Я не думаю что сильно ошибусь, если скажу, что у большинства читателей данной статьи на компьютере присутствует папка, в которой хранятся наработки кода, применяющиеся потом в боевых проектах. Маленькие такие кусочки алгоритмов, на которых проверяется сама возможность реализации той или иной идеи. Я их называю «ништячки».
Чем больше программист работает по своим задачам, тем больше эта папочка пухнет. Вот моя уже вылезла за пределы семи сотен различных демопримеров.
Но проблема в том, что в 99 процентов случаев все эти «ништячки» пишутся в стол, и о существовании оных наработок знает только владелец данной папки, а ведь там же иногда целые закрома идей, подходов к реализации, алгоритмических трюков, да и просто остановленных на взлете мыслей, которыми не грех бы и поделиться (а вдруг кто-то возьмет да и разовьет подход).
В данной статье я поделюсь тремя наработками, которые вышли как раз из таких вот «папок с ништяками» и уже не первый год применяются в наших боевых проектах.
Будет немножко ассемблера — но не пугайтесь, он там только в виде информационной составляющей.
Вряд ли я открою секрет, что побайтовое чтение файла — плохо.
Ну что значит — плохо, да оно работает, и ошибок не выдает, но тормоза… Головки цилиндров и так ишачат как ошпаренные, пытаясь выдать всем страждущим нужные им данные, а тут мы со своим чтением одного байта из файла.
А зачем мы вообще читаем ровно один байт?
Если немного абстрагироваться от нагрузки на файловую систему и представить что файл, который мы читаем, выглядит как: «байт, содержащий размер блока данных + блок данных, за ним опять байт, содержащий размер блока данных + блок данных» — то все абсолютно логично. В данном случае мы выполняем единственную верную логику, читаем префикс, содержащий размер и сам блок данных, после чего повторяем, пока не уперлись в конец файла.
Удобно? Даже не может возникнуть вопросов — конечно удобно.
А что нам приходится делать на самом деле, чтоб уйти от тормозов при чтении:
И такая вот чехарда с ручным кэшированием в целой куче мест проекта, где требуется работа с файлами.
Не удобно? Конечно неудобно, хочется такой-же простоты, как в первом варианте.
Осмыслив суть проблемы, наш коллектив разродился следующей идеей: раз работа с данными идет через наследники от TStream (TFileStream, TWinHTTHStream, TWinFTPStream) — то не написать ли нам кэширующий проксик над самим стримом? Ну а почему бы и нет, не мы же первые — взять, к примеру, за образец тот же TStreamAdapter из System.Classes, выступающий прослойкой между IStream и абстрактным TStream.
Удобная, кстати, вещь — советую.
Наш проксик выполнен в виде банального наследника от TStream, так что, при помощи него можно абсолютно свободно контролировать работу с данными любого другого наследника данного класса.
Вообще реализация таких прокси-стримов, достаточно часто встречается. К примеру, если опустить TStreamAdapter, вам скорее всего будут известны такие классы как TZCompressionStream и TZDecompressionStream из модуля ZLib, которые предоставляют очень удобный способ сжатия и распаковки данных, хранящихся в любом произвольном наследнике TStream. Да я и сам раньше таким баловался, реализовав в свое время достаточно удобный проксик в виде класса TFWZipItemStream, который, пропуская все данные через себя, производит их правку «на лету» и до кучи считает контрольную сумму всех прошедших через него данных.
Поэтому, взяв на вооружение уже накопленный ранее опыт, был рожден класс TBufferedStream, ну а в качестве уточнения по поводу работы с ним, к декларции класса был сразу прилеплен комментарий: "// типа буферизированное чтение из стрима. ReadOnly!!!"
Но, прежде чем приступить к изучению кода данного класса, давайте напишем небольшое консольное приложение, которое измеряет нагрузку на приложение при использовании различных варинатов наследников от TStream, по скорости исполнения кода.
В качестве PayLoad функционала сделаем следующее — вычислим оффсеты на секцию ресурсов каждой библиотеки, размещенной в системной директории (GetSystemDirectory) и засечем время, затраченное на выполнение при помощи TBufferedStream, затем TFileStream, ну и в конце, TMemoryStream.
Такая последовательность выполнения тестов была выбрана с целью нивелирования влияния кэша файловой системы, т.е. TBufferedStream будет работать с некэшированными данными, а последующие два теста будут (должны) выполнятся существенно быстрее из-за повторного обращения к кэшированным (файловой системой) данным.
Как думаете, кто победит?
Впрочем:
Для начала нам потребуется функция, которая построит список файлов, над которыми будет производится работа:
В ней создается экземпляр TStringList и заполняется путями к библиотекам, размер которых больше двух мегабайт (для демки — достаточно).
Лень было придумывать что-то сложное, наглядно демонстрирующее необходимость чтения файла кусками, поэтому я решил остановиться на работе с секциями PE файла.
Задача даной процедуры — вычислить адрес секции ресурсов (.rsrc) переданного ей файла (в виде стрима) и просто посчитать сумму всех байт, размещенных в даной секции.
В ней сразу видны два, необходимых для работы, чтения буфера с данными (DOS header и PE header), после которых происходит выход на секцию ресурсов, из которой читаются данные кусками по 64 байта и суммируются с результатом.
ЗЫ: да, я в курсе что данные из секции не считаются целиком, т.к. чтение идет блоками и последний, не кратный 64 байтам не считается, но на то это и пример.
Смотрим результат (на картинке уже включены результаты от TBufferedStream):
TFileStream, как и ожидалось, сильно отстал, а вот TMemoryStream показал результат очень приближенный к результатам еще не рассмотренного нами TBufferedStream.
Ничего страшного, дело в том, что сделал он это с большим оверхедом по памяти, т.к. ему пришлось загружать каждую библиотеку в память приложения (просадка), но догнал по скорости как раз по той же самой причине (уходом от необходимости частого чтения данных с диска).
Паблик секция не представляет из себя ничего необычного, все те же перекрытые Read/Write/Seek, как и у любого другого прокси-стрима.
Весь фокус начинается с вот такой функции:
Как можно понять по коду, мы пытаемся прочитать данные вызовом функции Buffer_Read, которая возвращает их из уже подготовленного кэша, а если не смогли прочитать, производится попытка переинициализации кэша вызовом Buffer_Update.
Реинициализация кэша выглядит так:
Т.е. выделяем память под кэш, размером, указанным в свойстве BufferSize класса, после чего производим попытку считать в кэш данные из контролируемого нами стрима.
Если данные считались успешно, правим фактический размер кэша (ибо если хотели считать мегабайт, а всего доступно только 15 байт, то освободим ненужную память, зачем нам лишнее?).
Операция чтения из кэша так-же проста:
Просто проверяем текущую позицию стрима и убеждаемся что мы действительно храним необходимые данные, доступные по данному оффсету, после чего банальным Move перекидываем данные во внешний буфер.
Остальные методы данного класса чересчур тривиальны, поэтому рассматривать я их не буду, с ними можно будет ознакомится в демопримерах в архиве к статье: ".\src\bufferedstream\"
Что в итоге получается:
Понравилось?
Тогда перейдем ко второй части.
А вот представьте что данные, которые мы хотим прочитать, уже расположены в памяти нашего приложения. Дабы не переусложнять, остановимся опять на тех же библиотеках, рассмотреных в первой части статьи. Чтобы выполнить ту же самую работу, которая была показана в функции CalcResOffset, нам потребуется каким-то образом перекинуть данные о библиотеке в какой-то наследник от TStream (к примеру в тот-же TMemoryStream).
И что мы сделаем в этом случае?
В 99 процентах случаев, создадим TMemoryStream и вызовем функцию Write(WriteBuffer).
А разве это нормально, ведь мы же по сути просто скопируем данные, которые и так уже у нас есть? И ведь сделаем то мы это по одной единственной причине — для того, чтобы можно было работать с данными посредством привычного нам TStream.
Чтобы исправить этот лишний оверхед по памяти, и был разработан вот такой простенький класс:
Даже не знаю что можно добавить к этому коду в качестве коментария, поэтому давайте просто посмотрим работу с данным классом.
