
PostgreSQL — мощная, гибкая и надёжная СУБД, способная обрабатывать огромные объёмы данных. Однако даже самая совершенная система может столкнуться с проблемами производительности, когда задержки в обработке запросов из миллисекунд превращаются в секунды. В таких ситуациях каждый лишний миг простоя дорого обходится бизнесу: клиенты уходят к конкурентам, сервер работает на пределе возможностей, а прибыль тает на глазах.
Вместо того чтобы действовать наугад, важно подойти к проблеме структурированно. Попытки просто добавить индексы или переписать запросы без понимания сути проблемы редко приводят к успеху. Именно поэтому для эффективной оптимизации необходимо детальнее погрузиться во внутренние процессы СУБД.
Для этого в PostgreSQL есть мощный встроенный инструмент — EXPLAIN ANALYZE, который показывает пошаговый план выполнения запроса: какие операции выполняются, сколько времени и ресурсов каждая из них отнимает и где именно скрывается «узкое место».
Этот материал — первая часть практического руководства по оптимизации. Сначала мы научимся читать и понимать отчёт EXPLAIN ANALYZE. Вы узнаете, как планировщик PostgreSQL принимает решения, что означают ключевые метрики вроде cost, Seq Scan или Buffers hit и какие цифры сразу сигналят о проблеме.
Во второй части мы применим эти знания на практике: возьмём реальный неоптимальный запрос и пройдём весь путь его диагностики и ускорения — от анализа плана до добавления индексов.
Стоит отметить, что проблема медленного исполнения запроса может зависеть от множества факторов: версии СУБД, структуры и объёма данных, их расположения на сервере, мощности оборудования, самого запроса, текущих настроек конфигурации PostgreSQL и т. д. Поэтому не существует единого решения, которое подходило бы во всех случаях.
В рамках даже нескольких статей сложно детально рассмотреть все факторы, влияющие на производительность запросов, поэтому мы сосредоточимся на наиболее распространённых.
Статья будет полезна начинающим разработчикам, инженерам и аналитикам, которые хотят перейти от интуитивных решений к системной диагностике и осознанной работе с базой данных. Если вы только выбираете СУБД или хотите разобраться в базовых принципах работы с базами данных, рекомендуем сначала ознакомиться с материалом «Что такое база данных и система управления базами данных».
Как планировщик PostgreSQL строит план запроса
За кажущейся простотой SQL-запроса в PostgreSQL стоит многоэтапный процесс планирования и выполнения. SQL — декларативный язык: мы описываем не последовательность действий для СУБД, а лишь желаемый результат — какие данные хотим получить и при каких условиях. На основе этого описания СУБД самостоятельно выбирает оптимальный путь выполнения запроса, чтобы обеспечить точность и высокую производительность ответа. Именно для этой задачи в СУБД используется планировщик запросов. Знание особенностей работы планировщика позволит максимально эффективно использовать ресурсы СУБД и улучшать качество запросов.
Выполнение SQL-запроса допускает множественные варианты реализации. Например, для объединения двух таблиц можно применить различные алгоритмы: вложенные циклы, слияние, хеширование. Увеличение числа таблиц в запросе приводит к кратному росту возможных способов их соединения. При построении плана запросов в PostgreSQL используется стоимостная модель оптимизации — на основе собственных коэффициентов сложности и собранной статистики.

Стоимостная модель: как планировщик считает «cost»
В результате построения модели рассчитывается cost — «стоимость». Задача планировщика — выбрать план выполнения запроса с минимальной стоимостью из множества вариаций.
PostgreSQL рассчитывает cost для каждого шага плана с помощью внутренней модели затрат, основанной на параметрах конфигурации СУБД и статистике. Планировщик оценивает многочисленные стратегии выполнения запроса и выбирает наиболее эффективную — ту, у которой меньшая стоимость.
Cost — многофакторная метрика, которую PostgreSQL рассчитывает для каждого узла в плане выполнения запроса. Если хотите больше узнать о расчете cost, можно почитать документацию PostgreSQL.
В упрощенном виде формулу для расчета можно представить так:
Cost = (CPU Cost) + (I/O Cost)
Где:
CPU Cost — затраты процессора на обработку данных.
= (Количество строк × cpu_tuple_cost) для обычных таблиц
+ (Количество записей индекса × cpu_index_tuple_cost) для сканирования индексов
+ (Количество операций × cpu_operator_cost) для фильтров, сортировок и сравненийI/O Cost — затраты на чтение данных с диска.
= Количество страниц × seq_page_cost (при последовательном чтении)
= Количество страниц × random_page_cost (при случайном чтении)
Основные параметры стоимости (по умолчанию):
seq_page_cost (1.0) — стоимость последовательного чтения страницы.
random_page_cost (4.0) — стоимость случайного чтения страницы.
cpu_tuple_cost (0.01) — стоимость обработки одной строки таблицы.
cpu_index_tuple_cost (0.005) — стоимость обработки одной записи индекса.
cpu_operator_cost (0.0025) — стоимость выполнения одного оператора (WHERE, JOIN, ORDER BY и др.).
