Если пройтись по коллегам и спросить сколько у них сотовых телефонов, то окажется, что в среднем их около 2.5, но при этом у подавляющего большинства их не больше одного. Тут возникает сразу множество вопросов начиная от того, почему их вдруг не целое число и как же все-таки оценить сколько телефонов в среднем у человека.
Для таких целей подойдет оценка медианы. То есть такая статистика, что половина значений выборки меньше, а половина больше. Более формально: упорядочим значения выборки) по порядку
по порядку ![(x_{[1]}, ..., x_{[n]})](http://tex.s2cms.ru/svg/(x_%7B%5B1%5D%7D%2C%20...%2C%20x_%7B%5Bn%5D%7D)) и выберем среди них с порядковым номером
и выберем среди них с порядковым номером ) . У такой оценки есть несколько преимуществ. Она менее подвержена влиянию ошибочных данных, значение всегда будет из того множества, что встречалось в выборке, но есть и неприятные недостатки, главный из них, это сложность подсчета, даже для довольно распространенных распределений не существует общей формулы расчета (точнее есть, но ее сложно применить на практике, смотрите Распределение порядковой статистики).
. У такой оценки есть несколько преимуществ. Она менее подвержена влиянию ошибочных данных, значение всегда будет из того множества, что встречалось в выборке, но есть и неприятные недостатки, главный из них, это сложность подсчета, даже для довольно распространенных распределений не существует общей формулы расчета (точнее есть, но ее сложно применить на практике, смотрите Распределение порядковой статистики).
Для конкретной же выборки, мы всегда можем упорядочить данные и взять из них средний элемент, но беда заключается в том, что для этого нам нужны все значения выборки, при этом одноврЕмЕнно. В работе Munro, Patterson (1980) заявлена теорема, которая говорит, что ничего лучше придумать нельзя и можно расходиться.

Но что же делать, если мы не можем позволить себе хранить сто тысяч миллионов значений. С одной стороны можно заняться задачей как отсортировать миллион int-ов в 2 мб оперативки. С другой, в упомянутой выше статье приводится простое решение, которое при некоторых допущениях с некоторой вероятностью приводит к правильному решению. А именно предлагается следующий алгоритм.
Пусть имеется поток данных длины (в этом алгоритме, хорошо бы длину потока знать заранее), который мы можем последовательно зачитывать по одному значению. Мы располагаем
(в этом алгоритме, хорошо бы длину потока знать заранее), который мы можем последовательно зачитывать по одному значению. Мы располагаем  ячейками памяти, при этом
ячейками памяти, при этом  и входной поток устроен таким образом, что любая перестановка из N элементов равновероятна. В таком случае, если нам повезет, то алгоритм выдаст значение медианы.
и входной поток устроен таким образом, что любая перестановка из N элементов равновероятна. В таком случае, если нам повезет, то алгоритм выдаст значение медианы.
Алгоритм очень прост: хранятся два счетчика) и подвыборку, состоящую из не более, чем
и подвыборку, состоящую из не более, чем  элементов из входных данных. Счетчик
элементов из входных данных. Счетчик  хранит число элементов, которые меньше минимального в подвыборке, счетчик
хранит число элементов, которые меньше минимального в подвыборке, счетчик  — число элементов, которые больше максимального. Сама подвыборка содержит отсортированный список, так что поиск минимума и максимума в нем работает за константу, а вставка элемента линейна по . Сбалансированные деревья дадут логарифмы для всех операций за небольшую плату дополнительного роста памяти. Когда место под список закончится крайние элементы вытесняются так чтобы уравновесить счетчики
— число элементов, которые больше максимального. Сама подвыборка содержит отсортированный список, так что поиск минимума и максимума в нем работает за константу, а вставка элемента линейна по . Сбалансированные деревья дадут логарифмы для всех операций за небольшую плату дополнительного роста памяти. Когда место под список закончится крайние элементы вытесняются так чтобы уравновесить счетчики  (если
(если  , то вытесняется минимальный элемент и наоборот).
, то вытесняется минимальный элемент и наоборот).
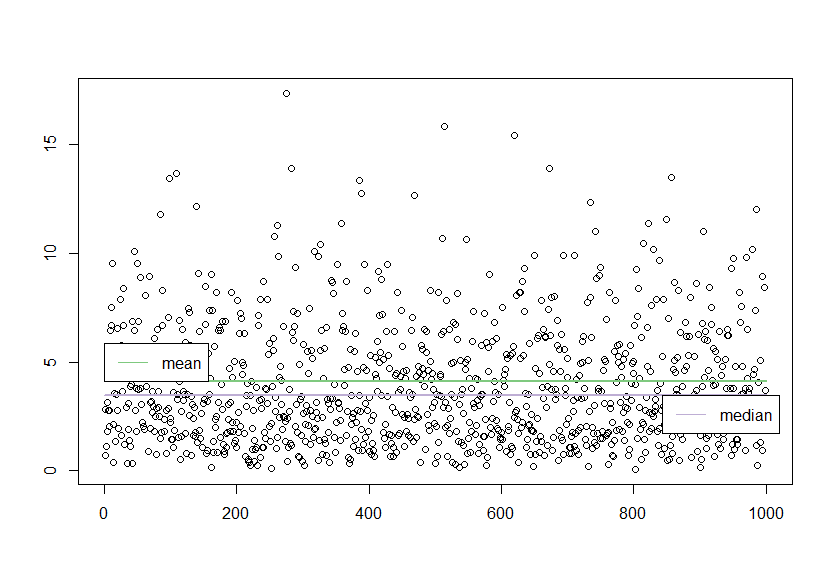
Так, что после тысячи случайных чисел при , мы можем наблюдать следующую картину.
, мы можем наблюдать следующую картину.
Если внимательно присмотреться к реализации, становится понятен смысл отсылки к “повезет, не повезет”. Медиана должна попасть в интервал значений хранимых в памяти. В статье приводятся оценки, что это будет происходить довольно часто, если пропорциональна  , что в свою очередь означает, что у нас заведомо должна быть информация о длине потока данных и даже в этом случае, мы можем оказаться очень далеко от истинного значения.
, что в свою очередь означает, что у нас заведомо должна быть информация о длине потока данных и даже в этом случае, мы можем оказаться очень далеко от истинного значения.
Данный алгоритм хорош как первое приближение, так как не очень понятно что же делать, если подсчет не удался и еще не понятно как его распараллеливать.
Дальнейшие исследования пошли в сторону приближенного вычисления медианы и идея приближения очень простая: -ая порядковая статистика это почти
-ая порядковая статистика это почти  порядковая статистика или
порядковая статистика или  или какую мы ещё помним недалеко от требуемой. Ошибку в оценке медианы измеряют в доле числа индексов, на которые мы можем “промахиваться”, к
или какую мы ещё помним недалеко от требуемой. Ошибку в оценке медианы измеряют в доле числа индексов, на которые мы можем “промахиваться”, к  — количеству просмотренных входных данных. Такую ошибку называют
— количеству просмотренных входных данных. Такую ошибку называют  , где
, где  — фиксированная допустимая ошибка: например,
— фиксированная допустимая ошибка: например,  при
при  означает, что если бы сохранили всю выборку, то полученная оценка медианы лежала бы между 495-ым и 505-ым отсортированными значениями. В случае если у нас всего 9 значений, то картинка группировки может быть следующей.
означает, что если бы сохранили всю выборку, то полученная оценка медианы лежала бы между 495-ым и 505-ым отсортированными значениями. В случае если у нас всего 9 значений, то картинка группировки может быть следующей.
Данный метод заимствует идею использования ячеек памяти, но использует отведенную память для равномерной оценки всех квантилей сразу с заданной точностью, которая зависит от объема допустимой памяти.
Данные собираются в декартово дерево (которые замечательно описаны с цикле статей), которое при достижении придельного объема отфильтровывает значения, так чтобы сохранялась заявленная точность приближения, за счет создания агрегированных узлов.
Узлом дерева является тройка: значение исходной последовательности, количество сгруппированных данных, поколение появления этого значения в исходной выборке. Так же если мы говорим о декартовой дереве мы должны определить функцию ключа и приоритета: ключом является само значение, а приоритетом количество агрегированных данных в данном узле (с примесью небольшой случайности, чтобы узлы с одинаковым числом агрегированных значений распределялись более равномерно по поддеревьям).
Для такого дерева можно определить следующие важные операции:
В статье приводится (без доказательства) теорема, о том что на случайном наборе данных количество узлов дерева будет расти пропорционально%2F%5Cvarepsilon) , что означает, что алгоритм должен быть очень компактен и спор.
, что означает, что алгоритм должен быть очень компактен и спор.
