Часть 1
Часть 3
В части 1 мы создали (немного бесполезное) mochiweb приложение, которое отправяет клиентам сообщение каждые 10 секунд. Мы настроили ядро Linux, и создали инструмент, чтобы установить много соединений для проверки использования памяти. Мы выяснили, что требуется приблизительно 45 Кб для каждого подключения.
В части 2 мы превратим наше приложение во что-то полезное, и уменьшим потребление памяти:
• Реализация маршрутизатора сообщения с login/logout/send API;
• Обновление mochiweb приложения для работы с маршрутизатором;
• Установка распределенной erlang системы, таким образом, мы можем запустить маршрутизатор на различных узлах;
• Создание инструмента тестирования маршрутизатора большим количеством сообщений;
• График использование памяти в течении 24 часов, оптимизация mochiweb приложение для экономии памяти.
Это означает, что мы разделим логику доставки сообщений и mochiweb приложение. В тандеме с утилитой floodtest из части 1 мы можем протестировать работу приложения в условиях, близких к промышленным.
Реализация маршрутизатора сообщения
API маршрутизатора содержит только 3 функции:
• login(Id, Pid) регистрирует процесс для получения сообщений;
• logout(Pid) прекращает получение сообщений;
• send(Id, Msg) посылает сообщений клиенту.
Отметьте, что для одного процесса возможно войти в систему с различными Id.
Этот модуль маршрутизатора в качестве примера использует 2 ets таблицы, чтобы хранить двунаправленные карты между Pids и Ids. (pid2id и id2pid в записи #state):
Давайте предполагать, что пользователь представлен целочисленным Id, основанным на URL, которым он соеденен с mochiweb, и использует этот идентификатор, чтобы зарегистрироваться в маршрутизаторе сообщений. Вместо того, чтобы блокироваться каждые 10 секунд, mochiweb блокируется при получении сообщений от маршрутизатора, и отправляет HTTP сообщение клиенту для каждого запроса, который маршрутизатор отправляет ему:
• Клиент соединяется с mochiweb через http://localhost:8000/test/123;
• приложение Mochiweb регистрирует Pid для этого подключения с идентификатором ‘123’ в маршрутизаторе сообщений;
• Если Вы отправляете сообщение маршрутизатору на адрес ‘123’, оно будет передано к корректному процессу mochiweb, и появится в браузере для этого пользователя.
Вот обновленная версия mochiconntest_web.erl:
Теперь давайте приведем все в порядок – мы будем использовать 2 оболочки erlang, одну для mochiweb и одну для маршрутизатора. Измените start-dev.sh, используемый, чтобы запустить mochiweb, и добавте следующие дополнительные параметры к erl:
• -sname n1, чтобы назвать erlang узел ‘n1’
• +K true, чтобы включить kernel-poll.
• +P 134217727 — максимальное количество процессов, которые Вы можете породить, 32768. Мы нуждаемся в одном процессе для каждого подключения, но я не знаю сколько понадобится конкретно. 134 217 727 — максимальное значение согласно “man erl”.
Теперь выполните make && ./start-dev.sh, и Вы должны видеть приветствие: (n1@localhost) 1> – Ваше mochiweb приложение теперь работает, и у erlang узла есть имя.
Теперь запустите другую оболочку erlang:
В настоящий момент те два узла erlang не знают друг о друге, исправим это:
Теперь скомпилируйте и запустите маршрутизатор:
Теперь для интереса, откройте http://localhost:8000/test/123 в Вашем браузере (или используйте lynx --source "http://localhost:8000/test/123" из консоли). Проверьте оболочку, в которой Вы запустили маршрутизатор, Вы должны видеть, что в систему вошел один пользователь.
Вы можете теперь отправить сообщения маршрутизатору и наблюдать, как они появляются в Вашем браузере. Пока что используйте только строки, потому что мы используем ~s параметр для вывода, и атом приведет к ошибке:
Проверьте свой браузер, Вы получили сообщение :)
Имеет смысл выполнять маршрутизатор и mochiweb на различных машинах. Допустим, у Вас есть несколько запасных машин для тестирования, Вы должны запустить оболочки erlang как распределенные узлы, то есть использовать -name n1@host1.example.com вместо -sname n1 (и то же самое для n2). Удостоверьтесь, что они могут видеть друг друга с помощью net_adm:ping (...) как в примере выше.
