При использовании средств параллельных вычислений весьма вероятно может сложиться ситуация, когда алгоритм содержит два таких последовательных этапа: i) каждый j-ый поток сохраняет некоторый промежуточный результат вычисления в j-ой ячейке памяти, а, затем, ii) этот поток должен использовать результаты одного или более «соседних» потоков. Очевидно, что необходимо организовать в коде программы некий барьер по времени, который каждым потоком преодолевается уже после того, как все сохранят свои промежуточные результаты в соответствующих ячейках памяти (этап (i)). В противном случае, какой-то поток может перейти к этапу (ii), пока какие-то другие потоки еще не завершили этап (i). Как это ни прискорбно, но создатели CUDA посчитали, что такой специальный встроенный механизм синхронизации любого числа потоков на одном GPU не нужен. Так как же можно бороться с этой напастью? Хотя Google, судя по подсказкам, и знаком с данным вопросом, но готового удовлетворительного рецепта под свою задачу найти не удалось, а на пути к достижению желаемого результата для новичка (которым я и являюсь) имеются некоторые подводные камни.
Для начала, позволю себе на основе официальной документации [1,2] и слайдах [3,4], материалах различных сторонних сайтов [5-11] напомнить общую картину, с которой сталкивается программист при использовании CUDA. На самом высоком уровне абстракции он получает параллельную вычислительную систему с архитектурой SIMT (Single-Instruction, Multiple-Thread) — одна команда параллельно выполняется множеством более-менее независимых потоков (threads). Совокупность всех этих потоков, запущенных в рамках одной задачи (см. Рис.1), носит название grid.
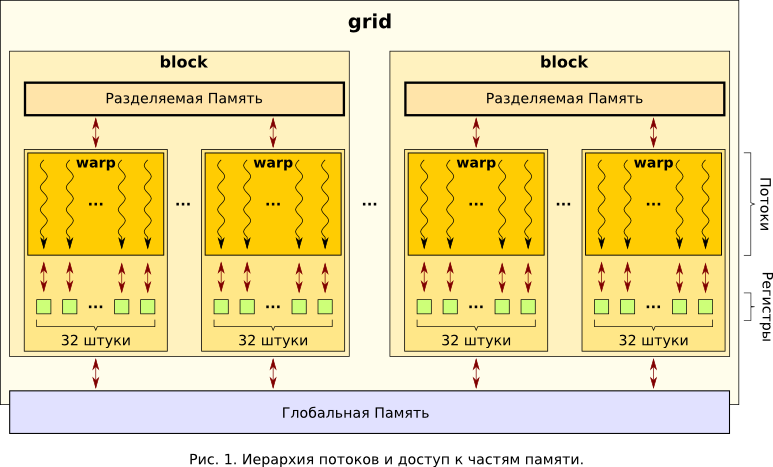
Параллельность исполнения grid`а обеспечивается, в первую очередь, наличием на видеокарте большего количества идентичных скалярных процессоров (scalar processors), которыми, собственно, и выполняются потоки (см. Рис.3). Физически (см. Рис.2), скалярные процессоры являются частями потоковых мультипроцессоров (streaming multiprocessors — SM).

Например, в моей Tesla есть 30 SM, в каждом из которых по 8 скалярных процессоров. Однако, на этих 240 ядрах можно запускать grid`ы из существенно большего числа потоков(1) благодаря аппаратным механизмам разделения доступных ресурсов (как рабочего времени этих ядер, так и доступной памяти). А некоторые особенности реализации как раз этих механизмов и определяют методику синхронизации потоков при доступе к общей для них памяти.
Одной из таких важных особенностей является группировка потоков по 32 штуки в warp`ы, которые оказываются частями более крупных образований — блоков (blocks). Все потоки каждого блока (например, для моей Tesla блок может содержать максимум 512 потоков(1)) запускаются строго на одном SM, поэтому имеют доступ только к его ресурсам. Однако, на одном SM может запускаться более одного блока (см. Рис.3), и ресурсы будут разделятся между ними поровну.

В каждом SM существует блок управления, который занимается распределением ресурса процессорного времени. Делается это так, что в каждый момент времени все ядра одного SM исполняют строго один warp. А по его завершению хитрым оптимальным способом выбирается следующий warp, приписанный к данному SM. Таким образом оказывается, что потоки одного warp`а синхронизируются за счет аппаратной особенности CUDA и исполняются по еще более близкому к SIMD (Single Instruction, Multiple Data) методу. Но потоки даже одного блока из разных warp`ов могут оказаться заметно рассинхронизированными.
Другой, не менее важной особенностью, является организация памяти в CUDA и доступа потоков к её различным частям. Наивысшей степенью общедоступности для потоков обладает глобальная память (global memory), физически реализованная в виде интегральных микросхем, запаянных на плате графического адаптера — та самая видеопамять, которая ныне исчисляется уже гигабайтами. Расположение вне процессора делает этот тип памяти наиболее медленным, по сравнению с другими, предоставляемыми для вычислений на видеокарте. Меньшим «градусом общедоступности» обладает разделяемая память (shared memory): расположенный в каждом SM блок (см. Рис.2), обычно размером в 16KB(1), доступен только тем потокам, которые выполняются на ядрах этого SM (см. Рис.1, Рис.3). Так как к параллельному исполнению на одном SM может быть отведено более одного блока, то весь доступный в SM объем разделяемой памяти распределяется между этими блоками поровну. Необходимо упомянуть, что разделяемая память физически расположена где-то очень близко к ядрам SM, поэтому обладает высокой скоростью доступа, сравнимой с быстродействием регистровой (registers) — основным видом памяти. Именно регистры могут служить операндами элементарных машинных команд, и являются наиболее быстрой памятью. Все наличные регистры одного SM поровну разделяются между всеми потоками, запущенными на этом SM. Группа регистров, выделенная в пользование какому-либо потоку, доступна ему и только ему. На правах иллюстрации мощи CUDA (или, наоборот, масштабов бедствия): в той же Tesla каждый SM предоставляет в пользование 16384 штук 32-х разрядных регистров общего назначения(1).
Из всего сказанного выше, можно сделать вывод, что взаимодействие между потоками одного блока следует стараться осуществлять через их общую быструю разделяемую память, а между потоками двух различных блоков — только с использованием глобальной памяти. Тут и возникает обозначенная во введении проблема: слежение за актуальностью данных в общедоступной разным потокам для чтения и записи области памяти. Иначе говоря — проблема синхронизации потоков. Как уже отмечалось, в рамках одного блока потоки каждого warp`а синхронизированы между собой. Для синхронизации потоков блока вне зависимости от принадлежности к warp`ам существует несколько команд барьерного типа:
Первая команда ставит единый барьер для всех потоков одного блока, три остальные — для каждого потока свой независимый барьер. Чтобы синхронизировать потоки всего grid надо будет придумать что-то еще. Прежде рассмотрения этого «еще», конкретизируем задачу, чтобы можно было привести пример осмысленного Си-кода.
Итак, конкретнее рассмотрим следующий пример. Пусть в глобальной памяти адаптера выделены два участка: под массивы X[] и P[] по 128 элементов. Пусть массив X[] записывается с хоста (центральным процессором из оперативной памяти компьютера). Создадим grid из двух блоков по 64 потока в каждом — то есть всего 128 потоков (см. Рис.4).

Теперь может быть выполнен этап (i): каждый поток с номером j будет складывать между собой все элементы массива X[], записывая результат в P[j]. Далее должен быть выполнен этап (ii): каждый j-ый поток начнет суммирование всех элементов массива P[], записывая их в соответствующие X[j]. Конечно, использовать CUDA для параллельного выполнения 128 раз одного и того же бессмысленно, но в реальной жизни каждый поток будет имеет свой набор весовых коэффициентов, с которыми происходит суммирование, а преобразования X->P и обратно, P->X — происходить многократно. В нашем же примере выбираем коэффициенты равными единицы — для наглядности и простоты, что не нарушит общности.
Перейдем от теории к эксперименту. Алгоритм весьма прозрачен, и человек, никогда не имевший дело с многопоточностью, сразу же может предложить такой код CUDA-ядра:
Многократное выполнение этого ядра покажет, что массив P[] раз от раза буде�� один и тот же, а, вот, X[] иногда могут различаться. Причем, если различие есть, то оно будет не в одном каком-то элементе X[j], а в группе из последовательных 32-х элементов! При этом индекс первого элемента в ошибочном блоке будет кратен также 32 — это как раз проявление синхронизации в тех самых warp`ах и некоторой рассинхронизированности потоков разных warp`ов. Если ошибка произошла в каком-то потоке, то она же будет у всех остальных его warp`а. Если применить предложенный разработчиками CUDA механизм синхронизации
то мы добьемся того, что каждый поток блока будет давать одинаковый результат. И если где-то он будет ошибочен — то у всего блока. Таким образом, остается как-то синхронизировать разные блоки.
