Задачей лексического анализа является разбить входную последовательность (в моем случае код на языке «Паскаль») на слова и лексемы.
Для начала я создал 5 типизированных листов для хранения данных, а именно: идентификаторов, констант, ключевых слов, разделителей и свертки. Также необходим массив разделителей
и массив ключевых слов. Я ограничился одиннадцатью ключевыми словами, так как статья написана как начальный пример реализации лексического анализа языка «Паскаль» на языке C#.
Итак, массив ключевых слов:
На входе мы имеем путь к .txt-файлу с программой в переменной path. Считываем весь в файл в AllTextProgram и начинаем.
В цикле for берем последовательно каждый символ из AllTextProgram и отправляем его в метод Analysis. Отдельно я рассматриваю лишь два исключения. Первое – это апострофы, которые в моем случае встречаются при использовании ключевого слова «writeln». Если встречаем апостроф, то отходим от правил и идем по переменной AllTextPorgram, пока ни найдем второй апостроф. Второе – это комментарии в программе. Для последних я просто считаю число открывающихся и закрывающихся фигурных скобок и ожидаю пока разница ни будет равна нулю.
Казалось бы программа должна зациклиться, если последующий апостроф не найден или кол-во фигурных скобок не равно 0. Да, это верно, в этих циклах необходимо добавить дополнительные условия выхода из проверки. Эти условия для систематизации я решил сделать на этапе синтаксического анализа.
Переменная type отвечает за номер таблицы, к которому относится лексема.
Идентификаторы – таблица 1
Константы – таблица 2
Ключевые слова – таблица 3
Разделители – таблица 4
Теперь настало время поговорить что же происходит в методе Analysis. Это лучше сделать в виде комментариев к коду. Сразу отмечу, что в переменной temp будем хранить промежуточный результат работы, пока ни встретим разделитель. Встретив разделитель, нам необходимо отправить переменную temp в метод Result, чтобы определить к идентификатору, константе или ключевому слову относится нынешняя лексема.
Заключительным для рассматрения является методе Result, где мы определяем, что же мы нашли. В самом начале проверяем переменную temp на принадлежность к ключевым словам. Проверяем в начале, чтобы не перепутать найденную лексему с идентификатором. Если найденное не является ключевым словом, то через switch проверяем тип таблицы, определенный заранее в методе Analysis. Не зыбываем проверить, чтобы найденный идентификатор/константа/разделитель уже не значился в таблице.
И легкий пример, чтобы показать как это все работает.
На входе программа:
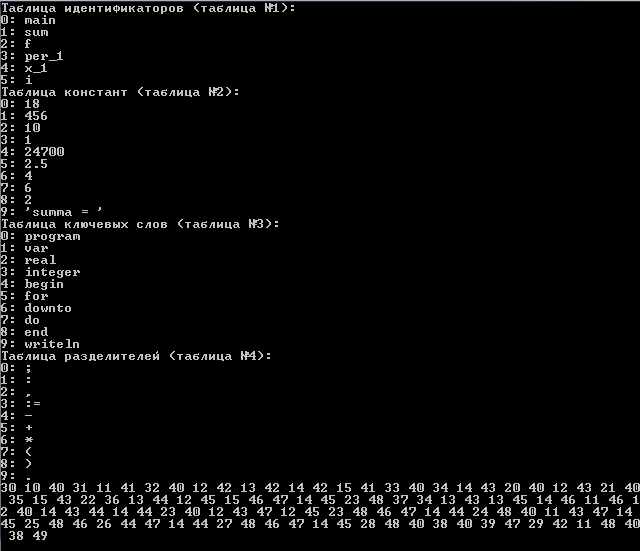
И результат работы:
Для начала я создал 5 типизированных листов для хранения данных, а именно: идентификаторов, констант, ключевых слов, разделителей и свертки. Также необходим массив разделителей
static char[] limiters = {',', '.', '(', ')', '[', ']', ':', ';', '+', '-', '*', '/', '<', '>', '@'};
и массив ключевых слов. Я ограничился одиннадцатью ключевыми словами, так как статья написана как начальный пример реализации лексического анализа языка «Паскаль» на языке C#.
Итак, массив ключевых слов:
static string[] reservedWords = { "program", "var", "real", "integer", "begin", "for", "downto", "do", "begin", "end", "writeln" };
На входе мы имеем путь к .txt-файлу с программой в переменной path. Считываем весь в файл в AllTextProgram и начинаем.
StreamReader sr = new StreamReader(path, Encoding.Default); AllTextProgram = sr.ReadToEnd(); sr.Close();
В цикле for берем последовательно каждый символ из AllTextProgram и отправляем его в метод Analysis. Отдельно я рассматриваю лишь два исключения. Первое – это апострофы, которые в моем случае встречаются при использовании ключевого слова «writeln». Если встречаем апостроф, то отходим от правил и идем по переменной AllTextPorgram, пока ни найдем второй апостроф. Второе – это комментарии в программе. Для последних я просто считаю число открывающихся и закрывающихся фигурных скобок и ожидаю пока разница ни будет равна нулю.
