Многие часто сталкиваются с необходимостью проверки орфографии на нескольких языках одновременно, однако далеко не все существующие программы позволяют производить такую проверку, предлагая пользователю переключаться с одного языка на другой, что довольно неудобно и отнимает массу времени.

Не желая мириться с подобным неудобством для программ, использующих Hunspell словари (FireFox, Seamonkey, Miranda и др.) было принято решение создать автоматическую графическую утилиту для склейки нескольких языков, с возможностью дальнейшего использования полученных словарей.
Пару строк об истории создания. Идея зародилась еще в 2008 году, когда мной был скомпилирован комплексный Русско–Английский словарик для FireFox.
Он был размещен на ftp сайте Mozilla.
ftp.mozilla-russia.org/dictionaries/ru-en_spell_dictionary.xpi
Так же была тема на форуме.
forum.mozilla-russia.org/viewtopic.php?id=15316
С того момента прошло немало времени, но буквально недавно я почти одновременно получил несколько писем от интересующихся людей, которые просили дать что-то более свежее.
Нежели рассылать готовые обновления я решил доработать GUI утилиту, которая позволила бы пользователям самостоятельно собрать несколько словарей воедино.
В тот момент утилита была написана «для себя» на Delphi, который использовался мной на работе, однако назвать это кроссплатформенным решением нельзя.
Конечно, сейчас можно использовать последние версии Embarcadero RAD Studio для создания кроссплатформенных решений, тем не менее я решил остановиться на реализации автоматической утилиты средствами Java.
Утилита в минимальной её реализации должна уметь
1. Загружать словари из следующих наиболее распространенных форматов
— несжатый вид *.dic и *.aff
— ZIP архив (*.zip)
— XPInstall формат (*.xpi)
— Расширения OpenOffice (*.oxt)
2. Давать возможность выбора словарей для склейки
3. Давать возможность изменения имени полученных словарей и описания
4. Выгружать в форматах
— несжатый вид *.dic и *.aff
— ZIP архив (*.zip)
— XPInstall формат (*.xpi)
Прежде чем приступить к созданию программы, необходимо было изучить формат словарей, чтобы иметь возможность их загрузить и склеить.
Информацию по Hunspell можно найти тут
hunspell.sourceforge.net
Описание формата
pwet.fr/man/linux/fichiers_speciaux/hunspell
или в русском переводе
mozilla-russia.org/projects/dictionary/hunspell.html
Вкратце, для проверки орфографии Hunspell требуется два файла. Первый файл — словарь, содержащий слова (*.dic), второй — файл аффиксов (*.aff), который определяет значения специальных меток (флагов) в словаре. Флаги назначаются для слов в файле словаря, а определяются в файле аффиксов.
Учитывая формат и структуру файлов основная задача состояла в том, чтобы помимо простой склейки файлов словарей не нарушить соответствие аффиксов для разных словарей.
Для именования флагов в файле аффиксов существует три подхода
1. По умолчанию – каждый аффикс именуется одной буквой (с учетом реестра) или цифрой.
2. Long — каждый аффикс именуется двумя буквами или буквой с цифрой.
3. Number – каждый аффикс имеет значение от 1 до 65000.
Поскольку в большинстве случаев (те словари с которыми я сталкивался) файл аффиксов содержал только по несколько десятков разных флагов аффиксов, то авторам словарей можно было использовать первый подход с одной буквой, однако он явно не подходил для склейки нескольких файлов по причине большого количества разных аффиксов, поэтому было принято решение в результирующих файлах использовать цифровое именование. Минус, конечно, есть – некоторое увеличение размера файлов, но я считаю это не критично.
Так же все файлы словарей часто были в разных кодировках, поэтому для унификации был выбрана общая результирующая кодировка UTF-8.
В остальном особых обозримых проблем не было.
Программа загружает словари, склеивает их, игнорируя дубликаты слов, в результате отбрасывает неиспользованные флаги аффиксов.
В рамках данной статьи я не буду вдаваться в реализацию отдельных процедур, поскольку для желающих я разместил исходный код тут.
Там так же есть скрипт для ANT сборщика.
code.google.com/p/hunspell-merge
На текущий момент я протестировал работу утилиты под Ubuntu и ОС Windows 7 с указанными в задаче на реализацию типами исходных файлов.
Для работы требуется Java Runtime (JRE).
Качаем с этой странички HunspellMerge.jar и файл запуска для вашей ОС Linux или Windows. Для Linux не забываем проставить права на запуск файла.
Так же возможен запуск с использованием Java Webstart — файл запуска находится по этой ссылке.

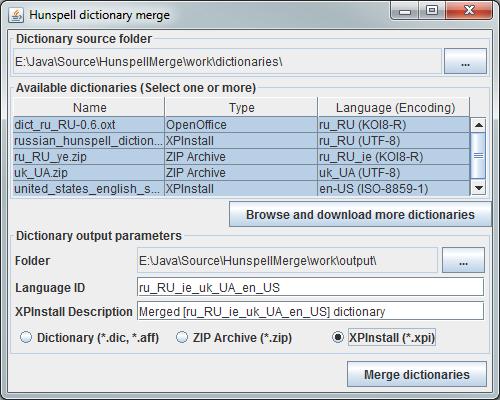
Для работы требуется иметь набор исходных файлов, которые по умолчанию могут быть размещены в подпапке dictionaries рабочей папки утилиты.
Дополнительные словари можно скачать по ссылкам размещенным тут
code.google.com/p/hunspell-merge/wiki/OnlineDictionaries
После запуска утилиты или выбора новой исходной папки словарей, они будут отображены в списке словарей.
Пользователю нужно только выделить (удерживая Ctrl или Shift) несколько словарей, выбрать папку назначения, указать название языка и если выгрузка будет в формате XPInstall, то поправить описание словаря.
FireFox
Формат вывода (XPInstall)
Просто копируем путь файла или перетягиваем файл в адресную строку браузера.
Нажимаем ввод и устанавливаем расширение.
Miranda / MirandaNG
Формат вывода (Dictionary)
Копируем файлы (*.aff, *.dic) в папку Dictionaries в каталоге с программой. Перезапускаем Miranda.
Поскольку утилита была написана за пару-тройку вечеров, то особого времени уделить тестированию и поддержке расширенных инструкций файла аффиксов не было. Это есть в планах на доработку, однако, некоторые инструкции для одного языка могут идти в разрез с такими же инструкциями для другого, поэтому пока поддерживается три типа основных флагов – суффиксы (SFX), префиксы (PFX), замена (REP).
Добавить русский язык для интерфейса.
Так же неплохо было бы написать документацию и облагородить страничку на GoogleCode.
Очень хотелось бы услышать в каких еще программах работают подобные склеенные словари.
Осознаю, что программа не лишена недостатков, поэтому буду рад услышать пожелания и предложения по усовершенствованию утилиты.
Спасибо за интерес.
UPD Как выяснилось есть польза даже от простой склейки словарей одного языка, загруженных, с разных ресурсов или имеющих разное направление, например, технические, экономические.
Не желая мириться с подобным неудобством для программ, использующих Hunspell словари (FireFox, Seamonkey, Miranda и др.) было принято решение создать автоматическую графическую утилиту для склейки нескольких языков, с возможностью дальнейшего использования полученных словарей.
История создания
Пару строк об истории создания. Идея зародилась еще в 2008 году, когда мной был скомпилирован комплексный Русско–Английский словарик для FireFox.
Он был размещен на ftp сайте Mozilla.
ftp.mozilla-russia.org/dictionaries/ru-en_spell_dictionary.xpi
Так же была тема на форуме.
forum.mozilla-russia.org/viewtopic.php?id=15316
С того момента прошло немало времени, но буквально недавно я почти одновременно получил несколько писем от интересующихся людей, которые просили дать что-то более свежее.
Нежели рассылать готовые обновления я решил доработать GUI утилиту, которая позволила бы пользователям самостоятельно собрать несколько словарей воедино.
В тот момент утилита была написана «для себя» на Delphi, который использовался мной на работе, однако назвать это кроссплатформенным решением нельзя.
Конечно, сейчас можно использовать последние версии Embarcadero RAD Studio для создания кроссплатформенных решений, тем не менее я решил остановиться на реализации автоматической утилиты средствами Java.
Задача
Утилита в минимальной её реализации должна уметь
1. Загружать словари из следующих наиболее распространенных форматов
— несжатый вид *.dic и *.aff
— ZIP архив (*.zip)
— XPInstall формат (*.xpi)
— Расширения OpenOffice (*.oxt)
2. Давать возможность выбора словарей для склейки
3. Давать возможность изменения имени полученных словарей и описания
4. Выгружать в форматах
— несжатый вид *.dic и *.aff
— ZIP архив (*.zip)
— XPInstall формат (*.xpi)
Реализация
Прежде чем приступить к созданию программы, необходимо было изучить формат словарей, чтобы иметь возможность их загрузить и склеить.
Информацию по Hunspell можно найти тут
hunspell.sourceforge.net
Описание формата
pwet.fr/man/linux/fichiers_speciaux/hunspell
или в русском переводе
mozilla-russia.org/projects/dictionary/hunspell.html
Вкратце, для проверки орфографии Hunspell требуется два файла. Первый файл — словарь, содержащий слова (*.dic), второй — файл аффиксов (*.aff), который определяет значения специальных меток (флагов) в словаре. Флаги назначаются для слов в файле словаря, а определяются в файле аффиксов.
Учитывая формат и структуру файлов основная задача состояла в том, чтобы помимо простой склейки файлов словарей не нарушить соответствие аффиксов для разных словарей.
Для именования флагов в файле аффиксов существует три подхода
1. По умолчанию – каждый аффикс именуется одной буквой (с учетом реестра) или цифрой.
2. Long — каждый аффикс именуется двумя буквами или буквой с цифрой.
3. Number – каждый аффикс имеет значение от 1 до 65000.
Поскольку в большинстве случаев (те словари с которыми я сталкивался) файл аффиксов содержал только по несколько десятков разных флагов аффиксов, то авторам словарей можно было использовать первый подход с одной буквой, однако он явно не подходил для склейки нескольких файлов по причине большого количества разных аффиксов, поэтому было принято решение в результирующих файлах использовать цифровое именование. Минус, конечно, есть – некоторое увеличение размера файлов, но я считаю это не критично.
Так же все файлы словарей часто были в разных кодировках, поэтому для унификации был выбрана общая результирующая кодировка UTF-8.
В остальном особых обозримых проблем не было.
Программа загружает словари, склеивает их, игнорируя дубликаты слов, в результате отбрасывает неиспользованные флаги аффиксов.
В рамках данной статьи я не буду вдаваться в реализацию отдельных процедур, поскольку для желающих я разместил исходный код тут.
Там так же есть скрипт для ANT сборщика.
code.google.com/p/hunspell-merge
Как работать
На текущий момент я протестировал работу утилиты под Ubuntu и ОС Windows 7 с указанными в задаче на реализацию типами исходных файлов.
Для работы требуется Java Runtime (JRE).
Качаем с этой странички HunspellMerge.jar и файл запуска для вашей ОС Linux или Windows. Для Linux не забываем проставить права на запуск файла.
Так же возможен запуск с использованием Java Webstart — файл запуска находится по этой ссылке.
Для работы требуется иметь набор исходных файлов, которые по умолчанию могут быть размещены в подпапке dictionaries рабочей папки утилиты.
Дополнительные словари можно скачать по ссылкам размещенным тут
code.google.com/p/hunspell-merge/wiki/OnlineDictionaries
После запуска утилиты или выбора новой исходной папки словарей, они будут отображены в списке словарей.
Пользователю нужно только выделить (удерживая Ctrl или Shift) несколько словарей, выбрать папку назначения, указать название языка и если выгрузка будет в формате XPInstall, то поправить описание словаря.
Использование результатов работы
FireFox
Формат вывода (XPInstall)
Просто копируем путь файла или перетягиваем файл в адресную строку браузера.
Нажимаем ввод и устанавливаем расширение.
Miranda / MirandaNG
Формат вывода (Dictionary)
Копируем файлы (*.aff, *.dic) в папку Dictionaries в каталоге с программой. Перезапускаем Miranda.
Планы
Поскольку утилита была написана за пару-тройку вечеров, то особого времени уделить тестированию и поддержке расширенных инструкций файла аффиксов не было. Это есть в планах на доработку, однако, некоторые инструкции для одного языка могут идти в разрез с такими же инструкциями для другого, поэтому пока поддерживается три типа основных флагов – суффиксы (SFX), префиксы (PFX), замена (REP).
Добавить русский язык для интерфейса.
Так же неплохо было бы написать документацию и облагородить страничку на GoogleCode.
Заключение
Очень хотелось бы услышать в каких еще программах работают подобные склеенные словари.
Осознаю, что программа не лишена недостатков, поэтому буду рад услышать пожелания и предложения по усовершенствованию утилиты.
Спасибо за интерес.
UPD Как выяснилось есть польза даже от простой склейки словарей одного языка, загруженных, с разных ресурсов или имеющих разное направление, например, технические, экономические.

