Приветствую, Хабрахабр. Сегодня я хочу, в своём обычном стиле, устроить сообществу небольшой ликбез по структурам данных. Только на этот раз он будет гораздо более всеобъемлющ, а его применения и практичность — простираться далеко в самые разнообразные области программирования. Самые красивые применения, я, конечно же, покажу и опишу непосредственно в статье.
Нам понадобится капелька абстрактного мышления, знание какого-нибудь сбалансированного дерева поиска (например, описанного мною ранее декартова дерева), умение читать простой код на C#, и желание применить полученные знания.
Итак, на повестке сегодняшнего дня — моноиды и их основное применение для кеширования вычислений в деревьях.
Представьте себе множество чего угодно, множество, состоящее из объектов, которыми мы собираемся манипулировать. Назовём его M. На этом множестве мы вводим бинарную операцию, то есть функцию, которая паре элементов множества ставит в соответствие новый элемент. Здесь и далее эту абстрактную операцию мы будем обозначать "⊗", и записывать выражения в инфиксной форме: если a и b — элементы множества, то c = a ⊗ b — тоже какой-то элемент этого множества.
Например, рассмотрим все строки, существующие на свете. И рассмотрим операцию конкатенации строк, традиционно обозначаемую в математике "◦", а в большинстве языков программирования "+":
Или другой пример — функция fst, известная в функциональных языках при манипуляции с кортежами. Из двух своих аргументов она возвращает в качестве результата первый по порядку. Так,fst(5, 2) = 5 ; fst( . Безразлично, на каком множестве рассматривать эту бинарную операцию, так что в вашей воле выбрать любое.
Далее мы на нашу операцию "⊗" накладываем ограничение ассоциативности. Это значит, что от неё требуется следующее: если с помощью "⊗" комбинируют последовательность объектов, то результат должен оставаться одинаковым вне зависимости от порядка применения "⊗". Более строго, для любых трёх объектов a, b и c должно иметь место:
(a ⊗ b) ⊗ c = a ⊗ (b ⊗ c)
Легко увидеть, что конкатенация строк ассоциативна: не важно, какое склеивание в последовательности строк выполнять раньше, а какое позже, в итоге все равно получится общая склейка всех строк в последовательности. То же касается и функции fst, ибо:
fst(fst(a, b), c) = a
fst(a, fst(b, c)) = a
Цепочка применений fst к последовательности в любом порядке всё равно выдаст её головной элемент.
И последнее, что мы потребуем: в множестве M по отношению к операции должен существовать нейтральный элемент, или единица операции. Это такой объект, который можно комбинировать с любым элементом множества, и это не изменит последний. Формально выражаясь, если e — нейтральный элемент, то для любого a из множества имеет место:
a ⊗ e = e ⊗ a = a
В примере со строками нейтральным элементом выступает пустая строкаfst(e, a) = e всегда, и если a ≠ e , то свойство нейтральности мы теряем. Можно, конечно, рассмотреть fst на множестве из одного элемента, но кому такая скука нужна? :)
Каждую такую тройку <M, ⊗, e> мы и будем торжественно называть моноидом. Зафиксируем это знание в коде:
Больше примеров моноидов, а также где мы их, собственно, применять будем, лежит под катом.
Перед тем как двигаться дальше, надо убедить читателя в том, что в мире встречается тьма-тьмущая различных моноидов. Некоторые из них мы будем использовать далее по тексту как примеры, другие читатель, возможно, встретит в своей практике. Я составлю простенький список, для каждого моноида указывая рассматриваемое множество, операцию комбинирования и нейтральный элемент. В ассоциативности всех операций вам предлагается убедиться самостоятельно, мне просто не хватит здесь места :) Кроме того, я капельку схитрю и несколько самых интересных и неординарных моноидов в перечисление не включу, ибо в последующем в статье им будут посвящены целые главы.
Итак, популярные моноиды:
На этом пока (!) покончим с примерами и перейдём к практике. Перед тем как собственно представить эту долгожданную практику, я запишу на C# определения парочки простеньких моноидов из этого списка, с которыми мы будем работать в следующей главе.
С этого момента мы вступаем в область практических применений.
Для начала нам понадобится определение структуры данных под названием Rope. Редкие русскоязычные источники, не мудрствуя лукаво, переводят её как верёвка, не буду отступать от этой традиции и я. Итак, верёвка впервые была предложена в 1995 году как удобная реализация неизменяемых строк с дополнительными возможностями — например, очень быстрой операцией взятия подстроки и слияния строк. С такими целями эта структура и продолжает использоваться, например, в библиотеке Java.
Представьте себе произвольное сбалансированное двоичное дерево. Подвесим к этому дереву в качестве листьев слова — т.е. массивы символов. Полученное дерево может выглядеть, например, так:
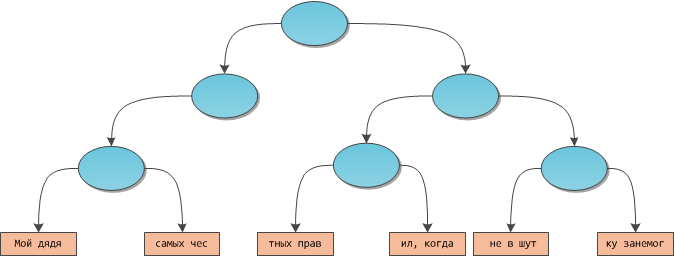
Такая структура данных и будет называться верёвкой.
Из прошлых статей о декартовом дереве мы помним, как можно в таком дереве, например, определить запрос символа по индексу — достаточно хранить в промежуточных вершинах размеры поддеревьев, в данном случае — суммарную длину строки, подвешенной к поддереву. Для данного дерева подобная схема будет выглядеть так:

Теперь, применив знакомый алгоритм K-й порядковой статистики, можно дойти до массива, содержащего символ под искомым номером, и вернуть нужный символ уже путем прямой индексации в памяти массива. Стоит заметить, что на листьях дерева подвешиваются массивы вместо отдельных символов исключительно из соображений оптимизации памяти на больших строках и производительности на небольших.
Чтобы склеить две верёвки, достаточно создать новую корневую вершину и подвесить к ней два данных дерева в качестве сыновей. Поскольку исходные деревья были сбалансированы, новая верёвка тоже получится сбалансированной. Часто также просматривают, а не являются ли склеиваемые верёвки слишком маленькими, нет ли смысла объединить в верёвке-результате какие-то листовые сегменты.
Чтобы выделить подстроку в строке, достаточно применить простой алгоритм, похожий на K-ю порядковую статистику. Пускай требуется выделить в верёвке T подстроку длины len, начиная с символа start.
Сначала рассмотрим два крайних случая.
Если
Далее возможен случай, когда искомая подстрока целиком лежит в левом поддереве, то есть имеет место
Симметричный случай — подстрока целиком в правом поддереве, то есть
В нашем примере можно сделать вызов
 И наконец, самый мудрёный случай — искомая подстрока перекрывает кусочек как левого, так и правого поддерева.
И наконец, самый мудрёный случай — искомая подстрока перекрывает кусочек как левого, так и правого поддерева.
