
Хабр Курсы для всех
РЕКЛАМА
Практикум, Хекслет, SkyPro, авторские курсы — собрали всех и попросили скидки. Осталось выбрать!
/0//0

a = b == c
/=, не вижу проблемы.cd /usr/share/X11/xkb/symbols
sudo mv -f ru.orig ru
sudo rm /var/lib/xkb/*xkm 2>/dev/null
сложно себе представить, откуда после rm /var/lib/xkb/*xkm иксы возьмут старую раскладку

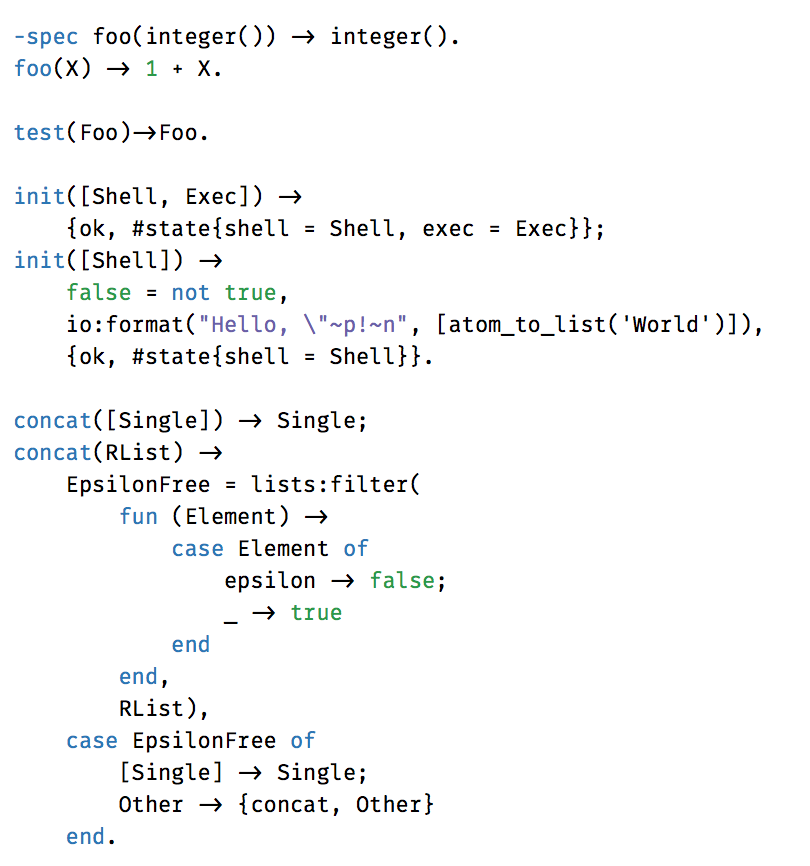
В любом языке полно составных знаков: ->, <=, ++, :=. По смыслу это один символ, но составленный из нескольких более простых. Мозгу требуются дополнительные усилия на то, чтобы считать и объединять такие конструкции на лету.
a<-b

! или not в логических выражениях заменялся на ¬. А в хаскеле с ним ещё и другая проблема. && на ∧, а вот || в некоторых языках используется в list comprehensions, а не как logical or./> для тегов, но нет </? ^ на ⊕, и вуаля.&&, парсер читает оператор-конъюнкции, редактор выдаёт глиф LOGICAL AND (U+2227), рендерер выбранного шрифта отображает ∧.

По смыслу это один символ, но составленный из нескольких более простых
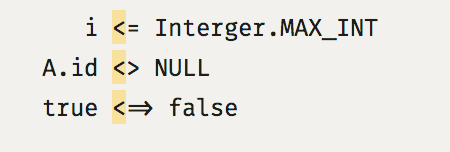
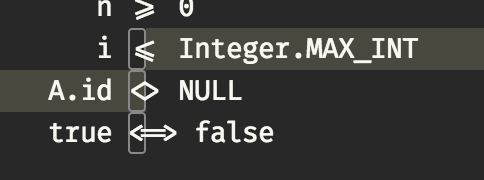
Ы, Ё, Й? Опознать число 10?>= или != мозг выделяет с такой же лёгкостью, как графически неразрывный символ. Вот отделять от окружающих символов пространством требуется для упрощения восприятия в любом случае. Поэтому a = 5, но не a=5.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Моноширинные шрифты с программистскими лигатурами