К сожалению, мне известно только два метода:
Первый вариант мне понравился не очень сильно, в связи с тем, что в моей задаче вызывать такие ядра надо часто (тысячи раз), а есть основания опасаться наличия дополнительных задержек на сам старт ядра. Хотя бы потому, что в начале каждого ядра нужно подготовить некоторые переменные, обработать аргументы функции-ядра… Логичнее и быстрее будет это сделать один раз в «большом» ядре, а затем не вмешивать CPU, оставив графический адаптер вариться в соку из данных в собственной памяти.
Что касается второго вариант с системой флагов, то подобный механизм упоминается и в разделе «B.5 Memory Fence Functions» в [1]. Однако, там рассматривается немного другой алгоритм работы ядра. Для реализации синхронизации блоков введем две функции: первая будет подготавливать значения счетчика отработавших блоков, а вторая будет играть роль барьера — задерживать каждый поток до тех пор, пока не отработают все блоки. К примеру, эти функции и ядро, их использующее, могут выглядеть так:
Вот, вроде, и все. Флаг завели, функции написали. Остается сравнить производительность первого и второго методов. Но, к сожалению, функция SyncWholeDevice() счетчик инкрементировать будет, а вот барьерную задержку не обеспечит. Казалось бы, почему? Ведь цикл while есть. Тут как раз мы и подплываем к упомянутому в абстракте подводному камню, который становится виден: если взглянуть на генерируемый компилятором nvcc ptx-файл [12-14], то оказывается, что он любезно выкидывает с его точки зрения пустой цикл. Заставить компилятор не оптимизировать цикл таким образом можно как минимум двумя способами.
Непременно рабочим окажется явная вставка на ptx-ассемблере. К примеру, такая функция, вызовом который следует заменить цикл while:
Другой, синтаксически более изящный способ — это использование спецификатора volatile при объявлении флага-счетчика. Это сообщит компилятору о том, что переменная в глобальной (или разделяемой) памяти может быть изменена любым потоком в любое время. Следовательно, при обращении к этой переменной необходимо отключать всякую оптимизацию. В коде будет необходимо изменить всего две строчки:
Проведем теперь грубую теоретическую оценку производительности двух методов синхронизации блоков. Поговаривают, что вызов ядра занимает ~10мкс — это цена синхронизации многократным вызовом ядер. В случае синхронизации введением барьера из цикла, ~10 потоков (смотря сколько блоков) инкрементируют и читают в цикле одну ячейку в глобальной памяти, где каждая операция ввода/вывода занимает порядка 500 тактов. Пусть таких операций каждый блок проводит 3. Тогда на операцию синхронизации будет тратиться примерно 10*500*3 = 1.5*10^4 тактов. При частоте ядер 1.5ГГц пол��чаем 1.0*10^(-5)cек = 10мкс. То есть порядок величин один и тот же.
Но, конечно же любопытно взглянуть на результаты хоть каких-нибудь тестов. На Рис.5 читатель поста может видеть сравнение потраченного времени на выполнение 100 последовательных преобразований X->P->X, повторенных 10 раз для каждой конфигурации grid`а. Повторение 10 раз делается для усреднения времени, требуемого для 100 преобразований(2).
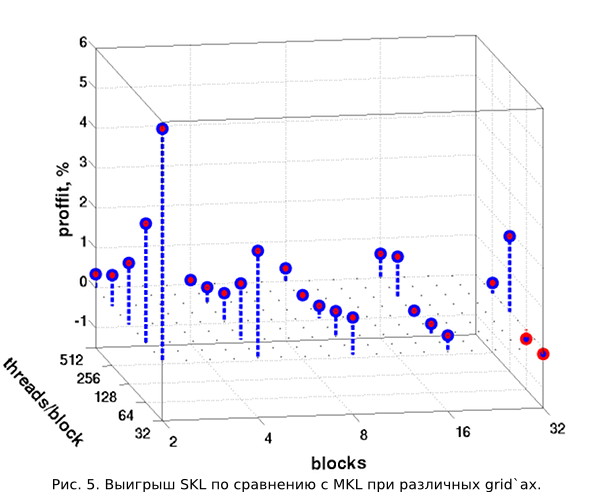
В горизонтальной плоскости отложены число запускаемых блоков и число потоков, в каждом из них. По вертикальной оси откладывается выигрыш по времени в процентах для метода «один вызов ядра, барьеры внутри» (назовем SKL — single kernel launch) относительно метода «многократный вызов ядер»(MKL — multi kernel launch). Хорошо видно, что выигрыш на рассматриваемых конфигурациях grid`а хоть и весьма мал, но почти всегда положителен. Однако, чем больше становится блоков, тем метод MKL отстает по производительности все меньше. Для 32-х блоков он даже незначительно обыгрывает метод SKL. Связано это с тем, что чем больше блоков, тем больше больше потоков (имеющих threadIdx.x == 0) читают переменную count из медленной глобальной памяти. А никакого механизма «один раз прочел, отдал значение всем потокам» нет. Если же рассматривать изменение относительной производительности в зависимости от числа потоков в блоке, при постоянном количестве самих блоков, то тоже можно заметить некоторую закономерность. Но тут работают неизвестные автору эффекты, связанные с синхрони��ацией потоков в блоке, управлением warp`ами в SM. Поэтому от дальнейших комментариев воздержимся.
Интересно взглянуть и на производительность при неизменном числе работающих потоков (1024), но разном их разделении на блоки. На Рис.6 как раз приведены графики перенормированного времени, потраченного на 100*10 вышеупомянутых преобразований для двух методов (MKL и SKL).

По сути, это диагональный «срез» на Рис.5. Хорошо видно, что сперва, при более крупных блоках, производительность обоих методов синхронизации растет одинаково. О таком эффекте разработчики CUDA предупреждают в официальной документации [2], но автор, опять же к сожалению, не владеет подробностями механизмов этого явления. Сокращение же разрыва и даже проигрыш метода SKL при наиболее мелком разделении на блоки связан, как уже говорилось, с увеличением числа считываний переменной count.
Необходимо отметить, что тесты проводились при реализации метода SKL через замену цикла while ptx-ассемблерной вставкой. Применение же спецификатора volatile иногда (в зависимости от конфигурации grid`а) замедляет процесс, а иногда — ускоряет. Величина замедления достигает 0.20%, а ускорения — 0.15%. Данное поведение, по всей видимости, определяется особенностями реализации цикла while компилятором и на ptx-ассемблерной вставке человеком, и позволяет считать обе реализации метода SKL равнопроизводительными.
В настоящей заметке я постарался осветить на базовом уровне проблему синхронизации потоков, способы синхронизации блоков; проведя некоторые тесты, дать с картинками общее описание системы CUDA. Кроме того, в исходном коде тестовой программы(2) читатель сможет найти очередной пример надежного использования буфера в разделяемой памяти (потоки синхронизируются через __syncthreads()). Надеюсь, кому-то это окажется полезным. Лично мне, эти сведения, собранные в одном месте, помогли бы сэкономить несколько дней экспериментов с кодом, и «гугления», так как обладаю дурацкой склонностью к не очень внимательному чтению документации.
(1) Для получения технической информации об имеющихся в компьютере адаптерах предлагается использовать Си-функцию CUDA API cudaGetDeviceProperties(...) [1-2, 15].
(2) Исходный код тестовый программы, залитый на pastebin.com.
[1] CUDA C Programming Guide
[2] CUDA C Best Practices Guide
[3] Advanced CUDA Webinar: Memory Optimizations
[4] S. Tariq, An Introduction to GPU Computing and CUDA Architecture
[5] Vanderbilt University, ACCRE, GPU Computing with CUDA
[6] ОмГТУ, Радиотехническом Факультет, Кафедра «Комплексная защита информации», программа переподготовки «Программирование для графических процессоров»
[7] Летняя Суперкомпьютерная Академия, Высокопроизводительные вычисления на кластерах с использованием графических ускорителей NVIDIA
[8] iXBT.com: NVIDIA CUDA — неграфические вычисления на графических процессорах
[9] cgm.computergraphics.ru: Введение в технологию CUDA
[10] THG.ru: nVidia CUDA: вычисления на видеокарте или смерть CPU?
[11] steps3d.narod.ru: Основы CUDA, Программирование на CUDA (часть 2)
[12] The CUDA Compiler Driver (NVCC)
[13] Using Inline PTX Assembly in CUDA
[14] PTX: Parallel Thread Execution ISA Version 3.0
[15] CUDA API Reference Manual (PDF, HTML online)
Несколько слов об архитектуре CUDA
Для начала, позволю себе на основе официальной документации [1,2] и слайдах [3,4], материалах различных сторонних сайтов [5-11] напомнить общую картину, с которой сталкивается программист при использовании CUDA. На самом высоком уровне абстракции он получает параллельную вычислительную систему с архитектурой SIMT (Single-Instruction, Multiple-Thread) — одна команда параллельно выполняется множеством более-менее независимых потоков (threads). Совокупность всех этих потоков, запущенных в рамках одной задачи (см. Рис.1), носит название grid.
Параллельность исполнения grid`а обеспечивается, в первую очередь, наличием на видеокарте большего количества идентичных скалярных процессоров (scalar processors), которыми, собственно, и выполняются потоки (см. Рис.3). Физически (см. Рис.2), скалярные процессоры являются частями потоковых мультипроцессоров (streaming multiprocessors — SM).
Например, в моей Tesla есть 30 SM, в каждом из которых по 8 скалярных процессоров. Однако, на этих 240 ядрах можно запускать grid`ы из существенно большего числа потоков(1) благодаря аппаратным механизмам разделения доступных ресурсов (как рабочего времени этих ядер, так и доступной памяти). А некоторые особенности реализации как раз этих механизмов и определяют методику синхронизации потоков при доступе к общей для них памяти.
Одной из таких важных особенностей является группировка потоков по 32 штуки в warp`ы, которые оказываются частями более крупных образований — блоков (blocks). Все потоки каждого блока (например, для моей Tesla блок может содержать максимум 512 потоков(1)) запускаются строго на одном SM, поэтому имеют доступ только к его ресурсам. Однако, на одном SM может запускаться более одного блока (см. Рис.3), и ресурсы будут разделятся между ними поровну.
В каждом SM существует блок управления, который занимается распределением ресурса процессорного времени. Делается это так, что в каждый момент времени все ядра одного SM исполняют строго один warp. А по его завершению хитрым оптимальным способом выбирается следующий warp, приписанный к данному SM. Таким образом оказывается, что потоки одного warp`а синхронизируются за счет аппаратной особенности CUDA и исполняются по еще более близкому к SIMD (Single Instruction, Multiple Data) методу. Но потоки даже одного блока из разных warp`ов могут оказаться заметно рассинхронизированными.
Другой, не менее важной особенностью, является организация памяти в CUDA и доступа потоков к её различным частям. Наивысшей степенью общедоступности для потоков обладает глобальная память (global memory), физически реализованная в виде интегральных микросхем, запаянных на плате графического адаптера — та самая видеопамять, которая ныне исчисляется уже гигабайтами. Расположение вне процессора делает этот тип памяти наиболее медленным, по сравнению с другими, предоставляемыми для вычислений на видеокарте. Меньшим «градусом общедоступности» обладает разделяемая память (shared memory): расположенный в каждом SM блок (см. Рис.2), обычно размером в 16KB(1), доступен только тем потокам, которые выполняются на ядрах этого SM (см. Рис.1, Рис.3). Так как к параллельному исполнению на одном SM может быть отведено более одного блока, то весь доступный в SM объем разделяемой памяти распределяется между этими блоками поровну. Необходимо упомянуть, что разделяемая память физически расположена где-то очень близко к ядрам SM, поэтому обладает высокой скоростью доступа, сравнимой с быстродействием регистровой (registers) — основным видом памяти. Именно регистры могут служить операндами элементарных машинных команд, и являются наиболее быстрой памятью. Все наличные регистры одного SM поровну разделяются между всеми потоками, запущенными на этом SM. Группа регистров, выделенная в пользование какому-либо потоку, доступна ему и только ему. На правах иллюстрации мощи CUDA (или, наоборот, масштабов бедствия): в той же Tesla каждый SM предоставляет в пользование 16384 штук 32-х разрядных регистров общего назначения(1).
Из всего сказанного выше, можно сделать вывод, что взаимодействие между потоками одного блока следует стараться осуществлять через их общую быструю разделяемую память, а между потоками двух различных блоков — только с использованием глобальной памяти. Тут и возникает обозначенная во введении проблема: слежение за актуальностью данных в общедоступной разным потокам для чтения и записи области памяти. Иначе говоря — проблема синхронизации потоков. Как уже отмечалось, в рамках одного блока потоки каждого warp`а синхронизированы между собой. Для синхронизации потоков блока вне зависимости от принадлежности к warp`ам существует несколько команд барьерного типа:
- __syncthreads() — самый верный способ. Эта функция заставит каждый поток ждать, пока (а) все остальные потоки этого блока достигнут этой точки и (б) все операции по доступу к разделяемой и глобальной памяти, совершенные потоками этого блока, завершатся и станут видны потокам этого блока. Не надо размещать эту команду внутри условного оператора if, но следует обеспечивать безусловный вызов этой функции всеми потоками блока.
- __threadfence_block() будет заставлять ждать вызвавший её поток, пока все совершенные операции доступа к разделяемой и глобальной памяти завершатся и станут видны потокам этого блока.
- __threadfence() будет заставлять ждать вызвавший её поток, пока все совершенные операции доступа к разделяемой памяти станут видны потокам этого блока, а операции с глобальной памятью — всем потокам на «устройстве». Под «устройством» понимает графический адаптер.
- __threadfence_system() подобна __threadfence(), но включает синхронизацию с потоками на CPU («хосте»), при использовании весьма удобной page-locked памяти. Подробнее в [1,2] и некоторых других источниках, приведенных в списке ниже.
Первая команда ставит единый барьер для всех потоков одного блока, три остальные — для каждого потока свой независимый барьер. Чтобы синхронизировать потоки всего grid надо будет придумать что-то еще. Прежде рассмотрения этого «еще», конкретизируем задачу, чтобы можно было привести пример осмысленного Си-кода.
Задача подробнее
Итак, конкретнее рассмотрим следующий пример. Пусть в глобальной памяти адаптера выделены два участка: под массивы X[] и P[] по 128 элементов. Пусть массив X[] записывается с хоста (центральным процессором из оперативной памяти компьютера). Создадим grid из двух блоков по 64 потока в каждом — то есть всего 128 потоков (см. Рис.4).
Теперь может быть выполнен этап (i): каждый поток с номером j будет складывать между собой все элементы массива X[], записывая результат в P[j]. Далее должен быть выполнен этап (ii): каждый j-ый поток начнет суммирование всех элементов массива P[], записывая их в соответствующие X[j]. Конечно, использовать CUDA для параллельного выполнения 128 раз одного и того же бессмысленно, но в реальной жизни каждый поток будет имеет свой набор весовых коэффициентов, с которыми происходит суммирование, а преобразования X->P и обратно, P->X — происходить многократно. В нашем же примере выбираем коэффициенты равными единицы — для наглядности и простоты, что не нарушит общности.
Перейдем от теории к эксперименту. Алгоритм весьма прозрачен, и человек, никогда не имевший дело с многопоточностью, сразу же может предложить такой код CUDA-ядра:
__global__ void Kernel(float *X, float *P) { const int N = 128; // Число элементов и используемых потоков в константе. const int index = threadIdx.x + blockIdx.x*blockDim.x; // Номер потока. float a; // Аккумулятор в регистре. Каждому потоку свой. /* этап (i): */ a = X[0]; for(int j = 1; j < N; ++j) // Собственно, цикл суммирования a += X[j]; P[index] = a / N; // Отнормируем, чтобы не получалось больших чисел. /* конец этапа (i). */ /* этап (ii): */ a = P[0]; for(int j = 1; j < N; ++j) // Собственно, цикл суммирования a += P[j]; X[index] = a / N; // Отнормируем, чтобы не получалось больших чисел. /* конец этапа (ii). */ }
Многократное выполнение этого ядра покажет, что массив P[] раз от раза буде�� один и тот же, а, вот, X[] иногда могут различаться. Причем, если различие есть, то оно будет не в одном каком-то элементе X[j], а в группе из последовательных 32-х элементов! При этом индекс первого элемента в ошибочном блоке будет кратен также 32 — это как раз проявление синхронизации в тех самых warp`ах и некоторой рассинхронизированности потоков разных warp`ов. Если ошибка произошла в каком-то потоке, то она же будет у всех остальных его warp`а. Если применить предложенный разработчиками CUDA механизм синхронизации
__global__ void Kernel(float *X, float *P) { ... /* конец этапа (i). */ __syncthreads(); /* этап (ii): */ ... }
то мы добьемся того, что каждый поток блока будет давать одинаковый результат. И если где-то он будет ошибочен — то у всего блока. Таким образом, остается как-то синхронизировать разные блоки.
Методы решения
К сожалению, мне известно только два метода:
- CUDA-ядро завершается тогда и только тогда, когда завершаются все потоки. Таким образом, одно ядро можно разбить на два и вызывать их из основной программы последовательно;
- Придумать систему флагов в глобальной памяти.
Первый вариант мне понравился не очень сильно, в связи с тем, что в моей задаче вызывать такие ядра надо часто (тысячи раз), а есть основания опасаться наличия дополнительных задержек на сам старт ядра. Хотя бы потому, что в начале каждого ядра нужно подготовить некоторые переменные, обработать аргументы функции-ядра… Логичнее и быстрее будет это сделать один раз в «большом» ядре, а затем не вмешивать CPU, оставив графический адаптер вариться в соку из данных в собственной памяти.