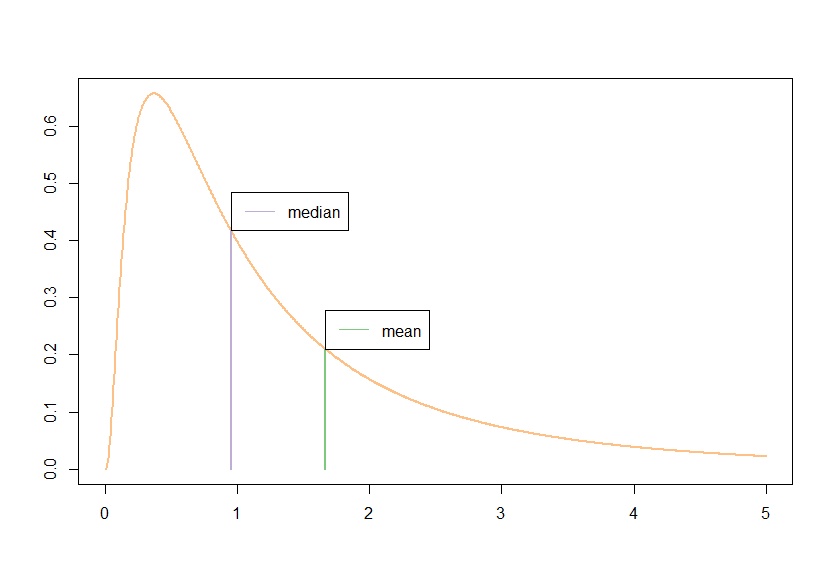
В качестве небольшого примера рассмотрим какое-нибудь симметричное и не симметричное распределения с известной медианой. Чтобы далеко не ходить, нормальное и лог-нормальное распределения нам должны подойти. Рассмотрим следующие оценки медианы для выборки в миллион значений:
Все оценки для каждого из распределений делаются на одних наборах данных и повторяются 100 раз.
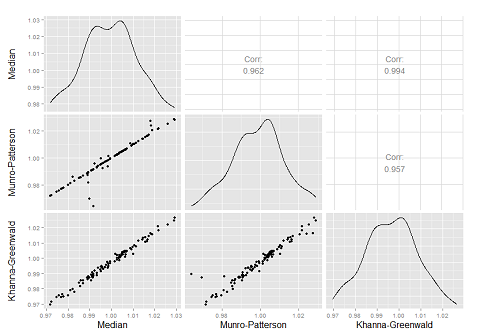
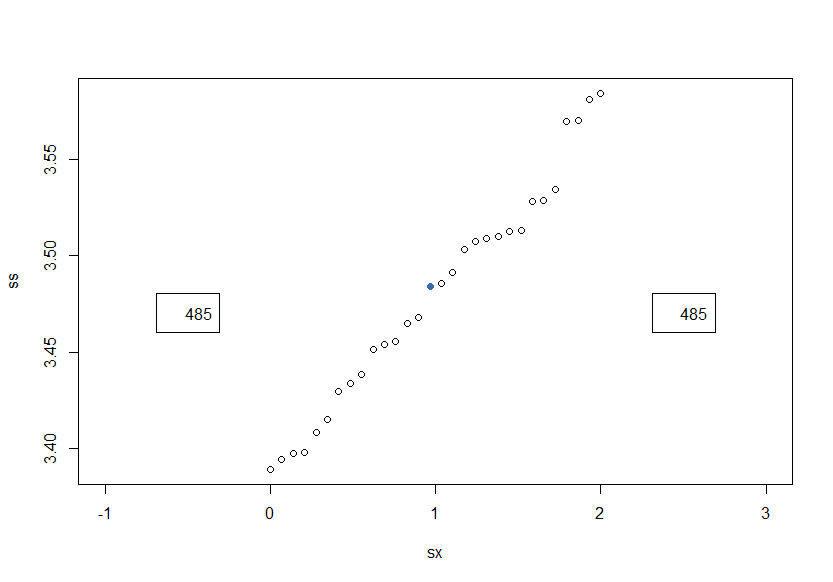
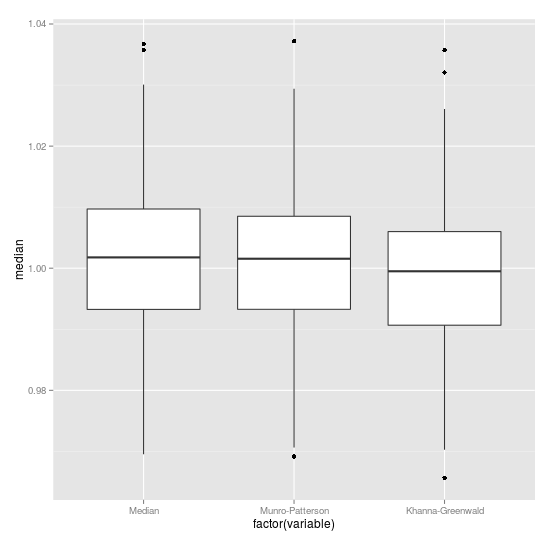
В случае нормального распределения среднее и медиана совпадают, в случае лог-нормального распределения они достаточно сильно различаются и использовать одно для оценки другого не имеет смысла (А лучше, так никогда не делать). По парным картинкам видно, что метод полной сортировки очень часто дает совпадение результатов с методом Манро-Патерсона и это правильно, но все-таки есть достаточно много около 8%, как и утверждается в статье, случаев, когда результат Манро-Патерсона отличается от истинного. Метод Канна-Гринвальда дает не плохой, но все же приближенный результат. Ниже видно, что разброс всех методов от истинного значения приблизительно одинаков.