В таком случае нам придется выделить тот кусочек, который входит только в левое поддерево, затем тот кусочек, который входит только в правое, и слить их. Сливать вместе две верёвки мы уже умеем.
Определить индексы искомых кусочков совсем несложно. Рекурсивный вызов для левого поддерева:
Для правого:
Опять-таки, нам пришлось передать правому поддереву ноль в качестве аргумента
Если эти индексы кажутся неочевидными — взгляните на рисунок.
В конце концов рекурсивные вызовы доходят до листьев, в которых запрос подстроки уже делается обычным линейным образом по сегменту. Таким образом гарантируется максимальная производительность. Общая сложность операции — O(log N).
Думаю, нет нужды говорить, что подобную структуру данных можно использовать не только для реализации строк. Любая гигантская последовательность элементов может быть представлена в подобном виде, достаточно выбрать оптимальную длину для низлежащих листовых сегментов, и — вуаля! — мы получаем удобную структуру данных для манипуляций над неизменяемыми последовательностями колоссальной длины. Правда, вы скажете, пока что операций что-то было продемонстрировано маловато, чтобы служить убедительным аргументом для такого перехода. Ничего, это поправимо :)
Я надеюсь, вы помните, как мы на примере декартового дерева делали множественные запросы на подотрезках. Вкратце напомню суть концепции: в каждой вершине дерева хранилась некая аннотация — параметр, равный запрашиваемой величине для подотрезка, соответствующего поддереву с корнем в этой вершине. Например, это могла быть сумма элементов поддерева, максимум элементов поддерева, наличие или отсутствие булевого флага на подотрезке и так далее. Когда пользователь хотел сделать запрос на подотрезке, нам не приходилось каждый раз заново считать его за O(N) для всех искомых вершин, ведь для некоторых поддеревьев ответы уже были закешированы в вершинах, и оставалось только объединить их.
В декартовом дереве всю «чёрную работу» по восстановлению справедливости в каждой вершине за нас делала функция Split, нам оставалось только вырезать искомый подотрезок из дерева и взять вычисленное значение в корне как ответ запроса. Но ведь можно было бы поступить и иначе. Помните алгоритм взятия подстроки в верёвке? Он рекурсивно спускался от вершины к вершине, локализируя левую и правую границу искомой подстроки, а потом сливал все, что найдет по пути. Этот подход прекрасно можно было бы применить и здесь.
Рассмотрим снова неявное декартово дерево с аннотациями — суммами поддеревьев — в вершинах, и попробуем сделать на нем запрос суммы на подотрезке
Инициализируем результат в 0.
На итерации 1 мы спускаемся в левое поддерево [0; 9]. Результат остается 0.
На итерации 2 мы спускаемся в правое поддерево [5; 9]. Результат увеличивается на значение в корне — 42.
На итерации 3 мы спускаемся в правое поддерево [8; 9]. Результат увеличивается на сумму левого поддерева [5; 6] плюс значение в корне и становится равен 42+23+3 = 68.
На итерации 4 мы спускаемся в левое поддерево [8; 8]. Результат остается 68.
На итерации 5 мы добавляем к результату значение в корне (29), получаем в сумме 97, и это ответ задачи.
Схема очень простая, основанная на уже знакомом разборе случаев в каждой вершине: как соотносится запрашиваемый отрезок с отрезками соответствующими моему левому сыну, правому сыну и мне самому? На основе этого мы делаем либо один, либо два рекурсивных вызова, которые вычисляют значения в подотрезках слева и справа и суммируют их (в примере выше два рекурсивных вызова никогда делать не потребовалось). Только теперь в разборе случаев ещё приходится учитывать данные, хранящиеся в корне.
Можно легко представить себе верёвку, хранящую в своих листьях сегменты чисел, а в вершинах — аннотации, соответствующие суммам на подотрезках. Тогда запрос суммы на любом подотрезке будет по своей структуре идентичен алгоритму взятия подстроки из предыдущего параграфа, только по пути он будет накапливать эту сумму, а возвращаясь из рекурсии — прибавлять ответ к результату и передавать выше. Простота схемы сомнений не вызывает, хочется только понять, почему же она всегда будет выдавать правильный ответ.
А понять это тоже несложно. Мы по факту производим то же суммирование, как если бы мы просто линейно прошлись по всем ячейкам подотрезка, только суммируем мы теперь а) целыми блоками ячеек; б) не обязательно в порядке слева направо. Фактически можно представить процесс так:
Линейный проход: (Cl + Cl+1 + … + Cr)
Запрос по дереву: (Cl + (((Cl+1 + … + Ci) + (Ci+1 + … + Cj)) + (Cj+1 + … + Cr-1) + … + Cr))
Мы по факту просто расставили скобки в каком-то другом порядке, и это ни в коем случае не изменило результат, ведь "+" — ассоциативная операция! О, встретилось знакомое слово из первых параграфов :) Похоже, здесь наклевывается гораздо более общая концепция…
Назовём функцию, характеризующую множество элементов, содержащихся в дереве, мерой дерева. Обычно мера дерева — это именно та операция, запросы по которой мы и будем впоследствии производить. Я уже приводил примеры: сумма элементов, максимум элементов, наличие флага на элементах и так далее. Можно представить себе более сложные меры, например, сумму квадратов либо гистограмму частотности символов.
Любую меру можно, пользуясь уже известной нам техникой, закешировать в вершинах верёвки для каждого поддерева. Тогда запрос меры на любом подотрезке по описанному выше алгоритму можно легко выполнить за логарифмическое время, если функция меры является ассоциативной. Добавим к этому свойству вполне логичное требование возможности определить меру для каждого отдельного элемента дерева.
Мы получим универсальную структуру данных: верёвку, которая позволяет быстро запрашивать значение меры на любом подотрезке, в том числе после склеивания и разрезания верёвок. Время доступа остаётся логарифмическим, ведь дерево-то самостоятельно балансируется! При добавлении элементов кешированные значения меры для новых поддеревьев пересчитываются, для нетронутых — остаются теми же. И всё это за O(log N). Потрясающе.
А теперь сузим немного определение меры. Пускай мы умеем измерять только каждый конкретный одиночный элемент дерева. Как теперь получать меру поддеревьев? Очень просто. Достаточно уметь комбинировать две меры между собой так, чтобы комбинация меры одного элемента с мерой другого давала меру множества их двоих. При этом этот процесс комбинирования должен быть ассоциативным, иначе наш алгоритм запроса будет получать неправильный ответы. Эти рассуждения приводят нас к естественному выводу: мерой может быть любая функция, результатом которой являются элементы моноида.
Мера «Максимум» — элементарная функция x с результатами в моноиде <Числа, max, -∞>.
Мера «Сумма квадратов» — элементарная функция x2 с результатами в моноиде <Числа, +, 0>.
Мера «Гистограмма частотности» — элементарная функция «100% для единственного данного символа» с результатами в моноиде <Гистограммы, комбинирование гистограмм с учётом количества символов, пустая гистограмма>. Читателю в качестве упражнения остаётся продумать полностью ассоциативную операцию комбинирования гистограмм частотности.
