Готовимся к любым падениям

Это продолжение цикла публикаций, посвященных вопросам планирования аварийного восстановления. В предыдущей статье речь шла об определении зоны планирования и нахождении точек отказа, которые могут приводить к сбоям в работе пользовательских сервисов. Следующий шаг – опираясь на информацию о точках отказа определить минимально возможные сроки устранения инцидентов, которые могут обеспечить технические специалисты при наличии всех необходимых ресурсов.
Собственно, необходимые ресурсы будут в дальнейшем предметом торга с руководством компании, помогая найти баланс между инвестициями в информационные технологии, временем простоя и потерей данных в случае сбоя. Но это потом, а пока нам нужно определить какие сроки восстановления мы в принципе можем выжать из ИТ-инфраструктуры в случае сбоя. Поехали:
1. Готовимся быстро обнаруживать сбойные элементы – составляем процедуры локализации
Самые большие простои случаются тогда, когда специалист техподдержки упорно пытается починить почтовый клиент на компьютере обратившегося пользователя, в то время как надо чинить сам почтовый сервер. Наша задача на данном этапе сделать так, чтобы информация о критичных сбоях оперативно находила нужных специалистов, способных провести работы по восстановлению сервиса, не беспокоя при этом их по пустякам. Для этого мы:
- Создаем процедуры проверки работы пользовательских сервисов и точек отказа. В рамках схемы зависимости (статья 1), специалист техподдержки должен иметь возможность провести диагностику работы как пользовательского сервиса, так и точек отказа, от которых зависит его работа.
- Настраиваем мониторинг точек отказа. В некоторых ситуациях он раньше пользователей может сообщить о проблемах. В других – позволит исключить часть точек отказа из списка подозреваемых.
- Определяем правила эскалации. В случае выявления проблем, влияющих на бизнес, – немедленно сообщить дежурному системному администратору. Влияющих на подразделение – провести локализацию (не более 5 минут) и привлечь соответствующих специалистов для восстановления или сообщить дежурному системному администратору, если локализовать причину сбоя не удалось и т.д.
- Проводим обучение специалистов техподдержки, чтобы они понимали роль тех или иных инфраструктурных элементов в работе пользовательских сервисов, владели общими навыками диагностики точек отказа, а также понимали свои цели и задачи и не боялись в случае чего лишний раз побеспокоить старших товарищей.
После этого вы можете оценить время на локализацию сбоя, применительно к каждой из точек отказа, и самая большая из этих величин будет вашим «временем локализации», которое пригодится нам при дальнейших расчетах.
2. Определяем необходимые ресурсы и условия для восстановления
В процессе аварийного восстановления можно выделить четыре этапа:
- Пользовательский сервис не работает.
- Пользовательский сервис работает с ограничениями (низкое качество или временное решение).
- Пользовательский сервис восстановлен в полном объеме, но с деградацией одной или нескольких ИТ-систем и/или отсутствием необходимых резервов.
- Все ИТ-системы восстановлены, необходимые резервы пополнены.
При планировании аварийного восстановления нас, в первую очередь, интересуют необходимые ресурсы и условия для достижения 3-го этапа, как необходимое и достаточное условие для полноценного восстановления конечного пользовательского сервиса. Обычно это:
- резервные единицы оборудования с аналогичным функционалом и мощностью.
- резервные копии данных/конфигураций и доступ к ним в момент аварии.
- дистрибутивы программного обеспечения.
- доступ к оборудованию и приложениям (как физический, так и информация по паролям).
- специалист соответствующей квалификации.
В зависимости от точек отказа, может вноситься своя специфика: в случае электроснабжения требуется либо дизель, либо резервная площадка для запуска систем, в случае отказа ИБП требуется переключение на питание от сети, в случае отказа внешнего DNS-хостинга требуются контактные данные по договору с регистратором для перевода домена на новый хостинг и т.д.
Записывайте все необходимые ресурсы, привязывайте их к точкам отказа и помечайте, какие из них уже есть у вас, а какие необходимо еще получить.
3. Определяем минимальное гарантируемое время восстановления пользовательского сервиса
В общем случае процедура восстановления пользовательского сервиса выглядит следующим образом:
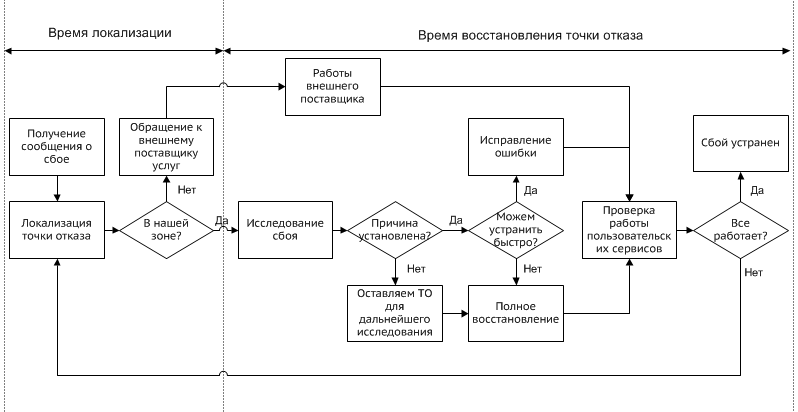
Самую большую сложность на данном этапе составляет определение гарантированного времени восстановления точки отказа. В процедуре восстановления есть только один маршрут с предсказуемым сроком — когда после небольшого, но достаточного исследования причин сбоя проводится полное восстановление точки отказа. Да, в большинстве случаев исправить ошибку быстрее, чем проводить полное восстановление, но гарантировать какие-либо сроки можно только по второму сценарию и по этой причине ориентироваться мы можем только на него.
Однако восстановление одной точки отказа не всегда означает восстановление пользовательского сервиса, так как зависимые точки отказа могут также быть неисправными (см. схему зависимостей в первой статье). Определив, на основе данной схемы, самый долгий возможный сценарий, вы получите «минимальное время восстановления» пользовательского сервиса, который может гарантировать бизнесу ИТ-служба. Если же этот срок даже на ваш взгляд выходит за все разумные рамки, то это повод подумать над его оптимизацией:
- Сделать предварительные заготовки для ускорения восстановления.
- Сократить время на исследование инцидентов (увеличивая вероятность потери данных).
- Изменить архитектуру точек отказа для увеличения скорости восстановления.
Собственно, ваши выводы касательно сроков восстановления и методов их сокращения стоит закрепить документально – они пригодятся в дальнейшем в диалоге с руководством. На этом можно было бы и заканчивать данный этап, если бы не пара неожиданностей, которые мы пока не учли:
4. Определяем факторы риска процедуры аварийного восстановления и планируем мероприятия по их контролю
Как же неприятно в момент аварии обнаружить, что в генераторе нет бензина или сел аккумулятор, что инструкция по аварийному восстановлению (не говоря уже о паролях), хранилась на том же самом упавшем сервере, что служба безопасности здания просто не пускает никого в серверную в ночное время, ну или что столь необходимая резервная копия не создавалась уже несколько месяцев подряд.
Чтобы такого не происходило, необходимо заранее определить причины, которые могут помешать вам получить необходимый ресурс в нужное время, в нужном месте и в нужном качестве. После этого спланировать задачи (или целые мероприятия), позволяющие контролировать факторы риска и если не исключать полностью, то хотя бы снижать их влияние на аварийное восстановление. Примером таких задач является:
- проверка корректности создания резервных копий,
- проверка качества работы резервных каналов связи,
- контроль наличия необходимых резервов оборудования,
- контроль состояния источников бесперебойного питания и генераторов,
- анализ соответствия планов полного восстановления текущему положению дел,
- и т.д.,
и, конечно же, не стоит забывать о непосредственном тестировании процедур полного восстановления точек отказа.
Частоту выполнения регламентных задач я рекомендую выбирать на собственное усмотрение, на основе критичности фактора риска, вероятности его наступления и трудоемкости задач по его контролю. Напоминаю, что для выполнения регламентных задач и, как следствие, контроля факторов риска, вам могут потребоваться дополнительные ресурсы.
5. Определяем ситуации, выходящие за рамки планирования