Замечу, что на строке 16 в router.erl, имя процесса маршрутизатора ('router') зарегистрировано глобально, именно поэтому мы используем следующий макрос, чтобы идентифицировать местоположение маршрутизатор в вызовах gen_server, даже в распределенной системе:
Глобальный реестр имен для процессов в распределенной системе — только одна из многих вещей, которые Вы получаете бесплатно с Erlang.
В реальной среде мы могли бы увидеть паттерн вроде «long-tail» с некоторыми очень активными пользователями и многими пассивными пользователями. Однако для этого теста мы будем посылать без разбора случайным пользователям поддельные сообщения.
Этот код отправит Num сообщений случайным идентификаторам пользователей между 1 и Max каждые Interval мс.
Вы можете увидеть это в действии, если Вы запустите маршрутизатор и mochiweb приложение, зайдете по адресу http://localhost:8000/test/3 и запустите:
Будет отправлено 20 сообщений случайным Идентификаторам между 1 и 5, каждые 10 мс по одному сообщению. Возможно, Вам повезет и Вы получите несколько сообщений.
Мы можем даже выполнить несколько из них параллельно, чтобы смоделировать многократные источники для сообщений. Вот пример работы 10 процессов, каждый отправляет 20 сообщений идентификаторам 1-5 с задержкой 100 мс между каждым сообщением:
У нас есть все части для теста более широкого масштаба; клиенты соединяются с нашим mochiweb приложением, которое регистрирует их в маршрутизаторе сообщения. Мы можем генерировать большой объем поддельных сообщений, чтобы отправлять в маршрутизатор, который отправит их любым зарегистрированным клиентам. Давайте проверим 10 000 параллельных соединеный снова из Части 1, но на сей раз мы оставим все клиенты подключенными, в то время как мы прогоняем множество сообщений через систему.
Допустим, Вы следовали инструкциям в части 1, чтобы настроить Ваше ядро и т.д. У Вас уже есть работающие mochiweb приложение и маршрутизатор, так что давайте пустим больше трафика на них.
Без подключенных клиентов mochiweb использует приблизительно 40 МБ памяти:
Я придумал эту отвратительную комманду, чтобы выводить время, текущее использование памяти mochiweb приложения, и число установленных соединений каждые 60 секунд:
Если кто-либо знает лучший способ графически изобразить использования памяти для единственного процесса, в течение долгого времени, пожалуйста, оставьте комментарий.
Теперь запустите floodtest из Части 1 в новой оболочке erl:
Проверим использование памяти:
Достигнуто 10 000 параллельных соединений (плюс один, который я открыл в firefox), и потребление памяти mochiweb составляет приблизительно 90 МБ (90964 Кб).
Теперь отправим несколько сообщений:
100 процессов отправляет миллион сообщений по 10 сообщений в секунду к случайным Id от 1 до 10 000. Это означает, что маршрутизатор обрабатывает 1000 сообщений в секунду, и в среднем каждый из наших 10 k клиентов получит одно сообщение каждые 10 секунд.
Проверьте вывод floodtest, и Вы увидите, что клиенты получают http сообщения (помните, что это {NumConnected, NumClosed, NumChunksRecvd}):
Миллион сообщений по 10 в секунду для каждого процесса займет 27 часов на работу. Ниже использование памяти в первые 10 минут:
Вы можете видеть, что размер уже вырос с 40 МБ до 90 МБ, когда все 10 k клиентов были соединены, и до 125 МБ после некоторого времени работы.
Стоит указать, что floodtest почти не использует CPU, msggen использует 2% CPU, а маршрутизатор и mochiweb меньше чем 1 %.
Приложение работало в течение 24 часов при мониторинге использования памяти процесса mochiweb. 10 000 соединенных клиентов, 1000 сообщений в секунду отправляемых случайным клиентам.
Следующая уловка использовалась, чтобы заставить gnuplot нарисовать график:
Этот график показывает, что использование памяти (с 10 k активных соединений и 1000 msg/sec) выравнивается в пределах 250 МБ за 24-часовой период. Два нижних экстремума появились из-за того, что я для интереса выполнил:
Это вынуждает все процессы собрать «мусор», и освободить приблизительно 100 МБ памяти. Сейчас мы исследуем способы сохранить память, не обращаясь к ручному принуждению сборки «мусора».
Заметьте, mochiweb приложение только отправляет сообщения и затем сразу забывает их, использование памяти не должно увеличиваться с числом отправленных сообщений.
Я — новичок когда дело доходит до управления памятью Erlang, но я собираюсь предположить, что, если я могу вынудить его собирать «мусор» чаще, оно позволит нам перенаправлять большую часть той памяти, и в конечном счете позволять нам обслужить больше пользователей с незаполненной системной памятью.
