Забавно, но не нашёл на хабре упоминания об этом даже в комментариях. Пора устранить этот недостаток, ведь многие используют только хабр, как источник информации.
Так вот PHP 6 не будет, вообще. 11 марта 2010 команда разработчиков приняла решение об отмене выпуска PHP 6 в текущем его виде. В результате транк с PHP 6 был перенесён в бранч, а в транке образовалась новая версия — 5.4, в которую разработчики перенесли все наработки из PHP 6, кроме юникода.
Ниже приведен краткий пересказ презентации (pdf), сделанной Andrei Zmievski на PHP Community Conference в 2011 году.
Так а в чём проблема спросите вы? Есть mbstring, используй и радуйся.
А дело в том, что разработчики решили поддержать юникод не на уровне библиотеки, а на уровне ядра. Это означает, что любая php-функция, а также строковые операторы, в потенциале, могут принимать в себя юникод и более менее гарантировать, что юникод символы не будут исковерканы, удалены и не произойдёт ошибки. Кроме того, сам mbstring реализует далеко не все стандартные строковые функции.
Взгляните на следующий примеры:
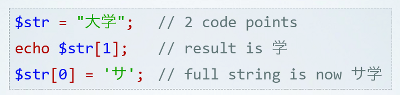
и

это максимально наглядные примеры того, что подразумевается под поддержкой на уровне ядра.
В результате выбор пал, на UTF-16 из-за библиотеки ICU. Надо отметить, что оглядываясь назад, разработчики заявили, что если бы им дали сделать выбор ещё раз, то они выбрали бы UTF-8, так как режим обратной совместимости снизил бы объём работы.
Во-первых: достаточно мало специалистов, которые понимают тонкости юникода и использования ICU.
Во-вторых: это технически сложная задача встроить юникод везде.
В-третьих: люди просто устали вставлять поддержку юникода и в без того прекрасно работающий код.
Поскольку в культуре PHP-разработчика принято фокусироваться на интересной работе, а поддержка юникода не является интересной работой, то проект выдохся.
Расширение mbstring неполноценно. Можно написать отдельный класс для работы с юникодом, но это также будет не полноценно. Поэтому как именно нужно поддерживать юникод в PHP сейчас всё ещё открытый вопрос.
Так вот PHP 6 не будет, вообще. 11 марта 2010 команда разработчиков приняла решение об отмене выпуска PHP 6 в текущем его виде. В результате транк с PHP 6 был перенесён в бранч, а в транке образовалась новая версия — 5.4, в которую разработчики перенесли все наработки из PHP 6, кроме юникода.
Ниже приведен краткий пересказ презентации (pdf), сделанной Andrei Zmievski на PHP Community Conference в 2011 году.
Но для начала рассмотрим как юникод поддерживается сейчас
- В исходном коде:
- Можно использовать в названии функций и переменных нелатинские символы, попадающие под регулярку [a-zA-Z_\x7f-\xff][a-zA-Z0-9_\x7f-\xff]*. Следующий код абсолютно валиден:
function привет(){} - Нормально обрабатываются документы с UTF-8 BOM, но только если нет пустых строк, иначе произойдёт отправка заголовков. Чтобы избежать этого рекомендуется держать HTML-код в шаблонах, а в самих PHP-файлах не использовать закрытие PHP-тега ?>
- Можно использовать в названии функций и переменных нелатинские символы, попадающие под регулярку [a-zA-Z_\x7f-\xff][a-zA-Z0-9_\x7f-\xff]*. Следующий код абсолютно валиден:
- При обработке строк:
- Стандартные строковые функции, нормально переваривают как минимум UTF-8, но с символами работать не умеют, поэтому такие вещи как определение позиции символа или размера строки будут работать не правильно.
- Стандартное расширение xml умеет перегонять текст из UTF-8 в ISO-8859-1 и обратно, но по сути это бесполезный функционал.
- Расширение mbstring (Multibyte String), которое поддерживает большинство кодировок, включая юникодовые. Правда обычно оно не включено по умолчанию.
- Стандартные строковые функции, нормально переваривают как минимум UTF-8, но с символами работать не умеют, поэтому такие вещи как определение позиции символа или размера строки будут работать не правильно.
Общий смысл презентации
Что хотелось иметь
Так а в чём проблема спросите вы? Есть mbstring, используй и радуйся.
А дело в том, что разработчики решили поддержать юникод не на уровне библиотеки, а на уровне ядра. Это означает, что любая php-функция, а также строковые операторы, в потенциале, могут принимать в себя юникод и более менее гарантировать, что юникод символы не будут исковерканы, удалены и не произойдёт ошибки. Кроме того, сам mbstring реализует далеко не все стандартные строковые функции.
Взгляните на следующий примеры:
и
это максимально наглядные примеры того, что подразумевается под поддержкой на уровне ядра.
Выбор кодировки
- UTF-8 — Достоинства: обратная совместимость в ASCII, преобладающая кодировка в вебе, есть много библиотек, поддерживающих её.
- UTF-16 — Достоинства: внутренняя кодировка библиотеки ICU, которая была выбрана для юникода и используется крупными игроками в вебе.
- UTF-32 — Достоинства: прямая индексация.
В результате выбор пал, на UTF-16 из-за библиотеки ICU. Надо отметить, что оглядываясь назад, разработчики заявили, что если бы им дали сделать выбор ещё раз, то они выбрали бы UTF-8, так как режим обратной совместимости снизил бы объём работы.
Что пошло не так
Во-первых: достаточно мало специалистов, которые понимают тонкости юникода и использования ICU.
Во-вторых: это технически сложная задача встроить юникод везде.
В-третьих: люди просто устали вставлять поддержку юникода и в без того прекрасно работающий код.
Результат
Поскольку в культуре PHP-разработчика принято фокусироваться на интересной работе, а поддержка юникода не является интересной работой, то проект выдохся.
Будущее
Расширение mbstring неполноценно. Можно написать отдельный класс для работы с юникодом, но это также будет не полноценно. Поэтому как именно нужно поддерживать юникод в PHP сейчас всё ещё открытый вопрос.
Выученные уроки
- Переписывать очень много работающего кода — трудно.
- Заставлять людей делать утомительные вещи — трудно.
- Ожидать результаты от вышеописанной деятельности, длящейся долгое время — трудно.
- Будьте преданны (stay committed).

