Предыстория
На хабре неоднократно упоминались различные инструменты и способы создания скриншотов WEB страниц.
Хочу поделиться собственным «велосипедом» для создания PDF на Python и QT, дополненным и улучшенным для централизованного использования несколькими проектами.
Изначально генерация запускалась из PHP скрипта, примерно так:
<?php // локальный файл exec('xvfb-run python2 html2pdf.py file:///tmp/in.html /tmp/out.pdf'); // или URL exec('xvfb-run python2 html2pdf.py http://habrahabr.ru /tmp/habr.pdf'); ?>
этого было достаточно и все было хорошо…
С чего все началось
Однако xvfb-run на время запуска создает DISPLAY :99 и при нескольких параллельных задачах «девочки ссорились» в логах, но как-то работали.
Благодаря xpra отпала необходимость каждый раз запускать обертку xvfb-run, появилась возможность многократно использовать виртуальный X, девочки помирились, накладные расходы сократились:
[user@rdesk ~]$ xpra start :99
И запускать стало возможно так:
<?php // локальный файл exec('DISPLAY=:99 python2 html2pdf.py file:///tmp/in.html /tmp/out.pdf'); // или URL exec('DISPLAY=:99 python2 html2pdf.py http://habrahabr.ru /tmp/habr.pdf'); ?>
Код приложения html2pdf.py, именно он создает браузер, загружает в него HTML и печатает его в PDF файл.
практически полный copy-paste найденный на просторах сети
#!/usr/bin/env python2 # -*- coding: UTF-8 -*- from PyQt4.QtCore import * from PyQt4.QtGui import * from PyQt4.QtWebKit import * import sys # примитивная проверка передаваемых параметров if len(sys.argv) != 3: print "USAGE app.py URL FILE" sys.exit() # основная процедура def html2pdf(f_url, f_name): # создаем QT приложение app = QApplication(sys.argv) # создаем "браузер" web = QWebView() # передаем URL для загрузки web.load(QUrl(f_url)) # создаем принтер printer = QPrinter() # размер листа printer.setPageSize(QPrinter.A4) # формат печати printer.setOutputFormat(QPrinter.PdfFormat) # выходной файл печати printer.setOutputFileName(f_name) # непосредственно печать содержимого "браузера" в PDF def convertIt(): web.print_(printer) QApplication.exit() # ждем сигнал от браузера, что страница загружена, после чего "печатаем" PDF QObject.connect(web, SIGNAL("loadFinished(bool)"), convertIt) sys.exit(app.exec_()) html2pdf(sys.argv[1], sys.argv[2])
Решение было вполне работоспособным, но с очевидным минусом — возможностью работать только с локальными документами. Масштабируемость сводилась к созданию полной копии окружения. Тем временем количество документов увеличивалось, росло и потребление ресурсов.
Назрела необходимость в централизованном решении.
Наращиваем мясо
Концепция
- Выделенный сервер
- Средство доставки задач для рендера
- Механизм обмена документами
- Общая логика системы
Средство доставки — уже был развернут rabbitmq поэтому логично было использовать имеющиеся ресурсы.
Обмен документами — передача исходных HTML на сервер рендера и получение результирующих PDF.
Почему HTML, а не просто «ходить по ссылке»: я не нашел способа отловить завершение загрузки страницы при наличии большого количества js подтягивающего динамический контент -> видны «часики» на результирующем PDF.
Как оказалось позднее в этом нет необходимости. На некоторые документы просто не существует внешних ссылок. Например есть документ А и Б, каждый состоит из 3х параграфов, есть 2 ссылки на полные документы, но реднерить нужно только Ап1 и Бп2. Позже прикрутили дополнительные стили, которые применялись при печати документа, превращаясь в «версию для печати» на лету.
FS, NFS, etc как хранилище промежуточных файлов — были отброшены сразу (увеличивается количество манипуляций при развертывании клиента).
Очевидным выбором был key-value storage. Почти идеально, подходил memcached, если бы не одно но — теряет все записи при перезапуске.
Выбор пал на стершего брата — Redis.
Прост, компактен, быстр, масштабируем, база хранится на диске, вкусные фичи вроде vm/swap
Общая логика — «Очевидное, лучше не очевидного» потому я использовал сквозной ID документа как в базе так и в очереди Rabbit:
ID задачи — Q_app1_1314422323.65 где:
Q от Queue
app1 — идентификатор проекта-источника
1314422323.65 Unix timestamp + ms
Результат: R_app1_1314422323.65 где:
R — Result
Архитектура
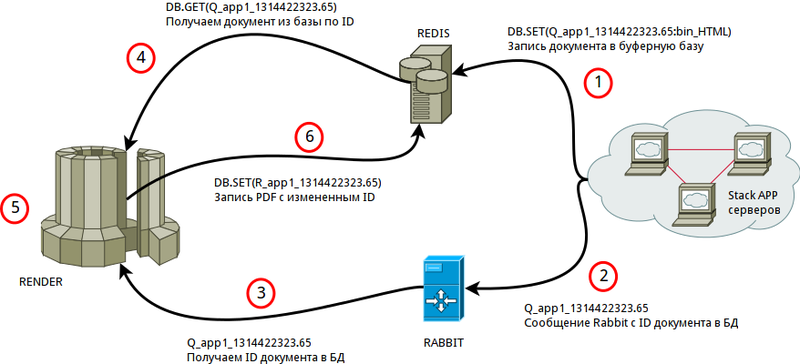
Описание маршрута:
- Поступает «заявка» на создание PDF, PHP записывает в базу HTML документ в бинарном формате, формирует ID
- После записи и проверки существования документа, происходит запись ID в очередь Rabbit
- Render получает новый ID
- Render забирает HTML документ из базы по ID
- Обработка документа (рендеринг)
- Запись PDF в базу с измененным ID, чистка базы от исходного HTML документа
Feedback окончания генерации не реализован.
