Добрый день, уважаемые читатели.
В прошлой статье было описано ввдение в визулизацию данных с Pandas и matplotlib. Сегодня же хотелось бы показать еще один способ отображения результатов анализа с помощью Vincent, который так же очень просто интегрируется с Pandas, хотя и займет это чуть больше действий, чем в случае с matplotlib.
Vincent — это модуль предназначенный для трасляции данных из python в JavaScript библиотеки для визуализации D3js и Vega, которые в свою очередь дают большие возможности для интерактивной визуализации данных.
Т.е. таким образом мы можем производить анализ на python, а графику к результатам мы сможем строить на js. Например это может быть удобно для визуализации каких-либо георафических данных и нанесения их на карту. Кроме того vincent обладает интеграцией с IPython Notebook, и, так же как и matplotlib, может выводить графику непосредственно в ней.
В качестве демонстрации возможностей данного модуля, я предлагаю реализовать 2 задачи:
В качестве исходных данных возьмем статисткику сайта Росстата.
Для начала давайте загрузим данные и посмортим нужна ли дополнительная обработка.
Итак для загрузки данных в этот раз мы используем фнкцию read_html() (данная фукция появилась в pandas начиная с 0.12 версии). В качестве параметров в нашем случае передается 3 аргумента:
После загрузки у нас получилась таблица следующего вида:
Как можно заметить нужна будет небольшая обработка таблицы, т.к. в ней присутствует один столбец без названия и один столбец с пустыми значениями. Ну что же давайте выберем нужные нам столцы (со 2 по 13) остальные стобцы и поместим их в новый DataFrame.
Теперь у нас получился набор данных, пригодный для работы. Конечно режет глаз названия столбцов, но такие имена нам ничуть не помешают решить поставленные задачи.
Итак, давайте приступим к выполнениию первой задачи по визуализации данных 2 округов. Чтобы получить данные, на основе которых мы построим график, необходимо выбрать интересующие нас округа (Московский и Приволжский), а затем транспонировать полученную таблицу. Сделать это можно так:
В приведенном выше коде, мы сначала фильтруем наш набор данных по нужным нам округам при момощи функции isin(), которая проверяет значение столбца в заданее заданном списке (аналог оператора IN в SQL). Затем используем функцию transpose() для транспонирования полученного набор данных и записываем результат в новый DataFrame.
Как можно заметить названия индексы в таблице у нас теперь равны номеру года в числовом формате. Это не очень удобно, поэтому давайте поменяем индекс на формат даты:
Фукция set_index() используется для задания нового индекса в DataFrame. В нашем случае ей передается 2 параметра:
Теперь данные у нас полностью готовы для построения графика. Итак если вы работаете в IPython Notebook и хотите видеть результат в реальном времени то для интеграции необходимо вызвать функцию initialize_notebook(). Выглядеть это будет следующим образом:
vincent.core.initialize_notebook()
Теперь нам нужно создать объект соответствующий типу диаграммы (полный список объектов можно увидеть в документации). В нашем случае это будут линейный график. Код будет следующий:
Вывес��и график можно с помощью функции display():
В результате мы увидим следующее:

Ну что же с первой задачей мы справились. Теперь давайте перейдем ко второй. Для ее решения нам понадобится TopoJSON файл с картой РФ, а также справочник регионов. Подробно о том как их получить и что это такое можно почитать здесь. Для начала давайте загрузим справочник регионов с помощью read_csv, описанной в одной из предыдущих статей:
Как можно заметить тут появилось несколько дополнительный параметров:
Если мы посмотрим внимательно, на наш набор данных stat, то можно увидеть, что его некоторые элементы содержат сноски тип '1)' и '2)', которые при парсинге с помощью read_html() перекодировались в обычные символы и добавились в конце соответствующих строк в индексом сотлбце. Кроме того перед именами городов в нашем наборе строит буква 'г. ', а в справочнике ее нет. Все эти мелочи влияют на то, что когда мы будем объединять набор со стат. данными и справочник, чтобы подтянуть коды к регионам, у нас будут регионы без кода.
Исправить это можно следующим образом:
Первая строка означает, что мы выделяем индексный столцеб в отдельную новую серию. Во втрой строке мы заменяем значения соответствующие регулярному выражению на пустые.
