В этом топике я хочу описать некоторые базовые различия между примитивными типами и соответствующими им объектными на примере int и Integer. Различия эти достаточно простые и, если немного задуматься, то вполне логичные, но, как показал опыт, программист не всегда над этим задумывается.
Основное различие, разумеется, в том, что Integer — это полнофункциональный объект, который занимает место в куче, а в коде вы пользуетесь ссылками на него, которые неявно преобразуются в значения:
Однако в большинстве случаев создаётся новый объект, и это может быть существенно. Помните так же, что объект Integer никогда не меняет своего значения. Рассмотрим такой на первый взгляд невинный код:
Очевидно, при каждом инкременте создаётся новый объект Integer, а старые затем подчищаются сборщиком мусора, когда их накапливается порядка ста тысяч. Неплохая нагрузка на систему для обычной операции инкремента.
В целом понятно, что Integer надо использовать только тогда, когда без него не обойтись. Один из таких примеров — это параметризованные типы (generics), к примеру, стандартные коллекции. Но и тут надо быть аккуратным, чтобы использовать память разумно. Я приведу несколько утрированный пример на основе проблемы, с которой я столкнулся в реальном проекте. В некотором научном анализе требовалось ассоциировать с определёнными объектами длинные множества натуральных чисел. Можно сэмулировать это следующим кодом:
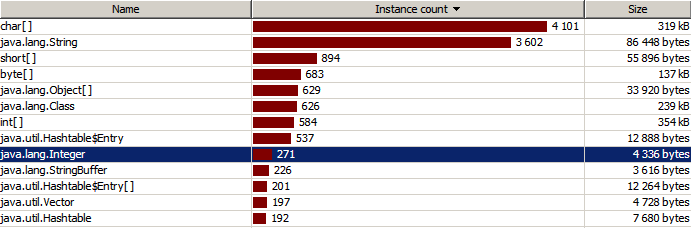
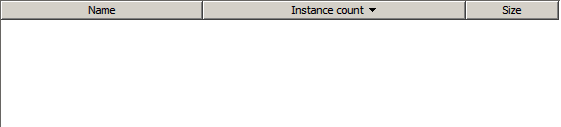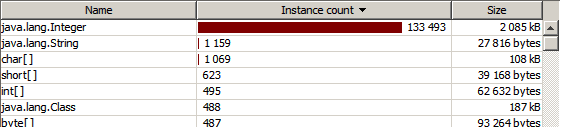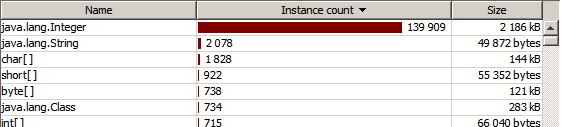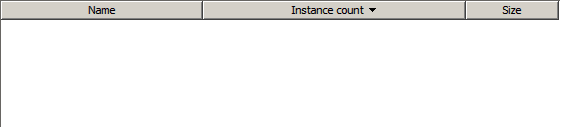
А вот после:
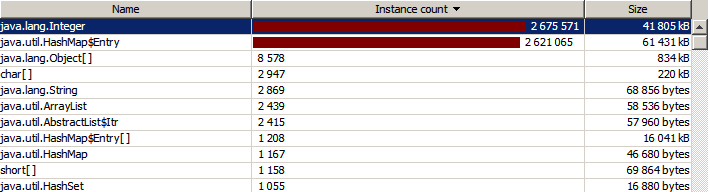
Принудительный запуск сборщика мусора помог несильно:

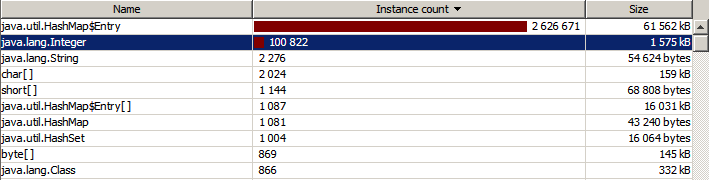
40 мегабайт памяти съедают целые числа — это печально. Причина кроется в прототипе метода put:
Из-за того, что здесь использован тип int, значения переменной i при передаче в метод автоматически преобразуются в int (unboxing), а затем заново в Integer (boxing), но уже создаётся новый объект. Заменим в прототипе
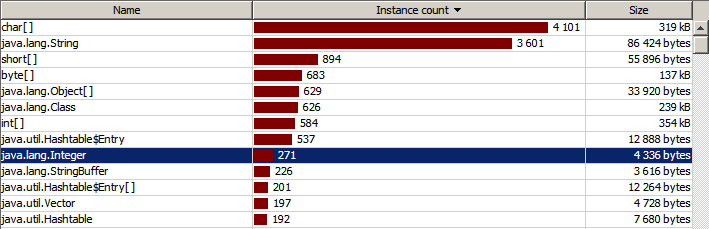
Зато в конце значительные отличия:
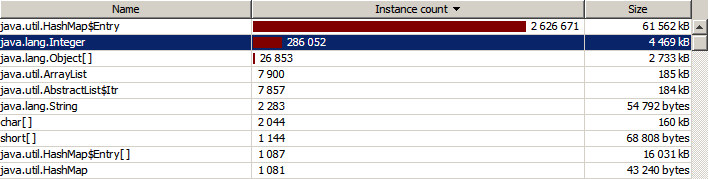
И после сборки мусора:
Так, заменив один int на Integer, можно сэкономить около 40% используемой памяти. Заметим, что в
Основное различие, разумеется, в том, что Integer — это полнофункциональный объект, который занимает место в куче, а в коде вы пользуетесь ссылками на него, которые неявно преобразуются в значения:
int a = 1000; // a - число
Integer b = 1000; // b - ссылка на объектnew Integer(1000) (так называемый autoboxing). Однако иногда переиспользуются старые объекты. Это иллюстрирует следующий код (JDK 1.6):Integer a1 = 50;
Integer a2 = 50;
Integer b1 = 500;