Здесь все просто — ищем адрес загруженной NTDLL.DLL и читаем ее секцию ресурсов напрямую из памяти, изпользуя все преимущества стрима (и не нужно ничего копировать во временный буфер.
Теперь несколько коментариев по использовании класса.
Вообще — он очень приятен, если его применять только в операциях чтения данных, но… как видно по коду, он не запрещает запись данных в контролируемый им блок памяти, а это может грозить большими неприятностями.
Мы можем легко перезатереть критичные для работы приложения данные, после чего выйти на банальное AV, поэтому в наших проектах использвание этой возможности класса сведено к минимуму (буквально перестраиваем поисковые индексы в нужных местах на заранее выделенном буфере — так просто проще).
Кстати, именно по этой причине мы отказались от использования Friendly классов, позволяющих получить доступ к вызову TCustomMemoryStream.SetPointer, т.к. в таком случае запись не будет контролироваться вообще никем, что может привести в итоге к хорошему такому «бадабуму».
Исходный код класса и примера можно посмотреть в архиве: ".src\onmemorystream\"
Впрочем, перейдем к заключающей части статьи.
Сейчас буду учить плохому.
Давайте посмотрим как в Delphi принято работать с объектами. Обычно это выглядит так:
Новички в языке, конечно, забывают про использование секции финализации, выкатывая перлы вроде этого:
А то и вообще, забывая про необходимость освобождения объекта, не говорят объекту Free.
Некоторые «продвинутые новички» умудряются реализовать даже вот такой «говнокод»
А однажды я встретился и вот с такой реализацией:
Ну старался человек — сразу видно.
Впрочем, давайте все же остановимся на первом варианте правильного кода.
Минус у него следующий — если нам потребуется работа с несколькими классами одновременно, нам придется существенно развернуть код из-за множественных использований секций финализации:
Есть, конечно, вариант, немножко сомнительный и не используемый мной, но в последнее время достаточно часто встречающийся на просторах интернета:
Из-за первоначальной инициализации каждого объекта в данном случае не произойдет ошибки при вызове Free еще не созданного объекта (если вдруг будет поднято исключение в конструкторе предыдущего), но все равно — выглядит чересчур сомнительно.
А как вы посмотрите на то, если я скажу что вызов метода Free вообще можно не делать?
Да-да, просто создаем объект и забываем вообще про то, что его нужно разрушать.
Как это выглядит? Да вот так:
Ну конечно прямо вот в таком виде это сделать не получится без мемлика — ну нет у нас сборщика мусора и прочего, но не торопитесь говорить: «Саня — да ты сдурел!»… ибо можно взять идею из других языков программирования и реализовать ее на нашем, «великом и могучем».
А идею мы возьмем от SharedPtr: смотрим документацию.
Логика данного класса проста — контроль времени жизни объекта посредством подсчета ссылок на него. Благо это мы умеем — есть у нас такой механизм, интерфейсами зовется.
Но не все так просто.
Конечно, с наскока, можно выкатить такую идею — реализуем в классе поддержку IUnknown и все, как только счетчик ссылок на экземпляр класса достигнет нуля — он разрушится.
Но сделать-то это мы сможет только с собственноручно написанными классами, а что делать с тем же TMemoryStream, которому весь этот фень-шуй по барабану, ибо он знать не знает об интерфейсах?
Самое логичное — писать очередной проксик, который будет держать линк на контролируемый им объект и в себе самом будет реализовывать подсчет ссылок, а при своем разрушении будет грохать доверенный ему на хранение объект.
Но тут тоже не все так радужно. Проксик-то мы напишем, да и что там его писать — идея ведь уже озвучена, но будет большая просадка как по памяти, так и по скорости работы с классом, если он будет использовать в качестве механизма подсчета ссылок классический интерфейс, со всем сопуствующим.
Временные затраты на исполнение данного кода будут в районе 3525 миллисекунд (запомним это число).
Суть: основную логику релизует класс TObjectDestroyer, который работает с подсчетом ссылок и разрушает переданный ему на хранение объект. TSharedPtr — структура, посредством которой происходит правильная работа со ссылками в тот момент, когда она выходит из области видимости (конечно, в данном случае, можно сделать и без этой структуры, но...).
Если запустите пример, то увидите, что созданные объекты будут разрушены до завершения работы приложения (впрочем, если бы это было не так, об этом вам явно было бы сообщено, т.к. взведен флаг ReportMemoryLeaksOnShutdown ).
Но давайте разберем подробней — где же здесь может быть ненужный нам оверхед (причем как по памяти, так и по скорости выполнения).
Ну, во-первых — TObjectDestroyer.InstanceSize равен 20.
Хех, получаем лишние 20 байт памяти на каждый контролируемый нами объект, а с учетом того что гранулярность менеджера памяти в Delphi равна 12 байтам, то теряются не 20 байт, а все 24. Думаете мелочи? Может быть и так — но наш вариант должен выходить (и будет) ровно на 12 байт, ибо если убирать оверхэд — так целиком.
Вторая проблема — избыточный оверхэд при вызове методов интерфейса.
Давайте вспомним, как выглядит в памяти VMT объекта, реализующего интерфейс.
VMT объекта начинается с виртуальных методов самого объекта, включая и перекрытые методы интерфейса, причем эти перекрытые методы не принадлежат интерфейсу.
И вот только за ними идет VMT методов самого интерфейса, при вызове которых происходит перенаправление (посредством CompilerMagic константы, рассчитываемой для каждого интрефейса на этапе компиляции) на реальный код.
Это можно увидеть наглядно выполнив вот такой код:
Если посмотреть на ассемблерный листинг, то мы увидим следующее:
… которые приводят к:
в первом случае, а во втором на:
Если бы мы наследовались в TObjectDestroyer не от IUnknown, а, к примеру, от IEnumerator, то компилятор автоматом подправил бы адреса выхода на VMT объекта примерно таким образом:
Именно через такой прыжок компилятор производит вызов методов _AddRef и _Release при изменении счетчика ссылок (к примеру при присвоении интерфейса новой переменной, или при выходе за область видимости).
Поэтому сейчас будем побеждать всю эту беду и напишем свой собственный интерфейс.
Итак пишем:
Думаете это структура типа record?
Неа — это самый что ни на есть объект, со своей собственной VMT, расположенной в VTable и размером ровно в 12 байт:
Теперь собственно сама «магия».
Инициализация VMT происходит в следующем методе:
Все по канонам, и Delphi даже не заподозрит тут какой-либо подвох, ведь для нее это будет абсолютно валидная VMT, реализованная по всем законам и правилам.
Ну а основной конструктор выглядит так:
Через GetMem выделяем место под InstanceSize нашего «якобы» класса, не смотря на то, что он в действительности является структурой, после чего инициализируем требуемые поля в виде указателя на VMT, счетчик ссылок и указатель на контролируемый классом объект.
Причем этим мы сразу обходим оверхэд на вызове InitInstance и сопутстующую ему нагрузку.
Обратите внимение — результат вызова конструктора — интерфейс IUnknown.
Хак? Конечно.
Работает? Безусловно.
Реализация методов QueryInterface, _AddRef и _Release взята от стандартного TIntefacedObject и не интересна. Впрочем QueryInterface в данном подходе по сути избыточен, но раз мы решили делать все по классике, и закладываемся на то, что какой-то «безумный программыст» все равно попробует дернуть данный метод, то оставим его на положенном ему месте (тем более что он и так должен идти первым в VMT интерфейса. Ну не оставлять же вместо него там мусорный указатель?).
Теперь немного поколдуем над структурой, с помощью которой мы обеспечивали контроль за ссылками:
Немножко поменялся конструктор:
Впрочем, суть от этого не изменилась.
Добавился новый метод, посредством которого можно будет получать доступ, к котролируемому нашим шарепойнтером объекту:
Ну и две утилитарных процедуры, первая из которых просто уменьшает количество ссылок:
А вторая отключает контролируемый классом объект от всего этого механизма:
Теперь давайте посмотрим — а зачем вообще оно все это нужно?