Например, если наша таблица содержит 1000 строк и 100 страниц, а коэффициенты в конфигурации не менялись (используются значения по умолчанию), тогда:
cost = (Количество строк × cpu_tuple_cost) + (Количество страниц × seq_page_cost)
cost = (1000 × 0.01) + (100 × 1.0) = 10 + 100 = 110.00
В данном примере мы рассматриваем сценарий, когда планировщик выбирает метод последовательного сканирования (Seq Scan). В этом случае применяются коэффициенты cpu_tuple_cost и seq_page_cost. Если бы использовались индексы или случайный доступ, применялись бы другие коэффициенты. Следует отметить, что это лишь упрощенный пример. На практике планировщик также учитывает cpu_operator_cost (затраты на фильтры и сравнения) и множество других факторов. Тем не менее даже такая базовая оценка позволяет понять, почему один план может быть «дешевле» другого.
Как можно заметить, значения cost зависят от объёма данных — количества строк и страниц (блоков). Операции, которые требуют значительных вычислительных затрат, — join, агрегации и подзапросы — заметно утяжеляют итоговую оценку. Если cost большой, возможно, вы извлекаете много данных или используете неэффективный доступ к ним, например, random_page_cost.
Роль статистики: почему планировщик может ошибаться
Как уже упоминалось, при расчете самого эффективного плана и значения cost планировщик использует собранную статистику и параметры конфигурации СУБД. Однако возможны неточности в оценке затрат, которые могут привести к выбору не самого оптимального плана.
Вот какие они бывают:
Ошибочная оценка количества строк в промежуточных результатах. Один из ключевых методов планировщика — оценка количества строк, которые будут обработаны на разных этапах выполнения запроса. Если статистика, на основе которой делаются эти оценки, устарела или неточна, это может привести к неправильным выводам о затратах на выполнение плана. Например, после массовых операций вставки (INSERT) или удаления (DELETE) необходимо обновить статистику, чтобы отразить изменения в количестве записей. Если этого не сделать, планировщик может выбрать более медленный план.
Некорректные параметры конфигурации. Параметры seq_page_cost и cpu_operator_cost призваны отражать реальную стоимость операций чтения и обработки данных. Если эти параметры настроены некорректно или не обновляются с учётом изменений в оборудовании и конфигурации системы (например, при переходе с HDD на SSD), это может привести к неправильной оценке затрат и выбору неэффективного плана выполнения запроса.
Использование генетического оптимизатора запросов (Geqo optimizer). Данный механизм упрощает выбор плана исполнения в сложных запросах с множеством соединений. В то же время не всегда гарантирует нахождение оптимального решения, так как он базируется на случайных выборках и сложных алгоритмах. Если запрос слишком сложный и содержит много соединений, то Geqo может упустить более эффективные соединения или варианты выполнения, так как он не может исследовать все возможные планы.
Есть и другие факторы, влияющие на выбор плана. Однако большинство из них так или иначе связано с неточностью статистики. Например, когда планировщик неправильно оценивает количество строк из-за неравномерного распределения данных или неоптимальной работы с временными таблицами (например, из-за отсутствия актуальной статистики, что приводит к завышенным оценкам), проблему часто решают обновлением статистики или увеличением её детализации.
Также при работе с подзапросами — где планировщик может столкнуться с особенностью оценки производных таблиц, для которых статистика либо отсутствует, либо недоступна на этапе планирования — проблема обычно сводится к отсутствию актуальных метрик, из-за чего приходится полагаться на приблизительные оценки.
Таким образом, регулярное обновление статистики — ключевой инструмент для минимизации ошибок планировщика, а понимание механизмов работы планировщика PostgreSQL — важный шаг оптимизации запросов.
Какие инструменты есть у планировщика: основные методы операций
После того как мы изучили принципы работы планировщика PostgreSQL, настало время подробнее рассмотреть физические операции, которые он использует для формирования плана выполнения запросов. Эти операции — ключевые в процессе оптимизации запросов, и правильный их выбор планировщиком непосредственно отражается на производительности и скорости обработки данных.
Условно методы операций можно разделить на 3 группы: доступа к данным, соединения данных и их обработки (агрегации, сортировки, фильтрации, ограничения).
Примечание
В статье используются термины «Методы доступа» и «Методы соединения». В других источниках вы можете встретить синонимы: «алгоритмы сканирования», «стратегии чтения», «план-ноды» (scan/join nodes). Все они описывают одни и те же механизмы планировщика PostgreSQL.
В других источниках “Операции обработки” не выделяют в отдельную категорию, однако в отчетах EXPLAIN ANALYZE они являются независимыми узлами, влияющими на потребление ресурсов (CPU, RAM). По этой причине решено отнести их к отдельной категории.
Методы доступа к данным (Access Methods): Seq Scan, Index Scan, Bitmap Scan
Представляют собой фундаментальный инс��рументарий СУБД, извлекающий данные из таблиц и индексов с применением различных алгоритмов в зависимости от конкретных условий.
Seq Scan — это базовый метод доступа к данным, при котором система последовательно просматривает каждую строку таблицы. Применяется, если нет подходящих индексов. Метод очень эффективен в ситуациях, когда условия фильтрации охватывают значительную часть таблицы. Также он предпочтителен для небольших таблиц, где индексация требует больше ресурсов, чем полное сканирование.