Опишу то, чего мы здесь только что добились, в коде. С этого момента хорошо бы переходить полностью на Haskell, ибо реализация все тех же идей на C# выглядит крайне уродливо и многосложно: так, дерево придется параметризовать тремя типовыми параметрами вместо двух!
Я приведу реализацию простого бинарного дерева без балансировки и собственно добавлений/склеек/разрезаний. Как реализуются эти операции, специфично для каждого конкретного вида сбалансированного дерева и потребовало бы отдельной статьи, что, как я уже говорил, не является моей целью. Читатель легко может представить на месте класса
Кульминацией всех наших усилий в данном параграфе станет обобщённый метод для запроса меры подотрезка.
Можно ещё больше расширить класс операций, которые мы умеем выполнять на верёвке, параметризированной моноидом. Мы уже умеем выполнять запрос разнообразных мер на подотрезках. Но часто в жизни требуется не просто знать некоторое значение, а ещё и элементы, которые «самым главным образом» учавствуют в его создании.
Например, если мера — максимум элементов отрезка, то неплохо бы узнать, на каком именно элементе по счёту этот максимум достигается. К таким же операциям относится и наш старый добрый доступ по индексу. Все эти операции, как мы помним, описываются очень похожим алгоритмом — он линейно спускается от одной вершины дерева к другой, пока не достигнет нужного листа. Так вот, существует очень простой способ все такие операции обобщить.
Рассмотрим некоторый предикат p, то бишь булевую функцию одного произвольного аргумента.
Пускай у нас есть последовательность объектовa1… aN . Объекты суть элементы какого-нибудь моноида. Например, пускай это будут строки.
Будем последовательно вычислять префиксные суммы нашей последовательности. Это будет такая новая последовательность:
a1
a1 ⊗ a2
a1 ⊗ a2 ⊗ a3
…
a1 ⊗ a2 ⊗ a3 ⊗… ⊗ aN
Здесь "⊗", как мы и договаривались, — операция моноида. Для примера со строками это будет конкатенация.
Теперь вычислим значение предиката на всех этих префиксных суммах. Получим последовательность булевских значений.
И наконец, назовём предикат монотонным, если он на наших префиксных суммах сначала постоянно равен False, потом в некоторый момент меняет False на True, после чего остаётся равным True до конца последовательности.
Проще говоря, если заменить False на 0, а True на 1, то последовательность результатов предиката должна быть неубывающей.
Я продемонстрирую это свойство на рисунке для моноида строк. Пусть p(s) = {s содержит
В вершинах верёвки — закешированные значения меры, то есть конкатенации строк поддерева.
Алгоритм постоянно поддерживает два префикса: один без учета текущего левого сына, второй — включает его. В зависимости от значения предиката на этих префиксах можно постоянно верно определять, внутри какого поддерева произошёл «скачок».
Например, когда мы находились в корне верёвки, алгоритм увидел, чтоp( , значит, скачок произошёл в правом поддереве, куда мы и спустились. Зато на следующей итерации значение на левом префиксе p( , стало быть, надо спускаться в левое поддерево.
По ходу спуска надо постоянно поддерживать корректное значение префикса, склеивая его с мерой текущего левого сына в случае спуска в правое поддерево.
В конце концов за логарифмическое число шагов мы доберемся до листа, в котором произошёл скачок. Внутри листового сегмента искать точное место скачка уже приходится отдельным способом, скорее всего последовательной проверкой. Впрочем, это может быть и не так тривиально: представьте себе вместо предиката «содержит данную подстроку» предикат «удовлетворяет данному регулярному выражению». Он тоже монотонный, но его вычисление требует некоторых усилий.
Для меры вида «сумма квадратов» и предиката «больше 256», к примеру, нам тоже потребовалось бы в листе отдельно вычислять квадраты каждого конкретного числа из сегмента, чтобы определить точную позицию скачка.
Кстати говоря. Если хранить в листах не сегменты со словами, а отдельные символы, то на основании данного алгоритма можно определить операцию split. Она разрезает дерево по монотонному предикату на два: в левом результате свойство предиката ещё не выполняется, а в правом — уже выполняется. Реализацию точного алгоритма split можно с чистой совестью оставить читателю как упражнение :)
Между прочим, в одном из последующих параграфов она нам таки пригодится.
Зато теперь видно, что, к примеру, доступ к элементу под индексом i — это просто поиск в дереве по монотонному предикату «длина префикса > i». Длина префикса — это обыкновенная мера, мы использовали её как меру, когда хранили в вершинах размеры поддеревьев. У этой меры элементарная функция — тождественная единичка, а значения лежат в моноиде <Числа, +, 0>. Позиция №i — это именно та позиция, где длина префикса последовательности начинает превышать i.
Итак, мы рассмотрели все основные преимущества, которые даёт нам такая концепция, как параметризация верёвки некоторым моноидом. Мы можем брать произвольные последовательности «измеримых» значений и комбинировать их друг за другом, для любого подотрезка получаемых последовательностей узнавая значение меры. Если нам будет интересно, можем узнать точную позицию достижения, разрезав полученную верёвку по некоторому монотонному предикату. И всё это за логарифмическое время, что даёт нам безграничный простор возможностей. Этот безграничный простор я и собираюсь сейчас применить на практике, показав вам три довольно нестандартных, очень жизненных и интересных моноида.
В этот раз мы манипулируем чем-то позанятнее скучных чисел, строк или булов. Объектом нашего пристального внимания станут… выборки.
Выборка, то есть конечный набор случайных значений из некоей генеральной совокупности, может быть измерима. Все знают основные характеристики выборки:
N — размер выборки.
M — среднее значение выборки.
V — дисперсия выборки, то есть среднее значение квадратов отклонения от среднего выборки.
Мы рассмотрим немасштабированную дисперсию, то есть просто сумму квадратов отклонения от среднего. При необходимости получить из неё настоящую можно элементарно, просто поделив число на N.
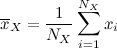
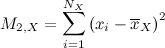
Я сказал абзацем ниже, что выборка «может быть измерима». Да, я не случайно употребил именно это слово :) Набор из этих трех базовых характеристик выборки может служить её мерой.
Стоп-стоп-стоп, скажете вы, какого это лешего набор из трёх малосвязанных чисел — элемент моноида? Какого вообще моноида-то? Надо как-то комбинировать выборки, получается? А как вообще?
Все это прекрасно делается. Пускай у вас есть две выборки A и B из одной генеральной совокупности. Вы сливаете эти выборки вместе, создавая совместную выборку X, чей размер — сумма размеров исходных. Тогда, как показал в 1979 году Tony Chan, можно вычислить среднее и немасштабированную дисперсию новой выборки по следующим формулам:
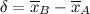
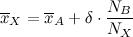
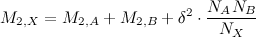
Очевидно, что не играет роли, в каком порядке смешивать вместе выборки — характеристики итоговой выборки будут одними и теми же. Таким образом, слияние выборок ассоциативно.
Остаётся формальности ради определить, что такое характеристики пустой выборки. Размер её, очевидно, 0, среднее в силу аддитивности тоже будет 0, а вот дисперсию определить удовлетворительно не получится. Впрочем, и не нужно — мы в наших деревьях дисперсии пустой выборки вообще касаться не будем.