Что касается второго вариант с системой флагов, то подобный механизм упоминается и в разделе «B.5 Memory Fence Functions» в [1]. Однако, там рассматривается немного другой алгоритм работы ядра. Для реализации синхронизации блоков введем две функции: первая будет подготавливать значения счетчика отработавших блоков, а вторая будет играть роль барьера — задерживать каждый поток до тех пор, пока не отработают все блоки. К примеру, эти функции и ядро, их использующее, могут выглядеть так:
__device__ unsigned int count; // Флаг-счетчик отработавших блоков. Под него выделится //4 байта в глобальной памяти устройства. /* Фунция начальной инициализации флага-счетчика: */ __device__ void InitSyncWholeDevice(const int index) { if (index == 0) // Первый поток в grid`е (индекс 0) запишет нулевое count = 0; //начальное значение в счетчик блоков. if (threadIdx.x == 0) // Первый поток каждого block`а будет ждать, пока флаг- while (count != 0); //счетчик действительно станет нулем. // Заставляем остальные потоки каждого block`а ждать, пока первые не выйдут из цикла: __syncthreads(); // Все, флаг-аккумулятор записан. Все потоки на device более-менее идут вровень. } /* Фунция синхронизации потоков на device: */ __device__ void SyncWholeDevice() { // Переменная под значение счетчика до инкремента: unsigned int oldc; // Каждый поток пождет, пока записанное им в gmem и smem, станет видно всему grid`у: __threadfence(); // Первые потоки каждого block`а атомарным образом инкрементируют (каждый по разу) //флаг-аккумулятор: if (threadIdx.x == 0) { // В oldc кладется значение count до "+1": oldc = atomicInc(&count, gridDim.x-1); // Пусть поток подождет, пока его инкремент "дойдет" до ячейки в gmem: __threadfence(); // Если это последний блок (остальные уже инкрементировали count и ждут за счет цикла ниже), //то и незачем ему считывать count, так как предварительно убедились, что его инкремент //записан в gmem. Если мы в блоке, который еще не "отработал", то его первый поток будет //зациклен, пока все остальные блоки не "отчитаются" о завершении счета. if (oldc != (gridDim.x-1)) while (count != 0); } // Заставляем потоки в каждом блоке ждать, пока первые не выйдут из цикла: __syncthreads(); } __global__ void Kernel_Synced(float *X, float *P) { InitSyncWholeDevice(threadIdx.x + blockIdx.x*blockDim.x); ... /* конец этапа (i). */ SyncWholeDevice(); /* этап (ii): */ ... }
Вот, вроде, и все. Флаг завели, функции написали. Остается сравнить производительность первого и второго методов. Но, к сожалению, функция SyncWholeDevice() счетчик инкрементировать будет, а вот барьерную задержку не обеспечит. Казалось бы, почему? Ведь цикл while есть. Тут как раз мы и подплываем к упомянутому в абстракте подводному камню, который становится виден: если взглянуть на генерируемый компилятором nvcc ptx-файл [12-14], то оказывается, что он любезно выкидывает с его точки зрения пустой цикл. Заставить компилятор не оптимизировать цикл таким образом можно как минимум двумя способами.
Непременно рабочим окажется явная вставка на ptx-ассемблере. К примеру, такая функция, вызовом который следует заменить цикл while:
__device__ void do_while_count_not_eq(int val) { asm("{\n\t" "$my_while_label: \n\t" " .reg .u32 r_count; \n\t" " .reg .pred p; \n\t" " ld.global.u32 r_count, [count]; \n\t" " setp.ne.u32 p, r_count, %0; \n\t" "@p bra $my_while_label; \n\t" "}\n\t" : : "r"(val)); }
Другой, синтаксически более изящный способ — это использование спецификатора volatile при объявлении флага-счетчика. Это сообщит компилятору о том, что переменная в глобальной (или разделяемой) памяти может быть изменена любым потоком в любое время. Следовательно, при обращении к этой переменной необходимо отключать всякую оптимизацию. В коде будет необходимо изменить всего две строчки:
__device__ volatile unsigned int count; // Флаг-счетчик отработавших блоков. Под него выделится //4 байта в глобальной памяти устройства. ... // В oldc кладется значение count до "+1": oldc = atomicInc((unsigned int*)&count, gridDim.x-1); ...
Оценка методов решения
Проведем теперь грубую теоретическую оценку производительности двух методов синхронизации блоков. Поговаривают, что вызов ядра занимает ~10мкс — это цена синхронизации многократным вызовом ядер. В случае синхронизации введением барьера из цикла, ~10 потоков (смотря сколько блоков) инкрементируют и читают в цикле одну ячейку в глобальной памяти, где каждая операция ввода/вывода занимает порядка 500 тактов. Пусть таких операций каждый блок проводит 3. Тогда на операцию синхронизации будет тратиться примерно 10*500*3 = 1.5*10^4 тактов. При частоте ядер 1.5ГГц пол��чаем 1.0*10^(-5)cек = 10мкс. То есть порядок величин один и тот же.
Но, конечно же любопытно взглянуть на результаты хоть каких-нибудь тестов. На Рис.5 читатель поста может видеть сравнение потраченного времени на выполнение 100 последовательных преобразований X->P->X, повторенных 10 раз для каждой конфигурации grid`а. Повторение 10 раз делается для усреднения времени, требуемого для 100 преобразований(2).