Исследование документации дало некоторый результат:
erlang:system_flag(fullsweep_after, Number)
Интригующе, но это применимо только к новым процессам и влияет на все процессы в VM, не только наши процессы mochiweb.
Далее:
erlang:system_flag(min_heap_size, MinHeapSize)
Могло бы быть полезным, но я вполне уверен, наши процессы mochiweb нуждаются в большей «куче» чем значение по умолчанию так или иначе. Я бы хотел избежать необходимости изменения исходных кодов mochiweb.
Рядом я заметил:
erlang:hibernate(Module, Function, Args)
Звучит разумным – давайте попытаемся переходить в спящий режим после каждого сообщения и посмотрим, что будет.
Отредактируйте mochiconntest_web.erl и измените следующее:
• Измените последнюю строку feed(Response, Id, N) функции, чтобы она переходила в спящий режим вместо того, чтобы вызвать себя;
• Вызывайте hibernate() сразу отправки сообщения в маршрутизатор, вместо того, чтобы блокироваться на receive;
• Не забудьте экспортировать feed/3.
Обновленный mochiconntest_web.erl со спящим режимом между сообщениями:
Я сделал эти изменения, пересобрал mochiweb, затем сделал заново тот же самый тест.
Использование hibernate(), означает, что память mochiweb приложения выравнивается в 78 МБ с 10 k соединений, намного лучше чем 450 МБ, которые мы видели в части 1. Не было никакого существенного увеличения использования CPU.
Мы создали Comet-приложение для Mochiweb, которое позволяет нам передавать произвольные сообщения пользователям, идентифицированным целочисленным ID. После перегона 1000 сообщений в секунду в течение 24 часов, с 10 000 соединенных пользователей, мы наблюдали использование 80 МБ памяти, или 8 Кб на каждого пользователя. Мы даже сделали симпатичные графики.
Это – действительно прогресс.
В части 3 я увеличу число пользователей до 1 миллиона. Я буду проводить тесты на мультипроцессорной машине с достаточным количеством памяти. Я также покажу некоторые дополнительные приемы и настройку, чтобы смоделировать 1 миллион соединений.
Приложение разовьется в своего рода «pub-sub» систему, где подписки связаны с Id пользователей и сохранены приложением. Мы будем использовать типичный набор данных социальной сети: друзей. Это позволит пользователю входить в систему с их идентификатором пользователя и автоматически получать любое событие, сгенерированное одним из их друзей.
Часть 3
В части 1 мы создали (немного бесполезное) mochiweb приложение, которое отправяет клиентам сообщение каждые 10 секунд. Мы настроили ядро Linux, и создали инструмент, чтобы установить много соединений для проверки использования памяти. Мы выяснили, что требуется приблизительно 45 Кб для каждого подключения.
В части 2 мы превратим наше приложение во что-то полезное, и уменьшим потребление памяти:
• Реализация маршрутизатора сообщения с login/logout/send API;
• Обновление mochiweb приложения для работы с маршрутизатором;
• Установка распределенной erlang системы, таким образом, мы можем запустить маршрутизатор на различных узлах;
• Создание инструмента тестирования маршрутизатора большим количеством сообщений;
• График использование памяти в течении 24 часов, оптимизация mochiweb приложение для экономии памяти.
Это означает, что мы разделим логику доставки сообщений и mochiweb приложение. В тандеме с утилитой floodtest из части 1 мы можем протестировать работу приложения в условиях, близких к промышленным.
Реализация маршрутизатора сообщения
API маршрутизатора содержит только 3 функции:
• login(Id, Pid) регистрирует процесс для получения сообщений;
• logout(Pid) прекращает получение сообщений;
• send(Id, Msg) посылает сообщений клиенту.
Отметьте, что для одного процесса возможно войти в систему с различными Id.
