Здравствуйте, меня зовут Константин, я работаю front-end-разработчиком на информационно-развлекательном портале, основную долю контента которого составляют новости и статьи. И, конечно же, нам было крайне важно организовать удобную работу с порталом для наших редакторов. О том, каких успехов мы добились на данном поприще, и будет эта статья.
У себя на портале для редактирования новостей и статей мы используем WYSIWYG-редактор TinyMCE версии 4.2.4. Он показал себя с наилучшей стороны среди всех WYSIWYG-редакторов как по стабильности работы, так и по качеству формируемой HTML-разметки. К тому же он оказался наиболее простым в освоении для людей, привыкших работать с офисными приложениями.
Но одних его базовых возможностей не хватает для того, чтобы реализовать все потребности редакции. Я не стану описывать процесс конфигурирования TinyMCE: во-первых, нужды у всех разные, а во-вторых, этот момент очень хорошо освещен в документации. Зато я расскажу о решениях, которые для многих могут оказаться полезными и которые не так просто найти в интернете.
А пойдет сегодня речь о:
В последнее время количество иллюстраций в наших статьях заметно возросло. И потому одной из важнейших задач для нас стала реализация простого и удобного механизма работы с изображениями.
Вот важнейшие моменты, которые мы для себя определили:
В интернете есть немало плагинов к TinyMCE для работы с графикой (в том числе и его родной, платный плагин MoxieManager), которые имитируют файловые менеджеры. Однако, как показала практика, все эти богатые возможности «а-ля» проводник Windows редакторам совсем не нужны. И потому мы решили отказаться от данной концепции и максимально упростить загрузку иллюстраций и добавление их в статью.
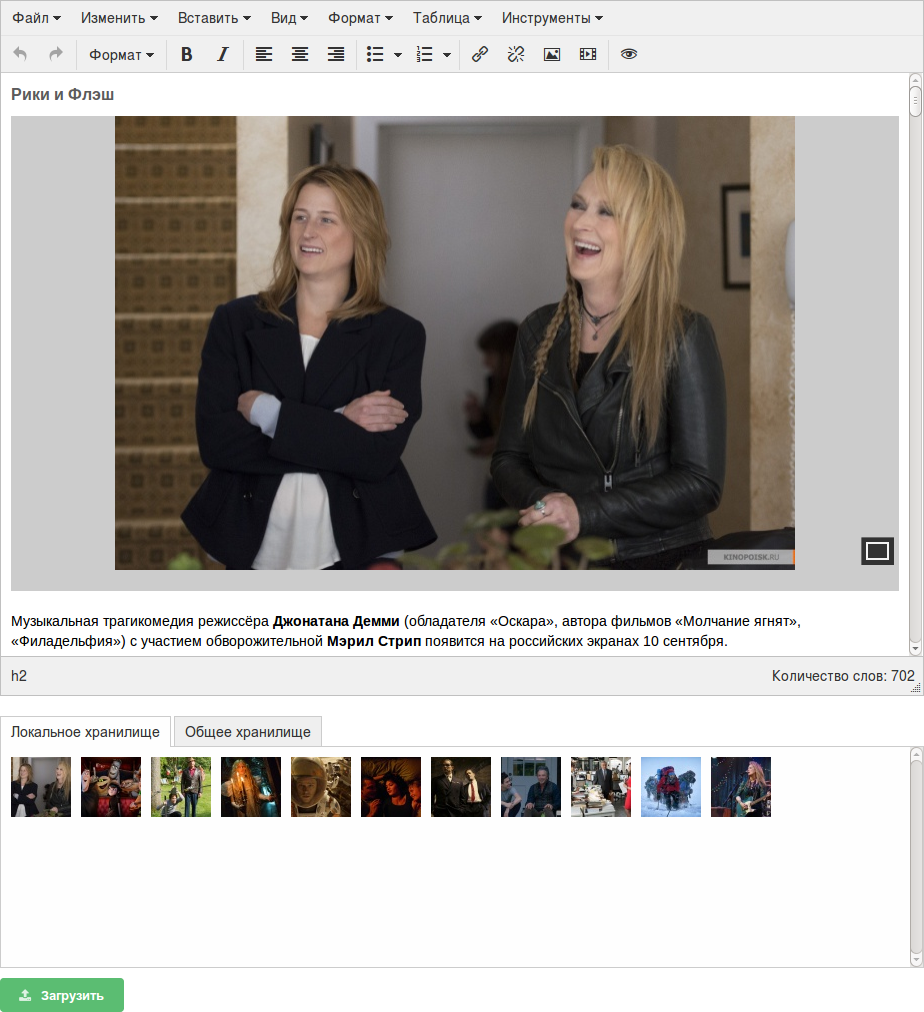
Для этого мы расположили под окном TinyMCE дополнительную панель конкретно для работы с изображениями. Мы решили, что когда кто-либо правит определенный текст, он должен видеть лишь те изображения, которые непосредственно относятся к этой статье. Их будет не так много, и каталогизировать изображения не придется. Также, на всякий случай, мы добавили в панель и вторую вкладку — для работы с глобальными иллюстрациями, которые могут быть доступны во всех статьях (но ей до сих пор не воспользовались).
Для загрузки изображений мы использовали плагин Dropzone.js. Он обладает следующими особенностями:
Его конфигурация, также как и конфигурация TinyMCE, хорошо описана в документации. Я уверен — вы с легкостью сможете заточить его работу под себя, и поэтому не буду заострять на нем внимание. Вы так же можете использовать любой другой подобный плагин, благо их сейчас достаточно много.
Благодаря такому подходу мы получили возможность хранить изображения на сервере так, как нам вздумается, и упростили процесс их загрузки. Но нашей конечной целью является все-таки добавление изображений в текст статьи.
Итак, мы имеем некую панель, на которой отображается список всех доступных для статьи изображений, и нам необходимо, чтобы при клике по этим изображениям они вставлялись в текст. Этого нам поможет добиться функция редактора TinyMCE execCommand:
Но это далеко не все — тут как раз начинается самая интересная часть. Действуя подобным образом, мы получаем богатые возможности по контролю над добавляемыми элементами.
К примеру, у нас на портале строго ограничена ширина контентной области, отведенной под статью. И если загруженное изображение намного шире — оно будет уменьшено до необходимых размеров и вставлено вместе с ссылкой на оригинал. При этом достаточно большие изображения у нас вставляются в обертке, которая растягивается на всю ширину статьи и заливается по краям средним цветом с помощью jQuery-плагина.
Определение соответствующего поведения происходит на стадии добавления иллюстрации в текст. Но как же быть, если пользователи будут редактировать изображения стандартными средствами управления TinyMCE? Чтобы не потерять контроль над элементами, добавим обработчик события NodeChange для редактора (мы делаем это в момент конфигурирования TinyMCE):
Так как различные встраиваемые элементы (iframe, embedded) в TinyMCE заменяются изображением-заглушкой, проводим дополнительную проверку на отсутствие класса mce-object, чтобы отличить их от обычных иллюстраций.
Отловив событие изменения элемента и определив, что этот элемент является изображением, мы возвращаем себе контроль над ним. Мы можем проверить, не вышли ли его размеры (установленные размеры будут переданы в объекте события: e.width, e.height) за допустимые пределы, не нарушены ли пропорции (и такое бывало) и т.д… Рекомендую сохранять оригинальные размеры изображений в data-* атрибутах элементов.
Вы можете возразить, сказав, что для отлова ресайза изображений в редакторе достаточно использовать события ObjectResizeStart и ObjectResized. Однако данные события не сработают, если размеры иллюстрации будут изменены с помощью инструмента вставки/редактирования изображения.
Еще одна хитрость — чтобы не дать изображению растягиваться больше заданных пределов (это могут быть как ограничения контентной области, так и максимальные размеры самого изображения), задайте для него свойства max-width и max-height в атрибуте style при вставке.
Таким образом мы решили несколько пунктов нашей первоначальной задачи, но нас все еще волнует ресайз изображений до размеров, заданных в статье на стороне сервера, чтобы посетителям портала не пришлось загружать большие (тяжелые) иллюстрации, которые бы лишь визуально уменьшались.
Данная проблема решается довольно просто, если для редактирования текста вы используете bb-коды — вы просто выполняете ресайз изображений в момент обработки команды вставки их в текст. В случае с WYSIWYG-редакторами у вас есть два варианта: парсить сформированный HTML или же использовать специальные ссылки. Мы выбрали второй.
Независимо от того, на чем написан ваш бэкенд, вы сможете сделать так, чтобы по определенным параметрам в ссылке формировалось подходящее изображение и помещалось в кэш. При вставке элемента в редактор сгенерировать соответствующую ссылку достаточно просто, а в момент редактирования изображения нам на помощь вновь придёт обработчик события NodeChange. Главное помнить, что при изменении атрибута src элемента необходимо будет поменять еще и атрибут data-mce-src.
Вот такой обработчик используется у нас (для работы с DOM здесь применяется jQuery):
Как видите, даже если оригинальные размеры изображения не указаны в data-* атрибутах, функция пытается вычислить их самостоятельно и выполнить все необходимые проверки. Такой подход позволяет обеспечить совместимость с уже накопленным ранее материалом на портале.
Именно эта задача вызвала у нас больше всего трудностей.
После тщательного изучения документации по TinyMCE было обнаружено, что нет никакой возможности сконфигурировать редактор так, чтобы он очищал HTML-разметку от различного мусора при вставке текста из Word'а или же с других сайтов, и при этом бы не урезал функциональные возможности пользователей. Готовых решений, удовлетворяющих нашим потребностям, в интернете мы также не нашли.
Пришлось справляться собственными силами, и вот что у нас получилось github.com/WEACOMRU/html-formatting.
Представленная в репозитории функция проверяет соответствие содержимого переданного ей контейнера определенным правилам и избавляется от всего лишнего. Она написана на чистом JS и не требует никаких зависимостей и распространяется по лицензии MIT.
Для форматирования разметки в момент вставки текста в TinyMCE необходимо задать обработчик события paste_postprocess:
С принципами конфигурирования правил вы можете ознакомиться на гитхабе, я же расскажу о том, как эта функция работает.
Если смотреть на уже готовое решение, все оказывается достаточно элементарно: в цикле перебираем все дочерние элементы HTML-контейнера и для каждого запускаем отдельную обработку. Функцию выполняем рекурсивно до тех пор, пока не достигнем самого глубокого уровня вложенности.
В процессе обработки отдельного элемента прежде всего проверяем, с чем мы имеем дело: с HTML-элементом или же с текстом.
Текстовые элементы обрабатываются по-своему — из них удаляются все неразрывные пробелы.
Это вызвано тем, что наши редакторы испытывали трудности из-за сохраняющихся неразрывных пробелов в скопированном тексте, которые ломали переносы в статье. Данная процедура решает эту проблему, однако она может оказаться нежелательной для вас, если это так — подправьте исходный код функции под свои нужды.
Обработка HTML-элементов выполняется в соответствии с заданными правилами.
Если правило для данного элемента не найдено — он распаковывается, т.е. все его дочерние элементы выносятся на уровень выше и заменяют данный элемент.
При наличии соответствующего правила элемент сохраняется, если он не пуст (непустым считается контейнер, содержащий хоть один текстовый элемент на любом уровне вложенности, состоящий не только из пробелов) или же в правиле нет установки удалять пустые элементы (no_empty).
В зависимости от конфигурации правила проверяются стили и классы элемента.
Тут же проверяется необходимость конвертации и его дополнительной обработки и удаляется идентификатор.
Надо отметить, что при конвертации создается новый элемент, в который помещаются все дочерние элементы текущего контейнера, также, при наличии, переносятся стили и классы, после чего контейнер замещается этим новым элементом.
Как вы уже, наверное, заметили, все манипуляции с DOM ставятся в очередь и выполняются по завершении текущего цикла по элементам, дабы не нарушать его.
Демо работы функции вы найдете в репозитории. Я надеюсь, что данное описание поможет вам видоизменять функцию под ваши конкретные нужды, если в чистом виде она вас не удовлетворит, или хотя бы послужит идейным вдохновением.
Ну и напоследок остается самое простое — внедрение типографа. Мы использовали замечательный скрипт Дениса Селезнева hcodes github.com/typograf/typograf.
Все, что нужно — это написать маленький плагин к TinyMCE:
Как видите, скрипт типографа размещен в папке с плагином и подгружается асинхронно средствами редактора https://www.tinymce.com/docs/api/class/tinymce.dom.scriptloader/. Вы же можете загружать скрипт отдельно от TinyMCE, если планируете использовать типограф и в других функциях.
Когда скрипт загружен, происходит инициализация переменной tp. Доступ к контенту редактора осуществляется с помощью методов getContent() и setContent(). Ну и, конечно, после применения типографики нужно добавить еще один уровень отката изменений, используя undoManager.
В качестве иконки для кнопки и пункта меню мы использовали шрифтовую иконку редактора для цитат. С перечнем доступных иконок в TinyMCE вы можете ознакомиться в файле skin.css — (классы .mce-i-*).
На этом все, надеемся наш опыт поможет вам в реализации собственных идей и сократит время поиска решений.
У себя на портале для редактирования новостей и статей мы используем WYSIWYG-редактор TinyMCE версии 4.2.4. Он показал себя с наилучшей стороны среди всех WYSIWYG-редакторов как по стабильности работы, так и по качеству формируемой HTML-разметки. К тому же он оказался наиболее простым в освоении для людей, привыкших работать с офисными приложениями.
Но одних его базовых возможностей не хватает для того, чтобы реализовать все потребности редакции. Я не стану описывать процесс конфигурирования TinyMCE: во-первых, нужды у всех разные, а во-вторых, этот момент очень хорошо освещен в документации. Зато я расскажу о решениях, которые для многих могут оказаться полезными и которые не так просто найти в интернете.
А пойдет сегодня речь о:
- работе с изображениями;
- форматировании HTML-разметки при вставке текста из внешних источников;
- типографике.
Работа с изображениями
В последнее время количество иллюстраций в наших статьях заметно возросло. И потому одной из важнейших задач для нас стала реализация простого и удобного механизма работы с изображениями.
Вот важнейшие моменты, которые мы для себя определили:
- простая загрузка изображений;
- простая вставка изображений в текст;
- ресайз изображений до размеров, заданных в тексте;
- простое создание ссылки на увеличенное изображение.
В интернете есть немало плагинов к TinyMCE для работы с графикой (в том числе и его родной, платный плагин MoxieManager), которые имитируют файловые менеджеры. Однако, как показала практика, все эти богатые возможности «а-ля» проводник Windows редакторам совсем не нужны. И потому мы решили отказаться от данной концепции и максимально упростить загрузку иллюстраций и добавление их в статью.
Для этого мы расположили под окном TinyMCE дополнительную панель конкретно для работы с изображениями. Мы решили, что когда кто-либо правит определенный текст, он должен видеть лишь те изображения, которые непосредственно относятся к этой статье. Их будет не так много, и каталогизировать изображения не придется. Также, на всякий случай, мы добавили в панель и вторую вкладку — для работы с глобальными иллюстрациями, которые могут быть доступны во всех статьях (но ей до сих пор не воспользовались).
Для загрузки изображений мы использовали плагин Dropzone.js. Он обладает следующими особенностями:
- поддержка Drag'n'Drop;
- мультизагрузка через Ajax;
- простая кастомизация;
- и никаких зависимостей — только ванильный JS.
Его конфигурация, также как и конфигурация TinyMCE, хорошо описана в документации. Я уверен — вы с легкостью сможете заточить его работу под себя, и поэтому не буду заострять на нем внимание. Вы так же можете использовать любой другой подобный плагин, благо их сейчас достаточно много.
Благодаря такому подходу мы получили возможность хранить изображения на сервере так, как нам вздумается, и упростили процесс их загрузки. Но нашей конечной целью является все-таки добавление изображений в текст статьи.
Итак, мы имеем некую панель, на которой отображается список всех доступных для статьи изображений, и нам необходимо, чтобы при клике по этим изображениям они вставлялись в текст. Этого нам поможет добиться функция редактора TinyMCE execCommand:
tinymce.activeEditor.execCommand('mceInsertContent', false, img);
Но это далеко не все — тут как раз начинается самая интересная часть. Действуя подобным образом, мы получаем богатые возможности по контролю над добавляемыми элементами.
К примеру, у нас на портале строго ограничена ширина контентной области, отведенной под статью. И если загруженное изображение намного шире — оно будет уменьшено до необходимых размеров и вставлено вместе с ссылкой на оригинал. При этом достаточно большие изображения у нас вставляются в обертке, которая растягивается на всю ширину статьи и заливается по краям средним цветом с помощью jQuery-плагина.
Определение соответствующего поведения происходит на стадии добавления иллюстрации в текст. Но как же быть, если пользователи будут редактировать изображения стандартными средствами управления TinyMCE? Чтобы не потерять контроль над элементами, добавим обработчик события NodeChange для редактора (мы делаем это в момент конфигурирования TinyMCE):
tinymce.init({ /* Конфигурация редактора */ setup: function (editor) { editor.on('NodeChange', function (e) { if (e.element.nodeName === 'IMG' && e.element.classList.contains('mce-object') === false) { /* Ваш код */ } }); } });
Так как различные встраиваемые элементы (iframe, embedded) в TinyMCE заменяются изображением-заглушкой, проводим дополнительную проверку на отсутствие класса mce-object, чтобы отличить их от обычных иллюстраций.
Отловив событие изменения элемента и определив, что этот элемент является изображением, мы возвращаем себе контроль над ним. Мы можем проверить, не вышли ли его размеры (установленные размеры будут переданы в объекте события: e.width, e.height) за допустимые пределы, не нарушены ли пропорции (и такое бывало) и т.д… Рекомендую сохранять оригинальные размеры изображений в data-* атрибутах элементов.
Вы можете возразить, сказав, что для отлова ресайза изображений в редакторе достаточно использовать события ObjectResizeStart и ObjectResized. Однако данные события не сработают, если размеры иллюстрации будут изменены с помощью инструмента вставки/редактирования изображения.
Еще одна хитрость — чтобы не дать изображению растягиваться больше заданных пределов (это могут быть как ограничения контентной области, так и максимальные размеры самого изображения), задайте для него свойства max-width и max-height в атрибуте style при вставке.
Таким образом мы решили несколько пунктов нашей первоначальной задачи, но нас все еще волнует ресайз изображений до размеров, заданных в статье на стороне сервера, чтобы посетителям портала не пришлось загружать большие (тяжелые) иллюстрации, которые бы лишь визуально уменьшались.
Данная проблема решается довольно просто, если для редактирования текста вы используете bb-коды — вы просто выполняете ресайз изображений в момент обработки команды вставки их в текст. В случае с WYSIWYG-редакторами у вас есть два варианта: парсить сформированный HTML или же использовать специальные ссылки. Мы выбрали второй.
Независимо от того, на чем написан ваш бэкенд, вы сможете сделать так, чтобы по определенным параметрам в ссылке формировалось подходящее изображение и помещалось в кэш. При вставке элемента в редактор сгенерировать соответствующую ссылку достаточно просто, а в момент редактирования изображения нам на помощь вновь придёт обработчик события NodeChange. Главное помнить, что при изменении атрибута src элемента необходимо будет поменять еще и атрибут data-mce-src.
Вот такой обработчик используется у нас (для работы с DOM здесь применяется jQuery):
resizeImage = function ($image, width, height) { var originalWidth = parseInt($image.data('originalWidth'), 10), originalHeight = parseInt($image.data('originalHeight'), 10), ratio, defaultWidth, defaultHeight, link = $image.attr('src'), linkParams; if (typeof width === 'undefined' || width === null) { width = parseInt($image.attr('width'), 10); } if (typeof height === 'undefined' || height === null) { height = parseInt($image.attr('height'), 10); } defaultWidth = width; defaultHeight = height; /* Для старых изображений, без сохраненных оригинальных размеров */ if (isNaN(originalWidth) || originalWidth === 0 || isNaN(originalHeight) || originalHeight === 0) { $image .attr({ width: '', height: '' }) .css({ maxWidth: 'none', maxHeight: 'none' }); originalWidth = $image.width(); originalHeight = $image.height(); ratio = originalWidth / originalHeight; var maxWidth = Math.min(originalWidth, pageWidth), maxHeight = (maxWidth === originalWidth ? originalHeight : Math.round(maxWidth / ratio)); $image .attr({ width: width, height: height, 'data-original-width': originalWidth, 'data-original-height': originalHeight }) .css({ maxWidth: maxWidth, maxHeight: maxHeight }); } else { ratio = originalWidth / originalHeight; } width = Math.min(originalWidth, pageWidth, width); height = (width === originalWidth ? originalHeight : Math.round(width / ratio)); if (link.substr(0, 7) === 'http://') { linkParams = link.substr(7).split('/'); } else { linkParams = link.split('/'); } /* Проверка соответсвия ссылки определенной структуре, и обновление ее */ if (linkParams.length === 6 && linkParams[0] === window.location.host && (linkParams[1] === 'r' || linkParams[1] === 'c') && isDecimal(linkParams[2]) && isDecimal(linkParams[3])) { link = 'http://' + linkParams[0] + '/' + linkParams[1] + '/' + width + '/' + height + '/' + linkParams[4] + '/' + linkParams[5]; $image.attr({ src: link, 'data-mce-src': link }); } if (width !== defaultWidth || height !== defaultHeight) { $image.attr({ width: width, height: height }); } } tinymce.init({ /* Конфигурация редактора */ setup: function (editor) { editor.on('NodeChange', function (e) { if (e.element.nodeName === 'IMG' && e.element.classList.contains('mce-object') === false) { resizeImage($(e.element), e.width, e.height); } }); } });
Как видите, даже если оригинальные размеры изображения не указаны в data-* атрибутах, функция пытается вычислить их самостоятельно и выполнить все необходимые проверки. Такой подход позволяет обеспечить совместимость с уже накопленным ранее материалом на портале.
Форматирование HTML-разметки
Именно эта задача вызвала у нас больше всего трудностей.
После тщательного изучения документации по TinyMCE было обнаружено, что нет никакой возможности сконфигурировать редактор так, чтобы он очищал HTML-разметку от различного мусора при вставке текста из Word'а или же с других сайтов, и при этом бы не урезал функциональные возможности пользователей. Готовых решений, удовлетворяющих нашим потребностям, в интернете мы также не нашли.
Пришлось справляться собственными силами, и вот что у нас получилось github.com/WEACOMRU/html-formatting.
Представленная в репозитории функция проверяет соответствие содержимого переданного ей контейнера определенным правилам и избавляется от всего лишнего. Она написана на чистом JS и не требует никаких зависимостей и распространяется по лицензии MIT.
Для форматирования разметки в момент вставки текста в TinyMCE необходимо задать обработчик события paste_postprocess:
tinymce.init({ /* Конфигурация редактора */ paste_postprocess: function (plugin, args) { var valid_elements = { /* Конфигурация правил форматирования */ }; htmlFormatting(args.node, valid_elements); } });
С принципами конфигурирования правил вы можете ознакомиться на гитхабе, я же расскажу о том, как эта функция работает.
