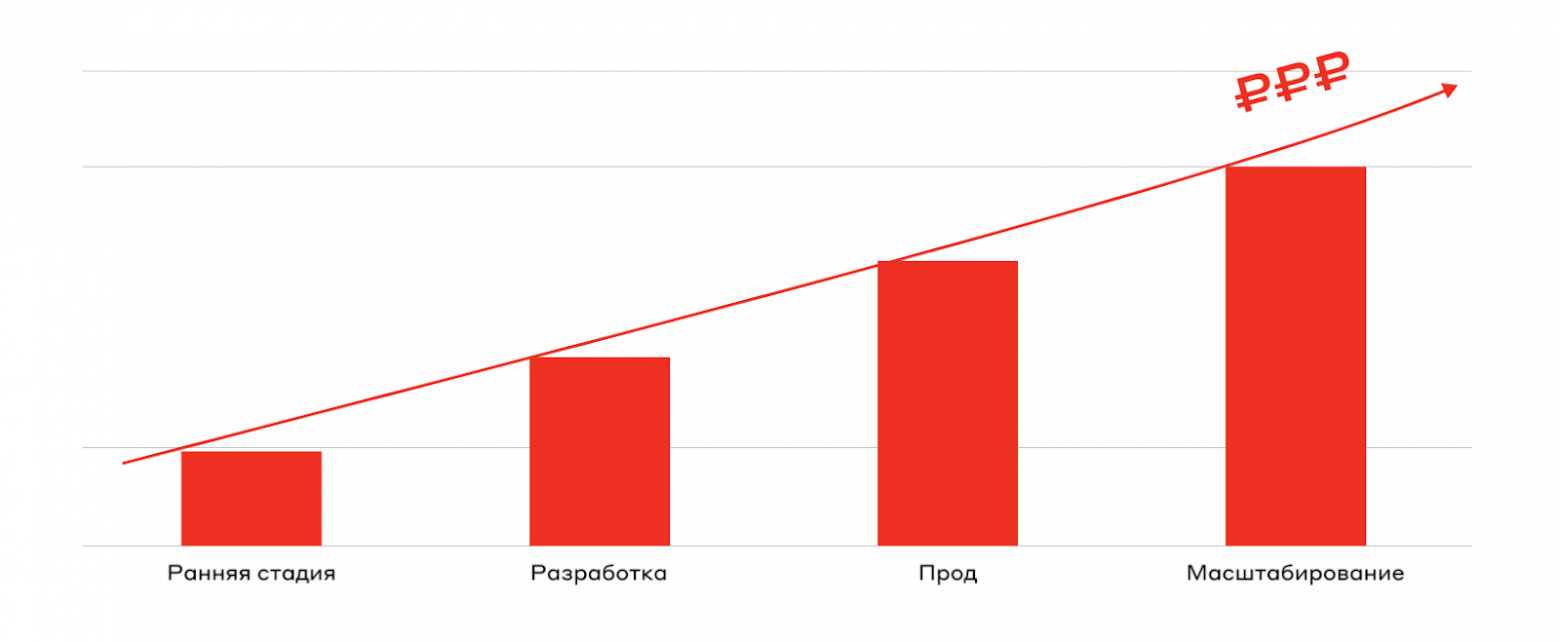
Первый — классическая диаграмма: чем позже устраняем техдолг, тем дороже он становится. На ранней стадии фиксы стоят копейки, но если мы дошли до продакшена и масштабирования, то цена устранения уже космическая.
А вот второй график про скорость разработки. Чем дальше мы тащим техдолг, тем медленнее двигаемся. Сначала он нас не тормозит, но через 6–12 месяцев команда уже тратит половину времени не на новые фичи, а на борьбу с «наследием».
На мой взгляд, визуализация этих зависимостей — мощнейший инструмент убеждения. Бизнес мыслит цифрами. Показать график, где скорость разработки неуклонно падает вниз (подкрепив это влиянием на ключевые задачи), гораздо эффективнее, чем рассказывать про «чистоту кода».
Кто управляет техдолгом?

Извечный философский вопрос: а кто вообще управляет техдолгом в команде? Разработчик? Архитектор? Продакт? QA?
На самом деле — все. Все отвечают за не_появление/устранение техдолга. Но если никто конкретно не несёт ответственности за техдолг, то он точно управляет вами.
Я считаю, что ответственность должна быть распределена, но координироваться одним лицом. Обычно эту роль берет на себя системный архитектор или тимлид. Однако, критическую роль играет аналитик.
Аналитик — ключевой фасилитатор техдолга.
