Многие слышали о мультиклеточной архитектуре, процессорах и даже первых устройствах на них. Особенно продвинутые пользователи опробовали свои алгоритмы. Были проведены первые простые тесты производительности, а также пользователь Barsmonster, вытравил кристалл процессора Р1. Сейчас уже проходит первые проверки процессор R1 и скоро будет доступен всем. Но ответ на вопрос о том, как работает мультиклеточная архитектура и в чём её отличие, знают не все. Попытаемся сейчас ввести в курс дела.
1.Мультиклеточность
Мультиклеточное ядро — это группа идентичных процессорных блоков(2 и более), объединенных полносвязной однонаправленной коммутационной средой. Особенности взаимодействия процессорных блоков между собой вытекают из представления алгоритма (об этом ниже). Процессорный блок в мультиклеточной архитектуре называется клеткой. Набор команд, который она может выполнять определяется конкретной реализацией и не зависит от архитектуры.
Алгоритмы «глазами» мультиклеточного ядра
Во-первых.
Любую формулу можно представить в виде ярусно-параллельной формы (ЯПФ). Рассмотрим
простой пример: g = e*(a+b) + (a-c)*f, в ЯПФ это может выглядеть так:

Рис 1. Пример ЯПФ
В общем случае, для выполнения операций узлы, расположенные на i-ом ярусе, могут использовать результаты, полученные на ярусах от 1 до (i-1)-го. Из этого следует, что команды, находящиеся на одном ярусе, независимы.
Любой алгоритм – это множество формул, которое разделено на подмножества — линейные участки, связанные между собой операторами передачи управления. Под линейным участком (ЛУ) понимается такое подмножество формул, которое вычисляется тогда и только тогда, когда управление передано на данный линейный участок. Внутри линейного участка, информационно несвязанные формулы могут выполняться в любом порядке.
Как известно, результат выполнения процессором любой команды выражается в изменении состояния процессора. Использование этого нового состояния последующими командами, образует информационную связь между командой–источником результата и командами–приемниками этого результата. Такая связь может быть как опосредованной (косвенной), так и непосредственной (прямой).
При косвенной связи результат доступен только после его отчуждения: записи в общедоступные регистры или память или др. устройства. Команда-источник должна поместить результат в эти устройства, а команда-приемник должна будет взять данные оттуда. Имя устройства указывается в качестве операнда. Такая связь между командами является основой абсолютно всех современных процессоров, кроме мультиклеточных.
В случае прямой информационной связи, команды именуются и при этом имена должны идентифицировать собственно команду, а не ее местоположение или другие особенности реализации. Доступ к результатам может осуществляться по именам как команд–источников, так команд–приемников. В первом случае используется широковещательная рассылка с последующим поименным отбором, при которой в поле операнда команды–приемника задают имя команды–источника. Во втором – выполняется поименная рассылка, при которой в команде–источнике задают имя команды–приемника результата.
Теоретически узлы ЯПФ мы можем поименовать любым образом. Единственное требование — однозначность. Для этого в мультиклеточном процессоре команды, при выборке из памяти, получают тег (метку) — таким образом им и их результатам дается локальное имя — и далее взаимодействие между командами организовывается через теги. Данные можно получать из любой команды с тегом меньше своего. Номер тега требуемого результата задается разницей значений тега команды и тега требуемого результата. Например, если в операнде указано @5, а тег команды равен 7, то в качестве операнда используется результат команды с тегом 2. Все результаты выполнения команд поступают в коммутационную среду, из которой по тегу отбираются требуемые. Таким образом в мультиклеточном процессоре используется широковещательная рассылка результатов с последующим их поименным отбором.
Стоит отметить, что из-за физических ограничений есть понятие «окна видимости», которое определяет максимальное расстояние команды-источника от команды приемника. Тег в процессе выборки команд изменяется циклически. Его максимальная величина определяется размером буфера команд. Фактически размер тега определяет количество команд, которые одновременно могут находиться на разных стадиях исполнения. Значение тега не может быть использовано, если команда, которой он ранее был присвоен, еще не выполнена.
Во-вторых.
Мультиклеточный процессор оперирует структурами, которые мы называем — параграфами.
Параграф — это информационно замкнутая последовательность команд. Параграф является аналогом команды, после выполнения которой, изменяется состояние процессора и/или систем в его составе (регистров, шин, ячеек памяти, каналов ввода/вывода и т.д.). Т.е. для мультиклеточного ядра параграф — это команда.
Основная особенность мультиклеточной архитектуры в том, что она непосредственно реализует ЯПФ представления алгоритма. Из такого понимания алгоритма вытекают многие свойства мультиклеточной архитектуры.
2.Свойства мультиклеточной архитектуры
Рассмотрим подробнее как будет выглядеть параграф для алгоритма, описанного в п.2.

Для мультиклеточно ядра характерна следующая схема построения параграфа (не является обязательной, в приведенном примере так же есть отступления):
Следует напомнить, что изменение состояния машины в мультиклеточном процессоре происходит по концу параграфа.
Алгоритм не зависит от кол-ва клеток.
Информационные связи между командами указаны явно и нет необходимости знать о количестве процессорных блоков, когда пишется программа. Команды просто ждут готовности своих операндов и после этого уходят на исполнение и им не важно кто и когда им подготовит операнды. Представьте лейку — вы не задумываетесь сколько отверстий в ее насадке, когда поливаете. Клетки идентичны и нет разницы в какой клетке будет выполняться та или иная команда.
Команды распределяются по клеткам в порядке их следования, 1 команда в 0 клетку, 2 команда в 1 клетку и т. д., когда передали команду в последнюю имеющуюся клетку — начинаем распределять заново с 0 клетки. Рассмотрим работу 4-х клеточного ядра. Параграф, приведенный выше, будет выполняться следующим образом:

Рис 2. Распределение команд по клеткам
Кол-во одновременно выполняемых команд зависит от кол-ва клеток. Выбор оптимального числа клеток для каждой задачи — это задача, которая требует анализа. Создать универсальную систему все равно не получится, поэтому можно ориентироваться на следующие данные: на общих задачах неплохо справляются 4 клетки, а с задачами обработки сигналов — 16 клеток, а для обработки видеоизображения их число может быть порядка сотен.
Можете провести анализ своего кода и представить каким было бы оптимальное число клеток для них. Для того потребуется представить ваш алгоритм в ЯПФ и подсчитать количество команд в ярусах. Среднее число команд в них будет намекать на оптимальное количество клеток в вашем конкретном случае.
Все команды, готовые к выполнению, выполняются одновременно.
Как упоминалось выше, мультиклеточное ядро реализует ЯПФ представление алгоритма, на ярусах располагаются независимые команды. Все, что в данный момент может быть выполнено — будет выполнено без каких-либо специальных указаний со стороны программиста, основное условие — команда должна получить все данные для исполнения.
Стоит учитывать технологические ограничения: кол-во клеток ограничено, поэтому выполняться одновременно будет столько команд, сколько клеток в ядре.
«Сход-развал» или динамическое распределение вычислительных ресурсов
Т.к. код не зависит от количества клеток, которым он будет исполняться, появляется способность мультиклеточного ядра к распределению своих вычислительных ресурсов во время работы, при этом управление происходит программно.
Способность мультиклеточной архитектуры перераспределять свои ресурсы мы называем — реконфигурацией. Например, клетки мультиклеточного ядра могут быть, как угодно распределены для выполнения какого-либо алгоритма или его части. Группа (лучше названия пока не придумали) — это часть клеток мультиклеточного ядра, которые связаны между собой для выполнения какого-либо алгоритма или части алгоритма. В группе может находиться 1 и более клеток. Когда мультиклеточное ядро разделяет группу на части — это называется декомпозиция. Процесс объединения в группу — композиция. На рис 3 ниже показано как 4-х клеточное ядро со временем реконфигурируется (пример). Клетки, выполняющие одну задачу, имеют одно цветовое заполнение.

Рис 3. Пример реконфигурации клеток
Снижение энергопотребления. Работает тогда, когда есть работа.
Принципиальной основой мультиклеточной архитектуры является широковещательная рассылка. На сегодняшний день – это пока единственная архитектура, использующая непосредственную информационную связь для передачи данных между командами в программе.
Если обратить внимание на рис 1, на котором показан пример выполнения кода 4-х клеточным процессором, то видно, что клетки выполняют команды расположенные на ярусах тогда, когда они готовы быть выполнены. Результат помещается в коммутационную среду и ждет своего потребителя.
Мультиклеточное ядро не совершает лишних действий, работает тогда, когда есть работа. Если какая-нибудь из составляющих процессора не готовая выполнить команду, то работа с ней приостанавливается до освобождения.
Масштабируемость, нет ограничений на кол-во клеток.
Архитектура не ограничивает кол-во клеток. Дело стоит за технологиями.
Есть несколько вариантов организации большого числа клеток, но это тема для отдельной статьи, которую подготовим позже.
3.Реализация
Мультиклеточный процессор «во-плоти»
Мультиклеточный процессор состоит из N идентичных клеток с номерами от 0 до n-1, объединённых коммутационной средой. Каждая клетка содержит блок памяти программ (PM), устройство управления (CU), буферные устройства (BUF), а также каждой клетке соответствует коммутационное устройство (SU), совокупность которых образует коммутационную среду (SB). Процессор также содержит память данных (DM), блок регистров общего назначения (GPR) и исполнительно устройство(EU), состоящее из арифметико-логического устройства для чисел с плавающей запятой(ALU_FLOAT), АЛУ для целых чисел(ALU_INTEGER) и блок доступа к памяти данных(DMS).
Программа для мультиклеточного ассемблера состоит из параграфов. Например:
На самом деле команда перехода на следующий параграф может стоять в любом месте текущего параграфа, но пока мы не заостряем на этом внимание. В данном примере параграф – это все команды от метки “Paragragh” до метки конца участка команд — «complete».
В параграфе команды могут располагаться в произвольном порядке, команды могут ссылаться на результат предыдущих команд с помощью оператора «@», но следует учитывать, что нельзя сослаться на результат команды, которая выше текущей на 64 команды. Т.е. окно видимости результата для каждой команды равно 64, при этом размер параграфа не ограничен, т.е. он может состоять хоть из нескольких тысяч команд. Рассмотрим пример:
В рассматриваемом примере команда addl @1, @2 выполняет сложение двух предыдущих команд, а команда addl @1, @3 выполняет сложение результата предыдущей команды и результат команды, которая на 3 строчки выше.
Состояние процессора меняется при переходах от одного параграфа к другому. Записи в память, регистры происходят по концу параграфа в случае, если контроль чтения записи включён или не используются команды прямого чтения и записи. Но есть возможность отключения контроля чтения и записи, т.е. запись в память будет проходить в самом параграфе, не дожидаясь его завершения (в случаях, когда есть возможность отключить контроль чтения и записи, при работе с памятью может принести ощутимое увеличение производительности). На самом деле выжать максимум из мультиклеточного процессора несложно, но это тема для отдельной статьи.
Для исполнения контекстно-зависимой программы, команды каждого параграфа последовательно, начиная с одного и того же адреса, являющегося адресом данного параграфа, размещают в PM клеток. Адрес размещения первого исполняемого параграфа равен адресу, начиная с которого клетки выбирают команды. В результате, в PM i–ой клетки, начиная с адреса параграфа, последовательно размещаются его команды с номерами i, N+i, 2*N+i,...,.
Каждая клетка обеспечивает, начиная с указанного ему адреса, последовательную выборку команд и размещение их на регистре команд для последующего декодирования. Команды клетками выбираются синхронно.
При декодировании каждой очередной выбранной группе из N команд присваивают очередное значение тега (t), а команде из группы и, соответственно, ее результату – номер. Выборка и декодирование команд продолжается до тех пор, пока не будет выбрана команда, отмеченная управляющим признаком «конец параграфа»(Complete). Адрес нового параграфа может поступить как в любой момент выборки команд текущего параграфа, так и после завершения выборки команд. Он поступает всем клеткам одновременно. Если к моменту выборки последней команды параграфа адрес следующего параграфа не вычислен, то выборка приостанавливается до получения адреса. Если адрес получен, то выборка продолжается с этого адреса. Выбранная команда поступает в буферное устройство, которое состоит из буфера первого операнда, буфера второго операнда и буфера команд (коды операций, теги и т.п.) Буферные устройства формируют команды и передают их соответствующему исполнительному устройству.
Операционная часть (буфер команд), кроме кода команды, включает в себя всю необходимую служебную информацию для рассылки и приема результатов, а именно, номер команды и признаки готовности первого (второго) операнда для выполнения команды.
Буфер хранения операндов имеет ассоциативную адресацию. Ассоциативным
адресом является тег запрашиваемого результата. В качестве операндов при выполнении операций могут использоваться:
В первом случае признак готовности данного операнда при записи команды устанавливают в состояние «не готов», а во втором – в состояние «готов». После получения запрошенного результата от коммутационного устройства, признак, в первом случае, также устанавливают в состояние «готов». Команда, получившая все операнды, проходит приоритетный отбор среди других готовых команд в буферном устройстве, после чего выдается на исполнение при условии незанятости исполнительного устройства.
В процессоре P1 для каждой клетки был выделен свой участок памяти, т.е. память программ и память данных не пересекались. В процессоре R1 память программ и память данных находятся в одном адресном пространстве, т.е. у клеток есть каналы доступа к памяти программ и памяти данных. На рис 4 приведена общая структура процессора P1. На рис 5 приведена структура клетки и её описание для процессора R1.
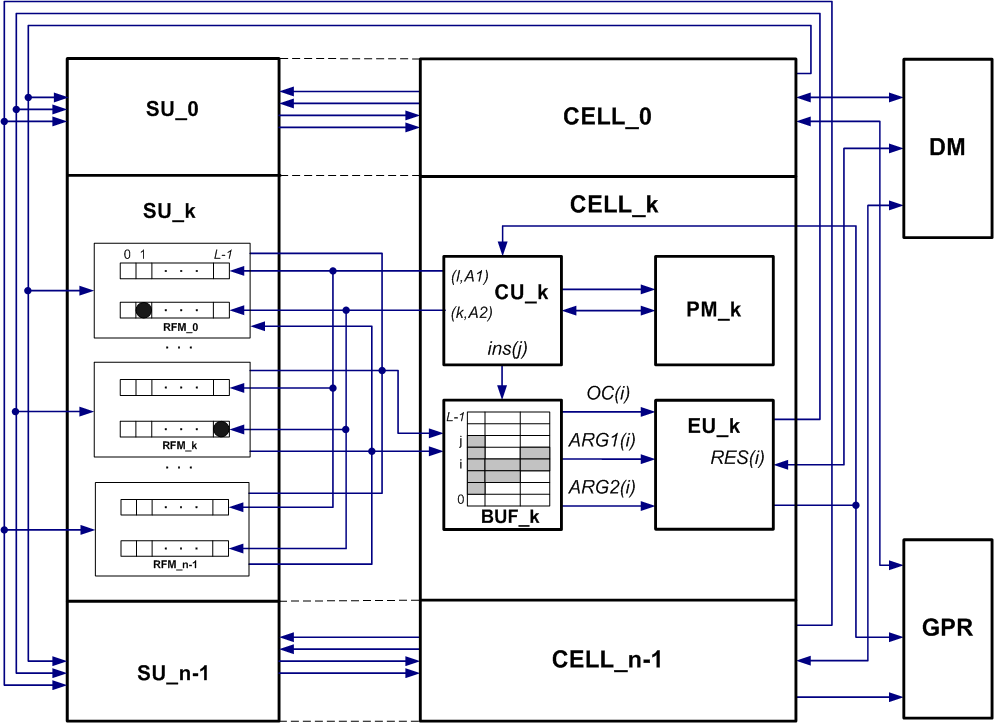
Рис 4. Общая структура мультиклеточного процессора
Арифметико-логические устройства (АЛУ), наряду с блоком DMS, входят в состав набора исполнительных устройств имеющегося в каждой клетке (CELL).
В состав клетки входят следующие устройства:
1. Устройство выборки команд IDU (Instruction Distribution Unit).
2. Устройство управления.
3. Коммутационное устройство SU (Switch Unit).
4. Буферное устройство.
5. Целочисленное АЛУ.
6. АЛУ с плавающей точкой.
7. Блок доступа к памяти данных DMS (Data Memory Service).
8. Мультиплексор результатов.
9. Набор регистров GPR (General-Purpose Registers).
10. Контроллер прерываний IC (Interrupt Controller).
11. Отладочный блок JTAG-GPR.
Подробная структура клетки представлена на рисунке 5:

Рис 5. Структура клетки.
Результат выполнения команд исполнительные устройства передают в коммутационное устройство.
Если одновременно готовы результаты выполнения команд целочисленного АЛУ, АЛУ с плавающей точкой и DMS, коммутационное устройство принимает результат выполнения команды АЛУ с плавающей точкой. По приоритету чтения результата исполнительные устройства распределяются следующим образом:
1.АЛУ с плавающей точкой;
2.DMS;
3.Целочисленное АЛУ.
Исполнительные устройства, результат работы которых на текущем такте не может быть выдан в коммутационное устройство, записывают результат выполнения команды в выходной регистр и ожидают своей очереди на выдачу результата.
Описанная выше ситуация имеет следствием то, что количество тактов, необходимое для выполнения команды, является величиной недетерминированной.
В каждой клетке имеются два АЛУ: целочисленное АЛУ и АЛУ обработки чисел с плавающей точкой.
Целочисленное АЛУ предназначено для выполнения команд над целочисленными операндами, при этом операнды могут быть представлены в следующих форматах (в зависимости от команды):
АЛУ с плавающей точкой предназначено для выполнения команд над операндами, представленными в формате чисел с плавающей запятой одинарной (32 бита) или двойной точности (64 бита) в соответствии с требованиями стандарта IEEE-754.
Структурно АЛУ с плавающей точкой состоит из трёх частей:
В чём отличие мультиклеточных процессоров от многоядерных?
В обычных процессорах, состоящих из одного или нескольких ядер, элементарной единицей исполнения является команда, выполняемая в определённом порядке. В мультиклеточном процессоре элементарной единицей исполнения является параграф, т.е. линейный участок, состоящий из неограниченного количества команд, после которых происходит переход на другой линейный участок с заданной меткой. Команды из этого участка будут выполняться параллельно там, где это возможно. Распараллеливание происходит аппаратно, т.е. программисту не нужно заботиться в какую клетку попадёт команда. Именно это мы и называем «естественный параллелелизм». Вследствие этого один и тот же код может быть выполнен на любом количестве клеток. Ещё одним отличием мультиклеточного процессора является передача результатов работы команд с помощью широковещательной рассылки, тогда как в много и одноядерных системах результаты передаются через память и регистры. Разумеется, в мультиклеточных процессорах имеется память и регистры для передачи данных между линейными участками, но внутри линейного участка основные операции можно провести без использования регистров и памяти. Данный факт даёт мультиклеточной архитектуре простоту реализации и уменьшение обращений к памяти, как следствие снижение энергопотребления. Кроме того выполнение одной и той же программы на одной, двух, …, двухсот пятидесяти шести клетках даёт возможности по реконфигурации (объединение клеток в task-группы) клеток, созданию отказоустойчивого процессора и масштабируемости.
К вопросам параллелилизма и реконфигурации мы ещё вернёмся далее в этой статье.
4.Примеры
Мультиклеточный процессор состоит из 4-х клеток (может быть 256 и более), клетки являются полностью равноправными и объединены коммутационной средой (коммутатором). Результат выполнения команд клетки хранят в коммутаторе.
Программа на ассемблере разделяется на секции и на параграфы, которые содержат команды.
Для обмена информацией между клетками служит коммутатор, а для обмена между параграфами существуют РОНы, индексные регистры, память данных. Для работы с периферией существуют периферийные регистры.
Чтобы отсеять высказывания вида:
Рассмотрим простую программу:
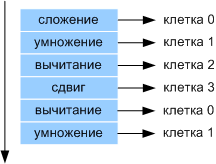
Рис 2. Распределение команд по клеткам
Как показано на рисунке 2 команды из параграфа будут распределяться по клеткам. Команды в каждых клетках выполняются параллельно («естественный параллелелизм»). Выполнение команд происходит по готовности аргументов. В данном случае программу выполняет группа из 4-х клеток. Программа успешно выполнится как на 4-х, так на любом другом количестве клеток. Основной принцип мультиклеточной архитектуры – клетки независимы друг от друга и от кого-либо и одинаковы. Данный принцип распространяется и на процессоры с реконфигурацией.
Реконфигурация — способность клеток процессора к композиции (сбор) и декомпозиции (разбор) по группам, т.е. возможность клеток объединяться в группы от одной клетки и до N(для N клеточного процессора) и выполнять свой участок кода. По умолчанию при старте любой программы все клетки находятся в одной группе. Стоит отметить, что у каждой группы появляется свой набор РОНов, индексных, управляющих регистров, можно назначить свой обработчик прерываний.
В статье про архитектуру фон-Неймана Леонид Черняк выделяет следующие три вида реконфигурируемых процессоров:
1) специализированные процессоры
2) конфигурируемые процессоры
3) динамически реконфигурируемые процессоры (в качестве примера приводится единственный класс этого вида, существующий на момент опубликования статьи Л.Черняка — FPGA).
Первые два вида приобретают свою специфику в процессе изготовления, а третий может программироваться.
Мультиклеточный процессор R1, в соответствии с этой классификацией, относится к динамически реконфигурируемым, однако это процессор на кристалле и, вследствие независимости машинного кода, перераспределение ресурсов (клеток) в отличие от FPGA происходит без остановки или перезагрузки процессора и без потери информации. Таким образом, MultiClet R1 представляет собой новый класс третьего вида (наряду с первым – FPGA).
На сегодня в мире таких процессоров не делал никто.
Предложенная Л.Черняком классификация, с поправкой на будущее развитие, может быть развита четвертым видом, который сформулируем, как
4) самоадаптирующиеся процессоры,
способные самостоятельно обеспечивать работу всех систем, автоматически перераспределяя ресурсы. При повреждении, отказах или при появлении дополнительных задач процессор или система из процессоров должна уметь самоадаптироваться к новым условиям.
Первым шагом к созданию таких систем, возможно, станет процессор Multiclet L1 или СвК на его основе.
Рассмотрим пример декомпозиции (разделения на группы) клеток:
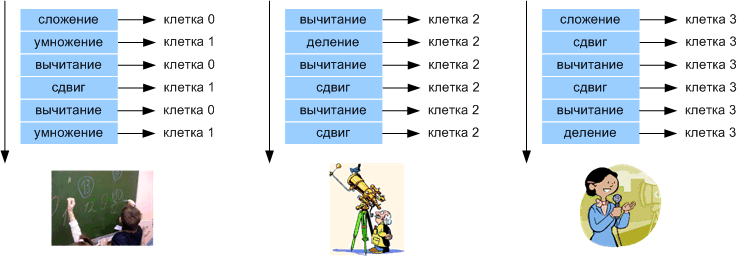
В данном примере мы видим разбиение на 3 группы: клетки с номерами 0 и 1 выполняют вычисления, клетка 2 выполняет сбор информации с датчиков, а клетка 3 составляет отчёты о работе и взаимодействует с внешней средой. Если случилось так, что клетки 0 и 1 не успевают обрабатывать данные, то клетка 3 может придти им на помощь и получатся две группы. Важно заметить, что сброса процессора для реконфигурации клеток не требуется. Клетка 3 будет разговаривать на одном языке с клетками 0 и 1, т.е. приобретёт их набор РОНов, индексных регистров и регистров управления.
Простой пример обычной программы на ассемблере (можно писать и на стандартном Си):
Параграфы находятся в секции размеченной как «.text». Параграф может содержать неограниченное количество команд (пока память программ позволяет), но каждая команда может обратиться за результатом только к команде, которая выше не более чем на 63 строки.
Для удобства в ассемблере можно задать метку к каждой команде, например:
В мультиклеточном процессоре нет аппаратных средств, обеспечивающих выявление информационных связей между выбранными операциями (командами) и их распределение по функциональным устройствам, т.е. динамическое распараллеливание отсутствует. Нет и статического распараллеливания, т.к. программа хотя и описывает информационные связи, но имеет линейную форму и не содержит каких-либо указаний, что и как можно выполнять параллельно. В этом состоит принципиальное отличие от других процессоров. Благодаря этой же особенности, потенциально обеспечивается живучесть мультиклеточного процессора, т.е. возможность непрерывного исполнения программы без перекомпиляции или перезагрузки при отказах его отдельных клеток (деградации процессора).
Благодаря свойству мультиклеточного процессора динамически распределять свои ресурсы, мы можем создавать системы способные выполнять задачу даже при отказах части клеток.
Деградация связана с потерей производительности и, соответственно, увеличением времени решения задач. Но, для целого ряда встроенных применений, живучесть мультиклеточного процессора позволяет управляемому объекту выполнять основные функции, либо за счет снижения их качества, либо за счет отказа от решения второстепенных задач.
Асинхронная и децентрализованная организация мультиклеточного процессора, как на системном уровне – между клетками (при реализации параллелизма), так и на внутриклеточном уровне – между блоками клетки (при реализации команд), дополнительно обеспечивает:
В результате, получается хорошо структурированная и модульная система, позволяющая резко уменьшить сложность процессора и, соответственно, снизить затраты и повысить качество проектирования. При этом по сравнению с фон-неймановской моделью, улучшаются и количественные характеристики процессора.
На данный момент проведены тесты простых алгоритмов, таких как POCNT и алгоритмов шифрования. Для теста popcnt была написана программа на ассемблере и результат мы сравнили с простой программой для Pentium Dual Core 5700 на Си.
Результаты тестирования можно свести в следующую таблицу (количество тактов на один цикл расчёта 32-х бит):
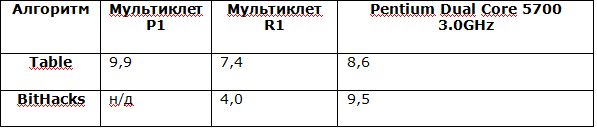
Т.е. можно сделать вывод, что процессор Мультиклет R1 на тесте «table» быстрее процессора Intel на 15%, а на тесте BitHacks процессор Мультиклет R1 быстрее чем Intel более чем в 2 раза. Тест popcnt для мультиклеточного процессора был достаточно просто преобразован для параллельных вычислений. Конечно, в новых процессорах Intel существует аппаратная реализация popcnt, но в данном тесте мы показали возможности наших процессоров.
5.Что у нас есть сейчас
На данный момент выпущен процессор Multiclet P1 и он доступен для заказа, а также две отладочные платы.