Этот модуль маршрутизатора в качестве примера использует 2 ets таблицы, чтобы хранить двунаправленные карты между Pids и Ids. (pid2id и id2pid в записи #state):
-module(router). -behaviour(gen_server). -export([start_link/0]). -export([init/1, handle_call/3, handle_cast/2, handle_info/2, terminate/2, code_change/3]). -export([send/2, login/2, logout/1]). -define(SERVER, global:whereis_name(?MODULE)). % will hold bidirectional mapping between id <–> pid -record(state, {pid2id, id2pid}). start_link() -> gen_server:start_link({global, ?MODULE}, ?MODULE, [], []). % sends Msg to anyone logged in as Id send(Id, Msg) -> gen_server:call(?SERVER, {send, Id, Msg}). login(Id, Pid) when is_pid(Pid) -> gen_server:call(?SERVER, {login, Id, Pid}). logout(Pid) when is_pid(Pid) -> gen_server:call(?SERVER, {logout, Pid}). init([]) -> % set this so we can catch death of logged in pids: process_flag(trap_exit, true), % use ets for routing tables {ok, #state{ pid2id = ets:new(?MODULE, [bag]), id2pid = ets:new(?MODULE, [bag]) } }. handle_call({login, Id, Pid}, _From, State) when is_pid(Pid) -> ets:insert(State#state.pid2id, {Pid, Id}), ets:insert(State#state.id2pid, {Id, Pid}), link(Pid), % tell us if they exit, so we can log them out io:format("~w logged in as ~w\n",[Pid, Id]), {reply, ok, State}; handle_call({logout, Pid}, _From, State) when is_pid(Pid) -> unlink(Pid), PidRows = ets:lookup(State#state.pid2id, Pid), case PidRows of [] -> ok; _ -> IdRows = [ {I,P} || {P,I} <- PidRows ], % invert tuples % delete all pid->id entries ets:delete(State#state.pid2id, Pid), % and all id->pid [ ets:delete_object(State#state.id2pid, Obj) || Obj <- IdRows ] end, io:format("pid ~w logged out\n",[Pid]), {reply, ok, State}; handle_call({send, Id, Msg}, _From, State) -> % get pids who are logged in as this Id Pids = [ P || { _Id, P } <- ets:lookup(State#state.id2pid, Id) ], % send Msg to them all M = {router_msg, Msg}, [ Pid ! M || Pid <- Pids ], {reply, ok, State}. % handle death and cleanup of logged in processes handle_info(Info, State) -> case Info of {‘EXIT’, Pid, _Why} -> % force logout: handle_call({logout, Pid}, blah, State); Wtf -> io:format("Caught unhandled message: ~w\n", [Wtf]) end, {noreply, State}. handle_cast(_Msg, State) -> {noreply, State}. terminate(_Reason, _State) -> ok. code_change(_OldVsn, State, _Extra) -> {ok, State}.
Обновление mochiweb приложения
Давайте предполагать, что пользователь представлен целочисленным Id, основанным на URL, которым он соеденен с mochiweb, и использует этот идентификатор, чтобы зарегистрироваться в маршрутизаторе сообщений. Вместо того, чтобы блокироваться каждые 10 секунд, mochiweb блокируется при получении сообщений от маршрутизатора, и отправляет HTTP сообщение клиенту для каждого запроса, который маршрутизатор отправляет ему:
• Клиент соединяется с mochiweb через http://localhost:8000/test/123;
• приложение Mochiweb регистрирует Pid для этого подключения с идентификатором ‘123’ в маршрутизаторе сообщений;
• Если Вы отправляете сообщение маршрутизатору на адрес ‘123’, оно будет передано к корректному процессу mochiweb, и появится в браузере для этого пользователя.
Вот обновленная версия mochiconntest_web.erl:
-module(mochiconntest_web). -export([start/1, stop/0, loop/2]). %% External API start(Options) -> {DocRoot, Options1} = get_option(docroot, Options), Loop = fun (Req) -> ?MODULE:loop(Req, DocRoot) end, % we’ll set our maximum to 1 million connections. (default: 2048) mochiweb_http:start([{max, 1000000}, {name, ?MODULE}, {loop, Loop} | Options1]). stop() -> mochiweb_http:stop(?MODULE). loop(Req, DocRoot) -> "/" ++ Path = Req:get(path), case Req:get(method) of Method when Method =:= ‘GET’; Method =:= ‘HEAD’ -> case Path of "test/" ++ Id -> Response = Req:ok({"text/html; charset=utf-8", [{"Server","Mochiweb-Test"}], chunked}), % login using an integer rather than a string {IdInt, _} = string:to_integer(Id), router:login(IdInt, self()), feed(Response, IdInt, 1); _ -> Req:not_found() end; ‘POST’ -> case Path of _ -> Req:not_found() end; _ -> Req:respond({501, [], []}) end. feed(Response, Id, N) -> receive {router_msg, Msg} -> Html = io_lib:format("Recvd msg #~w: ‘~s’", [N, Msg]), Response:write_chunk(Html) end, feed(Response, Id, N+1). %% Internal API get_option(Option, Options) -> {proplists:get_value(Option, Options), proplists:delete(Option, Options)}.
Оно работает!
Теперь давайте приведем все в порядок – мы будем использовать 2 оболочки erlang, одну для mochiweb и одну для маршрутизатора. Измените start-dev.sh, используемый, чтобы запустить mochiweb, и добавте следующие дополнительные параметры к erl:
• -sname n1, чтобы назвать erlang узел ‘n1’
• +K true, чтобы включить kernel-poll.
• +P 134217727 — максимальное количество процессов, которые Вы можете породить, 32768. Мы нуждаемся в одном процессе для каждого подключения, но я не знаю сколько понадобится конкретно. 134 217 727 — максимальное значение согласно “man erl”.
Теперь выполните make && ./start-dev.sh, и Вы должны видеть приветствие: (n1@localhost) 1> – Ваше mochiweb приложение теперь работает, и у erlang узла есть имя.
Теперь запустите другую оболочку erlang:
erl -sname n2
В настоящий момент те два узла erlang не знают друг о друге, исправим это:
(n2@localhost)1> nodes(). [] (n2@localhost)2> net_adm:ping(n1@localhost). pong (n2@localhost)3> nodes(). [n1@localhost]
Теперь скомпилируйте и запустите маршрутизатор:
(n2@localhost)4> c(router). {ok,router} (n2@localhost)5> router:start_link(). {ok,<0.38.0>}
Теперь для интереса, откройте http://localhost:8000/test/123 в Вашем браузере (или используйте lynx --source "http://localhost:8000/test/123" из консоли). Проверьте оболочку, в которой Вы запустили маршрутизатор, Вы должны видеть, что в систему вошел один пользователь.
Вы можете теперь отправить сообщения маршрутизатору и наблюдать, как они появляются в Вашем браузере. Пока что используйте только строки, потому что мы используем ~s параметр для вывода, и атом приведет к ошибке:
(n2@localhost)6> router:send(123, "Hello World"). (n2@localhost)7> router:send(123, "Why not open another browser window too?"). (n2@localhost)8> router:send(456, "This message will go into the void unless you are connected as /test/456 too").
Проверьте свой браузер, Вы получили сообщение :)
Запуск распределенной erlang системы
Имеет смысл выполнять маршрутизатор и mochiweb на различных машинах. Допустим, у Вас есть несколько запасных машин для тестирования, Вы должны запустить оболочки erlang как распределенные узлы, то есть использовать -name n1@host1.example.com вместо -sname n1 (и то же самое для n2). Удостоверьтесь, что они могут видеть друг друга с помощью net_adm:ping (...) как в примере выше.
Замечу, что на строке 16 в router.erl, имя процесса маршрутизатора ('router') зарегистрировано глобально, именно поэтому мы используем следующий макрос, чтобы идентифицировать местоположение маршрутизатор в вызовах gen_server, даже в распределенной системе:
-define(SERVER, global:whereis_name(?MODULE)).
Глобальный реестр имен для процессов в распределенной системе — только одна из многих вещей, которые Вы получаете бесплатно с Erlang.
Генерирование большого количества сообщений
В реальной среде мы могли бы увидеть паттерн вроде «long-tail» с некоторыми очень активными пользователями и многими пассивными пользователями. Однако для этого теста мы будем посылать без разбора случайным пользователям поддельные сообщения.
-module(msggen). -export([start/3]). start(0, _, _) -> ok; start(Num, Interval, Max) -> Id = random:uniform(Max), router:send(Id, "Fake message Num = " ++ Num), receive after Interval -> start(Num -1, Interval, Max) end.
Этот код отправит Num сообщений случайным идентификаторам пользователей между 1 и Max каждые Interval мс.
Вы можете увидеть это в действии, если Вы запустите маршрутизатор и mochiweb приложение, зайдете по адресу http://localhost:8000/test/3 и запустите:
erl -sname test (test@localhost)1> net_adm:ping(n1@localhost). pong (test@localhost)2> c(msggen). {ok,msggen} (test@localhost)3> msggen:start(20, 10, 5). ok
Будет отправлено 20 сообщений случайным Идентификаторам между 1 и 5, каждые 10 мс по одному сообщению. Возможно, Вам повезет и Вы получите несколько сообщений.