В горизонтальной плоскости отложены число запускаемых блоков и число потоков, в каждом из них. По вертикальной оси откладывается выигрыш по времени в процентах для метода «один вызов ядра, барьеры внутри» (назовем SKL — single kernel launch) относительно метода «многократный вызов ядер»(MKL — multi kernel launch). Хорошо видно, что выигрыш на рассматриваемых конфигурациях grid`а хоть и весьма мал, но почти всегда положителен. Однако, чем больше становится блоков, тем метод MKL отстает по производительности все меньше. Для 32-х блоков он даже незначительно обыгрывает метод SKL. Связано это с тем, что чем больше блоков, тем больше больше потоков (имеющих threadIdx.x == 0) читают переменную count из медленной глобальной памяти. А никакого механизма «один раз прочел, отдал значение всем потокам» нет. Если же рассматривать изменение относительной производительности в зависимости от числа потоков в блоке, при постоянном количестве самих блоков, то тоже можно заметить некоторую закономерность. Но тут работают неизвестные автору эффекты, связанные с синхрони��ацией потоков в блоке, управлением warp`ами в SM. Поэтому от дальнейших комментариев воздержимся.
Интересно взглянуть и на производительность при неизменном числе работающих потоков (1024), но разном их разделении на блоки. На Рис.6 как раз приведены графики перенормированного времени, потраченного на 100*10 вышеупомянутых преобразований для двух методов (MKL и SKL).
По сути, это диагональный «срез» на Рис.5. Хорошо видно, что сперва, при более крупных блоках, производительность обоих методов синхронизации растет одинаково. О таком эффекте разработчики CUDA предупреждают в официальной документации [2], но автор, опять же к сожалению, не владеет подробностями механизмов этого явления. Сокращение же разрыва и даже проигрыш метода SKL при наиболее мелком разделении на блоки связан, как уже говорилось, с увеличением числа считываний переменной count.
Необходимо отметить, что тесты проводились при реализации метода SKL через замену цикла while ptx-ассемблерной вставкой. Применение же спецификатора volatile иногда (в зависимости от конфигурации grid`а) замедляет процесс, а иногда — ускоряет. Величина замедления достигает 0.20%, а ускорения — 0.15%. Данное поведение, по всей видимости, определяется особенностями реализации цикла while компилятором и на ptx-ассемблерной вставке человеком, и позволяет считать обе реализации метода SKL равнопроизводительными.
Заключение
В настоящей заметке я постарался осветить на базовом уровне проблему синхронизации потоков, способы синхронизации блоков; проведя некоторые тесты, дать с картинками общее описание системы CUDA. Кроме того, в исходном коде тестовой программы(2) читатель сможет найти очередной пример надежного использования буфера в разделяемой памяти (потоки синхронизируются через __syncthreads()). Надеюсь, кому-то это окажется полезным. Лично мне, эти сведения, собранные в одном месте, помогли бы сэкономить несколько дней экспериментов с кодом, и «гугления», так как обладаю дурацкой склонностью к не очень внимательному чтению документации.
(1) Для получения технической информации об имеющихся в компьютере адаптерах предлагается использовать Си-функцию CUDA API cudaGetDeviceProperties(...) [1-2, 15].
(2) Исходный код тестовый программы, залитый на pastebin.com.
Список источников информации
[1] CUDA C Programming Guide
[2] CUDA C Best Practices Guide
[3] Advanced CUDA Webinar: Memory Optimizations
[4] S. Tariq, An Introduction to GPU Computing and CUDA Architecture
[5] Vanderbilt University, ACCRE, GPU Computing with CUDA
[6] ОмГТУ, Радиотехническом Факультет, Кафедра «Комплексная защита информации», программа переподготовки «Программирование для графических процессоров»
[7] Летняя Суперкомпьютерная Академия, Высокопроизводительные вычисления на кластерах с использованием графических ускорителей NVIDIA
[8] iXBT.com: NVIDIA CUDA — неграфические вычисления на графических процессорах
[9] cgm.computergraphics.ru: Введение в технологию CUDA
[10] THG.ru: nVidia CUDA: вычисления на видеокарте или смерть CPU?
[11] steps3d.narod.ru: Основы CUDA, Программирование на CUDA (часть 2)
[12] The CUDA Compiler Driver (NVCC)
[13] Using Inline PTX Assembly in CUDA
[14] PTX: Parallel Thread Execution ISA Version 3.0
[15] CUDA API Reference Manual (PDF, HTML online)