Рассмотрим ситуацию:
Вот, к примеру, создали мы некий экземпляр класса, за которым следит TObjectDestroyer и отдали его наружу, что в этом случае произойдет?
Правильно — как только завершится выполнение кода процедуры, в которой был создан объект, он будет сразу разрушен и внешний код будет работать с уже убитым указателем.
Именно для этого и введен класс TSharedPtr, посредством которого можно «прокидывать» данные по процедурам нашего приложения, не боясь преждевременного разрушения объекта. Как только он действительно станет никому не нужен — TObjectDestroyer его моментально грохнет и всем будет нирвана.
Но это еще не все.
Покрутив реализацию TSharedPtr мы все же пришли к выводу, что она не совсем удачна. И знаете почему?
А потому что вот такой код конструктора нам показался чересчур избыточным:
Ага — именно так это и нужно вызывать, но чтобы не пугать неподготовленных к такому счастью программистов, мы решили добавить небольшую оберточку вот такого плана:
После которой все стало гораздо приятней, и вызов шарепойнтера стал выглядеть гораздо привычнее, и похожим на создание ранее озвученного проксика:
Впрочем, хватит разглагольствовать и посмотрим на просадку по времени (а она, конечно, будет):
И смотрим, что получилось:
В первом варианте шарепойнтера была задержка в 3525 миллисекунд, новый вариант выдет число 2917 — не зря старались, получается.
Однако — что это за AutoDestroy, который обогнал шарепойнтер на целую секунду?
Это хэлпер, и это плохо.
Плохо, потому что этот хэлпер реализован над TObject:
Дело в том что, по крайней мере в ХЕ4 все еще не побежден конфликт с пересекающимися хэлперами, т.е. если у вас есть собственный хэлпер над TStream и вы попробуете подключить к нему в пару TObjectHelper — проект не сбилдится.
Не знаю, решена ли эта проблема в ХЕ7, но в четверке она точно присутствует, и по этой причине мы не используем данный кусок кода, хотя он гораздо производительней, чем использование структуры TSharedPtr.
Теперь давайте рассмотрим предпоследний момент, о котором я говорил выше, а именно — о реализации прыжка на VMT, для этого напишем две простых процедуры:
В самом начале я упоминал, что использорвание простейшего варианта TSharedPtr в самом первом примере немного избыточно. Да, это так, в том случае можно было просто запоминать ссылку на интерфейс в локальной переменной (чем TSharedPtr по сути и занимается, правда немного другим способом);
Итак, смотрим, что происходит в этом варианте кода:
1. Создание объекта и инициализация интерфейса:
2. Вызов секции финализации:
3. После чего управление передается на @IntfClear, где нас и поджидает озвученный ранее прыжок:
А что происходит в варинте использования TObjectDestroyer?
1. Создание объекта и создание самого TObjectDestroyer:
Да, есть оверхед, лишнее действие, как-никак. Впрочем, а что там с разрушением?
2. Все очень просто:
Практически идентично первому варианту.
Но самое интересное все же произойдет при вызове @IntfClear, он пропустит избыточные прыжки по VMT и передаст управление сразу на class function TObjectDestroyer._Release.
В итоге сэкономили на вызове двух инструкций (add и jmp), но это к сожалению пока что самое минимальное, что можно сделать, т.к. в случае использования проксика — накладные расходы ну просто не избежны.
В завершение, осталось только посмотреть, как использовать механизм автоматического разрушения объекта на практике:
К примеру, создадим файловый стрим и запишем в него некую константу:
Да, это все — время жизни стрима контролируется, и избыточных поползновений не требуется.
В данном случае структура TSharedPtr не используется, т.к. отсутствует необходимость передачи указателя между участками кода и достаточно функционала TObjectDestroyer.
А теперь прочитаем значение константы из файла и выведем на экран, причем сразу посмотрим на передачу данных между процедурами.
Вот так мы создадим объект, контролируемый шарепойнтером:
А так мы получим из этого объекта данные:
Как видите — код практически не изменился, если сравнивать его с классическим подходом к разработке ПО.
Плюсы — пропала необходимость использования блоков TRY..FINALLY, код стал менее перегруженным по объему.
Минусы — небольшой оверхэд по скорости и немного расширились конструкторы, заставляя нас каждый раз вызывать TSharedPtr.Create (в члучае передачи данных на внешку) или TObjectDestroyer для контроля времени жизни.
Так же появился дополнительный параметр Value, посредством которого можно получить доступ к контролируемому объекту в случае использования TSharedPtr, но к этому достаточно просто привыкнуть, тем более, что это все, на что способна дельфи в плане синтаксического сахара.
Хотя я все еще мечтаю что появится DEFAULT метод объекта (или свойство не перечислимого типа), которое можно будет вызывать без указания его имени простым обращением к переменной класа, тогда бы мы объявили свойство Value у класса TSharedPtr дефолтным и работали бы с базовым объектом, даже не зная что он находится под контролем проксика :)
Вывод один — утомился я все это расписывать.
А если серьезно, все три показанные выше подхода достаточно удобные, по сути, причем первые два я использую практически повсеместно.
С TSharedPtr я, конечно, осторожничаю.
Не подумайте что он плох — по другой причине. Мне все еще (за столько-то лет практики) некомфортно наблюдать код без использования секций финализации, хотя задним мозжечком-то я, конечно, понимаю, что все это сработает как надо — но… не привычно.
Поэтому TSharedPtr я использую только в нескольких частных случаях — когда нужно отпустить объект на волю во внешний, не контролируемый мной код, хотя мои коллеги придерживаются несколько другой точки зрения и используют его достаточно часто (конечно, не везде, ибо сами видите, что основной его минус — двойная просадка по скорости, как расплата за удобство использования).
И на этом, пожалуй, я закругляюсь.
Проверяйте свои закрома — делитесь, ведь там точно есть что-то полезное.
Исходный код демопримеров доступен по данной ссылке.
Чем больше программист работает по своим задачам, тем больше эта папочка пухнет. Вот моя уже вылезла за пределы семи сотен различных демопримеров.
Но проблема в том, что в 99 процентов случаев все эти «ништячки» пишутся в стол, и о существовании оных наработок знает только владелец данной папки, а ведь там же иногда целые закрома идей, подходов к реализации, алгоритмических трюков, да и просто остановленных на взлете мыслей, которыми не грех бы и поделиться (а вдруг кто-то возьмет да и разовьет подход).
В данной статье я поделюсь тремя наработками, которые вышли как раз из таких вот «папок с ништяками» и уже не первый год применяются в наших боевых проектах.
Будет немножко ассемблера — но не пугайтесь, он там только в виде информационной составляющей.
Начнем, пожалуй, с кэширования
Вряд ли я открою секрет, что побайтовое чтение файла — плохо.
Ну что значит — плохо, да оно работает, и ошибок не выдает, но тормоза… Головки цилиндров и так ишачат как ошпаренные, пытаясь выдать всем страждущим нужные им данные, а тут мы со своим чтением одного байта из файла.
А зачем мы вообще читаем ровно один байт?
Если немного абстрагироваться от нагрузки на файловую систему и представить что файл, который мы читаем, выглядит как: «байт, содержащий размер блока данных + блок данных, за ним опять байт, содержащий размер блока данных + блок данных» — то все абсолютно логично. В данном случае мы выполняем единственную верную логику, читаем префикс, содержащий размер и сам блок данных, после чего повторяем, пока не уперлись в конец файла.
Удобно? Даже не может возникнуть вопросов — конечно удобно.
А что нам приходится делать на самом деле, чтоб уйти от тормозов при чтении:
- Читать сразу большой объем данных во временный буфер;
- Реальное чтение производить уже из временного буфера;
- А если во временном буфере данных не достаточно, опять их читать из файла и учитывать оффсеты и прочее сопутствующее;
И такая вот чехарда с ручным кэшированием в целой куче мест проекта, где требуется работа с файлами.
Не удобно? Конечно неудобно, хочется такой-же простоты, как в первом варианте.