Теперь нам надо значения индекса заменить значениями из нового набора. Как показовалось выше, сделать это можно так:
Теперь мы можем объединить наш набор данных со справочником, чтобы получить коды регионов:
Наши данные после всех манипуляций выглядят так:
Итак перейдем к непосредственному построению карты и нанесению на нее данных. Для начача нам нужно создать словарь с описание нашей карты:
Теперь давайте создадим объект нашей карты и привяжем к нему наши данные. Сделать это можно функцией Map():
В качестве параметров функция принимает следующие аргументы:
Но тут наш ожидаем неожиданность: в авторской версии vincent, параметр rotate может быть только целочисленный. Для корретного отображения нашей карты, нужна возможность, чтобы данный параметр смог принимать значения в виде списка. Чтобы это исправить идем в файл %PYTHON_PATH%/\lib\site-packages\vincent\transforms.py заменям кусок кода отвечающий за проверку типа переменных:
на:
Теперь наш объект создастся корретно. Осталось поднастроить наш объект. Для начала давайте сделаем наши границы между меджу объектами менее заметными. Для этого у нас существуют метки (marks), которые являются основными строительным элементом. Подробней про них написано в документации к Vega. В нашем случае код выглядит так:
Теперь давайте зададим чтобы наши значения в зависимости от группы окрашивались в разные цвета. Сделать это можно с помощью объектов Scales, предназначенных для перевода значений данных (числовых, строковых, дат и тд) в значения для отображения (писксели, цвета, размеры). Код ниже:
Ну что же карта настроена, теперь ее можно посмотреть что у нас получилось. Как указаволось выше для этого можно использовать функцию display(), но у меня по неизвестным причинам она не сработала, поэтому я сначала выгрузил ее в итоговый json файл с по��ощью функции to_json():
В качестве параметров ей передается 3 параметра:
Чтобы посмотреть наш html файл нужен простой HTTP сервер входящий в Python. Для его запуска в командной строке надо выполнить команду:
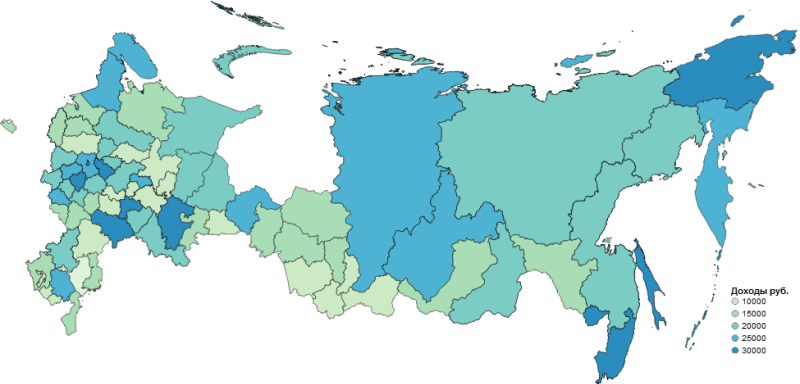
В итоге наша карта будет выглядеть так:
Сегодня я пострался показать еще один способ визуализации данных при использовании pandas. Так же хотелось бы отметить, что рассматриваемый модуль относительно молод и сейчас активно развивается. Из недостатков я бы отметил, что не все объекты отображаются при попытке вывода их прямо в IPython и отсутствие возможности выгрузить просто картинку, а не json файл, тем более что для vega такие инструменты разрабатываются
В прошлой статье было описано ввдение в визулизацию данных с Pandas и matplotlib. Сегодня же хотелось бы показать еще один способ отображения результатов анализа с помощью Vincent, который так же очень просто интегрируется с Pandas, хотя и займет это чуть больше действий, чем в случае с matplotlib.
Введение
Vincent — это модуль предназначенный для трасляции данных из python в JavaScript библиотеки для визуализации D3js и Vega, которые в свою очередь дают большие возможности для интерактивной визуализации данных.
Т.е. таким образом мы можем производить анализ на python, а графику к результатам мы сможем строить на js. Например это может быть удобно для визуализации каких-либо георафических данных и нанесения их на карту. Кроме того vincent обладает интеграцией с IPython Notebook, и, так же как и matplotlib, может выводить графику непосредственно в ней.
В качестве демонстрации возможностей данного модуля, я предлагаю реализовать 2 задачи:
- Покажем динамику среднедушевого дохода населения и Центральному и Приволжскому федерельным округам
- Покажем на карте РФ распределение по субъектам РФ среднедушевого дохода за 2010
В качестве исходных данных возьмем статисткику сайта Росстата.
Анализ данных
Для начала давайте загрузим данные и посмортим нужна ли дополнительная обработка.
import pandas as pd import vincent stat = pd.read_html('Data/AVGPeopleProfit.htm', header=0, index_col=0)[0]
Итак для загрузки данных в этот раз мы используем фнкцию read_html() (данная фукция появилась в pandas начиная с 0.12 версии). В качестве параметров в нашем случае передается 3 аргумента:
- Адрес html страницы
- Номер строки, содержащей имена столбцов
- Номер столбца, который будет использоваться в виде индекса
После загрузки у нас получилась таблица следующего вида:
| 1990.0 | 2000.0 | 2001.0 | 2002.0 | 2003.0 | 2004.0 | 2005.0 | 2006.0 | 2007.0 | 2008.0 | 2009.0 | 2010.0 | 2011.0 | nan | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Российская Федерация | NaN | 2281 | 3062 | 3947 | 5167 | 6399 | 8088 | 10155 | 12540 | 14864 | 16895 | 18951 | 20755 | NaN |
| Центральный федеральный округ | NaN | 3231 | 4300 | 5436 | 7189 | 8900 | 10902 | 13570 | 16631 | 18590 | 21931 | 24645 | 27091 | 1 |
| Белгородская область | NaN | 1555 | 2121 | 2762 | 3357 | 4069 | 5276 | 7083 | 9399 | 12749 | 14147 | 16993 | 18800 | 24 |
| Брянская область | NaN | 1312 | 1818 | 2452 | 3136 | 3725 | 4788 | 6171 | 7626 | 10083 | 11484 | 13358 | 15348 | 52 |
| Владимирская область | NaN | 1280 | 1666 | 2158 | 2837 | 3363 | 4107 | 5627 | 7015 | 9480 | 10827 | 12956 | 14312 | 64 |
Как можно заметить нужна будет небольшая обработка таблицы, т.к. в ней присутствует один столбец без названия и один столбец с пустыми значениями. Ну что же давайте выберем нужные нам столцы (со 2 по 13) остальные стобцы и поместим их в новый DataFrame.
stat = stat[stat.columns[1:13]]
Теперь у нас получился набор данных, пригодный для работы. Конечно режет глаз названия столбцов, но такие имена нам ничуть не помешают решить поставленные задачи.
| 2000.0 | 2001.0 | 2002.0 | 2003.0 | 2004.0 | 2005.0 | 2006.0 | 2007.0 | 2008.0 | 2009.0 | 2010.0 | 2011.0 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Российская Федерация | 2281 | 3062 | 3947 | 5167 | 6399 | 8088 | 10155 | 12540 | 14864 | 16895 | 18951 | 20755 |
| Центральный федеральный округ | 3231 | 4300 | 5436 | 7189 | 8900 | 10902 | 13570 | 16631 | 18590 | 21931 | 24645 | 27091 |
| Белгородская область | 1555 | 2121 | 2762 | 3357 | 4069 | 5276 | 7083 | 9399 | 12749 | 14147 | 16993 | 18800 |
| Брянская область | 1312 | 1818 | 2452 | 3136 | 3725 | 4788 | 6171 | 7626 | 10083 | 11484 | 13358 | 15348 |
| Владимирская область | 1280 | 1666 | 2158 | 2837 | 3363 | 4107 | 5627 | 7015 | 9480 | 10827 | 12956 | 14312 |
Итак, давайте приступим к выполнениию первой задачи по визуализации данных 2 округов. Чтобы получить данные, на основе которых мы построим график, необходимо выбрать интересующие нас округа (Московский и Приволжский), а затем транспонировать полученную таблицу. Сделать это можно так:
fo = [u'Приволжский федеральный округ',u'Центральный федеральный округ'] fostat = stat[stat.index.isin(fo)].transpose()
В приведенном выше коде, мы сначала фильтруем наш набор данных по нужным нам округам при момощи функции isin(), которая проверяет значение столбца в заданее заданном списке (аналог оператора IN в SQL). Затем используем функцию transpose() для транспонирования полученного набор данных и записываем результат в новый DataFrame.