Parallel Seq Scan — параллельное последовательное сканирование. Postgres использует несколько параллельных процессов для чтения строк из таблицы. Каждый процесс сканирует раздел таблицы последовательно, страница за страницей, в том порядке, в котором они расположены на диске. Полученные результаты затем объединяются в операции сбора данных. Для масштабных операций чтения параллельное последовательное сканирование оптимально. Тем не менее для получения небольшого количества строк из большой таблицы обычно более эффективно использовать индексные методы.
Index Scan — Postgres использует созданный индекс для быстрого поиска требуемых записей. Если необходимо, система дополняет результаты данными из основной таблицы.
Индексный механизм в СУБД функционирует как вспомогательный инструмент, создающий отдельную структуру данных для быстрого поиска информации в таблицах. Индексы ускоряют доступ к строкам таблицы по определённому ключу, а также упрощают выполнение операций, таких как JOIN и фильтрация данных.
Операция Index Scan неэффективна, когда возвращает значительную долю строк таблицы (например, более 20%). В этом случае возникает необходимость в многократных переходах от узлов индекса к реальным данным в основной таблице (Heap). Эти переходы соответствуют операциям случайного ввода-вывода (Random I/O). При расчете стоимости такого запроса планировщик будет использовать значение параметра random_page_cost с высокой стоимостью. И напротив, если в таблице есть уникальные ID, то это будет идеальный случай для Index Scan.
Index Only Scan — этот метод возвращает данные исключительно из индекса. Он эффективен, когда все запрашиваемые данные содержатся в индексе. Рекомендуется для сценариев, где операции чтения преобладают над операциями записи. Например, это могут быть аналитические запросы по истории продаж. Ист��рических данных много, и они редко изменяются, но нужны часто.
Bitmap Index Scan — алгоритм создает битовую карту, указывающую на строки, удовлетворяющие запросу. Битовая карта (bitmap) — это структура данных, которая представляет собой последовательность битов (0 и 1), где каждый бит соответствует определенному элементу или условию.
Сам метод состоит из 4 этапов:
Создаются битовые карты для каждого индекса, где каждый бит — это результат проверки условия для каждой строки таблицы.
Объединение битовых карт с помощью логических операций (И, ИЛИ).
Сканирование строк. Происходит фильтрация по битовой карте.
Извлечение данных. На этом этапе получаем полную информацию о выбранных строках.
Bitmap Index Scan эффективен, когда есть множественные условия фильтрации, ограничение по использованию оперативной памяти и вычислительным ресурсам.
Метод эффективно обрабатывает запросы с использованием индексов, что особенно важно при работе с большими объемами данных, такими как аналитические запросы.
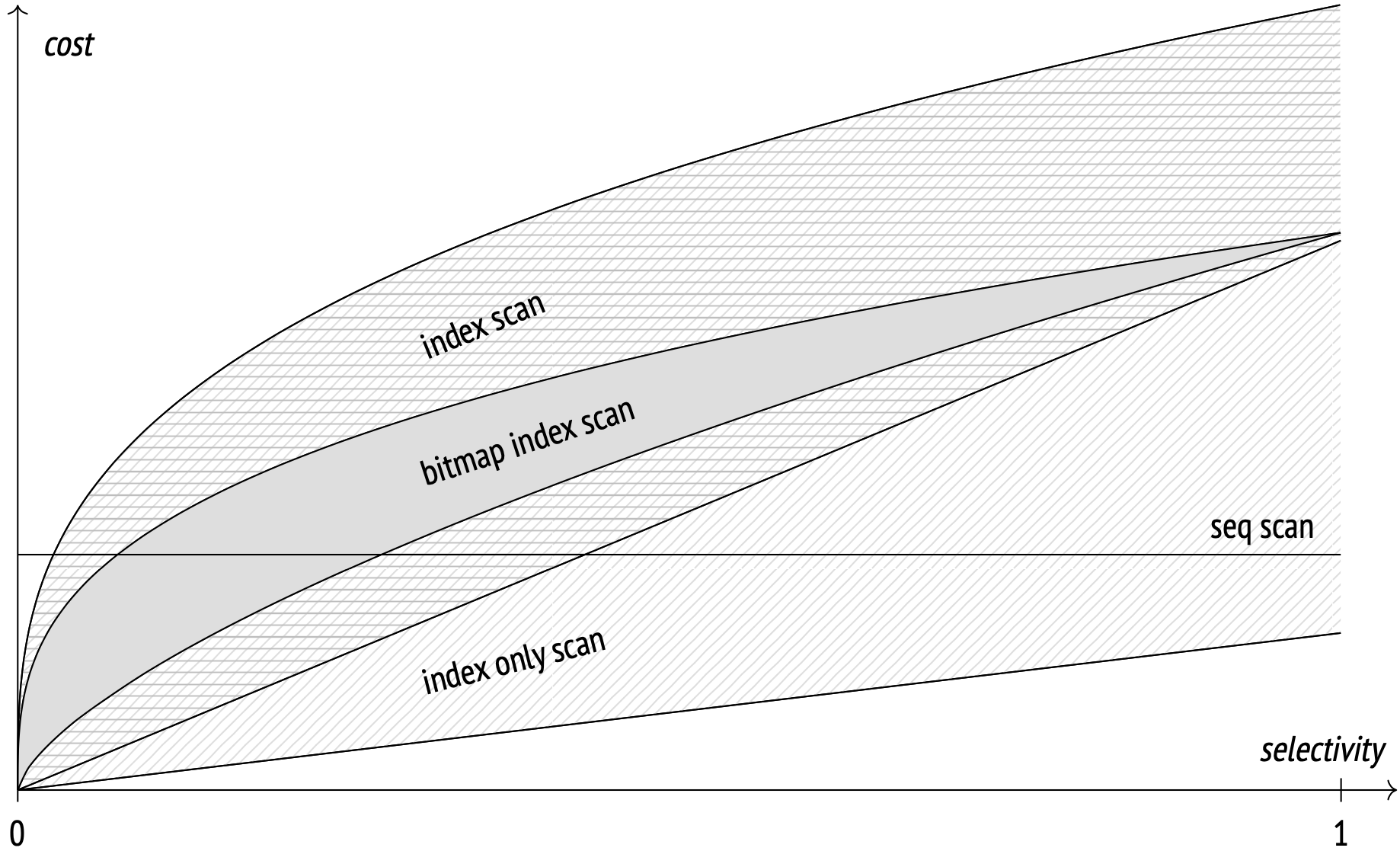
Чтобы лучше разобраться, когда тот или иной алгоритм эффективен, можно визуально их сравнить.

На графике отображена зависимость между cost и selectivity для операций объединения данных.
Показатель cost мы уже рассмотрели, а показатель selectivity может быть незнаком.