Мы можем даже выполнить несколько из них параллельно, чтобы смоделировать многократные источники для сообщений. Вот пример работы 10 процессов, каждый отправляет 20 сообщений идентификаторам 1-5 с задержкой 100 мс между каждым сообщением:
[ spawn(fun() -> msggen:start(20, 100, 5), io:format("~w finished.\n", [self()]) end) || _ <- lists:seq(1,10) ]. [<0.97.0>,<0.98.0>,<0.99.0>,<0.100.0>,<0.101.0>,<0.102.0>, <0.103.0>,<0.104.0>,<0.105.0>,<0.106.0>] <0.101.0> finished. <0.105.0> finished. <0.106.0> finished. <0.104.0> finished. <0.102.0> finished. <0.98.0> finished. <0.99.0> finished. <0.100.0> finished. <0.103.0> finished. <0.97.0> finished.
C10K
У нас есть все части для теста более широкого масштаба; клиенты соединяются с нашим mochiweb приложением, которое регистрирует их в маршрутизаторе сообщения. Мы можем генерировать большой объем поддельных сообщений, чтобы отправлять в маршрутизатор, который отправит их любым зарегистрированным клиентам. Давайте проверим 10 000 параллельных соединеный снова из Части 1, но на сей раз мы оставим все клиенты подключенными, в то время как мы прогоняем множество сообщений через систему.
Допустим, Вы следовали инструкциям в части 1, чтобы настроить Ваше ядро и т.д. У Вас уже есть работающие mochiweb приложение и маршрутизатор, так что давайте пустим больше трафика на них.
Без подключенных клиентов mochiweb использует приблизительно 40 МБ памяти:
$ ps -o rss= -p `pgrep -f 'sname n1'` 40156
Я придумал эту отвратительную комманду, чтобы выводить время, текущее использование памяти mochiweb приложения, и число установленных соединений каждые 60 секунд:
$ MOCHIPID=`pgrep -f 'name n1'`; while [ 1 ] ; do NUMCON=`netstat -n | awk '/ESTABLISHED/ && $4=="127.0.0.1:8000"' | wc -l`; MEM=`ps -o rss= -p $MOCHIPID`; echo -e "`date`\t`date +%s`\t$MEM\t$NUMCON"; sleep 60; done | tee -a mochimem.log
Если кто-либо знает лучший способ графически изобразить использования памяти для единственного процесса, в течение долгого времени, пожалуйста, оставьте комментарий.
Теперь запустите floodtest из Части 1 в новой оболочке erl:
erl> floodtest:start("/tmp/mochi-urls.txt", 10). Это установит 100 новых соединений в секунду, пока все 10 000 клиентов не будут соединены. Stats: {825,0,0} Stats: {1629,0,0} Stats: {2397,0,0} Stats: {3218,0,0} Stats: {4057,0,0} Stats: {4837,0,0} Stats: {5565,0,0} Stats: {6295,0,0} Stats: {7022,0,0} Stats: {7727,0,0} Stats: {8415,0,0} Stats: {9116,0,0} Stats: {9792,0,0} Stats: {10000,0,0} ...
Проверим использование памяти:
Mon Oct 20 16:57:24 BST 2008 1224518244 40388 1 Mon Oct 20 16:58:25 BST 2008 1224518305 41120 263 Mon Oct 20 16:59:27 BST 2008 1224518367 65252 5267 Mon Oct 20 17:00:32 BST 2008 1224518432 89008 9836 Mon Oct 20 17:01:37 BST 2008 1224518497 90748 10001 Mon Oct 20 17:02:41 BST 2008 1224518561 90964 10001 Mon Oct 20 17:03:46 BST 2008 1224518626 90964 10001 Mon Oct 20 17:04:51 BST 2008 1224518691 90964 10001
Достигнуто 10 000 параллельных соединений (плюс один, который я открыл в firefox), и потребление памяти mochiweb составляет приблизительно 90 МБ (90964 Кб).
Теперь отправим несколько сообщений:
erl> [ spawn(fun() -> msggen:start(1000000, 100, 10000) end) || _ <- lists:seq(1,100) ]. [<0.65.0>,<0.66.0>,<0.67.0>,<0.68.0>,<0.69.0>,<0.70.0>, <0.71.0>,<0.72.0>,<0.73.0>,<0.74.0>,<0.75.0>,<0.76.0>, <0.77.0>,<0.78.0>,<0.79.0>,<0.80.0>,<0.81.0>,<0.82.0>, <0.83.0>,<0.84.0>,<0.85.0>,<0.86.0>,<0.87.0>,<0.88.0>, <0.89.0>,<0.90.0>,<0.91.0>,<0.92.0>,<0.93.0>|...]
100 процессов отправляет миллион сообщений по 10 сообщений в секунду к случайным Id от 1 до 10 000. Это означает, что маршрутизатор обрабатывает 1000 сообщений в секунду, и в среднем каждый из наших 10 k клиентов получит одно сообщение каждые 10 секунд.