Определение моноида статистических характеристик и всего, что из него следует, мне пришлось поместить на pastie.org, потому что ограничение Хабрахабра на размер статьи начинает несколько напрягать :)
Можно легко представить себе поток случайных величин, по которым движется «окно» размера K, т.е. нам постоянно нужно узнавать дисперсию и матожидание последних K величин. Создаётся дерево, из него последовательно убираются и добавляются элементы, как в очередь, а в корне дерева всегда лежат нужные нам вычисленные величины. Красота.

Есть два полупрозрачных изображения (с альфа-каналом). Мы хотим определить оператор наложения двух изображений, более известный как альфа-композиция. С его действием знакомы все, кто когда-нибудь игрался с полупрозрачными изображениями в Photoshop.
Для каждого пикселя у изображений определено два параметра: цвет C и альфа-канал α. Задание формул для вычисления этих значений полностью и однозначно задаёт оператор наложения. Так вот, оказывается, что можно легко вывести математически следующие факты:
За доказательством этих фактов и конкретными формулами отсылаю вас к соответствующей статье Википедии.
Таким образом, полупрозрачные изображения по операции альфа-композиции образуют моноид. Это даёт нам возможность обрабатывать гигантские наборы изображений, которые должны одно за другим накладываться друг на друга, с помощью соответствующего дерева.
К сожалению, объём, накладываемый Хабрахабром на статью, не дает мне возможности закончить её толково и подробно описать третий красивый моноид, а именно моноид переходных функций конечных автоматов для распознавания регулярных выражений. Его использование на верёвку позволяет создать инкрементальный лексер — структуру, которая позволяет производить над строкой быстрые модификации, и в любой момент времени давать моментальный ответ, где в строке матчится наперёд заданное регулярное выражение. За дальнейшими подробностями отсылаю вас к переводу оригинальной статьи Дэна Пипони и более подробной статье-реализации Евгения Кирпичева. Картинка-затравка:

А пока что всем спасибо за внимание.
Нам понадобится капелька абстрактного мышления, знание какого-нибудь сбалансированного дерева поиска (например, описанного мною ранее декартова дерева), умение читать простой код на C#, и желание применить полученные знания.
Итак, на повестке сегодняшнего дня — моноиды и их основное применение для кеширования вычислений в деревьях.
Моноид как концепция
Представьте себе множество чего угодно, множество, состоящее из объектов, которыми мы собираемся манипулировать. Назовём его M. На этом множестве мы вводим бинарную операцию, то есть функцию, которая паре элементов множества ставит в соответствие новый элемент. Здесь и далее эту абстрактную операцию мы будем обозначать "⊗", и записывать выражения в инфиксной форме: если a и b — элементы множества, то c = a ⊗ b — тоже какой-то элемент этого множества.
Например, рассмотрим все строки, существующие на свете. И рассмотрим операцию конкатенации строк, традиционно обозначаемую в математике "◦", а в большинстве языков программирования "+":
"John" ◦ "Doe" = "JohnDoe"Или другой пример — функция fst, известная в функциональных языках при манипуляции с кортежами. Из двух своих аргументов она возвращает в качестве результата первый по порядку. Так,
"foo", "bar") = "foo"Далее мы на нашу операцию "⊗" накладываем ограничение ассоциативности. Это значит, что от неё требуется следующее: если с помощью "⊗" комбинируют последовательность объектов, то результат должен оставаться одинаковым вне зависимости от порядка применения "⊗". Более строго, для любых трёх объектов a, b и c должно иметь место:
Легко увидеть, что конкатенация строк ассоциативна: не важно, какое склеивание в последовательности строк выполнять раньше, а какое позже, в итоге все равно получится общая склейка всех строк в последовательности. То же касается и функции fst, ибо:
fst(fst(a, b), c) = a
fst(a, fst(b, c)) = a
Цепочка применений fst к последовательности в любом порядке всё равно выдаст её головной элемент.
И последнее, что мы потребуем: в множестве M по отношению к операции должен существовать нейтральный элемент, или единица операции. Это такой объект, который можно комбинировать с любым элементом множества, и это не изменит последний. Формально выражаясь, если e — нейтральный элемент, то для любого a из множества имеет место:
a ⊗ e = e ⊗ a = a
В примере со строками нейтральным элементом выступает пустая строка
"": с какой стороны к какой строке её ни приклеивай, строка не поменяется. А вот fst в этом отношении нам устроит подлянку: нейтральный элемент для неё придумать невозможно. Ведь Каждую такую тройку <M, ⊗, e> мы и будем торжественно называть моноидом. Зафиксируем это знание в коде:
public interface IMonoid<T> { T Zero { get; } T Append(T a, T b); }
Больше примеров моноидов, а также где мы их, собственно, применять будем, лежит под катом.
Примеры
Перед тем как двигаться дальше, надо убедить читателя в том, что в мире встречается тьма-тьмущая различных моноидов. Некоторые из них мы будем использовать далее по тексту как примеры, другие читатель, возможно, встретит в своей практике. Я составлю простенький список, для каждого моноида указывая рассматриваемое множество, операцию комбинирования и нейтральный элемент. В ассоциативности всех операций вам предлагается убедиться самостоятельно, мне просто не хватит здесь места :) Кроме того, я капельку схитрю и несколько самых интересных и неординарных моноидов в перечисление не включу, ибо в последующем в статье им будут посвящены целые главы.
Итак, популярные моноиды:
- <Числа, +, 0>. Под числами понимается любое численное множество — от натуральных до комплексных.
- <Числа, *, 1>.
- <Boolean, &&, True>.
- <Boolean, ||, False>.
- <Строки, конкатенация ◦, пустая строка
"">. - <Списки, конкатенация ++, пустой список []>.
- <Множества, объединение ∪, пустое множество ∅>.
- <Сортированные списки, merge, пустой список []>. Здесь под merge понимается линейная операция слияния двух упорядоченных списков, наверняка известная вам по алгоритму сортировки Merge Sort. Кстати, корректность самого алгоритма Merge Sort вытекает именно из того, что merge — моноидальная операция. Более того, идеей, подобной его основной идее, мы сегодня воспользуемся не раз.
- <Целые числа, НОК, 1>.
- <Многочлены одной переменной, НОК, 1>.
- <Целые числа и многочлены, НОД, 0>. Ассоциативность наибольшего общего делителя понятна. Что касается нуля как нейтрального элемента, то это свойство часто полагают по определению, ибо оно легко согласуется с алгоритмом Эвклида.
- <Матрицы, *, единичная матрица>. Что интересно, если ограничить множество невырожденными матрицами (у которых определитель не равен 0), то полученная структура все равно останется моноидом — произведение невырожденных матриц даёт невырожденную матрицу. Это нехитрое утверждение вытекает из свойств определителя.
- <Числа, min, +∞>.
- <Числа, max, -∞>.
- <Перестановки чисел от 1 до N, произведение перестановок ◦, тождественная перестановка (123..N)>.