Кроме того на первом мультиклеточном процессоре разработано устройство для защиты информации Multiclet Key_P1, первая серийная партия запланирована на сентябрь 2014 года.

Кроме того на базе процессора Р1 был разработан и поставляется серийно принтер для тиснения фольгой от компании ООО Виршке.
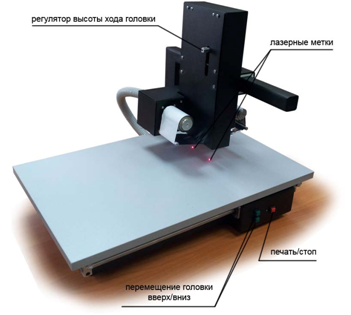
Пользователи активно осваивают мультиклеточные процессоры и дополняют библиотеки, а также создают новые полезные примеры.

Получена первая партия процессоров R1, начато тестирование новых процессоров.
Первая ревизия процессора называется R1-1.
Опять же новый процессор – тема для отдельной статьи, характеристики процессора первой ревизии опубликуем чуть позже.

Для данного процессора компания LDM-Systems выпустила отладочную плату, состоящую из базовой и процессорной. На фотографии версия с колодкой. Пользовательская версия будет немного отличаться. Комплектацию базовой платы можно будет выбирать под свои задачи, в максимальной комплектации базовая+процессорная платы будут иметь приемлемую стоимость.

Комплект ПО включает:
• Ассемблер
• Си компилятор
• Функциональная модель
• Библиотеки
• Отладчик для IDE Geany
• ОС FreeRTOS
• Примеры программ
• Графопостроитель
P.S. Если вам понравилась данная статья несмотря на большой объём, то могу написать продолжение по программированию процессоров, обзор процессора R1 и принципы построения высокопроизводительных систем на мультиклеточных процессорах.
UPD: Программа для проверки времени работы алгоритма popcnt взята с сайта www.strchr.com/crc32_popcnt. Как уже отмечалось в статье, для процессоров Интел существуют и другие более быстрые алгоритмы реализации теста popcnt, которые требуют определенных команд, реализованных на аппаратном уровне. Для оценки возможностей мультиклеточной архитектуры были взяты алгоритмы Table и Bit hacks.
UPD2: Обновлен рисунок 2. Команда add @3, @2 должна быть растянута на две строки, а команда mpy @4, @3 была уменьшена по длительности, т.к. аргументы для неё были готовы раньше, что уменьшило и общую длительность параграфа. Также команда mpy заменена на mul.
UPD3: Каждая клетка содержит буфер на 64 команды. Выборка команд параграфа клетками продолжается параллельно с выполнением, выборка следующего параграфа может быть начата, только в случае если известен адрес перехода на него.
1.Мультиклеточность
Мультиклеточное ядро — это группа идентичных процессорных блоков(2 и более), объединенных полносвязной однонаправленной коммутационной средой. Особенности взаимодействия процессорных блоков между собой вытекают из представления алгоритма (об этом ниже). Процессорный блок в мультиклеточной архитектуре называется клеткой. Набор команд, который она может выполнять определяется конкретной реализацией и не зависит от архитектуры.
Алгоритмы «глазами» мультиклеточного ядра
Во-первых.
Любую формулу можно представить в виде ярусно-параллельной формы (ЯПФ). Рассмотрим
простой пример: g = e*(a+b) + (a-c)*f, в ЯПФ это может выглядеть так:
Рис 1. Пример ЯПФ
В общем случае, для выполнения операций узлы, расположенные на i-ом ярусе, могут использовать результаты, полученные на ярусах от 1 до (i-1)-го. Из этого следует, что команды, находящиеся на одном ярусе, независимы.
Любой алгоритм – это множество формул, которое разделено на подмножества — линейные участки, связанные между собой операторами передачи управления. Под линейным участком (ЛУ) понимается такое подмножество формул, которое вычисляется тогда и только тогда, когда управление передано на данный линейный участок. Внутри линейного участка, информационно несвязанные формулы могут выполняться в любом порядке.
Как известно, результат выполнения процессором любой команды выражается в изменении состояния процессора. Использование этого нового состояния последующими командами, образует информационную связь между командой–источником результата и командами–приемниками этого результата. Такая связь может быть как опосредованной (косвенной), так и непосредственной (прямой).
При косвенной связи результат доступен только после его отчуждения: записи в общедоступные регистры или память или др. устройства. Команда-источник должна поместить результат в эти устройства, а команда-приемник должна будет взять данные оттуда. Имя устройства указывается в качестве операнда. Такая связь между командами является основой абсолютно всех современных процессоров, кроме мультиклеточных.
В случае прямой информационной связи, команды именуются и при этом имена должны идентифицировать собственно команду, а не ее местоположение или другие особенности реализации. Доступ к результатам может осуществляться по именам как команд–источников, так команд–приемников. В первом случае используется широковещательная рассылка с последующим поименным отбором, при которой в поле операнда команды–приемника задают имя команды–источника. Во втором – выполняется поименная рассылка, при которой в команде–источнике задают имя команды–приемника результата.
Теоретически узлы ЯПФ мы можем поименовать любым образом. Единственное требование — однозначность. Для этого в мультиклеточном процессоре команды, при выборке из памяти, получают тег (метку) — таким образом им и их результатам дается локальное имя — и далее взаимодействие между командами организовывается через теги. Данные можно получать из любой команды с тегом меньше своего. Номер тега требуемого результата задается разницей значений тега команды и тега требуемого результата. Например, если в операнде указано @5, а тег команды равен 7, то в качестве операнда используется результат команды с тегом 2. Все результаты выполнения команд поступают в коммутационную среду, из которой по тегу отбираются требуемые. Таким образом в мультиклеточном процессоре используется широковещательная рассылка результатов с последующим их поименным отбором.
Стоит отметить, что из-за физических ограничений есть понятие «окна видимости», которое определяет максимальное расстояние команды-источника от команды приемника. Тег в процессе выборки команд изменяется циклически. Его максимальная величина определяется размером буфера команд. Фактически размер тега определяет количество команд, которые одновременно могут находиться на разных стадиях исполнения. Значение тега не может быть использовано, если команда, которой он ранее был присвоен, еще не выполнена.
Во-вторых.
Мультиклеточный процессор оперирует структурами, которые мы называем — параграфами.
Параграф — это информационно замкнутая последовательность команд. Параграф является аналогом команды, после выполнения которой, изменяется состояние процессора и/или систем в его составе (регистров, шин, ячеек памяти, каналов ввода/вывода и т.д.). Т.е. для мультиклеточного ядра параграф — это команда.
Основная особенность мультиклеточной архитектуры в том, что она непосредственно реализует ЯПФ представления алгоритма. Из такого понимания алгоритма вытекают многие свойства мультиклеточной архитектуры.
2.Свойства мультиклеточной архитектуры
- независимость от кол-ва клеток;
- динамическое распределение вычислительных ресурсов;
- все команды, готовые к выполнению, выполняются одновременно;
- снижение энергопотребления. Работает тогда, когда есть работа;
- масштабируемость, нет ограничений на кол-во клеток.
Рассмотрим подробнее как будет выглядеть параграф для алгоритма, описанного в п.2.
Для мультиклеточно ядра характерна следующая схема построения параграфа (не является обязательной, в приведенном примере так же есть отступления):
- получение данных для работы (команды с тегом 0-2,4,6 в примере);
- процесс обработки данных (команды с тегом 3,5,7-9 в примере);
- сохранение результатов (команда с тегом 10 в примере).
Следует напомнить, что изменение состояния машины в мультиклеточном процессоре происходит по концу параграфа.
Алгоритм не зависит от кол-ва клеток.
Информационные связи между командами указаны явно и нет необходимости знать о количестве процессорных блоков, когда пишется программа. Команды просто ждут готовности своих операндов и после этого уходят на исполнение и им не важно кто и когда им подготовит операнды. Представьте лейку — вы не задумываетесь сколько отверстий в ее насадке, когда поливаете. Клетки идентичны и нет разницы в какой клетке будет выполняться та или иная команда.
Команды распределяются по клеткам в порядке их следования, 1 команда в 0 клетку, 2 команда в 1 клетку и т. д., когда передали команду в последнюю имеющуюся клетку — начинаем распределять заново с 0 клетки. Рассмотрим работу 4-х клеточного ядра. Параграф, приведенный выше, будет выполняться следующим образом:
Рис 2. Распределение команд по клеткам
Кол-во одновременно выполняемых команд зависит от кол-ва клеток. Выбор оптимального числа клеток для каждой задачи — это задача, которая требует анализа. Создать универсальную систему все равно не получится, поэтому можно ориентироваться на следующие данные: на общих задачах неплохо справляются 4 клетки, а с задачами обработки сигналов — 16 клеток, а для обработки видеоизображения их число может быть порядка сотен.
Можете провести анализ своего кода и представить каким было бы оптимальное число клеток для них. Для того потребуется представить ваш алгоритм в ЯПФ и подсчитать количество команд в ярусах. Среднее число команд в них будет намекать на оптимальное количество клеток в вашем конкретном случае.
Все команды, готовые к выполнению, выполняются одновременно.
Как упоминалось выше, мультиклеточное ядро реализует ЯПФ представление алгоритма, на ярусах располагаются независимые команды. Все, что в данный момент может быть выполнено — будет выполнено без каких-либо специальных указаний со стороны программиста, основное условие — команда должна получить все данные для исполнения.
Стоит учитывать технологические ограничения: кол-во клеток ограничено, поэтому выполняться одновременно будет столько команд, сколько клеток в ядре.
«Сход-развал» или динамическое распределение вычислительных ресурсов
Т.к. код не зависит от количества клеток, которым он будет исполняться, появляется способность мультиклеточного ядра к распределению своих вычислительных ресурсов во время работы, при этом управление происходит программно.
Способность мультиклеточной архитектуры перераспределять свои ресурсы мы называем — реконфигурацией. Например, клетки мультиклеточного ядра могут быть, как угодно распределены для выполнения какого-либо алгоритма или его части. Группа (лучше названия пока не придумали) — это часть клеток мультиклеточного ядра, которые связаны между собой для выполнения какого-либо алгоритма или части алгоритма. В группе может находиться 1 и более клеток. Когда мультиклеточное ядро разделяет группу на части — это называется декомпозиция. Процесс объединения в группу — композиция. На рис 3 ниже показано как 4-х клеточное ядро со временем реконфигурируется (пример). Клетки, выполняющие одну задачу, имеют одно цветовое заполнение.
Рис 3. Пример реконфигурации клеток
Снижение энергопотребления. Работает тогда, когда есть работа.
Принципиальной основой мультиклеточной архитектуры является широковещательная рассылка. На сегодняшний день – это пока единственная архитектура, использующая непосредственную информационную связь для передачи данных между командами в программе.
Если обратить внимание на рис 1, на котором показан пример выполнения кода 4-х клеточным процессором, то видно, что клетки выполняют команды расположенные на ярусах тогда, когда они готовы быть выполнены. Результат помещается в коммутационную среду и ждет своего потребителя.
Мультиклеточное ядро не совершает лишних действий, работает тогда, когда есть работа. Если какая-нибудь из составляющих процессора не готовая выполнить команду, то работа с ней приостанавливается до освобождения.
Масштабируемость, нет ограничений на кол-во клеток.
Архитектура не ограничивает кол-во клеток. Дело стоит за технологиями.
Есть несколько вариантов организации большого числа клеток, но это тема для отдельной статьи, которую подготовим позже.
3.Реализация
Мультиклеточный процессор «во-плоти»
Мультиклеточный процессор состоит из N идентичных клеток с номерами от 0 до n-1, объединённых коммутационной средой. Каждая клетка содержит блок памяти программ (PM), устройство управления (CU), буферные устройства (BUF), а также каждой клетке соответствует коммутационное устройство (SU), совокупность которых образует коммутационную среду (SB). Процессор также содержит память данных (DM), блок регистров общего назначения (GPR) и исполнительно устройство(EU), состоящее из арифметико-логического устройства для чисел с плавающей запятой(ALU_FLOAT), АЛУ для целых чисел(ALU_INTEGER) и блок доступа к памяти данных(DMS).
Программа для мультиклеточного ассемблера состоит из параграфов. Например:
Paragraph: ;Различные команды jmp paragraph_next ; переход на следующий параграф complete
На самом деле команда перехода на следующий параграф может стоять в любом месте текущего параграфа, но пока мы не заостряем на этом внимание. В данном примере параграф – это все команды от метки “Paragragh” до метки конца участка команд — «complete».
В параграфе команды могут располагаться в произвольном порядке, команды могут ссылаться на результат предыдущих команд с помощью оператора «@», но следует учитывать, что нельзя сослаться на результат команды, которая выше текущей на 64 команды. Т.е. окно видимости результата для каждой команды равно 64, при этом размер параграфа не ограничен, т.е. он может состоять хоть из нескольких тысяч команд. Рассмотрим пример:
Paragraph: getl 2 ;загрузка числа в коммутатор getl 3 ;загрузка числа в коммутатор addl @1, @2 ;сложение 2 + 3 addl @1, @3 ;сложение 5 +2 jmp paragraph2 complete
В рассматриваемом примере команда addl @1, @2 выполняет сложение двух предыдущих команд, а команда addl @1, @3 выполняет сложение результата предыдущей команды и результат команды, которая на 3 строчки выше.
Состояние процессора меняется при переходах от одного параграфа к другому. Записи в память, регистры происходят по концу параграфа в случае, если контроль чтения записи включён или не используются команды прямого чтения и записи. Но есть возможность отключения контроля чтения и записи, т.е. запись в память будет проходить в самом параграфе, не дожидаясь его завершения (в случаях, когда есть возможность отключить контроль чтения и записи, при работе с памятью может принести ощутимое увеличение производительности). На самом деле выжать максимум из мультиклеточного процессора несложно, но это тема для отдельной статьи.
Для исполнения контекстно-зависимой программы, команды каждого параграфа последовательно, начиная с одного и того же адреса, являющегося адресом данного параграфа, размещают в PM клеток. Адрес размещения первого исполняемого параграфа равен адресу, начиная с которого клетки выбирают команды. В результате, в PM i–ой клетки, начиная с адреса параграфа, последовательно размещаются его команды с номерами i, N+i, 2*N+i,...,.
Каждая клетка обеспечивает, начиная с указанного ему адреса, последовательную выборку команд и размещение их на регистре команд для последующего декодирования. Команды клетками выбираются синхронно.
При декодировании каждой очередной выбранной группе из N команд присваивают очередное значение тега (t), а команде из группы и, соответственно, ее результату – номер. Выборка и декодирование команд продолжается до тех пор, пока не будет выбрана команда, отмеченная управляющим признаком «конец параграфа»(Complete). Адрес нового параграфа может поступить как в любой момент выборки команд текущего параграфа, так и после завершения выборки команд. Он поступает всем клеткам одновременно. Если к моменту выборки последней команды параграфа адрес следующего параграфа не вычислен, то выборка приостанавливается до получения адреса. Если адрес получен, то выборка продолжается с этого адреса. Выбранная команда поступает в буферное устройство, которое состоит из буфера первого операнда, буфера второго операнда и буфера команд (коды операций, теги и т.п.) Буферные устройства формируют команды и передают их соответствующему исполнительному устройству.
Операционная часть (буфер команд), кроме кода команды, включает в себя всю необходимую служебную информацию для рассылки и приема результатов, а именно, номер команды и признаки готовности первого (второго) операнда для выполнения команды.
Буфер хранения операндов имеет ассоциативную адресацию. Ассоциативным
адресом является тег запрашиваемого результата. В качестве операндов при выполнении операций могут использоваться:
- запрошенные результаты команд–источников, поступающие из коммутатора;
- значения, вычисленные при декодировании командного слова, а также непосредственно присутствующие в командном слове или взятые из регистров общего назначения.
В первом случае признак готовности данного операнда при записи команды устанавливают в состояние «не готов», а во втором – в состояние «готов». После получения запрошенного результата от коммутационного устройства, признак, в первом случае, также устанавливают в состояние «готов». Команда, получившая все операнды, проходит приоритетный отбор среди других готовых команд в буферном устройстве, после чего выдается на исполнение при условии незанятости исполнительного устройства.
В процессоре P1 для каждой клетки был выделен свой участок памяти, т.е. память программ и память данных не пересекались. В процессоре R1 память программ и память данных находятся в одном адресном пространстве, т.е. у клеток есть каналы доступа к памяти программ и памяти данных. На рис 4 приведена общая структура процессора P1. На рис 5 приведена структура клетки и её описание для процессора R1.
Рис 4. Общая структура мультиклеточного процессора
Арифметико-логические устройства (АЛУ), наряду с блоком DMS, входят в состав набора исполнительных устройств имеющегося в каждой клетке (CELL).
В состав клетки входят следующие устройства:
1. Устройство выборки команд IDU (Instruction Distribution Unit).
2. Устройство управления.
3. Коммутационное устройство SU (Switch Unit).
4. Буферное устройство.
5. Целочисленное АЛУ.
6. АЛУ с плавающей точкой.
7. Блок доступа к памяти данных DMS (Data Memory Service).
8. Мультиплексор результатов.
9. Набор регистров GPR (General-Purpose Registers).
10. Контроллер прерываний IC (Interrupt Controller).
11. Отладочный блок JTAG-GPR.
Подробная структура клетки представлена на рисунке 5:
Рис 5. Структура клетки.
Результат выполнения команд исполнительные устройства передают в коммутационное устройство.
Если одновременно готовы результаты выполнения команд целочисленного АЛУ, АЛУ с плавающей точкой и DMS, коммутационное устройство принимает результат выполнения команды АЛУ с плавающей точкой. По приоритету чтения результата исполнительные устройства распределяются следующим образом:
1.АЛУ с плавающей точкой;
2.DMS;
3.Целочисленное АЛУ.
Исполнительные устройства, результат работы которых на текущем такте не может быть выдан в коммутационное устройство, записывают результат выполнения команды в выходной регистр и ожидают своей очереди на выдачу результата.
Описанная выше ситуация имеет следствием то, что количество тактов, необходимое для выполнения команды, является величиной недетерминированной.
В каждой клетке имеются два АЛУ: целочисленное АЛУ и АЛУ обработки чисел с плавающей точкой.
Целочисленное АЛУ предназначено для выполнения команд над целочисленными операндами, при этом операнды могут быть представлены в следующих форматах (в зависимости от команды):
- 64-битные;
- 32-битные;
- 16-битные;
- 8-битные;
- упакованные 32-битные;
- упакованные 16-битные.
АЛУ с плавающей точкой предназначено для выполнения команд над операндами, представленными в формате чисел с плавающей запятой одинарной (32 бита) или двойной точности (64 бита) в соответствии с требованиями стандарта IEEE-754.
Структурно АЛУ с плавающей точкой состоит из трёх частей:
- Делитель одинарной точности (деление, извлечение квадратного корня)
- Делитель двойной точности
- Вычислитель (выполнение остальных команд)
В чём отличие мультиклеточных процессоров от многоядерных?
В обычных процессорах, состоящих из одного или нескольких ядер, элементарной единицей исполнения является команда, выполняемая в определённом порядке. В мультиклеточном процессоре элементарной единицей исполнения является параграф, т.е. линейный участок, состоящий из неограниченного количества команд, после которых происходит переход на другой линейный участок с заданной меткой. Команды из этого участка будут выполняться параллельно там, где это возможно. Распараллеливание происходит аппаратно, т.е. программисту не нужно заботиться в какую клетку попадёт команда. Именно это мы и называем «естественный параллелелизм». Вследствие этого один и тот же код может быть выполнен на любом количестве клеток. Ещё одним отличием мультиклеточного процессора является передача результатов работы команд с помощью широковещательной рассылки, тогда как в много и одноядерных системах результаты передаются через память и регистры. Разумеется, в мультиклеточных процессорах имеется память и регистры для передачи данных между линейными участками, но внутри линейного участка основные операции можно провести без использования регистров и памяти. Данный факт даёт мультиклеточной архитектуре простоту реализации и уменьшение обращений к памяти, как следствие снижение энергопотребления. Кроме того выполнение одной и той же программы на одной, двух, …, двухсот пятидесяти шести клетках даёт возможности по реконфигурации (объединение клеток в task-группы) клеток, созданию отказоустойчивого процессора и масштабируемости.
К вопросам параллелилизма и реконфигурации мы ещё вернёмся далее в этой статье.
4.Примеры
Мультиклеточный процессор состоит из 4-х клеток (может быть 256 и более), клетки являются полностью равноправными и объединены коммутационной средой (коммутатором). Результат выполнения команд клетки хранят в коммутаторе.
Программа на ассемблере разделяется на секции и на параграфы, которые содержат команды.
Для обмена информацией между клетками служит коммутатор, а для обмена между параграфами существуют РОНы, индексные регистры, память данных. Для работы с периферией существуют периферийные регистры.
Чтобы отсеять высказывания вида:
- Пусть даже это «страница» памяти, но кто «рулит» всей памятью? Где старшее (верхнее) УУ, управляющее клетками? Кто загружает память клеток?
- Параллелит программист, а не процессор
Рассмотрим простую программу:
Рис 2. Распределение команд по клеткам
Как показано на рисунке 2 команды из параграфа будут распределяться по клеткам. Команды в каждых клетках выполняются параллельно («естественный параллелелизм»). Выполнение команд происходит по готовности аргументов. В данном случае программу выполняет группа из 4-х клеток. Программа успешно выполнится как на 4-х, так на любом другом количестве клеток. Основной принцип мультиклеточной архитектуры – клетки независимы друг от друга и от кого-либо и одинаковы. Данный принцип распространяется и на процессоры с реконфигурацией.
Реконфигурация — способность клеток процессора к композиции (сбор) и декомпозиции (разбор) по группам, т.е. возможность клеток объединяться в группы от одной клетки и до N(для N клеточного процессора) и выполнять свой участок кода. По умолчанию при старте любой программы все клетки находятся в одной группе. Стоит отметить, что у каждой группы появляется свой набор РОНов, индексных, управляющих регистров, можно назначить свой обработчик прерываний.
В статье про архитектуру фон-Неймана Леонид Черняк выделяет следующие три вида реконфигурируемых процессоров:
1) специализированные процессоры
2) конфигурируемые процессоры
3) динамически реконфигурируемые процессоры (в качестве примера приводится единственный класс этого вида, существующий на момент опубликования статьи Л.Черняка — FPGA).
Первые два вида приобретают свою специфику в процессе изготовления, а третий может программироваться.
Мультиклеточный процессор R1, в соответствии с этой классификацией, относится к динамически реконфигурируемым, однако это процессор на кристалле и, вследствие независимости машинного кода, перераспределение ресурсов (клеток) в отличие от FPGA происходит без остановки или перезагрузки процессора и без потери информации. Таким образом, MultiClet R1 представляет собой новый класс третьего вида (наряду с первым – FPGA).
На сегодня в мире таких процессоров не делал никто.
Предложенная Л.Черняком классификация, с поправкой на будущее развитие, может быть развита четвертым видом, который сформулируем, как
4) самоадаптирующиеся процессоры,
способные самостоятельно обеспечивать работу всех систем, автоматически перераспределяя ресурсы. При повреждении, отказах или при появлении дополнительных задач процессор или система из процессоров должна уметь самоадаптироваться к новым условиям.
Первым шагом к созданию таких систем, возможно, станет процессор Multiclet L1 или СвК на его основе.
Рассмотрим пример декомпозиции (разделения на группы) клеток:
В данном примере мы видим разбиение на 3 группы: клетки с номерами 0 и 1 выполняют вычисления, клетка 2 выполняет сбор информации с датчиков, а клетка 3 составляет отчёты о работе и взаимодействует с внешней средой. Если случилось так, что клетки 0 и 1 не успевают обрабатывать данные, то клетка 3 может придти им на помощь и получатся две группы. Важно заметить, что сброса процессора для реконфигурации клеток не требуется. Клетка 3 будет разговаривать на одном языке с клетками 0 и 1, т.е. приобретёт их набор РОНов, индексных регистров и регистров управления.
Простой пример обычной программы на ассемблере (можно писать и на стандартном Си):
.text habr: getl 4 ;загрузка константы в коммутатор getl 5 ; загрузка константы в коммутатор addl @1, @2 ;сложение 4 + 5 = 9 mull @3, @2 ;умножение 4 * 5 = 20 subl @1, @2 ;вычитание 20 – 9 = 11 slrl @1, 2 ;сдвиг 11 << 2 = 44 subl @1, @2 ;вычитание 44 – 11 = 33 mull @4, @5 ;умножение 20 * 9 = 180 jmp habrahabr ;переход на следующий параграф complete habrahabr: getl 5 ;загрузка константы в коммутатор addl @1, [10] ;сложение константы и значения из памяти по адресу 10 setl #32, @1 ;запись суммы в регистр номер 32 complete
Параграфы находятся в секции размеченной как «.text». Параграф может содержать неограниченное количество команд (пока память программ позволяет), но каждая команда может обратиться за результатом только к команде, которая выше не более чем на 63 строки.
Для удобства в ассемблере можно задать метку к каждой команде, например:
habr: arg1 := getl 5 ;загрузка константы в коммутатор sum1 := addl @arg1, [10] ;сложение константы и значения из памяти по адресу 10 setl #32, @sum1 ;запись суммы в регистр номер 32 complete
В мультиклеточном процессоре нет аппаратных средств, обеспечивающих выявление информационных связей между выбранными операциями (командами) и их распределение по функциональным устройствам, т.е. динамическое распараллеливание отсутствует. Нет и статического распараллеливания, т.к. программа хотя и описывает информационные связи, но имеет линейную форму и не содержит каких-либо указаний, что и как можно выполнять параллельно. В этом состоит принципиальное отличие от других процессоров. Благодаря этой же особенности, потенциально обеспечивается живучесть мультиклеточного процессора, т.е. возможность непрерывного исполнения программы без перекомпиляции или перезагрузки при отказах его отдельных клеток (деградации процессора).
Благодаря свойству мультиклеточного процессора динамически распределять свои ресурсы, мы можем создавать системы способные выполнять задачу даже при отказах части клеток.
Деградация связана с потерей производительности и, соответственно, увеличением времени решения задач. Но, для целого ряда встроенных применений, живучесть мультиклеточного процессора позволяет управляемому объекту выполнять основные функции, либо за счет снижения их качества, либо за счет отказа от решения второстепенных задач.
Асинхронная и децентрализованная организация мультиклеточного процессора, как на системном уровне – между клетками (при реализации параллелизма), так и на внутриклеточном уровне – между блоками клетки (при реализации команд), дополнительно обеспечивает:
- минимизацию номенклатуры объектов проектирования и уменьшение их
сложности; - уменьшение площади кристалла процессора (объем оборудования при
децентрализованном управлении меньше, чем при централизованном); - увеличение производительности и сокращение энергопотребления за счет
реализации более эффективного вычислительного процесса; - использование индивидуальной системы синхронизации для каждой клетки
при реализации на одном кристалле десятков и сотен клеток.
В результате, получается хорошо структурированная и модульная система, позволяющая резко уменьшить сложность процессора и, соответственно, снизить затраты и повысить качество проектирования. При этом по сравнению с фон-неймановской моделью, улучшаются и количественные характеристики процессора.
На данный момент проведены тесты простых алгоритмов, таких как POCNT и алгоритмов шифрования. Для теста popcnt была написана программа на ассемблере и результат мы сравнили с простой программой для Pentium Dual Core 5700 на Си.
Результаты тестирования можно свести в следующую таблицу (количество тактов на один цикл расчёта 32-х бит):