Проверьте вывод floodtest, и Вы увидите, что клиенты получают http сообщения (помните, что это {NumConnected, NumClosed, NumChunksRecvd}):
... Stats: {10000,0,5912} Stats: {10000,0,15496} Stats: {10000,0,25145} Stats: {10000,0,34755} Stats: {10000,0,44342} ...
Миллион сообщений по 10 в секунду для каждого процесса займет 27 часов на работу. Ниже использование памяти в первые 10 минут:
Mon Oct 20 16:57:24 BST 2008 1224518244 40388 1 Mon Oct 20 16:58:25 BST 2008 1224518305 41120 263 Mon Oct 20 16:59:27 BST 2008 1224518367 65252 5267 Mon Oct 20 17:00:32 BST 2008 1224518432 89008 9836 Mon Oct 20 17:01:37 BST 2008 1224518497 90748 10001 Mon Oct 20 17:02:41 BST 2008 1224518561 90964 10001 Mon Oct 20 17:03:46 BST 2008 1224518626 90964 10001 Mon Oct 20 17:04:51 BST 2008 1224518691 90964 10001 Mon Oct 20 17:05:55 BST 2008 1224518755 90980 10001 Mon Oct 20 17:07:00 BST 2008 1224518820 91120 10001 Mon Oct 20 17:08:05 BST 2008 1224518885 98664 10001 Mon Oct 20 17:09:10 BST 2008 1224518950 106752 10001 Mon Oct 20 17:10:15 BST 2008 1224519015 114044 10001 Mon Oct 20 17:11:20 BST 2008 1224519080 119468 10001 Mon Oct 20 17:12:25 BST 2008 1224519145 125360 10001
Вы можете видеть, что размер уже вырос с 40 МБ до 90 МБ, когда все 10 k клиентов были соединены, и до 125 МБ после некоторого времени работы.
Стоит указать, что floodtest почти не использует CPU, msggen использует 2% CPU, а маршрутизатор и mochiweb меньше чем 1 %.
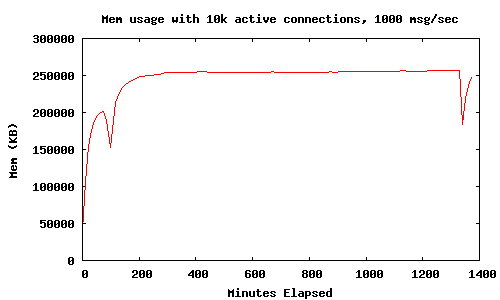
Результаты после выполнения в течение 24 часов
Приложение работало в течение 24 часов при мониторинге использования памяти процесса mochiweb. 10 000 соединенных клиентов, 1000 сообщений в секунду отправляемых случайным клиентам.
Следующая уловка использовалась, чтобы заставить gnuplot нарисовать график:
(echo -e "set terminal png size 500,300\nset xlabel \"Minutes Elapsed\"\nset ylabel \"Mem (KB)\"\nset title \"Mem usage with 10k active connections, 1000 msg/sec\"\nplot \"-\" using 1:2 with lines notitle" ; awk 'BEGIN{FS="\t";} NR%10==0 {if(!t){t=$2} mins=($2-t)/60; printf("%d %d\n",mins,$3)}' mochimem.log ; echo -e "end" ) | gnuplot > mochimem.png
Этот график показывает, что использование памяти (с 10 k активных соединений и 1000 msg/sec) выравнивается в пределах 250 МБ за 24-часовой период. Два нижних экстремума появились из-за того, что я для интереса выполнил:
erl> [erlang:garbage_collect(P) || P <- erlang:processes()].
Это вынуждает все процессы собрать «мусор», и освободить приблизительно 100 МБ памяти. Сейчас мы исследуем способы сохранить память, не обращаясь к ручному принуждению сборки «мусора».
Сокращение использования памяти в mochiweb
Заметьте, mochiweb приложение только отправляет сообщения и затем сразу забывает их, использование памяти не должно увеличиваться с числом отправленных сообщений.
Я — новичок когда дело доходит до управления памятью Erlang, но я собираюсь предположить, что, если я могу вынудить его собирать «мусор» чаще, оно позволит нам перенаправлять большую часть той памяти, и в конечном счете позволять нам обслужить больше пользователей с незаполненной системной памятью.
Исследование документации дало некоторый результат:
erlang:system_flag(fullsweep_after, Number)
Интригующе, но это применимо только к новым процессам и влияет на все процессы в VM, не только наши процессы mochiweb.