Selectivity отражает долю строк в таблице, которая будет выбрана по определённому условию запроса — это числовое значение от 0 до 1. Например, если в таблице с 1000 строк по условию фильтрации будет выбрано 100 строк, то селективность будет 100/1000 = 0,1 или 10%. Высокая селективность — это когда выбирается малое количество строк, низкая селективность — когда берется много строк, и показатель близок к 1.
При высокой селективности лучшими алгоритмами будут index scan, index only scan и bitmap index scan, так как cost у них ниже. Для низкой селективности подойдёт seq scan. Это вполне разумно: если нам нужно прочитать много строк таблицы, то лучше использовать последовательное сканирование (seq scan), а если мало строк — лучше использовать индексы (index scan, index only scan и bitmap index scan).
Методы соединения (Join Methods): Nested Loop, Hash Join, Merge Join
Чтобы соединить данные из нескольких источников или таблиц в PostgreSQL, используются специальные методы соединения.
Nested Loop Join — один из самых простых и классических алгоритмов соединения данных. Его суть сводится к перебору строк одной таблицы с последующим поиском соответствий во второй таблице. Эффективен для небольших наборов данных или когда одна из таблиц имеет достаточное количество созданных индексов.
Hash Join — метод соединения с использованием хеш-таблицы. Хеш-таблица — это структура данных, в которой происходит преобразование ключа (значения) в числовой индекс (хеш-код). Например, ключ-имя “Иван” с помощью преобразования хеш-функцией будет соответствовать 42 индексу массива. Хеш-таблица — это как быстрый справочник, где можно моментально найти нужную информацию по ключу.
Механизм работы Hash Join сводится к созданию хеш-таблицы из меньшей таблицы и поиску совпадений в большей таблице. Используется всегда, когда невозможно применить другие виды соединения: если соединяемые наборы данных достаточно велики и/или столбцы соединения не отсортированы и отсутствуют индексы. Поскольку создание хеш-таблицы — ресурсоемкий процесс, при тестировании производительности запросов Hash Join может быть принудительно отключен с помощью параметра enable_hashjoin = off, что заставит планировщик использовать альтернативные методы соединения, такие как Merge Join и Nested Loop.
Merge Join — механизм, который объединяет два отсортированных набора данных. Метод требует обязательной сортировки данных и максимально эффективен при работе с большими объёмами информации, которые уже отсортированы или их можно быстро отсортировать.
Давайте посмотрим на зависимость между cost и selectivity для операций объединения данных. И если в данных высокая селективность, то лучшими алгоритмами будут Hash Join и Merge Join + index, так как в этом случае cost у них ниже. Для запросов с низкой селективностью подойдут Nested Loop и Merge Join + sort.

Операции обработки данных: Sort, Aggregate, Filter
Операции обработки данных в системах управления базами данных (СУБД) — ключевые методы трансформации данных для удобства и эффективности анализа. Включают в себя такие операции:
Sort — упорядочивает данные по одному или нескольким столбцам. Сортировка организовывает данные в удобном для анализа виде, улучшает восприятие информации и облегчает выявление закономерностей. В отчёте EXPLAIN ее можно увидеть под названием Sort Method, а самые популярные алгоритмы для выполнения этой задачи включают quicksort и top-N heapsort. Сортировка часто используется в комбинации с операторами ORDER BY и GROUP BY.
