
Ранее мы познакомились с тем, как ядро управляет виртуальной памятью процесса, однако работу с файлами и ввод/вывод мы опустили. В этой статье рассмотрим важный и часто вызывающий заблуждения вопрос о том, какая существует связь между оперативной памятью и файловыми операциями, и как она влияет на производительность системы.
Что касается работы с файлами, тут операционная система должна решить две важные проблемы. Первая проблема – удивительно низкая скорость работы жестих дисков (особенно операций поиска) по сравнению со скоростью оперативной памяти. Вторая проблема – возможность совместного использования единожды загруженного в оперативную память файла разными программами. Взглянув на процессы с помощью Process Explorer, мы увидим, что порядка 15 МБ оперативной памяти в каждом процессе тратится на общие DLL-библиотеки. На моем компьютере в данный момент выполняется 100 процессов, и, если бы не существовала возможность совместного использования файлов в памяти, то около 1,5 ГБ памяти тратилось бы только на общие DLL-библиотеки. Это, конечно, неприемлемо. В Linux, программы тоже используют разделяемые библиотеки типа ld.so, libc и других.
К счастью, обе проблемы можно решить, как говорится, одним махом – с помощью страничного кэша (page cache). Страничный кэш используется ядром для хранения фрагментов файлов, причем каждый фрагмент имеет размер в одну страницу. Для того, чтобы лучше проиллюстрировать идею страничного кэша, я придумал программу под названием render, которая открывает файл scene.dat, читает его порциями по 512 байт и копирует их в выделенное пространство в куче. Первая операция чтения будет осуществлена так, как показано на рисунке вверху.
После того, как будут прочитаны 12 KБ, куча процесса render и имеющие отношения к делу физические страницы будут выглядеть следующим образом:

Кажется, все просто, но на деле все, много чего происходит. Во-первых, даже несмотря на то, что наша программа использует обычные вызовы read(), в результате их выполнения в страничном кэше окажется три 4-килобайтных страницы с содержимым файла scene.dat. Многие удивляются, но все стандартные операции файлового ввода / вывода работают через страничный кэш. В Linux на x86-платформе, ядро представляет файл в виде последовательности 4-килобайтных фрагментов. Если запросить прочтение всего навсего одного байта из файла, то этого приведет к тому, что 4-килобайтный фрагмент, содержащий данный байт, будет целиком прочитан с диска и помещен в страничный кэш. Вообще говоря, в этом есть смысл, потому что, во-первых, производительность при непрерывном чтении с диска (sustained disk throughput) является достаточно высокой, и, во-вторых, программы обычно читают более одного байта из некоторой области файла. Страничный кэш знает о том, какое место в файле занимает каждый скэшированный его фрагмент; это изображено на рисунке как #0, #1, и т.д. В Windows используются 256-килобайтные фрагменты (называемые “view”), которые по своему предназначению аналогичны страницам в страничном кэше Linux.
При использовании обычных операций чтения, данные сначала попадают в страничный кэш. Программисту данные доступны порционально, через буфер, и из него он копирует их (в нашем примере) в область в куче. Данный подход к делу является крайне неэффективным – не только тратятся вычислительные ресурсы процессора и оказывается негативное влияние на процессорные кэши, но также происходит напрасная трата оперативной памяти на хранение копий одних и тех же данных. Если взглянуть на предыдущий рисунок, то будет видно, что содержимое файла scene.dat хранится сразу в двух экземплярах; любой новый процесс, работающий с этим файлом, скопирует эти данные еще раз. Таким образом, вот чего мы добились – несколько уменьшили проблему задержки при чтении с диска, но в остальном потерпели полную неудачу. Однако, решение проблемы существует – это «отображение файлов в память» (memory-mapped files):

Когда программист использует отображение файлов в память, ядро мэппирует виртуальные страницы напрямую в физические страницы в страничном кэше. Это позволяет добиться значительного прироста производительности – в Windows System Programming пишут об ускорении времени выполнения программы на 30% и более по сравнению со стандартными файловыми операциями ввода/вывода. Аналогичные цифры, только теперь уже для Linux и Solaris, приводятся и в книге Advanced Programming in the Unix Environment. С помощью данного механизма можно писать программы, которые будут использовать значительно меньше оперативной памяти (хотя тут многое также зависит от особенностей самой программы).