Казалось бы программа должна зациклиться, если последующий апостроф не найден или кол-во фигурных скобок не равно 0. Да, это верно, в этих циклах необходимо добавить дополнительные условия выхода из проверки. Эти условия для систематизации я решил сделать на этапе синтаксического анализа.
for (i = 0; i < AllTextProgram.Length; i++) { char c = AllTextProgram[i]; if (AllTextProgram[i] == '\'') { temp += '\''; i++; while (AllTextProgram[i] != '\'') { temp += AllTextProgram[i]; i++; } temp += '\''; type = 2; Result(temp); temp = null; } if (AllTextProgram[i] == '{') { int chet = 1; while (chet != 0) { i++; if (AllTextProgram[i] == '{') chet++; if (AllTextProgram[i] == '}') chet--; } } Analysis(AllTextProgram[i]); }
Переменная type отвечает за номер таблицы, к которому относится лексема.
Идентификаторы – таблица 1
Константы – таблица 2
Ключевые слова – таблица 3
Разделители – таблица 4
Теперь настало время поговорить что же происходит в методе Analysis. Это лучше сделать в виде комментариев к коду. Сразу отмечу, что в переменной temp будем хранить промежуточный результат работы, пока ни встретим разделитель. Встретив разделитель, нам необходимо отправить переменную temp в метод Result, чтобы определить к идентификатору, константе или ключевому слову относится нынешняя лексема.
static void Analysis(char nextChar) { int acsiiCode = (int)nextChar; // Получаем код символа // Проверяем относится ли код символа к буквам английского алфавита и знаку нижнего подчеркивания if (((acsiiCode >= 65) && (acsiiCode <= 90)) || ((acsiiCode >= 97) && (acsiiCode <= 122)) || (acsiiCode == 95) { if (temp == null) type = 1; temp += nextChar; return; } // Проверяем относится ли код символа к цифрам или к точке if (((acsiiCode >= 48) && (acsiiCode <= 57)) || (acsiiCode == 46)) { // Отдельная проверка, если код символа относиться к точке проверяем, чтобы в переменной temp // было число. Если в temp число, значит теперь // мы считаем его дробным, в противном случае это что-то другое if (acsiiCode == 46) { int out_r; if (!int.TryParse(temp, out out_r)) goto not_the_number; } if (temp == null) type = 2; temp += nextChar; return; } not_the_number: if ((nextChar == ' ' || nextChar == '\n') && temp != null) { Result(temp); temp = null; return; } // И последняя проверка на принадлежность к массиву разделителей. Не забываем о двойном разделителе «:=» и двойных условных разделителях. foreach (char c in limiters) { if (nextChar == c) { if (temp != null) Result(temp); type = 3; if (nextChar == ':' && AllTextProgram[i+1] == '=') { temp = nextChar.ToString() + AllTextProgram[i + 1]; Result(temp); temp = null; return; } if (nextChar == '<' && (AllTextProgram[i + 1] == '>' || AllTextProgram[i + 1] == '=')) { temp = nextChar.ToString() + AllTextProgram[i + 1]; Result(temp); temp = null; return; } if (nextChar == '>' && AllTextProgram[i + 1] == '=') { temp = nextChar.ToString() + AllTextProgram[i + 1]; Result(temp); temp = null; return; } temp = nextChar.ToString(); Result(temp); temp = null; return; } }
Заключительным для рассматрения является методе Result, где мы определяем, что же мы нашли. В самом начале проверяем переменную temp на принадлежность к ключевым словам. Проверяем в начале, чтобы не перепутать найденную лексему с идентификатором. Если найденное не является ключевым словом, то через switch проверяем тип таблицы, определенный заранее в методе Analysis. Не зыбываем проверить, чтобы найденный идентификатор/константа/разделитель уже не значился в таблице.
static void Result(string temp) { for (int j = 0; j < reservedWords.Length; j++) { if (temp == reservedWords[j]) { for (int i = 0; i < tableR.Count; i++) { if (temp == tableR[i]) { LConv.Add("3" + i); return; } } tableR.Add(temp); LConv.Add("3" + (tableR.Count - 1)); return; } } switch (type) { case 1: for (int j = 0; j < tableI.Count; j++) { if (temp == tableI[j]) { LConv.Add("1" + j); return; } } tableI.Add(temp); LConv.Add("1" + (tableI.Count - 1)); break; case 2: for (int j = 0; j < tableC.Count; j++) { if (temp == tableC[j]) { LConv.Add("2" + j); return; } } tableC.Add(temp); LConv.Add("2" + (tableC.Count - 1)); break; case 3: for (int j = 0; j < tableL.Count; j++) { if (temp == tableL[j]) { LConv.Add("4" + j); return; } } tableL.Add(temp); LConv.Add("4" + (tableL.Count - 1)); break; } }
И легкий пример, чтобы показать как это все работает.
На входе программа:
program main; { pro{g}am }
var sum: real;
f, per_1, x_1,i:integer;
begin
{sum:=(-x_1+2.5)*4 - (x_1-6)*((((x_1+2))));}
x_1:=18;
f:= 456;
for i:=10 downto per_1-f+i*(x_1+1) do
begin
per_1 := per_1 + x_1*sum*f;
x_1:=-x_1-1;
f:=(f+1)*(x_1-24700);
sum:=(x_1+2.5)*4 - (x_1-6)*(x_1+2);
end;
writeln('summa = ', sum);
end.И результат работы:

