В комментариях к блестящему топику «Как выглядит китайская клавиатура» высказали интересную идею: рассказать про набор текста в разных языках с необычной письменностью.
Арабам относительно повезло: у них лишь 28 букв — даже меньше, чем в русском. Каждой букве можно назначить отдельную клавишу, и ещё останутся свободные. Зато с их письменностью возникают свои сложности, неведомые китайцам.
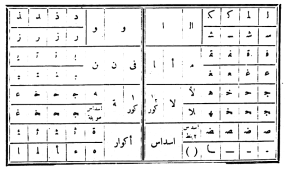
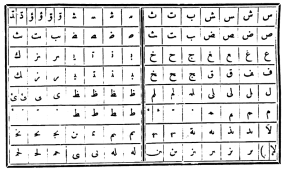
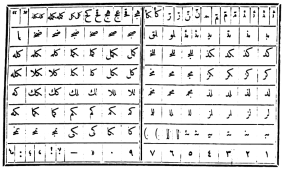
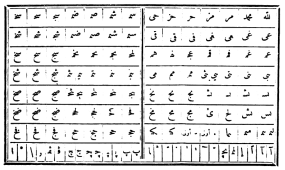
По стандарту 1906 г., арабский шрифт должен был состоять из 470 литер. В 1945 г. приняли новый стандарт, сокративший число литер до 72: теперь литера соответствовала не букве целиком, а графическому элементу — например, отдельно «подкова», и отдельно «хвостик». На все 28 букв есть всего несколько различных форм хвостиков, что позволяет сократить число различных литер. Кроме того, в новом стандарте отказались от диакритики и от большинства лигатур. Что важно, новый стандарт был «обратно совместимым»: все новые литеры можно было получить из старых, распиливая их на части. Не нужно было отливать новые шрифты: можно было «апгрейдить» существующие. Диакритические же значки в случае необходимости врисовывались в текст вручную.
Сокращённый стандарт был принят за основу арабского машинописного шрифта; адаптация была необходима из-за того, что в печати «хвостик» мог набираться под буквой, но в машинописи буквы следовали одна за другой в строчку. Ровная строчка однообразных букв, наверное, соответствовала европейским понятиям о типографике; но от традиционных печатных и рукописных текстов, где форма и положение букв менялись в зависимости от контекста, она отличалась разительно.
Каретка печатной машинки двигалась справа налево, не позволяя вставлять в текст фрагменты латиницей. (Числа тоже набирались справа налево.) «Урезанные» символы (буквы заодно с хвостиками, цифры, основная пунктуация) заполнили все четыре ряда клавиш, в обоих регистрах:


В верхнем регистре верхнего ряда — цифры (от 0 и 1 справа до 9 слева); слева от ряда цифр — табуляция; ниже — CapsLock, ещё ниже — Shift. Справа, под Backspace — возврат каретки (красный), под ним — Shift. Для большинства клавиш, символы в двух регистрах образуют пару «буква без хвостика, та же буква с хвостиком». Ещё можно заметить, что расположение пунктуации на этих двух клавиатурах не полностью совпадает.
Первые арабские текстовые процессоры, естественно, приняли за основу раскладку арабской печатной машинки, и соответствующий набор символов. Но если в машинописи ещё можно обойтись без латиницы, то в компьютере — вряд ли; поэтому с самого начала стояла проблема создания двуязычной латинско-арабской кодировки.
В кодировке DOS для арабского (CP-864) обнаруживаем по символу для каждой литеры арабской печатной машинке. Они почти полностью заполнили верхнюю (нелатинскую) половину кодировки, не оставив места даже для традиционной досовской псевдографики. Важно заметить, что это визуальная кодировка: она кодирует не сам текст, а то, как он выглядит на экране. Даже сами символы печатались слева направо: ОС была не в курсе, что часть символов «особенные», и выводила все одинаково. Естественно, что для программ обработки текста это был ад: даже поиск в тексте заданного сочетания букв оказывался нетривиальным.
