От переводчика
Это перевод статьи Drew Crawford «Why mobile web apps are slow», опубликованной 09 июля 2013. Статья очень интересная, но большая — ошибки возможны — прошу простить и присылать замечания в личку.
Поскольку затронута острая тема, прошу заметить, что переводчик не обязательно разделяет мнение автора статьи!
При переводе текст слегка видоизменялся, поскольку прямой перевод не всегда понятно передает смысл. Для перевода термина «native code» был использован англицизм «нативный код», который понятнее и короче, чем «родной для платформы код». Термин «word processing» переводится как «верстка текста», хотя это немного сужает первоначальный смысл. Термин managed код («управляемый код») не был переведен, так как удачного перевод (на взгляд переводчика) не существует. Под «терминированием» приложения подразумевается его принудительное завершение операционной системой.
Повествование в статье ведется от первого лица: автора статьи.
Реакцией на мою предыдущую статью (утверждающую, что веб-приложения на мобильных платформах работают медленно) явилось необычно высокое количество интересных обсуждений. Из статьи, как из искры, разгорелось пламя дискуссии, протекавшей как в Сети, так и в реальной жизни. К сожалению, эта дискуссия не так сильно опиралась на факты, как хотелось бы.
В этой статье я собираюсь привести фактические подтверждения, связанные с обсуждаемой проблемой, вместо того, чтобы играть в игру «кто кого перекричит». Вы увидите сравнительные тесты, услышите мнения экспертов и даже сможете прочесть «искренние-как-на-исповеди» заметки из тематических журналов. В этой статье более 100 цитат, и это — не шутка. Я не гарантирую, что эта статья вас переубедит, более того, даже не гарантирую, что все в ней абсолютно достоверно (это невозможно сделать в статье такого размера), но зато я могу гарантировать, что это наиболее полный и объективный подход к проблеме, которую уже осознали многие iOS разработчики: что веб-приложения на мобильных платформах работают медленно и будут работать медленно в обозримом будущем.
Сразу хочу предупредить — статья нереально большая, более 10000 слов. Так оно и задумывалось. Последнее время я предпочитаю содержательные статьи популярным. Эта статья — вклад в копилку содержательных статей — как попытка практиковать то, что я сам ранее проповедовал: следует поощрять глубокие, основанные на доказательной базе дискуссии в противовес написанию пустых, но остроумных комментариев.
Статья написана сухим языком, потому что исследуемая тема уже много раз обсасывалась в разных формах. Если вы хотели прочесть 30-секундный треп на тему «мобильные веб-приложения сосут!»/«черт! нет», эта статья не для вас (от переводчика: здесь в исходной статье приводится масса ссылок на подобные англоязычные обсуждения). С другой стороны, насколько мне известно, не существует полного, объективного, доказательного обсуждения этой проблемы в Сети. Может и глупая затея, но эта статья является попыткой говорить доказательно и содержательно о проблеме, 100% обсуждений которой обычно сводятся к холивору. В свою защиту могу сказать, что верю, что это происходит не из-за самой проблемы, а из нежелания улучшить качество дискусии ее участниками. Полагаю, что мы выясним, так ли это.
Итак, если вы мучительно пытаетесь понять чего обкурились ваши друзья — нативные разработчики мобильных приложений — упорно пишущие порочные, нативные приложения, находясь на вершине эры веб-революции, то заносите статью в закладки, наливайте себе кофе, освобождайте утро, находите удобное кресло и будем готовы.
КРАТКИЙ ОБЗОР
Моя предыдущая статья, основываясь на тестах производительности SunSpider, утверждала, что, на текущий момент, веб-приложения на мобильных платформах работают медленно:
«Если под 'веб-приложением' подразумевается 'страница с парой кнопок', то уютные тесты производительности, подобные SunSpider, вполне сгодятся. Но заниматься легковесной обработкой фотографий, легковесной версткой текста, хранением данных на стороне пользователя и анимацией между экранами в веб-приложении, запущенном на архитектуре ARM, следует только по одной причине: если вашей жизни угрожает смертельная опасность.»
Вам следует прочесть ту статью, но, в любом случае, вот результаты тестов:

Есть три существенные категории возражений по поводу этого графика:
1. Факт, что JS работает медленнее нативного кода, не является новостью: это известно всем со времен CS1 и обсуждений компилируемых, JIT и интерпретируемых языков. Вопрос лишь в том — не слишком ли медленно JS работает для вашей конкретной задачи — и синтетические тесты не дают ответа на этот вопрос.
2. Да, JS работает медленее и это мешает, но он становится все быстрее и рано или поздно он станет настолько быстр, что потянет вашу задачу (см. пункт 1), так что пора начинать инвестировать в JS.
3. Я пишу серверный код на Python/PHP/Ruby и понятия не имею, о чем это вы все говорите. Я знаю, что мои серверы побыстрее, чем ваши мобильники, но я-то уверенно держу X,000 пользователей, используя интерпретируемый язык программирования, а вы не можете сообразить, как одного удовлетворить на JIT-языке?
У меня заоблачная цель — хочу опровергнуть все эти три утверждения в этой статье! Да, JS медленный настолько, что становится непригодным; нет, он не станет существенно быстрее в ближайшие годы; нет, ваш опыт серверного программирования на скриптовых языках невозможно перенести адекватно на мобильные платформы.
Как правило, в подобных статьях «слона-то и не приметили», то есть никто не попробовал реально измерить насколько JS медленнее или предложил бы полезный, пригодный способ это сделать (ну вы понимаете… медленный, по сравнению с чем?). В этой статье я приведу не один, а целых три способа измерения эквивалентности производительности по отношению к производительности JS. Так что, не просто буду болтать языком «бла бла JS тормозит», но приведу измерительные сравнения по отношению к нескольким задачам, с которыми вы реально сталкиваетесь как разработчики, так что сможете сами посчитать — хватит ли производительности для вашей конкретной задачи.
ЛАДНО, НО КАК ТОЧНО ИЗМЕРИТЬ ПРОИЗВОДИТЕЛЬНОСТЬ JAVASCRIPT ПО ОТНОШЕНИЮ К НАТИВНОМУ КОДУ?
Хороший вопрос. Чтобы дать на него ответ, я выбрал случайный тест производительности у The Benchmarks Game. Затем нашел старую C программу, которая делает тоже самое (старую, поскольку новые содержат всякие x86 оптимизации). Затем померял производительность Nitro (от переводчика: JS-движок Safari) по отношению к LLVM на моем верном iPhone 4S. Весь код доступен на GitHub.
Да, это все очень случайный код. Но и в реальной жизни код не менее случаен. Хотите провести эксперимент получше — флаг вам в руки. Я провел этот эксперимент просто по той причине, что других подобных (сравнивающих Nitro и LLVM) не нашел.
В любом случае, в данном синтетическом тесте LLVM (от переводчика: то есть нативный код) примерно в 4.5 раз быстрее Nitro (от переводчика: JavaScript-кода).

Так что, если вы задаетесь вопросом — «насколько быстрее работает моя функция, исполняемая нативно, в сравнении с исполнением ее на Nitro JS», то ответ такой: она работает примерно в 5 раз быстрее. Этот результат приблизительно соответствует результатам Benchmarks Game, где сравниваются x86/GCC/V8. Они утверждают, что GCC/x86 работает в среднем от двух до девяти раз быстрее чем V8/x86. Так что полученный мной результат не выпадает из картины мира, причем верен и для архитектуры ARM, и для x86.
НО РАЗВЕ 640 КБ ПАМЯТИ 1/5 ПРОИЗВОДИТЕЛЬНОСТИ НЕДОСТАТОЧНО ДЛЯ ВСЕХ?
Вполне достаточно на x86. Ну, правда, ну насколько же ресурсоемко вывести табличку? Не сильно. Одна проблема: ARM — это не x86.
Согласно GeekBench, последний MacBook Pro быстрее последнего iPhone на порядок. Ну и ладно, на таблички все равно хватит. Достаточно нам 10% производительности. Секунду! Вы эти 10% не забыли поделить еще на 5? Итак, в сухом остатке имеем всего 2% производительности от десктопа (я немного небрежно округляю единицы измерения, но для наших рассуждений точности хватит).