Aggregate — вычисляет агрегированные значения на основе группировки строк. Этот этап необходим для получения сводной информации: общее количество, среднее значение или максимальное значение в подмножествах данных. В PostgreSQL реализованы два основных метода агрегации: HashAggregate и GroupAggregate, которые эффективно обрабатывают запросы с использованием функций, таких как COUNT, SUM, AVG, MAX, MIN и других. В отчёте EXPLAIN этот этап отображается, когда система группирует записи и выполняет необходимые вычисления.
Filter — отсекает строки данных по определённым условиям. Обеспечивает выборку только тех записей, которые соответствуют заданным критериям, способствуя тем самым более точному анализу. В отчёте EXPLAIN можно увидеть строку Filter: (condition), что указывает на применяемые условия в запросах, использующих операторы WHERE или HAVING, а также при выполнении операций JOIN.
Limit — ограничивает количество возвращаемых строк в результате выполнения SQL-запроса. Используя команды LIMIT или OFFSET, разработчик может управлять объемом данных, получаемых из базы. В отчёте EXPLAIN эта операция представлена с одноимённым названием, указывая, что выполнение запроса останавливается при достижении указанного предела.

Полноценный анализ производительности SQL-запросов невозможен без детального рассмотрения параметров Sort, Aggregate, Filter и Limit. Эти операции регулярно встречаются в отчетах EXPLAIN ANALYZE и напрямую влияют на производительность базы данных. Рассмотрим подробнее некоторые важные аспекты данных методов.
Фильтрация данных без применения соответствующих индексов приводит к выполнению полного последовательного сканирования таблицы (Seq Scan), что существенно увеличивает время обработки запроса и создает дополнительную нагрузку на систему.
Особенности методов агрегации:
GroupAggregate обеспечивает предсказуемую производительность с относительно стабильными показателями, но работает медленнее.
HashAggregate эффективен при обработке масштабных наборов данных, однако требует больших ресурсов памяти.
Ограничение результатов с помощью оператора LIMIT рекомендуется применять на ранних этапах выполнения запроса, до операций сортировки и агрегации. Это существенно сократит объем обрабатываемых данных и ускорит выполнение запроса.
Разбираем отчёт EXPLAIN ANALYZE: структура и расшифровка
Мы разобрали внутреннюю логику планировщика: как он рассчитывает стоимость, какие может использовать методы доступа и соединения данных. Теперь настало время увидеть результаты этой работы. Чтобы понять, какой путь выбрал оптимизатор и насколько его прогнозы соответствуют действительности, предусмотрены команды EXPLAIN и EXPLAIN ANALYZE. Эти команды — самый простой способ проверить оптимальность вашего запроса.
Команда EXPLAIN позволяет увидеть план запроса, какие алгоритмы выполнения подобрал планировщик, сразу заметить неэффективные операции.
Команда EXPLAIN ANALYZE даёт возможность не только спланировать, но и фактически выполнить запрос, получив при этом детальные метрики производительности. Будет доступно представление данных о времени выполнения запроса, обработке шагов и количестве затронутых строк.
Далее мы подробно разберём древовидную структуру плана выполнения команд и расшифруем ключевые метрики, которые помогут лучше понять, как интерпретировать эти данные.
Структура плана и формат строки-узла
Результат выполнения EXPLAIN ANALYZE имеет вид древовидной структуры из нескольких узлов. Родительский узел (как в нашем примере — Limit) находится сверху, а нижние узлы, дочерние, имеют отступ и начинаются со стрелки (->). Узлы с одинаковым отступом располагаются на одном уровне.
Корневой узел (финальная операция) │ (например: Limit, Sort, Aggregate) │ ├── Узел ОБЪЕДИНЕНИЯ (Join) │ │ (например: Hash Join, Nested Loop, Merge Join) │ │ │ ├── Ветка ЛЕВОЙ таблицы │ │ ├── Узел ЧТЕНИЯ (например: Seq Scan on table_a) │ │ └── Узел ФИЛЬТРАЦИИ (например: Filter) │ │ │ └── Ветка ПРАВОЙ таблицы │ ├── Узел ЧТЕНИЯ (например: Index Scan on table_b) │ └── Узел ТРАНСФОРМАЦИИ (например: Sort) │ └── Узел АГРЕГАЦИИ или ГРУППИРОВКИ └── Узел источника данных
PostgreSQL выполняет план снизу вверх и слева направо. Сначала отрабатывают нижние узлы (например, чтение таблицы), их результат передаётся выше (например, на фильтрацию или соединение), и так — до корневого узла, который выдаёт итоговый результат. В нашем примере все начинается с операции “Seq Scan on customers” и заканчивается на “limit”.
На верхнем уровне плана запроса (в корневой строке) указывается суммарная стоимость его выполнения. Здесь операция «limit» имеет стоимость 495.12 — именно эту величину пытается уменьшить планировщик.