Под произведением перестановок s и t в дискретной математике понимают следующую операцию: берём число на первой позиции s, по этому индексу берём число в t и ставим его на первую позицию результата; затем повторяем эту двойную индексацию для второй позиции и так далее до N-й. То есть еслиu = s ◦ t , тоu[i] = t[s[i]], i = 1..N - Рассмотрим некоторое множество X. Под XX в математике принято обозначать множество эндоморфизмов — произвольных функций из множества X в него же. Так, если X — целые числа, то любая функция вида
int → int
Так вот, <Эндоморфизмы, композиция функций, тождественная функция id> — моноид. - Возьмите обычную линейную целочисленную операцию ("+" или "*") и ограничьте её применение до чисел, берущихся по остатку от некоего числа P. Например, можно рассматривать умножение по модулю 7, где 3*4 = 5, потому что 12 % 7 = 5. Полученные операции на таком множестве останутся замкнутыми и тоже будут образовывать моноид — крайне важный моноид для теории чисел и криптографии.
Кстати, если принять P = 2, то мы получим побитовые операции. Так, "&" — это умножение по модулю 2, а "^", известная также как XOR — сложение по модулю 2. Таким образом,<Boolean, ^, False> — тоже моноид. - <Словари (ассоциативные массивы), объединение, пустой словарь>. Данные, хранимые в словаре, сами должны образовывать моноид, таким образом разрешаются конфликты при объединении:
(map1 ∪ map2)[key] = map1[key] ⊗ map2[key]
Или можно рассматривать не просто словари из ключей в значения (K -> V), а мульти-словари из ключей в списки значений (K -> [V]), тогда при объединении словарей списки с одинаковыми ключами можно просто сливать, пользуясь тем, что списки сами образуют моноид.
На этом пока (!) покончим с примерами и перейдём к практике. Перед тем как собственно представить эту долгожданную практику, я запишу на C# определения парочки простеньких моноидов из этого списка, с которыми мы будем работать в следующей главе.
Все моноиды мы будем реализовывать как синглтоны. Чтобы было впоследствии удобнее делать доступ к экземпляру для любого неизвестного типа-моноида, я вынес его создание в отдельный статический класс.
public static class Singleton<T> where T : new() { private static readonly T _instance = new T(); public static T Instance { get { return _instance; } } } public class AddMonoid : IMonoid<int> { public AddMonoid() {} public int Zero { get { return 0; } } public int Append(int a, int b) { return a + b; } } public class FunctionMonoid<T> : IMonoid<Func<T, T>> { public FunctionMonoid() {} public Func<T, T> Zero { get { return x => x; } } public Func<T, T> Append(Func<T, T> f, Func<T, T> g) { return x => g(f(x)); } } public class GCDMonoid : IMonoid<int> { public GCDMonoid() {} private int gcd(int a, int b) { return b == 0 ? a : gcd(b, a % b); } public int Zero { get { return 0; } } public int Append(int a, int b) { return gcd(a, b); } }
Откуда в информатике верёвки
С этого момента мы вступаем в область практических применений.
Для начала нам понадобится определение структуры данных под названием Rope. Редкие русскоязычные источники, не мудрствуя лукаво, переводят её как верёвка, не буду отступать от этой традиции и я. Итак, верёвка впервые была предложена в 1995 году как удобная реализация неизменяемых строк с дополнительными возможностями — например, очень быстрой операцией взятия подстроки и слияния строк. С такими целями эта структура и продолжает использоваться, например, в библиотеке Java.
Представьте себе произвольное сбалансированное двоичное дерево. Подвесим к этому дереву в качестве листьев слова — т.е. массивы символов. Полученное дерево может выглядеть, например, так:
Такая структура данных и будет называться верёвкой.
Доступ по индексу
Из прошлых статей о декартовом дереве мы помним, как можно в таком дереве, например, определить запрос символа по индексу — достаточно хранить в промежуточных вершинах размеры поддеревьев, в данном случае — суммарную длину строки, подвешенной к поддереву. Для данного дерева подобная схема будет выглядеть так:
Теперь, применив знакомый алгоритм K-й порядковой статистики, можно дойти до массива, содержащего символ под искомым номером, и вернуть нужный символ уже путем прямой индексации в памяти массива. Стоит заметить, что на листьях дерева подвешиваются массивы вместо отдельных символов исключительно из соображений оптимизации памяти на больших строках и производительности на небольших.
Склейка
Чтобы склеить две верёвки, достаточно создать новую корневую вершину и подвесить к ней два данных дерева в качестве сыновей. Поскольку исходные деревья были сбалансированы, новая верёвка тоже получится сбалансированной. Часто также просматривают, а не являются ли склеиваемые верёвки слишком маленькими, нет ли смысла объединить в верёвке-результате какие-то листовые сегменты.
Запрос подстроки
Чтобы выделить подстроку в строке, достаточно применить простой алгоритм, похожий на K-ю порядковую статистику. Пускай требуется выделить в верёвке T подстроку длины len, начиная с символа start.
Сначала рассмотрим два крайних случая.
Если
start = 0len = T.Left.SizeT.Left. Аналогично, если start = T.Left.Sizelen = T.Right.SizeT.Right. На рисунке выше второй случай реализуется, если вызвать функцию Substring(start: 18, len: 37), тогда функция сразу вернет правое поддерево с искомой подстрокой "тных правил, когда не в шутку занемог".Далее возможен случай, когда искомая подстрока целиком лежит в левом поддереве, то есть имеет место
start < T.Left.Sizestart + len ≤ T.Left.SizeСимметричный случай — подстрока целиком в правом поддереве, то есть
start ≥ T.Left.Sizestart + len ≤ T.Left.Size + T.Right.Sizestart размер левого поддерева — ведь индексация-то в правом поддереве будет начинаться с нуля, оно считает себя независимым деревом.В нашем примере можно сделать вызов
Substring(start: 18, len: 18). Тогда на первом шаге функция определит, что необходимо спуститься рекурсивно вправо и сделает на правом поддереве вызов Substring(start: 0, len: 18). А он, в свою очередь, согласно первому случаю вернет нам целиком своё левое поддерево, соответствующее подстроке "тных правил, когда".И наконец, самый мудрёный случай — искомая подстрока перекрывает кусочек как левого, так и правого поддерева.В таком случае нам придется выделить тот кусочек, который входит только в левое поддерево, затем тот кусочек, который входит только в правое, и слить их. Сливать вместе две верёвки мы уже умеем.
Определить индексы искомых кусочков совсем несложно. Рекурсивный вызов для левого поддерева:
Substring(start: start, len: T.Left.Size - start)Для правого:
Substring(start: 0, len: len - (T.Left.Size - start))Опять-таки, нам пришлось передать правому поддереву ноль в качестве аргумента
start, потому как функция на нём будет работать независимо.Если эти индексы кажутся неочевидными — взгляните на рисунок.
В конце концов рекурсивные вызовы доходят до листьев, в которых запрос подстроки уже делается обычным линейным образом по сегменту. Таким образом гарантируется максимальная производительность. Общая сложность операции — O(log N).