| Центральный федеральный округ | Приволжский федеральный округ | |
|---|---|---|
| 2000 | 3231 | 1726 |
| 2001 | 4300 | 2319 |
| 2002 | 5436 | 3035 |
| 2003 | 7189 | 3917 |
| 2004 | 8900 | 4787 |
| 2005 | 10902 | 6229 |
| 2006 | 13570 | 8014 |
| 2007 | 16631 | 9959 |
| 2008 | 18590 | 12392 |
| 2009 | 21931 | 13962 |
| 2010 | 24645 | 15840 |
| 2011 | 27091 | 17282 |
Как можно заметить названия индексы в таблице у нас теперь равны номеру года в числовом формате. Это не очень удобно, поэтому давайте поменяем индекс на формат даты:
fostat.set_index(pd.date_range('1999','2011', freq='AS'), inplace=True)
Фукция set_index() используется для задания нового индекса в DataFrame. В нашем случае ей передается 2 параметра:
- Список новых значений индекса(может быть также названием столбца)
- Парамерт означает, что мы заменяем индекс в текущем наборе, если он будет False индекс не сохранится
Теперь данные у нас полностью готовы для построения графика. Итак если вы работаете в IPython Notebook и хотите видеть результат в реальном времени то для интеграции необходимо вызвать функцию initialize_notebook(). Выглядеть это будет следующим образом:
vincent.core.initialize_notebook()
Теперь нам нужно создать объект соответствующий типу диаграммы (полный список объектов можно увидеть в документации). В нашем случае это будут линейный график. Код будет следующий:
line = vincent.Line(fostat) #создаем объект графика line.axis_titles(x=u'Год', y=u'тыс. руб') #задаем названия осей line.legend(title=u'ЦФО vs ПФО') #выводим легенду и задаем ей заголовок
Вывес��и график можно с помощью функции display():
line.display()
В результате мы увидим следующее:
Построение картограммы
Ну что же с первой задачей мы справились. Теперь давайте перейдем ко второй. Для ее решения нам понадобится TopoJSON файл с картой РФ, а также справочник регионов. Подробно о том как их получить и что это такое можно почитать здесь. Для начала давайте загрузим справочник регионов с помощью read_csv, описанной в одной из предыдущих статей:
spr = pd.read_csv('Data/russia-region-names.tsv','\t', index_col=0, header=None, names = ['name','code'], encoding='utf-8')
Как можно заметить тут появилось несколько дополнительный параметров:
- index_col — задает номер столбца который будет использоватся в качестве индекса
- header — в нашем случае означает, что для определения заголовков мы не используем строки из файла
- names — получает список, элементы которого будут названиями столбцов
- encoding — задает кодировку в котрой хранится файл
Если мы посмотрим внимательно, на наш набор данных stat, то можно увидеть, что его некоторые элементы содержат сноски тип '1)' и '2)', которые при парсинге с помощью read_html() перекодировались в обычные символы и добавились в конце соответствующих строк в индексом сотлбце. Кроме того перед именами городов в нашем наборе строит буква 'г. ', а в справочнике ее нет. Все эти мелочи влияют на то, что когда мы будем объединять набор со стат. данными и справочник, чтобы подтянуть коды к регионам, у нас будут регионы без кода.
Исправить это можно следующим образом:
ew_index = stat.index.to_series() new_index = new_index.str.replace(u'(2\))|(1\))|(г. )','')
Первая строка означает, что мы выделяем индексный столцеб в отдельную новую серию. Во втрой строке мы заменяем значения соответствующие регулярному выражению на пустые.