С типами операций планировщика и их группировкой мы уже познакомились ранее. Рассмотрим, как они выглядят в отчёте EXPLAIN ANALYZE. Группы — это «роли» в плане. Как в театре: группа Доступа — исполнители первого плана, которые «выносят данные на сцену», обеспечивая базовый доступ к информации (Scan); группа Соединения — дирижёры процесса, координирующие взаимодействие между потоками данных (Join); группа Обработки — художники-постановщики, отвечающие за финальную трансформацию данных (Sort, Aggregate). Поток данных идет всегда снизу вверх. Сначала выполняются узлы [ДОСТУПА], их результат передаётся в [СОЕДИНЕНИЯ] или [ОБРАБОТКИ], и так до корня. Самые «тяжёлые» узлы часто находятся внизу. Если операция Seq Scan обрабатывает миллион строк, это повлияет на все узлы выше нее. Вложенность = зависимость. Узел с большим отступом — это детальная операция, результат которой нужен родительскому узлу.

Давайте более подробно рассмотрим строки EXPLAIN ANALYZE. Каждая строка плана выполнения соответствует отдельному узлу дерева и содержит информацию, логически разделённую на четыре группы: тип операции, плановые показатели, фактические показатели и дополнительные данные.
Правило чтения: Планируемые и фактические показатели всегда заключены в круглые скобки и следуют строго в указанном порядке.
Пример строки:
Index Scan using orders_pkey on orders (cost=0.43..8.45 rows=1 width=24) (actual time=0.025..0.026 rows=1 loops=1)
Здесь:
Index Scan using orders_pkey on orders — тип операции и целевой объект,
(cost=0.43..8.45 rows=1 width=24) — планируемые показатели,
(actual time=0.025..0.026 rows=1 loops=1) — фактические показатели.
Эти четыре группы формируют ядро каждой строки плана. Однако EXPLAIN ANALYZE с расширенными параметрами (buffers, verbose и др.) генерирует детализированный отчет, где вспомогательные метрики отображаются вложенными строками под основным описанием узла. В результате полный отчет EXPLAIN ANALYZE получается более информативным и состоит из следующих уровней:
Тип операции (seq scan, index scan, aggregate и др.)
Целевой объект (таблица или индекс, к которому применяется операция)
Планируемые показатели (cost, rows, width)
Фактические показатели (actual time, rows, loops)
Статистика по буферам и I/O (shared hit, local hit и др.)
Общие временные метрики всего запроса (planning time, execution time)
Дополнительные метрики (при дополнительных аргументах: VERBOSE, SETTINGS, WAL и др.).
Мы уже изучили основные типы операций и их представление в EXPLAIN ANALYZE. Теперь рассмотрим остальные уровни отчёта и научимся их корректно интерпретировать при анализе запросов.
Планируемые показатели (план «на бумаге»)
Данные метрики рассчитываются до исполнения запроса. Они позволяют получить оценку затрат — cost и увидеть алгоритм работы планировщика PostgreSQL.
Cost — один из самых значимых показателей, на который стоит обратить внимание при анализе результатов EXPLAIN ANALYZE. Поэтому его расчёт был подробно рассмотрен ранее в контексте работы планировщика PostgreSQL. Однако есть некоторые важные аспекты отображения cost в EXPLAIN ANALYZE, о которых стоит упомянуть.
Этот показатель представляет собой оценочную стоимость, которую система управления базами данных (СУБД) рассчитывает в условных единицах. Показатель представлен в виде диапазона, где первое значение указывает стоимость получения первой строки, а второе — стоимости получения всех строк.
Иногда первое значение (startup cost) может быть нулевым или около нуля, но это не должно вас настораживать. Это бывает при быстром доступе к данным, например, при последовательном сканировании (seq scan), в случаях, когда данные могут полностью извлекаться из кэша СУБД или когда извлекается малый объём данных.

Другие планируемые показатели:
Rows — прогноз о том, сколько строк будет обработано. Чем больше строк, тем дольше будет выполняться запрос.
Width — планируемый средний размер строки в байтах. Width (ширина) важна, поскольку чем шире строка, тем больше данных приходится извлекать.
Если вы заметили высокие значения width, это сигнал проверить тип данных. Он важен: например, поля типа UUID занимают 16 байт, а varchar(36) — до 77 байт. Разница в несколько раз может существенно отразиться на скорости выполнения запроса. Таким образом, оптимизация типов данных является важным аспектом эксплуатации базы данных, наряду с соблюдением правил нормализации, которые помогают избежать избыточности и повышают целостность данных.
Фактические показатели (реальное выполнение)
На основе фактических показателей можно провести точную оценку производительности запроса, сопоставить их с плановыми и сформулировать итоговые выводы.
Actual time — показывает фактическое время выполнения операции. Включает start time — время начала выполнения узла и end time — общее время выполнения узла.
Rows — реальное число строк, обработанных запросом.
Loops — значение показывает, сколько раз одна и та же операция была выполнена. Например, разные узлы внутри могут быть выполнены многократно.