Integer b2 = 500;
System.out.println(a1==a2);
System.out.println(b1==b2);true
falseОднако в большинстве случаев создаётся новый объект, и это может быть существенно. Помните так же, что объект Integer никогда не меняет своего значения. Рассмотрим такой на первый взгляд невинный код:
public class Increment
{
public static void main(String[] args)
{
Integer a=0;
while(true) a++;
}
}Очевидно, при каждом инкременте создаётся новый объект Integer, а старые затем подчищаются сборщиком мусора, когда их накапливается порядка ста тысяч. Неплохая нагрузка на систему для обычной операции инкремента.
В целом понятно, что Integer надо использовать только тогда, когда без него не обойтись. Один из таких примеров — это параметризованные типы (generics), к примеру, стандартные коллекции. Но и тут надо быть аккуратным, чтобы использовать память разумно. Я приведу несколько утрированный пример на основе проблемы, с которой я столкнулся в реальном проекте. В некотором научном анализе требовалось ассоциировать с определёнными объектами длинные множества натуральных чисел. Можно сэмулировать это следующим кодом:
import java.util.*;
public class MapInteger
{
static Map<Integer, Set<Integer>> subSets = new HashMap<Integer, Set<Integer>>();
public static void put(Integer key, int value)
{
if(!subSets.containsKey(key)) subSets.put(key, new HashSet<Integer>());
subSets.get(key).add(value);
}
public static Collection<Integer> getRandomKeys()
{
List<Integer> vals = new ArrayList<Integer>();
for(int i=0; i<(int)(Math.random()*500); i++)
{
vals.add((int)(Math.random()*1000));
}
return vals;
}
public static void main(String[] args)
{
new Scanner(System.in).nextLine();
for(Integer i=0; i<100000; i++)
{
for(Integer key: getRandomKeys())
put(key, i);
}
new Scanner(System.in).nextLine();
}
}А вот после:
Принудительный запуск сборщика мусора помог несильно:
40 мегабайт памяти съедают целые числа — это печально. Причина кроется в прототипе метода put:
public static void put(Integer key, int value)Из-за того, что здесь использован тип int, значения переменной i при передаче в метод автоматически преобразуются в int (unboxing), а затем заново в Integer (boxing), но уже создаётся новый объект. Заменим в прототипе
int value на Integer value и запустим профайлер заново. В начале картина такая же:Зато в конце значительные отличия:
И после сборки мусора:
Так, заменив один int на Integer, можно сэкономить около 40% используемой памяти. Заметим, что в
for(Integer i=0; i<100000; i++) тоже неслучайно используется Integer: напишем здесь int, и первое исправление не поможет. Видим, что правило писать int везде, где можно не писать Integer, работает не всегда: в каждом отдельном случае надо думать. Иногда также может пригодиться собственная реализация кэша целых чисел.
