 Неделю назад утекла база хешей с LinkedIn, для других это событие может быть примечательным само по себе, но для меня, в первую очередь, это означает возможность провести анализ современных возможностей взлома паролей. И я не собираюсь рассказывать о том сколько раз слово «password» было встречено среди паролей и о том, сколько времени занимает перебор шестисимвольных комбинаций. Скорее буду пугать пользователей тем, насколько сложные пароли можно «взломать» за несколько часов. А программистам расскажу как это возможно эффективно реализовать, и в качестве небольшого подарка приложу программу, которую я написал для массового аудита. Присутствует и некоторый ликбез по использованию радужных таблиц с простыми выводами.
Неделю назад утекла база хешей с LinkedIn, для других это событие может быть примечательным само по себе, но для меня, в первую очередь, это означает возможность провести анализ современных возможностей взлома паролей. И я не собираюсь рассказывать о том сколько раз слово «password» было встречено среди паролей и о том, сколько времени занимает перебор шестисимвольных комбинаций. Скорее буду пугать пользователей тем, насколько сложные пароли можно «взломать» за несколько часов. А программистам расскажу как это возможно эффективно реализовать, и в качестве небольшого подарка приложу программу, которую я написал для массового аудита. Присутствует и некоторый ликбез по использованию радужных таблиц с простыми выводами.И так, за час удалось «восстановить» около 2.5 миллионов паролей на средней рабочей конфигурации, без специальных словарей и радужных таблиц. Среди найденных паролей присутствуют 16-символьные алфавитно-цифровые комбинации, и далеко не в единственном экземпляре.
Но начнем по порядку. Представьте, что вам попадается база из 6.5 миллионов пресных хешей (уникальных всего 5 787 239), какие способы восстановить максимальное количество паролей за разумное (скажем 7 дней) время существуют?
- Радужные таблицы;
- Прямой перебор;
- Атака по словарям (с правилами);
- Частотный анализ.
Небольшой ликбез. Многие верят в чудесные свойства радужных таблиц, якобы они «что-то способное сломать все и сразу». Это огромное заблуждение, более того, для массового аудита (тысячи или миллионы хешей) они непригодны вовсе. Поэтому забудьте фразу «взломщик же может сгенерировать радужную таблицу!».
Почему? Возьмем набор хиленьких радужных таблиц размером в сотню гигабайт, которые способны с вероятностью в 98% восстановить любой пароль до 8 алфавитно-цифровых символов одного регистра. К слову, такие таблицы можно сгенерить где-то за пару месяцев на довольно-таки мощной машине, но пусть они у нас уже будут, как некий божественный дар.
Время, необходимое на поиск пароля к одному хеш-значению по таким таблицам — около минуты. За это время необходимо выполнить chain_length операций хеширования, редукции и поиска по тем самым 100Gb.
Возможности оптимально искать сразу несколько паролей к разным хеш-значениям — не существует; для каждого хеша требуется строить отдельную радужную цепочку и искать ее в таблице. Таким образом, нам понадобится примерно 5.7 миллионов минут на поиск.
Это где-то 10 лет. Поэтому, наш божественный дар в данном случае нельзя считать и скромным подарком.
Однако хороший набор радужных таблиц поможет восстановить пароль к одному хеш-значению за минуты (при учете тех же скромных ограничений в 8-9 символов длины).
Прямой перебор же несколько отличается от радужных таблиц для массового взлома — он легко оптимизируется на предмет поиска перебираемых значений в больших наборах хеш-значений.
Нужно взять каждую строчку из набора {a..z0..9}^8, посчитать ее хеш, и поискать в базе хеш-значений, которые в данном случае LinkedIn заботливо нам предоставил.
И поиск — операция, которую в данном случае довольно легко оптимизировать. Забегая вперед, в своей программе я добился O(1) поиска даже на таких больших базах.