В нашем примере начальное время занято 2,188 миллисекунды, общее время — 2,190 миллисекунды, строк вернулось 10, количество циклов — 1. Стоит немного подробнее рассказать об особенностях расчета времени выполнения операции. Показатель actual time указывает время на один цикл (loop). Чтобы получить полное время, затраченное узлом, нужно умножить общее время (end time) на количество loops. Например, для корневого узла “limit” общее время равно 2.190 * 1 = 2.190 мс. Кроме того, время узла включает в себя время всех его дочерних узлов. Чтобы узнать «собственное» время узла (exclusive time), из его общего времени нужно вычесть время потомков. Для корневого узла вычитание не требуется. Например, если мы хотим найти собственное время узла “Sort”, то нужно отнять общее время потомка “Seq Scan on customers”. Получим 2.187 - 1.304 = 0.883 мс.

Переходя к следующему важному аспекту, стоит обращать внимание на соответствие количества планируемых и фактических строк. Если эти значения расходятся, то, вероятно, планировщик использует устаревшую статистику, которую следует обновить. Для этого достаточно выполнить:
ANALYZE таблица;
В результате выполнения команды в нужной таблице будет обновлена статистика. Это позволит оптимизатору запросов лучше оценивать стоимость выполнения запросов, поскольку он будет использовать актуальные данные о распределении значений и количестве строк в таблице.
Статистика по буферам и I/O (аргумент BUFFERS)
Время выполнения операции (actual time) в EXPLAIN ANALYZE зависит не только от сложности операций и объёма данных, но и от источника чтения: из быстрой оперативной памяти или с более медленного постоянного хранилища. Поскольку избыточное обращение к жёсткому диску может замедлить запрос, критически важно понимать нагрузку на I/O. Именно поэтому аргумент BUFFERS рекомендуется использовать всегда, чтобы понимать реальное влияние операций ввода-вывода на производительность. А в версии PostgreSQL 18+ он включается автоматически в команде EXPLAIN ANALYZE.
Стоит рассказать об особенностях работы СУБД с хранением данных. Если все запросы однотипные и обращаются к одной и той же таблице, то СУБД кэширует блоки и блоки индексов таблиц в памяти, и их не нужно читать с диска, что значительно повышает скорость выполнения запроса. А если характер запросов постоянно меняется, то планировщик не может выбрать оптимальный план запроса и получает данные из диска, что очень медленно.
Опция BUFFERS позволяет получить:
Shared hit — показывает, сколько страниц считалось из кеша СУБД.
Read — отображает, сколько страниц считалось с диска.
Dirtied — говорит о числе страниц, измененных запросом. Может возникнуть при операциях INSERT/UPDATE и демонстрирует нагрузку на систему при модификации данных.
Written — отражает количество страниц данных, которые были физически сброшены с оперативной памяти на жесткий диск во время выполнения запроса.
В нашем примере “Buffers: shared hit=179” означает чтение из кеша (буферного кеша PostgreSQL). Операций Buffers типа read не было, а значит, не было обращений к диску. Почему это стоит отслеживать? По показателям hit и read можно сделать выводы по эффективности кэширования и использования оперативной памяти сервера. Чем больше hit и меньше read, тем эффективнее работает кэширование.

Чтобы быстро проверить эффективность кэширования, можно взглянуть на соотношение hit к read. Отношение 10:1 — обычно хороший показатель. Если read превышает 10–20% от общего числа операций, это сигнал для углубленного анализа. Возможно, нужно скорректировать конфигурацию PostgreSQL. Также это может значит, что индексы неэффективны, запросы сложны и неоптимизированны, а оперативной памяти сервера не хватает.
Также с помощью аргумента BUFFERS можно оценить объём данных, обрабатываемых в операциях. Это помогает выявить нагрузку запроса и возможные аномалии (например, избыточное чтение страниц). В нашем примере объем данных из кеша составил 179 блоков × 8 КБ ≈ 1.4 MB данных. Это нормальный и ожидаемый результат.
Общие временные метрики всего запроса
Отчет EXPLAIN ANALYZE в PostgreSQL предоставляет два ключевых показателя: время планирования (Planning Time) и время исполнения (Execution Time). Понимание разницы между ними помогает точнее диагностировать проблемы производительности. Показатели представлены в миллисекундах. Давайте разберемся, что именно измеряет каждый из этих показателей.
Время планирования — это время на работу планировщика, о котором мы уже упоминали. В это время планировщик перебирает стоимостные модели.
Время исполнения — это время, за которое происходит выполнение запроса.
В нашем примере на планирование ушло 0,439 мс, а на все выполнение — еще 2,220 мс. Обычно время планирования и время выполнения отличаются. Если запрос прост — например, выборка из небольшой таблицы — расхождение допустимо.

Однако в случае со сложными запросами, обрабатывающими значительные объёмы данных, следует обращать особое внимание на следующие показатели:
Если время планирования (Planning Time) превышает ~ 30% от общего времени выполнения (Execution Time)
Или если время планирования превышает ~ 10 мс
В большинстве случаев, если время планирования запроса сравнимо со временем его выполнения или, тем более, значительно больше, это может указывать на проблемы с актуальностью статистики. Во время планирования оптимизатор опирается на заранее собранную статистику. Если эта статистика устарела из-за интенсивных изменений данных, планировщик вынужден работать с неточными оценками, что может привести к перебору альтернативных планов или применению сложных операций — и как следствие, к увеличению времени планирования.