Осмыслив суть проблемы, наш коллектив разродился следующей идеей: раз работа с данными идет через наследники от TStream (TFileStream, TWinHTTHStream, TWinFTPStream) — то не написать ли нам кэширующий проксик над самим стримом? Ну а почему бы и нет, не мы же первые — взять, к примеру, за образец тот же TStreamAdapter из System.Classes, выступающий прослойкой между IStream и абстрактным TStream.
Удобная, кстати, вещь — советую.
Наш проксик выполнен в виде банального наследника от TStream, так что, при помощи него можно абсолютно свободно контролировать работу с данными любого другого наследника данного класса.
Вообще реализация таких прокси-стримов, достаточно часто встречается. К примеру, если опустить TStreamAdapter, вам скорее всего будут известны такие классы как TZCompressionStream и TZDecompressionStream из модуля ZLib, которые предоставляют очень удобный способ сжатия и распаковки данных, хранящихся в любом произвольном наследнике TStream. Да я и сам раньше таким баловался, реализовав в свое время достаточно удобный проксик в виде класса TFWZipItemStream, который, пропуская все данные через себя, производит их правку «на лету» и до кучи считает контрольную сумму всех прошедших через него данных.
Поэтому, взяв на вооружение уже накопленный ранее опыт, был рожден класс TBufferedStream, ну а в качестве уточнения по поводу работы с ним, к декларции класса был сразу прилеплен комментарий: "// типа буферизированное чтение из стрима. ReadOnly!!!"
Но, прежде чем приступить к изучению кода данного класса, давайте напишем небольшое консольное приложение, которое измеряет нагрузку на приложение при использовании различных варинатов наследников от TStream, по скорости исполнения кода.
В качестве PayLoad функционала сделаем следующее — вычислим оффсеты на секцию ресурсов каждой библиотеки, размещенной в системной директории (GetSystemDirectory) и засечем время, затраченное на выполнение при помощи TBufferedStream, затем TFileStream, ну и в конце, TMemoryStream.
Такая последовательность выполнения тестов была выбрана с целью нивелирования влияния кэша файловой системы, т.е. TBufferedStream будет работать с некэшированными данными, а последующие два теста будут (должны) выполнятся существенно быстрее из-за повторного обращения к кэшированным (файловой системой) данным.
Как думаете, кто победит?
Впрочем:
Для начала нам потребуется функция, которая построит список файлов, над которыми будет производится работа:
function GetSystemRootFiles: TStringList; var Path: string; SR: TSearchRec; begin Result := TStringList.Create; SetLength(Path, MAX_PATH); GetSystemDirectory(@Path[1], MAX_PATH); Path := IncludeTrailingPathDelimiter(PChar(Path)); if FindFirst(Path + '*.dll', faAnyFile, SR) = 0 then try repeat if SR.FindData.nFileSizeLow > 1024 * 1024 * 2 then Result.Add(Path + SR.Name); until FindNext(SR) <> 0; finally FindClose(SR); end; end;
В ней создается экземпляр TStringList и заполняется путями к библиотекам, размер которых больше двух мегабайт (для демки — достаточно).
Следующей функцией выступит общий обвес над стартом каждого теста с замером времени, тоже простенький, по сути:
function MakeTest(AData: TStringList; StreamType: TStreamClass): DWORD; var TotalTime: DWORD; I: Integer; AStream: TStream; begin Writeln(StreamType.ClassName, ': '); Writeln('==========================================='); AStream := nil; TotalTime := GetTickCount; try for I := 0 to AData.Count - 1 do begin if StreamType = TBufferedStream then AStream := TBufferedStream.Create(AData[I], fmOpenRead or fmShareDenyWrite, $4000); if StreamType = TFileStream then AStream := TFileStream.Create(AData[I], fmOpenRead or fmShareDenyWrite); if StreamType = TMemoryStream then begin AStream := TMemoryStream.Create; TMemoryStream(AStream).LoadFromFile(AData[I]); end; Write('File: "', AData[I], '" CRC = '); CalcResOffset(AStream); end; finally Result := GetTickCount - TotalTime; end; end;
Сам PayLoad функционал вынесен в модуль common_payload.pas и выглядит в виде процедуры CalcResOffset.
procedure CalcResOffset(AData: TStream; ReleaseStream: Boolean); var IDH: TImageDosHeader; NT: TImageNtHeaders; Section: TImageSectionHeader; I, A, CRC, Size: Integer; Buff: array [0..65] of Byte; begin try // читаем ImageDosHeader AData.ReadBuffer(IDH, SizeOf(TImageDosHeader)); // смотрим по сигнатуре, что не ошиблись и работаем с правильным файлом if IDH.e_magic <> IMAGE_DOS_SIGNATURE then begin Writeln('Invalid DOS header'); Exit; end; // прыгаем на начало PE заголовка AData.Position := IDH._lfanew; // читаем его AData.ReadBuffer(NT, SizeOf(TImageNtHeaders)); // смотрим по сигнатуре, что не ошиблись и работаем с правильным файлом if NT.Signature <> IMAGE_NT_SIGNATURE then begin Writeln('Invalid NT header'); Exit; end; // делаем "быструю" проверку на наличие секции ресурсов if NT.OptionalHeader.DataDirectory[IMAGE_DIRECTORY_ENTRY_RESOURCE].VirtualAddress = 0 then begin Writeln('Resource section not found'); Exit; end; // "прыгаем" в начало списка секций AData.Position := IDH._lfanew + SizeOf(TImageFileHeader) + 4 + Nt.FileHeader.SizeOfOptionalHeader; // перечисляем их до тех пор... for I := 0 to NT.FileHeader.NumberOfSections - 1 do begin AData.ReadBuffer(Section, SizeOf(TImageSectionHeader)); // ...пока не встретим секцию ресурсов if PAnsiChar(@Section.Name[0]) = '.rsrc' then begin // а когда найдем ее - сразу "прыгаем" на ее начало AData.Position := Section.PointerToRawData; Break; end; end; // "полезная нагрузка" (PayLoad) - суммируем все байты секции ресурсов // типа контрольная сумма :) CRC := 0; Size := Section.SizeOfRawData div SizeOf(Buff); for I := 0 to Size - 1 do begin AData.ReadBuffer(Buff[0], SizeOf(Buff)); for A := Low(Buff) to High(Buff) do Inc(CRC, Buff[A]); end; Writeln(CRC); finally if ReleaseStream then AData.Free; end; end;
Лень было придумывать что-то сложное, наглядно демонстрирующее необходимость чтения файла кусками, поэтому я решил остановиться на работе с секциями PE файла.
Задача даной процедуры — вычислить адрес секции ресурсов (.rsrc) переданного ей файла (в виде стрима) и просто посчитать сумму всех байт, размещенных в даной секции.
В ней сразу видны два, необходимых для работы, чтения буфера с данными (DOS header и PE header), после которых происходит выход на секцию ресурсов, из которой читаются данные кусками по 64 байта и суммируются с результатом.
ЗЫ: да, я в курсе что данные из секции не считаются целиком, т.к. чтение идет блоками и последний, не кратный 64 байтам не считается, но на то это и пример.
Запустим эту беду вот таким кодом:
var S: TStringList; A, B, C: DWORD; begin try S := GetSystemRootFiles; try //A := MakeTest(S, TBufferedStream); B := MakeTest(S, TFileStream); C := MakeTest(S, TMemoryStream); Writeln('==========================================='); //Writeln('TBufferedStream = ', A); Writeln('TFileStream = ', B); Writeln('TMemoryStream = ', C); finally S.Free; end; except on E: Exception do Writeln(E.ClassName, ': ', E.Message); end; Readln; end.
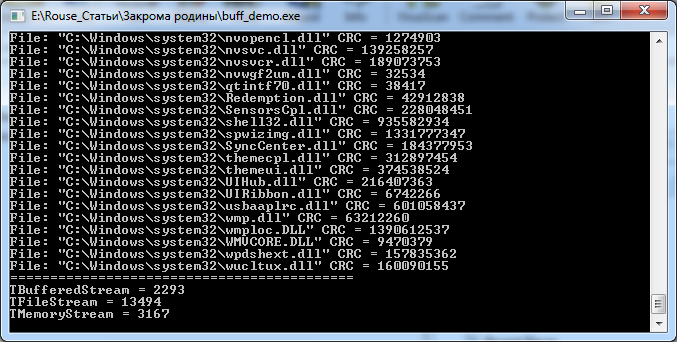
Смотрим результат (на картинке уже включены результаты от TBufferedStream):
TFileStream, как и ожидалось, сильно отстал, а вот TMemoryStream показал результат очень приближенный к результатам еще не рассмотренного нами TBufferedStream.
