
Хабр Курсы для всех
РЕКЛАМА
Практикум, Хекслет, SkyPro, авторские курсы — собрали всех и попросили скидки. Осталось выбрать!
заканчивается следующим слешем(/), знаком вопроса(?) или октоторпом(#)(да-да, «решеточка» зовется именно так=)) или концом URI
http://habrahabr.ru:80/post/232385/?some=val#comment_8495021:http— scheme
habrahabr.ru:80— host
/post/232385/— path
some=val— query
comment_8495021— fragment
Путь начинается со слеша(/) и заканчивается знаком вопроса(?), октоторпом(#) или концом URI
иные варианты названия: «решётка», «хеш», «знак номера», «диез» (или «шарп» (англ. sharp), из-за внешнего сходства этих двух символов), «знак фунта»
url = (is_https?'https://':'http://')+host+path;url = '//'+host+path;Для того чтобы ссылка считалась URI необходимо наличие:
либо scheme+authority+path,
либо sheme+authority,
либо только path.
The scheme and path components are required, though the path may be
empty (no characters). When authority is present, the path must
either be empty or begin with a slash ("/") character. When
authority is not present, the path cannot begin with two slash
characters ("//"). These restrictions result in five different ABNF
rules for a path (Section 3.3), only one of which will match any
given URI reference.
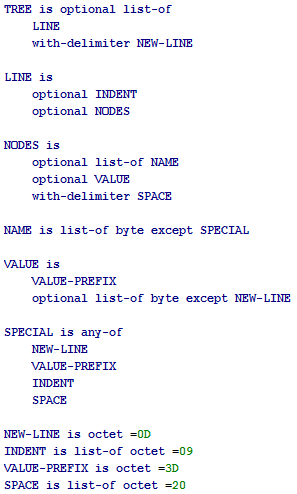
URI-reference = URI / relative-ref
URI = scheme ":" hier-part [ "?" query ] [ "#" fragment ]
relative-ref = relative-part [ "?" query ] [ "#" fragment ]
URI-reference = URI / relative-refЧитается как
URI и/или relative-refURI = scheme ":" hier-part [ "?" query ] [ "#" fragment ]Читается как
scheme и ":" и hier-part и/или [ "?" и query ] и/или [ "#" и fragment ]relative-ref = relative-part [ "?" query ] [ "#" fragment ]Читается как
relative-part и/или [ "?" и query ] и/или [ "#" и fragment ]hier-part? Это authority + path, но path может быть нулевым, то есть hier-part = authority [ "/" path ], или если так не нравится, то можно не оборачивать в квадратные скобки, но тогда учитывать что отсутствие path это тоже path.relative-part? Это "/" path / path, то есть relative-part = ["/"] path
URI-reference = scheme ":" authority [ "/" path ] [ "?" query ] [ "#" fragment ] / ["/"] path [ "?" query ] [ "#" fragment ]
scheme ":" authority и любой набор оставшихся компонент и тогда это абсолютный URI, либо любой набор компонент при отсутствующей scheme ":" authority и тогда это относительный URI.ABNF вы читать не умеете и мне пытаетесь предъявить, что я пишу глупости.
Читается как URI и/или relative-ref
Что есть hier-part?
hier-part = "//" authority path-abempty / path-absolute / path-rootless / path-empty
path-abempty = *( "/" segment )
path-absolute = "/" [ segment-nz *( "/" segment ) ]
path-rootless = segment-nz *( "/" segment )
path-empty = 0<pchar>
либо scheme+authority+path,
либо sheme+path,
либо только path.
P.S. Да, еще я бы акцентировал, что PATH и QUERY регистрозависимы, в отличие от HOST.
mailto:addr1%2C%20addr2
is equivalent to
mailto:?to=addr1%2C%20addr2
is equivalent to
mailto:addr1?to=addr2
Синтаксис регистрационного имени позволяет использование процентно-кодированных символов, для представления не-ASCII символов
http://%D0%BF%D1%80%D0%B5%D0%B7%D0%B8%D0%B4%D0%B5%D0%BD%D1%82.%D1%80%D1%84 http://www.президент.рф/
URI — сложно о простом (Часть 1)