Метод Канна-Гринвальда должен быть достаточно экономичным как по памяти так и по скорости работы, а именно в дереве храниться число элементов пропорциональное логарифму длины входной последовательности и обратно пропорциональное ошибке, а время заполнения пропорционально  .
.
Примеры реализации можно найти по ссылке на bitbucket, но это не самая оптимальная реализация.
Уже подготавливая текст я обнаружил, что именно эти статьи и методы упоминаются в курсе алгоритмы обработки потоковых данных в ПОМИ.
Спасибо parpalak за редактор.
Для таких целей подойдет оценка медианы. То есть такая статистика, что половина значений выборки меньше, а половина больше. Более формально: упорядочим значения выборки
Для конкретной же выборки, мы всегда можем упорядочить данные и взять из них средний элемент, но беда заключается в том, что для этого нам нужны все значения выборки, при этом одноврЕмЕнно. В работе Munro, Patterson (1980) заявлена теорема, которая говорит, что ничего лучше придумать нельзя и можно расходиться.
Но что же делать, если мы не можем позволить себе хранить сто тысяч миллионов значений. С одной стороны можно заняться задачей как отсортировать миллион int-ов в 2 мб оперативки. С другой, в упомянутой выше статье приводится простое решение, которое при некоторых допущениях с некоторой вероятностью приводит к правильному решению. А именно предлагается следующий алгоритм.
Метод Манро-Патерсона
Пусть имеется поток данных длины
Алгоритм очень прост: хранятся два счетчика
Так, что после тысячи случайных чисел при
Если внимательно присмотреться к реализации, становится понятен смысл отсылки к “повезет, не повезет”. Медиана должна попасть в интервал значений хранимых в памяти. В статье приводятся оценки, что это будет происходить довольно часто, если
Данный алгоритм хорош как первое приближение, так как не очень понятно что же делать, если подсчет не удался и еще не понятно как его распараллеливать.
Дальнейшие исследования пошли в сторону приближенного вычисления медианы и идея приближения очень простая:
Приближенный метод Канна-Гринвальда
Данный метод заимствует идею использования
Данные собираются в декартово дерево (которые замечательно описаны с цикле статей), которое при достижении придельного объема отфильтровывает значения, так чтобы сохранялась заявленная точность приближения, за счет создания агрегированных узлов.
Узлом дерева является тройка: значение исходной последовательности, количество сгруппированных данных, поколение появления этого значения в исходной выборке. Так же если мы говорим о декартовой дереве мы должны определить функцию ключа и приоритета: ключом является само значение, а приоритетом количество агрегированных данных в данном узле (с примесью небольшой случайности, чтобы узлы с одинаковым числом агрегированных значений распределялись более равномерно по поддеревьям).
Для такого дерева можно определить следующие важные операции:
- Добавление нового значения за
;
- Вычисления медианы и, как легко заметить, произвольного квантиля за линейное по
- Объединение деревьев при одинаковом опять же за линейное по
В статье приводится (без доказательства) теорема, о том что на случайном наборе данных количество узлов дерева будет расти пропорционально
Примеры
В качестве небольшого примера рассмотрим какое-нибудь симметричное и не симметричное распределения с известной медианой. Чтобы далеко не ходить, нормальное и лог-нормальное распределения нам должны подойти. Рассмотрим следующие оценки медианы для выборки в миллион значений:
- Упорядочивание значений
- Методом Манро-Патерсона, с параметром равным
- Методом Канна-Гринвальда c параметром
Все оценки для каждого из распределений делаются на одних наборах данных и повторяются 100 раз.
В случае нормального распределения среднее и медиана совпадают, в случае лог-нормального распределения они достаточно сильно различаются и использовать одно для оценки другого не имеет смысла (А лучше, так никогда не делать). По парным картинкам видно, что метод полной сортировки очень часто дает совпадение результатов с методом Манро-Патерсона и это правильно, но все-таки есть достаточно много около 8%, как и утверждается в статье, случаев, когда результат Манро-Патерсона отличается от истинного. Метод Канна-Гринвальда дает не плохой, но все же приближенный результат. Ниже видно, что разброс всех методов от истинного значения приблизительно одинаков.
Метод Канна-Гринвальда должен быть достаточно экономичным как по памяти так и по скорости работы, а именно в дереве храниться число элементов пропорциональное логарифму длины входной последовательности и обратно пропорциональное ошибке
ПС
Примеры реализации можно найти по ссылке на bitbucket, но это не самая оптимальная реализация.
Уже подготавливая текст я обнаружил, что именно эти статьи и методы упоминаются в курсе алгоритмы обработки потоковых данных в ПОМИ.
Спасибо parpalak за редактор.