Ничего страшного, дело в том, что сделал он это с большим оверхедом по памяти, т.к. ему пришлось загружать каждую библиотеку в память приложения (просадка), но догнал по скорости как раз по той же самой причине (уходом от необходимости частого чтения данных с диска).
А теперь сам TBufferedStream:
TBufferedStream = class(TStream) private FStream: TStream; FOwnership: TStreamOwnership; FPosition: Int64; FBuff: array of byte; FBuffStartPosition: Int64; FBuffSize: Integer; function GetBuffer_EndPosition: Int64; procedure SetBufferSize(Value: Integer); protected property Buffer_StartPosition: Int64 read FBuffStartPosition; property Buffer_EndPosition: Int64 read GetBuffer_EndPosition; function Buffer_Read(var Buffer; Size: LongInt): Longint; function Buffer_Update: Boolean; function Buffer_Contains(APosition: Int64): Boolean; public constructor Create(AStream: TStream; AOwnership: TStreamOwnership = soReference); overload; constructor Create(const AFileName: string; Mode: Word; ABuffSize: Integer = 1024 * 1024); overload; destructor Destroy; override; function Read(var Buffer; Count: Longint): Longint; override; function Write(const Buffer; Count: Longint): Longint; override; function Seek(const Offset: Int64; Origin: TSeekOrigin): Int64; override; property BufferSize: Integer read FBuffSize write SetBufferSize; procedure InvalidateBuffer; end;
Паблик секция не представляет из себя ничего необычного, все те же перекрытые Read/Write/Seek, как и у любого другого прокси-стрима.
Весь фокус начинается с вот такой функции:
function TBufferedStream.Read(var Buffer; Count: Longint): Longint; var Readed: Integer; begin Result := 0; while Result < Count do begin Readed := Buffer_Read(PAnsiChar(@Buffer)[Result], Count - Result); Inc(Result, Readed); if Readed = 0 then if not Buffer_Update then Exit; end; end;
Как можно понять по коду, мы пытаемся прочитать данные вызовом функции Buffer_Read, которая возвращает их из уже подготовленного кэша, а если не смогли прочитать, производится попытка переинициализации кэша вызовом Buffer_Update.
Реинициализация кэша выглядит так:
function TBufferedStream.Buffer_Update: Boolean; begin FStream.Position := FPosition; FBuffStartPosition := FPosition; SetLength(FBuff, FBuffSize); SetLength(FBuff, FStream.Read(FBuff[0], FBuffSize)); Result := Length(FBuff) > 0 end;
Т.е. выделяем память под кэш, размером, указанным в свойстве BufferSize класса, после чего производим попытку считать в кэш данные из контролируемого нами стрима.
Если данные считались успешно, правим фактический размер кэша (ибо если хотели считать мегабайт, а всего доступно только 15 байт, то освободим ненужную память, зачем нам лишнее?).
Операция чтения из кэша так-же проста:
function TBufferedStream.Buffer_Read(var Buffer; Size: LongInt): Longint; begin Result := 0; if not Buffer_Contains(FPosition) then Exit; Result := Buffer_EndPosition - FPosition + 1; if Result > Size then Result := Size; Move(FBuff[Integer(FPosition - Buffer_StartPosition)], Buffer, Result); Inc(FPosition, Result); end;
Просто проверяем текущую позицию стрима и убеждаемся что мы действительно храним необходимые данные, доступные по данному оффсету, после чего банальным Move перекидываем данные во внешний буфер.
Остальные методы данного класса чересчур тривиальны, поэтому рассматривать я их не буду, с ними можно будет ознакомится в демопримерах в архиве к статье: ".\src\bufferedstream\"
Что в итоге получается:
- Класс TBufferedStream имеет гораздо меньший (в разы) оверхед по скорости чтения данных, чем TFileStream, из-за реализованного в нем кэша. Количество операций чтения данных с диска (что само по себе есть достаточно «тяжелая операция») существенно уменьшено.
- По этой же причине накладные расходы по скорости гораздо меньше по сравнению с TMemoryStream, т.к. читаются в кэш только нужные данные, а не весь файл целиком.
- Оверхед по памяти существенно ниже чем у TMemoryStream, по понятным причинам. Конечно, в данном случае, по затратам на память выиграет TFileStream, но, опять-же, скорость...
- Класс предоставляет удобную в использовании прослойку, позволяющую не задумываться о времени жизни контролируемого им стрима и сохраняющую весь необходимый для работы функционал.
Понравилось?
Тогда перейдем ко второй части.
TOnMemoryStream
А вот представьте что данные, которые мы хотим прочитать, уже расположены в памяти нашего приложения. Дабы не переусложнять, остановимся опять на тех же библиотеках, рассмотреных в первой части статьи. Чтобы выполнить ту же самую работу, которая была показана в функции CalcResOffset, нам потребуется каким-то образом перекинуть данные о библиотеке в какой-то наследник от TStream (к примеру в тот-же TMemoryStream).
И что мы сделаем в этом случае?
В 99 процентах случаев, создадим TMemoryStream и вызовем функцию Write(WriteBuffer).
А разве это нормально, ведь мы же по сути просто скопируем данные, которые и так уже у нас есть? И ведь сделаем то мы это по одной единственной причине — для того, чтобы можно было работать с данными посредством привычного нам TStream.
Чтобы исправить этот лишний оверхед по памяти, и был разработан вот такой простенький класс:
type TOnMemoryStream = class(TCustomMemoryStream) ///Работаем на уже выделенном блоке памяти. ///Писать можем только в случае режима not ReadOnly, и только не выходя за пределы буфера private FReadOnly: Boolean; protected procedure SetSize(NewSize: Longint); override; public constructor Create(Ptr: Pointer; Size: Longint; ReadOnlyMode: Boolean = True); function Write(const Buffer; Count: Longint): Longint; override; property ReadOnly: Boolean read FReadOnly write FReadOnly; end; implementation { TOnMemoryStream } constructor TOnMemoryStream.Create(Ptr: Pointer; Size: Longint; ReadOnlyMode: Boolean = True); begin inherited Create; SetPointer(Ptr, Size); FReadOnly := ReadOnlyMode; end; function TOnMemoryStream.Write(const Buffer; Count: Longint): Longint; var Pos: Longint; begin if (Position >= 0) and (Count >= 0) and (not ReadOnly) and (Position + Count <=Size) then begin Pos := Position + Count; Move(Buffer, Pointer(Longint(Memory) + Position)^, Count); Position := Pos; Result := Count; end else Result := 0; end; procedure TOnMemoryStream.SetSize(NewSize: Longint); begin raise Exception.Create('TOnMemoryStream.SetSize can not be called.'); end;
Даже не знаю что можно добавить к этому коду в качестве коментария, поэтому давайте просто посмотрим работу с данным классом.
program onmemorystream_demo; {$APPTYPE CONSOLE} {$R *.res} uses Windows, SysUtils, common_payload in '..\common\common_payload.pas', OnMemoryStream in 'OnMemoryStream.pas'; var M: TOnMemoryStream; begin try M := TOnMemoryStream.Create( Pointer(GetModuleHandle('ntdll.dll')), 1024 * 1024 * 8 {позволяем читать данные в пределах 8 мегабайт}); try CalcResOffset(M, False); finally M.Free; end; except on E: Exception do Writeln(E.ClassName, ': ', E.Message); end; Readln; end.
Здесь все просто — ищем адрес загруженной NTDLL.DLL и читаем ее секцию ресурсов напрямую из памяти, изпользуя все преимущества стрима (и не нужно ничего копировать во временный буфер.
Теперь несколько коментариев по использовании класса.