Ну, хорошо, но насколько в действительности ресурсоемким является верстка текста? Разве ею не занимались еще на m68k? Что ж, на этот вопрос легко ответить. Может вы и не помните, но совместная работа с документами появилась в Google Docs не сразу. Они значительно переписали код и добавили эту фичу в апреле 2010 года. Давайте посмотрим на производительность браузеров в далеком 2010:
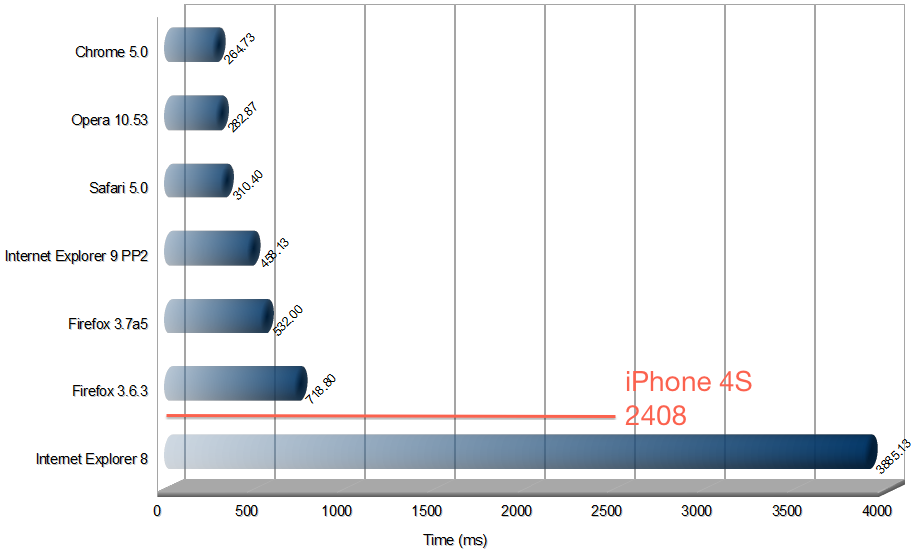
Этот график отчетливо показывает, что iPhone 4S не может соперничать с браузерами на момент времени, когда Google добавил совместную работу с документами. Ну, то есть IE8 он обгоняет, поздравляем!
Давайте посмотрим на еще одно серьезное JS-приложение: Google Wave. Wave никогда не работала в IE8 (согласно Google), потому что он был слишком медленный.
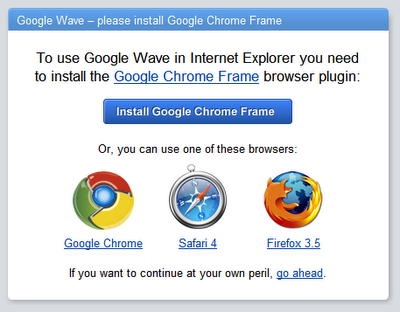
Обратите внимание, что поддерживаемые браузеры уложились в 1000, а тот, который выдал 3800, был исключен, потому что медленный. iPhone выдает 2400. И, как и IE8, недостаточно производителен, чтобы запустить Wave.
Для ясности: совместная работа с документами на мобильных устройствах — возможна. Но только не на JS. Разница в производительности между нативным и веб приложением сравнима с разницей производительности между FireFox и IE8 и является слишком большой для серьезной работы.
НО МНЕ КАЗАЛОСЬ, ЧТО ПРОИЗВОДИТЕЛЬНОСТЬ V8/СОВРЕМЕННОГО-JAVASCRIPT СРАВНИМА С ПРОИЗВОДИТЕЛЬНОСТЬ ПРИЛОЖЕНИЯ НА C?
Зависит от того, что считать «сравнимым». Если C-программа выполняется за 10 мс, то 50 мс программа на JS может считаться «сравнимой». Но если C-приложение занимает 10 сек, то 50 сек JS приложение для большинства уже несравнимо с ним.
ВЗГЛЯД СО СТОРОНЫ АППАРАТНОГО ОБЕСПЕЧЕНИЯ
Отставание в 5 раз, вообщем, не страшно на платформе x86, потому что x86, для начала, на порядок быстрее ARM. Есть запас. Решение просто: повысить производительность ARM в 10 раз и — вуаля — получим производительность десктопа на мобильном девайсе.
Осуществимость этого так или иначе крутится вокруг вашей веры в Закон Мура, который пытается ускорить чип, работающий на 80 г батарейке. Не являясь инженером аппаратного обеспечения, я работал на крупную полупроводниковую компанию и ее работники говорили мне, что производительность в текущий момент это результат техпроцесса (вот этой вот фигни, которую меряют в нанометрах). Впечатляющий рост производительности iPhone 5 в большей степени вызван уменьшением техпроцесса — с 45 нм до 32 нм — примерно на треть. Чтобы повторить этот шаг Apple придется уменьшить техпроцесс до 22 нм.
На всякий случай, отметим, что Intel-овский процессор Atom следующего поколения (Bay Trail) — на техпроцессе 22 нм — еще не существует. И Intel пришлось изобрести совершенно новый тип транзистора, так как старый просто не мог работать на 22 нм. Как думаете они лицензируют эту технологию ARM? Подумайте снова. Есть только планы по строительству 22 нм фабрик и большинство их контролируется Intel.
На самом деле, ARM уменьшит техпроцесс до 28 нм в следующем году или около того (следите за A7), а Intel готовится к переходу на 22 нм (а может и на 20 нм) чуть позже. На аппаратном уровне я гораздо больше готов поверить в том, что x86 вставят в мобильник раньше, чем появится ARM-чип со сравнимой производительностью.
Замечания от бывшего инженера Intel:
Я — бывший инженер, который работал над микропроцессорами для мобильной платформы и позже над Атомами. Мое (невероятно предвзятое) мнение: проще будет воткнуть x86 в телефон, отказавшись от части функционала, чем нарастить производительность ARM до сравнимой с x86, добавляя в него функционал с нуля.
Замечание от инженера робототехники:
Вы абсолютно правы, когда говорите, что не будет значительного роста производительности, и что Intel получит более производительный мобильный процессор только через несколько лет. На самом деле, мобильные процессоры уперлись в предел, в который раньше уперлись десктопные процессоры, когда достигли частоты ~3 Ghz: дальнейшее увеличение частоты влечет за собой резкий рост потребляемой мощности и это правило будет действовать и для следующих процессов, хотя они немного увеличат IPC (на 10-20 %). Упершись в этот предел, десктопные процессоры стали многоядерными, но мобильные системы-на-чипе уже многоядерные, так что легкой прибавки производительности не будет.
Так что, может Закон Мура и выполняется, но при условии, что вся мобильная экосистема перейдет на x86. Это не является абсолютно невозможным — так делали раньше. Но в тот момент продажи составляли примерно миллион устройств в год, а сейчас за один квартал продается 62 миллиона. Это было сделано с помощью виртуализации, которая эмулировала старую архитектуру на уровне 60% производительности, в то время как современные гипотетические виртуализации для оптимизированного (O3) ARM кода ближе к 27%.
Чтобы верить, что производительность JS рано или поздно перестанет быть проблемой, проще всего идти по аппаратному пути. Либо в течение лет пяти у Intel появится жизнеспособный чип для iPhone (что вероятно) и Apple перейдет на него (что маловероятно), либо ARM-ы подтянутся за следующую декаду (спросите 10 инженеров на этот счет и получите 10 мнений). Но декада все же большой срок, на мой взгляд, для чего-то, что выстрелит.
Боюсь, что мое знание аппаратной части здесь заканчивается. Если хотите верить, что ARM догонит x86 за 5 лет, то первый шаг — найти кого-то, кто работает на ARM или Intel и кто согласится с вами. Я со многими подобными инженерами проконсультировался и все они отклонили это утверждение. Из чего следует, что этого, скорее всего, не произойдет.
ВЗГЛЯД СО СТОРОНЫ ПРОГРАММНОГО ОБЕСПЕЧЕНИЯ
Многие компетентные программисты совершают одну и ту же ошибку. Они размышляют следующим образом: JavaScript уже стал намного быстрее, чем был! И он будет становится все быстрее и быстрее!
Посылка верна. JavaScript серьезно ускорился. Но мы находимся в данный момент на пике производительности JavaScript. Дальнейшее ускорение вряд ли возможно.
