
Если ты ИТшник, то нельзя просто так взять и выйти на работу 2-го января: пересмотреть 3-ий сезон битвы экстрасенсов или запись программы «Гордон» на НТВ (дело
Нельзя потому, что у других сотрудников обязательно будут для тебя подарки: у секретарши закончился кофе, у МП — закончились дедлайны, а у администратора баз данных —
Оказалось, что инженеры из команды Hadoop тоже любят побаловать друг друга новогодними сюрпризами.
2008
2 января. Упуская подробное описание эмоционально-психологического состояния лиц, участвующих в описанных ниже событиях, сразу перейду к факту: поставлен таск MAPREDUCE-279 «Map-Reduce 2.0». Оставив шутки про число, обращу внимание, что до 1-ой стабильной версии Hadoop остается чуть менее 4 лет.
За это время проект Hadoop пройдет эволюцию из маленького инновационного снежка, запущенного в 2005, в большой снежный
Ниже мы предпримем попытку разобраться, какое же значение январский таск MAPREDUCE-279 играл (и, уверен, еще сыграет в 2013) в эволюции платформы Hadoop.
2011
В феврале 2011 года инженеры Yahoo порадовали мир статьей «The Next Generation of Apache Hadoop MapReduce» [2]. В октябре 2011 года Apache Software Foundation опубликовало в своей wiki-труд под названием «Apache Hadoop NextGen MapReduce (YARN)» [1]. 27 декабря на сайте Apache Software Foundation мир увидел надпись:
…release 1.0.0 available. After six years of gestation, Hadoop reaches 1.0.0!и ссылку стабильную версию Hadoop v1.0.
2012
Hadoop 2.0.0-alpha стал доступен для скачивания в конце мая. В мае же в печать вышла книга «Hadoop: The Definitive Guide, Third Edition» (автор Tom White), где довольно значительный объем отводится YARN. В начале июня Tom White выступил с презентацией «MapReduce 2.0» (видео) на Chicago Hadoop User Group. В это же месяце Cloudera с анонсировала поддержку Hadoop 2.0.0 Alpha в своем продукте CDH4. Немногим позже о поддержке Hadoop 2.0 в своих дистрибутивах заявила и компания Hortonworks.
17 сентября на сайте Apache Software Foundation было опубликовано, что YARN and MapReduce v2 доступны в Hadoop 0.23.3.
Ниже будут рассмотрены походы к распределенным вычислениям в классическом Hadoop MapReduce и новой архитектуре, описаны приемы и компоненты, реализующие концепции новой модели, а также проведено сравнение классической и 2.0 архитектур.
1. Hadoop MapReduce Classic
Hadoop – попул��рная программная платформа (software framework) построения распределенных приложений для массово-параллельной обработки (massive parallel processing, MPP) данных.
Hadoop включает в себе следующие компоненты:
- HDFS – распределенная файловая система;
- Hadoop MapReduce – программная модель (framework) выполнения распределенных вычислений для больших объемов данных в рамках парадигмы map/reduce.
Концепции, заложенные в архитектуру Hadoop MapReduce и структуру HDFS, стали причиной ряда узких мест в самих компонентах, в том числе и единичные точки отказа. Что, в конечном итоге, определило ограничения платформы Hadoop в целом.
К последним можно отнести:
- Ограничение масштабируемости кластера Hadoop: ~4K вычислительных узлов; ~40K параллельных заданий;
- Сильная связанность фреймворка распределенных вычислений и клиентских библиотек, реализующих распределенный алгоритм. Как следствие:
- Отсутствие поддержки альтернативной программной модели выполнения распределенных вычислений: в Hadoop v1.0 поддерживается только модель вычислений map/reduce.
- Наличие единичных точек отказа и, как следствие, невозможность использования в средах с высокими требованиями к надежности;
- Проблемы версионной совместимости: требование по единовременному обновлению всех вычислительных узлов кластера при обновлении платформы Hadoop (установке новой версии или пакета обновлений);
- Отсутствие поддержки работы с обновляемыми/потоковыми данными.