Вообще — он очень приятен, если его применять только в операциях чтения данных, но… как видно по коду, он не запрещает запись данных в контролируемый им блок памяти, а это может грозить большими неприятностями.
Мы можем легко перезатереть критичные для работы приложения данные, после чего выйти на банальное AV, поэтому в наших проектах использвание этой возможности класса сведено к минимуму (буквально перестраиваем поисковые индексы в нужных местах на заранее выделенном буфере — так просто проще).
Кстати, именно по этой причине мы отказались от использования Friendly классов, позволяющих получить доступ к вызову TCustomMemoryStream.SetPointer, т.к. в таком случае запись не будет контролироваться вообще никем, что может привести в итоге к хорошему такому «бадабуму».
Исходный код класса и примера можно посмотреть в архиве: ".src\onmemorystream\"
Впрочем, перейдем к заключающей части статьи.
Частный случай смартпойнера — SharedPtr
Сейчас буду учить плохому.
Давайте посмотрим как в Delphi принято работать с объектами. Обычно это выглядит так:
var T: TObject; begin T := TObject.Create; try // работаем с Т finally T.Free; end;
Новички в языке, конечно, забывают про использование секции финализации, выкатывая перлы вроде этого:
T := TObject.Create; // работаем с Т T.Free;
А то и вообще, забывая про необходимость освобождения объекта, не говорят объекту Free.
Некоторые «продвинутые новички» умудряются реализовать даже вот такой «говнокод»
try T := TObject.Create; // работаем с Т finally T.Free; end;
А однажды я встретился и вот с такой реализацией:
try finally T := TObject.Create; // работаем с Т T.Free; end;
Ну старался человек — сразу видно.
Впрочем, давайте все же остановимся на первом варианте правильного кода.
Минус у него следующий — если нам потребуется работа с несколькими классами одновременно, нам придется существенно развернуть код из-за множественных использований секций финализации:
var T1, T2, T3: TObject; begin T1 := TObject.Create; try T2 := TObject.Create; try T3 := TObject.Create; try // работаем со всеми тремя экземплярами Т1/Т2/Т3 finally T3.Free; end; finally T2.Free; end; finally T1.Free; end;
Есть, конечно, вариант, немножко сомнительный и не используемый мной, но в последнее время достаточно часто встречающийся на просторах интернета:
T1 := nil; T2 := nil; T3 := nil; try T1 := TObject.Create; T2 := TObject.Create; T3 := TObject.Create; // работаем со всеми тремя экземплярами Т1/Т2/Т3 finally T3.Free; T2.Free; T1.Free; end;
Из-за первоначальной инициализации каждого объекта в данном случае не произойдет ошибки при вызове Free еще не созданного объекта (если вдруг будет поднято исключение в конструкторе предыдущего), но все равно — выглядит чересчур сомнительно.
А как вы посмотрите на то, если я скажу что вызов метода Free вообще можно не делать?
Да-да, просто создаем объект и забываем вообще про то, что его нужно разрушать.
Как это выглядит? Да вот так:
T := TObject.Create; // работаем с Т
Ну конечно прямо вот в таком виде это сделать не получится без мемлика — ну нет у нас сборщика мусора и прочего, но не торопитесь говорить: «Саня — да ты сдурел!»… ибо можно взять идею из других языков программирования и реализовать ее на нашем, «великом и могучем».
А идею мы возьмем от SharedPtr: смотрим документацию.
Логика данного класса проста — контроль времени жизни объекта посредством подсчета ссылок на него. Благо это мы умеем — есть у нас такой механизм, интерфейсами зовется.
Но не все так просто.
Конечно, с наскока, можно выкатить такую идею — реализуем в классе поддержку IUnknown и все, как только счетчик ссылок на экземпляр класса достигнет нуля — он разрушится.
Но сделать-то это мы сможет только с собственноручно написанными классами, а что делать с тем же TMemoryStream, которому весь этот фень-шуй по барабану, ибо он знать не знает об интерфейсах?
Самое логичное — писать очередной проксик, который будет держать линк на контролируемый им объект и в себе самом будет реализовывать подсчет ссылок, а при своем разрушении будет грохать доверенный ему на хранение объект.
Но тут тоже не все так радужно. Проксик-то мы напишем, да и что там его писать — идея ведь уже озвучена, но будет большая просадка как по памяти, так и по скорости работы с классом, если он будет использовать в качестве механизма подсчета ссылок классический интерфейс, со всем сопуствующим.
Поэтому подойдем к решению задачи с технической стороны и посмотрим на минусы реализации через интерфейс:
program slowsharedptr; {$APPTYPE CONSOLE} {$R *.res} uses Windows, Classes, SysUtils; type TObjectDestroyer = class(TInterfacedObject) private FObject: TObject; public constructor Create(AObject: TObject); destructor Destroy; override; end; TSharedPtr = record private FDestroyerObj: TObjectDestroyer; FDestroyer: IUnknown; public constructor Create(const AValue: TObject); end; { TObjectDestroyer } constructor TObjectDestroyer.Create(AObject: TObject); begin inherited Create; FObject := AObject; end; destructor TObjectDestroyer.Destroy; begin FObject.Free; inherited; end; { TSharedPtr } constructor TSharedPtr.Create(const AValue: TObject); begin FDestroyerObj := TObjectDestroyer.Create(AValue); FDestroyer := FDestroyerObj; end; var I: Integer; T: DWORD; begin ReportMemoryLeaksOnShutdown := True; try T := GetTickCount; for I := 0 to $FFFFFF do TSharedPtr.Create(TObject.Create); Writeln(GetTickCount - T); except on E: Exception do Writeln(E.ClassName, ': ', E.Message); end; Readln; end.
Временные затраты на исполнение данного кода будут в районе 3525 миллисекунд (запомним это число).
Суть: основную логику релизует класс TObjectDestroyer, который работает с подсчетом ссылок и разрушает переданный ему на хранение объект. TSharedPtr — структура, посредством которой происходит правильная работа со ссылками в тот момент, когда она выходит из области видимости (конечно, в данном случае, можно сделать и без этой структуры, но...).
Если запустите пример, то увидите, что созданные объекты будут разрушены до завершения работы приложения (впрочем, если бы это было не так, об этом вам явно было бы сообщено, т.к. взведен флаг ReportMemoryLeaksOnShutdown ).
Но давайте разберем подробней — где же здесь может быть ненужный нам оверхед (причем как по памяти, так и по скорости выполнения).
Ну, во-первых — TObjectDestroyer.InstanceSize равен 20.
Хех, получаем лишние 20 байт памяти на каждый контролируемый нами объект, а с учетом того что гранулярность менеджера памяти в Delphi равна 12 байтам, то теряются не 20 байт, а все 24. Думаете мелочи? Может быть и так — но наш вариант должен выходить (и будет) ровно на 12 байт, ибо если убирать оверхэд — так целиком.
Вторая проблема — избыточный оверхэд при вызове методов интерфейса.
Давайте вспомним, как выглядит в памяти VMT объекта, реализующего интерфейс.
VMT объекта начинается с виртуальных методов самого объекта, включая и перекрытые методы интерфейса, причем эти перекрытые методы не принадлежат интерфейсу.
И вот только за ними идет VMT методов самого интерфейса, при вызове которых происходит перенаправление (посредством CompilerMagic константы, рассчитываемой для каждого интрефейса на этапе компиляции) на реальный код.