Причина? Для начала, отметим, что большинство улучшений JS за его историю на самом деле связаны с аппаратной частью. Jeff Atwood пишет:
Я обнаружил, что производительность JavaScript выросла с 1996 по 2006 в 100 раз. Построение Web 2.0 «на скелете» JavaScript стало возможным, в основном, по причине роста производительности по закону Мура.
Если связать рост производительности JS с ростом производительности аппаратной платформы, то, не следует ожидать значительного роста программной производительности в ближайшем будущем. Хотите или нет, но если вы верите, что скорость JS возрастет, то наиболее вероятно, что это произойдет из-за роста аппаратной производительности, поскольку таковы исторически тренды.
Как насчет JIT (от переводчика: виртуальные машины, ускорившие исполнение JS)? V8, Nitro/SFX, TraceMonkey/IonMonkey, Chakra и прочая? Ну, в момент своего появления они сыграли свою роль, но все же не настолько большую, как вам хотелось бы думать. V8 вышел в свет в сентябре 2008 года. Я раскопал копию Firefox 3.0.3 примерно из того же промежутка времени:

Вы только не поймите меня неправильно — 9-ти кратный рост производительности — не шутка; в конце концов, примерно такая разница в мощности между ARM и x86. Однако, разница в производительности между Chrome 8 и Chrome 26 — это пологая кривая, потому что с 2008 года ничего революционного здесь не случилось. Остальные производители браузеров подтянулись — где-то чуть медленнее, где-то чуть быстрее, но никто не смог серьезно улучшить скорость кода с той поры.
НАБЛЮДАЕТСЯ ЛИ РОСТ ПРОИЗВОДИТЕЛЬНОСТИ JAVASCRIPT В НАСТОЯЩЕЕ ВРЕМЯ?
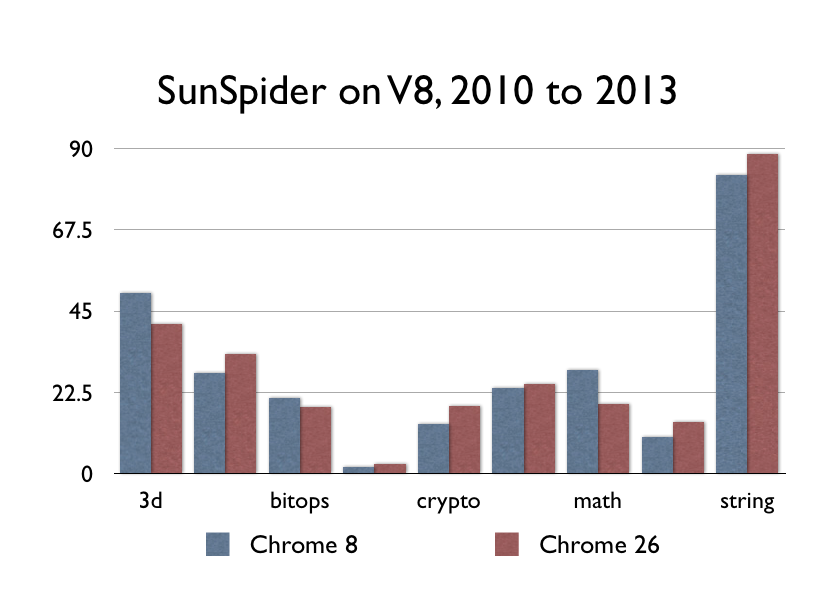
Вот Chrome 8 на моем Маке (самый ранний из тех, что еще работают, декабрь 2010). А вот Chrome 26.
Можете заметить разницу? Потому что ее нет. В последнее время не случилось ничего революционного в коде, который исполняет JavaScript.
Если вам кажется, что веб ускорился в сравнении с 2010 годом, то это, скорее всего, следствие того, что ваш компьютер работает быстрее и никак не связано с улучшениями Хрома.
ЗАМЕЧАНИЕ. Некоторые умники отметили, что тест SunSpider не годится в текущее время (не приводя конкретных доказательств). В интересах истины, я запустил Octane (старый тест производительности от Google) на старых версиях Хрома и увидел некоторые улучшения:

На мой взгляд, прирост производительности за этот период слишком мал, чтобы утверждать, что JS догонит нативный код за разумный период времени. Честно признаюсь, что немного перебрал: производительность JS подросла за этот период. Однако, на мой взгляд, эти цифры все равно подтверждают мою гипотезу: что JS не догонит нативный код за разумное время. Нужно увеличить производительность от 2 до 9 раз, чтобы догнать LLVM. Улучшения есть, но они недостаточны. КОНЕЦ ЗАМЕЧАНИЯ.
На самом деле, идее — ускорить JS с помощью JIT — 60 лет и за этот срок были проделаны всевозможные исследования и тысячи оптимизаций для всех мыслимых языков программирования. Но этому пришел конец, ребята, мы выжали из этих идей все, что было можно. Конец фильма. Может за последующие 60 лет придумаем что-то новое.
НО SAFARI ОЧЕВИДНО РАБОТАЕТ БЫСТРЕЕ, ЧЕМ РАНЬШЕ
Но если все так, как вы говорите, отчего постоянно мы слышим о значительном росте производительности JS? Каждую неделю кто-то говорит об очередном ускорении в очередном тесте производительности. Вот Apple утверждает, что добилась потрясающей прибавки скорости в 3.8 раз на тесте JBench:
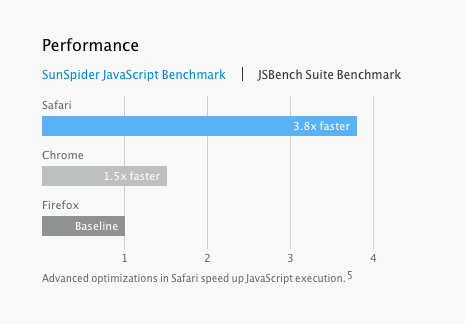
Возможно, на руку Apple тот факт, что эта версия Safari еще находится под соглашением NDA (от переводчика: о неразглашении), так что никто другой не в состоянии опубликовать независимые измерения. Но позвольте мне сделать кое-какие выводы, основываясь исключительно на публичной информации.
Мне кажется довольно забавным, что заявленная Apple производительность JS в тесте JSBench гораздо выше, чем заявленная производительность в традиционных тестах, таких как SunSpider. За JSBench стоят известные личности, такие как Brenden Eich (создатель JavaScript). Однако, в отличие от традиционных тестов, JSBench не использует программы, которые умножают числа или делают что-то подобное. Вместо этого, JSBench всасывает то, что выдают Amazon, Facebook, и Twitter, и строит свои тесты производительности на этой основе. Если вы пишете браузер, который большинство используют, чтобы ходить на Facebook, то, разумеется, иметь тест, который имитирует Facebook, будет весьма полезно. С другой стороны, если вы пишете табличное приложение, игру или графический фильтр, мне кажется, традиционный тест производительности с его умножениями и вычислениями хэшей md5 будет гораздо более адекватным и полезным, чем информация о том, насколько быстро работает аналитика Facebook.
Другим важным фактом является тот, что улучшение в тесте SunSpider (по заявлениям Apple) не означает, что автоматически все остальное ускорится. В заметке, представляющей предпочитаемый Apple тест производительности, Eich и прочие пишут:
Эта диаграмма отчетливо показывает, что, согласно тесту SunSpider, производительность FireFox возросла в 13 раз от версии 1.5 до версии 3.6. Однако, если посмотреть на производительность в тесте amazon, то здесь видим умеренный рост в 3 раза. Что любопытно, за последние два года роста производительности в тесте amazon практически не наблюдается. Полагаю, что многие оптимизации, которые отлично сработали в тесте SunSpider, не играют роли для теста amazon.
В этой заметке создатель JavaScript и один из топ-архитекторов Mozilla открыто признается, что за последние два года с производительностью JavaScript в тесте Amazon не случилось вообще ничего, более того — за всю историю не случалось ничего революционного. Это пример того, как ребята из отдела по маркетингу немного переоценивают вещи в последнее время.
(Они продолжают настаивать, что тест Amazon лучше помогает предсказать время работы Amazon, чем тест SunSpider [ привет К.О.! ], так что он полезен для браузеров, которые люди используют, чтобы ходить на Amazon. Но ничто из этого не поможет вам написать веб-приложение для обработки фотографий).