Если смотреть на уже готовое решение, все оказывается достаточно элементарно: в цикле перебираем все дочерние элементы HTML-контейнера и для каждого запускаем отдельную обработку. Функцию выполняем рекурсивно до тех пор, пока не достигнем самого глубокого уровня вложенности.
process = function (node, valid_elements) { var taskSet = [], i; for (i = 0; i < node.childNodes.length; i++) { processNode(node.childNodes[i], valid_elements, taskSet); } doTasks(taskSet); }
В процессе обработки отдельного элемента прежде всего проверяем, с чем мы имеем дело: с HTML-элементом или же с текстом.
processNode = function (node, valid_elements, taskSet) { var rule; if (node.nodeType === 1) { /* HTML-элемент */ } else if (node.nodeType === 3) { /* Текстовый элемент */ } }
Текстовые элементы обрабатываются по-своему — из них удаляются все неразрывные пробелы.
processText = function (node) { node.nodeValue = node.nodeValue.replace(/\xa0/g, ' '); }
Это вызвано тем, что наши редакторы испытывали трудности из-за сохраняющихся неразрывных пробелов в скопированном тексте, которые ломали переносы в статье. Данная процедура решает эту проблему, однако она может оказаться нежелательной для вас, если это так — подправьте исходный код функции под свои нужды.
Обработка HTML-элементов выполняется в соответствии с заданными правилами.
getRule = function (node, valid_elements) { var re = new RegExp('(?:^|,)' + node.tagName.toLowerCase() + '(?:,|$)'), rules = Object.keys(valid_elements), rule = false, i; for (i = 0; i < rules.length && !rule; i++) { if (re.test(rules[i])) { rule = valid_elements[rules[i]]; } } return rule; } ... processNode = function (node, valid_elements, taskSet) { var rule; if (node.nodeType === 1) { rule = getRule(node, valid_elements); ... } else if (node.nodeType === 3) { processText(node); } }
Если правило для данного элемента не найдено — он распаковывается, т.е. все его дочерние элементы выносятся на уровень выше и заменяют данный элемент.
unpack = function (node) { var parent = node.parentNode; while (node.childNodes.length > 0) { parent.insertBefore(node.childNodes[0], node); } } ... if (rule) { if (typeof rule.valid_elements === 'undefined') { process(node, valid_elements); } else { process(node, rule.valid_elements) } ... } else { process(node, valid_elements); if (node.hasChildNodes()) { taskSet.push({ task: 'unpack', node: node }); } taskSet.push({ task: 'remove', node: node }) }
При наличии соответствующего правила элемент сохраняется, если он не пуст (непустым считается контейнер, содержащий хоть один текстовый элемент на любом уровне вложенности, состоящий не только из пробелов) или же в правиле нет установки удалять пустые элементы (no_empty).
isEmpty = function (node) { var result = true, re = /^\s*$/, i, child; if (node.hasChildNodes()) { for (i = 0; i < node.childNodes.length && result; i++) { child = node.childNodes[i]; if (child.nodeType === 1) { result = isEmpty(child); } else if (child.nodeType === 3 && !re.test(child.nodeValue)) { result = false; } } } return result; } ... if (rule.no_empty && isEmpty(node)) { taskSet.push({ task: 'remove', node: node }); } else { ... }
В зависимости от конфигурации правила проверяются стили и классы элемента.