Теперь нам надо значения индекса заменить значениями из нового набора. Как показовалось выше, сделать это можно так:
tat.set_index(new_index, inplace=True)
Теперь мы можем объединить наш набор данных со справочником, чтобы получить коды регионов:
RegionProfit = stat.join(spr, how='inner')
Наши данные после всех манипуляций выглядят так:
| 2000.0 | 2001.0 | 2002.0 | 2003.0 | 2004.0 | 2005.0 | 2006.0 | 2007.0 | 2008.0 | 2009.0 | 2010.0 | 2011.0 | code | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Белгородская область | 1555 | 2121 | 2762 | 3357 | 4069 | 5276 | 7083 | 9399 | 12749 | 14147 | 16993 | 18800 | RU-BEL |
| Брянская область | 1312 | 1818 | 2452 | 3136 | 3725 | 4788 | 6171 | 7626 | 10083 | 11484 | 13358 | 15348 | RU-BRY |
| Владимирская область | 1280 | 1666 | 2158 | 2837 | 3363 | 4107 | 5627 | 7015 | 9480 | 10827 | 12956 | 14312 | RU-VLA |
| Воронежская область | 1486 | 2040 | 2597 | 3381 | 4104 | 5398 | 6862 | 8307 | 10587 | 11999 | 13883 | 15871 | RU-VOR |
| Ивановская область | 1038 | 1298 | 1778 | 2292 | 2855 | 3480 | 4457 | 5684 | 8343 | 9351 | 11124 | 13006 | RU-IVA |
Итак перейдем к непосредственному построению карты и нанесению на нее данных. Для начача нам нужно создать словарь с описание нашей карты:
geo_data = [{'name': 'rus', #имя карты 'url': 'RusMap/russia.json', #путь до TopoJSON файла с картой 'feature': 'russia'}] #имя объекта из файла карты
Теперь давайте создадим объект нашей карты и привяжем к нему наши данные. Сделать это можно функцией Map():
vis = vincent.Map(data=RegionProfit, geo_data=geo_data,scale=700, projection='conicEqualArea', rotate = [-105,0], center = [-10, 65], data_bind=2011, data_key='code', map_key={'rus': 'properties.region'})
В качестве параметров функция принимает следующие аргументы:
- data — набор с данными
- geo_data — объект с нашей картой
- projection,- проекция в которой наша карта будет отображатся
- rotate, center, scale — параметры проекции
- data_bind — столбец с данными, которые будут отображатся
- data_key — поле с кодом по которому будет осуществлятся связка карты и данных
- map_key — словарь тип {'имя объекта с картой':'имя свойства по которому осуществляется привязка'}
Но тут наш ожидаем неожиданность: в авторской версии vincent, параметр rotate может быть только целочисленный. Для корретного отображения нашей карты, нужна возможность, чтобы данный параметр смог принимать значения в виде списка. Чтобы это исправить идем в файл %PYTHON_PATH%/\lib\site-packages\vincent\transforms.py заменям кусок кода отвечающий за проверку типа переменных:
@grammar(int) def rotate(value): """The rotation of the projection""" if value < 0: raise ValueError('The rotation cannot be negative.')
на:
@grammar(list) def rotate(value): if len(value) != 2: raise ValueError('len(center) must = 2')
Теперь наш объект создастся корретно. Осталось поднастроить наш объект. Для начала давайте сделаем наши границы между меджу объектами менее заметными. Для этого у нас существуют метки (marks), которые являются основными строительным элементом. Подробней про них написано в документации к Vega. В нашем случае код выглядит так:
vis.marks[0].properties.enter.stroke_opacity = vincent.ValueRef(value=0.5)
Теперь давайте зададим чтобы наши значения в зависимости от группы окрашивались в разные цвета. Сделать это можно с помощью объектов Scales, предназначенных для перевода значений данных (числовых, строковых, дат и тд) в значения для отображения (писксели, цвета, размеры). Код ниже:
vis.scales['color'].type = 'threshold' #задает тип шкалы vis.scales['color'].domain = [10000, 15000, 20000, 25000, 30000] #задаем набор значений данных для группировки vis.legend(title=u'Доходы руб.') #вводим легенду карты
Ну что же карта настроена, теперь ее можно посмотреть что у нас получилось. Как указаволось выше для этого можно использовать функцию display(), но у меня по неизвестным причинам она не сработала, поэтому я сначала выгрузил ее в итоговый json файл с по��ощью функции to_json():
vis.to_json('example_map.json', html_out=True, html_path='example_map.html')
В качестве параметров ей передается 3 параметра:
- имя итогового файла
- html_out указывает что необходимо создать еще и html файл оболочки
- html_path — задает путь до html файла
Чтобы посмотреть наш html файл нужен простой HTTP сервер входящий в Python. Для его запуска в командной строке надо выполнить команду:
python -m SimpleHTTPServer 8000
В итоге наша карта будет выглядеть так:
Заключение
Сегодня я пострался показать еще один способ визуализации данных при использовании pandas. Так же хотелось бы отметить, что рассматриваемый модуль относительно молод и сейчас активно развивается. Из недостатков я бы отметил, что не все объекты отображаются при попытке вывода их прямо в IPython и отсутствие возможности выгрузить просто картинку, а не json файл, тем более что для vega такие инструменты разрабатываются

