Данная статья написана по следам статьи Steve Yegge. A portrait of a n00b (с подачи хабраперевода). Для меня основной посыл статьи прозвучал так — меньше комментариев, меньше классов, меньше методов, больше кода. Делайте код плотнее, не усердствуйте в моделировании. Мне сложно судить это видение мира, да и вообще вопрос комментариев как таковых больше умозрительный. Но вот что засело во мне стальной иглой, так это проблема тестирования такого плотного кода.
Чтобы обрисовать проблему, давайте рассмотрим небольшой пример. Допустим, у вас есть сервер и ему извне поступают команды. Вам необходимо написать логику обработки этих команд. Я бы смоделировал эту проблему как-то так:
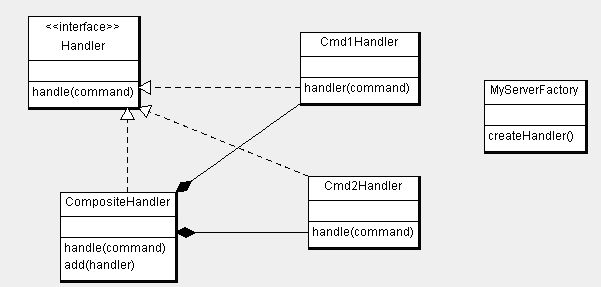
Почему именно так и столько: во-первых, мы придерживаемся принципа Code to Interface, что позволит нам, например, при тестировании сервера подделать (mock) обработчик команд; во-вторых, изолируя логику каждой команды в отдельном классе, мы можем легко протестировать эту логику. Вы можете подумать, почему бы нам просто не сделать один класс
Теперь попробуем подумать, как бы эта проблема была реализована в виде «плотного кода». Конечно, я не могу говорить и думать за автора, человека с 20-25 годами опыта. Возможно, он имеет в виду нечто другое. Но в данном контексте для меня уплотнение кода — это, например, спайка всех обработчиков в один класс. А ещё лучше в один метод:
А может быть, вообще не выносить в отдельный класс обработку команд? Просто поместить их прямо в сервер?
Как вы предполагаете это тестировать? Тут только интеграционные тесты могут хоть как-то спасти отца русской демократии. Возможно, автор имел в виду нечто совсем другое? Буду рад, если хабрагуру просветят меня и других «подростков» на эту тему.
В мультипарадигменных языках типа Lisp или Python ситуация несколько иная. Функции в них имеют тенденцию превращаться в многоуровневые наслоения map-filter-reduce.
Здесь, мне кажется, нет особого смысла выделять каждую операцию map, filter или reduce в отдельную функцию. Достаточно использовать хорошо протестированные предикаты вместо невменяемых лямбд, комментировать самые важные слои map-filter-reduce, а также хорошо тестировать конечные функции.
P.S. Оговорюсь, что я вполне допускаю плотную реализацию в императивных языках некоторых алгоритмов наподобие сортировки. Такие алгоритмы как жонглёры — нет никакого смысла жонглировать одним шаром, смысл появляется только при одновременном жонглировании множеством шаров (объектов, переменных и т.п.). Хотя тут тоже, мне кажется, бывают варианты.
Чтобы обрисовать проблему, давайте рассмотрим небольшой пример. Допустим, у вас есть сервер и ему извне поступают команды. Вам необходимо написать логику обработки этих команд. Я бы смоделировал эту проблему как-то так:
Почему именно так и столько: во-первых, мы придерживаемся принципа Code to Interface, что позволит нам, например, при тестировании сервера подделать (mock) обработчик команд; во-вторых, изолируя логику каждой команды в отдельном классе, мы можем легко протестировать эту логику. Вы можете подумать, почему бы нам просто не сделать один класс
Handler и в него добавить публичные методы для каждой команды и подвергать тестам эти методы, зачем городить кучу классов? Но, на мой взгляд, проблема в том, что функция класса в этом случае как-бы «размазывается» по классу, мы в каком-то смысле открываем внешнему миру ненужные ему подробности реализации нашего обработчика. Ведь всё, что сервер должен знать, это то, что данный класс может обработать любую команду, а не то, что он может обработать команду 1, команду 2 и команду 3.Теперь попробуем подумать, как бы эта проблема была реализована в виде «плотного кода». Конечно, я не могу говорить и думать за автора, человека с 20-25 годами опыта. Возможно, он имеет в виду нечто другое. Но в данном контексте для меня уплотнение кода — это, например, спайка всех обработчиков в один класс. А ещё лучше в один метод:
public class Handler {
public Result handle(Command command) {
if (command == COMMAND1) {
// perform logic 1
} else if (command == COMMAND2) {
// perform logic 2
}
// . . . .
else {
log.error("Don't know how to handle command " + command);
}
return result;
}
}
А может быть, вообще не выносить в отдельный класс обработку команд? Просто поместить их прямо в сервер?
public class Server {
public void converse(Socket client) {
int command;
while ((command = client.getInputStream().read()) != -1) {
if (command == COMMAND1) {
// perform logic 1
} else if (command == COMMAND2) {
// perform logic 2
}
// . . . .
else {
log.error("Don't know how to handle command " + command);
}
}
}
}
Как вы предполагаете это тестировать? Тут только интеграционные тесты могут хоть как-то спасти отца русской демократии. Возможно, автор имел в виду нечто совсем другое? Буду рад, если хабрагуру просветят меня и других «подростков» на эту тему.
В мультипарадигменных языках типа Lisp или Python ситуация несколько иная. Функции в них имеют тенденцию превращаться в многоуровневые наслоения map-filter-reduce.
Здесь, мне кажется, нет особого смысла выделять каждую операцию map, filter или reduce в отдельную функцию. Достаточно использовать хорошо протестированные предикаты вместо невменяемых лямбд, комментировать самые важные слои map-filter-reduce, а также хорошо тестировать конечные функции.
P.S. Оговорюсь, что я вполне допускаю плотную реализацию в императивных языках некоторых алгоритмов наподобие сортировки. Такие алгоритмы как жонглёры — нет никакого смысла жонглировать одним шаром, смысл появляется только при одновременном жонглировании множеством шаров (объектов, переменных и т.п.). Хотя тут тоже, мне кажется, бывают варианты.