Т.е. можно сделать вывод, что процессор Мультиклет R1 на тесте «table» быстрее процессора Intel на 15%, а на тесте BitHacks процессор Мультиклет R1 быстрее чем Intel более чем в 2 раза. Тест popcnt для мультиклеточного процессора был достаточно просто преобразован для параллельных вычислений. Конечно, в новых процессорах Intel существует аппаратная реализация popcnt, но в данном тесте мы показали возможности наших процессоров.
5.Что у нас есть сейчас
На данный момент выпущен процессор Multiclet P1 и он доступен для заказа, а также две отладочные платы.

Кроме того на первом мультиклеточном процессоре разработано устройство для защиты информации Multiclet Key_P1, первая серийная партия запланирована на сентябрь 2014 года.

Кроме того на базе процессора Р1 был разработан и поставляется серийно принтер для тиснения фольгой от компании ООО Виршке.

Пользователи активно осваивают мультиклеточные процессоры и дополняют библиотеки, а также создают новые полезные примеры.

Получена первая партия процессоров R1, начато тестирование новых процессоров.
Первая ревизия процессора называется R1-1.
Опять же новый процессор – тема для отдельной статьи, характеристики процессора первой ревизии опубликуем чуть позже.

Для данного процессора компания LDM-Systems выпустила отладочную плату, состоящую из базовой и процессорной. На фотографии версия с колодкой. Пользовательская версия будет немного отличаться. Комплектацию базовой платы можно будет выбирать под свои задачи, в максимальной комплектации базовая+процессорная платы будут иметь приемлемую стоимость.

Комплект ПО включает:
• Ассемблер
• Си компилятор
• Функциональная модель
• Библиотеки
• Отладчик для IDE Geany
• ОС FreeRTOS
• Примеры программ
• Графопостроитель
P.S. Если вам понравилась данная статья несмотря на большой объём, то могу написать продолжение по программированию процессоров, обзор процессора R1 и принципы построения высокопроизводительных систем на мультиклеточных процессорах.
UPD: Программа для проверки времени работы алгоритма popcnt взята с сайта www.strchr.com/crc32_popcnt. Как уже отмечалось в статье, для процессоров Интел существуют и другие более быстрые алгоритмы реализации теста popcnt, которые требуют определенных команд, реализованных на аппаратном уровне. Для оценки возможностей мультиклеточной архитектуры были взяты алгоритмы Table и Bit hacks.
UPD2: Обновлен рисунок 2. Команда add @3, @2 должна быть растянута на две строки, а команда mpy @4, @3 была уменьшена по длительности, т.к. аргументы для неё были готовы раньше, что уменьшило и общую длительность параграфа. Также команда mpy заменена на mul.
UPD3: Каждая клетка содержит буфер на 64 команды. Выборка команд параграфа клетками продолжается параллельно с выполнением, выборка следующего параграфа может быть начата, только в случае если известен адрес перехода на него.