Самое сильное негативное влияние на бизнес оказывают не единичные (или последовательные) отказы, к которым технические специалисты готовы в той или иной мере, а форс-мажорные ситуации, приводящие к параллельному падению нескольких одинаковых систем. Пожары, сильные перепады напряжения, вирусные атаки и даже неправомерные действия третьих лиц могут не только нанести сильный урон, но и стать фатальными для бизнеса. В таких ситуациях сложно применять термин «оперативное восстановление», но есть ряд мероприятий, которые позволяют смягчить удар:
- Проработать вопрос резервного копирования данных на случай форс-мажорных обстоятельств. Местом хранения носителей с резервными копиями должен быть не только офис компании, но и, например, банковская ячейка. Если у компании есть несколько локаций – можно предусмотреть перекрестное резервное копирование.
- Определить приоритетность восстановления пользовательских сервисов. Всегда есть что-то единственное, без чего бизнес не выживет – все остальное подождет.
- Обезопасить резервы от влияния форс-мажорных факторов. Если резервы укомплектованы в полном объеме, то как минимум один сервис вы на них запустите.
- Подготовить (ну или хотя бы наметить) резервную площадку для развертывания. Хоть в квартире генерального директора – на войне все средства хороши.
В целом вопрос форс-мажорного планирования является отдельной большой темой. В рамках планирования аварийного восстановления этот термин используется скорее для обозначения ситуаций, на которые не распространяются сроки восстановления. Обычно такие ситуации звучат как «одновременный отказ двух и более единиц оборудование или программного обеспечения одного класса», т.к. редко кто содержит двойные резервы и штат специалистов, способных проводить параллельные работы по двум и более одинаковым системам. Тем не менее, ситуации бывают разные и, возможно, в вашем случае руководство пойдет и на такую дополнительную степень надежности.
Сводя воедино все выводы, вы можете определить набор необходимых ресурсов и регламентных задач для минимизации времени восстановления пользовательских сервисов в рамках существующей ИТ-инфраструктуры, и выделить перечень ситуаций, в которых гарантировать какие-либо сроки не представляется возможным. Схематично ваш план будет выглядеть следующим образом:

Осталось только соотнести его с реалиями и потребностями бизнеса, и совместно с руководством найти устраивающее всех решение, но об этом в следующей статье.
Часть 1: habrahabr.ru/post/225719
Часть 3: habrahabr.ru/post/228115
Успехов!
Иван Кормачев
t.me/depit_ru

