Для примера я создал на популярной площадке, которая отображает номера в виде картинок, объявление.

Вот сам номер:
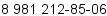
Прежде всего мне нужен будет словарь всех символов, которые могут встретится в подобных картинках, поэтому начну не с этого телефона, а с обучения. Для этого я нашёл на том же сайте объявлений 2 телефона, которые содержали в себе все возможные 10 цифр и склеил их в одно изображение:

Каждый символ выделяет то, что он не сливается с фоном, а каждый идентичный символ нарисован одним и тем же образом. Для начала уберем прозрачность:
Отрезаем лишнее:
Метод GetCorner особо описывать не буду. Вкратце, он попиксельно сравнивает цвета и возвращает верхнюю левую или нижнюю правую точки, обрамляющего полезную область, прямоугольника.
Далее разбираем полученную картинку на символы и добавляем их в коллекцию. Я использовал алгоритм, который каждую итерацию отщипывает по символу слева:
Ключевых момента здесь 2:
1. stringPattern представляет собой сроку «8929520-51-488926959-74-93», каждый символ которой соответствует графическому представлению символа.
2. Сущность, которая описывает символ:
Теперь, вернувшись к номеру в объявлении, остается только лишь сколотить аналогичную коллекцию (с одним отличием: символьное представление для каждого элемента будет занимать пробел) и сравнить каждый элемент со словарем.
В результате мы имеем коллекцию символов, для которой железяка подобрала и правильно проставила все цифры.