В основе поиска лежит простая фильтрация, — не пытаться искать те хеши, которые мы заведомо не найдем. Создаем массив битовых значений (checkup) размером SIZE, где-то сотню мегабайт и строим функцию, которая отображает хеш-значение в индекс этого массива. Как ни странно, такой объект тоже называется хеш-функцией, только не криптографической, и частенько его называют сверткой. Для каждого хеша из LinkedIn мы вычисляем свертку, и записываем «1» в соответствующие биты массива checkup.
При переборе, считаем от полученного значения свертку == j, смотрим checkup[j], если там 0, то смысла искать такое значение в наборе нет (это проверяется за O(1)). Иначе — используем двоичный поиск, который справляется уже за O(log(N)).
Если вернуться к цифрам, то прямой перебор с подобной оптимизацией займет около месяца на том же железе, или несколько дней на видеокартах.
То есть, для массового взлома даже прямой перебор выгоднее таблиц!
Но мы бы хотели справиться и с паролями длиннее 8 символов и на помощь нам приходят словари. Словари это очень круто! Они содержат те пароли, которые уже были чьими-то, и вероятность оказаться среди наших — у них гораздо выше, чем у случайных строчек. А если еще и добавить некоторый набор правил замены — то можно творить чудеса. При этом скорость такого перебора будет сравнима со скоростью прямого перебора.
Но есть один недостаток — словари должны откуда-то взяться. То есть выборка слов не должна быть случайной, а должна быть следствием некоторого анализа. И скачав словарь с просторов Глобальной Сети, вы можете получить полное «барахло», эффективность перебора по которому будет ниже прямого перебора (я вот, например, специально впишу туда строки, которые вряд ли кто-то поставит как пароль).
Сделай сам
Вот мы и подошли к оптимальной на мой взгляд стратегии массового взлома, связанной с частотным анализом. И нам вообще ничего не понадобится кроме слитого списка хешей.
Шаг первый. Запускаем прямой перебор по набору всех символов, которые возможно ввести с клавиатуры, длиной до 5-6 символов. В сущности, у нас нет задачи получить все пароли такой длины, просто хочется получить некоторое количество, сотни тысяч — для дальнейшего анализа. Если 6 символов — слишком короткая длина, то можно взять 7-8, опять же, нам не требуется исчерпать весь диапазон для перебора.
Главное, чтобы поработало минут 5-10.
Итак, мы нашли некоторые пароли. Теперь можно провести частотный анализ, выделив наиболее вероятные комбинации символов, идущих подряд. Например, «pass» одна из таких комбинаций, а на LinkedIn и «link» тоже.
Шаг второй. Запускаем перебор по конкатенации словаря частых комбинаций самого с собой. Сейчас я просто напоминаю, но если суть не ясна, рекомендую почитать мою предыдущую заметку.
Пусть тоже поработает минут 5-10, и заметьте, находить пароли оно будет гораздо резвее, чем в прошлый раз.
И шаг третий. Набрав «критическую массу» найденных паролей, скажем десятую часть от всех, повторяем частотный анализ и снова запускаем перебор, по полученным словарям. Теперь уже можно не останавливать — он свое дело сделает.
На настоящий момент перебор у меня работает уже часа два без остановки, и находит «на глаз» где-то 50-100 паролей в секунду.
А вот пример полученного словаря: dl.dropbox.com/u/243445/md5h/relevant.txt
Вы можете проверить безопасность своего пароля, попытавшись «собрать его из кусочков» словаря.
Если достаточно четырех или меньше кусочков — он плохой, меняйте.
Что удалось «сломать»
linkedinmel1234, andrea71103245, hockey101155239, magmag624222, carlito5657224, linda@790212, supercow779212, jesus143mary143, linkedin#239133, linkedinpassword123, thepassword1776000, 13051987159000, meatballstew123, latenightbreeze, whatthedillyo, friendofkellyg, hannah11emily9, linkedin7barry5, linkedin.passwd, linkedinrocksforeva, philip23marcus, 54fordpickup, nabe1959@, ge0rgin@, #1dust67, logic123tree456, ramgopal@123456, Jk971423, tiger!376400, ...