Это можно увидеть наглядно выполнив вот такой код:
constructor TSharedPtr.Create(const AValue: TObject); var I: IUnknown; begin FDestroyerObj := TObjectDestroyer.Create(AValue); I := FDestroyerObj; I._AddRef; I._Release;
Если посмотреть на ассемблерный листинг, то мы увидим следующее:
slowsharedptr.dpr.51: I._AddRef; 004D3C73 8B45F4 mov eax,[ebp-$0c] 004D3C76 50 push eax 004D3C77 8B00 mov eax,[eax] 004D3C79 FF5004 call dword ptr [eax+$04] // нас интересует вот этот вызов slowsharedptr.dpr.52: I._Release; 004D3C7C 8B45F4 mov eax,[ebp-$0c] 004D3C7F 50 push eax 004D3C80 8B00 mov eax,[eax] 004D3C82 FF5008 call dword ptr [eax+$08] // и вот этот вызов
… которые приводят к:
004021A3 83442404F8 add dword ptr [esp+$04],-$08 // выход на VMT объекта 004021A8 E93FB00000 jmp TInterfacedObject._AddRef
в первом случае, а во втором на:
004021AD 83442404F8 add dword ptr [esp+$04],-$08 // выход на VMT объекта 004021B2 E951B00000 jmp TInterfacedObject._Release
Если бы мы наследовались в TObjectDestroyer не от IUnknown, а, к примеру, от IEnumerator, то компилятор автоматом подправил бы адреса выхода на VMT объекта примерно таким образом:
004D3A4B 83442404F0 add dword ptr [esp+$04],-$10 // было 8, стало 16 004D3A50 E9CB97F3FF jmp TInterfacedObject._AddRef 004D3A55 83442404F0 add dword ptr [esp+$04],-$10 // т.к. добавились еще несколько функций 004D3A5A E9DD97F3FF jmp TInterfacedObject._Release
Именно через такой прыжок компилятор производит вызов методов _AddRef и _Release при изменении счетчика ссылок (к примеру при присвоении интерфейса новой переменной, или при выходе за область видимости).
Поэтому сейчас будем побеждать всю эту беду и напишем свой собственный интерфейс.
Итак пишем:
PObjectDestroyer = ^TObjectDestroyer; TObjectDestroyer = record strict private class var VTable: array[0..2] of Pointer; class function QueryInterface(Self: PObjectDestroyer; const IID: TGUID; out Obj): HResult; stdcall; static; class function _AddRef(Self: PObjectDestroyer): Integer; stdcall; static; class function _Release(Self: PObjectDestroyer): Integer; stdcall; static; class constructor ClassCreate; private FVTable: Pointer; FRefCount: Integer; FObj: TObject; public class function Create(AObj: TObject): IUnknown; static; end;
Думаете это структура типа record?
Неа — это самый что ни на есть объект, со своей собственной VMT, расположенной в VTable и размером ровно в 12 байт:
FVTable: Pointer; FRefCount: Integer; FObj: TObject;
Теперь собственно сама «магия».
Инициализация VMT происходит в следующем методе:
class constructor TObjectDestroyer.ClassCreate; begin VTable[0] := @QueryInterface; VTable[1] := @_AddRef; VTable[2] := @_Release; end;
Все по канонам, и Delphi даже не заподозрит тут какой-либо подвох, ведь для нее это будет абсолютно валидная VMT, реализованная по всем законам и правилам.
Ну а основной конструктор выглядит так:
class function TObjectDestroyer.Create(AObj: TObject): IUnknown; var P: PObjectDestroyer; begin if AObj = nil then Exit(nil); GetMem(P, SizeOf(TObjectDestroyer)); P^.FVTable := @VTable; P^.FRefCount := 0; P^.FObj := AObj; Result := IUnknown(P); end;
Через GetMem выделяем место под InstanceSize нашего «якобы» класса, не смотря на то, что он в действительности является структурой, после чего инициализируем требуемые поля в виде указателя на VMT, счетчик ссылок и указатель на контролируемый классом объект.
Причем этим мы сразу обходим оверхэд на вызове InitInstance и сопутстующую ему нагрузку.
Обратите внимение — результат вызова конструктора — интерфейс IUnknown.
Хак? Конечно.
Работает? Безусловно.
Реализация методов QueryInterface, _AddRef и _Release взята от стандартного TIntefacedObject и не интересна. Впрочем QueryInterface в данном подходе по сути избыточен, но раз мы решили делать все по классике, и закладываемся на то, что какой-то «безумный программыст» все равно попробует дернуть данный метод, то оставим его на положенном ему месте (тем более что он и так должен идти первым в VMT интерфейса. Ну не оставлять же вместо него там мусорный указатель?).
Теперь немного поколдуем над структурой, с помощью которой мы обеспечивали контроль за ссылками:
TSharedPtr<T: class> = record private FPtr: IUnknown; function GetValue: T; inline; public class function Create(AObj: T): TSharedPtr<T>; static; inline; class function Null: TSharedPtr<T>; static; property Value: T read GetValue; function Unwrap: T; end;
Немножко поменялся конструктор:
class function TSharedPtr<T>.Create(AObj: T): TSharedPtr<T>; begin Result.FPtr := TObjectDestroyer.Create(AObj); end;
Впрочем, суть от этого не изменилась.
Добавился новый метод, посредством которого можно будет получать доступ, к котролируемому нашим шарепойнтером объекту:
function TSharedPtr<T>.GetValue: T; begin if FPtr = nil then Exit(nil); Result := T(PObjectDestroyer(FPtr)^.FObj); end;
Ну и две утилитарных процедуры, первая из которых просто уменьшает количество ссылок:
class function TSharedPtr<T>.Null: TSharedPtr<T>; begin Result.FPtr := nil; end;
А вторая отключает контролируемый классом объект от всего этого механизма:
function TSharedPtr<T>.Unwrap: T; begin if FPtr = nil then Exit(nil); Result := T(PObjectDestroyer(FPtr).FObj); PObjectDestroyer(FPtr).FObj := nil; FPtr := nil; end;
Теперь давайте посмотрим — а зачем вообще оно все это нужно?
Рассмотрим ситуацию:
Вот, к примеру, создали мы некий экземпляр класса, за которым следит TObjectDestroyer и отдали его наружу, что в этом случае произойдет?
Правильно — как только завершится выполнение кода процедуры, в которой был создан объект, он будет сразу разрушен и внешний код будет работать с уже убитым указателем.
Именно для этого и введен класс TSharedPtr, посредством которого можно «прокидывать» данные по процедурам нашего приложения, не боясь преждевременного разрушения объекта. Как только он действительно станет никому не нужен — TObjectDestroyer его моментально грохнет и всем будет нирвана.
Но это еще не все.
Покрутив реализацию TSharedPtr мы все же пришли к выводу, что она не совсем удачна. И знаете почему?
А потому что вот такой код конструктора нам показался чересчур избыточным:
TSharedPtr<TMyObj>.Create(TMyObj.Create);
Ага — именно так это и нужно вызывать, но чтобы не пугать неподготовленных к такому счастью программистов, мы решили добавить небольшую оберточку вот такого плана:
TSharedPtr = record public class function Create<T: class>(AObj: T): TSharedPtr<T>; static; inline; end; ... class function TSharedPtr.Create<T>(AObj: T): TSharedPtr<T>; begin Result.FPtr := TObjectDestroyer.Create(AObj); end;
После которой все стало гораздо приятней, и вызов шарепойнтера стал выглядеть гораздо привычнее, и похожим на создание ранее озвученного проксика:
TSharedPtr.Create(TObject.Create)
Впрочем, хватит разглагольствовать и посмотрим на просадку по времени (а она, конечно, будет):
Пишем код:
program sharedptr_demo; {$APPTYPE CONSOLE} {$R *.res} uses Windows, System.SysUtils, StaredPtr in 'StaredPtr.pas'; const Count = $FFFFFF; procedure TestObj; var I: Integer; Start: Cardinal; Obj: TObject; begin Start := GetTickCount; for I := 0 to Count - 1 do begin Obj := TObject.Create; try // do nothing... finally Obj.Free; end; end; Writeln(PChar('TObject: ' + (GetTickCount - Start).ToString())); end; procedure TestAutoDestroy; var I: Integer; Start: Cardinal; begin Start := GetTickCount; for I := 0 to Count - 1 do TObject.Create.AutoDestroy; Writeln(PChar('AutoDestroy: ' + (GetTickCount - Start).ToString())); end; procedure TestSharedPtr; var I: Integer; Start: Cardinal; begin Start := GetTickCount; for I := 0 to Count - 1 do TSharedPtr.Create(TObject.Create); Writeln(PChar('SharedPtr: ' + (GetTickCount - Start).ToString())); end; begin try TestObj; TestAutoDestroy; TestSharedPtr; except on E: Exception do Writeln(E.ClassName, ': ', E.Message); end; Readln; end.