Почему? Потому что именно аналитик может заносить в бэклог задачи по техдолгу и следить за их приоритизацией. Да, обычно аналитики любят писать требования, а не фиксить костыли. Но если не вести учёт, долги просто копятся «под ковром».
Симптомы наличия техдолга на проекте
Как вовремя распознать проблему? Существует ряд симптомов, которые должны зажечь красные лампочки в голове руководителя.
№1. Частые баги. Если каждый новый релиз приносит больше багов, чем фич, значит где-то закопано. Это признак того, что система стала хрупкой. Изменения в одном месте ломают другое.
№2. Страх изменений. Когда разработчики боятся трогать код, потому что «он упадёт». И тут уже никакие тимбилдинги не помогут. Потому что настоящая сплочённость проверяется в проде ночью, когда что-то отвалилось. Страх — это индикатор низкого качества тестов и высокой связности кода.
№3. Время на простые доработки. На простые доработки уходит куча времени. Добавить поле в форму — неделя. Добавить новый отчёт — месяц. Если у вас так, поздравляю: техдолг живёт в вашей системе. Это прямой показатель потери гибкости.
№4. Код-смрад. Вы открываете файл и чувствуете запах: переменные называются a, b, c, классы по 2000 строк. Тут даже IDE плачет. Это вопрос культуры разработки, который напрямую влияет на поддерживаемость.
№5. Низкий процент покрытия автотестами. Когда на вопрос «А у нас есть тесты?» в комнате воцаряется тишина. Без тестов рефакторинг невозможен, так как нет страховки от регрессии.
№6. Неактуальная документация. Это классика жанра: документация есть, но её никто не обновлял с 2018 года. Там нарисованы сервера, которых уже нет в природе. Документация, которая врет, хуже, чем отсутствие документации, потому что она вводит в заблуждение.
На мой взгляд, наличие трех и более симптомов из этого списка — это повод объявлять «технический таймаут» (об этом ниже) и останавливать разработку новых фич для стабилизации системы.
Стадии работы с техдолгом: путь от отрицания к устранению
Работа с техдолгом часто проходит через стадии, напоминающие стадии принятия горя. Понимание этого помогает нам управлять ожиданиями команды и бизнеса.
Отрицание. Команда говорит: «У нас всё нормально». А на самом деле уже всё плохо. Это самая опасная стадия, так как проблема игнорируется.
Гнев. Когда бизнес наконец видит масштабы проблемы, и на архитектора сыплются вопросы: «Почему вы так сделали?!». Эмоции зашкаливают, поиск виноватых заменяет поиск решений.
Торг. Где мы договариваемся: «Давайте хотя бы часть долгов закроем», и начинаем искать компромиссы. Это начало конструктивного диалога.
Документирование. Мы, наконец, начинаем фиксировать долги: в Confluence, в Jira, в Excel. Вопрос «где вести» обычно превращается в холивар. Но главное — начать вести.
Устранение. Это когда команда реально выделяет время и ресурсы, чтобы закрывать долги.
Я считаю, что наша задача — сократить время прохождения первых трех стадий. Не ждать, пока бизнес «увидит масштабы проблемы» через инциденты, а проактивно демонстрировать риски на стадии отрицания.
Стратегии управления техдолгом
Как же бороться с этой проблемой? Обычно выделяют четкое разделение на проактивные и реактивные стратегии. Я считаю, что идеальный подход — это комбинация обоих методов.
Проактивные стратегии: профилактика
Проактивные методы направлены на то, чтобы не допускать накопления критического долга.
№1. Boy Scout Rule.
Первое правило — «Оставляй код чище, чем нашёл». Звучит очень просто. Представьте, что вы зашли в чужой модуль, чтобы добавить маленький фикс. Видите, что переменные названы a1, a2, a3. Что мешает вам переименовать их в нормальные имена? Это займёт 5 минут, но через месяц другой разработчик сэкономит полдня на разборе.
Кейс: в банке был сервис расчёта комиссий, писался на скорую руку. В нём был метод calcX() на 200 строк. Каждое посещение этого метода превращалось в квест. Мы договорились, что каждый разработчик, заходя туда, будет немного «расчищать лес». Через пару месяцев метод «распилили» на маленькие функции, и он перестал быть страшилкой для команды.
№2. Чистый код и стандарты.
Звучит скучно, но работает. В больших организациях всегда есть соблазн: «запилим, побыстрее, потом переделаем». Но «потом» никогда не наступает. А стандарт проектирования — это страховка от хаоса. Стандарты должны быть автоматизированы. Линтеры, статические анализаторы кода должны работать в CI/CD. Человек забывает, машина — нет.