Проекты самостоятельно обращаются к базе и проверяют результат
DB.EXISTS('R_app1_1314422323.65')
Реализация
Код сокращен для облегчения восприятия.
#!/usr/bin/env python2 # -*- coding: UTF-8 -*- import pika, os, time, threading, logging, redis, Queue RBT_HOST = 'rabbit.myhost.ru' RBT_QE = 'pdf.render' RDS_HOST = 'redis.myhost.ru' LOG = 'watcher.log' MAX_THREADS = 4 # подкручиваем формат лога logging.basicConfig(level=logging.DEBUG, format='%(asctime)-15s - %(threadName)-10s - %(message)s', filename=LOG ) def render(msg_id): # формируем имена временных файлов output_file = '/tmp/' + msg_id + '.pdf' input_file = '/tmp/' + msg_id + '.html' # получаем HTML из базы logging.debug('[R] Loading HTML from DB...') dbcon_r = redis.Redis(RDS_HOST, port=6379, db=0) bq = dbcon_r.get(msg_id) logging.debug('[R] HTML loaded...') # сохраняем HTML во временный файл logging.debug('[R] Write tmp HTML...') fin1 = open(input_file, "wb") fin1.write(bq) fin1.close() logging.debug('[R] HTML writed...') # формируем внешнюю команду рендера command = 'DISPLAY=:99 python2 ./html2pdf.py %s %s' % ( 'file://' + input_file, output_file ) # засекаем время выполнения t_start = time.time() sys_output = int(os.system(command)) t_finish = time.time() # считаем размеры входного и выходного файлов i_size = str(os.path.getsize(input_file)/1024) o_size = str(os.path.getsize(output_file)/1024) # формируем запись ститистики реднера в log dbg_mesg = '[R] Render [msg.id:' + msg_id + '] ' +\ '[rend.time:' + str(t_finish-t_start) + 'sec]' + \ '[in.fle:' + input_file + '(' + i_size+ 'kb)]' +\ '[ou.fle:' + output_file + '(' + o_size + 'kb)]' # пишем log logging.debug(dbg_mesg) # читаем PDF logging.debug('[R] Loading PDF...') fin = open(output_file, "rb") binary_data = fin.read() fin.close() logging.debug('[R] PDF loaded...') # меняем ID документа с Q_ на R_ msg_out = msg_id.split('_') msg = 'R_' + msg_out[1] + '_' + msg_out[2] # пишем PDF в базу logging.debug('[R] Write PDF 2 DB...') dbcon_r.set(msg, binary_data) logging.debug('[R] PDF commited...') # подчищаем (временные файлы, записи в БД) logging.debug('[R] DEL db record: ' + msg_id) dbcon_r.delete(msg_id) logging.debug('[R] DEL tmp: ' + output_file) os.remove(output_file) logging.debug('[R] DEL tmp: ' + input_file) os.remove(input_file) logging.debug('[R] Render done') # rets if not sys_output: return True, output_file return False, sys_output def catcher(q): ''' запускается в N потоков и мониторит очередь ''' while True: try: item = q.get() # ждём данные в очереди except Queue.Empty: break logging.debug('Queue send task to render: ' + item) render(item) # передаем данные рендеру q.task_done() # задача завершена # запуск logging.debug('Daemon START') # создание очереди TQ = Queue.Queue() logging.debug('Starting threads...') # создание пула потоков for i in xrange(MAX_THREADS): wrkr_T = threading.Thread(target = catcher, args=(TQ,)) wrkr_T.daemon = True wrkr_T.start() logging.debug('Thread: ' + str(i) + ' started') logging.debug('Start Consuming...') # основное тело, запускаем консьюмера, пишем в очередь try: connection = pika.BlockingConnection(pika.ConnectionParameters(host = RBT_HOST)) channel = connection.channel() channel.queue_declare(queue = RBT_QE) def callback(ch, method, properties, body): TQ.put(body) logging.debug('Consumer got task: ' + body) channel.basic_consume(callback, queue = RBT_QE, no_ack = True) channel.start_consuming() except KeyboardInterrupt: logging.debug('Daemon END') print '\nApp terminated!'
Немного статистики
На среднем железе, по современным меркам ProLiant DL360 G5 (8 ядер E5410@2.33GHz, 16Гб RAM)
получены результаты:
8 потоков, LA 120
Исходные HTML размером 10Кб...5Мб
~5000 генераций в минуту
Среднее время на документ — 5 секунд
Выявлена интересная зависимость (линейная) между размером исходного HTML и памятью для его обработки:
1Мб HTML = ~17Мб RAM
«Cтресс-тест на выносливость» при размере HTML 370Мб
Честно говоря ожидал падения в районе WebKit, как оказалось зря.
Документ был обработан без ошибок, получен PDF из ~28000 страниц и конечно мелочь, что на это ушло ~50 часов и ~12Гб RAM (:
Ссылки
Redis + Python
Rabbit + Pika
xpra
Код на GitHub

