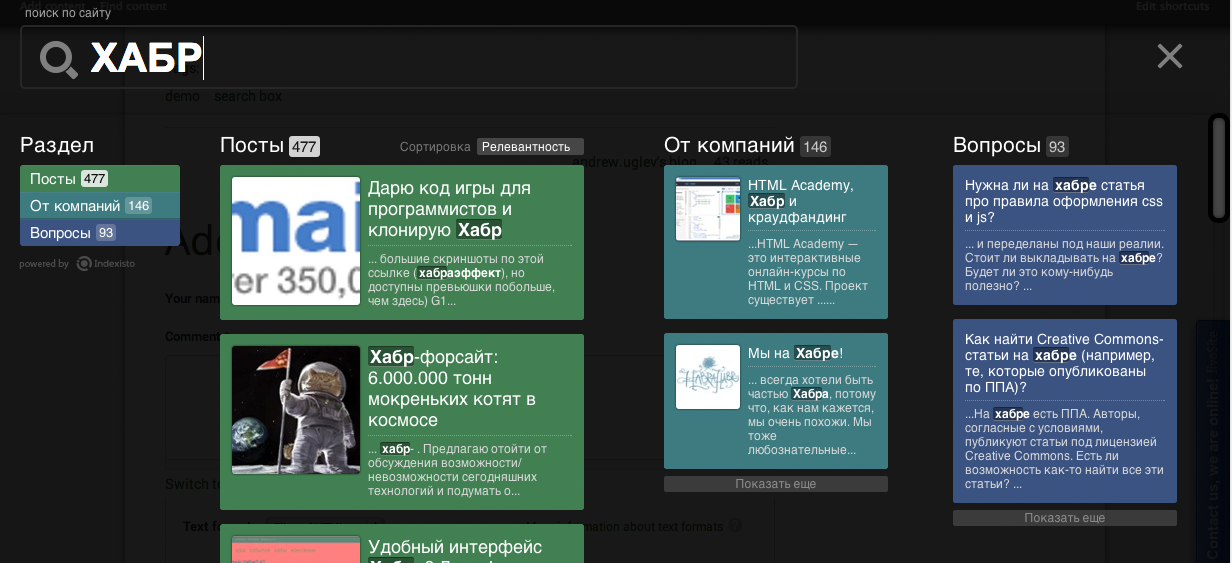
Хмурым осенним утром в качестве эксперимента мы запилили свой поиск для Хабра со структурой и скоростью. На все работы ушло минут 10. Тем кому лень читать тык для просмотра нового поиска (поисковый инпут прямо в теле записи в блоге)
Для получения такого поиска мы не просили доступа к базе, или заливки статей через наше API. Все делается очень просто, через обычный краулер. Для примера мы скраулили порядка 5000 статей.
Предыстория
Всем привет. Напомню, что мы делаем быстрый структурированный поиск для сайтов Indexisto (+наш пост на хабре). Долгое время от нас ничего не было слышно, и вот мы, наконец, выходим с релизом.
После первой публикации многим понравилось то, что мы делаем и многие захотели внедрения. Я очень благодарен первым подключившимся — мы увидели множество скажем так «тонкостей», которые сами бы не нашли. Мы довольно быстро все чинили, и при этом ни разу не уронили ни один «живой» индекс. Однако была структурная проблема:
— Очень высокий порог вхождения. Сложное подключение через базу данных, сложные настройки темплейтов, поискового запроса, анализаторов и т.д.
Эту проблему мы решали ручными настройками конфигов клиентов (например, можно посмотреть нашу выдачу на maximonline.ru), и объяснениями, что нам нужны early adopters. Разработка (помимо багов) при этом практически встала, и мы поняли что либо мы становимся интегратором, либо надо что-то менять, чтобы остаться интернет проектом.
Развитие событий
Сегодня мы хотим представить кардинальное решение проблемы с подключением — надо просто ввести URL сайта, и получить готовую поисковую выдачу. That's it.

Все остальное делается автоматически. Множество сложных настроек берется из готового шаблона и применяется к вашему индексу. При этом панель администратора сократилась донельзя — до галочек и выпадающих списков. Для любителей хардкора мы оставили возможность переключиться в advanced режим.
Краулер и парсер
И так, теперь у нас есть краулер и парсер контента. Краулер дает относительно разумные страницы: мы более или менее научились отбрасывать пагинации, различные фиды, изменения представл��ния (типа ?sort=date.asc). Но даже если краулер отработает идеально, у нас будут страницы со статьями в которых тонна лишнего: меню, блоки в правой и левой колонке. Скажем прямо, не очень хотелось бы видеть все это в поисковой выдаче, если придерживаться нашего позиционирования.
Здесь мы переходим к без сомнения убер системе: парсеру позволяющую извлекать любые данные со страницы.
Концептуально система сочетает два подхода:
- автоматическое извлечения контента на основе алгоритмов, например вот этого Boilerplate Detection using Shallow Text Features. Про это будет отдельный пост.
- извлечение данных «в лоб» с помощью xpath. Напомню, если по простому — xpath позволяет искать текст в определенных тэгах, например
//span[contains(@class, 'post_title')]— вытащить заголовок из тэга span с классом post_title.
Система может работать как без дополнительных настроек, так с помощью ручных настроек для конкретного сайта.
Маски парсера для извлечения контента
Все настройки xpath мы храним в масках
Парсер получает на вход страницу и начинает прогонять ее по разным маскам, передавая от одной к другой. Каждая маска пытается что-нибудь вычленить из html страницы и дописать к полученному документу: заголовок, картинку, текст статьи. Например есть маска которая извлекает Open Graph тэги и дописывает их содержание в документ:
<mask name="ogHighPrecision" level="0.50123"> <document name="ogHighPrecisionTags"> <field name="_url">//meta[contains(@property, 'og:url')]/@content</field> <field name="_subtype">//meta[contains(@property, 'og:type')]/@content</field> <field name="_image">//meta[contains(@property, 'og:image')]/@content</field> <field name="title">//meta[contains(@property, 'og:title')]/@content</field> <field name="description">//meta[contains(@property, 'og:description')]/@content</field> <field name="siteName">//meta[contains(@property, 'og:site_name')]/@content</field> </document> </mask>
Как уже понятно маски мы описываем в XML. Особых пояснений код не требует )
Таких масок у нас довольно много — для OG, микродаты, отброса страниц с noindex и т.д.
Таким образом, можно в принципе ввести адрес сайта, и получить приемлемую выдачу.
Однако многие хотят не просто приемлемо, а идеально. И здесь мы даем вам возможность писать xpath самостоятельно.
Пользовательские маски
Без лишней воды посмотрим как мы извлекли данные с Хабры
<?xml version="1.0" encoding="UTF-8"?> <mask name="habrahabrBody" level="0.21"> <allowUrl>/company/</allowUrl> <allowUrl>/events/</allowUrl> <allowUrl>/post/</allowUrl> <allowUrl>/qa/</allowUrl> <document name="habrahabrBody"> <field name="body" required="true">//div[contains(@class, 'html_format')]</field> <field name="title" required="true">//span[contains(@class, 'post_title')]</field> </document> </mask>
Код в пояснения не нуждается ) На самом деле мы сказали этой маске: работай только на страницах постов, компаний, событий и вопросов, тело статьи бери из div с классом html_format, заголовок из span с классом post_title
Извлечение картинки происходит на уровне системных(встроенных) масок по тэгу Open Graph, поэтому про картинку мы ничего в свой маске не вспоминали.
В дальнейшем мы постараемся сделать этот процесс еще легче, как у Google в панели вебмастра (Видео)