Распознавание букв алфавита, к примеру, буквы «й», несколько сложнее, за счет того, что они имеют составные части и требуют более сложного алгоритма нахождения обрамляющего прямоугольника, но сам алгоритм сравнения при этом будет тот же.
P.S. Что касается сторонних библиотек, в то время я находил их несколько, среди которых (впрочем, названия прочих я не помню) выбрал для своих целей библиотеку MODI от Microsoft (она входила в состав MS Office). Текст распознавала она отлично. Из минусов — в контексте одного процесса могла работать только одна процедура распознания, т.е. просто распаралеливаться в несколько потоков она не хотела.
Вот сам номер:
Прежде всего мне нужен будет словарь всех символов, которые могут встретится в подобных картинках, поэтому начну не с этого телефона, а с обучения. Для этого я нашёл на том же сайте объявлений 2 телефона, которые содержали в себе все возможные 10 цифр и склеил их в одно изображение:
Каждый символ выделяет то, что он не сливается с фоном, а каждый идентичный символ нарисован одним и тем же образом. Для начала уберем прозрачность:
void RemoveAlphaChannel(Bitmap src) { for (int y = 0; y < src.Height; y++) for (int x = 0; x < src.Width; x++) { var pxl = src.GetPixel(x, y); if (pxl.A == 0) src.SetPixel(x, y, Color.FromArgb(255, 255, 255, 255)); } }
Отрезаем лишнее:
private Bitmap CropImage(Bitmap sourceBitmap) { var upperLeft = GetCorner(sourceBitmap, true); var lowerRight = GetCorner(sourceBitmap, false); var width = lowerRight.X - upperLeft.X; var height = lowerRight.Y - upperLeft.Y; Bitmap target = new Bitmap(width, height); using (Graphics g = Graphics.FromImage(target)) { g.DrawImage(sourceBitmap, new Rectangle(0, 0, target.Width, target.Height), new Rectangle(ul, new Size(width, height)), GraphicsUnit.Pixel); } return target; }
Метод GetCorner особо описывать не буду. Вкратце, он попиксельно сравнивает цвета и возвращает верхнюю левую или нижнюю правую точки, обрамляющего полезную область, прямоугольника.
Далее разбираем полученную картинку на символы и добавляем их в коллекцию. Я использовал алгоритм, который каждую итерацию отщипывает по символу слева:
private void CropChars(Bitmap bitmapPattern, string stringPattern) { var croped = CropImage(bitmapPattern); RemoveAlphaChannel(croped); int cntr = 0; for (int x = 0; x < croped.Width; x++) { for (int y = 0; y < croped.Height; y++) { if ( (y == croped.Height - 1 && x > 0) || (x == croped.Width - 1 && x > 0) ) { var rect = new Rectangle(0, 0, x, croped.Height); //Дубли пропускаем if (_charInfoDictionary.FirstOrDefault(c => c.Char == stringPattern[cntr]) == null) _charInfoDictionary.Add(new CharInfo(CropImage(croped, rect), stringPattern[cntr])); ++cntr; if (croped.Width - x <= 1) return; croped = CropImage(croped, new Rectangle(x, 0, croped.Width - x, croped.Height)); x = 0; } if (!IsEmptyPixel(croped.GetPixel(x, y))) { break; } } } }
Ключевых момента здесь 2:
1. stringPattern представляет собой сроку «8929520-51-488926959-74-93», каждый символ которой соответствует графическому представлению символа.
2. Сущность, которая описывает символ:
public class CharInfo { //Последовательность яркостей public int[] _hsbSequence; //Кол-во областей, на которые будут разделены символы, для составления последовательности яркостей (по горизонтали и вертикали) private const int XPoints = 4; private const int YPoints = 4; //Символьное представление сущности public char Char { get; set; } //Графическое представление сущности public Bitmap CharBitmap { get; private set; } public CharInfo(Bitmap charBitmap, char letter) { Char = letter; CharBitmap = charBitmap; //Сжимаем наш символ в соответствии с кол-вом областей Bitmap resized = new Bitmap(charBitmap, XPoints, YPoints); _hsbSequence = new int[XPoints * YPoints]; int i = 0; //И заполняем последовательность яркостями*10. Сама яркость, это double от 0.0(черное) до 1.0(белое) for (int y = 0; y < YPoints; y++) for (int x = 0; x < XPoints; x++) _hsbSequence[i++] = (int)(resized.GetPixel(x, y).GetBrightness()*10); } /// <summary> /// Метод сравнения с другим символом, сравнивает последовательности яркостей /// </summary> /// <param name="charInfo"></param> /// <returns>Количество совпадений</returns> public int Compare(CharInfo charInfo) { int matches = 0; for (int i = 0; i < _hsbSequence.Length; i++) { if (_hsbSequence[i] == charInfo._hsbSequence[i]) ++matches; } return matches; } }
Теперь, вернувшись к номеру в объявлении, остается только лишь сколотить аналогичную коллекцию (с одним отличием: символьное представление для каждого элемента будет занимать пробел) и сравнить каждый элемент со словарем.
public IEnumerable<CharInfo> Recognize(Bitmap bitmap) { RemoveAlphaChannel(bitmap); var charsToRecognize = CropChars(bitmap); List<CharInfo> result = new List<CharInfo>(); foreach (var charInfo in charsToRecognize) { CharInfo closestChar = null; int maxMatches = 0; foreach (var dictItem in _charInfoDictionary) { var matches = dictItem.Compare(charInfo); if (matches > maxMatches) { maxMatches = matches; closestChar = dictItem; } } result.Add(closestChar); } return result; }
В результате мы имеем коллекцию символов, для которой железяка подобрала и правильно проставила все цифры.
StringBuilder sb = new StringBuilder(); foreach (var charInfo in charsToRecognize) sb.Append(charInfo.Char); textBox1.Text = sb.ToString();
Распознавание букв алфавита, к примеру, буквы «й», несколько сложнее, за счет того, что они имеют составные части и требуют более сложного алгоритма нахождения обрамляющего прямоугольника, но сам алгоритм сравнения при этом будет тот же.
P.S. Что касается сторонних библиотек, в то время я находил их несколько, среди которых (впрочем, названия прочих я не помню) выбрал для своих целей библиотеку MODI от Microsoft (она входила в состав MS Office). Текст распознавала она отлично. Из минусов — в контексте одного процесса могла работать только одна процедура распознания, т.е. просто распаралеливаться в несколько потоков она не хотела.