Прочее
Думаю, нет нужды говорить, что подобную структуру данных можно использовать не только для реализации строк. Любая гигантская последовательность элементов может быть представлена в подобном виде, достаточно выбрать оптимальную длину для низлежащих листовых сегментов, и — вуаля! — мы получаем удобную структуру данных для манипуляций над неизменяемыми последовательностями колоссальной длины. Правда, вы скажете, пока что операций что-то было продемонстрировано маловато, чтобы служить убедительным аргументом для такого перехода. Ничего, это поправимо :)
Что касается выбора структуры. Можно выбрать произвольное самобалансирующееся двоичное дерево, которое хранит свои данные в листьях, например, 2-3 дерево или B-дерево. Много деревьев поиска, созданных прежде всего для реализации множеств, хранят свои данные в каждой вершине, в том числе красно-черное дерево и декартово дерево. Реализовывать на них верёвки-строки непрактично, это приведет к большому количеству аллокаций памяти по ходу операций и несколько усложненному коду, однако главная задача данной статьи — параметризация деревьев моноидами — с лёгкостью подходит как для деревьев первого, так и второго типа. Так что по ходу рассказа я иногда буду ссылаться на текст статьи о декартовом дереве, а иногда — на Finger tree, чтобы облегчить себе изложение и не захламлять его деталями реализаций тех или иных сбалансированных деревьев, что здесь было бы совершенно лишним. Я надеюсь, читатель прекрасно поймет и примет любой подход.
Параметризация, или как померить дерево
Я надеюсь, вы помните, как мы на примере декартового дерева делали множественные запросы на подотрезках. Вкратце напомню суть концепции: в каждой вершине дерева хранилась некая аннотация — параметр, равный запрашиваемой величине для подотрезка, соответствующего поддереву с корнем в этой вершине. Например, это могла быть сумма элементов поддерева, максимум элементов поддерева, наличие или отсутствие булевого флага на подотрезке и так далее. Когда пользователь хотел сделать запрос на подотрезке, нам не приходилось каждый раз заново считать его за O(N) для всех искомых вершин, ведь для некоторых поддеревьев ответы уже были закешированы в вершинах, и оставалось только объединить их.
В декартовом дереве всю «чёрную работу» по восстановлению справедливости в каждой вершине за нас делала функция Split, нам оставалось только вырезать искомый подотрезок из дерева и взять вычисленное значение в корне как ответ запроса. Но ведь можно было бы поступить и иначе. Помните алгоритм взятия подстроки в верёвке? Он рекурсивно спускался от вершины к вершине, локализируя левую и правую границу искомой подстроки, а потом сливал все, что найдет по пути. Этот подход прекрасно можно было бы применить и здесь.
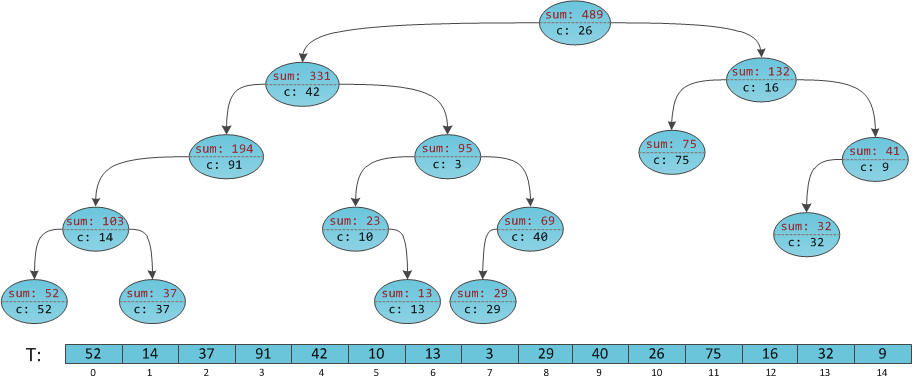
Рассмотрим снова неявное декартово дерево с аннотациями — суммами поддеревьев — в вершинах, и попробуем сделать на нем запрос суммы на подотрезке
[4; 8].Инициализируем результат в 0.
На итерации 1 мы спускаемся в левое поддерево [0; 9]. Результат остается 0.
На итерации 2 мы спускаемся в правое поддерево [5; 9]. Результат увеличивается на значение в корне — 42.
На итерации 3 мы спускаемся в правое поддерево [8; 9]. Результат увеличивается на сумму левого поддерева [5; 6] плюс значение в корне и становится равен 42+23+3 = 68.
На итерации 4 мы спускаемся в левое поддерево [8; 8]. Результат остается 68.
На итерации 5 мы добавляем к результату значение в корне (29), получаем в сумме 97, и это ответ задачи.
Схема очень простая, основанная на уже знакомом разборе случаев в каждой вершине: как соотносится запрашиваемый отрезок с отрезками соответствующими моему левому сыну, правому сыну и мне самому? На основе этого мы делаем либо один, либо два рекурсивных вызова, которые вычисляют значения в подотрезках слева и справа и суммируют их (в примере выше два рекурсивных вызова никогда делать не потребовалось). Только теперь в разборе случаев ещё приходится учитывать данные, хранящиеся в корне.
Можно легко представить себе верёвку, хранящую в своих листьях сегменты чисел, а в вершинах — аннотации, соответствующие суммам на подотрезках. Тогда запрос суммы на любом подотрезке будет по своей структуре идентичен алгоритму взятия подстроки из предыдущего параграфа, только по пути он будет накапливать эту сумму, а возвращаясь из рекурсии — прибавлять ответ к результату и передавать выше. Простота схемы сомнений не вызывает, хочется только понять, почему же она всегда будет выдавать правильный ответ.
А понять это тоже несложно. Мы по факту производим то же суммирование, как если бы мы просто линейно прошлись по всем ячейкам подотрезка, только суммируем мы теперь а) целыми блоками ячеек; б) не обязательно в порядке слева направо. Фактически можно представить процесс так:
Линейный проход: (Cl + Cl+1 + … + Cr)
Запрос по дереву: (Cl + (((Cl+1 + … + Ci) + (Ci+1 + … + Cj)) + (Cj+1 + … + Cr-1) + … + Cr))
Мы по факту просто расставили скобки в каком-то другом порядке, и это ни в коем случае не изменило результат, ведь "+" — ассоциативная операция! О, встретилось знакомое слово из первых параграфов :) Похоже, здесь наклевывается гораздо более общая концепция…
Мера
Назовём функцию, характеризующую множество элементов, содержащихся в дереве, мерой дерева. Обычно мера дерева — это именно та операция, запросы по которой мы и будем впоследствии производить. Я уже приводил примеры: сумма элементов, максимум элементов, наличие флага на элементах и так далее. Можно представить себе более сложные меры, например, сумму квадратов либо гистограмму частотности символов.
Любую меру можно, пользуясь уже известной нам техникой, закешировать в вершинах верёвки для каждого поддерева. Тогда запрос меры на любом подотрезке по описанному выше алгоритму можно легко выполнить за логарифмическое время, если функция меры является ассоциативной. Добавим к этому свойству вполне логичное требование возможности определить меру для каждого отдельного элемента дерева.