Более поздняя DOS-кодировка, CP-708, содержит по единственному символу для каждой арабской буквы, поэтому в ней осталось место и для псевдографики, и для французских дополнительных букв — для применения в странах Магриба, где вторым языком является французский. ОС по-прежнему выводит все символы слева направо, но теперь она уже умеет опознавать сочетания соседних арабских букв, и отображать их правильно соединёнными. Арабский текст записывается «логически» — каждый символ соответствует букве — но задом наперёд: от конца предложения к началу. Это означает, например, что каждую вводимую с клавиатуры строчку приходилось «разворачивать», чтоб можно было показать её на экране.
На сайте Microsoft нет ни малейшего упоминания CP-864; вероятно, её делали «на коленке» местные умельцы, не озабоченные совместимостью ни с независимыми стандартами, ни с европейскими вариантами DOS. (Похожим образом, вообще говоря, появилась и CP-866. Её создание уже описано самими создателями; маленькая выдержка: «Нужно написать о том, как решалась судьба буквы Ё. У Давыдова на даче по этому поводу была собрана вся наша команда, и под водочку мы решили, что без этой буквы русский язык много чего потеряет — так буква Ё получила право на существование.») С другой стороны, CP-708 совместима со стандартом ISO-8859-6, разработанным, ни много ни мало, международной «арабской организацией по стандартизации и метрологии» (ASMO). Стандарт определяет не все 256 символов; CP-708 доопределила стандарт, добавив в кодировку псевдографику и французские буквы. На Макинтошах применялась арабская кодировка, также совместимая с ISO-8859-6, но несовместимая с CP-708: тамошние арабификаторы дополнили её по-своему, добавив французские буквы в другом порядке, и заменив псевдографику «зеркальной пунктуацией», о которой мы ещё упомянём.
Любопытно, что в раскладке от Microsoft осталась «обязательная» лигатура لا, упомянутая в начале поста; при нажатии этой клавиши вводится пара символов لـ+ـا, как если бы их нажали последовательно.
Латинская часть раскладки соответствовала французской AZERTY — у магрибинцев, и американской QWERTY — на востоке:



На первой фотографии — марокканская клавиатура, на второй — йеменская, на третьей — катарский макбук.
Для Windows выдумали новую, ни с чем не совместимую арабскую кодировку CP-1256, хотя раскладку клавиатуры оставили старую. (Ветераны помнят, как в русской раскладке для Windows перетасовали пунктуацию.) Как и в предыдущие кодировки, в CP-1256 вошли заодно с арабскими буквами французские, а также новые появившиеся в Windows типографические символы: длинное тире, неразрывный пробел, и т.п.
Другая важная новая фича Windows — логический порядок букв в тексте: предложения записываются от начала к концу, и выводятся на экран справа налево, как положено. Когда в одной строчке сочетаются латиница и арабица, Windows высокоинтеллектуально догадывается, в каких точках нужно изменить направление вывода; выводимые буквы прыгают взад и вперёд по всей строчке, образуя визуальные разрывы в логически непрерывных блоках текста, как было проиллюстрировано разорванной ссылкой в начале поста.
Но самая заморочная проблема с логическим направлением письма — это ориентация парных символов, например скобок. Предположим, араб напечатал предложение, и взял в нём одно слово в скобки. Это значит, правую скобку он напечатал раньше левой. Если использовать визуальный порядок, как в DOS, то никакой проблемы нет: араб печатает «аб)вг(де»; мы при вводе разворачиваем строку и храним её в виде «ед(гв)ба»; если напечатаем её слева направо, получим именно то, что араб имел в виду. При логическом же порядке, введённая строка так и будет храниться в виде «аб)вг(де», а значит, любая программа обработки текста споткнётся о непарные скобки. Есть несколько вариантов решения: можно переписать программу так, чтобы внутри арабского предложения она трактовала скобки наоборот. Можно объявить, что в арабской раскладке набираются особые «арабские скобки», для которых правая всегда должна идти перед левой. (Именно эту «зеркальную пунктуацию» добавили в арабскую кодировку для Макинтошей; у каждого парного знака препинания были отдельные «латинский» и «арабский» варианты.) Тогда неарабифицированная программа обработки текста просто не заметит арабские скобки, а арабифицированная будет уметь правильно их обрабатывать. С одной стороны, это удобнее, чем первое решение: тут не нужно анализировать контекст, чтобы определять про каждую скобку, «латинская» она или «арабская»; с другой стороны, символы, которые вводятся одинаково, выглядят одинаково, но обрабатываются по-разному, — вызывают жуткую путаницу. Наверняка вам не единожды доводилось путать русскую «с» и латинскую «c»; представьте себе, каково было арабам со скобками.