Для того чтобы увеличить скорость выполнения запроса, нам нужно стараться повлиять на оба показателя в комплексе: как на планирование (Planning Time), так и на исполнение (Execution Time). Например, для улучшения времени планирования достаточно актуализировать статистику, а для времени на исполнение возможны варианты: от изменения запроса до обновления жестких дисков сервера.
Анализ времени планирования и исполнения в отчете EXPLAIN ANALYZE — ключевой элемент для оценки эффективности оптимизации запросов. Именно по изменению этих двух времен до и после правок мы можем однозначно судить, принесла ли оптимизация реальный результат.
Дополнительные аргументы (VERBOSE, FORMAT, SETTINGS, WAL)
Бывают ситуации, когда стандартного вывода EXPLAIN ANALYZE недостаточно. Для таких случаев существуют некоторые дополнительные аргументы для команды EXPLAIN ANALYZE, которые позволяют расширить возможности для анализа показателей запросов. С полным списком можете ознакомится в документации PostgreSQL.
Самые популярные аргументы:
VERBOSE — предоставляет детальную информацию о плане выполнения. Когда необходим более глубокий анализ внутренней работы запроса.
FORMAT — позволяет выбрать формат вывода. В числе поддерживаемых: JSON, XML, YAML. Например, можете выбрать JSON-формат и визуализировать результат в стороннем сервисе.
SETTINGS — позволяет временно изменять параметры выполнения запроса. Например: запретить последовательное сканирование или изменить стоимость случайного доступа. Удобная опция, позволяющая настраивать оптимизацию без постоянного изменения конфигурации СУБД.
WAL — параметр (Write-Ahead Logging) показывает, как данные записываются в журнал во время выполнения запроса. Он гарантирует целостность данных и позволяет восстановить систему после сбоев. Анализ показателей WAL помогает выявить проблемы с производительностью записи и оптимизировать настройки для высоких нагрузок. Опция для более опытных пользователей PostgreSQL.
Например, при выполнении запроса EXPLAIN ANALYZE с дополнительными параметрами:
SET random_page_cost = 1.5; EXPLAIN (ANALYZE, VERBOSE, SETTINGS TRUE) SELECT id FROM test;
Получим следующий результат:

Заметим, что в результате добавления команды VERBOSE появилось дополнительное поле Output: id. Этот параметр предоставляет информацию о том, какие именно данные будут извлечены. Это помогает убедиться, что вы получаете именно те поля, которые ожидаете. Это особенно полезно в сложных запросах. Также появилось дополнительное поле: Settings: random_page_cost = '1.5', так как р��нее мы изменили значение командой SET. Подобные настройки дают возможность тестировать различные параметры и их влияние на производительность запроса без постоянных изменений в конфигурации.
Дополнительные параметры могут повысить гибкость и информативность отчета, позволяя пользователям адаптировать выводы под конкретные задачи и потребности.
Выводы. Практический чек-лист для анализа
Для чтения плана EXPLAIN ANALYZE можно использовать небольшой чек-лист:
1. Найти узкое место по времени
Критерий: Узел, где actual time превышает ~30% от Execution Time.
Действие: Оптимизируйте в первую очередь эту операцию.
2. Проверить точность оценок планировщика
Критерий: Расхождение rows (план) и rows (факт) в 10+ раз.
Действие: Выполните ANALYZE таблица;.
3. Оценить стоимость операций
Критерий: Узлы с максимальной cost (особенно второе число в диапазоне).
Действие: Ищите способ снизить стоимость: добавьте индекс, попробуйте переписать запрос, проверка объема выборки.
4. Проверить базовые методы
Критерий: Seq Scan на больших таблицах или Nested Loop с большим внутренним циклом.
Действие: Ищите способ заменить на более быстрые алгоритмы Index Scan, Hash join: добавьте индекс, попробуйте переписать запрос.
5. Проанализировать фильтрацию
Критерий: Узел, где Rows Removed by Filter превышает ~80% от прочитанных строк в конце плана выполнения.
Действие: Попробуйте переписать запрос с целью переноса условия фильтра ближе к началу выполнения, добавьте индекс.
6. Оценить работу с кешем (I/O)
Критерий: Высокий shared read при низком shared hit в BUFFERS.
Действие: Оцените настройки конфигурации shared_buffers, доступный объем оперативной памяти на сервере, попробуйте переписать запрос.
7. Учесть вариативность
Критерий: Замеры на «холодном» и «горячем» кеше отличаются в разы.
Действие: Тестируйте несколько раз. Основной ориентир — Execution Time при повторных запусках.
EXPLAIN ANALYZE в PostgreSQL — это мощный инструмент, который помогает понять, как выполняются запросы. Анализируя план выполнения запросов, мы можем оперативно выявлять потенциальные проблемы с производительностью и исправлять их.
Во второй части гайда я подробнее расскажу о работе со статистикой в PostgreSQL и покажу, как можно применять EXPLAIN ANALYZE на практике.
Автор текста Макаренков Вячеслав
НЛО прилетело и оставило здесь промокод для читателей нашего блога:
-15% на заказ любого VDS (кроме тарифа Прогрев) — HABRFIRSTVDS


{kind=link}