№3. Регулярный аудит и рефакторинг.
Техдолг — как зубы. Если не ходить к стоматологу раз в полгода, потом придётся ставить имплант. Так и в архитектуре: регулярный аудит помогает поймать проблему на ранней стадии.
Аудит не должен быть карательной мерой. Это должна быть сессия по улучшению, где команда сама находит узкие места.
№4. Автоматизация развёртывания.
Если у вас нормальный CI/CD, то вероятность завести новый техдолг меньше, потому что всё прозрачно и автоматизировано. CI/CD — это не роскошь, а способ снизить техдолг. Если у вас релиз — это набор шаманских танцев в ночь с пятницы на субботу, значит, техдолг уже в инфраструктуре. Инфраструктурный долг часто игнорируется, но именно он становится причиной самых длительных простоев.
№5. ADR (Architectural Decision Records).
Архитектурные решения должны документироваться. Когда на проекте 200 человек, а архитектурное решение живёт только в голове у одного архитектора — это прямая дорога к техдолгу. Если у вас нет ADR, через год никто не вспомнит, почему база выбрана именно PostgreSQL, а не Mongo. ADR — это история проекта. Без неё новые сотрудники обречены наступать на те же грабли, что и предыдущие.
№6. Страховка архитектурными антипаттернами.
Самый распространённый пример — использование единой БД для нескольких сервисов. При таком подходе ломается изоляция сервисов, возникают сильные связности, сложности с развёртыванием и масштабированием, а также растёт риск неконсистентности данных. Это один из самых сложных моментов в миграции на микросервисы. Разделение базы данных часто требует переписывания значительной части логики, но это необходимо для истинной независимости сервисов.
Реактивные стратегии: лечение
Когда долг уже накоплен, нужны другие методы.
№1. Документирование, приоритизация и планирование.
Это как с кредитной картой: сначала нужно хотя бы честно признать, сколько вы должны.
№2 Метрики.
Если вы не измеряете техдолг, то он для вас невидим. А невидимое всегда кажется маленьким. Когда мы начали отслеживать среднее время разработки новой фичи, то спор о том, «есть ли техдолг», закончился. Потому что в начале года на фичу уходило 2 недели, а в конце — уже 6. График для бизнеса был весьма нагляден. Метрики должны быть простыми и понятными бизнесу. «Время вывода на рынок» (Time to Market) — лучший показатель.
№3. Strangler Fig (постепенная модернизация).
Не надо пытаться переписать всё с нуля — такие проекты редко выживают. Надо «обвивать» старую систему новой архитектурой и постепенно вырезать легаси.
Кейс: Мы так делали с нашей старой платёжной системой. Переписывать её целиком было бы безумием: риски огромные. Тогда мы начали с вынесения API наружу в отдельный слой, потом постепенно перевели модули расчётов и проверки AML. Через год легаси почти не осталось, и ни один клиент не заметил миграции. Это единственно верный путь для крупных энтерпрайз-систем. Big Bang реврайты почти всегда проваливаются.
№4. Замена критичного долга менее критичным.
Например, у нас старая библиотека небезопасна. Обновить её — космос. Тогда мы подключаем SaaS-сервис и пишем адаптер. Да, это новый долг. Но более управляемый. Это тактика «меньшего зла». Иногда лучше взять внешний долг (зависимость от вендора), чем держать внутреннюю бомбу замедленного действия.
Техквота и технический таймаут
Два конкретных инструмента управления ресурсами.
№1. Техквота — когда техдолг ещё не захлестнул. Регулярная доля рабочего времени команды, выделяемая специально для борьбы с техническим долгом. Обычно выделяется 20% от капацитета спринта, которые идут исключительно на улучшение качества кода, устранение узких мест, повышение стабильности и отказоустойчивости системы. Как по мне, 20% — это золотой стандарт. Меньше — незаметно, больше — бизнес начинает нервничать. Главное — не позволять бизнесу «занимать» эту квоту в горячие периоды. Если вы отдали техквоту один раз, вы не вернёте её никогда.
№2. Технический таймаут — когда дошли до предела. Запланированная остановка разработки новых функций или изменений продукта с целью устранения накопленного технического долга. Во время такого тайм-аута команда фокусируется исключительно на рефакторинге устаревшего кода, оптимизации архитектуры, исправлении дефектов и повышении производительности. Это радикальная мера, но иногда необходимая. Лучше остановиться на месяц сейчас, чем потерять систему навсегда позже. Это требует мужества от менеджмента.
Техники оценки…
Как понять, какой долг гасить в первую очередь? Нельзя рефакторить всё подряд. Нужен подход.