В Юникоде используется третье решение: объявим, что нет символов «левая скобка» и «правая скобка», а есть «открывающая скобка» и есть «закрывающая». В любом тексте открывающая скобка должна идти перед закрывающей. В латинской раскладке клавиша «левая скобка» вводит открывающую скобку, а «правая» — закрывающую; в арабской раскладке — наоборот. Аналогично при выводе: в арабском тексте отображаем открывающую скобку как левую, а закрывающую как правую; в тексте латиницей — наоборот. Как и в первом решении, здесь приходится анализировать для каждой скобки контекст; но теперь это возлагается не на прикладную программу, а на процедуру отрисовки текста в операционной системе. Всё описанное касается не только круглых скобок, но и квадратных, и фигурных, и знаков «больше-меньше», и ещё десятков символов Юникода. Одна из частей этого стандарта — список «зеркальных пар», которые должны взаимозаменяться при выводе арабского текста. Стандарт регламентирует также и алгоритм определения «ориентации» скобок по их контексту. Для текстов на естественных языках он даёт более-менее приемлемые результаты, но, например, код на языках программирования чаще всего содержит причудливые сочетания знаков препинания, которые превращают двуязычный код в нечитаемую кашу.
Поэтому в исходниках, в смсках, а также на просторах Интернета — в мессенджерах, чатах и форумах, где поддержка арабского письма оставляет желать лучшего, — арабы по сей день интенсивно пользуются транслитом. Так одним махом решаются все перечисленные в начале поста проблемы. Арабский «интернет-транслит» примечателен тем, что буквы, для которых не нашлось соответствия в латинице, обозначаются цифрами: например, «Hlalik mal3ab lin-najmat feeki byet3'anna el 7adi» соответствует в ISO-транслитерации «hlālik malʿab li-n-naǧmāt, fīki byatḡanna al-ḥādī». (Эта строчка знакома многим в виде «Денег мало, длинный шмель, ты в кибитку не ходи».) Заменит ли транслит традиционную письменность, тем самым избавляя арабов от столь многих сложностей? Это предположение не такое фантастическое, каким кажется на первый взгляд: мальтийский диалект арабского пользуется латиницей уже несколько веков. Развитие и распространение ИТ будут настойчиво подталкивать в эту сторону и остальных арабов.
Арабам относительно повезло: у них лишь 28 букв — даже меньше, чем в русском. Каждой букве можно назначить отдельную клавишу, и ещё останутся свободные. Зато с их письменностью возникают свои сложности, неведомые китайцам.
- Позиционные формы букв. Арабы пишут слитным курсивом, поэтому одна и та же буква может менять форму в зависимости от положения в слове. Грубо говоря, на конце слова у буквы будет «хвостик», в середине — «соединение», и т.п.
Для примера, буква ع, когда она в конце слова, выглядит как ـع, когда в начале — عـ, когда в середине — ـعـ
«Ядро» этой буквы — с-образная «подкова», к которой может добавляться росчерк налево и вниз в конце слова, и может добавляться соединение с предыдущей буквой, образуя петельку. - Слитные написания (лигатуры). В отличие от латиницы, в которой есть две «стандартные» лигатуры æ и œ и несколько «опциональных» (например, fi, ff, ft), — традиция арабской типографики насчитывает буквально сотни лигатур, от «обязательных», которые будет ошибкой напечатать раздельными символами, до «каллиграфических», которые только в самых изысканных шрифтах реализованы слитной литерой.