Во всяком случае, основываясь на публично доступной информации, хочу отметить, что заверения Apple в 3.8-ном росте производительности никакой пользы вам не принесут. Также должен сказать, что, даже имея на руках тесты, в которых опровергается утверждение Apple, что Safari обгоняет Chrome, я бы не имел права их публиковать.
Давайте завершим этот раздел заключением, что даже если кто-то нарисовал график, на котором его браузер стал быстрее, это совершенно необязательно означает, что JavaScript в целом становится быстрее.
Но есть и более крупная проблема.
СПРОЕКТИРОВАН НЕ ДЛЯ ВЫСОКОЙ ПРОИЗВОДИТЕЛЬНОСТИ

(от переводчика: левая книга называется «JavaScript: хорошие стороны», правая — «JavaScript: полный справочник»).
Процитируем Herb Sutter, крупную величину в мире современного C++:
Этот мем уже невозможно уничтожить — «просто ждите следующего поколения (JIT или обычных) компиляторов и уж на них managed код будет работать сравнимо эффективно». Да, я жду улучшений компиляторов C# и Java — и JIT, и NGEN-подобных статических компиляторов. Но, нет, они не сотрут разницу в производительности с нативным кодом по двум причинам. Во-первых, JIT компиляция не является главной проблемой. Основная причина отставания является более фундаментальной: managed платформы были намеренно спроектированы для увеличения продуктивности программиста, даже если это шло в ущерб производительности. В частности, создатели managed платформ решили затрачивать ресурсы на определенные возможности, даже если те не используются приложением; основные из таких фич: всегда работающая сборка мусора, система исполнения виртуальной машины и метаданные. Но не только это, есть и другие примеры: в managed языках вызовы функций по умолчанию виртуальны, в то время как в C++ вызовы по умолчанию inline-ятся (от переводчика: то есть тело функции напрямую компилируется в код вместо call/ret) и ложка предотвращения inline-а стоит бочки девиртуализующей оптимизации.
Эта цитата принадлежит Miguel de Icaza из проекта Mono, который входит в довольно небольшой список «людей, разрабатывающих JIT-компилятор». Он говорит:
Это довольно точное определение отличия популярных виртуальных машин для managed языков (.NET, Java и JavaScript). Дизайнеры managed платформ предпочли безопасность производительности при их проектировании.
Или спросить Alex Gaynor, который поддерживает проект оптимизирующего JIT для Ruby и также учавствует в проекте оптимизирующего JIT для Python:
Это проклятие высокопродуктивных, динамических языков. В них слишком легко сделать хэш-таблицу. (от переводчика: полагаю, тут имеется в виду встроенная возможность таких языков по динамическому расширению объектов именованными свойствами) И это здорово, потому что C-программисты недооценивают хэш-таблицы, так как в C их трудно использовать. Для начала нет встроенного функционала. Во-вторых, использование хэш таблиц в C — это хождение по мукам. В противоположность этому, программисты на Python, Ruby, JavaScript склонны излишне часто использовать хэштаблицы, потому что это так доступно и просто… В результате, людям все равно…
Google, похоже, считает, что JavaScript уперся в стену ограничения роста производительности:
Сложные веб-приложения — на которых специализируется Google — упираются в недостатки платформы и основаны на языке, который нельзя оптимизировать и который имеет врожденные проблемы с производительностью.
Наконец, послушайте Самого. Один из моих читателей указал мне на этот комментарий Brendan Eich. Ну, знаете, это тот самый парень, который изобрел JavaScript.
Одну вещь Mike забыл упомянуть: упростите язык. Lua намного проще, чем JS. Это значит, что можно сделать более простой интерпретатор, который работает достаточно быстро, чтобы сравниться с производительностью JIT-кода (что невозможно для JS)
И немного пониже:
По поводу различий между JS и Lua, можете сказать, что дело в правильном дизайне и проектировании (ну а в чем еще?), но неотъемлемые трудности, связанные с разными направлениями дизайна, очень много значат. Вы, конечно, можете убрать ресурсоемкие места из часто исполняемых кусков кода, но они все равно останутся непроизводительными. В JS таких мест больше, чем в Lua. Один пример: в Lua (если явно не использовать metatable) нет ничего похожего на прототипную цепочку вызовов JS.
Итак, мнение о том, что JS (в частности) или динамические языки (в общем) догонят C, среди людей, которые и занимаются этим самым, является непопулярным. Есть некоторое кол-во несогласных, но никакого общего мнения — что с этим делать (и нужно ли вообще что-то делать) — нету. Но на вопрос «подтянутся ли JIT-машины в общем по производительности к программам на C» ответ людей, которые над этим работают, такой: «нет, если только не сменить язык или API».
Но существует проблема еще важнее.
ВСЯ ПРАВДА О СБОРЩИКЕ МУСОРА

Дело в том, что проблема производительности, связанная с вычислительной мощностью — и все тесты на этот счет, и все инженерные решения — это только одна сторона медали. Другая — это память. И, может статься, что проблема с памятью настолько велика, что вопрос вычислительной производительности — это как верхушка айсберга. На самом, деле обсуждение вычислительных проблем призвано только отвлекать внимание от настоящих проблем. Далее написано то, что, возможно, серьезно изменит ваше представление о разработке мобильных приложений.
В 2012 Apple сделала забавный и неожиданный ход (неожиданный для вас, если только вы не John Gruber и предсказывали это). Они удалили сборщик мусора из OSX. Кроме шуток, читайте руководство программиста. В правом верхнем углу жирным шрифтом написано «Не рекомендуется к использованию». Если вы пришли из мира Ruby, или Python, или JavaScript, или Java, или C#, да из любого языка, созданного после 1990, то это известие, должно быть, вас ошеломит. Не затронет, поскольку вы вряд ли пишете под Маками на ObjC. Но, все же, покажется странным. В конце-то концов, сборщики мусора уже давно с нами и проверены временем. Какого хрена их объявляют устаревшими? Вот, что говорит Apple:
Мы настолько уверены, что ARC является правильным подходом к управлению памятью, что решили отказаться от Сборщика Мусора в OSX (- Session 101, Platforms Kickoff, 2012, ~01:13:50)
О чем умалчивает эта цитата? Об аплодисментах аудитории после нее. Ладно, вот это по-настоящему странно. Вы хотите сказать, что комната забита разработчиками, которые торжественно приветствуют возвращение хаоса «эры-до-сборщиков-мусора»? Вы только представьте себе реакцию зала на заявление Matz-а об отказе от сборщика мусора на RubyConf. А эти радуются? Психи.
Не спешите списать это на эппл-бойство, такая странная реакция должна навести вас на мысль — тут что-то недосказано. И мы попробуем как раз сейчас разобраться, что именно.
Итак, мы размышляем: отказ от работающего сборщика мусора в языке — это безумие, не так ли? Наверное, попросту ARC — это специальный маркетинговый термин Apple для разукрашенного сборщика мусора, так что все эти разработчики на самом деле рады апгрейду, а не даунгрейду. Кстати, это мнение сильно распространено среди новичков в iOS.
ARC НЕ ЯВЛЯЕТСЯ СБОРЩИКОМ МУСОРА
Всем, кто уверен, что ARC — это сборщик мусора, врежу по физиономии вот этим слайдом от Apple:

(перевод слайда:
Чем НЕ является ARC:
— новым runtime для памяти;
— автоматизацией malloc, free, и пр.
— сборщиком мусора:
— нет сканирования хипов;
— нет замирания всего приложения;
— нет неопределенного освобождения памяти.
)
Никакой связи с одноименным алгоритмом сборщика мусора. Это не сборщик мусора, не похоже на сборщик мусора, работает не как сборщик мусора, нет возможностей как у сборщика мусора, ничего не сканируется, не чистится, не тормозится. Все, точка. ARC — не сборщик мусора.
Этот миф родился в тот момент, когда большая часть документации была под соглашением о неразглашении (но спеки были доступны, так что оправданием это явиться не может) и в блогосфере широко разошлось мнение, что это — правда. Это неправда. Все, прекратите уже.
СБОРЩИК МУСОРА НЕ НАСТОЛЬКО ХОРОШ, НАСКОЛЬКО ВАМ ПОДСКАЗЫВАЕТ ВАШ ОПЫТ
Вот что сказала Apple насчет ARC против GC (сборщика мусора), когда на нее надавили:
Самым главным пожеланием среди тех, что мы могли для вас сделать, является возврат сборщика мусора в iOS. И именно это мы делать не будем. К сожалению, сборщик мусора серьезно уменьшает производительность. Ваше приложение может накопить мусора и превысить допустимый лимит памяти. И сборка мусора начинается в непредсказуемые моменты времени, что приводит к пожиранию ресурса CPU и заминках в интерфейсе пользователя. Именно поэтому, GC не подходит нам на наших мобильных платформах. В противовес GС, прямое управление памятью через retain/release труднее понять и, честно говоря, геморройнее использовать. Но производительность при этом выше и более предсказуема, и поэтому прямое управление было выбрано в качестве базиса для нашей стратегии управления памятью. Потому что, в реальном мире, высокая производительность и плавный интерфейс имеют высокую ценность среди наших пользователей (~Session 300, Developer Tools Kickoff, 2011, 00:47:49).
Но это ж безумие?! Для начала:
1. Это полностью противоречит всему вашему карьерному опыту на десктопах;
2. Windows Mobile, Android, MonoTouch и многие другие похоже вполне удовлетворены GC.
Давайте и на них посмотрим.
СБОРЩИК МУСОРА НА МОБИЛЬНОЙ ПЛАТФОРМЕ ЭТО НЕ ТОЖЕ САМОЕ, ЧТО СБОРЩИК МУСОРА НА ДЕСКТОПЕ
Знаю, что вы думаете. Вы программируете на Питоне уже N лет. Сейчас 2013 год. Проблема сборки мусора полностью и бесповоротно решена.
Вот документ, который вы ищете. Похоже, проблема не совсем решена:
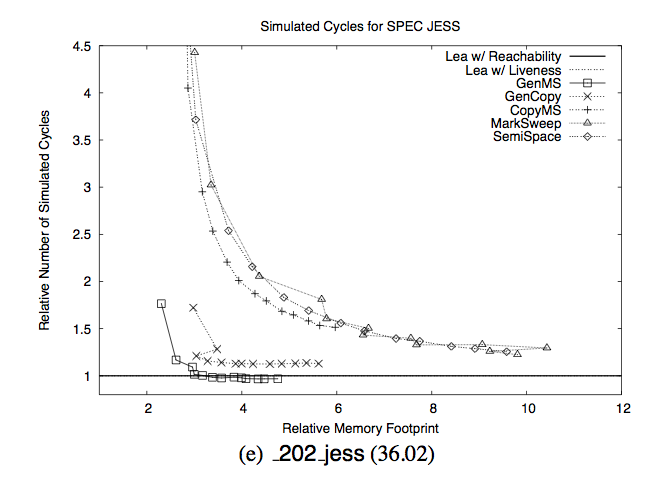
Если у вас из этой статьи в голове останется что-то одно, пусть это будет этот слайд. Ось Y — это время, потраченное на сборку мусора. Ось X — это «относительный расход памяти». Относительный к чему? К минимальному требуемому размеру памяти.
Вот то, что этот слайд нам хочет сказать: «Пока у тебя в 6 раз больше памяти, чем нужно на самом деле, ты — в шоколаде. Но горе тебе, если опустишься ниже 4 размеров требуемой памяти». Необязательно верить мне на слово:
Точнее, когда у сборщика мусора есть в 5 раз больше памяти, чем требуется, его производительность совпадает или слегка превосходит прямое управление памятью. Однако, производительность сборщика мусора быстро деградирует, когда ему требуется работать с небольшими хипами. С 3-мя размерами требуемой памяти он, в среднем, работает на 17% медленнее, а с двумя размерами — на 70% медленнее. Также сборщик мусора более подвержен пейджингу, если память дефрагментирована. В подобных условиях, все протестированные нами сборщики мусора работают на порядок медленнее прямого управления памятью.
Давайте сравним с прямым (явным) управлением памятью:
Эти графики показывают, что, если приложению доступно разумное количество памяти (но недостаточное для того, что уместить приложение целиком), оба менеджера прямого управления памятью значительно превосходят по скорости все сборщики мусора. К примеру, pseudoJBB на 63 Мб доступной памяти и аллокатором Lea завершает задачу за 25 секунд. На таком же количество памяти GenMS требуется в 10 раз больше времени (255 секунд). Похожее поведение наблюдается на всех тестах, входящих в набор. Наиболее отличительный тест — 213 javac: на 36 Мб памяти с аллокатором Lea общее время работы составляет 14 секунд, в то время как время выполнения теста на GenMS составляет 211 сек, что в 15 раз дольше.
Фундаментальный вывод состоит в том, что производительность сборщика мусора в окружении с ограниченным количеством памяти резко снижается. Если вы программируете на Питоне, Руби или JavaScript на десктопах, то, скорее всего, вы всегда находитесь в правой части графика и за всю свою жизнь ни разу не столкнетесь с медленным сборщиком мусора. Переходите на левую сторону, чтобы понять с чем имеют дело остальные.
СКОЛЬКО ПАМЯТИ ДОСТУПНО ПРИЛОЖЕНИЮ НА IOS?
Точно сказать трудно. Размер физической памяти на устройствах разнится от 512 Мб на iPhone 4 до 1 Гб на iPhone 5. Но большая часть этой памяти используется системой и также под многозадачность. Единственный способ проверить — запустить в реальных условиях. Jan Ilavsky создал приложение для этой цели, но похоже никто до сих пор не публиковал результаты. До сегодняшнего дня.
Важно измерять память в «нормальных» условиях, потому что, если делать это сразу после загрузки, то результаты будут лучше, поскольку нет расходов на страницы, открытых в Safari и тому подобного. Так что я буквально взял свои девайсы, разбросанные по квартире, и прогнал тесты на них.


Чтобы увидеть детали, кликните картинку, но, собственно говоря, на iPhone 4S приложение начинает получать предупреждения о недостатке памяти, выделив примерно 40 Мб, и терминируется на (примерно) 213 Мб. На iPad 3 предупреждение на 400 Мб и терминирование на 550 Мб. Разумеется, это мои результаты — если пользователь слушает фоновую музыку, то памяти может оказаться значительно меньше, но это хоть какой-то ориентир для начала. Вроде немало (213 Мб должно хватить каждому, верно?), но с практической точки зрения недостаточно. К примеру, iPhone 4S делает снимки размером 3264×2448 пикселей. Это примерно 30 Мб данных на один снимок. Это означает получение предупреждения при наличии всего двух снимков в памяти и терминирование приложения, которое держит 7 снимков в памяти. Ах, вы хотели цикл по фотографиям в альбоме написать? Приложение будет закрыто!
Важно подчеркнуть, что на практике весьма часто один и тот же снимок хранится в нескольких местах в памяти. Например, если вы делаете снимок с камеры, то в памяти хранится 1) экран камеры, который отображает то, что она видит 2) снимок, который камера сделала 3) буфер, в котором вы сжимаете изображение в JPEG, чтобы сохранить на диск 4) версию снимка, которую вы хотите показать на следующем экране 5) версию снимка, которую вы загружаете на какой-то сервер.
В какой-то момент вы поймете, что использовать 30 Мб буфер изображения для показа превьюшек — идея не очень хорошая и добавите в приложение 6) буфер для превьюшки на следующий экран 7) буфер, в котором собственно и происходит создание превьюшки в фоне (поскольку делать это в основном потоке нельзя — слишком медленно). И потом вы вдруг поймете, что в действительности требуются превьюшки 5 разных размеров и потихоньку начнете сходить с ума. Одним словом, даже работая с единственной фотографией легко превысить доступный лимит памяти. Можете не верить мне:
Худшая идея при ограниченном количестве памяти — это кэшировать изображения. Когда изображение копируется в контекст вывода или отображается на экране, необходимо декодировать его в битмап. На каждый пиксель в битмапе отводится 4 байта, независимо от размера изображения. Этот битмап «подвешивается» к объекту с исходным изображением и его время жизни совпадает с временем жизни объекта изображения. Так что, если вы кешируете изображения, которые хотя бы раз были отображены на экране, то для каждого вы теперь храните связанный битмап. Поэтому никогда не помещайте UIImages или CGImages в кеш, если только у вас нет очень уважительной (и кратковременной) причины это делать. — Session 318, iOS Performance In Depth, 2011
Да можете даже им не верить. На самом деле, размер памяти, которую ваше приложение выделяет, является верхушкой айсберга. Серьезно, вот слайд, на котором представлен сам айсберг (Session 242, iOS App Performance – Memory, 2012):

(перевод слайда: НЕ ТОЛЬКО ОБЪЕКТЫ
* память хипа
— * +[NSObject] alloc]/malloc
— * объекты/буферы, выделенные фреймворками
* другая память
— * код и глобальные переменные (___TEXT, ___DATA)
— * стеки потоков
— * данные изображений
— * буфера CALayer
— * кеши баз данных
* память, вне вашего приложения
)
И эта свеча горит с обоих концов. Гораздо труднее работать с фотографиями, если у вас всего 213 Мб, в отличие от десктопа. И одновременно спрос на фото-приложения гораздо выше, поскольку у вашего десктопа нет крутой камеры и он не помещается в карман.
Возьмем другой пример. У iPad 3 разрешение дисплея, скорее всего, превышает разрешение вашего монитора (с точки зрения кинематографии этот экран находится в диапазоне между 2K и 4K). Каждый кадр изображения занимает 12 Мб. Если вы не хотите нарушать лимиты памяти, то сможете хранить примерно 45 кадров несжатого видео или анимации в памяти одновременно, что займет 1.5 секунды при 30 FPS, или .75 сек при системных 60 FPS. Случайно поместили в буфер секунду полноэкранной анимации? Приложение будет закрыто. И тут можно еще обратить внимание, что задержка в AirPlay составляет 2 секунды, так что для любого медиа приложения у вас гарантированно не хватит памяти.
И здесь опять возникает та же проблема нескольких копий изображения. К примеру, Apple утверждает, что «с каждым UIView связан CALayer и изображения слоев остаются в памяти, пока CALayer находится в иерархии объектов». Это означает, что в памяти может находится много изображений с промежуточным представлением вашей иерархии представления.
А ведь есть еще прямоугольники отсечения и буферы слоев. Эта замечательная архитектура с точки зрения экономии CPU, но ее производительность достигается за счет выделения как можно большего количества памяти. iOS спроектирована не с точки зрения экономии памяти, а с точки зрения высокой производительности. Что не очень хорошо сочетается со сборкой мусора.
И опять свеча горит с двух концов. У нас не только весьма ограниченное окружение для полноэкранной анимации. Но и огромный спрос на высококачественное видео и анимацию, поскольку это ужасная, малопамятная среда является фактически единственным форм-фактором, в котором можно приобрести высококачественный-кино-дисплей. Если вы хотите создавать программы для подобного разрешения на десктопах, то вначале убедите своих пользователей потратить $700 только на монитор. Или они могут купить iPad за $500, причем в нем уже есть и компьютер.
УВЕЛИЧИТСЯ ЛИ КОЛИЧЕСТВО ДОСТУПНОЙ ПАМЯТИ?
Некоторые умники говорят мне — «ОК, ты убедил, мы не получим более быстрый мобильный CPU. Но кол-во памяти-то вырастет, верно? Выросло же на десктопах».
Проблема этой теории заключена в том, что в ARM память находится на самом процессоре. Эта схема называется package on package (PoP) (от переводчика: чип на чипе). Так что трудности увеличения объемов памяти на самом деле аналогичны трудностям разгона CPU, поскольку сводятся к тому, как вместить больше транзисторов на чип. Транзисторы памяти вмещать немного легче, они одинаковы по размеру, но все равно трудно.
Если вы посмотрите на изображение A6 на сайте iFixit, то увидите, что почти 100% площади на поверхности чипа занято памятью. Это значит, что для увеличения памяти, надо уменьшить техпроцесс или увеличить чип. И если измерять относительно техпроцесса, то увеличение памяти всякий раз связано с увеличением размера чипа:

Кремний — материал не идеальный, так что с увеличением размеров идет экспоненциальный рост стоимости годных чипов. И такие чипы труднее охладить и поместить в мобильник. И у них те же проблемы, что и у CPU, поскольку память — это верхний слой чипа, в который надо впихнуть больше транзисторов.
Чего я не знаю, это отчего производители перед лицом этих проблем с PoP продолжают ее использовать. Я не нашел ARM инженера, который бы мне это объяснил. Может кто-то комментарий напишет. Возможно стоит отказаться от PoP в пользу отдельных модулей памяти как на десктопах. Но раз этого нет, значит есть какая-то причина это не делать.
Однако, мне написали несколько инженеров.
Бывший инженер Intel:
Что касается PoP. Эта архитектура серьезно повышает пропускную способность и упрощает маршрутизацию. Но я не занимаюсь ARM и могу всего не знать.
Инженер робототехники:
Когда станет не хватать PoP, «3D» память сможет дать «достаточно памяти для всех»: чипы памяти, сложенные в стопку, с возможностью разместить более 10 слоев 1 Гб памяти в том же объеме, что и сейчас. Но: затраты возрастут, а вольтаж и частоты придется уменьшить, чтобы уложиться в ограничения мощности.
Пропускная способность мобильной памяти не будет расти так быстро, как росла до этого. Она ограничена кол-вом линий между CPU и памятью. В настоящее время, большая часть периферийных соединений CPU используется для шины памяти. Средняя часть CPU не может быть использована для этого из-за технических ограничений. Следующий прорыв следует ждать от интеграции памяти прямо внутри CPU: при этом вырастет пропускная способность, будет больше свободы проектирования CPU и упадет вольтаж. И возможно появится большой быстрый кэш.
НО КАК ТОГДА MONO/ANDROID/WINDOWS MOBILE УСПЕШНО СПРАВЛЯЮТСЯ С ЭТИМ?
Есть два ответа на этот вопрос. Первый следует из графика (от переводчика: расход памяти сборщиком мусора): если у вас памяти в 6 раз больше, чем нужно, то сборка мусора идет быстро. Если, допустим, вы программируете текстовый редактор, то вполне можете уложиться в 35 Мб, что составляет 1/6 лимита памяти, на котором приложение на iPhone 4S терминируется. Так что можете взять Monо, написать редактор, убедиться, что он работает быстро и посчитать, что сборка мусора вполне шустра. И будете правы.
Да, но на Xamarin в поставку входит симулятор полетов. Выходит, что сборка мусора нормально работает и для больших мобильных приложений? Или нет?
С каким проблемами пришлось столкнуться при разработке этой игры? «Производительность была основной проблемой и продолжает оставаться таковой на всех платформах. Первые Windows Phone были довольно медленные и нам пришлось потратить много времени на оптимизацию, чтобы добиться приемлемого FPS. Эти оптимизации затронули как код симуляции, так и 3D движок. „Узким горлышком“ являются сборка мусора и слабость GPU.»
Без малейшего намека в вопросе разработчики приводят сборку мусора как одно из основных «узких мест» производительности. Если это делают люди в твоей команде разработчиков, стоит задуматься. Но может Xamarin — не типичный пример. Почитаем разработчиков на Андроиде:
Обратите внимание — приложения запускаются на моем Galaxy Nexus — назвать который медленным не поворачивается язык. Посмотрите на время, потраченное на рендеринг. На десктопе эти изображения были созданы за пару сотен мс, в то время как на мобильном устройстве на это было потрачено на два порядка больше времени. Больше 6 секунд на «inferno» (от переводчика: планета со сложным рендерингом)? Безумие!.. За это время сборщик мусора отработает 10-15 раз.
Еще:
Если вы собираетесь заниматься обработкой снимков камеры на устройствах Андроид для распознавания объектов в real-time или для создания Дополненной Реальности, вы вероятно слышали про проблему памяти превью камеры. Всякий раз, когда Java приложение получает картинку предпросмотра, выделяется новый буфер в памяти. Когда этот буфер освобождается сборщиком мусора, система замирает на 100-200 мс. Еще хуже, если система под нагрузкой (я занимаюсь распознаванием изображений — это отъедает весь CPU). Если вы посмотрите исходники Андроид 1.6, то увидите, что это происходит по той, причине, что обертка (которая защищает нас от нативного кода) выделяет новый буфер памяти на каждый новый фрейм. У встроенного нативного кода этой проблемы, конечно, нет.
Или можем почитать Stack Overflow:
Я занимаюсь улучшением производительности интерактивных игра на Java под Андроид. Время от времени в отображении или взаимодействии возникает задержка на сборку мусора. Обычно это длится меньше десятой секунды, но иногда это может занять и 200 мс на медленных устройствах… Если во внутреннем цикле мне вдруг понадобятся хэши, я знаю, что мне надо быть осторожным или вообще переписать их самому вместо использования фреймворка Java Collections поскольку не могу себе позволить лишние сборки мусора.
Вот самый значимый ответ, 27 голосов «за»:
Я занимался мобильными играми на Java… Лучший способ избежать сборки мусора (которая будет происходить в произвольный момент времени и убьет производительность игры) — вообще не создавать объекты в основном цикле. Другого пути нет… Толькохардкорручное управление объектами, увы. Так делают все основные высокопроизводительные игры на мобильных устройствах.
Послушаем Jon Perlow из Facebook:
Сборщик мусора является огромной проблемы для производительности при разработки «плавных» приложений на Андроид. В Facebook одной из основных проблем является замирание потока UI при сборках мусора. Когда вы обрабатываете большое число битмапов, сборка мусора происходит часто и избежать ее невозможно. Одна такая сбора приводит к потере нескольких фреймов. Даже если сборка заблокирует основной поток всего на несколько миллисекунд, это может не позволить сгенерить фрейм в отведенные на это 16 мс.
Почитаем Microsoft MVP:
В нормальной ситуации ваш код отображения уложится в 33.33 мс (от переводчика: на один кадр), поддерживая приемлемые 30 FPS… Однако, сборка мусора отнимает время. Если вы не мусорили на хипе, сборка отработает быстро и не составит проблемы. Но поддерживание хипа «в чистоте», достаточной для быстрой отбработки сборщика мусора — это сложная программистская задача, которая требует тщательного планирования и переписывания кода и при этом все равно не гарантирует устойчивую работу (как правило, в сложной игре на хипе хранится очень много всего). Проще (если возможно) ограничить или, вообще, не выделять память во время процесса игры.
Лучший способ обыграть сборщик мусора — вообще не играть. Это утверждение (в более слабо выраженной форме) находится в официальной документации по Андроид:
Создание объекта не является бесплатным. Сборщик мусора, использующий поколения и пулы на каждый поток, может ускорить выделение памяти, но выделение памяти всегда дороже не выделения памяти. По мере того, как вы выделяете все больше объектов, вы столкнетесь с периодической сборкой мусора, которая вызывает небольшие задержки интерфейса. Сборщик мусора, который появился в Андроид 2.3, работает лучше, но все равно следует избегать ненужной работы. Так что не создавайте объекты, которые вам не нужны… Точнее, не стоит создавать временные объекты, если в этом нет необходимости. Меньше объектов, меньше сборки, что положительно влияет на юзабилити.
Все еще не убеждены. Давайте спросим инженера по Сборке Мусора. Который пишет сборщики. И зарабатывает себе на хлеб этим самым. Короче, это тот парень, которому по работе приходится это все знать.
Однако, с появлением WP7 возможности устройств в терминах производительности CPU и памяти резко выросли. Появились игры и приложения на Silverlight, занимающие по 100 Мб памяти. По мере увеличения доступной памяти число объектов выросло экспоненциально. По схеме (описанной выше) сборщик мусора должен обойти каждый объект и все его ссылки, чтобы пометить их (mark) и позднее очистить (sweep). Так что время, потраченное на сборку мусора, также значительно возросло и стало зависеть от размера «ссылочной сети» приложения. Это привело к очень длительным паузам в случаях больших XNA игр и SL приложений, что приводит к длительной их загрузке (поскольку сборка работает и в это время) и подергиваниям во время игры/анимации.
Все еще не убеждены? У Хрома есть тест, который измеряет производительность сборки мусора. Посмотрим как он справляется…

Видим немалое число остановок, потраченных на сборку мусора. Да, это стресс-тест, но все же. Вы действительно готовы ждать 1 секунду при рендеринге фрейма? Вы с ума сошли.
СЛУШАЙ, ЦИТАТ СЛИШКОМ МНОГО, НЕ МОГУ ИХ ВСЕ ПРОЧЕСТЬ. ДАВАЙ УЖЕ ЗАКЛЮЧЕНИЕ.
Вот заключение: на мобильных устройствах управление памяти дается непросто. iOS сформировала культуру ручного управления большинством вещей, при этом компилятор выполняет простые вещи. Андроид продвигает улучшенную сборку мусора, которой они сами же изо всех сил стараются не пользоваться. В любом случае, при написании приложений под мобильные устройства надо поломать голову над управлением памятью. Этого просто невозможно избежать.
Когда программисты JavaScript или Ruby или Python слышат про «сборку мусора», они думают, что это «сборка мусора» как «палочка-выручалочка». Они думают «сборка мусора дает мне возможность не думать об управлении памятью». Но на мобильных устройствах такой «палочки-выручалочки» нету. Любой программист мобильных устройств вынужден решать задачи управления памятью, независимо от того — есть сборка мусора, или ее нет. Сборка мусора может стать «палочкой-выручалочкой» на мобильных устройствах только тем же способом, что и на десктопах — затратив в 10 раз больше памяти, чем требуется.
Весь дизайн JavaScript основан на утверждении, что о памяти беспокоится не следует. Спросите у разработчиков Хромиума:
есть ли хоть какой-то способ заставить движок хрома выполнить сборку мусора? Вообще говоря — нет и это сделано намеренно.
Спецификация ECMA не содержит слова «выделение памяти» (allocation), единственная ссылка на «память» утверждает, что это полностью зависит от «окружения» (host-defined).
Вики по ECMA версии 6 содержит несколько драфтовых страниц, которые сводятся к следующему (я не шучу):
сборщик мусора НЕ ДОЛЖЕН собирать память, содержимое которой может понадобится для продолжения корректного выполнения программы… Все объекты, которые (сильно) недоступны от корня ДОЛЖНЫ быть очищены, если для продолжения корректной работы приложению не хватает памяти.
Все верно, они действительно внесли в спецификацию следующее утверждение: сборщик мусора не должен собирать объекты, которые не должен собирать, и должен собирать объекты, которые должен собирать. Добро пожаловать в клуб тавтологии. Возможно, для нас более интересной является эта цитата:
Вообще говоря, не существует спецификации на то, сколько действительно памяти занимает объект, и вряд ли такая спецификация появится. По этой причине мы не можем гарантировать, что произвольное приложение не исчерпает доступную память, так что никакой нижней оценки получить невозможно.
По-русски: философия JavaScript (если она вообще есть) заключается в том, что вы не имеет никакого представления о том, что творится в системной памяти, точка. Это настолько невероятно расходится с тем, как в реальности создаются мобильные приложения, что я даже не могу подобрать слов, чтобы выразить свое отношение. Смотрите: во вселенной iOS люди не верят в сборку мусора и считают, что программисты Андроид сошли с ума. Подозреваю, что во вселенной Андроид разработчики считают, что программисты iOS сошли с ума, раз занимаются ручным управлением памятью. Но есть одно мнение, с которым согласны оба лагеря. Программисты JavaScript безумны в квадрате. Есть примерно нулевая вероятность, что вы сможете написать мобильное приложение, не заботясь о расходе памяти. Так что, отложив в сторону тесты производительности SunSpider и прочие вещи, связанные с CPU, мы приходим к заключению, что JavaScript в настоящее время фундаментально противоположен концепции «тщательное-управление-памятью», которая является абсолютно необходимой при программировании под мобильные устройства.
До тех пор, пока пользователи хотят от мобильных устройств видео и фото приложений, которых и на десктопах-то никогда и не было, и до тех пор, пока на мобильных устройствах намного меньше памяти, эта проблема является неразрешимой. Требуются серьезные гарантии управления памятью на мобильных устройствах. И JavaScript не дает их, намеренно.
А ЕСЛИ ВДРУГ ДАСТ?
Теперь вы можете сказать — «ладно, JavaScript парни живут на десктопах и не знакомы с проблемами мобильных приложений. Но может их переубедили. Или кто-то, кто занят мобильными приложениями, форкнул JavaScript. В теории, из этого может что-то выйти?»
Не уверен, что эта задача легко решается, но могу попробовать обрисовать границы. Есть группа людей, которые попробовали форкнуть динамический язык, чтобы он подходил для разработки на мобильных устройствах — и называется он RubyMotion.
Это умные люди, которые хорошо знают Ruby. И эти люди решили, что сборка мусора для их форка языка — это плохая идея (слышите защитники сборки мусора?). Так что они взамен привили к языку нечто, очень похожее на ARC. Но похоже не очень-то вышло:
Заключение: многие разработчики столкнулись с проблемами с памятью, которые являются результатом RM-3 (от переводчика: баг RubyMotion, по утверждениям разработчиков был пофиксен 11 июля 2013) или еще каких-то невыявленных проблем, связанных с выделением памяти в RubyMotion.
Ben Sheldon отмечает:
Не только у вас. Я сам столкнулся с крашами, связанными с памятью (типа SIGSEGV и SIGBUS), которые проявляются у 10-20% пользователей.
Есть определенные сомнения насчет того, можно ли отследить проблему:
Я поднял вопрос о RM-3 на последней встрече и ответили и Laurent, и Watson. Watson заметил, что RM-3 — это самый трудно исправляемый баг, Laurent рассказал, что он попробовал несколько подходов, но ни один не помог. Оба являются сильными разработчиками, которым можно верить.
Есть также сомнение, решается ли это вообще:
Долгое время я считал, что блоками легко может управлять компилятор, то есть содержимое блока можно статически проанализировать, чтобы определить, что блок ссылается на переменную вне своей видимости. Я полагал, что все подобные переменные можно занять при создании блока и освободить при уничтожении блока. Что привяжет время жизни переменной ко времени жизни блока (не полное время жизни, конечно). Но есть одна проблема: instance_eval. Содержимое блока может использоваться раньше времени.
У RubyMotion есть еще проблема — утечка памяти. И может есть и другие проблемы. Никто не может гарантировать, что утечки вызвана 2 или 200 причинами. Все что мы знаем, что пользователи сообщают об утечках. Очень часто.
Что это все значит: что одни из лучших разработчиков мира форкнули Ruby специально для использования на мобильных устройствах и получилась система, которая крэшится и теряет память, что и составляет основной набор ошибок памяти. До настоящего момента исправить это им не удалось, хотя они явно стараются из всех сил. И они же утверждают, что «пробовали несколько раз это починить, но хорошего решения (которое сохраняет производительность) не нашли».
Я не утверждаю, что форкнуть JavaScript, чтобы получить приемлемую производительность при работе с памятью — невозможно. Лишь хочу сказать, что похоже это сделать это очень сложно.
Дополнение. Участник проекта Rust:
Я участвую в проекте Rust, целью которого является безопасная работа с памятью без дополнительных буферов (zero-overhead memory safety). Мы поддерживаем GC-объекты через синтаксис "@-обертки" (описание типа будет "@ T" для любого типа T) и столкнулись с проблемой, которая заключается в том, что сборка мусора затрагивает все аспекты языка. Даже если сборка мусора поддерживается опционально, необходимо тщательно проектировать язык, чтобы не тратить лишнее место на обычные указатели (не управляемые сборщиком). Это нетривиальная проблема, не думаю, что ее можно решить, форкнув JavaScript.
ЛАДНО, ЧТО НАСЧЕТ ASM.JS?
ams.js интересен тем, что предоставляет модель JavaScript, но без сборщика мусора. Теоретически, в «правильном» браузере и с правильными API, может и выгорит. Вопрос в том, получим ли мы «правильный браузер».
Mozilla, являясь автором технологии, разумеется легко согласилась и реализация появится уже в этом году. Реакция Хрома более смешанная. Очевидно, что это конкурирует с собственной разработкой Google: Dart и PNaCl. Есть даже баг на этот счет, но один из хакеров V8 его не любит. Что касается Apple, ребята из WebKit хранят молчание. IE? Тут надежды нет.
В любом случае, не очень ясно, отчего этот Единственно Правильный Пофиксенный JavaScript удовлетворит всем просьбам. Даже если он победит — вряд ли это будет JavaScript. В конец концов, он порожден отказом от сборщика мусора. Так что он может быть похож на C/C++ или другой язык с ручным управлением памятью. Но он точно не будет тем динамическим языком, который мы знаем и любим.
МЕДЛЕННЫЙ ПО СРАВНЕНИЮ С ЧЕМ?
Одна из проблем с утверждениями «X медленный» и «X не медленный» заключается в том, что никто не задает точку отсчета. Если вы программируете веб, то для вас «медленный» значит нечто иное, чем для разработчика высокопроизводительного кластера или разработчика встроенных систем. Ну теперь, когда мы прошли по всем ухабам и проделали всевозможные тесты производительности, я назову три точки отсчета, которые полезны и сравнительно корректны.
Если вы — разработчик веб, смотрите на iPhone 4S Nitro как на IE8, их производительность примерно одинакового класса. Это позволит вам примерно представить как написать код. JS следует использовать очень аккуратно, или вы столкнетесь с различными платформо-зависимыми хаками, которые его разгоняют. Некоторые приложения просто не удастся эффективно реализовать, даже в популярных браузерах.
Если вы — разработчик x86 C/C++, смотрите на разработку веб-приложений на iPhone 4S как на C окружение, которое работает в 50 раз медленнее, чем аналогичное на десктопе. На порядок скорость уменьшает архитектура ARM и еще в 5 раз — JavaScript. Или можете взвесить плюсы и минусы разработки в не-JavaScript среде, которая на порядок медленнее декстопа.
Если вы — разработчик Java, Ruby, Python, C# , смотрите на разработку веб-приложений на iPhone 4S следующим образом. Это компьютер, который на порядок медленнее, чем вы ожидаете (потому что ARM) и производительность экспоненциально падает, если использование памяти превышает 35 Мб в любой момент времени, поскольку именно так ведет себя сборщик мусора на этой платформе. Также приложение будет закрыто, если выделение памяти превысит 213 Мб. И никто не даст этой информации на этот счет в момент выполнения, намеренно. Ах, ну да — и люди еще будут просить создавать приложения, которые обрабатывают фото и видео.
ЭТО РЕАЛЬНО БОЛЬШАЯ СТАТЬЯ
Вот что следует помнить:
* в 2013 году JavaScript является слишком медленным, чтобы его можно было использовать на мобильных устройствах для создания приложений типа обработки фотографий и пр.:
— он в 5 раз медленнее нативного кода;
— он сравним с IE8;
— он медленнее, чем x86 C/C++, примерно в 50 раз;
— он медленнее, чем серверные Java/Ruby/Python/C# примерно в 10 раз, если программа выделяет не больше 35 Мб памяти и резко замедляется при дальнейшем выделении памяти;
* Наиболее реальный способ его разогнать — это увеличить производительность процессора до уровня десктопа. Возможно это и произойдет, но не в ближайшем будущем;
* Сам язык последнее время нисколько не ускорился и его разработчики утверждают, что при сохранении языка и API, производительность никогда не догонит нативный код;
* Сборщик мусора сильно тормозит при ограниченном количестве доступной памяти. Он ведет себя сильно хуже, чем на декстопах или серверах;
* Каждый мобильный разработчик, независимо от того — использует он сборку мусора или нет — тщательно продумывает работу с памятью;
* JavaScript в настоящий момент фундаментально против того, чтобы даже попробовать оценить расход памяти на мобильных устройствах;
* Даже если они захотят дать эту возможность, опыт подсказывает, что сделать это будет очень трудно;
* Есть надежда на asm.js, но он, скорее, напоминает C\C++, чем что-то динамическое типа JS.
ПОДНИМЕМ ГРАДУС УРОВЕНЬ ДИСКУССИИ
Не сомневаюсь, что после статьи на меня посыпятся сотни емейлов, которые цитируют одно из вышеприведенных утверждений и не согласны с ним, не приводя никаких доказательств (типа тех, что предоставил я) или утверждая, что «однажды я написал текстовый редактор и он работал нормально» или «есть люди, которых я не знаю, и которые написали симулятор полета и у них не было проблем». Я их буду удалять.
Если мы хотим прогресса в мобильных нативных или веб приложениях, то дискуссия должна опираться хоть на какую-то основу: тесты, цитаты, статьи, что угодно. Хватит уже комментариев типа «однажды написал я веб-приложение и оно работало нормально». Достаточно уже было гадания на тему — правильно ли Facebook выбрал HTML5 или надо было писать нативно.
Задача в том, что определить количественно насколько мобильные веб-приложения и нативная экосистема может стать лучше. Ну и потом что-то с этим сделать.