Карта техдолга — визуализация системы с пометками. Чем краснее и больше кружок, тем хуже. Отличный способ показать бизнесу масштаб проблемы без лишних слов. Визуализация работает лучше таблиц. Бизнес любит картинки, где проблемы видны сразу.
Табличное представление: классификация, описание, влияние. Это скучно, но зато очень структурирует.
Отчётики: аудит решений, выгрузки из арх.репозиториев. Иногда полезно показать график: «Вот столько багов у нас сейчас». Работает лучше любых метафор.
…И приоритизации
Матрица критичности. Смотрим на влияние на бизнес и технические риски. Если что-то угрожает безопасности или доходу, это приоритет номер один. Мы оцениваем не только технические риски, но и бизнес-ценность.
Покер-оценка. Команда голосует, обсуждает расхождения и находит консенсус. Это работает лучше, чем если архитектор решает всё единолично. Коллективная оценка повышает ответственность команды. Если они сами оценили задачу как сложную и важную, они будут мотивированы её сделать.
C2V (Cost to Value / Cost of Negative Scenario). Считаем стоимость негативного сценария. Удобный аргумент для бизнеса: «Если этот долг выстрелит, мы потеряем Х миллионов». Это самый сильный аргумент. Перевод технических рисков в деньги — очень важный поинт в вопросах, связанных с техдолгом .
Внедрение процесса работы с долгом
Выделение техквоты. Это правило 80/20: 20% времени тратим на долг, 80% — на новые фичи. Это лучше, чем ждать, пока долг съест все 100%.
Инвестиции в CI/CD. Каждый рубль, вложенный в автоматизацию, возвращается сторицей. Это проверено и в банке, и в стартапах.
Технические ретроспективы. Раз в N спринтов проводить ретро, посвящённое только техдолгу. Обсуждать не «как мы общаемся», а «какие долги нам мешают». Можно строить карту боли: разработчики клеят стикеры на сервисы, в которых им тяжелее всего работать. Ретроспективы по техдолгу должны быть безопасными — разработчики не должны бояться признаваться в наличии «костылей», иначе они будут их скрывать.
Коммуникация с бизнесом: язык пользы
Это, пожалуй, самый важный раздел. Можно быть гениальным архитектором, но если вы не сможете объяснить ценность своей работы бизнесу, вы не получите ресурсов на устранение долга.
Ключевые правила обсуждения техдолга:
Говорить на языке бизнеса. Если приходите к заказчкику и говорите «У нас 500 через раз», он не поймёт. Но если вы скажете: «Это замедлит вывод продукта на рынок на 3 месяца», — услышит сразу. Архитекторы и аналитики должны быть всегда немного переводчиками. Они переводят с технического на экономический.
Считать деньги. Техдолг — это не только про изящность решений, но и про экономику. Если долг стоит компании миллион в год, то бизнесу проще инвестировать в его устранение.
Регулярный обзор техдолга. Если в банке есть комитеты по рискам, почему бы не делать комитеты по техдолгу? Институционализация процесса повышает его статус. Техдолг становится таким же риском, как валютный или юридический.
Технические демо. Показывайте бизнесу не только фичи, но и работу над техдолгом. Когда продакт видит, что после рефакторинга скорость релизов выросла, он начинает верить.
Демонстрировать невидимую работу сложно, но нужно. Показывайте графики ускорения, снижения количества инцидентов.
Главные принципы победы
Подводя итог своим рассуждениям, хочу выделить главные принципы, которые, на мой взгляд, являются фундаментом успешной борьбы с техническим долгом.
Постоянность. Нельзя бороться с техдолгом разовыми акциями. Это ежедневная гигиена. Как чистить зубы.
Пропорциональность. Нужно находить баланс. Нельзя загнать бизнес в стоп-фичи на полгода, но и нельзя игнорировать долг полностью. Золотая середина — техквота.
Компромиссы. Нужно понимать, где можно взять долг осознанно ради бизнеса, а где нельзя. Это вопрос зрелости архитектора.
Коммуникация. Без этого техдолг победить нельзя. Тут как в браке: либо учитесь разговаривать, либо готовьтесь к разводу. Отношения между IT и Бизнесом должны строиться на доверии и прозрачности.
Помните: техдолг — это не враг, это часть нашей работы. Это инструмент, который может помочь быстро стартовать, но может и убить проект при неправильном использовании. Если мы не управляем им, то он обязательно управляет нами.
Подписывайтесь на Телеграм-канал Alfa Digital — там мы постим новости, опросы, видео с митапов, краткие выжимки из статей, иногда шутим.
Читайте также:
