
Всем привет! Я создал инструмент для разработки AIDD и назвал его Spawn. Это Python-утилита, которая помогает когерентно использовать несколько AIDD-методологий в одном репозитории — без ручной синхронизации правил, скилов и MCP-конфигов между ними.
Далее — краткое введение, затем я расскажу, как работает Spawn, как им пользоваться с клиентской точки зрения, как разрабатывать расширения, и приведу несколько примеров.
Кому может быть интересно
Руководители команд разработки — для разработки командных правил и процессов, касающихся разработки с помощью ИИ и не только.
Индивидуальные разработчики — использовать готовый SDD фреймворк или создать свой чисто «под себя».
Потенциально — разработчики софта для AIDD-разработки полного цикла.
DevOps-инженеры, инфраструктурщики и технические писатели — при условии, что скрипты, конфигурации или документы хранятся в репозиториях.
Ключевые идеи
Spawn позволяет использовать несколько AIDD (или наборов правил) когерентно, он автоматически пробрасывает глобальные обязательные правила или описания процессов между артефактами установленных расширений в рамках одного репозитория — у агента всегда есть перекрестные инструкции.
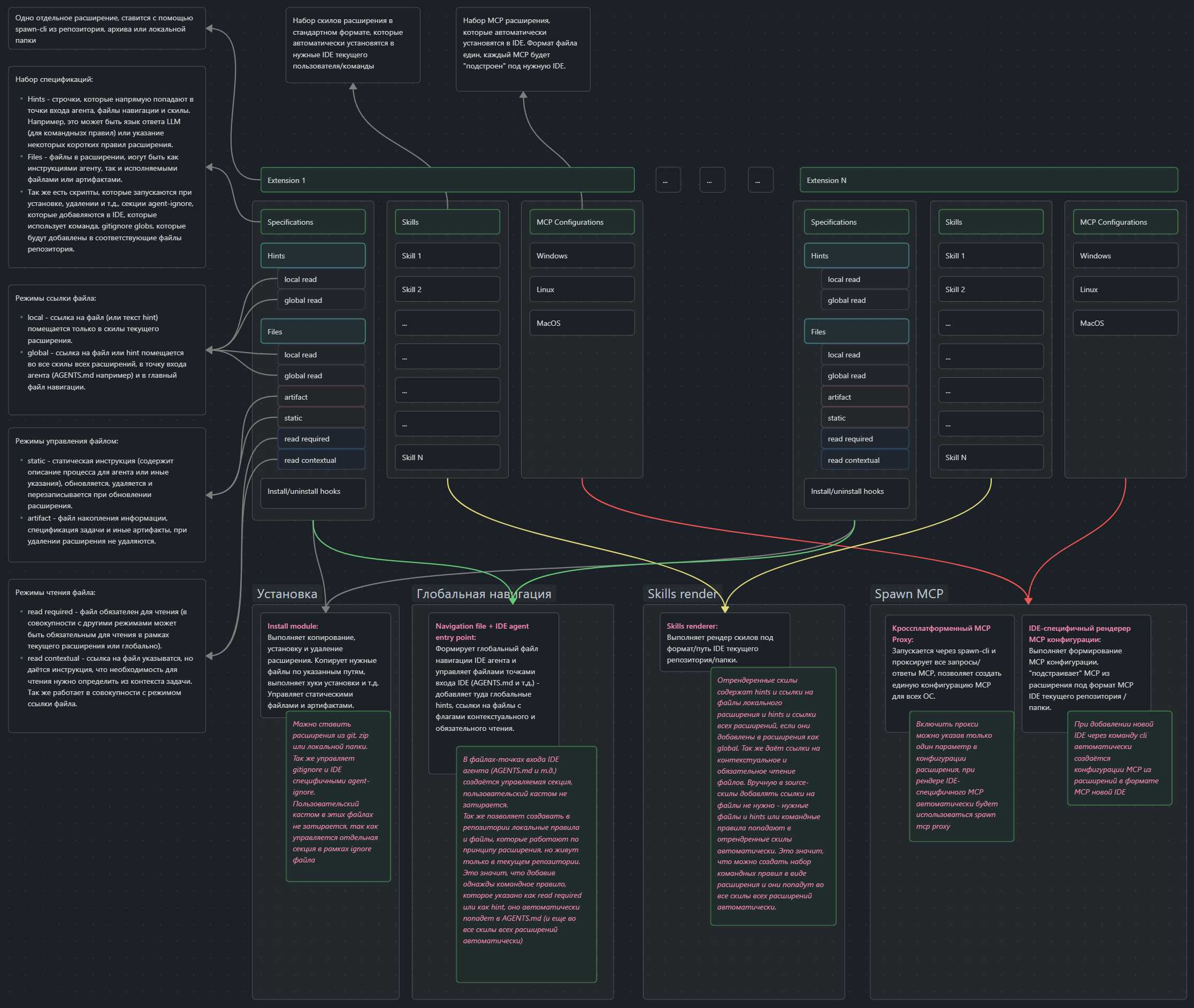
Расширение в терминах Spawn — это и есть AIDD-методология, которую можно установить в репозиторий. Для утилиты это набор документов, инструкций, скриптов, скилов и конфигураций MCP.
Расширением также может быть набор командных правил, scaffold-файлы проекта или набор автоматизаций — то, что ещё нельзя назвать методологией, но уже хочется переиспользовать.
Spawn позволяет устанавливать IDE-специфичные артефакты (MCP, скилы, agent-ignore и git-ignore списки) под выбранные поддерживаемые IDE, в то же время разработчик расширения не должен «подстраивать» каждый такой артефакт под конкретную IDE — Spawn сделает это самостоятельно. Утилита работает с универсальными, IDE-независимыми конфигурациями, которые потом «рендерятся» под IDE, которые использует команда.
Есть возможность создавать кроссплатформенные MCP, Spawn самостоятельно запустит нужный на текущей ОС через MCP-прокси — это важно для команд, члены которых работают на разных ОС.
После
spawn initв репозитории появляется директория./spawn— она хранит метаданные установленных расширений, локальные конфигурации и навигацию. Эту папку нужно коммитить в репозиторий, не добавляйте её в.gitignore.
Установка и быстрый старт
Установка Spawn CLI
Требуется Python 3.10+. Рекомендуемый способ — через uv:
uv tool install spawn-cli && spawn --help
Инициализация репозитория
spawn init
Подключение IDE
spawn ide add cursor # можно добавить несколько сразу: spawn ide add cursor codex
Чтобы посмотреть все поддерживаемые IDE и что каждая из них умеет рендерить:
spawn ide list-supported-ides
На момент публикации поддерживаются: cursor, codex, claude-code, windsurf, github-copilot, gemini-cli. Актуальный список всегда возвращает сама команда.
Установка первого расширения
spawn extension add https://github.com/noant/spawn-ext-spectask.git
Терминология
Расширение — контент конкретной AIDD методологии, содержащий файл конфигурации расширения, набор IDE-независимых файлов скилов и MCP, файлы-инструкции, скрипты и т.д. Расширение может быть установлено из GIT репозитория, zip-архива или локальной папки.
Точка входа IDE агента — файл, который читает IDE перед тем как выполнять любую команду. Например, в Cursor это AGENTS.md.
Hint — короткая строка-напоминание, которая вставляется напрямую в скилы и точку входа агента. Агент видит её сразу в контексте — без дополнительного чтения файла. Например: язык ответов (RU/EN), тон, специфика проекта. Hint может быть глобальным (попадает во все скилы всех расширений и в управляемый блок точки входа агента — например AGENTS.md) или локальным (только в скилы текущего расширения).
Файл инструкций — AI-читаемый файл, описывающий процесс, правило или соглашение. В отличие от hint’а, агент читает его целенаправленно — увидев ссылку в навигации или скиле. Бывает двух режимов чтения: required-read — ссылка всегда присутствует в скилах и точке входа агента, агент обязан прочитать его при каждом обращении; contextual-read — ссылка присутствует в навигации, но агент читает его по ситуации, только когда задача релевантна содержимому. Область действия задаётся через globalRead/localRead: глобальный файл попадает во все скилы всех расширений, локальный — только в скилы своего расширения.
Глобальный файл навигации — файл, содержащий все ссылки на нужные файлы инструкций (не скилы) с коротким описанием, областью применения, указанием обязательности чтения или контекстуальным (ситуативным) чтением. Также глобальный файл навигации содержит hints и ссылки на локальные файлы правил.
Локальные правила — файлы инструкций и hint’ы, которые можно добавить в репозиторий, не устанавливая расширение. Может быть полезно, если есть понимание, что правила не станут универсальными. При необходимости такие правила всегда можно упаковать в расширение и переиспользовать в других проектах.
Режим файла расширения — определяет поведение файла при обновлении расширения. Static — файл перезаписывается из исходника при каждом обновлении; используется для инструкций, которые должны всегда соответствовать последней версии расширения. Artifact — файл создаётся один раз при установке и после этого принадлежит проекту; при обновлении не перезаписывается; используется для конфигураций и данных, которые проект адаптирует под себя.
Работа с расширениями
Управление установленными расширениями
# в примерах ниже spectask — имя установленного расширения spawn extension list # список установленных расширений spawn extension update spectask # обновить расширение из исходного источника spawn extension reinstall spectask # полная переустановка (при повреждении) spawn extension remove spectask # удалить расширение spawn extension healthcheck spectask # проверить состояние расширения
Сборки расширений
Установка нескольких расширений (так называемые «сборки расширений»):
spawn build install https://github.com/org/team-methodology.git --branch main # или из локальной директории, в корне которой лежит extensions.yaml: spawn build install .
Локальные правила и refresh
Добавление правил без установки расширений:
# создать файл правил в spawn/rules/ и запустить refresh: spawn refresh
После редактирования файлов в spawn/rules/ или hint’ов в spawn/navigation.yaml нужно запустить refresh, чтобы скилы и точки входа IDE актуализировались. Есть два варианта:
spawn refresh— полный пересчёт: обновляетnavigation.yaml, перегенерирует скилы и точки входа агента. Использовать после любых изменений. Автоматически выполняется при установке расширения или добавлении IDE.spawn rules refresh— только синкает файлы изspawn/rules/вnavigation.yaml, без перегенерации скилов и точек входа. Подходит, если нужно быстро обновить навигацию, не затрагивая IDE-артефакты.
Важно: Spawn редактирует только те файлы, которые он установил сам. Сторонние скилы и правила вне этих путей он не трогает при
refreshили обновлении расширений.
Что происходит при spawn extension add
При выполнении spawn extension add <url> Spawn:
Клонирует исходный репозиторий расширения (или распаковывает ZIP / копирует из локальной папки) во временную директорию.
Читает
extsrc/config.yamlрасширения — идентифицирует стабильноеname, версию, список файлов, скилов, MCP-серверов и правил игнора.Копирует файлы из
extsrc/files/в целевой репозиторий согласно объявленным путям. Файлы с режимомstaticбудут перезаписываться при обновлениях; файлы с режимомartifactсоздаются один раз и дальше принадлежат проекту.Регистрирует скилы: исходники из
extsrc/skills/рендерятся с учётом активных IDE — в каждый скил встраиваются ссылки на обязательные файлы инструкций, hints и глобальная навигация.Подключает MCP-серверы из
extsrc/mcp/{windows,linux,macos}.json: для каждой зарегистрированной IDE генерируется IDE-специфичный конфиг, при этом кроссплатформенные серверы автоматически оборачиваются в MCP-прокси.Выполняет lifecycle-скрипты из
setup/(напримерafter-install) — установка зависимостей, инициализация артефактов и т.д.Обновляет
spawn/navigation.yaml: добавляет блокext:расширения с его обязательными и контекстуальными reads, глобальными hints и ссылками на файлы инструкций.Генерирует точки входа IDE агента (например
AGENTS.mdдля Cursor): объединяет навигацию всех установленных расширений и локальных правил в единый согласованный файл.Обновляет
.gitignoreи agent-ignore согласно паттернам, объявленным вconfig.yamlрасширения.
Метаданные об установленном расширении сохраняются в spawn/.extend/<name>/ — это позволяет spawn extension update / reinstall / remove работать корректно, а spawn extension healthcheck — диагностировать расхождения между тем, что объявлено в config.yaml, и тем, что реально лежит в репозитории.
Примеры готовых расширений
Ниже — два расширения, которыми я пользуюсь сам: SDD-методология Spectask и интеграция с локальной семантической памятью MemPalace.
Spectask — SDD-расширение
Это расширение позволяет:
Вести в репозитории спецификации задач
Декомпозировать задачи
Самостоятельно создавать схему параллельности выполнения подзадач
Выполнять подзадачи разными субагентами
Создавать задачи из Jira тикетов
Поддерживать файлы архитектуры в актуальном состоянии.
Установка расширения:
spawn extension add https://github.com/noant/spawn-ext-spectask.git
Как создать задачу из Jira тикета (вызов скила, пример для Cursor):
/spectask-from-jira import PROJ-123
Как создать задачу без Jira тикета (вызов скила, пример для Cursor):
/spectask-create добавить авторизацию через OAuth
Задача идет по флоу процесса, со следующими шагами:
[1] spec created → [2] self spec review → [3] spec review (user) → [4] code implemented → [5] self code review → [6] code review (user) → [7] design documents updated
Шаги 1, 2, 4, 5, 7 выполняет агент; шаги 3 и 6 — пользователь (подтверждение). Шаг 4 запускает отдельный субагент на каждую подзадачу.