Например, сочетание لـا режет арабу глаза: символы должны завиться узелком, образуя лигатуру لا.
Другая стандартная лигатура — لمـ. В экранных шрифтах она обычно не реализована, но в печати вертикальную палочку всегда соединят с узелком:ﳌ
Из экзотических лигатур: буквы слова لحم иногда не соединют в строчку, а печатают одну над другой — Приближается к уровню идеографического письма, не находите?
Приближается к уровню идеографического письма, не находите?
В Юникоде предусмотрели символ даже для лигатуры-фразы «да благословит его Аллах и приветствует»: ﷺ Эту фразу, хотя бы в виде неразборчиво мелкой лигатуры, положено употреблять после упоминания имени Пророка. - Диакритические символы. В повседневных текстах гласные не обозначаются, но когда нужно указать точное произношение слова (в словарях, в учебниках, в незнакомом или неоднозначном слове — аналогично проставлению ударений в текстах на русском), то гласные обозначаются особыми значками над или под буквами текста. Этих дополнительных значков набирается больше десятка.
- Направление письма. Когда приходится смешивать арабский текст с латиницей, из-за смены направления посреди строк текст легко превращается в кашу. Например, ويوم بصل эта ссылка يوم عسل выглядит разорванной на три части — но все они одновременно подсвечиваются при наведении курсора, подтверждая, что это одна ссылка, а не три. (Попробуйте выделить её мышью — выделение тоже будет разорвано на три части!)
- С другой стороны, в отличие от европейских алфавитов, в арабском нет «заглавных» и «прописных» букв — поэтому «верхний регистр» клавиатуры можно переприспособить под другие нужды.




По стандарту 1906 г., арабский шрифт должен был состоять из 470 литер. В 1945 г. приняли новый стандарт, сокративший число литер до 72: теперь литера соответствовала не букве целиком, а графическому элементу — например, отдельно «подкова», и отдельно «хвостик». На все 28 букв есть всего несколько различных форм хвостиков, что позволяет сократить число различных литер. Кроме того, в новом стандарте отказались от диакритики и от большинства лигатур. Что важно, новый стандарт был «обратно совместимым»: все новые литеры можно было получить из старых, распиливая их на части. Не нужно было отливать новые шрифты: можно было «апгрейдить» существующие. Диакритические же значки в случае необходимости врисовывались в текст вручную.
Сокращённый стандарт был принят за основу арабского машинописного шрифта; адаптация была необходима из-за того, что в печати «хвостик» мог набираться под буквой, но в машинописи буквы следовали одна за другой в строчку. Ровная строчка однообразных букв, наверное, соответствовала европейским понятиям о типографике; но от традиционных печатных и рукописных текстов, где форма и положение букв менялись в зависимости от контекста, она отличалась разительно.
Каретка печатной машинки двигалась справа налево, не позволяя вставлять в текст фрагменты латиницей. (Числа тоже набирались справа налево.) «Урезанные» символы (буквы заодно с хвостиками, цифры, основная пунктуация) заполнили все четыре ряда клавиш, в обоих регистрах:
В верхнем регистре верхнего ряда — цифры (от 0 и 1 справа до 9 слева); слева от ряда цифр — табуляция; ниже — CapsLock, ещё ниже — Shift. Справа, под Backspace — возврат каретки (красный), под ним — Shift. Для большинства клавиш, символы в двух регистрах образуют пару «буква без хвостика, та же буква с хвостиком». Ещё можно заметить, что расположение пунктуации на этих двух клавиатурах не полностью совпадает.
Первые арабские текстовые процессоры, естественно, приняли за основу раскладку арабской печатной машинки, и соответствующий набор символов. Но если в машинописи ещё можно обойтись без латиницы, то в компьютере — вряд ли; поэтому с самого начала стояла проблема создания двуязычной латинско-арабской кодировки.
В кодировке DOS для арабского (CP-864) обнаруживаем по символу для каждой литеры арабской печатной машинке. Они почти полностью заполнили верхнюю (нелатинскую) половину кодировки, не оставив места даже для традиционной досовской псевдографики. Важно заметить, что это визуальная кодировка: она кодирует не сам текст, а то, как он выглядит на экране. Даже сами символы печатались слева направо: ОС была не в курсе, что часть символов «особенные», и выводила все одинаково. Естественно, что для программ обработки текста это был ад: даже поиск в тексте заданного сочетания букв оказывался нетривиальным.
Более поздняя DOS-кодировка, CP-708, содержит по единственному символу для каждой арабской буквы, поэтому в ней осталось место и для псевдографики, и для французских дополнительных букв — для применения в странах Магриба, где вторым языком является французский. ОС по-прежнему выводит все символы слева направо, но теперь она уже умеет опознавать сочетания соседних арабских букв, и отображать их правильно соединёнными. Арабский текст записывается «логически» — каждый символ соответствует букве — но задом наперёд: от конца предложения к началу. Это означает, например, что каждую вводимую с клавиатуры строчку приходилось «разворачивать», чтоб можно было показать её на экране.
На сайте Microsoft нет ни малейшего упоминания CP-864; вероятно, её делали «на коленке» местные умельцы, не озабоченные совместимостью ни с независимыми стандартами, ни с европейскими вариантами DOS. (Похожим образом, вообще говоря, появилась и CP-866. Её создание уже описано самими создателями; маленькая выдержка: «Нужно написать о том, как решалась судьба буквы Ё. У Давыдова на даче по этому поводу была собрана вся наша команда, и под водочку мы решили, что без этой буквы русский язык много чего потеряет — так буква Ё получила право на существование.») С другой стороны, CP-708 совместима со стандартом ISO-8859-6, разработанным, ни много ни мало, международной «арабской организацией по стандартизации и метрологии» (ASMO). Стандарт определяет не все 256 символов; CP-708 доопределила стандарт, добавив в кодировку псевдографику и французские буквы. На Макинтошах применялась арабская кодировка, также совместимая с ISO-8859-6, но несовместимая с CP-708: тамошние арабификаторы дополнили её по-своему, добавив французские буквы в другом порядке, и заменив псевдографику «зеркальной пунктуацией», о которой мы ещё упомянём.
Арабская раскладка клавиатуры получилась из раскладки печатной машинки: там, где клавише в обоих регистрах соответствовала одна буква, оставили эту букву; там, где разные — по возможности оставили одну из них. Освободившийся верхний регистр раскладки заняли диакритикой и пунктуацией. Неудивительно, что Apple сделали всё по-своему, и оставили на «спорных» клавишах другие буквы; так что на их арабских клавиатурах даже порядок букв отличается, не говоря уже о пунктуации.
Включите фоном арабскую музыку! (тема из Civilization IV: Warlords)
Любопытно, что в раскладке от Microsoft осталась «обязательная» лигатура لا, упомянутая в начале поста; при нажатии этой клавиши вводится пара символов لـ+ـا, как если бы их нажали последовательно.
Латинская часть раскладки соответствовала французской AZERTY — у магрибинцев, и американской QWERTY — на востоке:
На первой фотографии — марокканская клавиатура, на второй — йеменская, на третьей — катарский макбук.
Для Windows выдумали новую, ни с чем не совместимую арабскую кодировку CP-1256, хотя раскладку клавиатуры оставили старую. (Ветераны помнят, как в русской раскладке для Windows перетасовали пунктуацию.) Как и в предыдущие кодировки, в CP-1256 вошли заодно с арабскими буквами французские, а также новые появившиеся в Windows типографические символы: длинное тире, неразрывный пробел, и т.п.
Другая важная новая фича Windows — логический порядок букв в тексте: предложения записываются от начала к концу, и выводятся на экран справа налево, как положено. Когда в одной строчке сочетаются латиница и арабица, Windows высокоинтеллектуально догадывается, в каких точках нужно изменить направление вывода; выводимые буквы прыгают взад и вперёд по всей строчке, образуя визуальные разрывы в логически непрерывных блоках текста, как было проиллюстрировано разорванной ссылкой в начале поста.
Но самая заморочная проблема с логическим направлением письма — это ориентация парных символов, например скобок. Предположим, араб напечатал предложение, и взял в нём одно слово в скобки. Это значит, правую скобку он напечатал раньше левой. Если использовать визуальный порядок, как в DOS, то никакой проблемы нет: араб печатает «аб)вг(де»; мы при вводе разворачиваем строку и храним её в виде «ед(гв)ба»; если напечатаем её слева направо, получим именно то, что араб имел в виду. При логическом же порядке, введённая строка так и будет храниться в виде «аб)вг(де», а значит, любая программа обработки текста споткнётся о непарные скобки. Есть несколько вариантов решения: можно переписать программу так, чтобы внутри арабского предложения она трактовала скобки наоборот. Можно объявить, что в арабской раскладке набираются особые «арабские скобки», для которых правая всегда должна идти перед левой. (Именно эту «зеркальную пунктуацию» добавили в арабскую кодировку для Макинтошей; у каждого парного знака препинания были отдельные «латинский» и «арабский» варианты.) Тогда неарабифицированная программа обработки текста просто не заметит арабские скобки, а арабифицированная будет уметь правильно их обрабатывать. С одной стороны, это удобнее, чем первое решение: тут не нужно анализировать контекст, чтобы определять про каждую скобку, «латинская» она или «арабская»; с другой стороны, символы, которые вводятся одинаково, выглядят одинаково, но обрабатываются по-разному, — вызывают жуткую путаницу. Наверняка вам не единожды доводилось путать русскую «с» и латинскую «c»; представьте себе, каково было арабам со скобками.
В Юникоде используется третье решение: объявим, что нет символов «левая скобка» и «правая скобка», а есть «открывающая скобка» и есть «закрывающая». В любом тексте открывающая скобка должна идти перед закрывающей. В латинской раскладке клавиша «левая скобка» вводит открывающую скобку, а «правая» — закрывающую; в арабской раскладке — наоборот. Аналогично при выводе: в арабском тексте отображаем открывающую скобку как левую, а закрывающую как правую; в тексте латиницей — наоборот. Как и в первом решении, здесь приходится анализировать для каждой скобки контекст; но теперь это возлагается не на прикладную программу, а на процедуру отрисовки текста в операционной системе. Всё описанное касается не только круглых скобок, но и квадратных, и фигурных, и знаков «больше-меньше», и ещё десятков символов Юникода. Одна из частей этого стандарта — список «зеркальных пар», которые должны взаимозаменяться при выводе арабского текста. Стандарт регламентирует также и алгоритм определения «ориентации» скобок по их контексту. Для текстов на естественных языках он даёт более-менее приемлемые результаты, но, например, код на языках программирования чаще всего содержит причудливые сочетания знаков препинания, которые превращают двуязычный код в нечитаемую кашу.
Поэтому в исходниках, в смсках, а также на просторах Интернета — в мессенджерах, чатах и форумах, где поддержка арабского письма оставляет желать лучшего, — арабы по сей день интенсивно пользуются транслитом. Так одним махом решаются все перечисленные в начале поста проблемы. Арабский «интернет-транслит» примечателен тем, что буквы, для которых не нашлось соответствия в латинице, обозначаются цифрами: например, «Hlalik mal3ab lin-najmat feeki byet3'anna el 7adi» соответствует в ISO-транслитерации «hlālik malʿab li-n-naǧmāt, fīki byatḡanna al-ḥādī». (Эта строчка знакома многим в виде «Денег мало, длинный шмель, ты в кибитку не ходи».) Заменит ли транслит традиционную письменность, тем самым избавляя арабов от столь многих сложностей? Это предположение не такое фантастическое, каким кажется на первый взгляд: мальтийский диалект арабского пользуется латиницей уже несколько веков. Развитие и распространение ИТ будут настойчиво подталкивать в эту сторону и остальных арабов.