Как всегда, главное в вопросах производительности – это измерения и наглядные результаты. Но даже и без этого, отображение файлов в память вполне себя окупает. Интерфейс программирования – достаточно приятный и позволяет читать файлы как обычные байты в памяти. Ради всех преимуществ данного механизма не придется чем-то особенным жертвовать, например, читаемость кода никак не пострадает. Как говорится, флаг вам в руки – не бойтесь экспериментировать со своим адресным пространством и вызовом mmap в Unix-подобных системах, вызовом CreateFileMapping в Windows, а также разными оберточными функциями, доступными в высокоуровневых языках программирования.
Когда создается отображение файла в память, его содержимое попадает туда не сразу, а постепенно – по мере, того, как процессор отлавливает page faults, вызванные обращением к еще незагруженным фрагментам файла. Обработчик для такого page fault отыщит нужный page-фрейм в страничном кэше и осуществит мэппирование виртуальной страницы в данный page-фрейм. Если нужные данные до этого не были скэшированы в страничном кэше, то будет инициирована операция чтения с диска.
А теперь, вопрос. Представим, что программа render завершила выполнение, и никаких ее дочерних процессов тоже не осталось. Будут ли при этом тут же высвобождены страницы в страничном кэше, хранящие фрагменты файла scene.dat? Многие думают, что да – но это было бы неэффективно. Вообще, если попытаться проанализировать ситуацию, то вот что приходит в голову: достаточно часто мы создаем файл в одной программе, она завершает свое выполнение, затем файл используется в другой программе. Страничный кэш должен предусматривать такие ситуации. И вообще, зачем ядру в принципе избавляться от содержимого страничного кэша? Мы же помним, что скорость работы жесткого диска на пять порядков медленнее оперативной памяти. И если случается так, что данные ранее уже были скэшированы, то нам крупно повезло. Именно поэтому, из страничного кэша ничего не удаляется, по крайней мере до тех пор, пока есть свободная оперативная память. Страничный кэш не зависит от какого-то конкретного процесса, наоборот – это такой ресурс, который совместно использует вся система. Неделю спустя, вновь запустим render, и если файл scene.dat все еще находится в страничном кэше — ну, что ж, нам везет! Вот почему размер страничного кэша постепенно растет, а затем его рост вдруг останавливается. Нет, не потому что операционная система – полная фигня, которая съедает всю оперативу. А потому, что так и должно быть. Неиспользуемая оперативная память – это тоже своего рода напрасно растрачиваемый ресурс. Лучше использовать как можно больше оперативной памяти под страничный кэш, чем вообще никак не использовать.
Когда программа делает вызов write(), данные просто копируются в соответствующую страницу в страничном кэше, и она помечается флагом «dirty». Запись непосредственно на сам жесткий диск не происходит сразу же, и нет смысла блокировать программу в ожидании, пока дисковая подсистема станет доступной. Есть у этого поведения и свой недостаток – если компьютер упадет в синий экран, то данные могут так и не попасть на диск. Именно поэтому критически важные файлы, как например, файлы журнала транзакций баз данных, нужно синхронизировать специальным вызовом fsync() (но вообще, есть еще кэш контроллера жесткого диска, так что и здесь нельзя быть абсолютно уверенным в успешности операции записи). Вызов read() напротив блокирует программу до тех пор, пока диск не станет доступным и данные не будут прочитаны. Для того, чтобы несколько смягчить данную проблему, операционные системы используют т.н. «метод нетерпеливой загрузки» (eager loading), и примером этого метода является «опережающее чтение» (read ahead). Когда задействуется опережающее чтение, ядро производит упреждающую загрузку определенного количества файловых фрагментов в страничный кэш, предвосхищая тем самым последуюшие запросы на чтение. Можно помочь ядру с выбором оптимальных параметров для опережающего чтения, выбрав параметр в зависимости от того, как Вы собираетесь читать файл – последовательно или в произвольном порядке (вызовы madvise(), readahead(), в Windows — cache хинты). Linux использует опережающее чтение для файлов, отраженных в память; насчет Windows я не уверен. Наконец, можно вообще не использовать страничный кэш – за это ответственны флаги O_DIRECT в Linux и NO_BUFFERING в Windows; базы данных так довольно часто и поступают.