Все скилы с описанием:
Скил | Назначение |
|---|---|
| Создать спецификацию задачи — Шаги 1–2 (без реализации) |
| Шаг 3: подтвердить спецификацию и перейти к реализации |
| Шаги 4–5: реализовать задачу и провести self-ревью кода |
| Шаг 6: подтвердить код, запустить обновление архитектурных документов (Шаг 7) |
| Зарегистрировать архитектурные файлы в |
| Зафиксировать черновую идею как |
| Импортировать Jira тикет в папку задачи через MCP или CLI |
Seeds
Перед созданием полноценной задачи можно быстро зафиксировать идею как seed-файл в spec/seeds/. Это неформальная заметка без полного флоу — полезно, когда идея есть, но до реализации ещё далеко. При готовности seed легко продвигается в полноценную задачу через spectask-create, а после закрытия задачи seed переименовывается с префиксом _DONE_.
Jira интеграция
Расширение поставляется с MCP-сервером spectask-mcp, который устанавливается автоматически при установке расширения. Он позволяет скилу spectask-from-jira напрямую получать данные из Jira по ключу тикета.
Настройка выполняется через интерактивный сетап во время установки расширения (запускается автоматически, если stdin — TTY). При необходимости его можно вызвать повторно руками:
spectask-mcp interactive --setup
Конфигурация (URL, токен, опциональный SOCKS5 прокси) сохраняется в spec/.config/config.yaml — этот файл автоматически добавляется в .gitignore и agent-ignore, чтобы секреты не попали в репозиторий.
Методология описана в главном файле main.md репозитория расширения — там же лежит полный процесс и правила. Spawn CLI разработан с использованием этой методологии.
Репозиторий расширения: github.com/noant/spawn-ext-spectask.
MemPalace
Это расширение позволяет установить MemPalace (локальная семантическая память — «дворец памяти») из оригинального пакета в текущий репозиторий, а также предоставляет поверх этого кроссплатформенный MCP (необходимый для функционирования MemPalace), набор скилов и скриптов для настройки mempalace. Подробнее о самом MemPalace — на официальном сайте проекта.
Установка расширения:
spawn extension add https://github.com/noant/spawn-ext-mempalace.git
Настройка дворца памяти (вызов скила):
/mempalace-configure-palace
(пример для Cursor)
После установки расширение автоматически:
устанавливает пакет
mempalaceчерезpip(а при его отсутствии — черезuv pip), если не заданMEMPALACE_EXTENSION_SKIP_PIPинициализирует palace в
<repo>/.mempalace/palace(черезmempalace init .); переопределяется флагомMEMPALACE_EXTENSION_GLOBAL_PALACEили переменнойMEMPALACE_PALACE_PATHподключает два MCP-сервера:
mempalace-mcp(официальные инструменты MemPalace) иmempalace-mine-mcp(бридж для индексации и обновления wake-up контекста)
Как это работает
Семантическая память хранится в .mempalace/palace (по умолчанию ChromaDB; бекенд pluggable). После существенных правок в репозитории агент вызывает mempalace_mine — это переиндексирует файлы и обновляет .mempalace/wakeup.md. Этот файл объявлен как обязательный для чтения в spawn/navigation.yaml, поэтому агент загружает актуальный контекст из palace в начале каждой сессии — без повторного объяснения структуры проекта.
Скилы:
Скил | Назначение |
|---|---|
| Настроить palace: глобальный конфиг, |
| Семантический поиск через MemPalace MCP или CLI с фолбеком на поиск по воркспейсу |
| Диагностика установки, выравнивания palace path, MCP и wake-up контекста |
После этого при любом существенном изменении проекта агент будет сам предлагать переиндексировать файлы в palace.
Репозиторий расширения: github.com/noant/spawn-ext-mempalace. Оригинальный репозиторий MemPalace: github.com/MemPalace/mempalace.
Как создать своё расширение
Два пути: CLI-скаффолд и spawn-ext-creator
Быстрый старт через CLI — создаёт минимальный скаффолд (extsrc/ с config.yaml, пустыми skills/, files/, setup/) без каких-либо дополнительных расширений:
spawn extension init --name my-extension
Полноценный скаффолд через spawn-ext-creator — расширение, которое добавляет скилы для агента: он сам проведёт через объявление config.yaml, скилов и MCP, через верификацию и прочие шаги. Подходит, когда расширение планируется нетривиальным.