Далее:
erlang:system_flag(min_heap_size, MinHeapSize)
Могло бы быть полезным, но я вполне уверен, наши процессы mochiweb нуждаются в большей «куче» чем значение по умолчанию так или иначе. Я бы хотел избежать необходимости изменения исходных кодов mochiweb.
Рядом я заметил:
erlang:hibernate(Module, Function, Args)
Звучит разумным – давайте попытаемся переходить в спящий режим после каждого сообщения и посмотрим, что будет.
Отредактируйте mochiconntest_web.erl и измените следующее:
• Измените последнюю строку feed(Response, Id, N) функции, чтобы она переходила в спящий режим вместо того, чтобы вызвать себя;
• Вызывайте hibernate() сразу отправки сообщения в маршрутизатор, вместо того, чтобы блокироваться на receive;
• Не забудьте экспортировать feed/3.
Обновленный mochiconntest_web.erl со спящим режимом между сообщениями:
-module(mochiconntest_web). -export([start/1, stop/0, loop/2, feed/3]). %% External API start(Options) -> {DocRoot, Options1} = get_option(docroot, Options), Loop = fun (Req) -> ?MODULE:loop(Req, DocRoot) end, % we’ll set our maximum to 1 million connections. (default: 2048) mochiweb_http:start([{max, 1000000}, {name, ?MODULE}, {loop, Loop} | Options1]). stop() -> mochiweb_http:stop(?MODULE). loop(Req, DocRoot) -> "/" ++ Path = Req:get(path), case Req:get(method) of Method when Method =:= ‘GET’; Method =:= ‘HEAD’ -> case Path of "test/" ++ IdStr -> Response = Req:ok({"text/html; charset=utf-8", [{"Server","Mochiweb-Test"}], chunked}), {Id, _} = string:to_integer(IdStr), router:login(Id, self()), % Hibernate this process until it receives a message: proc_lib:hibernate(?MODULE, feed, [Response, Id, 1]); _ -> Req:not_found() end; ‘POST’ -> case Path of _ -> Req:not_found() end; _ -> Req:respond({501, [], []}) end. feed(Response, Id, N) -> receive {router_msg, Msg} -> Html = io_lib:format("Recvd msg #~w: ‘~w’ ", [N, Msg]), Response:write_chunk(Html) end, % Hibernate this process until it receives a message: proc_lib:hibernate(?MODULE, feed, [Response, Id, N+1]). %% Internal API get_option(Option, Options) -> {proplists:get_value(Option, Options), proplists:delete(Option, Options)}.
Я сделал эти изменения, пересобрал mochiweb, затем сделал заново тот же самый тест.
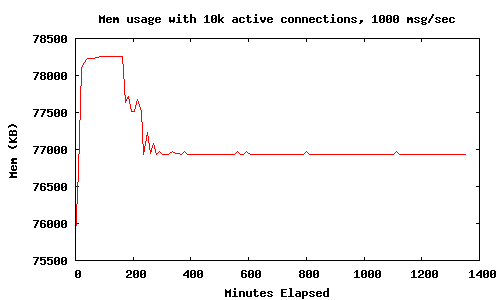
Результаты после выполнения в течение 24 часов с proc_lib:hibernate ()
Использование hibernate(), означает, что память mochiweb приложения выравнивается в 78 МБ с 10 k соединений, намного лучше чем 450 МБ, которые мы видели в части 1. Не было никакого существенного увеличения использования CPU.
Итак...
Мы создали Comet-приложение для Mochiweb, которое позволяет нам передавать произвольные сообщения пользователям, идентифицированным целочисленным ID. После перегона 1000 сообщений в секунду в течение 24 часов, с 10 000 соединенных пользователей, мы наблюдали использование 80 МБ памяти, или 8 Кб на каждого пользователя. Мы даже сделали симпатичные графики.
Это – действительно прогресс.
Следующие Шаги
В части 3 я увеличу число пользователей до 1 миллиона. Я буду проводить тесты на мультипроцессорной машине с достаточным количеством памяти. Я также покажу некоторые дополнительные приемы и настройку, чтобы смоделировать 1 миллион соединений.
Приложение разовьется в своего рода «pub-sub» систему, где подписки связаны с Id пользователей и сохранены приложением. Мы будем использовать типичный набор данных социальной сети: друзей. Это позволит пользователю входить в систему с их идентификатором пользователя и автоматически получать любое событие, сгенерированное одним из их друзей.