Мэппинг файла в память может быть двух типов – или private, или shared. Эти термины обозначают только то, как система будет реагировать на изменение данных в оперативной памяти: в случае с shared-мэппингами любое изменение данных будет сбрасываться на диск или будет видимым в других процессах; в случае с private-мэппингами этого не произойдет. Для реализации private-мэппингов, ядро опирается на механизм copy-on-write, который основан на определенном использовании записей в page-таблицах. В следующем примере, наша программа render, а также программа render3d (а у меня талант на выдумывание названий программ!) создают private-мэппинг для файла scene.dat. Затем, render пишет в область виртуальной памяти, которая поставлена в соответствие файлу:
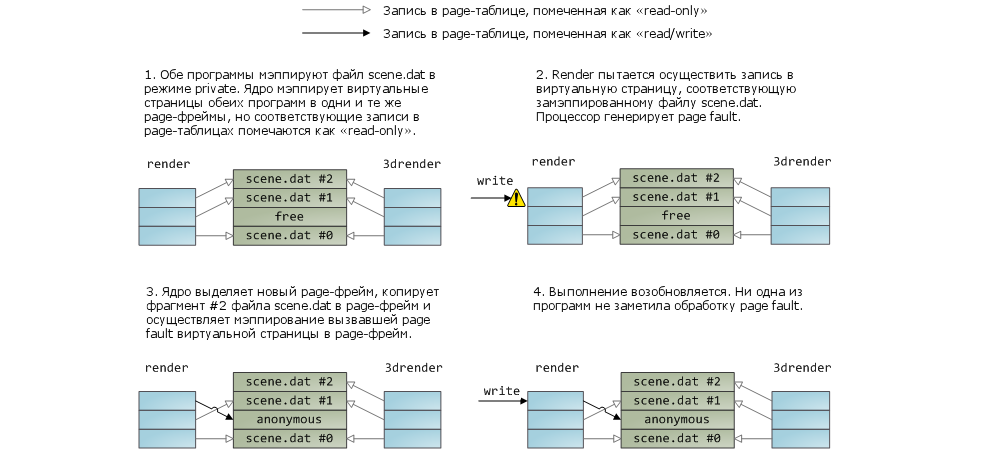
То, что записи в page-таблицах являются read-only (см. на рисунке) не должно нас смущать; и это еще не означает, что мэппинг будет доступен только на чтение. Это просто такой прием, с помощью которого ядро обеспечивает совместное использование страницы разными процессами и оттягивает необходимость создавать копию страницы до самого последнего момента. Глядя на рисунок понимаешь, что термин “private” возможно и не самый удачный, но если вспомнить, что он описывает исключительно поведение при изменении данных, то все нормально. У механизма мэппирования есть и еще одна особенность. Допустим, есть две программы, которые не связаны отношениями «родительский процесс – дочерний процесс». Программы работают с одним и тем же файлом, но мэппирют его по-разному – в одной программе это private-мэппинг, в другой – shared-мэппинг. Так вот, программа с private-мэппингом (назовем ее «первой программой») будет видеть все изменения, вносимые второй программой в некоторую страницу, до тех пор, пока первая программа сама не попытается записать что-нибудь в эту страницу (что приведет к созданию отдельной копии страницы для первой программы). Т.е. как только отработает механизм copy-on-write, изменения, вносимые другими программами, уже видны не будут. Ядро не гарантирует подобного поведения, но в случае с x86-процессорами так и происходит; и в этом есть определенный смысл, даже с точки зрения того же API.
Что же касается shared-мэппингов, то здесь дела обстоят следующим образом. На страницы выставляются права «read/write», и они просто мэппируются в страничный кэш. Таким образом, кто бы не вносил изменения в страницу, это увидят все процессы. Помимо этого, данные сбрасываются на жесткий диск. Ну и наконец, если страницы на предыдущем рисунке были бы действительно read-only, то page fault, отловленный при обращении к ним, повлек бы за собой ошибку сегментации (segmentation fault), а не отработку логики copy-on-write.
Разделяемые библиотеки также отображаются в память как и любые другие файлы. В этом нет ничего особенного — все тот же private-мэппинг, доступный программисту через вызов API. Далее приводится пример, показывающий часть адресного пространства двух экземпляров программы render, использующих механизм отображения файлов в память. Помимо этого, показаны соответствующие области физической памяти. Таким образом мы можем увязать вместе те концепций, с которыми познакомились в данной статье:

На этом завершим нашу серию из трёх статей, посвященных основам работы памяти. Надеюсь информация была для вас полезной и позволила составить общее представление по данной теме.
Ссылки на статьи серии:
- Организация памяти процесса
habrahabr.ru/company/smart_soft/blog/185226
duartes.org/gustavo/blog/post/anatomy-of-a-program-in-memory - Как ядро управляет памятью
habrahabr.ru/company/smart_soft/blog/226315
duartes.org/gustavo/blog/post/how-the-kernel-manages-your-memory - Page-кэш, или как связаны между собой оперативная память и файлы
habrahabr.ru/company/smart_soft/blog/227905
duartes.org/gustavo/blog/post/page-cache-the-affair-between-memory-and-files
Материал подготовлен сотрудниками компании Smart-Soft — smart-soft.ru.