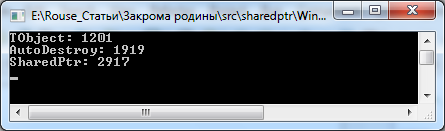
И смотрим, что получилось:

В первом варианте шарепойнтера была задержка в 3525 миллисекунд, новый вариант выдет число 2917 — не зря старались, получается.
Однако — что это за AutoDestroy, который обогнал шарепойнтер на целую секунду?
Это хэлпер, и это плохо.
Плохо, потому что этот хэлпер реализован над TObject:
TObjectHelper = class helper for TObject public function AutoDestroy: IUnknown; inline; end; ... { TObjectHelper } function TObjectHelper.AutoDestroy: IUnknown; begin Result := TObjectDestroyer.Create(Self); end;
Дело в том что, по крайней мере в ХЕ4 все еще не побежден конфликт с пересекающимися хэлперами, т.е. если у вас есть собственный хэлпер над TStream и вы попробуете подключить к нему в пару TObjectHelper — проект не сбилдится.
Не знаю, решена ли эта проблема в ХЕ7, но в четверке она точно присутствует, и по этой причине мы не используем данный кусок кода, хотя он гораздо производительней, чем использование структуры TSharedPtr.
Теперь давайте рассмотрим предпоследний момент, о котором я говорил выше, а именно — о реализации прыжка на VMT, для этого напишем две простых процедуры:
procedure TestInterfacedObjectVMT; var I: IUnknown; begin I := TInterfacedObject.Create; end;
В самом начале я упоминал, что использорвание простейшего варианта TSharedPtr в самом первом примере немного избыточно. Да, это так, в том случае можно было просто запоминать ссылку на интерфейс в локальной переменной (чем TSharedPtr по сути и занимается, правда немного другим способом);
Итак, смотрим, что происходит в этом варианте кода:
1. Создание объекта и инициализация интерфейса:
sharedptr_demo.dpr.60: I := TInterfacedObject.Create; 004192BB B201 mov dl,$01 004192BD A11C1E4000 mov eax,[$00401e1c] 004192C2 E899C5FEFF call TObject.Create 004192C7 8BD0 mov edx,eax 004192C9 85D2 test edx,edx 004192CB 7403 jz $004192d0 004192CD 83EAF8 sub edx,-$08 004192D0 8D45FC lea eax,[ebp-$04] 004192D3 E8C801FFFF call @IntfCopy
2. Вызов секции финализации:
sharedptr_demo.dpr.61: end; 004192D8 33C0 xor eax,eax 004192DA 5A pop edx 004192DB 59 pop ecx 004192DC 59 pop ecx 004192DD 648910 mov fs:[eax],edx 004192E0 68F5924100 push $004192f5 004192E5 8D45FC lea eax,[ebp-$04] 004192E8 E89B01FFFF call @IntfClear // <<< нас интересует вот этот вызов 004192ED C3 ret
3. После чего управление передается на @IntfClear, где нас и поджидает озвученный ранее прыжок:
00401DE1 83442404F8 add dword ptr [esp+$04],-$08 00401DE6 E951770000 jmp TInterfacedObject._Release
А что происходит в варинте использования TObjectDestroyer?
procedure TestSharedPtrVMT; begin TObjectDestroyer.Create(TObject.Create); end;
1. Создание объекта и создание самого TObjectDestroyer:
sharedptr_demo.dpr.66: TObjectDestroyer.Create(TObject.Create); 004D3C27 B201 mov dl,$01 004D3C29 A184164000 mov eax,[$00401684] 004D3C2E E89945F3FF call TObject.Create 004D3C33 8D55FC lea edx,[ebp-$04] 004D3C36 E8B5FBFFFF call TObjectDestroyer.Create
Да, есть оверхед, лишнее действие, как-никак. Впрочем, а что там с разрушением?
2. Все очень просто:
sharedptr_demo.dpr.67: end; 004D3C3B 33C0 xor eax,eax 004D3C3D 5A pop edx 004D3C3E 59 pop ecx 004D3C3F 59 pop ecx 004D3C40 648910 mov fs:[eax],edx 004D3C43 68583C4D00 push $004d3c58 004D3C48 8D45FC lea eax,[ebp-$04] 004D3C4B E8DC92F3FF call @IntfClear 004D3C50 C3 ret
Практически идентично первому варианту.
Но самое интересное все же произойдет при вызове @IntfClear, он пропустит избыточные прыжки по VMT и передаст управление сразу на class function TObjectDestroyer._Release.
В итоге сэкономили на вызове двух инструкций (add и jmp), но это к сожалению пока что самое минимальное, что можно сделать, т.к. в случае использования проксика — накладные расходы ну просто не избежны.
В завершение, осталось только посмотреть, как использовать механизм автоматического разрушения объекта на практике:
К примеру, создадим файловый стрим и запишем в него некую константу:
procedure TestWriteBySharedPtr; var F: TFileStream; ConstData: DWORD; begin ConstData := $DEADBEEF; F := TFileStream.Create('data.bin', fmCreate); TObjectDestroyer.Create(F); F.WriteBuffer(ConstData, SizeOf(ConstData)); end;
Да, это все — время жизни стрима контролируется, и избыточных поползновений не требуется.
В данном случае структура TSharedPtr не используется, т.к. отсутствует необходимость передачи указателя между участками кода и достаточно функционала TObjectDestroyer.
А теперь прочитаем значение константы из файла и выведем на экран, причем сразу посмотрим на передачу данных между процедурами.
Вот так мы создадим объект, контролируемый шарепойнтером:
function CreateReadStream: TSharedPtr<TFileStream>; begin Result := TSharedPtr.Create(TFileStream.Create('data.bin', fmOpenRead or fmShareDenyWrite)); end;
А так мы получим из этого объекта данные:
procedure TestReadBySharedPtr; var F: TSharedPtr<TFileStream>; ConstData: DWORD; begin F := CreateReadStream; F.Value.ReadBuffer(ConstData, SizeOf(ConstData)); Writeln(IntToHex(ConstData, 8)); end;
Как видите — код практически не изменился, если сравнивать его с классическим подходом к разработке ПО.
Плюсы — пропала необходимость использования блоков TRY..FINALLY, код стал менее перегруженным по объему.
Минусы — небольшой оверхэд по скорости и немного расширились конструкторы, заставляя нас каждый раз вызывать TSharedPtr.Create (в члучае передачи данных на внешку) или TObjectDestroyer для контроля времени жизни.
Так же появился дополнительный параметр Value, посредством которого можно получить доступ к контролируемому объекту в случае использования TSharedPtr, но к этому достаточно просто привыкнуть, тем более, что это все, на что способна дельфи в плане синтаксического сахара.
Хотя я все еще мечтаю что появится DEFAULT метод объекта (или свойство не перечислимого типа), которое можно будет вызывать без указания его имени простым обращением к переменной класа, тогда бы мы объявили свойство Value у класса TSharedPtr дефолтным и работали бы с базовым объектом, даже не зная что он находится под контролем проксика :)
Выводы
Вывод один — утомился я все это расписывать.
А если серьезно, все три показанные выше подхода достаточно удобные, по сути, причем первые два я использую практически повсеместно.
С TSharedPtr я, конечно, осторожничаю.
Не подумайте что он плох — по другой причине. Мне все еще (за столько-то лет практики) некомфортно наблюдать код без использования секций финализации, хотя задним мозжечком-то я, конечно, понимаю, что все это сработает как надо — но… не привычно.
Поэтому TSharedPtr я использую только в нескольких частных случаях — когда нужно отпустить объект на волю во внешний, не контролируемый мной код, хотя мои коллеги придерживаются несколько другой точки зрения и используют его достаточно часто (конечно, не везде, ибо сами видите, что основной его минус — двойная просадка по скорости, как расплата за удобство использования).
И на этом, пожалуй, я закругляюсь.
Проверяйте свои закрома — делитесь, ведь там точно есть что-то полезное.
Исходный код демопримеров доступен по данной ссылке.

