
В последнее время всё чаще стали появляться новости о планах по завоеванию серверного рынка системами построенными на ARM-архитектуре. Более того, воплотились в кремнии настоящие серверные ARM-процессоры от Calxeda, а также системы на их основе от Boston Viridis и в скором времени от HP — Moonshot.
Сервера на базе Intel® Atom™ я использую уже 4 года, а вот ARM-ы мне знакомы только с мобильной телефонно-планшетной стороны. На что же он способен, современный ARM-процессор? Сможет ли он конкурировать с Atom-ами? Прямого сравнения на серверном фронте я не нашел, только синтетику на Phoronix. Интересное тестирование было на AnandTech, но там Xeon-ы. Calxeda в своём бенчмарке также сравнивает с Xeon-ами. Мне же было интересно сравнить именно с Atom-ами в связке Linux+NGINX для отдачи статики.
Atom-ы, помимо нетбуков/неттопов — изначальной цели этих процессоров, прижились у меня в универсальных роутерах (прокси-почта-фаервол) для офиса средних размеров, в сетевых хранилищах (файл-сервер), в фронт-эндах и серверах для статики. Почему именно статики — потому что это минимально достаточный процессор для таких задач. И хоть уважаемые товарищи пишут, что HP лучше (меня) знает, и что это вполне может быть сервер приложений или облачных вычислений, я считаю, что калибр ружья должен хоть как-то соотносится с размером тушки. Да, туча комаров, вполне может загрызть медведя, но это будет долго и мучительно.
Знающие люди обязательно отпишут в комментариях, что для статики нужно использовать CDN-ы. Предваряя такой вопрос отвечу — да, можно использовать, если масштаб задачи (и кошелёк заказчика) соответствующий. Я периодически провожу мониторинг цен, и пока не увидел никого, кто бы сравнился по цене с арендованными Atom-ами, висящими на безлимитных (или почти безлимитных) 100-мегабитных аплинках. Например, 5 серверов, каждый из которых выдаёт от 7-ми до 22-х Тб в месяц. Сколько это будет стоить на Amazon-е?
Выбор соперника
Для тестирования нужна плата с современным многоядерным ARM-процессором, SATA-портом и как минимум 100-мегабитным Ethernet-ом. Выбор оказался крайне ограниченным — тут либо вышеупомянутая система от Boston Viridis за $20.000, либо плата для разработчика SABRE Lite за $220. Выбирал я не долго :)
К сожалению, на момент заказа более продвинутая (+1GB RAM, +WiFi, +Bluetooth) и дешёвая ($129) плата на том же процессоре от Wandboard была ещё недоступна, а предел мечтаний ARMBRIX Zero на Samsung Exynos 5250 (ARM Cortex-A15 @1.7GHz) уже отменена.
Процессор Freescale i.MX6Q основан на ядре Cortex-A9, т.е. не самый свежий, но Calxeda основана на том же ядре, да и ничего другого я попросту не нашёл. Кроме того у меня был обширный опыт ковыряния с предыдущей серией i.MX51 на китайских планшетах. Изучив работу Cortex-A9 и приняв на веру то, что A15 на той же частоте будет на 40% быстрее, можно грубо экстраполировать результаты на гипотетическую систему с Cortex-A15 на большей частоте.
Участники соревнований
Процессор Atom будет представлен в двумя моделями:
- Старым-добрым D525 на платформе SuperMicro SuperServer 5015A-EHF-D525
- Снятым с производства флагманом D2700 на плате Intel® Desktop Board D2700MUD
Две модели нужны для того, чтобы выяснить как система масштабируется по частоте. К сожалению, Intel решила, что в дешёвых десктопных процессорах технологии энергосбережения (управления питанием/частотой) ни к чему, они и так потребляют всего-ничего.
Процессор i.MX6Q тоже будет рассмотрен в двух вариантах — 996MHz и 396MHz — это частоты, поддерживаемые в cpufreq.
Софт и настройки на всех системах идентичны: Gentoo Linux 3.x, NGINX 1.4.1, OpenSSL 1.0.1e, GCC 4.8.1 (-O3 -march=native), а на ARM-е дополнительно опция генерации кода в Thumb (-mthumb). По поводу последней есть разные мнения, но конкретно на моей системе, помимо того, что код получался гарантировано меньшего размера, в большинстве тестов ещё и немного быстрее.
Система на Atom-е будет протестирована в 32-битном режиме и в 64-битных x86-64 и x32 ABI. Зачем х32? — интересно проверить развенчание мифов!
Тестовые системы и клиентский компьютер гигабитными портами включены в гигабитный свитч.
Взвешивание
| Intel Atom D2700 | Freescale i.MX6Q | |
|---|---|---|
| Количество ядер | 2 | 4 |
| Количество потоков | 4 | 4 |
| Тактовая частота | 2.13 GHz | 996 Mhz |
| Кэш L2 | 1 MB | 1 MB |
| Разрядность | 64-бит | 32-бит |
| Максимальная потребляемая мощность процессора | 10 Вт | 3 Вт |
| Максимальная потребляемая мощность платы + SSD под нагрузкой | 30 Вт | 9 Вт |
| Вес материнской платы :) | 336 гр | 74 гр |
| Цена | $52 | $40 |
К плюсам Atom-ов можно отнести поддержку 64-битного режима, практическую пользу которого мы проверим в тестах.
i.MX6Q основан на ядре Cortex-A9, а значит он, в отличии от соперника, поддерживает внеочерёдное исполнение команд (out-of-order), плюс 4 честных ядра. Кроме того в нём интегрирован аппаратный криптографический движок CAAM — тоже попытаемся изучить.
По суммарным Гигагерцам практически паритет — 4.26 у Atom-а, против 3.98 у i.MX6Q.
Волевым решением судей соперники признаются в равной весовой категории, и допускаются к следующему этапу.
Фотосессия
Для масштаба на фото красуется новенький SSD Silicon Power T10 (JMicron JMF616) на 32GB. Именно на нём будут установлены все тестовые системы.
Это не самый быстрый вариант, но его заявленной скорости чтения в 200 МБ/с с запасом хватит чтобы перекрыть гигабитный канал, не говоря уже про 100 мегабит.
Там же лежит mSATA модуль, как памятник человеческой глупости, и напоминание о том, что не на всякой материнке Mini-PCIE == mSATA. Даже на Intel-овской.

Квалификация
Вместо SPEC-синтетики, проведём простые тесты подсистем, от которых зависит производительность web-сервера.
Данные собирались с помощью следующего
незамысловатого скрипта:
#!/bin/bash CPU=`uname -p` CIPHERS="rc4 aes-128-cbc aes-256-cbc" MULTI="1 2 4" SPEED="openssl speed -elapsed -multi" GFILE="/sys/devices/system/cpu/cpu0/cpufreq/scaling_governor" if [ -f "${GFILE}" ]; then GVRS="powersave performance" else GVRS="stub" GFILE="/dev/null" fi for G in ${GVRS}; do # Set frequency echo "${G}" > "${GFILE}" sleep 1 # Log file name if [ "${GVRS}" != "stub" ]; then FREQ=`cat /sys/devices/system/cpu/cpu0/cpufreq/cpuinfo_cur_freq` else FREQ=`grep "cpu MHz" /proc/cpuinfo | head -n 1 | awk '{print $4}'` fi BDIR="${CPU}/@${FREQ}" if [ ! -d "${BDIR}" ]; then mkdir -p "${BDIR}" fi # hard disk testing LOG="${BDIR}/hdparm.txt" for I in 1 2 3; do echo "#${I} :" >> "${LOG}" hdparm -tT /dev/sda >> "${LOG}" done # gzip testing LOG="${BDIR}/gzip.txt" for I in 1 2 3; do echo -n "#${I} :" >> "${LOG}" { time gzip -c pages/*.html >/dev/null ; } 2>>"${LOG}" done # OpenSSl testing for M in ${MULTI}; do for C in ${CIPHERS}; do LOG="${BDIR}/ssl_m${M}_${C}.txt" for I in 1 2 3; do echo -n "#${I} :" >> "${LOG}" ${SPEED} ${M} ${C} | tail -n 1 >> "${LOG}" done done done done
Тренировка — сжатие gzip-ом
Допустим, сервер выступает фронт-эндом для PHP-FPM/FCGI сервера. Сжимать ответ — признак хорошего тона. Ну и трафик экономится.
Сжимается 441 файл (типичные странички с phpBB-шного форума) общим размером 42МБ.

i.MX-ы проигрывают, но это однопоточный тест, так что возможно не всё так плохо. Спишем на медленную подсистему памяти.
Разминка — скорость шифрования OpenSSL алгоритмами RC4 (быстро) и AES-256 (круто)
Многие клиенты хотят https://, поэтому всё, даже картинки, нужно шифровать.
i.MX6Q включает в себя криптографический ускоритель CAAM, поддерживающий
множество полезных вещей
Среди них RC4 и AES-256. Очень заманчиво аппаратно ускориться. Но всё оказалось несколько сложней. Стандартный OpenSSL не использует Crypto-API ядра Linux. Поддержка Freescale отписала, что якобы OpenSSL может его использовать через NetKey API (AF_ALG?). Но явно не использовало. Потом наткнулся на Cryptodev-linux module. Включил в ядре поддержку /dev/crypto и пересобрал OpenSSL c -DHAVE_CRYPTODEV. Все равно не видит. Отключил родной cryptodev, пропатчил ядро и OpenSSL патчем с этого сайта. И чудо! — они увидели друг друга. Но скорость оказалась разочаровывающе низкой. Собственно об этом было предупреждение, что на современных процессорах, скорее всего, шифровать в софте будет быстрее. А так получается красиво, аппаратно, асинхронно, но медленно. Может быть ещё что-то подкрутят в драйверах, и оно заработает быстрее, но пока не вариант.Secure memory feature with HW enforced access control
Cryptographic authentication
* Hashing algorithms
* MD5
* SHA-1
* SHA-224
* SHA-256
* Message authentication codes (MAC)
* HMAC-all hashing algorithms
* AES-CMAC
* AES-XCBC-MAC
* Auto padding
* ICV checking
Authenticated encryption algorithms
* AES-CCM (counter with CBC-MAC)
Symmetric key block ciphers
* AES (128-bit, 192-bit or 256-bit keys)
* DES (64-bit keys, including key parity)
* 3DES (128-bit or 192-bit keys, including key parity)
Cipher modes
* ECB, CBC, CFB, OFB for all block ciphers
* CTR for AES
Symmetric key stream ciphers
* ArcFour (alleged RC4 with 40 — 128 bit keys)
* Random-number generation
* Entropy is generated via an independent free running ring oscillator
* Oscillator is off when not generating entropy; for lower-power consumption
* NIST-compliant, pseudo random-number generator seeded using hardware generated entropy
Cryptographic authentication
* Hashing algorithms
* MD5
* SHA-1
* SHA-224
* SHA-256
* Message authentication codes (MAC)
* HMAC-all hashing algorithms
* AES-CMAC
* AES-XCBC-MAC
* Auto padding
* ICV checking
Authenticated encryption algorithms
* AES-CCM (counter with CBC-MAC)
Symmetric key block ciphers
* AES (128-bit, 192-bit or 256-bit keys)
* DES (64-bit keys, including key parity)
* 3DES (128-bit or 192-bit keys, including key parity)
Cipher modes
* ECB, CBC, CFB, OFB for all block ciphers
* CTR for AES
Symmetric key stream ciphers
* ArcFour (alleged RC4 with 40 — 128 bit keys)
* Random-number generation
* Entropy is generated via an independent free running ring oscillator
* Oscillator is off when not generating entropy; for lower-power consumption
* NIST-compliant, pseudo random-number generator seeded using hardware generated entropy

i.MX-ы снова проигрывают, но не сильно. Разница в скорости между двумя и четырмя потоками на i.MX ровно в два раза, что неудивительно, так как у нас четыре честных ядра. А вот на Atom-е гораздо интереснее. В х86 режиме разница составляет 1.45, т.е. Hyper-threading добавляет почти целое виртуальное ядро, а в 64-битном режиме разница всего 1.3, — эффективность от Hyper-threading ниже, но общая производительность всё равно выше. Разница в результатах между D2700 и D525 пропорциональна частоте.
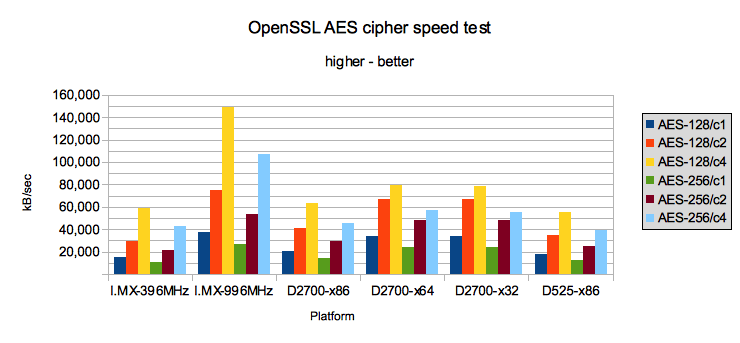
i.MX наконец-то неожиданно вырывается сильно вперёд. Возможно это объясняется тем, что алгоритм требует гораздо больше вычислительных ресурсов, а требования к памяти ниже.
В стане Atom-ов разница в работе Hyper-threading стала ещё более выраженная. Чем оптимальнее/быстрее код, тем меньше выигрыш от виртуальных ядер. Скорее всего дело в in-order архитектуре — чем полнее один поток загружает ресурсы ядра, тем меньше останется на второй.
В бой
Для тестирования на 4-х системах был поднят nginx с одинаковым конфигом и данными. Три виртуальных сервера с одним root-ом, но разными настройками: обычный на 80-ом порту, SSL с шифрованием RC4 на 443-ем, и SSL с AES-256 на 444-ом.
Статистика собиралась с помощью утилиты Apache Bench.
Вот этим скриптом
#!/bin/bash HOST="test.XXXX.net" CONQS="1 2 4 10 100 1000" PREFS="http://${HOST} https://${HOST} https://${HOST}:444" AB="ab -d -k -n 1000" for P in ${PREFS}; do URL="${P}/plain/test.htm" echo ${URL} echo "Plain HTML" for C in ${CONQS}; do echo -n "C=${C} : " ${AB} -c ${C} "${URL}" 2>&1 | grep "Transfer rate:" | awk '{print $3}' done echo "Gzipped HTML" for C in ${CONQS}; do echo -n "C=${C} : " ${AB} -H "Accept-Encoding: gzip" -c ${C} "${URL}" 2>&1 | grep "Transfer rate:" | awk '{print $3}' done URL="${P}/plain/test.jpg" echo ${URL} for C in ${CONQS}; do echo -n "C=${C} : " ${AB} -c ${C} "${URL}" 2>&1 | grep "Transfer rate:" | awk '{print $3}' done done CONQS="1 2 4 10 100" AB="ab -d -k -n 100" for P in ${PREFS}; do URL="${P}/plain/test.bin" echo ${URL} for C in ${CONQS}; do echo -n "C=${C} : " ${AB} -c ${C} "${URL}" 2>&1 | grep "Transfer rate:" | awk '{print $3}' done done
Раунд первый — статический HTML-файл
Тут и дальше скорость указана в килобайтах в секунду, как её выдаёт ab, т. е. 20,000 kB/sec — это 20 МБ/с
/cXX показывает количество одновременных сессий (concurrency).

Очень сильно удивляет отставание i.MX-систем. Да, 100 мегабит они дают (и для моих задач этого достаточно), даже целых 500, но почему не гигабит, как Atom-ы? Несложная вроде задача, про которую говорят «как два байта переслать». Заменил патчкорд, порт, разные настройки в ядре — тоже самое. Потом порылся по профильным форумам, и вот засада — это, оказывается, аппаратный баг, который софтом не лечится.
Раунд второй — статический HTML-файл со сжатием
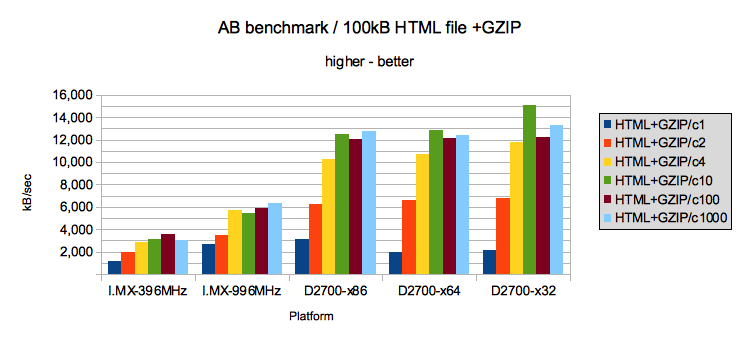
Atom-ы уверенно выигрывают. X32 ABI показывает небольшое преимущество.
Раунд третий — статический HTML-файл со сжатием и шифрованием RC4

Раунд снова за Atom-ами. Огромное превосходство х64 над х86. Хорошо заметен прирост в новомодном х32 ABI.
Раунд четвёртый — статический HTML-файл со сжатием и шифрованием AES-256

64-битные Atom-ы впереди. Совершенно необъяснимо «выстреливает» х64 система. i.MX немного опередил х86!
Раунд пятый — JPEG файл

Раунд шестой — JPEG файл с шифрованием RC4
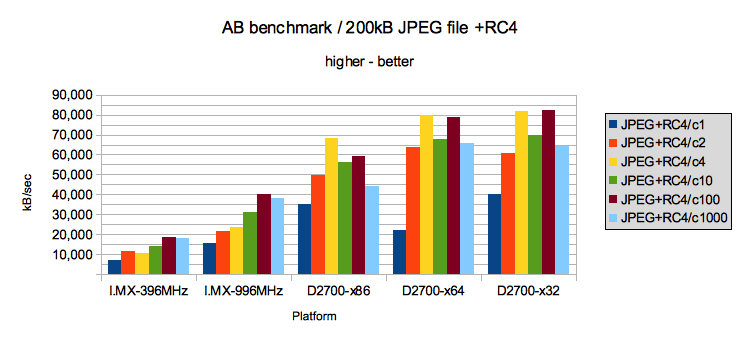
Раунд седьмой — JPEG файл с шифрованием AES-256
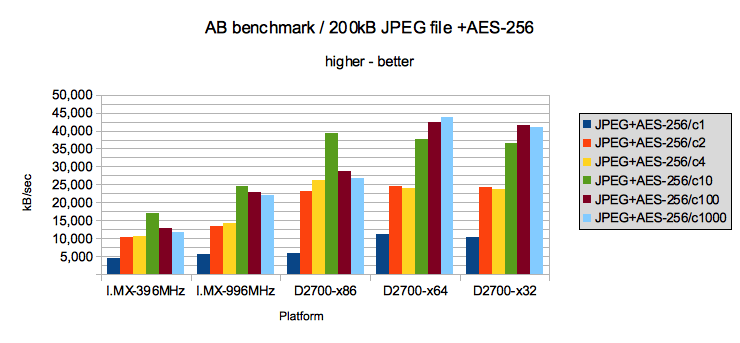
Раунд восьмой — большой файл размером 100МБ
Тут произошёл первый нокдаун — i.MX начал постоянно зависать. Потрогал крышку, очень горячая, по датчикам — 73°.
Наклеил радиатор
Оставшиеся три раунда прошли без проблем.В принципе, их можно было и не проводить, т. к. результаты полностью совпадают с тестами JPEG-ов, которые, в свою очередь, похожи на тест со статическим HTML.
Результаты
По очкам побеждает Atom.
Но оказывается, для моих скоромных задач в виде забивания 100-мегабитного канала, вполне хватает i.MX-а на 400MHz. Ну а фронтэндом (раздающим пожатый и шифрованный HTML) ему пока не быть.
Если верить заявлениям ARM-а относительно производительности A15, в том числе и подсистемы памяти, то вероятно победителем вышел бы Cortex-A15.