Мы получим универсальную структуру данных: верёвку, которая позволяет быстро запрашивать значение меры на любом подотрезке, в том числе после склеивания и разрезания верёвок. Время доступа остаётся логарифмическим, ведь дерево-то самостоятельно балансируется! При добавлении элементов кешированные значения меры для новых поддеревьев пересчитываются, для нетронутых — остаются теми же. И всё это за O(log N). Потрясающе.
А теперь сузим немного определение меры. Пускай мы умеем измерять только каждый конкретный одиночный элемент дерева. Как теперь получать меру поддеревьев? Очень просто. Достаточно уметь комбинировать две меры между собой так, чтобы комбинация меры одного элемента с мерой другого давала меру множества их двоих. При этом этот процесс комбинирования должен быть ассоциативным, иначе наш алгоритм запроса будет получать неправильный ответы. Эти рассуждения приводят нас к естественному выводу: мерой может быть любая функция, результатом которой являются элементы моноида.
Мера «Максимум» — элементарная функция x с результатами в моноиде <Числа, max, -∞>.
Мера «Сумма квадратов» — элементарная функция x2 с результатами в моноиде <Числа, +, 0>.
Мера «Гистограмма частотности» — элементарная функция «100% для единственного данного символа» с результатами в моноиде <Гистограммы, комбинирование гистограмм с учётом количества символов, пустая гистограмма>. Читателю в качестве упражнения остаётся продумать полностью ассоциативную операцию комбинирования гистограмм частотности.
Опишу то, чего мы здесь только что добились, в коде. С этого момента хорошо бы переходить полностью на Haskell, ибо реализация все тех же идей на C# выглядит крайне уродливо и многосложно: так, дерево придется параметризовать тремя типовыми параметрами вместо двух!
Я приведу реализацию простого бинарного дерева без балансировки и собственно добавлений/склеек/разрезаний. Как реализуются эти операции, специфично для каждого конкретного вида сбалансированного дерева и потребовало бы отдельной статьи, что, как я уже говорил, не является моей целью. Читатель легко может представить на месте класса
Tree, например, FingerTree. Или несколько усложненный ImplicitTreap, в котором переписана соответствующая функция «восстановления справедливости» и учтено, что в вершинах дерева тоже хранятся данные, а потомки вершин дерева тоже могут быть пустыми (null).// Произвольный объект, который был измерен. public interface IMeasured<V> { V Measure { get; } } // Пример меры: тождественная функция на каждом элементе public class IdentityMeasure<T> : IMeasured<T> { public readonly T Data; public IdentityMeasure(T data) { Data = data; } public T Measure { get { return Data; } } } // T - тип элементов в листьях дерева // V - тип аннотаций в вершинах дерева // M - моноид, с помощью которого собирается мера и генерируются аннотации public class Tree<T, M, V> : IMeasured<V> where M: IMonoid<V>, new() where T: IMeasured<V> { public readonly T Data; // только для листьев public readonly Tree<T, M, V> Left; public readonly Tree<T, M, V> Right; private readonly V _measure; public V Measure { get { return _measure; } } public Tree(T data) // конструктор листа { Left = Right = null; Data = data; _measure = data.Measure; } public Tree(Tree<T, M, V> left, Tree<T, M, V> right) // конструктор вершины { Left = left; Right = right; Data = default(T); _measure = Singleton<M>.Instance.Append(left.Measure, right.Measure); } } // Дерево сумм, хранящее сумму на своих подотрезках public class SumTree : Tree<IdentityMeasure<int>, AddMonoid, int> { public SumTree(int data) // конструктор листа : base(new IdentityMeasure<int>(data)) {} public SumTree(SumTree left, SumTree right) // конструктор вершины : base(left, right) {} } // Дерево приоритетов, хранящее максимумы на своих подотрезках public class PriorityTree : Tree<IdentityMeasure<double>, MaxMonoid, double> { public PriorityTree(double data) // конструктор листа : base(new IdentityMeasure<double>(data)) {} public PriorityTree(PriorityTree left, PriorityTree right) // конструктор вершины : base(left, right) {} }
Кульминацией всех наших усилий в данном параграфе станет обобщённый метод для запроса меры подотрезка.
// Размер поддерева. // Не забыть добавить в конструктор вершины: Size = 1 + left.Size + right.Size; public readonly int Size = 1; public V MeasureOn(int start, int length) { if (start == 0 && length == Left.Size) return Left.Measure; if (start == Left.Size && length == Right.Size) return Right.Measure; if (start + length <= Left.Size) return Left.MeasureOn(start, length); if (start >= Left.Size) return Right.MeasureOn(start - Left.Size, length); var monoidV = Singleton<M>.Instance; var leftValue = Left.MeasureOn(start, Left.Size - start); var rightValue = Right.MeasureOn(0, length - (Left.Size - start)); return monoidV.Append(leftValue, rightValue); }
Новая ступень: предикаты
Можно ещё больше расширить класс операций, которые мы умеем выполнять на верёвке, параметризированной моноидом. Мы уже умеем выполнять запрос разнообразных мер на подотрезках. Но часто в жизни требуется не просто знать некоторое значение, а ещё и элементы, которые «самым главным образом» учавствуют в его создании.
Например, если мера — максимум элементов отрезка, то неплохо бы узнать, на каком именно элементе по счёту этот максимум достигается. К таким же операциям относится и наш старый добрый доступ по индексу. Все эти операции, как мы помним, описываются очень похожим алгоритмом — он линейно спускается от одной вершины дерева к другой, пока не достигнет нужного листа. Так вот, существует очень простой способ все такие операции обобщить.
Рассмотрим некоторый предикат p, то бишь булевую функцию одного произвольного аргумента.
Пускай у нас есть последовательность объектов
Будем последовательно вычислять префиксные суммы нашей последовательности. Это будет такая новая последовательность:
a1
a1 ⊗ a2
a1 ⊗ a2 ⊗ a3
…
a1 ⊗ a2 ⊗ a3 ⊗… ⊗ aN
Здесь "⊗", как мы и договаривались, — операция моноида. Для примера со строками это будет конкатенация.
Теперь вычислим значение предиката на всех этих префиксных суммах. Получим последовательность булевских значений.
И наконец, назовём предикат монотонным, если он на наших префиксных суммах сначала постоянно равен False, потом в некоторый момент меняет False на True, после чего остаётся равным True до конца последовательности.
Проще говоря, если заменить False на 0, а True на 1, то последовательность результатов предиката должна быть неубывающей.
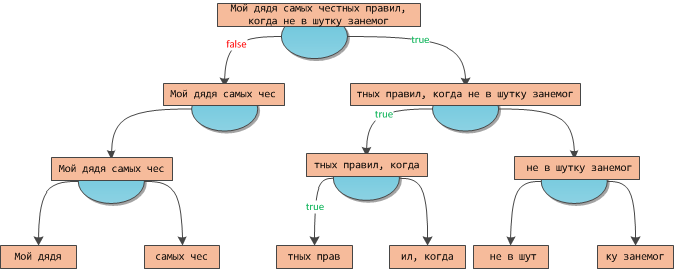
Я продемонстрирую это свойство на рисунке для моноида строк. Пусть p(s) = {s содержит
"прав" как подстроку}.В вершинах верёвки — закешированные значения меры, то есть конкатенации строк поддерева.