checkStyles = function (node, valid_styles) { var i, re; if (typeof valid_styles === 'string' && node.style.length) { for (i = node.style.length - 1; i >= 0; i--) { re = new RegExp('(?:^|,)' + node.style[i] + '(?:,|$)'); if (!re.test(valid_styles)) { node.style[node.style[i]] = ''; } } if (!node.style.cssText) { node.removeAttribute('style'); } } } checkClasses = function (node, valid_classes) { var i, re; if (typeof valid_classes === 'string' && node.classList.length) { for (i = node.classList.length - 1; i >= 0; i--) { re = new RegExp('(?:^|\\s)' + node.classList[i] + '(?:\\s|$)'); if (!re.test(valid_classes)) { node.classList.remove(node.classList[i]); } } if (!node.className) { node.removeAttribute('class'); } } } ... checkStyles(node, rule.valid_styles); checkClasses(node, rule.valid_classes);
Тут же проверяется необходимость конвертации и его дополнительной обработки и удаляется идентификатор.
if (rule.convert_to) { taskSet.push({ task: 'convert', node: node, convert_to: rule.convert_to }); } else if (node.id) { node.removeAttribute('id'); } if (typeof rule.process === 'function') { taskSet.push({ task: 'process', node: node, process: rule.process }); }
Надо отметить, что при конвертации создается новый элемент, в который помещаются все дочерние элементы текущего контейнера, также, при наличии, переносятся стили и классы, после чего контейнер замещается этим новым элементом.
convert = function (node, convert_to) { var parent = node.parentNode, converted = document.createElement(convert_to); if (node.style.cssText) { converted.style.cssText = node.style.cssText; } if (node.className) { converted.className = node.className; } while (node.childNodes.length > 0) { converted.appendChild(node.childNodes[0]); } parent.replaceChild(converted, node); }
Как вы уже, наверное, заметили, все манипуляции с DOM ставятся в очередь и выполняются по завершении текущего цикла по элементам, дабы не нарушать его.
doTasks = function (taskSet) { var i; for (i = 0; i < taskSet.length; i++) { switch (taskSet[i].task) { case 'remove': taskSet[i].node.parentNode.removeChild(taskSet[i].node); break; case 'convert': convert(taskSet[i].node, taskSet[i].convert_to); break; case 'process': taskSet[i].process(taskSet[i].node); break; case 'unpack': unpack(taskSet[i].node); break; } } }
Демо работы функции вы найдете в репозитории. Я надеюсь, что данное описание поможет вам видоизменять функцию под ваши конкретные нужды, если в чистом виде она вас не удовлетворит, или хотя бы послужит идейным вдохновением.
Типографика
Ну и напоследок остается самое простое — внедрение типографа. Мы использовали замечательный скрипт Дениса Селезнева hcodes github.com/typograf/typograf.
Все, что нужно — это написать маленький плагин к TinyMCE:
tinymce.PluginManager.add('typograf', function (editor, url) { 'use strict'; var scriptLoader = new tinymce.dom.ScriptLoader(), tp, typo = function () { if (tp) { editor.setContent(tp.execute(editor.getContent())); editor.undoManager.add(); } }; scriptLoader.add(url + '/typograf.min.js'); scriptLoader.loadQueue(function () { tp = new Typograf({ lang: 'ru', mode: 'name' }); }); editor.addButton('typograf', { text: 'Типографика', icon: 'blockquote', onclick: typo }); editor.addMenuItem('typograf', { context: 'format', text: 'Типографика', icon: 'blockquote', onclick: typo }); });
Как видите, скрипт типографа размещен в папке с плагином и подгружается асинхронно средствами редактора https://www.tinymce.com/docs/api/class/tinymce.dom.scriptloader/. Вы же можете загружать скрипт отдельно от TinyMCE, если планируете использовать типограф и в других функциях.
Когда скрипт загружен, происходит инициализация переменной tp. Доступ к контенту редактора осуществляется с помощью методов getContent() и setContent(). Ну и, конечно, после применения типографики нужно добавить еще один уровень отката изменений, используя undoManager.
В качестве иконки для кнопки и пункта меню мы использовали шрифтовую иконку редактора для цитат. С перечнем доступных иконок в TinyMCE вы можете ознакомиться в файле skin.css — (классы .mce-i-*).
На этом все, надеемся наш опыт поможет вам в реализации собственных идей и сократит время поиска решений.