Новая архитектура Hadoop ставила своей целью убрать многие из вышеперечисленных ограничений.
О самой архитектуре Hadoop 2.0 и ограничениях, которые она позволила преодолеть, и поговорим ниже.
2. Hadoop MapReduce Next
Основные изменения коснулись компонента выполнения распределенных вычислений Hadoop MapReduce.
Классический Hadoop MapReduce представлял собой один процесс JobTracker и произвольное количество процессов TaskTracker.
В новой архитектуре Hadoop MapReduce функции JobTracker по управлению ресурсами и планированию/координации жизненного цикла выполнения заданий были разделены на 2 отдельных компонента:
- менеджер ресурсов ResourceManager;
- планировщик и координатор приложения ApplicationMaster.
Рассмотрим каждый компонент подробнее.
ResourceManager
ResourceManager (RM) – глобальный менеджер ресурсов, чьей задачей является распределение ресурсов, затребованных приложениями и наблюдение за вычислительными узлами, на которых эти приложения выполняются.
ResourceManager, в свою очередь, включает в себя следующие компоненты:
- Scheduler – планировщик, ответственный за распределение ресурсов между затребовавшими ресурсы приложениями.
Scheduler является «чистым» планировщиков: он не ведет мониторинга и не отслеживает статус приложений.
- ApplicationsManager (AsM) – компонент, ответственный за запуск экземпляров ApplicationMaster, а также мониторингов узлов (контейнеров), на которых происходит выполнение, и перезапуск «мертвых» узлов.
Стоит отметить, что Scheduler в ResourceManager является сменным компонентом (pluggable). Всего имеются 3 типа Scheduler: FIFO scheduler (по умолчанию), Capacity scheduler и Fair scheduler. В версии Hadoop 0.23 первые 2 типа планировщиков поддерживаются, 3-ий — нет.
Ресурсы у RM запрашиваются для абстрактного понятия Container, о котором речь еще пойдет и которому можно задать такие параметры как требуемое процессорное время, объем оперативной памяти, необходимая пропускная способность сети. На декабрь 2012 года поддерживается только параметр «объем RAM».
Введение RM позволяет относиться к узлам кластера как к вычислительным ресурсам, что качественно повышает утилизацию ресурсов кластера.
ApplicationMaster
ApplicationMaster (AM) – компонент, ответственный за планирование жизненного цикла, координацию и отслеживание ��татуса выполнения распределенного приложения. Каждое приложение имеет свой экземпляр ApplicationMaster.
На этом уровне как раз стоит рассмотреть YARN.
YARN (Yet Another Resource Negotiator) – это программный фреймворк выполнения распределенных приложений (каким экземпляр ApplicationMaster и является). YARN предоставляет компоненты и API, необходимые для разработки распределенных приложений различных типов. Сам фреймворк берет на себя ответственность по распределению ресурсов в ответ на запросы ресурсов от выполняемых приложений и ответственность за отслеживанием статуса выполнения приложений.
Модель YARN более общая (generic), чем модель, реализованная в классическом Hadoop MapReduce.
Благодаря YARN на Hadoop-кластере возможно запускать не только «map/reduce»-приложения, но и распределенные приложения, созданные с использованием: Open MPI, Spark, Apache HAMA, Apache Giraph, etc. Есть возможность реализовать и другие распределенные алгоритмы (вот она сила ООП!). Подробные инструкции описаны в Apache Wiki.
В свою очередь, MapReduce 2.0 (или MR2, или MRv2) – это фреймворк выполнения распределенных вычислений в рамках программной модели map/reduce, «лежащий» над уровнем YARN.
Разделение ответственности по управлению ресурсами и планированию/координации жизненного цикла приложения между компонентами ResourceManager и ApplicationMaster придали платформе Hadoop более распределенный характер. Что, в свою очередь, положительно сказалось на масштабируемости платформы.
NodeManager
NodeManager (NM) – агент, запущенный на вычислительном узле, в чьи обязанности входит:
- отслеживание используемых вычислительных ресурсов (CPU, RAM, network, etc.);
- отправка отчетов по используемым ресурсам планировщику менеджера ресурсов ResourceManager/Scheduler.
Протоколы взаимодействия
Управляющие команды и передача статусов различным компонентов платформы Hadoop проходят посредством следующих протоколов:
- ClientRMProtocol – протокол взаимодействия клиента с ResourceManager для запуска, проверки статуса и закрытия приложений.
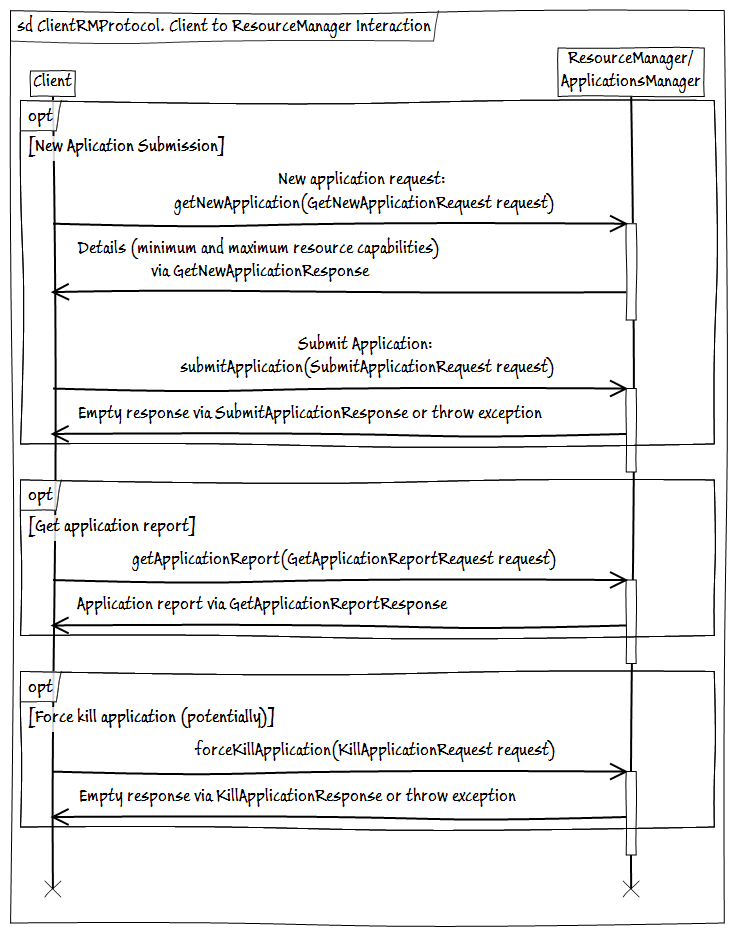
- AMRMProtocol — протокол взаимодействия экземпляров ApplicationMaster с ResourceManager для подписки/отписки AM, отправки запроса и получения ресурсов от RM.
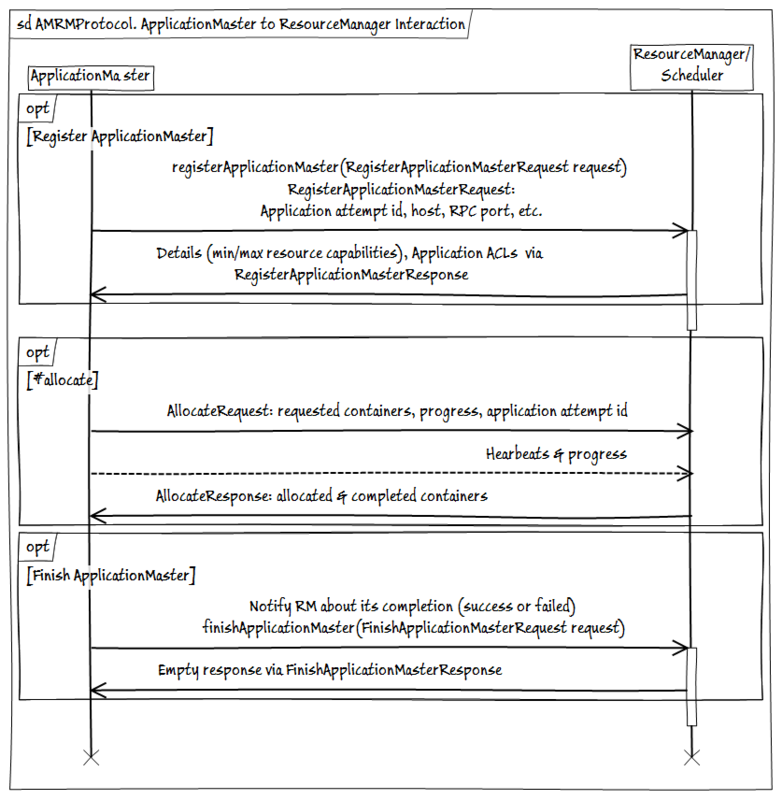
- ContainerManager — протокол взаимодействия ApplicationMaster с NodeManager для запуска/остановки и получения статуса контейнеров, находящихся под управлением NM.

3. Hadoop MapReduce. Vis-à-vis
В части 1 «Hadoop MapReduce Classic» было дано введение в платформу Hadoop и описаны основные ограничения платформы. В части 2 «Hadoop MapReduce Next» были описаны концепции и компоненты, введенные в новую версию фреймворка распределенных вычислений Hadoop MapReduce.
Обсудим, как концепции YARN, MR2 и компоненты, реализующие эти концепции, изменили архитектуру распределенного вычисления на платформе Hadoop, а также как эти изменения помогли (или нет) обойти с существующие ограничения платформы.
— О терминологии
Так как далее речь будет идти о сравнении классической и «2.0» версий Hadoop MapReduce, то во избежание:
- неоднозначностей, связанных с обсуждаемой версией, и/или
- бесконечных уточнений версии, о которой идет речь,
- Hadoop MapReduce 1.0 – «классический» plain (если не оговорено иное) Hadoop MapReduce;
- Hadoop MapReduce 2.0 – это YARN и MapReduce v2.0.
Архитектура
В Hadoop MapReduce 1.0 кластер имеет единственный узел JobTracker, который занимается распределением задач по многочисленным узлам TaskTracker, непосредственно выполняющим задачи.
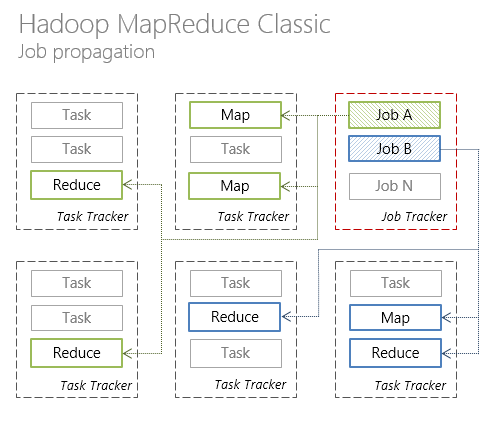
В новой архитектуре Hadoop MapReduce ответственность по управлению ресурсами и планированию/координации за жизненным циклом выполнения приложений разделены между ResourceManager (per-cluster) и ApplicationMaster (per-application), соответственно.
Каждый вычислительный узел разделен на произвольное количество контейнеров Container, содержащих предопределенное количество ресурсов: CPU, RAM и т.д. Наблюдение за контейнерами ведет NodeManager (per-node).

Ниже представлена иллюстрация взаимодействия отдельных компонент Hadoop MapReduce в классическом варианте архитектуры
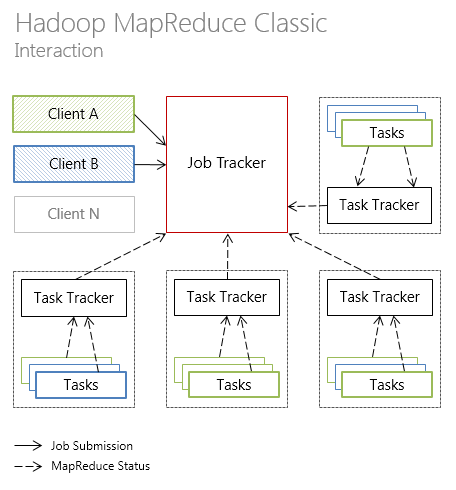
и YARN-подобной архитектуру (новые типы коммуникаций между компонентами выделены жирным).
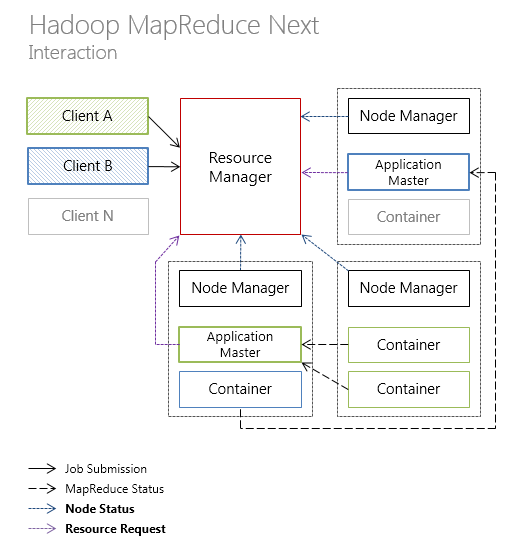
Далее рассмотрим, как новая архитектура Hadoop MapReduce повлияла на такие аспекты платформы как доступность, масштабируемость, утилизация ресурсов.
Доступность
В Hadoop MapReduce 1.0 сбой JobTracker приводит к необходимости перезапуска JobTracker с чтением состояния из специальных журналов, что, в конечном итоге, приводит к простою кластера.
В новой версии решения по доступности хоть и не поднялись на качественно новый уровень, но все же дела обстоят не хуже. Hadoop MapReduce 2.0 задача высокой доступности решается следующим способом: сохраняется состояние компонентов ResourceManager и ApplicationMaster и обеспечивается система автоматического перезапуска перечисленных компонентов при сбое с подгрузкой последнего успешно сохраненного состояния.
Для ResourceManager сохранением состояния занимается Apache ZooKeeper. И при сбое менеджера ресурсов, создается новый процесс RM с состоянием, которое было до сбоя. Таким образом, последствия от сбоя RM сводятся к тому, что перезапустятся все запланированные и запущенные приложения.
Для ApplicationMaster используется собственный механизм checkpoint’ов. В процессе работы AM сохраняет свое состояние в HDFS. Если AM становится недоступным, то RM перезапускает его с состоянием из snapshot’а.
Масштабируемость
Разработчики, работающие с Hadoop MapReduce 1.0, неоднократно указывали, что предел масштабируемости Hadoop-кластера лежит в районе 4K машин. Основная причина этого ограничения — узел JobTracker довольно значительное количество своих ресурсов тратит на задачи, связанные с жизненным циклом приложения. Последние можно отнести к задачам специфическим для конкретного приложения, а не для кластера в целом.
Разделение ответственности за задачи, относящиеся к разным уровням, между ResourceManager и ApplicationMaster стало, пожалуй, главным ноухау Hadoop MapReduce 2.0.
Планируется, что Hadoop MapReduce 2.0 может работать на кластерах до 10K+ вычислительных узлов, что является существенным прогрессом, в сравнении с классической версией Hadoop MapReduce.
Утилизация ресурсов
Невысокая утилизация ресурсов вследствие жесткого деления ресурсов кластера на map- и reduce-слоты нередко также является объектом критики классического Hadoop MapReduce. На смену концепции слотов в MapReduce 1.0 пришла концепция универсальных контейнеров – набора взаимозаменяемых изолированных ресурсов.
Введения понятия «Container» в Hadoop MapReduce 2.0, по сути, добавил платформе Hadoop еще одно свойство – мультитенантность. Отношение к узлам кластера как к вычислительным ресурсам позволит избавиться от негативного влияния слотов на утилизацию ресурсов.
Связанность
Одной из архитектурных проблем Hadoop MapReduce 1.0 было сильная связанность 2-ух, по сути, не взаимозависимых систем: фреймворка распределенных вычислений и клиентских библиотек, реализующих распределенный алгоритм.
Это связанность стала причиной невозможности запуска на Hadoop-кластере MPI или других, альтернативных map/reduce, распределенных алгоритмов.
В новой архитектуре был выделен фреймворк распределенных вычислений YARN и фреймворк вычислений в рамках программной модели map/reduce, базирующийся на основе YARN – MR2.
MR2 является application-specific фреймворком, представленным ApplicationMaster, в то время как YARN «представлен» компонентами ResourceManager и NodeManager и полностью независим от специфики распределенного алгоритма.
За кадром
Целостной картины не будет, если не упомянуть 2 аспекта:
1. В статье рассматривался только фреймворк распределенных вычислений.
За рамками статьи остались изменения, коснувшиеся хранилища данных. Наиболее заметные из них — высокая доступность узла имен HDFS и федерации узлов имен HDFS.
2. Описанное выше будет реализовано только в Hadoop v2.0 (на время написания статьи доступен alfa-версия). Так YARN и MR2 доступны уже в Hadoop v0.23, но без поддержки высокой доступности NameNode.
Отдельно отмечу, что на июньской конференции Chicago HUG 2012, о которой я упомянул во введении, Tom White говорил, что в Hadoop 2.0 Alpha еще есть работы, связанные и с производительность, и с безопасностью, и с ResourceManager.
Заключение
Проект Hadoop в 2010 приятно удивлял идеями, в 2011 – скоростью распространения, в 2012 поразил масштабом изменений.
Не буду тратить Ваше время на «традиционное» краткое изложение того, что изменили YARN и MR2 в платформе Hadoop. Это без сомнения качественный скачок платформы.
Сейчас Hadoop выглядит как дефакто отраслевой стандарт в задачах, связанных с Big Data. Будущий релиз версии 2.0 даст разработчикам открытый, отказоустойчивый, вели��олепно масштабируемый, расширяемый инструмент массово-параллельной обработки, не «зацикленный» исключительно на программной модели map/reduce.
Звучит невероятно. Еще невероятнее, что это совсем недалекая реальность. Остается только один ньанс — быть этой реальности готовым.
Список источников
[1] Apache Hadoop NextGen MapReduce (YARN). Apache Software Foundation, 2011.
[2] Arun C Murthy. The Next Generation of Apache Hadoop MapReduce. Yahoo, 2011.
[3] Ahmed Radwan. MapReduce 2.0 in Hadoop 0.23. Cloudera, 2012.
[4] Tom White. Hadoop: The Definitive Guide, 3rd Edition. O'Reilly Media / Yahoo Press, 2012.
[5] Apache Hadoop Main 2.0.2-alpha API. Apache Software Foundation, 2012.
Постскриптум и прочие переживания автора
* Cloudera позволяет скачать дистрибутив CDH4 (с поддержкой YARN) для запуска на локальной машине в псевдораспределенном режиме. Дистрибутив и инструкции.