Алгоритм постоянно поддерживает два префикса: один без учета текущего левого сына, второй — включает его. В зависимости от значения предиката на этих префиксах можно постоянно верно определять, внутри какого поддерева произошёл «скачок».
Например, когда мы находились в корне верёвки, алгоритм увидел, что
"Мой дядя самых чес") = False"Мой дядя самых честных правил, когда") = TrueПо ходу спуска надо постоянно поддерживать корректное значение префикса, склеивая его с мерой текущего левого сына в случае спуска в правое поддерево.
В конце концов за логарифмическое число шагов мы доберемся до листа, в котором произошёл скачок. Внутри листового сегмента искать точное место скачка уже приходится отдельным способом, скорее всего последовательной проверкой. Впрочем, это может быть и не так тривиально: представьте себе вместо предиката «содержит данную подстроку» предикат «удовлетворяет данному регулярному выражению». Он тоже монотонный, но его вычисление требует некоторых усилий.
Для меры вида «сумма квадратов» и предиката «больше 256», к примеру, нам тоже потребовалось бы в листе отдельно вычислять квадраты каждого конкретного числа из сегмента, чтобы определить точную позицию скачка.
Кстати говоря. Если хранить в листах не сегменты со словами, а отдельные символы, то на основании данного алгоритма можно определить операцию split. Она разрезает дерево по монотонному предикату на два: в левом результате свойство предиката ещё не выполняется, а в правом — уже выполняется. Реализацию точного алгоритма split можно с чистой совестью оставить читателю как упражнение :)
Между прочим, в одном из последующих параграфов она нам таки пригодится.
Может показаться, что название операции разрезания по предикату путается с одноимённой операцией разрезания по ключу декартового дерева. На самом деле на данном этапе рассказа это уже не важно, поскольку мы давно уже отрешились от конкретной реализации верёвки и проблем выбора того или иного сбалансированного дерева. Сейчас о декартовых деревьях я уже упоминать попросту не собираюсь.
Зато теперь видно, что, к примеру, доступ к элементу под индексом i — это просто поиск в дереве по монотонному предикату «длина префикса > i». Длина префикса — это обыкновенная мера, мы использовали её как меру, когда хранили в вершинах размеры поддеревьев. У этой меры элементарная функция — тождественная единичка, а значения лежат в моноиде <Числа, +, 0>. Позиция №i — это именно та позиция, где длина префикса последовательности начинает превышать i.
Отборнейшие примеры
Итак, мы рассмотрели все основные преимущества, которые даёт нам такая концепция, как параметризация верёвки некоторым моноидом. Мы можем брать произвольные последовательности «измеримых» значений и комбинировать их друг за другом, для любого подотрезка получаемых последовательностей узнавая значение меры. Если нам будет интересно, можем узнать точную позицию достижения, разрезав полученную верёвку по некоторому монотонному предикату. И всё это за логарифмическое время, что даёт нам безграничный простор возможностей. Этот безграничный простор я и собираюсь сейчас применить на практике, показав вам три довольно нестандартных, очень жизненных и интересных моноида.
Пример №1: статистика
В этот раз мы манипулируем чем-то позанятнее скучных чисел, строк или булов. Объектом нашего пристального внимания станут… выборки.
Выборка, то есть конечный набор случайных значений из некоей генеральной совокупности, может быть измерима. Все знают основные характеристики выборки:
N — размер выборки.
M — среднее значение выборки.
V — дисперсия выборки, то есть среднее значение квадратов отклонения от среднего выборки.
Мы рассмотрим немасштабированную дисперсию, то есть просто сумму квадратов отклонения от среднего. При необходимости получить из неё настоящую можно элементарно, просто поделив число на N.
Я сказал абзацем ниже, что выборка «может быть измерима». Да, я не случайно употребил именно это слово :) Набор из этих трех базовых характеристик выборки может служить её мерой.
Стоп-стоп-стоп, скажете вы, какого это лешего набор из трёх малосвязанных чисел — элемент моноида? Какого вообще моноида-то? Надо как-то комбинировать выборки, получается? А как вообще?
Все это прекрасно делается. Пускай у вас есть две выборки A и B из одной генеральной совокупности. Вы сливаете эти выборки вместе, создавая совместную выборку X, чей размер — сумма размеров исходных. Тогда, как показал в 1979 году Tony Chan, можно вычислить среднее и немасштабированную дисперсию новой выборки по следующим формулам:
Очевидно, что не играет роли, в каком порядке смешивать вместе выборки — характеристики итоговой выборки будут одними и теми же. Таким образом, слияние выборок ассоциативно.
Остаётся формальности ради определить, что такое характеристики пустой выборки. Размер её, очевидно, 0, среднее в силу аддитивности тоже будет 0, а вот дисперсию определить удовлетворительно не получится. Впрочем, и не нужно — мы в наших деревьях дисперсии пустой выборки вообще касаться не будем.
Определение моноида статистических характеристик и всего, что из него следует, мне пришлось поместить на pastie.org, потому что ограничение Хабрахабра на размер статьи начинает несколько напрягать :)
Можно легко представить себе поток случайных величин, по которым движется «окно» размера K, т.е. нам постоянно нужно узнавать дисперсию и матожидание последних K величин. Создаётся дерево, из него последовательно убираются и добавляются элементы, как в очередь, а в корне дерева всегда лежат нужные нам вычисленные величины. Красота.
Пример №2: альфа-композиция изображений
Есть два полупрозрачных изображения (с альфа-каналом). Мы хотим определить оператор наложения двух изображений, более известный как альфа-композиция. С его действием знакомы все, кто когда-нибудь игрался с полупрозрачными изображениями в Photoshop.
Для каждого пикселя у изображений определено два параметра: цвет C и альфа-канал α. Задание формул для вычисления этих значений полностью и однозначно задаёт оператор наложения. Так вот, оказывается, что можно легко вывести математически следующие факты:
- Оператор наложения ассоциативен;
- Любое изображение с альфа-каналом, равным 0, служит для оператора наложения единицей.
За доказательством этих фактов и конкретными формулами отсылаю вас к соответствующей статье Википедии.
Таким образом, полупрозрачные изображения по операции альфа-композиции образуют моноид. Это даёт нам возможность обрабатывать гигантские наборы изображений, которые должны одно за другим накладываться друг на друга, с помощью соответствующего дерева.
Пример №3: регулярные выражения
К сожалению, объём, накладываемый Хабрахабром на статью, не дает мне возможности закончить её толково и подробно описать третий красивый моноид, а именно моноид переходных функций конечных автоматов для распознавания регулярных выражений. Его использование на верёвку позволяет создать инкрементальный лексер — структуру, которая позволяет производить над строкой быстрые модификации, и в любой момент времени давать моментальный ответ, где в строке матчится наперёд заданное регулярное выражение. За дальнейшими подробностями отсылаю вас к переводу оригинальной статьи Дэна Пипони и более подробной статье-реализации Евгения Кирпичева. Картинка-затравка:
А пока что всем спасибо за внимание.