UPD вот скрин с посчитанной статистикой для найденных паролей (могу обсчитать еще какие-нибудь параметры, если нужны):
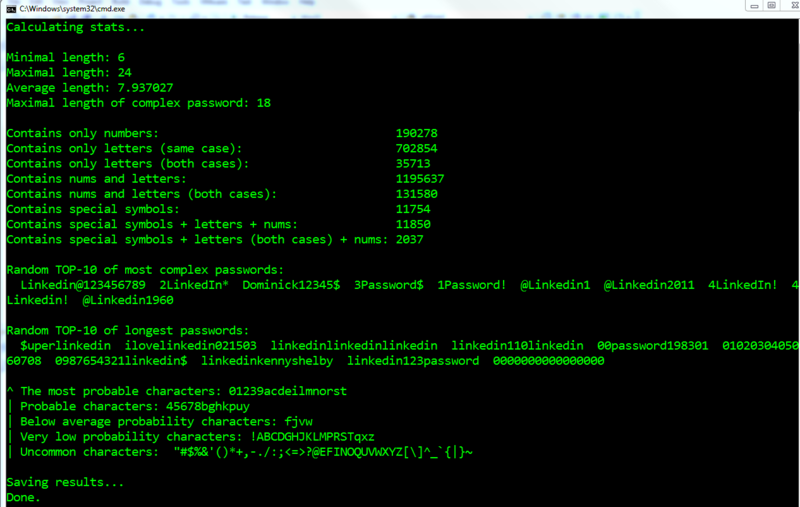
Мы видим, что не спасает ни длина пароля, ни использование спец-символов, ни комбинации регистров и цифр, ни случайность.
Программа
Как и обещал — вот программа, которой удалось это сделать. И кстати, вы свободны в попытках повторить результат (или добиться лучшего).
Исходники: dl.dropbox.com/u/243445/md5h/src.7z
Бинарник: dl.dropbox.com/u/243445/md5h/MD5BLAST.exe
Не удивляйтесь, что он называется MD5-, а не SHA- ибо, в качестве заготовки я взял свою программу, о которой уже рассказывал.
Все так же необходим CUDA Toolkit: developer.nvidia.com/cuda-toolkit-32-downloads#Windows
Скорость перебора по словарям для SHA1 на GTX460 при наличии 5.7 млн уникальных хешей в списке — более 60 mpwd/s. И не ругайте «низкую» скорость — это же:
* SHA1;
* 5.7 миллионов хешей для поиска;
* конкатенация словаря из строк произвольной длины.
Аналогов с более высокой скоростью для данной задачи пока все равно нет.
Чтобы запустить перебор нужно сохранить хеши в файле hash_list.txt, словарь в файл words.txt и вызвать:
MD5Blast words.txt 3 0.0где 3 — максимальная степень (количество конкатенаций словаря), а 0.0 — начальный прогресс в процентах.
Для шага 1 из вышеописанной схемы, в words.txt должны быть все вводимые с клавиатуры знаки, по одному на каждую строчку:
a
b
c
...
Чтобы получить список релеватных комбинаций:
MD5Blast _found.txt relevant.txt 1.0 4.0 16.0где первый файл — исходный для анализа, второй — для записи результатов (да, немного не Unix-way),
а оставшиеся три параметра — адаптивные пороги частоты для двух, трех, и четырехсимвольных комбинаций соответственно (выше число — меньше комбинаций в результате, с ними можно экспериментировать).
Небольшие выводы
- Радужные таблицы при массовом взломе — бесполезны;
- Длина пароля, наличие спецсимволов, его бессмысленность, разные регистры — по отдельности не составляют безопасность;
- Хешировать пароли без использования соли — все равно что хранить половину из них в открытом тексте (учимся на своих ошибках);
- Частотный анализ позволяет генерировать неплохие словари «из ничего».