Установка расширения spawn-ext-creator:
spawn extension add https://github.com/noant/spawn-ext-creator.git
Скилы spawn-ext-creator
Скил | Назначение |
|---|---|
| Спроектировать методологию: неймспейсы в |
| Старт с нуля: |
| Поддерживать |
| Объявить |
| Написать |
| Создать |
| Запустить |
| Поднять |
Рекомендуемый порядок при создании нового расширения: spawn-methodology-shape → spawn-ext-bootstrap → spawn-ext-config → spawn-ext-skill-sources → spawn-ext-mcp (опционально) → spawn-ext-verify. Перед каждым релизом: spawn-ext-increment-version → spawn-ext-verify.
Рекомендация: для расширений сложнее минимального используйте spawn-ext-creator — это быстрее и надёжнее, чем собирать структуру руками.
Структура extsrc/
Центральный файл расширения — config.yaml. Файловая структура расширения выглядит так:
my-extension/ └── extsrc/ ├── config.yaml # обязательно: схема, версия, имя, объявление файлов и скилов ├── files/ # файлы, которые будут скопированы в целевой репозиторий ├── skills/ # исходники скилов (IDE-независимые) ├── mcp/ # (опционально) объявление MCP-серверов: windows.json, linux.json, macos.json ├── agent-ignore # (опционально) паттерны для agent-ignore └── setup/ # (опционально) скрипты, выполняемые при установке/обновлении
Единственный обязательный файл — extsrc/config.yaml. Всё остальное опционально в зависимости от того, что делает расширение.
Справочник: пример config.yaml со всеми полями
Ниже — пример с описанием всех полей и того, как они работают после установки расширения в проект:
# Версия схемы конфига — всегда 1 schema: 1 # Стабильный идентификатор расширения (используется как имя папки spawn/.extend/<name>/) # Не менять после первой публикации name: my-extension # Версия расширения (semver) version: "1.0.0" # Папки, принадлежащие проекту (artifact — не перезаписываются при обновлении расширения) folders: my-extension/data: mode: artifact # Паттерны для agent-ignore (агент не будет читать эти файлы) agent-ignore: - my-extension/data/secrets/** # Паттерны для git-ignore git-ignore: - my-extension/data/secrets/** # Скрипты, выполняемые при установке/обновлении setup: # Путь от корня extsrc/ — здесь будет лежать extsrc/setup/install.py after-install: setup/install.py # Файлы расширения files: # Статический файл — перезаписывается при обновлении расширения my-extension/process.md: description: "Описание процесса разработки." mode: static # globalRead: required — ссылка попадёт во все скилы всех расширений # globalRead: auto — только если агент счёл файл релевантным глобально # globalRead: no — не попадает в глобальную навигацию globalRead: auto # localRead: required — всегда читается при использовании скилов этого расширения # localRead: auto — читается по ситуации localRead: required # Артефактный файл — создаётся при установке, потом принадлежит проекту my-extension/config.yaml: description: "Конфигурация расширения для текущего проекта." mode: artifact globalRead: no localRead: auto # Скилы расширения (исходники лежат в extsrc/skills/) skills: my-skill.md: name: my-skill description: "Описание скила — что делает агент при вызове." # Файлы, которые агент обязан прочитать перед выполнением скила required-read: - my-extension/process.md
Валидация и публикация
Валидация расширения перед публикацией:
spawn extension check ./my-extension spawn extension check ./my-extension --strict
Установка готового расширения в проект:
spawn extension add https://github.com/your-org/your-extension.git
Полное описание модели расширения (все поля config.yaml, статический vs артефактный контент, lifecycle-скрипты и т.д.) — в extension-author-guide в репозитории.
Упаковка локальных правил в расширение
Если у вас уже есть локальные правила в spawn/rules/ и вы хотите упаковать их в расширение (например, чтобы переиспользовать в других проектах):
spawn extension from-rules ./repo-with-spawn-rules --name my-ext --output ./out # или из удалённого репозитория: spawn extension from-rules https://github.com/org/my-repo.git --name my-ext --output ./out
Связь с автором
Исходный код Spawn CLI: github.com/noant/spawn-cli — issues приветствуются, обсудим.
Прямая связь: anton.novgorodcev@gmail.com
Всем спасибо!
P.S. ниже диаграмма, которая может помочь с пониманием того, как работает Spawn

Эта же статья, но на англоязычных ресурсах: dev.to medium.com


{kind=link}